안녕하세요.
이번 글에서는 YOLO V3 object detection "TECH REPORT"를 설명하려고 합니다.
지금까지 리뷰한 object detection 모델은 어떤 학회나 저널에 제출된 논문들이었습니다.
하지만, YOLO V3 저자는 YOLO V3가 YOLO V2를 약간 업데이트한 버전이라서 논문이 아닌 TECH REPORT 개념으로 작성한다고 언급했습니다.그래서, 현재 어떤 학회에 제출되지 않고 arXiv에만 올라와 있는 상태 입니다.
그렇게 때문에 YOLO V2를 잘 이해하고 있으시다면 어렵지 않게 이해하실 것으로 판단됩니다.
그럼, 지금부터 YOLO V3 TECH REPORT를 리뷰해보도록 하겠습니다.
Paper: YOLOv3: An incremental Improvement
2018. 04. 08 arXiv

[영어단어 및 표현 정리]
- Incremental: Incremental is used to describe something that increases in value or worth, often by a regular amount.
0. Abstract

YOLO V3는 YOLO(V2)의 디자인을 약간씩 변경했다고 언급하고 있습니다. 대표적으로 변경한 부분은 새로운 네트워크 부분인데, 뒤에서 자세히 언급하겠지만 YOLO V2에서 사용했던 darknet19을 darknet53으로 발전시켜 YOLO V3의 backbone 네트워크로 사용했습니다.
이러한 변경들로 인해 YOLO V2에 비해 모델이 약간 커지긴 했지만 정확성이 높아졌다고 합니다.
- 320×320 (input resolution) YOLO V3 performance
- Speed1 (mAP 기준): 22ms ← three times faster than SSD
- Accuracy1 (mAP 기준): 28.2 mAP ← same as SSD
- Speed2 (\(AP_{50}\) 기준):: 51ms (on Titan X) ← about four times faster than RetinaNet
- Accuracy 2 (\(AP_{50}\) 기준):: 57.9 \(AP_{50}\) ← same as RetinaNet
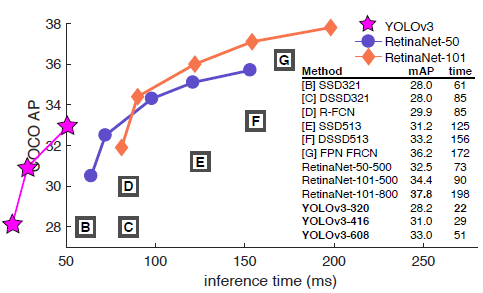
이 논문에서는 YOLO V3를 mAP가 아닌 \(AP_{50}\)를 강조하고 있는데요. 이 이유에 대해서는 뒤에서 자세히 설명하도록 하겠습니다.
[영어단어 및 표현 정리]
- swell: an old word that basically means fantastic, generally used by old people or hipsters to try to sound hip.
- YOLO V3 글 자체가 TECH REPORT다 보니까 슬랭(slang)어를 자주 사용하는 경우가 있습니다. 그래서, 공식사전같은 곳에서 swell의 뜻을 대입해 해석하면 이상해지는 경우가 많죠. 보통 영어 슬랭어는 Urban dictionary 라는 사전을 이용하면 잘 찾을 수 있습니다.
https://www.urbandictionary.com/
Urban Dictionary, August 25: milves
plural of milf.
www.urbandictionary.com
1. Introduction
[첫 번째 문단]

역시 official paper가 아니기 때문에 처음에 친숙한 어투로 글 전개를 시작 하는것 같습니다.
"가끔 그냥 너도 1년 동안 다른 짓만 할때도 있잖아? 나도 올해에는 research 많이 안하고 트위터만 한 듯... 뭐 물론 GAN 같은 것도 조금 해보긴 했지만...."
"그래도 여력이 조금 남아있어서 YOLO (V2) 성능을 조금 개선시키긴 했어~"
"근데 뭐 막 엄청 interesting한 기법을 쓴건 아니고, 조금씩 변화만 줘서 실험했어~"
[영어단어 및 표현 정리]
- kinda: (구어) kind of ((발음대로 철자한 것))
- momentum: If a process or movement gains momentum, it keeps developing or happening more quickly and keeps becoming less likely to stop. (=impetus)
[두 번째 문단]

대부분 학회에서는 "Camera ready due"가 있습니다.
학회같은 곳에서 다루는 paper 종류는 두 가지 입니다.
- Accepted paper
- Camera-ready paper
아래 그림1을 보면 "Paper Submission Deadline"이라고 나와있을 겁니다. 일반적으로 학회에 제출하여 논문에 accept되면 이를 "Accepted paper"라고 합니다.
그런데, "accepted paper"를 최종 인쇄하기 위해서는 "폰트 종류, 크기", "대소문자" 등의 양식을 다시 통일시켜주어야 합니다. 이때 최종 인쇄를 위해 통일된 양식으로 바꾼 paper를 "Camera-ready paper"라고 보시면 됩니다.

YOLO V3 저자가 Camera-ready를 하긴했지만, "a source"가 없어서 TECH REPORT로 내기로 했다고 한 것 같네요. (정확히 "a source"가 무엇을 의미하는지는 모르겠습니다....)
[세 번째 문단]
이 tech report는 크게 세 가지 section으로 구성되어 있습니다.

- Deal: Method (YOLO V3에 대한 전반적인 architecture를 설명)
- How we do: Experiment (YOLO V3 결과 해석)
- Things we tried that didn't work: Ablation Study 개념
- What this all means: Conclusion + 기존 evaluation 방식 불만 제기
[영어단어 및 표현 정리]
- intros: an introduction의 복수형
- y'all: you-all의 축약형
- contemplate: 생각하다
2. Deal

Section2("2. The Deal) 에서는 YOLOv3의 아키텍처에 대해 설명합니다. Secion2 구성을 미리 설명하면 다음과 같습니다.
- 2.1. Bounding Box Prediction: 제목 그대로 bbox prediction 할 때 사용되는 수식들을 설명합니다 (미리 말씀드리면, 이 부분은 YOLOv2와 동일합니다.
- 2.2. Class Prediction
- 2.3. Predicitons Across Scales: darknet-53으로 feature extraction 한 후, bounding box를 찾을 때 다양한 resolution에서 boundinb box를 찾는 방식을 설명합니다. 이 부분이 YOLOv2와 다른 첫 번째 특징입니다.
- 2.4. Feature Extractor: YOLOv2에서 feature extractor로 사용한 darknet-19를 업그레이드 한, new classifier인 darknet-53을 소개 합니다. 이 부분이 YOLOv2와 다른 두 번재 특징입니다.
- 2.5. Training: YOLOv3를 어떻게 학습시켰는지 설명합니다.
제가 글을 읽어보면서 순서를 조금 변경시키면 좋겠다고 판단하여, 이 블로그에서는 순서를 아래와 같이 변경하여 설명하려고 합니다.
- 2.4. Feature Extractor
- 2.3. Predictions Across Scales
- 2.2. Class Prediction
- 2.1. Bounding Box Prediction
- 2.5. Training
2-4. Feature Extractor

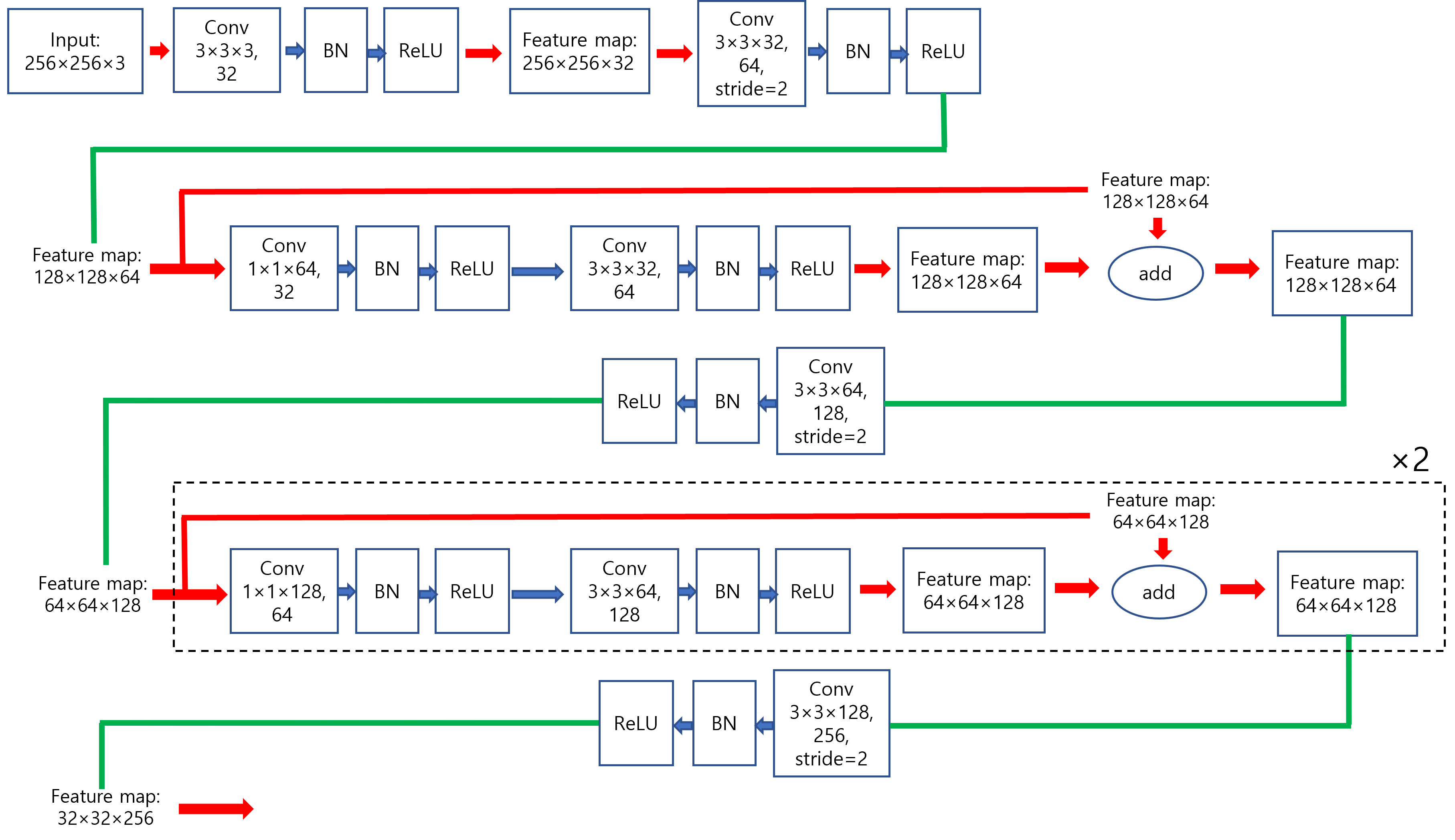
YOLO V2에서는 feature extractor로써 darknet-19를 사용했었습니다. 아래 그림(테이블)에서 darknet-19를 보면 convolutional layer가 19개인 것을 확인할 수 있습니다. YOLO V3에서는 residual connection을 이용하여 layer를 더 deep하게 쌓게 되었고, 그 결과 darknet-53을 만들 수 있게 되었습니다. 아래 그림에서 darknet-53은 convolutional layer가 총 52개인데, 아마 Avgpool(=average pooling layer) 직전에 1×1×1000 convolutional layer가 생략된 듯 합니다. 이렇게 추측한 이유는 다음과 같습니다.
- Connected가 softmax 직전에 위치한 것을 보면 logit인 것을 알 수 있습니다.
- Connected는 average pooling 결과라고 볼 수 있는데, 아래 그림상으로는 average pooling에 들어가기 직전의 convolutional channel 수 는 1024개 입니다.
- Average pooling 연산 후 1000개의 neuron을 출력하기 위해서는 입력 직전의 convolutional channel 수가 1000개여야 하기 때문에, 1000개의 채널을 갖는 1×1 convolutional layer가 생략되었다는걸 추측 할 수 있습니다.
- 즉, 아래 그림의 convolutional layer 총 개수와 Avgpool 직전에 생략된 하나의 1×1 convolutional layer를 더하면 총 convolutional layer 개수가 53개인 것을 확인할 수 있습니다.
- (참고로, Size 부분에 "/2"라고 되어 있는 부분은 convolution filter의 stride=2라는 뜻입니다. Pooling이 아닌 conv filter의 stride를 통해 downsampling을 진행했네요)
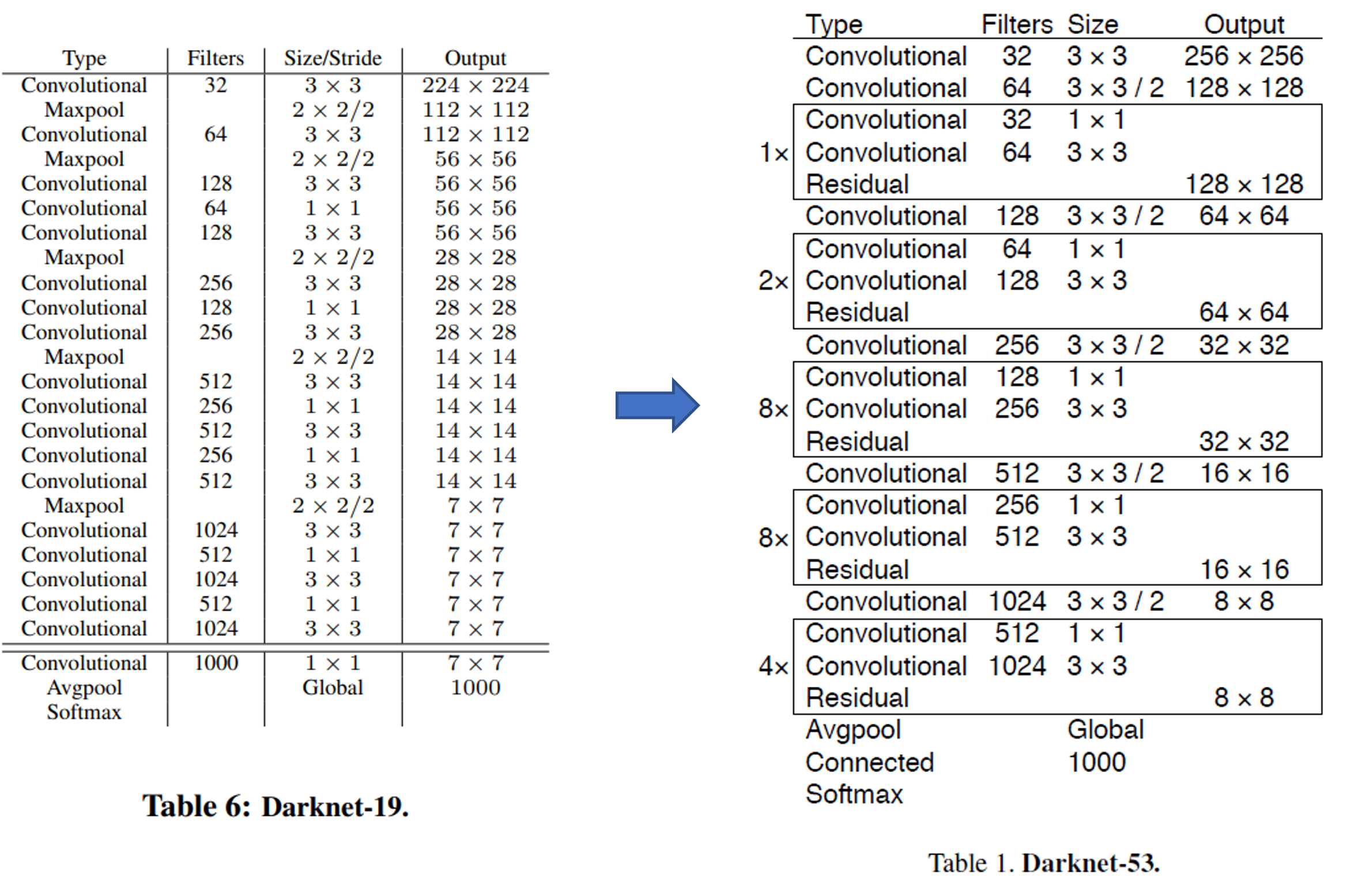
Darknet-53을 자세히 도식화하면 다음과 아래 그림과 같이 표현할 수 있습니다. (제가 임의대로 그린거라 틀린부분이 있으면 말씀해주세요!)
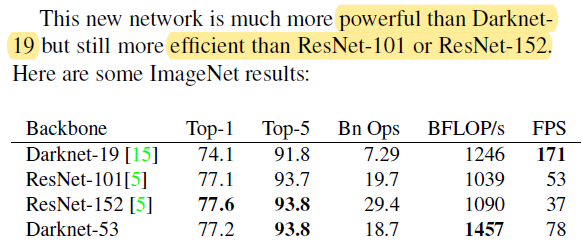
위의 결과표를 보면 darknet-53이 darknet-19보다 좋은 accurcay를 기록하고 있다는걸 알 수 있습니다. ResNet-152보다는 accuracy가 조금 떨어지기는 하지만 더 효율적이라고 하는데, 이 부분은 바로 다음 문단에서 설명하도록 하겠습니다.

Darknet-53이 ResNet 모델들 보다 efficient하다고 하는 이유는 FPS, BFLOP/s 에 있습니다 (BFLOP의 B는 Billion의 약자입니다. FLOPS에 대한 설명은 아래 글을 참고해주세요!)
https://89douner.tistory.com/159
4.NVIDIA GPU 아키텍처(feat.FLOPS)
안녕하세요~ 이번글에서는 NVIDIA에서 출시했던 GPU 아키텍처들에 대해 알아볼거에요. 가장 먼저 출시됐던 Tesla 아키텍처를 살펴보면서 기본적인 NVIDIA GPU 구조에 대해서 알아보고, 해당 GPU의 스펙
89douner.tistory.com
컴퓨터가 초당 연산할 수 있는 능력을 "BFLOP/s"로 나타내는데, "BFLOP/s"가 높을 수록 GPU가 1초에 더 많은 연산을 실행해준다는 것과 같으니 GPU utilization을 잘 활용한다는 것을 뜻하기도 합니다. 결국, darknet-53이 ResNet-152보다 성능이 약간 떨어지긴 해도 (개인적으로는 0.4%의 오차는 편차에 따라서 큰 의미가 없을 수 있다고 생각하긴 합니다만...), FPS (or GPU utilization)이 월등이 높기 때문에 더 "efficient"하다고 주장하는 것이지요.
[영어단어 및 표현 정리]
- newfangle
- 형용사로 쓰이는 경우: Eager for novelties; desirous of changing
- 동사로 쓰이는 경우: To change by introducing novelties
2-3. Predictions Across Scales


위의 두 문단을 정리한 그림을 도식화해서 보여드리겠습니다. (아래 그림에서 "conv[3,3,32,64]/2"라고 되어 있는 부분에서 "/2"가 의미하는 바는 conv filter의 stride가 2라는 뜻힙니다 (즉, conv filter의 stride를 크게 설정함으로써 downsampling을 해주겠다는 뜻이죠))

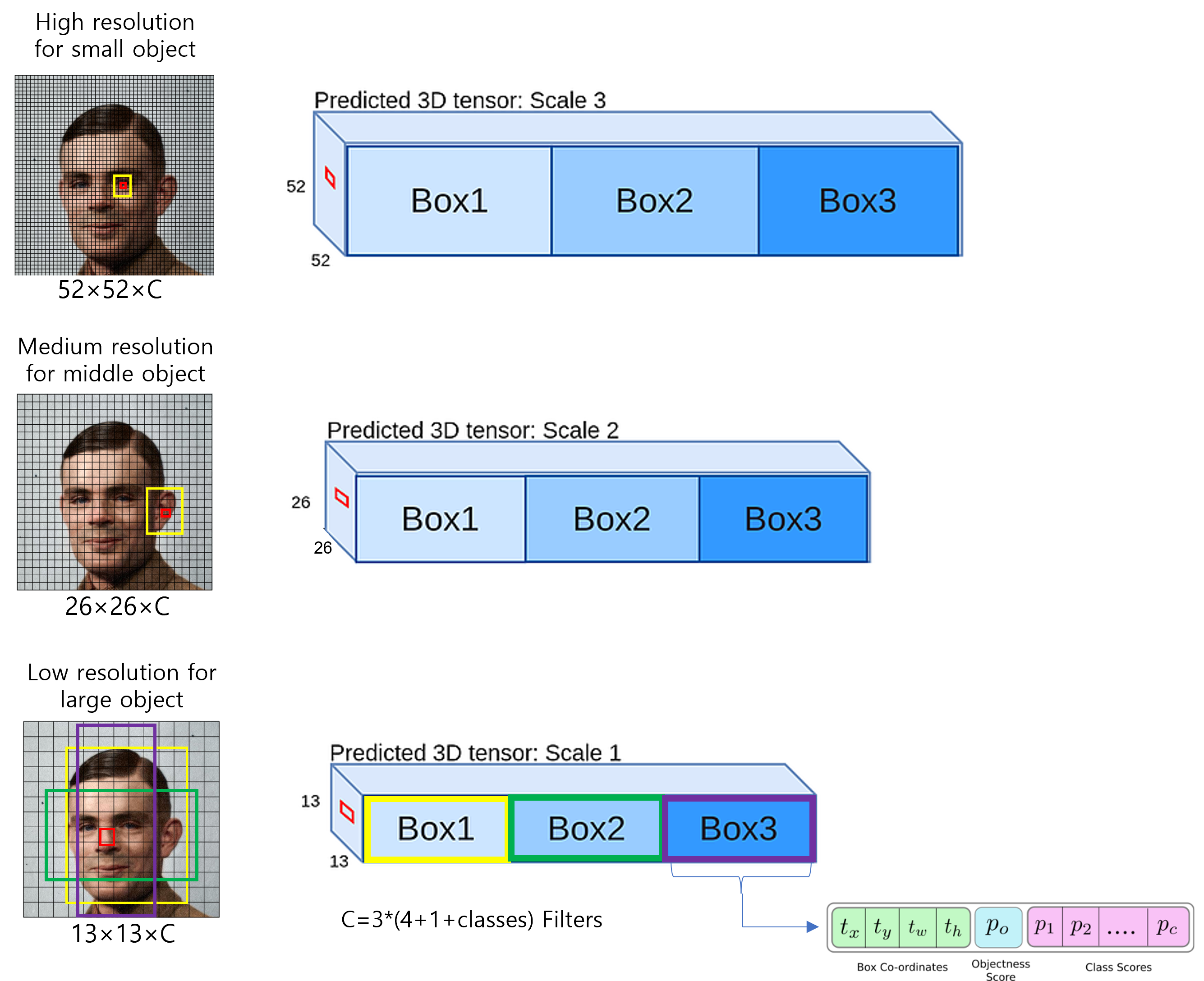

우선 저 "We perform the same design~ " 문단은 정확히 무엇을 의미하는 내용들인지 모르겠네요.
"We still use k-means ~" 문단은 YOLOv3가 학습 전에 bounding box의 aspect ratio를 각 scale마다 어떻게 설정해 줄 지 사전정의한 hyper-parameter 입니다. (제 생각으로는, (10×13), (16×30), (33×23) 이렇게 3개는 small object (52×52 feature map과 관련된 bounding box 정보인듯 합니다. 아니라면 답변주세요!)
2-2. Class Prediction

우선 위의 문장에서 의미하는 바들을 이해하기 쉽게 풀어서 설명해보도록 하겠습니다.
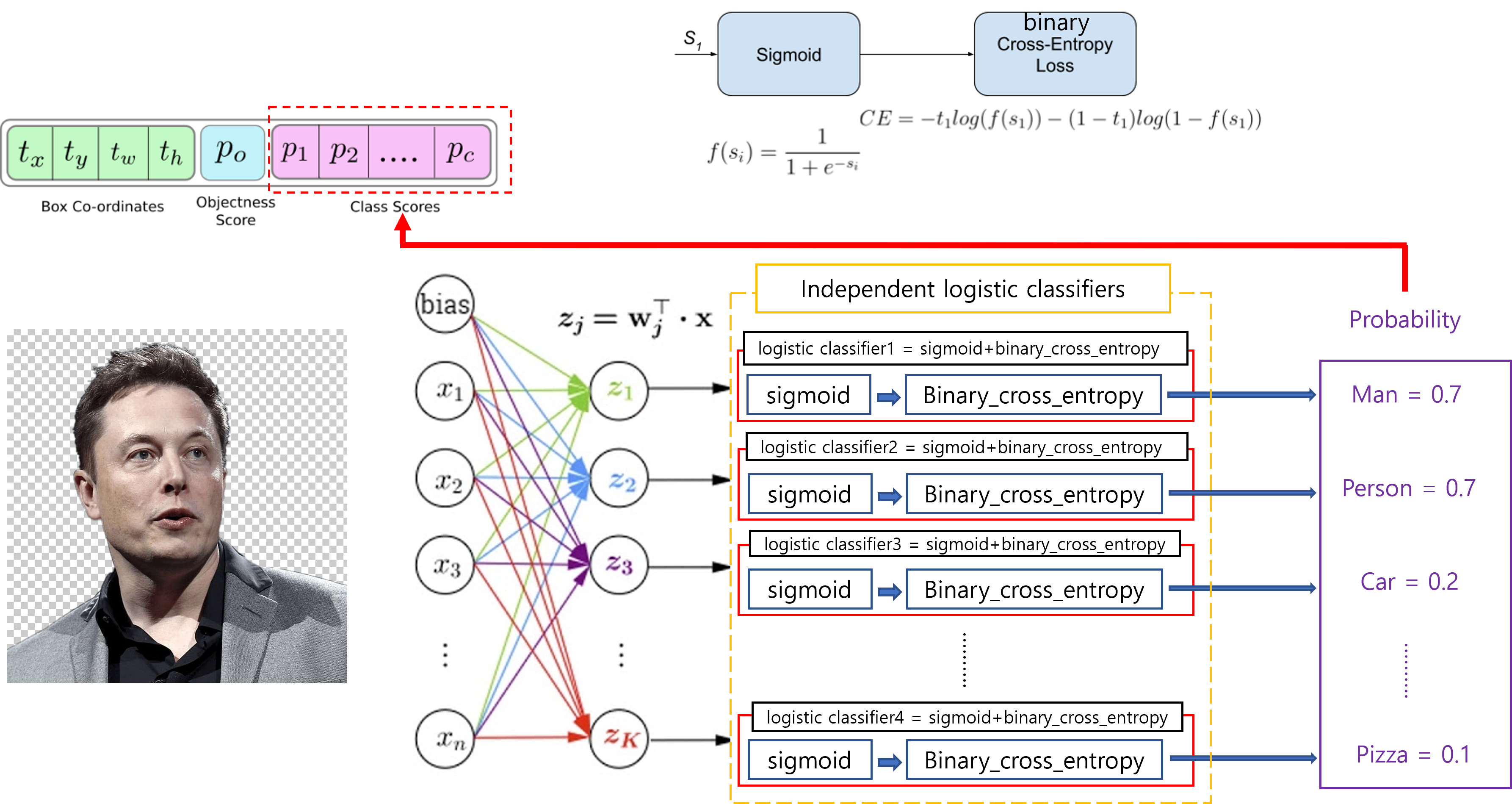
COCO dataset은 80개의 클래스를 갖고 있습니다. 즉, COCO dataset의 이미지들을 분류하겠다는 것은 80개의 class들을 분류하는 multi-classification task인 것이죠. 그런데, 80개의 클래스들이 모두 서로 전혀관계가 없는 것은 아닙니다. 예를 들어, 80개에 "Person", "Man"이라는 클래스가 포함될 수 도 있는데, 이 두 클래스는 서로 독립적인 클래스가 아니죠. 왜냐하면, "Man"은 "Person"의 부분집합 개념이기 때문입니다. 그래서, '앨론 머스크' 이미지를 classification하면 "Man"이 나올 수 도 있고, "Person"이 나올 수 도 있는 것이죠. (보통 이러한 관계를 지닌 클래스들은 서로 hierarchy한 구조를 갖고 있다고 합니다)
일반적으로 classification 방식은 softmax를 취해준 후, cross entropy를 계산하는 경우가 대부분입니다. 그런데, softmax를 취해주면 logit값(=softmax 입력 값: \(z_{i}\))이 제일 높은 하나의 클래스 확률 값만 지나치게 높게 설정해주는 경우가 있습니다. 이렇게 하나의 클래스 확률 값만 높여주는 이유는 입력 이미지에는 하나의 클래스만 있을 것이라는 가정을 하기 때문입니다.

그런데, 앞서 설명했듯이 위의 '앨론 머스크' 이미지는 두 가지 클래스(=레이블)를 갖고 있을 수 있다고 했습니다. 즉, muti-label 이미지인 것이죠. 그래서, 이 경우는 multi-label을 모두 정확하게 예측하기 위해서 independent logistic classifiers를 사용합니다.
2-1. Bounding Box Prediction
※"2-1.Bounding Box Prediction" 파트는 총 두 문단으로 구성되어 있는데, 여기에서는 문단 순서를 바꾸어 설명하도록 하겠습니다.

위의 문장을 요약하면 아래 그림으로 표현할 수 있습니다.
YOLOv3는 한 번 연산할 때, feature map의 한 cell당 총 3개의 box에 해당하는 3d-tensor들을 출력합니다. 이론적으로, 한 번 학습 시 생성되는 bounding box 개수는 (10647=52×52×3+26×26×3+13×13×3) 일겁니다. 여기서 IOU가 제일 높은 box의 3d-tensor만 loss function을 위해 사용하게 됩니다. 또한, IOU가 제일 높은 3d-tensor의 objectness score(=confidence score)를 1로 설정해줍니다. (이 과정을 굉장히 간단하게 설명했지만, 실제로 bounding box 후보군을 가려내는 작업은 훨씬 복잡합니다. 이 부분은 코드 구현 부에서 좀 더 자세히 다루도록 하겠습니다)

YOLOv3에서는 IOU의 threshold를 0.5로 설정하고 있습니다. 그렇기 때문에, 초기에는 10647개 box들의 IOU가 모두 0.5가 넘지 않을 수 도 있습니다. 이 경우에는 아래 YOLO loss에서 objectness loss 부분을 제외한 regression loss, classification loss를 발생시키지 않습니다. (아마, loss를 발생시키지 않는다는 것은 loss 값을 0으로 할당시켜준다는 뜻 같은데, 이 부분은 코드를 리뷰하면서 더 자세히 살펴보도록 하겠습니다. (사실 엄밀히 말하면 아래 수식은 YOLOv1의 loss function입니다. 실제로는 시그마 부분이 좀 변경되어야 할 것 같네요.)


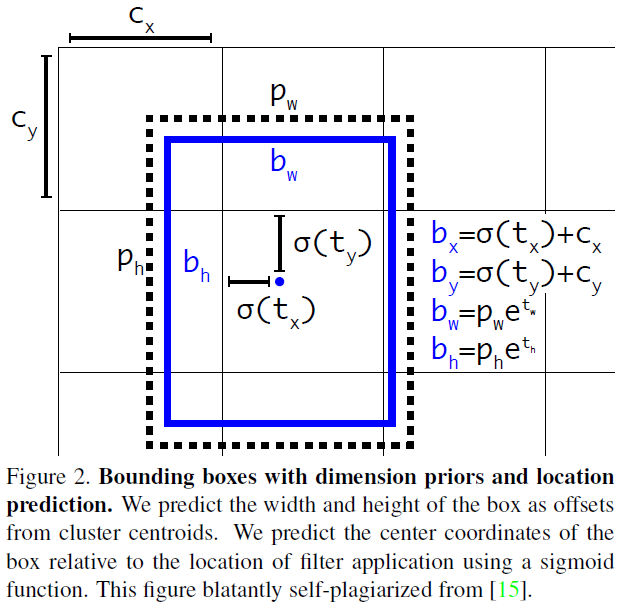
이 부분은 YOLOv2와 똑같기 때문에 설명을 더 하지는 않겠습니다.
(↓↓↓아래 글에서 "3-3) Direct location prediction" 부분을 참고해주세요!↓↓↓)
https://89douner.tistory.com/93
10. YOLO V2
안녕하세요~ 이번글에서는 YOLO V1을 업그레이드한 버전인 YOLO V2에 대해서 알아보도록 할거에요. YOLO V2 논문에서는 YOLO V1을 3가지 측면에서 업그레이드 시켜서 논문 제목을 Better, Faster, Stronger이라
89douner.tistory.com
3. How We Do
[첫 번째 문단]

COCO dataset의 mAP 성능을 살펴보니 SSD variants (SSD513, DSSD513)와 동일한 반면 속도는 3배더 빨랐다고 합니다. 하지만, 여전히 RetinaNet의 mAP 성능을 뛰어넘진 못했네요. (YOLO v3 저자는 mAP 방식의 evaluation 방식이 "weird"하다고 표현했는데, 그 이유는 "5.What This All Means"에서 설명드리도록 하겠습니다)
[영어단어 및 표현 정리]
- on par with: ~와 동등(대등)한
(※아래 "stealing all these tables from [9]" 표현은 RetinaNet 모델 결과는 RetinaNet 논문 [9]에서 그냥 가져온거라고 합니다. RetinaNet을 Scratch로 구현하려면 너무 오래 걸린기 때문에 이렇게 했다고 하네요)
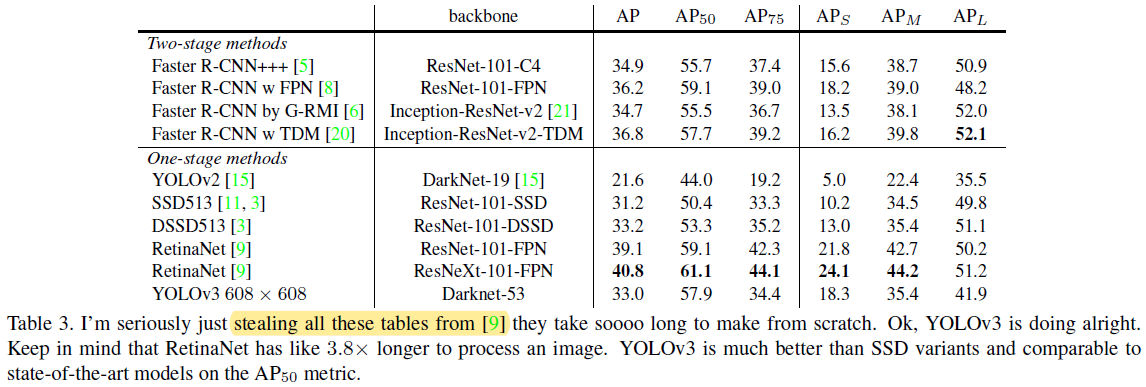
[두 번째 문단]

하지만, \(AP_{50}\)을 기준으로하면 YOLOv3의 성능은 RetinaNet과 동등해집니다. 하지만, IOU의 threshold를 올리면 AP 성능이 급격히 떨어지는데, 이러한 것으로 보아 YOLOv3 모델이 어떤 객체를 완전히 "fit"(정확)하게 detect하지 못하는걸 알 수 있습니다.
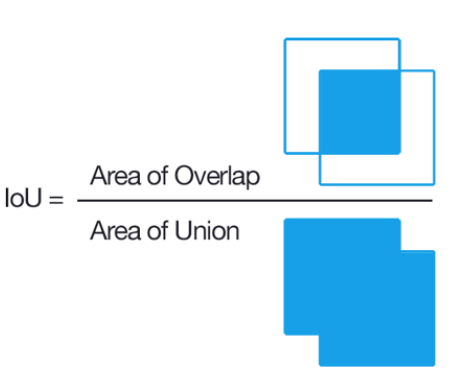

[영어단어 및 표현 정리]
- on par with: ~와 동등(대등)한
- excel at ~ing: ~하는 것이 뛰어나다
[세 번째 문단]

위의 그림?(Table 3)을 보면 예전 YOLO(v2) 같은 경우에는 small object에 대한 성능이 매우 안좋았음을 알 수 있습니다. "2.3. Predictions Across Scales"에서 언급된 multi-scale predictions을 이용해 small object에 대한 AP (\(AP_{S})\)를 향상시킬 수 있었습니다.
하지만, medium, large size objects의 detection 성능 향상 정도가 small object 성능 향상 정도에 미치지 못했다고 합니다. (개인적으로는 뭐... 당연한거 같다는 생각이... YOLO V2에서 multi-scale을 쓰지 않았으면 small object를 아예 놓치는 경우가 있을 수 있을테니, 이런 경우에 mAP를 성능을 크게 깍아먹지 않았었을까라는 생각이 드네요.)
[영어단어 및 표현 정리]
- get to the bottom of it: 진상을 규명하다; 진짜 이유를 찾아내다.
- "get to the bottom of ~"의 본래 뜻은 ~의 바닥까지 본다입니다. 진상을 확인 하는 것도 보이지 않는 밑바닥까지 살펴보는 행위라고 볼 수 있기 때문에, 관용어구로 사용됩니다.
[세 번째 문단]

(논문에서 "see figure 5"라고 했는데, 제가 봤을 땐 오타 같습니다. "see figure 3"이 맞는듯 하네요.)
확실히 mAP보다 mAP-50 지표로 보면 YOLOv3의 성능이 굉장히 좋게 보입니다.


4. Things We Tried That Didn't Work
이 부분은 오히려 설명을 하는게 YOLOv3를 이해하는데 더 혼동시킬 수 도 있다고 생각하여 따로 글을 올리진 안았습니다. 아래 영상 "24:38~27:00"를 참고하시는게 더 좋을 듯 합니다.
5. What This All Means
[첫 번째 문단]

저자는 YOLOv3가 mAP와 \(AP_{50}\) 간의 성능차가 심하게 나는 것을 강조하고 있습니다.
[두 번째 문단]

mAP 성능이 안좋아서 그런지.... ,mAP를 evaluation 지표로 사용하는 것에 대한 불만을 제기하는데, 그 이유는 아래와 같습니다.
"사람도 50% IoU와 30% IoU를 잘 구분하지 못하는데, 즉 20% 차이나는 IOU gap도 구별을 못하는데, 50%, 55%, 60%, ..., 95%씩 나눠서 평가하고 mAP을 구하는게 무슨 의미가 있는거냐"
저자는 추가적인 (좀 더 근본적인) 이유도 이야기를 하는데, 그 내용은 뒤에 "6.Rebuttal"에서 설명하도록 하겠습니다.
[영어단어 및 표현 정리]
- cryptic: A cryptic remark or message contains a hidden meaning or is difficult to understand.
[세 번째, 네 번째, 다섯 번째 문단]

그리고, 자신이 개발 중인 기술에 대한 근원적인 질문을 합니다.
"우리가 object detection 기술을 가졌으니, 그걸로 뭘 할거냐?"
이 질문과 함께 자신이 개발한 기술이 privacy를 침해하는 데 사용될 수 있고, 사람을 죽이는 military 목적으로 사용될 수 있다는 것을 우려하고 있습니다. 해당 기술 (Object Detection)은 동물원의 얼룩말 수를 세는 것이나, 자신들의 애완동물을 잘 찾을 수 있는 용도로 사용되어야 한다고 강조합니다. 그리고, 이러한 방향으로 기술이 개발되도록 책임의식을 갖어야 한다고 주장하면서 글을 마무리합니다. (트위터도 끊을 거라고 하네요.. 근데, 2020년에 트위터 내용을 보니 못 끊은건지... 다시 가입한건지..)
6. Rebuttal
Reference 뒷 부분을 보면 "Rebuttal"이라는 section이 있습니다. 일반적으로 저자가 논문이나 자신의 article을 제출하면 reviewer들이 comment를 남깁니다. 그럼, 저자는 해당 comment에 대한 답변을 해야하는데 이러한 답변을 보통 "Rebuttal Letter"라고 부릅니다. 보통 답변을 할 때는 두 가지의 제스처를 취할 수 있습니다.
- 수락: reviewer들로부터 피드백 받은 comment들 기반으로 잘 내용들을 업데이트 하겠다.
- 반박: reviewer들이 comment한 것을 동의하기 어려운 경우도 있습니다. 이 때는 동의하지 않는 이유를 설명합니다.
YOLO V3 tech report에서는 저자가 따로 comment 받은 내용과 자신의 rebuttal letter를 "Rebuttal" section으로 만들어 공개했습니다. (첫 번째 문단을 보면 ICCV에 제출한건지......)
첫 번재 문단은 따로 설명하지 않겠습니다. YOLO랑 크게 관련 없는 내용이라....
[첫 번째 문단 관련 영어단어 및 표현 정리]
- shouts: shout이 보통 복수형으로 쓰이면 '외침'이라는 뜻으로 쓰이긴 하는데, 슬랭의 의미로 사용할 때는 누군가가 좋은 아이디어를 낼 때 "that's shouts'라고 사용한다고 하네요.
- heartfelt: 진심어린
- invariably: 변함없이, 언제나
[첫 번째 Reviewer: Dan Grossman]

첫 번째로 받은 comment는 "Figure 1, 3"에 대한 지적입니다. "Figure1", "Figure3" 두 그림을 보면 YOLOv3 그래프의 X축이 0부터 시작하지 않습니다.

그래서, 이러한 comment를 받아들여, 아래와 같은 "Figure 4"를 만들어 제공했습니다.

[첫 번째 Reviewer관련 용어]
- AKA: 일명 ~로 알려진 (as known as ~)
- throw in ~: ~를 덧 붙이다.
[두 번째 Reviewer: JudasAdventus]


JudasAdventus라는 사람이 "the arguments against the MSCOCO metrics seem a bit weak."라고 comment 해준 것 같은데, 뭔가.. YOLO v3 저자가 굉장히 기분 안좋은 것 같은 반응을....(제가 해석을 잘 못 하고 있는건지...) 아마, reviewer가 "COCO 데이터 셋은 segmentation 관련 label도 진행하기 때문에 더 정확한 bounding box 정답 좌표를 갖고 있을 것이기 때문에 COCO metric을 쓰는 것에 대한 반문은 "bit weak"하다고 한 것 같습니다. 그러자, 저자는 그런게 문제가 아니라 mAP 쓰는 것에 대한 정당성 자체에 문제를 제기하고 있는 거라고 반문합니다. (그 이유는 아래 문단에서...)

YOLO v3 저자가 지적하는 바는 다음과 같습니다. Objecet detection 모델은 bounding box loss와 classification loss로 구성된 multi-task learning (← classification 학습도 하고, bounding box regression 학습도 하기 때문에 multi-task learning이라고 부름) 을 하는데, 기본적으로 bounding box regression 부분을 지나치게 강조하면 classification 학습이 잘 안될 수 있다는 것이 문제임을 제기합니다. 현실적으로도 물체를 잘 classification하는게 중요한거지 bounding box의 IoU를 50%, 55%, 60% 이런식으로 타이트하게 맞추는게 더 중요하지 않다고 주장하고 있습니다. (예를 들면, 보행자에서 지나가는 물체가 사람임을 인식하는게 중요한거지 사람에 대한 bounding box를 정확히 치는것이 중요하지 않다는 논리인것 같습니다)
또한, mAP라는 성능 지표자체가 갖고 있는 치명적인 결함은 다음과 같습니다. 아래 그림에서 누가봐도 "Detection #1"의 결과가 "Detection #2"의 결과보다 좋은거 같은데, 실제 "Detection #1"과 "Detection #2"의 mAP 값이 동일하게 나옵니다. 그 이유는 다음과 같습니다.

그 이유는 아래글에서 object detection에서의 precision 개념을 살펴보시면 이해할 수 있으실 겁니다! (간단하게만 말하자면, Detector2의 경우 FN이 많아진 것일 뿐, TP, FP의 개수에는 변함이 없습니다. 그래서, Precision=TP/(TP+FP) 수식 관점에서는 precision은 변하지 않는 것이죠)
https://89douner.tistory.com/76?category=878735

위와 같은 이유를 들어 저자는 mAP 성능 지표를 쓰는 것이 현실적으로 의미가 있는거냐라는 질문을 다시 한 번 하고 있습니다.
7. Joseph Redmon quits CV research
YOLO V1부터 YOLO V3까지 개발해왔던 Joseph Redmon은 2020년이 되자 더 이상 CV (Computer Vision) 연구를 진행하지 않겠다고 선언합니다. 자기가 개발하는 CV 기술들이 군사목적으로 사용되는 것도 원치 않고 privacy 문제도에도 영향을 미치는 것 같다고 합니다 (뭐 드론 같은데에 잘 못 쓰이면 심각한 privacy 문제가 생길 수 있죠). 그래서 YOLO를 더 이상 개발하지 않습니다.
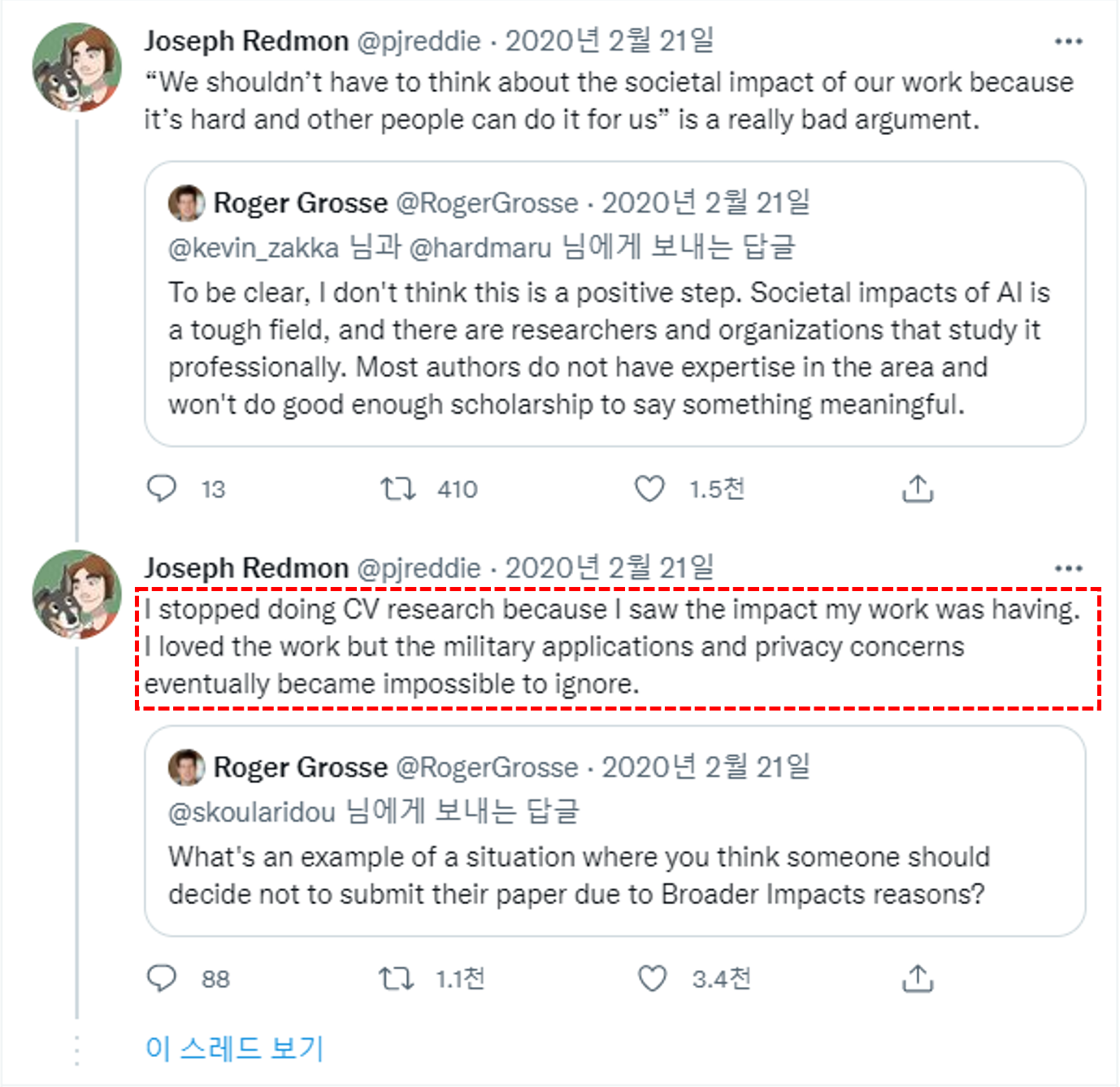
하지만, Alexey Bochkovskiy라는 러시아 연구원이 이전부터 YOLO 연구를 계속하고 있었기 때문에, Joseph Redmon이 YOLO 개발 중지 선언한 두 달 뒤 (2020.04.23) YOLO V4를 개발하고 논문화합니다. YOLO V4는 다른 글에서 설명하도록 하겠습니다.
[참고한 자료]
1. PR-12. YOLOv3 이진원님 발표영상
'Deep Learning for Computer Vision > Object Detection (OD)' 카테고리의 다른 글
| 14. Object Detection Trend (2019~2021.08) (7) | 2021.09.12 |
|---|---|
| 11. SSD (3) | 2020.02.06 |
| 10. YOLO V2 (4) | 2020.02.06 |
| 9. YOLO V1 (4) | 2020.02.06 |
| 8. Faster RCNN (1) | 2020.02.06 |