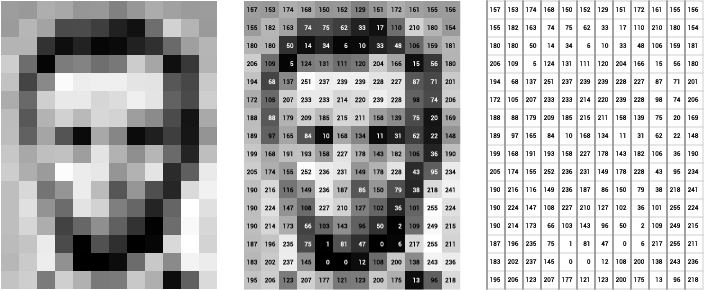
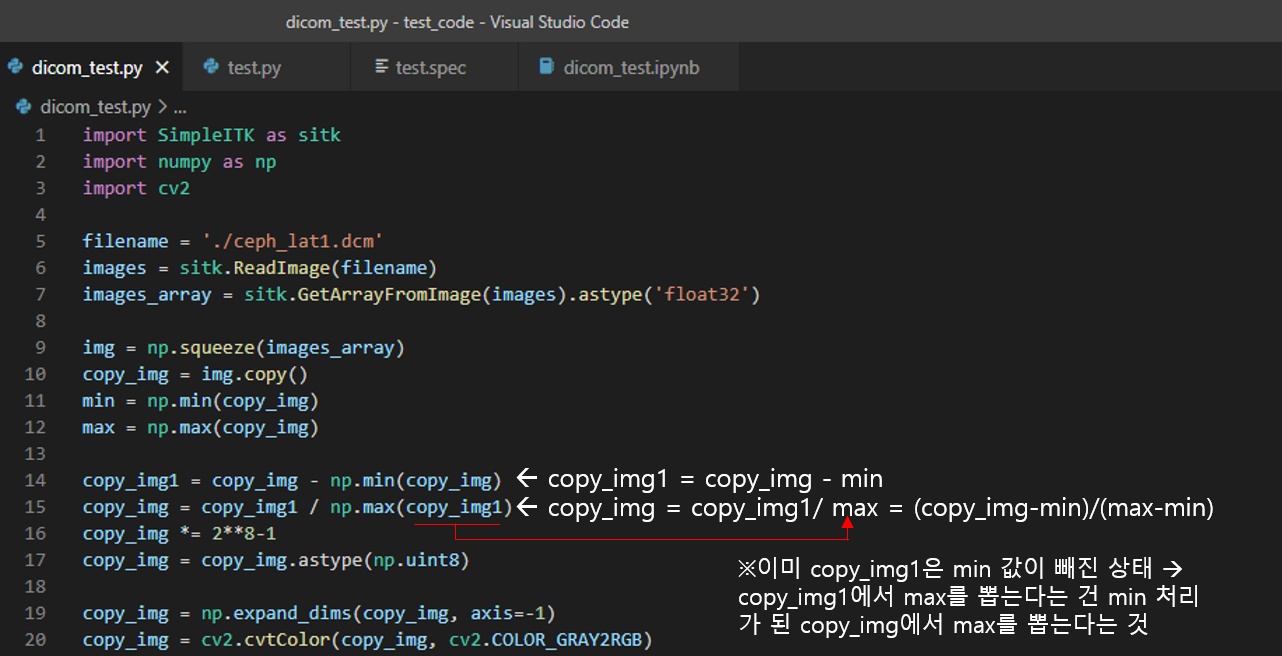
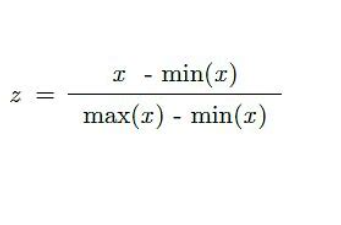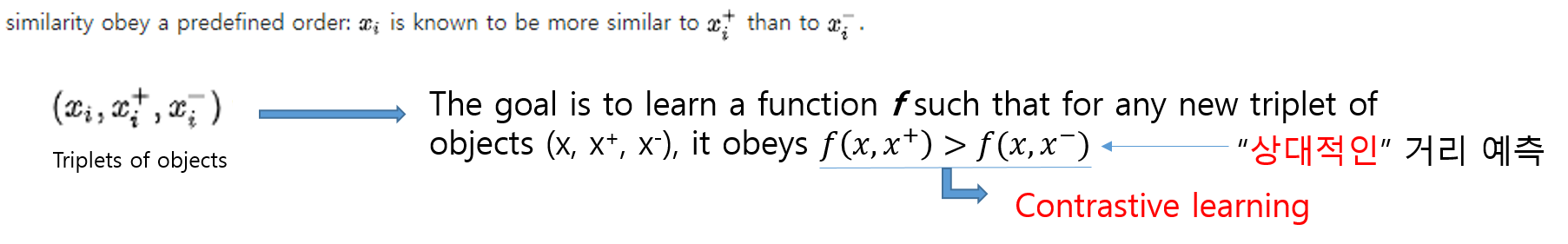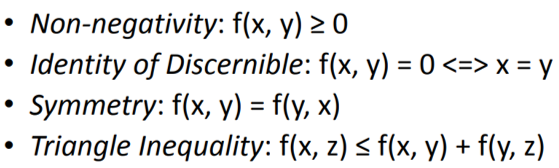하지만, dicom 파일을 구성하고 있는 pixel은 0~255의 범위만 갖고 있는 것이 아니라, "-x ~ +x" 와 같이 범위가 마이너스부터 시작 되는 경우도 있고, bit depth가 12bit, 16bit로 구성되어 있는 것도 많습니다.
예를 들어, CT에는 hounsfield unit (HU)이라는 것이 있습니다. X-ray 또는 CT 촬영 원리는사람에게 방사선을 쏴서 방사능 투과율에 따라 detector 부분이 다르게 보이는 것입니다.
결국 투과율에 따라 detector에 입력되는 값들이 다를 텐데, hounsfield라는 사람은 HU라는 단위를 통해 물체를 구분했습니다. HU 단위는 물을 기준으로 하고 뼈는 400~1000 HU 사이의 값을 갖고, 공기는 -1000의 값을 갖는다고 정의했습니다. 값이 작을 수록 검은색을 띄며, 값이 클 수록 흰색을 띕니다 (gray scale과 비슷하죠)
"A contrast is a great difference between two or more things which is clear when you compare them."
그렇다면, contrastive learning이라는 것은 대상들의 차이를 좀 더 명확하게 보여줄 수 있도록 학습 한다는 뜻이 되겠죠?
'대상들의 차이'라는 말에서 중점적으로 봐야 할 것은 '차이'라는 용어입니다. 보통 어떤 '기준'으로 인해 '차이'가 발생합니다.
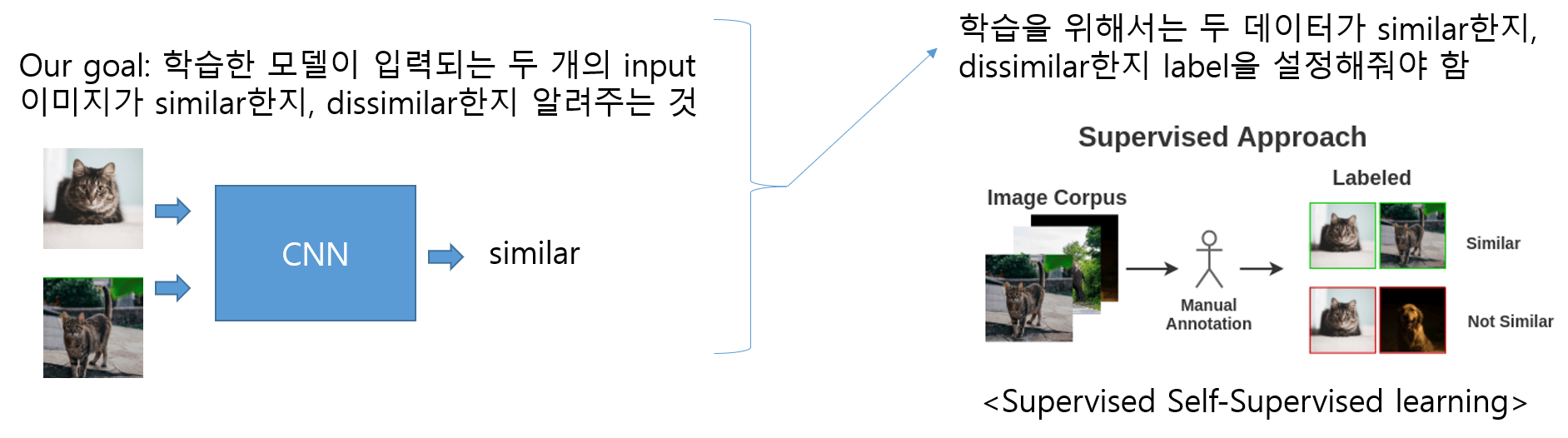
예를 들어, 어떤 이미지들이 서로 유사하다고 판단하게 하기 위해서는 어떤 기준들이 적용되어야 할까요? 즉, 어떤 '기준'을 적용하면 이미지들이 비슷한지, 비슷하지 않은지에 대한 '차이'를 만들어 낼 수 있을까요?
고양이라는 이미지가 있다고 가정해보겠습니다. 고양이 이미지에 augmentation을 주게 되도 그 이미지는 고양이 일 것입니다. 즉, 원본 고양이 이미지와 augmentation이 적용된 고양이 이미지는 서로 유사(=positive pair)하다고 할 수 있죠.
누군가(제3자)가 augmented image에 굳이 'similar'라고 labeling 해줄 필요 없이 input data 자기 자신(self)에 의해 파생된 라벨링(supervised ← ex: augmented image) 데이터로 학습(learning)하기 때문에 self-supervlsed learning이라고 할 수 있습니다.
"하지만 'similar' 정의는 어떤 기준을 삼느냐에 따라 굉장히 달라 질 수 있습니다."
물론, similar를 찾는 방법도 굉장히 다양하겠죠. 지금부터 이에 대해서 천천히 알아보도록 하겠습니다.
1. Similarity learning
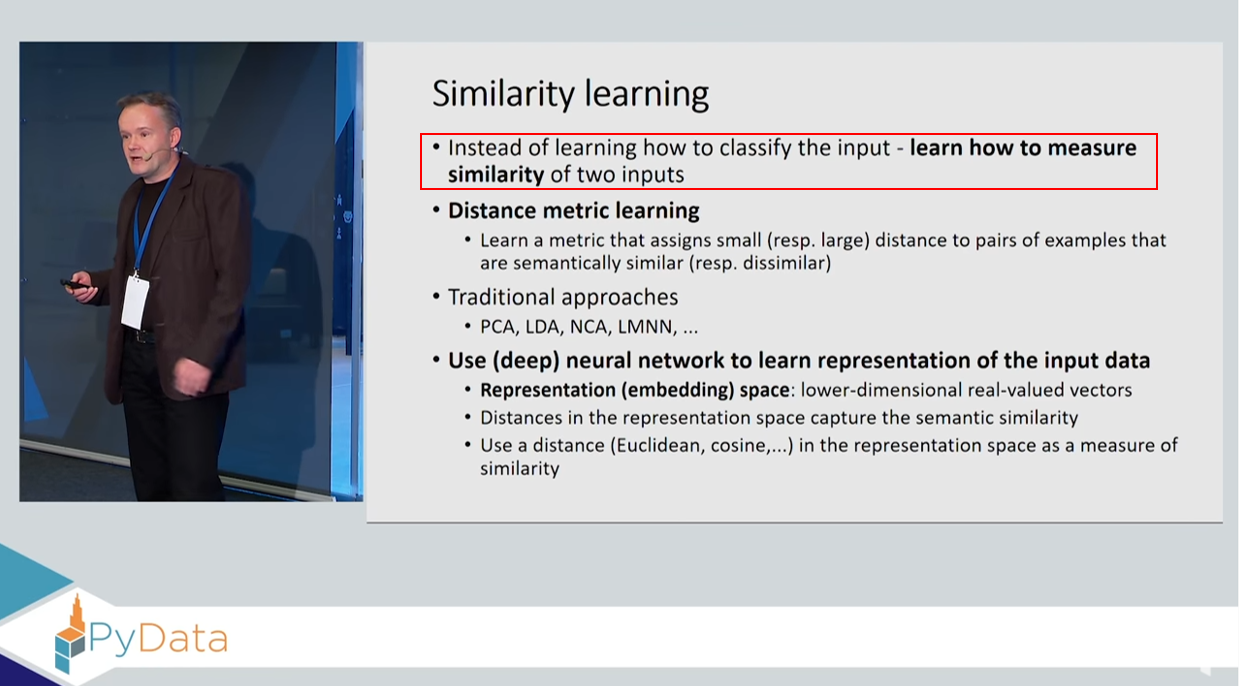
앞서 언급한 내용 중에 가장 핵심적이고 자주 등장하는 용어가 'similar'입니다. 그렇다면, contrastive learning과 similarity learning은 어떤 관계가 있을까요? 먼저, similarity learning의 정의부터 살펴보겠습니다.
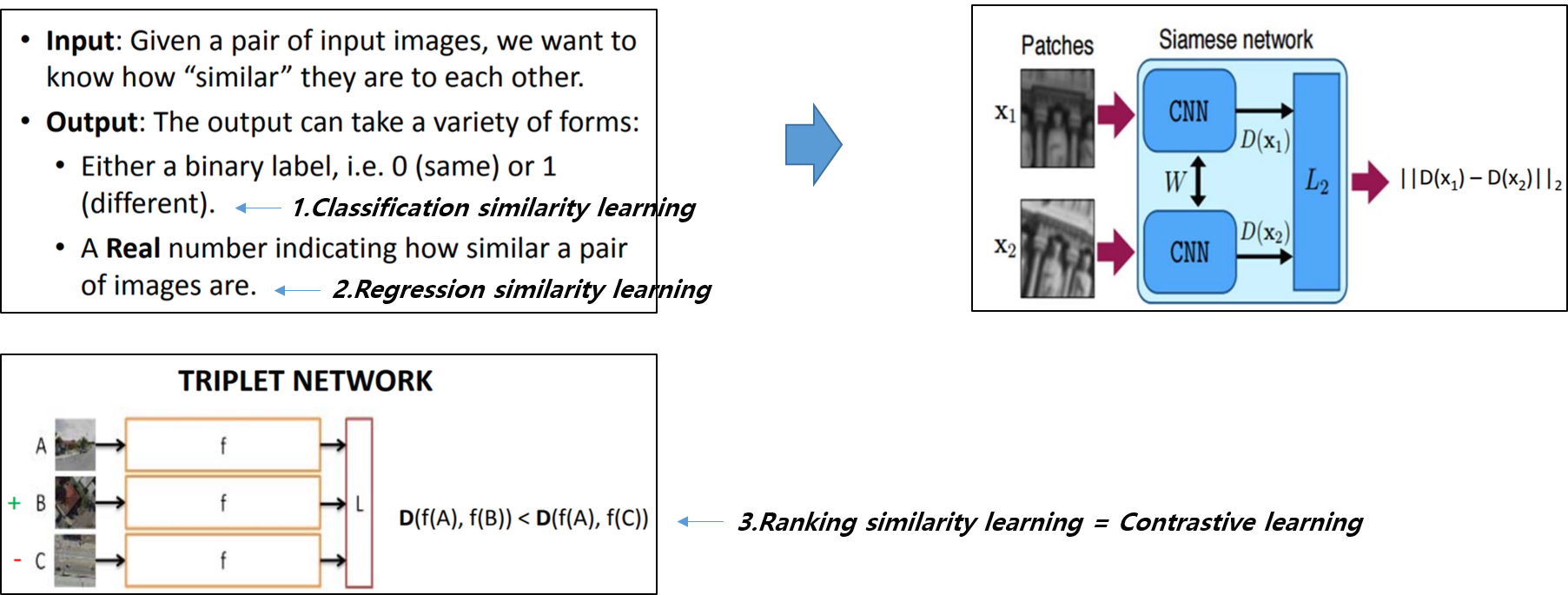
"Similaritylearning is closely related to regression and classification, but the goal is to learn a similarity function that measureshow similar or related two objects are."
결국, contrastive learning과 similarity learning 모두 다 어떤 객체들에 대한 유사도와 관련이 있다는걸 알 수 있습니다.
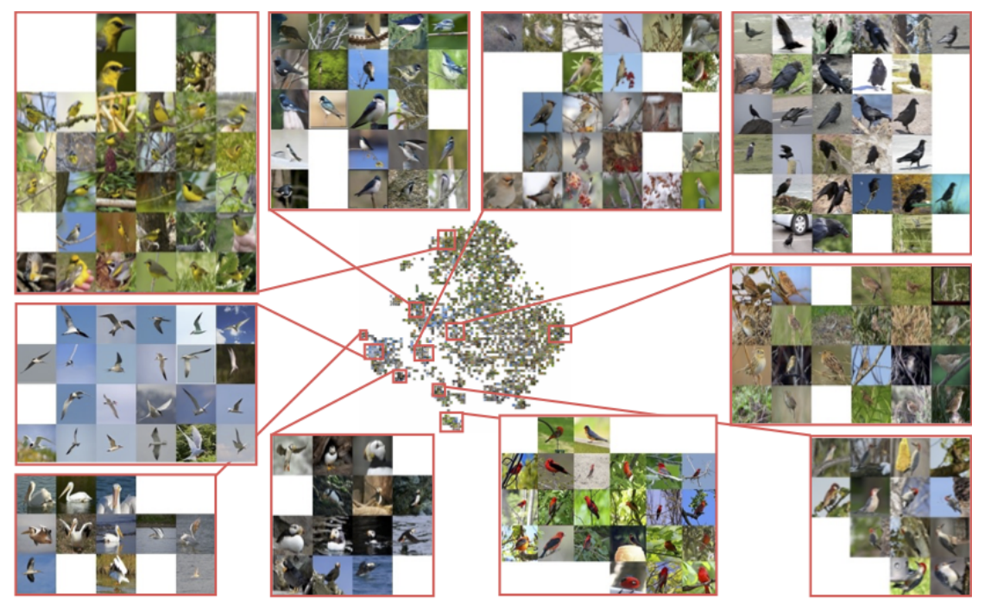
<이미지 출처 논문: Deep Metric Learning via Lifted Structured Feature Embedding>
"Similarity learning is closely related to distance metric learning."
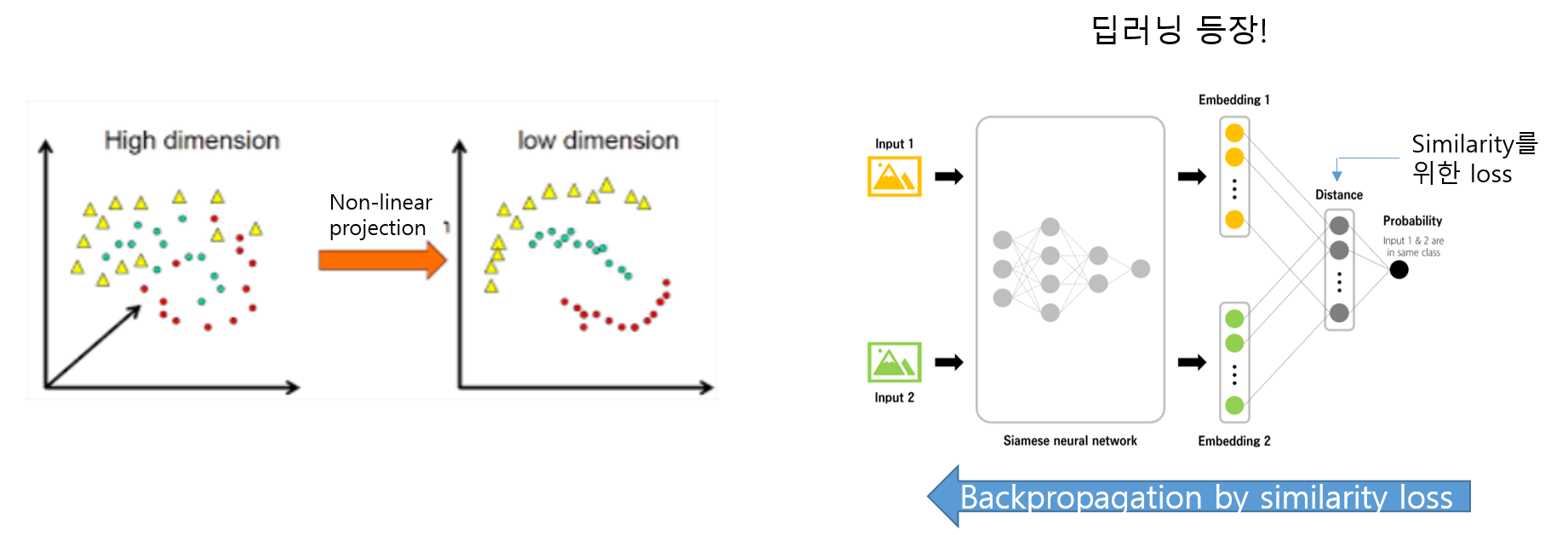
데이터들끼리 유사도가 높다는 것을 거리(distance)의 관점에서 해석해볼 수 도 있습니다. 예를 들어, 유사한 데이터 끼리는 거리가 가깝다는 식으로 해석해 볼 수 있는 것이죠. 그래서, similarity learning, contrastive learning을 배우다 보면 distance metric learning이라는 용어가 자주 등장합니다.
2. (Distance) Metric learning
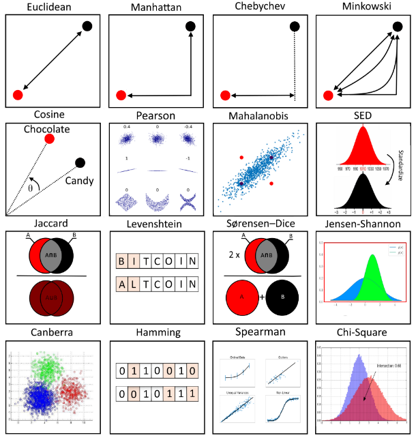
유사도를 판단하는데 있어서는 굉장히 다양한 기준이 적용될 수 있습니다. 유사도를 판단하는 한 가지 방법은 거리의 관점에서 해석하는 것입니다.
보통 거리라는 개념을 단순히 점과 점 사이의 최단 거리로만 이해하는 경우가 있지만, 거리를 측정하는 방식에는 다양한 방법이 존재 합니다. 즉, "거리"라는 개념을 어떻게 해석하느냐가 굉장히 중요한 문제라고 볼 수 있습니다.
결국, 두 객체간의 거리를 측정할 수 있는 방법이 다양하기 때문에 두 객체간의 유사도를 적용할 수 있는 기준이 다양하다고 할 수 있습니다.
"Similarity learning is closely related to distance metric learning. Metric learning is the task of learning a distance function over objects."
위의 정의에 따라 metric learning은 객체간의 거리를 학습하는 방법들에 대해 연구하는 분야라고 할 수 있습니다.
그렇다면, metric이라는 개념부터 정의해볼까요?
"A Metric is a function that quantifies a “distance” between every pair of elements in a set, thus inducing a measure of similarity."
객체(데이터)들 간의 거리(or 유사도)를 수량화 하는 방법은 여러가지가 있습니다. (결국, 우리가 배우는 contrastive learning 기법에서도 아래와 같은 metric들 중에 어느 것을 사용하느냐에 따라 다양한 연구가 진행 될 수 있겠죠.)
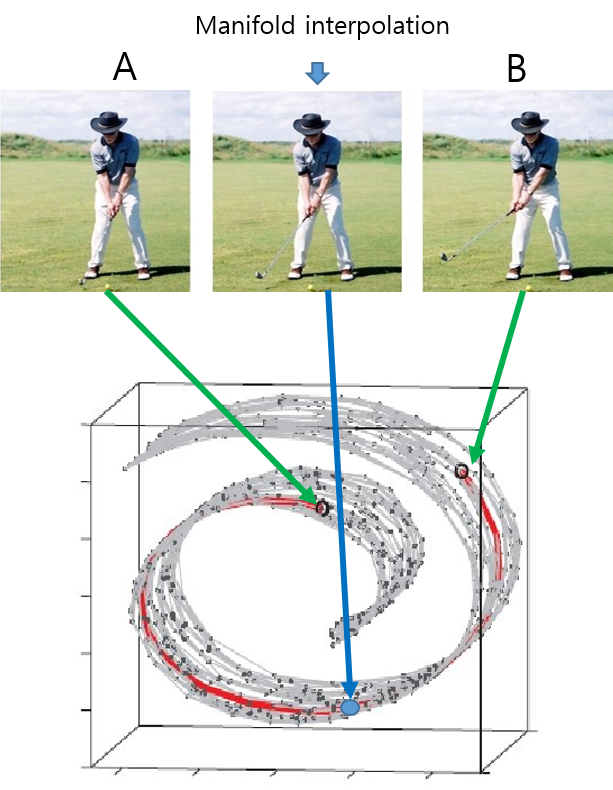
결국, 특정 metric(ex: Euclidean distance)을 기준으로 한 유사도를 찾기 위해 deep learning model의 parameter들이 학습된다면, 이는 해당 meteric을 찾기 위한 manifold를 찾는 과정이라고 볼 수 있고, 이 과정 자체가 "estimated from the data"를 의미하기 때문에, learned metrics라고 볼 수 있는 것입니다.
먼저, 유사한 이미지를 한 쌍으로 한 positive pair 끼리는 Euclidian Loss가 최소화가 되도록 학습 시키면, deep neural network는 고차원 원본 데이터 positive pair끼리 거리가 가깝도록 low dimension으로 dimension reduction(or embedding) 할 것입니다. 즉, positive pair끼리는 Euclidian loss가 최소화 되게 parameter들이 학습된 것인데, 이것을 원본 데이터로 부터 추정(estimation)되었다고 볼 수 있기 때문에 learned metric이라고 한 것이죠.
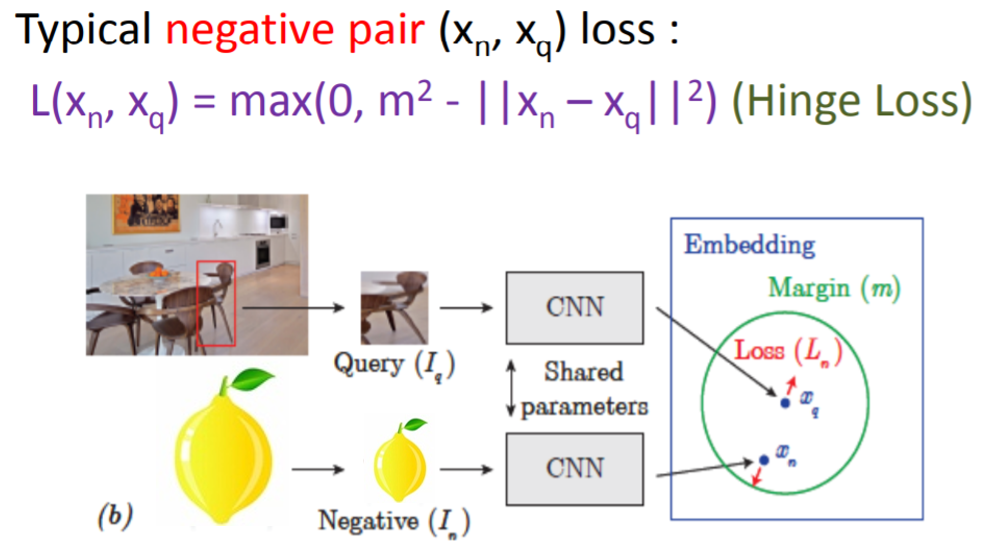
또한, negative pair 끼리는 Euclidan distance 값이 커지도록 설정해줄 수 있습니다. 아래 수식을 보면, margin (m) 이라는 개념이 도입되는데, margin은 negative pair간의 최소한의 거리를 의미합니다. 예를 들어, 우리는 loss 값이 최소가 되기를 바라는데, negative pair (xn, xq) 의 거리가 m 보다 작다면 계속해서 loss 값을 생성해낼 것 입니다. 그런데, 만약 학습을 통해 negative pair 간의 거리가 m 보다 크게 되면 loss 값을 0으로 수렴시킬 수 있게되죠.
위에서 언급한 두 수식을 결합한 loss를 contrastive loss라고 합니다.
쉽게, contrastive loss를 통해 학습을 한다는 것은 두 데이터가 negative pair일 때, margin 이상의 거리를 갖게 하도록 학습하는 것과 동일하다고 할 수 있습니다.
사실, contrastive loss라는 용어와 개념은 "Dimensionality Reduction by Learning an Invariant Mapping"이라는 논문에서 기원했습니다. 아래 논문의 저자로 우리가 익히 알고 있는 'Yann LeCun' 교수님도 있으시네요.
“Contrastive loss (Chopra et al. 2005) is one of the earliest training objectives used for deep metric learning in a contrastive fashion.”
앞서, 소개한 contrastive loss는 contrastive learning의 한 종류입니다.
즉, contrastive learning 이라는 것은 데이터들 간의 특정한 기준에 의해 유사도를 측정하는 방식인데, contrastive loss는 positive pair와 negative pair 간의 유사도를 Euclidean distance 또는 cosine similairty를 이용해 측정하여, positive pair 끼리는 가깝게, negative pair 끼리는 멀게 하도록 하는 deep metric learning (or learned metric) 이라고 정리할 수 있습니다.
(참고로, contrastive learning을 굳이 deep neural network로 하지 않아도 되지만, deep neural network의 강력한 효용성 때문에 deep neural network를 기반으로한 deep metric learning 방식인 contrastive learning을 하려고 하는 것이 죠.)
Positive pair 끼리는 가깝게,negative pair 끼리는 멀게 하도록 하는 deep metric learning (or learned metric) 기반의contrastive learning종류는 굉장히 다양합니다.즉, 유사도를 측정하는 방식이 다양하죠. 예를 들어, infoNCE는 mutual information이라는 개념을 기반으로 유사도를 측정합니다. (Triplet loss는 이미 similarity learning에서 간단히 설명한 바 있습니다). (Mutual information 관련 설명은 다음 글에서 하도록 하겠습니다).
지금까지의 설명을 기반으로 봤을 때 deep metric learning 기반의 contrastive learning이라는 분야를 다룰 때 중요하게 다루어야 하는 개념이 두 가지가 있습니다.
Similarity Measure (Metric)
Contrastive learning은 positive pair 끼리는 가깝게, negative pair 끼리는 멀게 하도록 해주는 것이 목적입니다.
이 때, positive pair라는 것을 상징하는 유사도 값의 종류는 굉장히 다양합니다.