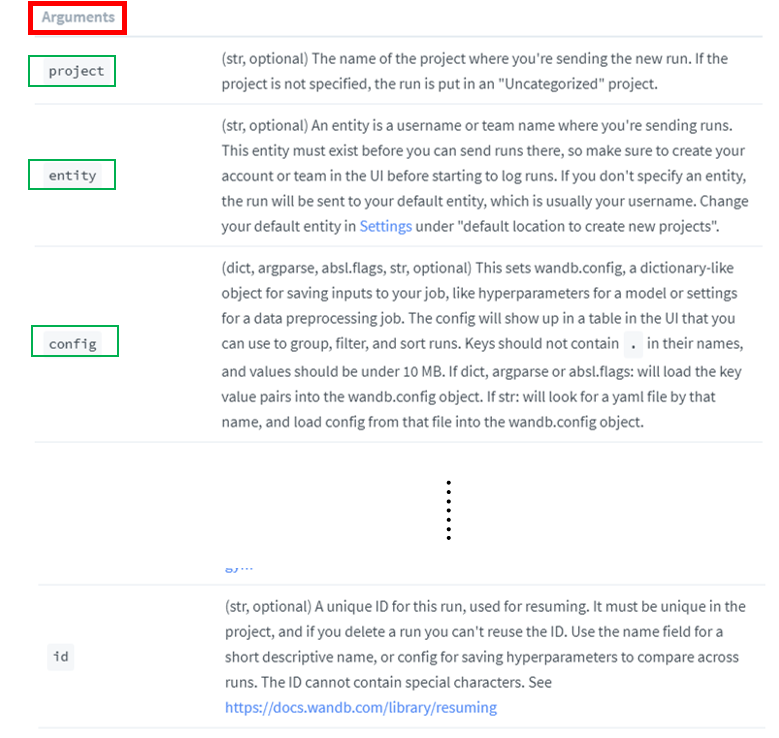
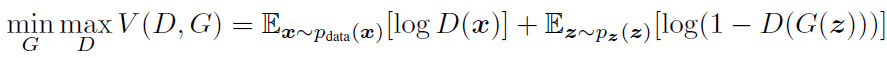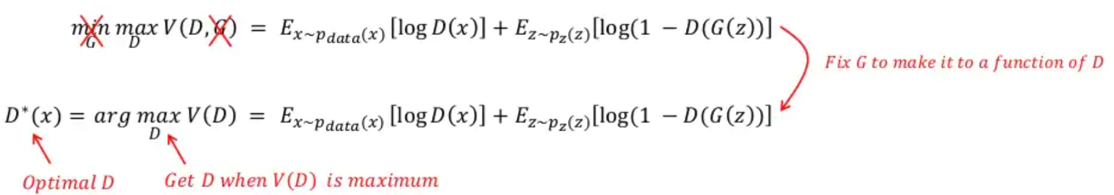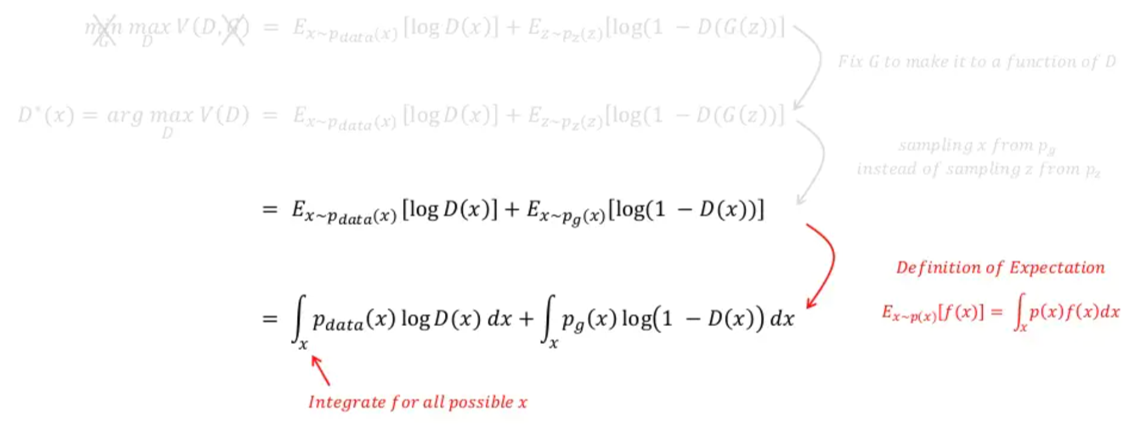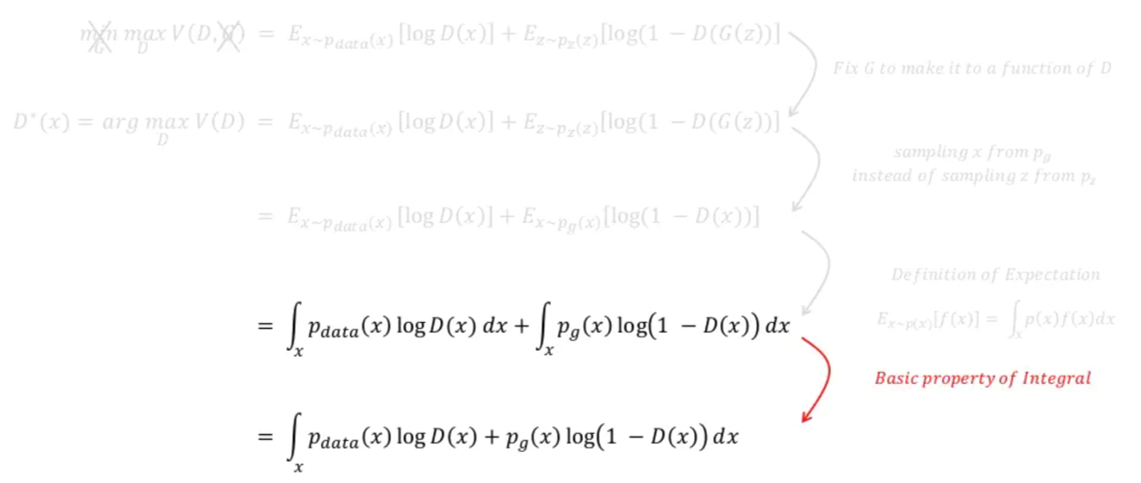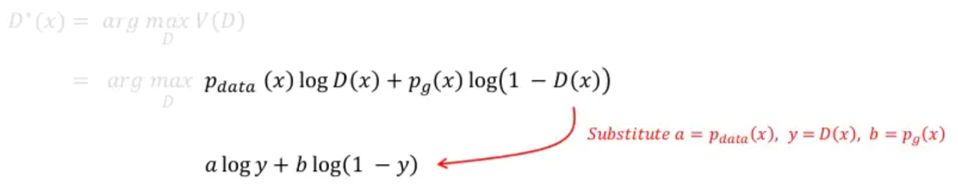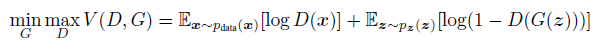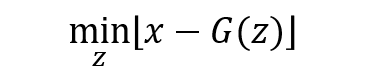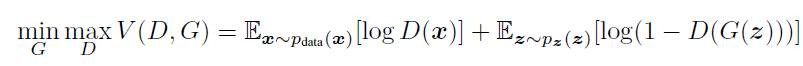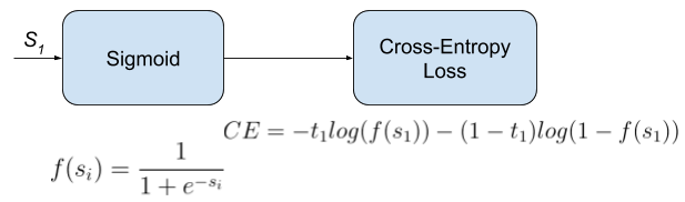"그렇다면, GAN의 최종 loss는 어떠한 값을 갖어야 global optimum이라고 할 수 있을까요?"
"즉, 최종적으로 도달하고자 하는 loss 값은 무엇일까요?
지금부터 이에 대한 답을 해보도록 하겠습니다.
Generator관점에서 MinMax problem (value function)은 \(P_{g}=P_{data}\) 에서 global optimum 값을 갖아야 합니다. 직관적으로 봤을 때,Generator가 Data와 유사한 distribution을 형성하는 지점인 곳에서 global optimum 값을 찾게 되면 학습을 중단하겠죠?
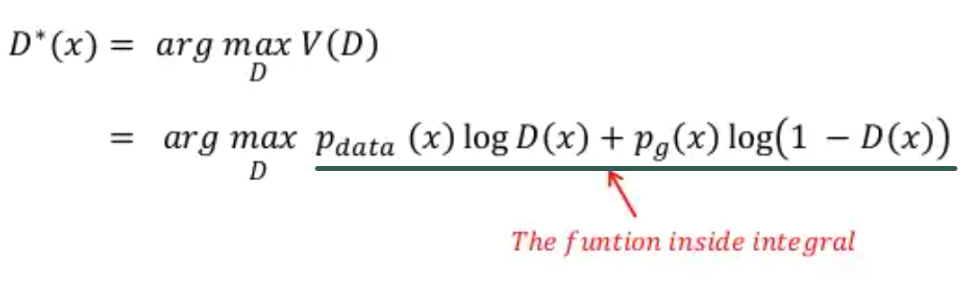
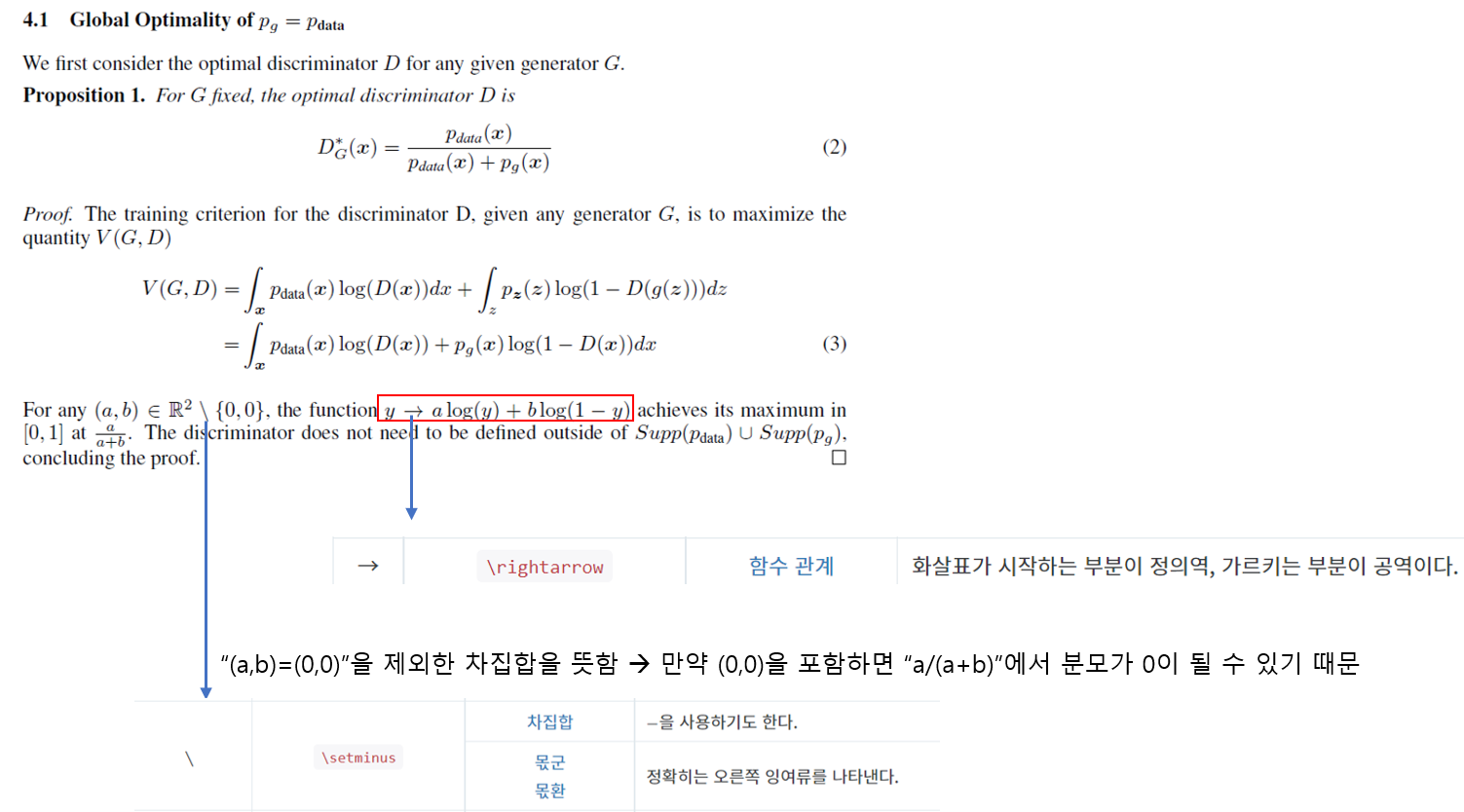
이 논문에서는 optimal discriminator의 global optimum 값은 아래와 같은 수식에 의해 도출 된다고 합니다.
\(P_{g}=P_{data}\) 일 경우 \(D^{*}(x)=\frac{1}{2}\) 값을 갖는데, 이것이 의미하는 바는 discriminator가 가짜 이미지와 진짜 이미지를 판별할 확률이 모두 \(\frac{1}{2}\)라는 사실과 값습니다. 즉, 가짜와 진짜를 완벽히 혼동한 상태인 것이죠. 그러므로, GAN loss function인 V(D,G) 값이 \(\frac{1}{2}\)에 가까이 도달하면 학습을 종료하면 됩니다. (CNN loss인 Cross entropy 에서는 0값에 도달하면 보통 학습을 중단시키죠)
Optimal discriminator 상태에 도달했다는 것은Generator관점에서 봤을 때 이미 \(P_{data}=P_{g}\) 상태로 학습이 거의 다 됐다는 것을 의미합니다.즉 G가 이미 최상의 상태에 도달했다고 가정하여 G를 fix시키고 optimal discriminator D*(x)에 대한 수식만 찾는 것이죠.
위와 같은 사실을 봤을 때, GAN이라는 모델은 generator와 관련된 loss가 아닌 discriminator와 관련된 loss에 의해 학습을 종료할지 말지 결정하게 되는 것이죠. 바꿔 말하자면, optimal discriminator의 값을 찾기 위해 discriminator(D) 부분만 고려하겠다는 것입니다.
▼
▼
▼
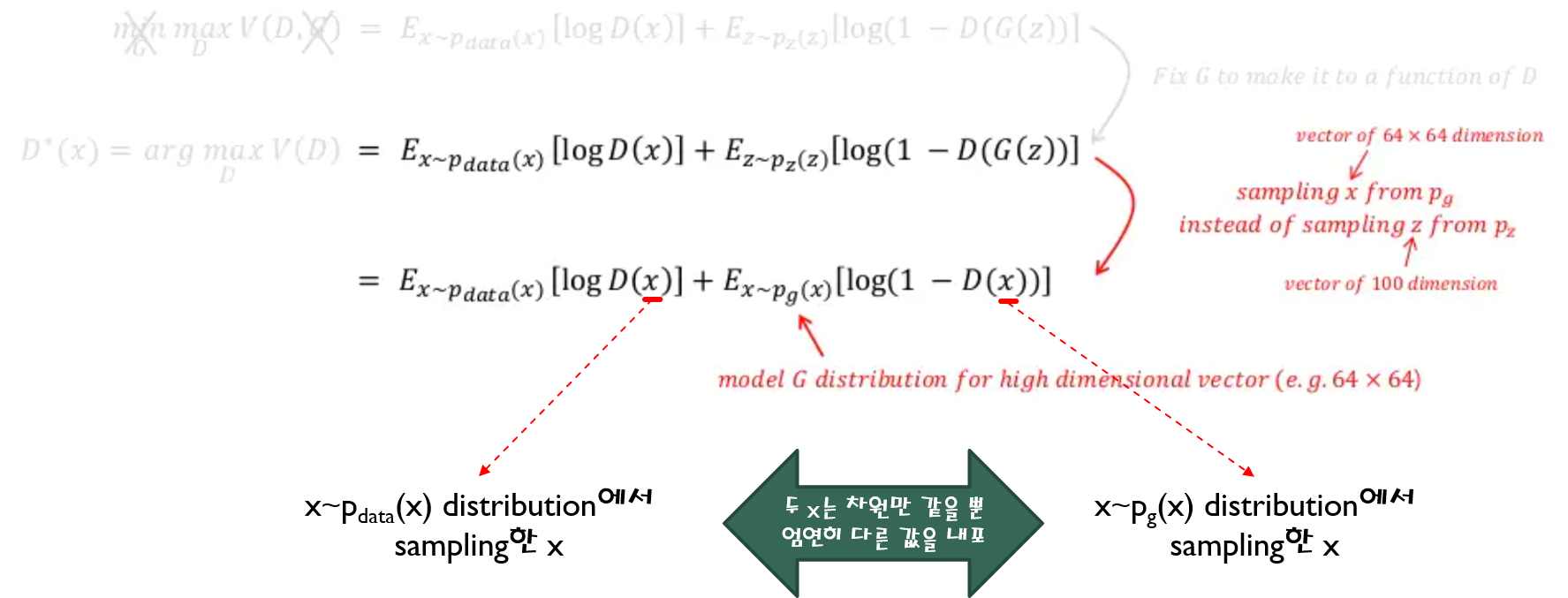
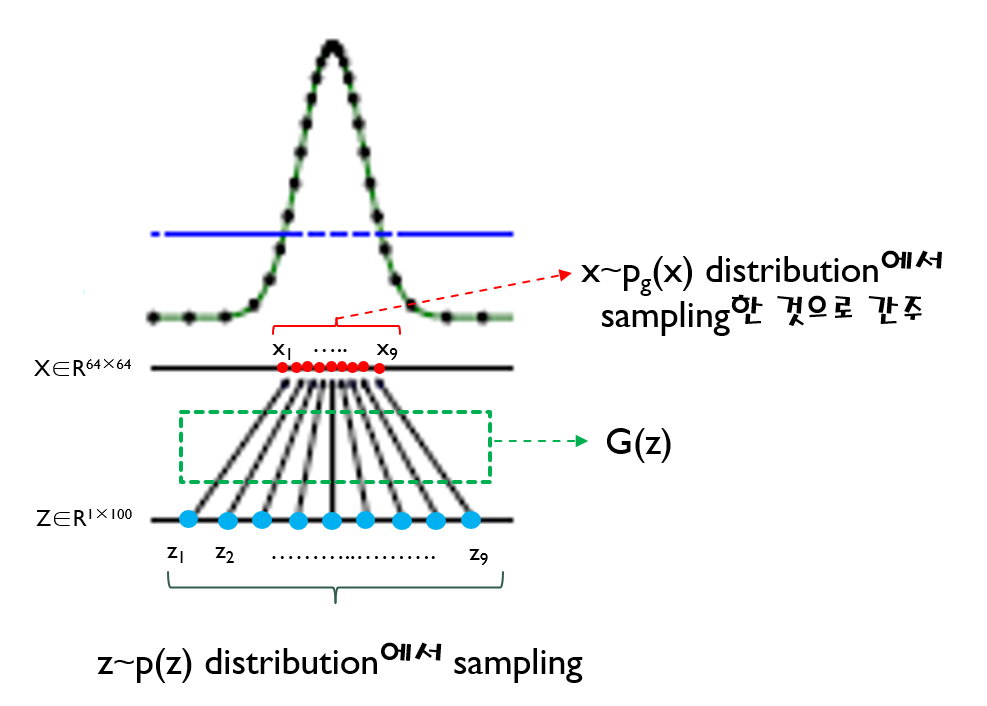
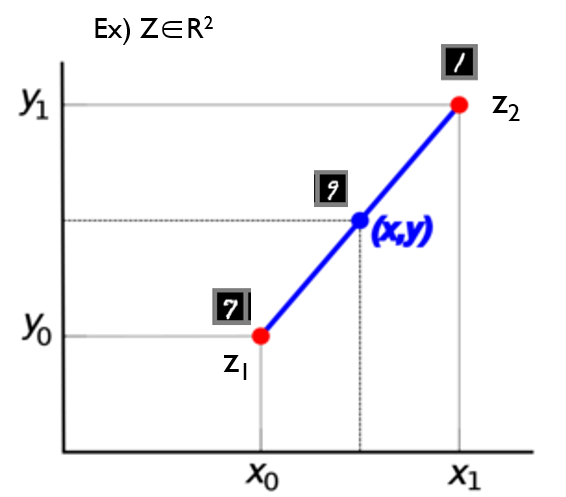
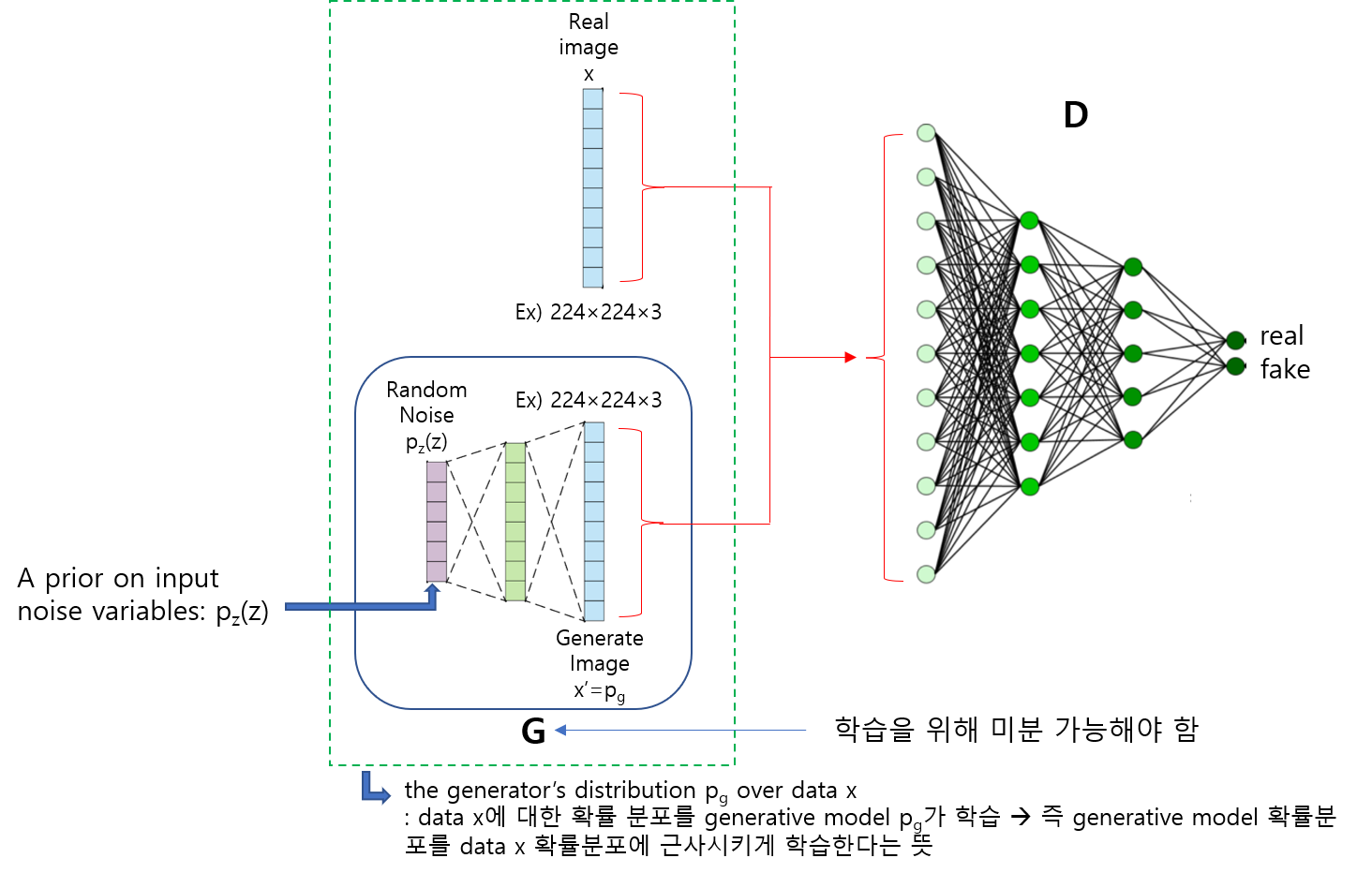
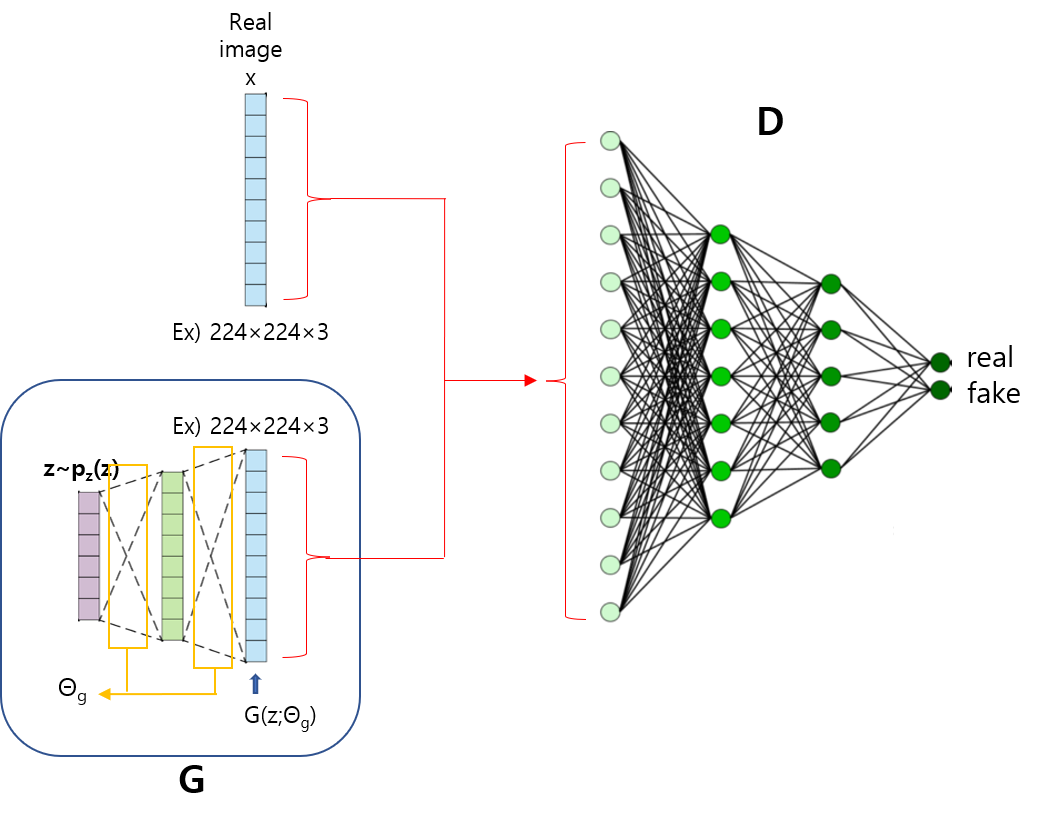
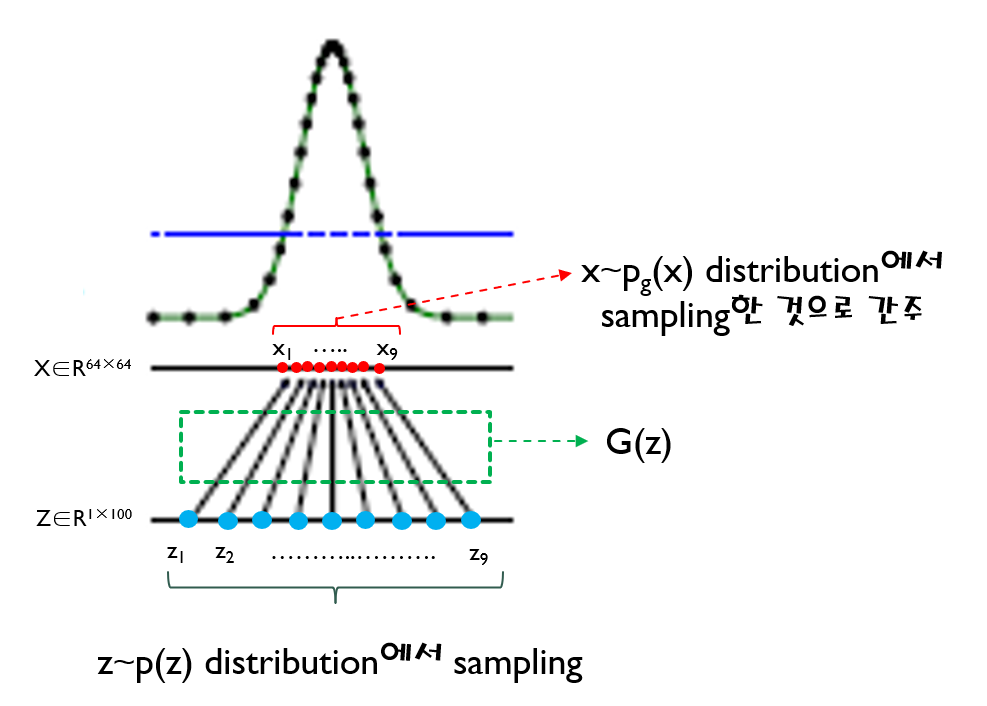
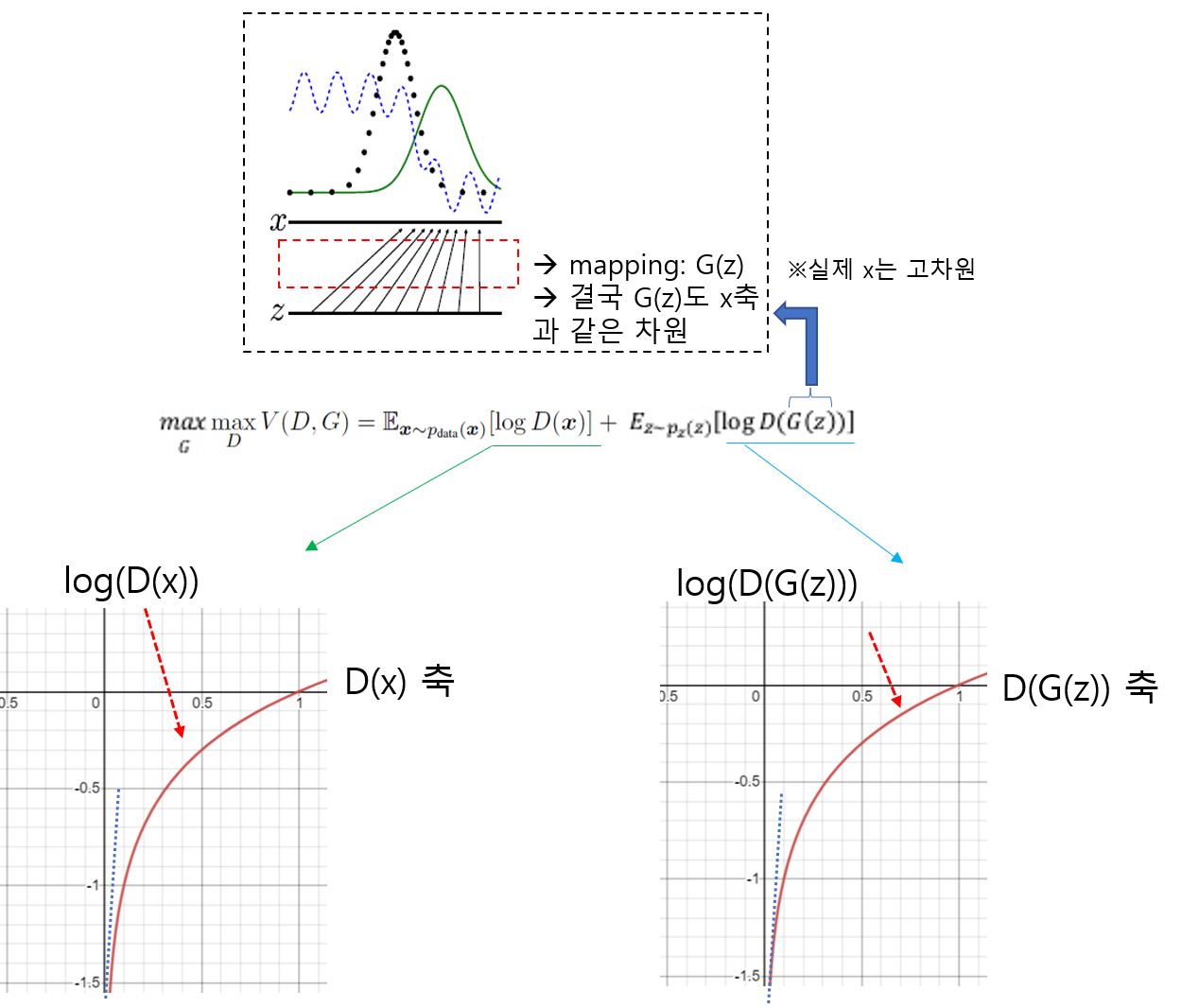
위 수식을 보면 G(z)를 x로 바꿔 주면서 \(E_{z\sim ~p_{z}(z)}\) 수식부분이 \(E_{x\sim ~p_{g}(x)}\) 로 변경된 것을 확인할 수 있습니다. 이것이 가능한 이유는 G(z)의 차원이 곧 X차원과 동일하여 G(z)에서 발생한 값을 X 차원 상의 하나의 x값으로 표현(=mapping)할 수 있기 때문입니다.
Pz(z): low dimension distribution,z = 100
Pg(x): high dimension distribution, x = 64x64
위와 관련된 내용은 아래 링크(글)에서 “3. Adversarial nets”→“[3-2-2. Second paragraph & Second sentence]" 부분을 참고해주세요.
그럼, 딥러닝 모델 설계 시 고려해야 하는 4가지 질문 중, 세 번째 질문에 대한 답을 설명드려보겠습니다.
"설계한 확률(딥러닝)모델이 최적해(global optimum)에 수렴하는가?"
위에 있는 질문을 바꿔서 표현하면 "\(p_{g}\)가 \(p_{data}\)로 수렴할 수 있는가?"로 표현할 수 있습니다. 즉, generative model인 \(p_{g}\) 관점에서 loss 함수가 (global optimum으로) convergence(수렴) 할 수 있는지 따져야 하는 것입니다.
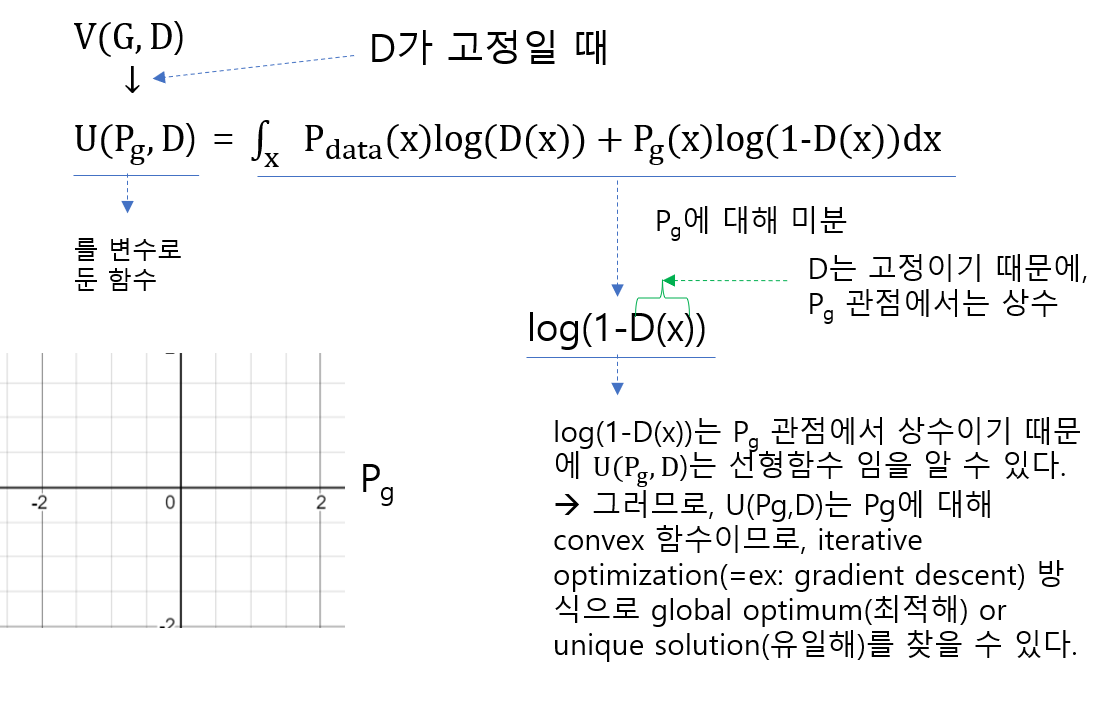
"Generative model인 \(p_{g}\) 관점에서 loss 함수가 (global optimum으로) convergence(수렴) 할 수 있는지 따지기 위해서는 'D를 고정시키고, loss 함수가 convex한지 확인하는 것' 입니다."
아래 그림을 잠깐 설명해보겠습니다. D는 고정했기 때문에 \(U(P_{g},D)\) 를 \(P_{g}\) 관점에서 보면 D는 (고정된) 상수값입니다. 바꿔말해,\(P_{g}\)관점에서 보면 \(U(P_{g},D)\)의 변수는 \(P_{g}\)인 셈인 것입니다. 결국, \(P_{g}\)가 학습함에 따라서 변할 텐데, 변하는\(P_{g}\)에 따라서 \(U(P_{g},D)\)가 convex한지 알아봐야 iterative optimization(=ex: gradient descent) 방식으로 global optimum을 찾을 수 있는지 확인 할 수 있습니다.
위의 설명 중에서 "어떤 함수를 미분했을 때, 해당 함수가 상수 값을 갖는다면 그 함수는 convex하다고 할 수 있다"는 개념이 있습니다. 예를 들어 보충 설명하면, 2x+1라는 수식에서 x에 대해서 미분하면미분값=2가 나옵니다. 즉, 어떤 수식을 x로 미분 했더니 상수가 나오면 그 수식은 선형함수가 되는 것입니다. 그리고, 선형함수는 convex 라고 할 수 있는데,특정 구간 (ex=(0,1))을 설정해놓으면, 해당 구간에서 minimum 값을 찾을 수 있게 됩니다.
(↓↓↓linear function이 convex function 임을 보여주는 글↓↓↓)
"설계한 확률(딥러닝)모델의 최적해(global optimum)을 찾을 수 있는 알고리즘이 존재하는가?"
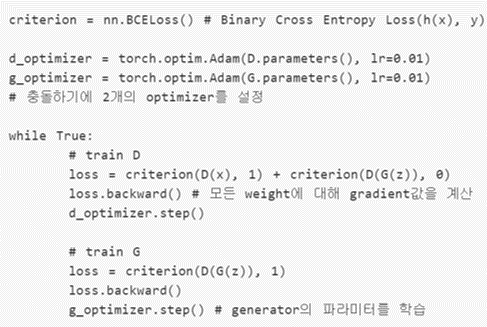
이 논문에서는 아래와 같은 방식으로 D와 G를 서로 학습함으로써 최적해(global optimum)을 찾을 수 있음을 보여줬습니다.
위의 알고리즘을 실제로 코딩할 때 아래와 같이 구현할 수 있습니다. (D학습시 따로 k step을 두진 않은 것 같네요)
(↓↓↓D, G 관련 loss가 왜 아래와 같이 변하는지는 GAN part1에서 설명 함↓↓↓)
[Neural network를 Generative model에 도입할 경우]
GAN을 통해 생성하는 데이터의 분포 \(p_{g}\)를 추정하고 최적화 하는 것이 아니라, \(p_{g}\)를 생성하는데 직접적인 영향을 미치는 parameter인 \(\theta_{g}\)를 추정하고 최적화 합니다. 또한, 엄밀히 말하자면 수학적인 증명에서는 generative model, discriminative model이 neural network를 사용한다는 언급이 없습니다. 그런데, Generative model을 MLP(multilayer perceptron; neural network; deep learning)와 같은 것으로 설정하게 되면 실제로 최종 loss function 자체가 convex하지 않을 수 있고, 즉 multiple critical points를 가질 수 있습니다. 하지만, 마법같은 MLP는 이러한 theoretical guarantees가 굳이 보장되지 않고도 나름 생성모델에서 잘 작동한다고 주장하고 있습니다.
5. Advantages and disadvantages
이 부분("5. Advantages and disadvantages")은 GAN의 대표적인 disadvantage라고 할 수 있는 mode collapse에 대해서만 설명하도록 하겠습니다.
먼저, mode라는 용어에 대해서 이해하도록 하겠습니다.
보통 통계학에서 mean, median, mode, range라는 용어가 사용되는데, 해당 용어들이 의미하는바는 아래와 같습니다.
MinMax Value function을 살펴보면, 학습 시 G(z)가 생성하는 이미지의 종류에 대해서는 고려하지 않습니다. 예를 들어서, G(z)가 MNIST의 1이라는 이미지를 생성하는데 D가 계속해서 판별을 못하고, G(z)가 생성하는 MNIST의 2라는 이미지만 잘 판별해도 되면 결국 value loss 값은 낮아지게 되는 것이죠. 극단적으로 설명해서 MinMax 방식으로 서로 학습하면 D가 만족하는 (판별을 잘 할 수 있는) 이미지(from G(z))만 생성하도록 G가 학습할 것이며, 결국 (서로 좋은쪽으로만) 편향되게 D와 G는 alternative하게 학습하게 될 것 입니다.
앞서 설명한 것을 다르게 표현하면, G(z)는 MNIST의 1의 distribution은 잘 표현해주지 못하고, 2라는 이미지의 distribution만 잘 표현해도 전체 value function의 loss 값은 낮게 나올 수 있습니다. 이렇게 되면 Generative model G가 특정 숫자만 생성하게 되겠죠.
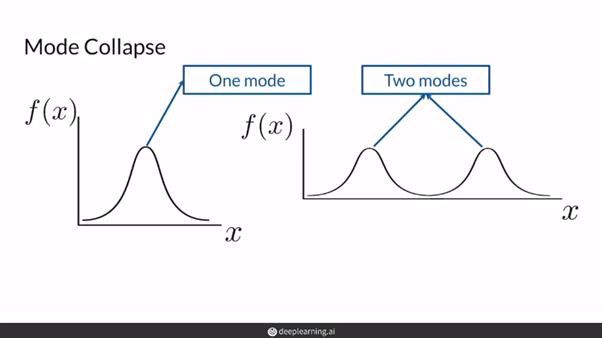
Mode collpase를 정리하자면 아래와 같이 표현할 수 있습니다.
"Mode collapse happens when the generator can only produce a single type of output or a small set of outputs. This may happen due to problems in training, such as the generator finds a type of data that is easily able to fool the discriminator and thus keeps generating that one type."
위의 그림을 설명하면 다음과 같습니다.
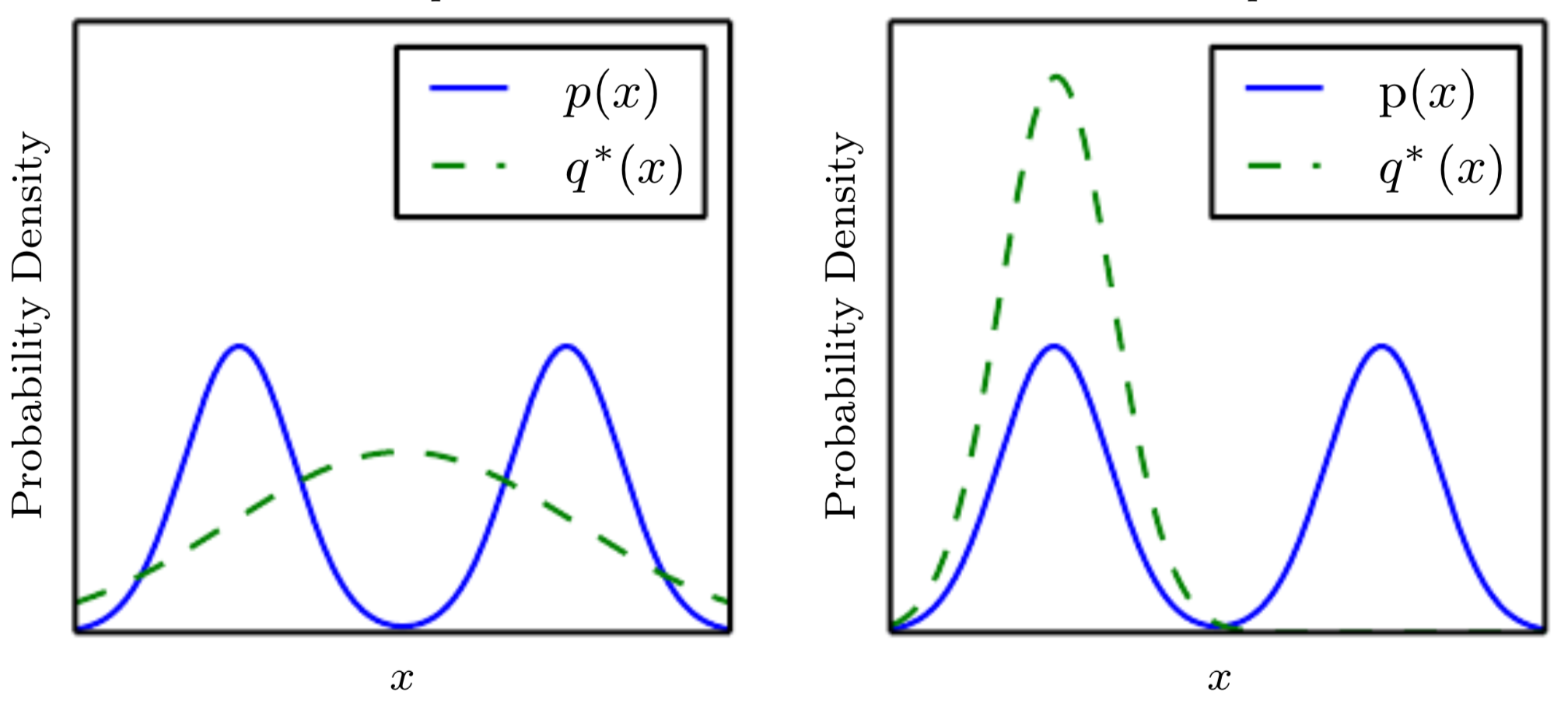
먼저 3개의 검은색 실선이 실제 이미지를 나타내는 것이라고 볼 수 있습니다. 예를 들어, 각각의 실선들은 금발여성, 흑발과 안경을 쓰고 있는 남성, 흑발 여성을 나타낸다고 해보겠습니다.
"즉 우리가 원하는 목표는 실선 3개를 모두 표현해줄 수 있는 확률 분포를 익히는 것이라고 볼 수 있습니다."
가운데 실선에 해당하는 데이터 셋이 제일 많다고 하면, VAE는 제일 데이터 셋이 많은 그룹에 맞게 distribution을 형성하면서 동시에 normal distribution을 이용해 주변 이미지 그룹들도 다 포괄할 수 있도록 학습을 하기 때문에 모든 데이터 그룹을 포괄하려는 것을 볼 수 있습니다.
반대로 GAN은 generator가 만드는 이미지 그룹을 discriminator가 더 이상 구별해내지 못할 때 (real image가 들어왔을 때 맞출 확률 ½, fake image가 들어왔을 때 맞출 확률 ½ 이 될 때) 학습이 종료가 됩니다. 그렇기 때문에 이미지 데이터 셋이 많은 (가운데 실선에 해당하는) 그룹만 학습하다 끝내버리면 해당 그룹만 잘 generation해주는 현상이 발생 할 수 있습니다.
각각의 실선 (이미지 그룹)이 우리가 representation (By generator)해야 할 중요한 mode라고 부르기도 하는데, GAN에서는 이러한 mode들을 잘 학습하는 것이 안되는 붕괴(collapsing) 현상이 일어난다고 하여 mode collapsing의 단점을 갖고 있다고도 합니다.
그 외 mode collpase에 대한 설명이 필요하시면 아래 링크를 참고해주시면 좋을 것 같습니다.
Generator nets: a mixture of rectifier activations and sigmoid activations
Discriminator net: maxout activations
Drop out
discriminator net 학습시에만 drop out 적용
Noise
이론적으로는 intermediate layers of generator에 주겠금 되어있음
하지만, 실제 구현 상에서는 "the bottommost layer of the generator network"의 input에 해당하는 data에 noise를 주어 학습 시킴
"Conventionally people usually draw neural networks from left to right or from bottom-up (input to output). So by “top layer” it’s more likely to be the last (output) layer."
<그림 출처: https://velog.io/@hwany/GAN>
아래 그림 처럼 논문에서는 1과 5 사이의 vector linear interpolation, 7과 1사이의 vector linear interpolation 했을 때의 결과를 보여줍니다.
아래 수식을 이용하면 실제 이미지 데이터에 대응하는 z 값을 찾을 수 있습니다.
이렇게 찾은 z값들 간에 vector linear interpolation을 하게 되면, 7과 1사이의 z 중간 값이 9가 나오는걸 확인할 수 있습니다.
실제 논문에서는 결과에 대한 여러 해석들이 있는데, 요즘에 사용하고 있는 GAN 평가지표와는 다른 부분이 있어 생략하도록 하겠습니다.
이번 글에서는 최초의 GAN 논문인 "Generative Adversarial Nets"을 리뷰하려고 합니다.
우선, GAN이라는 모델이 설명할 내용이 많다고 판단하여 파트를 두 개로 나누었습니다.
Part1에서는 GAN architecture를 포함한 GAN에 대한 전반적인 내용들(Abstract, 1.introduction, 3.Adversarial nets)을 이야기하고, Part2에서는 GAN을 수학적으로 정리한 내용(4.Theoretical results) 및 나머지 부분들(5.Experiments, 6.Advantages and disadvantages)에 대해 이야기 해보도록 하겠습니다.
논문을 리뷰하기 전에 GAN의 저자인 Ian J. Goodfellow를 간략히 소개할까 합니다. (딥러닝 하시는 분들이라면 대부분 알고 있으실테니, 보기 편하게 간략히 정리하는 정도로만 하겠습니다~)
B.S, M.S (2004~2009)
University: Stanford University
Major: Computer Science
Supervisor: Andrew Ng
Ph.D (2010~2014)
University: Université de Montréal
Major: Machine Learning
Supervisor1: Yoshua Bengio
Supervisor2: Aaron Courville
GAN 논문은 박사과정때 쓴 것 (arXiv 2014.06)
Google Brain (2015~2016)
Senior Research Scientist
Open AI (2016~2017)
Research Scientist
GAN논문이 NIPS에 accept되어, presentation 발표함
Google Research (2017~2019)
Senior Staff Research Scientist
Apple (2019~Current)
Director of Machine Learning
(↓↓↓2016 NIPS에서 Open AI 소속으로 GAN을 발표하는 Ian J. Goodfellow↓↓↓)
Ian J. Goodfellow는 박사과정 졸업 후, supervisor인 Yoshua Bengio, Aaron Courville와 함께 Deep Learning book을 편찬했습니다. 제 생각에는 책의 발행년도가 2015년이니 이전부터 아마 박사과정 졸업 논문을 쓰면서 background로 정리해 놨던 내용들을 지도교수들과 함께 책으로 만든게 아닌가 싶습니다. 제가 석사 때 다녔던 대학원을 포함해, 많은 학교에서 이 책을 deep learning 수업교재로 사용했던걸로 기억합니다.
GAN의 저자인 Ian J. Goodfellow에 대해서 간단히 알아봤으니 이제부터는 논문을 본격적으로 리뷰해보도록 하겠습니다.
0. Abstract
Abstract에서 설명한 내용을 6가지 key words로 나누어 설명드리고자 합니다.
Adversarial process (Abstract에서 분홍색 음영처리 된 부분)
Minimax two-player game (Abstract에서 주황색 음영처리 된 부분)
Estimating generative models (Abstract에서 노란색 음영처리 된 부분)
A unique solution (Abstract에서 보라색 음영처리 된 부분)
Architecture (Abstract에서 빨간색 음영처리 된 부분)
Qualitative and quantitative evaluation (Abstract에서 회색 음영처리 된 부분)
[0-1. Adversarial process]
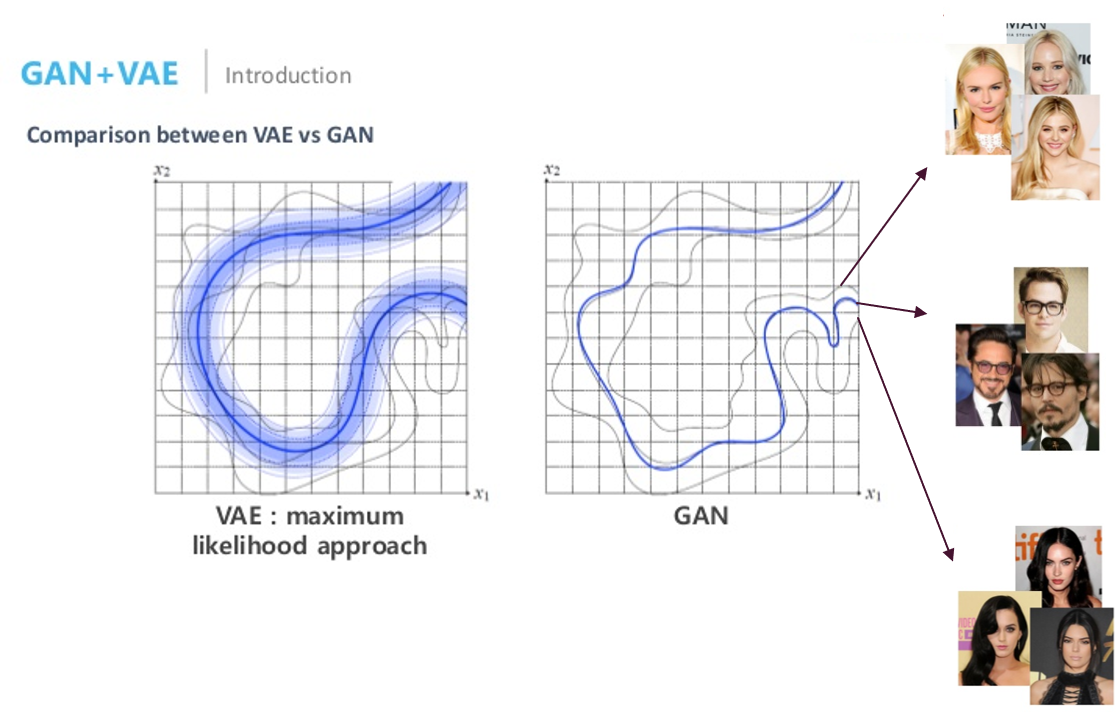
"GAN이라는 것은 기본적으로 generative model의 성능을 높이기 위해 고안된 architecture입니다."
즉, 실제와 유사한 이미지를 생성해주는 generative model을 만드는 것이 목적이죠.
이렇게 이상적인 generative model을 만들기 위해 생각한 것이 generative model을 경쟁시키는 것입니다.
"우리도 경쟁을 통해서 성장하는 것 처럼 generative model도 경쟁을 통해 성장하게 하는 것이 GAN 논문의 기본 철학이죠."
GAN이라는 구조에서는 generative model의 경쟁자를 discriminator model로 두고 있습니다. 그리고, 앞서 언급한 경쟁이라는 표현보다는 "adversarial(적대적)"이라는 표현을 사용합니다. "Adversarial"이라는 표현을 쓴 이유는 generative model과 discriminator model은 서로 반대의 목적을 갖고 있었기 때문이라고 생각합니다 (경쟁이라는 표현은 사실 같은 목적을 두고도 사용할 수 있으니까요).
예를 들어, 위조 지폐범과 경찰은 서로 적대적이라고 할 수 있습니다. 왜냐하면, 위조지폐범은 일반인들이 진짜라고 믿게 만드는 fake money를 잘 생성하는 것이 목적이고, 경찰은 일반인들이 위조지폐를 가려낼 수 있는 방법들을 알려주는 것이 목적이기 때문입니다.
"범죄라는 것이 항상 '만들어 놓은 예방법을 피해가려는' 속성이 있기 때문에, 위조지폐를 가려낼 수 있는 방법이 좋아질 수록, 이를 피해 위조지폐를 만드는 기술도 더욱 교묘해 집니다."
"이렇게 서로 적대적인 경쟁을 하다보면 위조지폐(=generative model)의 성능은 계속해서 좋아질 겁니다."
"a discriminative model D that estimates the probability that a sample came from the training data rather than G."라는 표현을 쓴 이유는 discriminative model이 기준을 'generative model로 부터 생성된 이미지인지를 판별하는 것'에 두는 것이 아니라, '실제 이미지인지를 판별하는 것'에 두는 것으로 봤기 때문이 아닌가 싶습니다. (CNN 관점에서 보면 background or negative sample 들을 잘 구별할 수 있게 학습하는 것과, foreground or positive sample들을 잘 구별할 수 있게 학습하는 것은 다른 문제이니까요. 예를 들어, 한 이미지에는 대부분 negative sample or background들이 많을 텐데, 이를 방치해두면 학습시 인공지능 모델이 background or negative sample만 잘 구분할 수 있도록 학습하게 될거에요. ) ← 혹시 이 부분에 대해서 다른 의견이 있으면 댓글로 남겨주세요!
[0-2. Minmax two-player game]
앞서 언급한 "adversarial"이라는 개념을 좀 더 간단히 표현하면 다음과 같습니다.
"경찰(D)가 최대한(max) 위조지폐를 구분할 수 있는 능력을 높일수록, (adversarial 관계에 의해) 위조지폐범(G)은 (경찰을 속이기 위해) 자신들이 만들어내는 가짜 이미지와 실제 이미지의 차이를 최소화(min)하게 된다."
위의 말을 수식적으로 아래와 같이 표현하는데, 아래 수식에 대한 설명은 뒤에서 더 자세히 다루도록 하겠습니다.
[0-3. Estimating generative models]
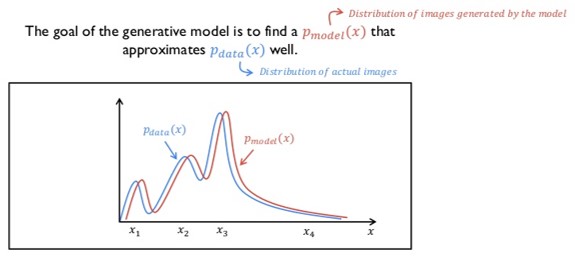
Generative model을 추정(estimating)한다는 것의 의미를 파악하기 위해서는 이미지라는 개념을 distribution 관점에서 해석할 수 있어야 합니다.
위의 링크를 토대로 추가적인 설명하면 generative model을 추정한다는 개념을 아래와 같이 정리할 수 있습니다.
"Generative model을 추정한다는 것은 실제 이미지 확률 분포에 maximum likelihood하도록 하는 generative model의 확률 분포를 추정(estimating)한다고 간주할 수 있습니다."
[0-4. A unique solution]
이 부분은 "3.Adversarial nets", "4.Theoretical results"에서 좀 더 상세히 설명하도록 하겠습니다.
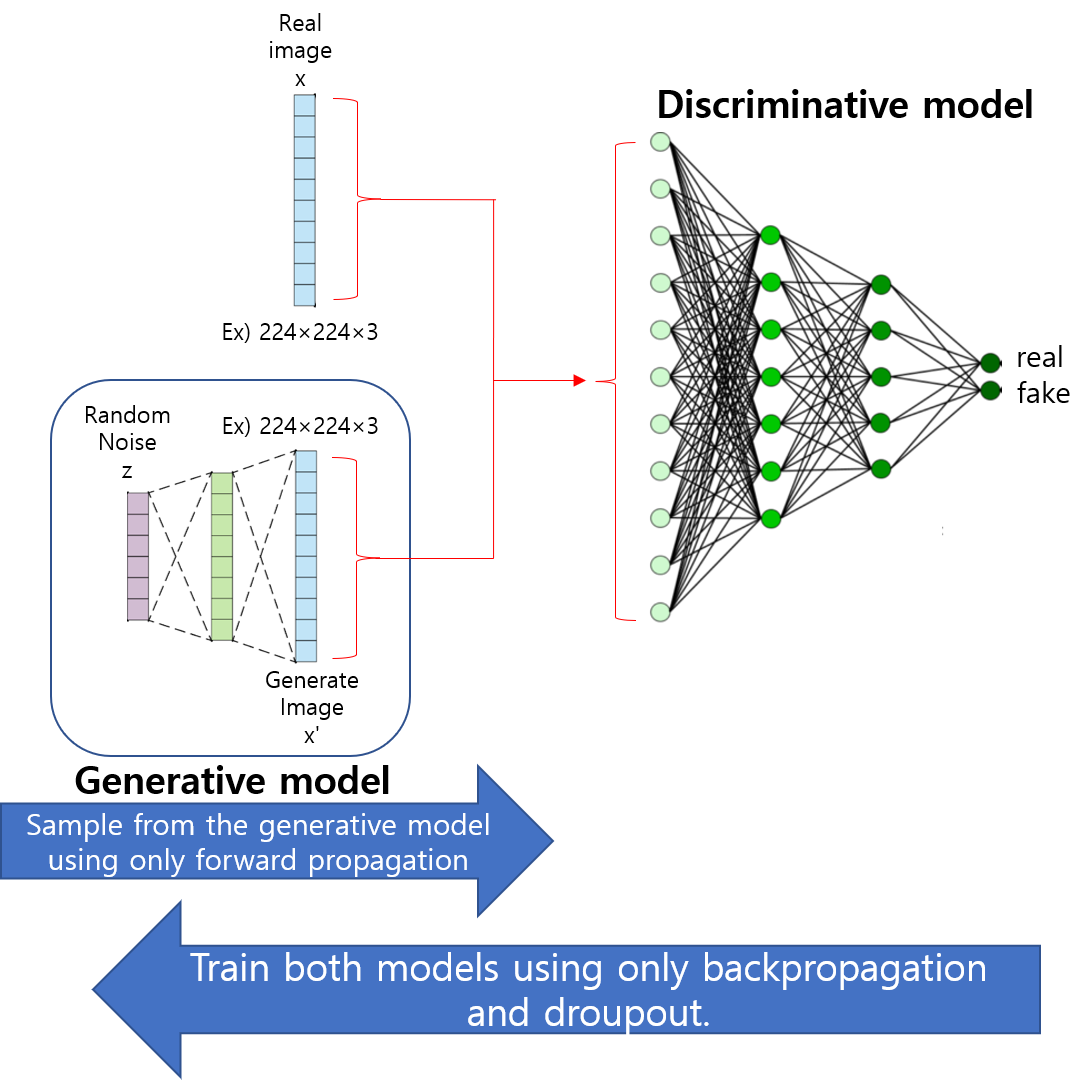
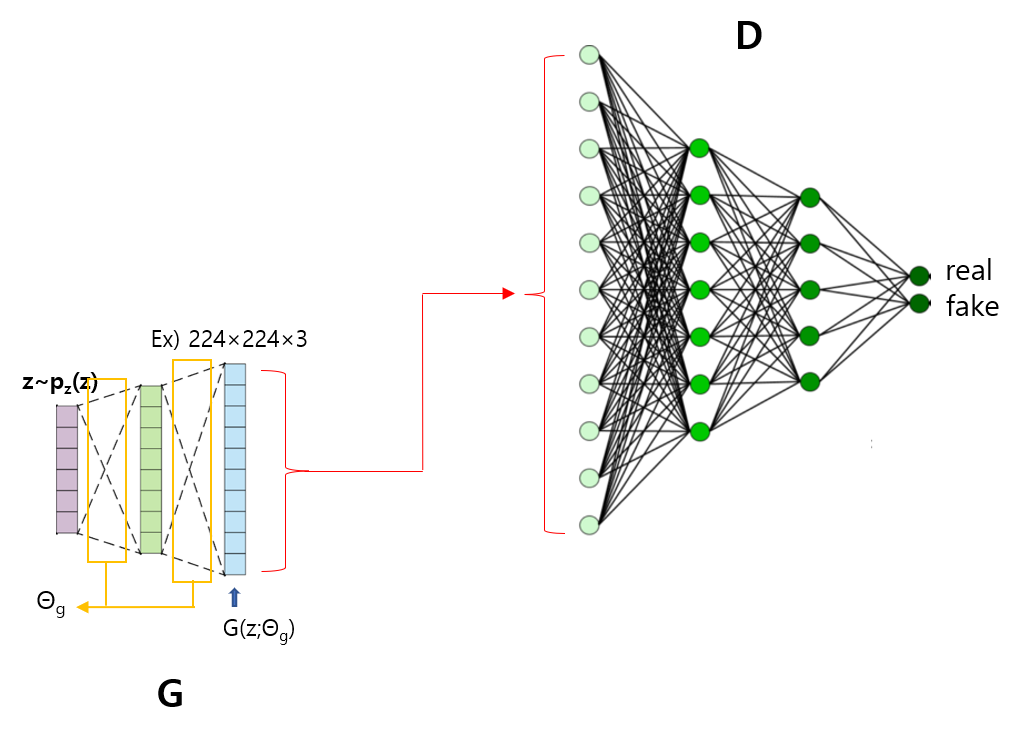
[0-5. Architecture]
위의 내용에 대한 설명은 아래 그림으로 대체하겠습니다. (보통 Vision 분야에서 생각하고 있는 GAN은 DCGAN을 기반으로 한 것인데, DCGAN은 이 논문 이후에 나온 모델입니다. 그래서, 아래 그림은 현재 논문에서 설명하고 있는 MLP를 기반으로 구성되었습니다)
CNN, Object detection, Segmentation 모두 각각의 task에 대한 성능을 평가하기 위한 지표들이 존재합니다. (ex: F1 score, ACC, mAP, Dice loss, etc ...) 예를 들어, CNN model에서는 VGGNet보다 ResNet의 ACC가 더 좋으면 ResNet이 더 좋은 모델이라고 (일반적으로) 평가하죠.
마찬가지로 generative model도 여러 종류들이 있을 텐데 어떠한 생성모델이 좋은지 평가할 수 있는 기준이 있어야겠죠?
보통 generative model의 성능 평가 지표는 두 가지 큰 categories가 있습니다.
Qualitative measures are those measures that are not numerical and often involve human subjective evaluation or evaluation via comparison.
ex) Rapid Scene Categorization: 사람한테 잠깐 보여주고 이미지가 뭔지 맞추게 하여 생성모델이 이미지를 잘 생성하는지 평가
Quantitative GAN generator evaluation refers to the calculation of specific numerical scores used to summarize the quality of generated images
ex) Frechet Inception Score (FIS) → DCGAN paper에서 설명할 예정
※이 논문에서 Markov Chain 관련 내용이 많이 나오는데, 이 글에서는 넘어가도록 하겠습니다. Markov Chain에 대한 설명까지 하게 되면 글이 너무 길어질 것 같아서....
1. Introduction
Introduction 부분은 문단(paragraph) 별, 문장(sentence) 별로 설명할 내용들이 많아 따로따로 나누어서 설명하도록 하겠습니다.
[1-1-1. First paragraph & First sentence]
[영어단어]
corpora: 말뭉치(corpus의 복수형태)
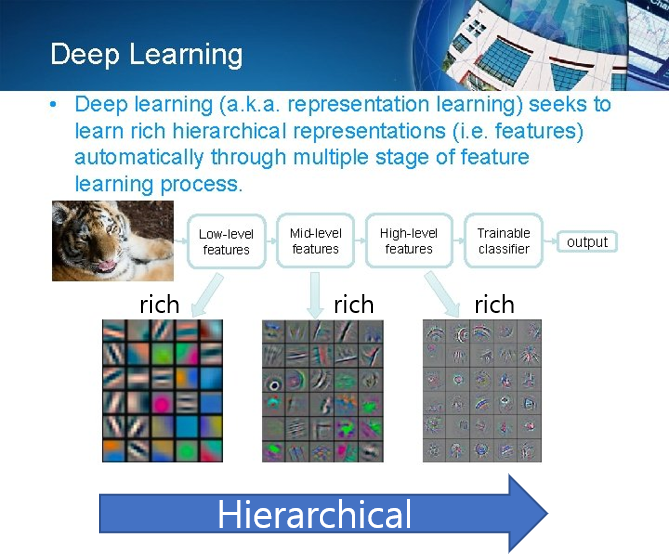
보통CNN같은 경우 다양하고(rich)구조적(hierarchical)으로filter가 구성되어 있습니다.예를 들어, low-levellayer만해도 가로edge,세로edge등 다양한feature들을extraction해줄 수 있는filter들로 구성 되어있죠.또한, low-level layer에서는edge, middle-level layer에서는texture, high-level layer에서는semantic정보들을 추출해 줄 수 있게filter가 구성되어 있습니다.
위와 같은 CNN(discriminator)모델은 어떤 이미지를 분류하기 위해 filter들이 최적화되었다고 볼 수 있습니다. 결국 어떤 이미지를 생성하는 generative model 역시 다양한 이미지를 생성하기 위해 rich and hierarchical feature들을 생성해야겠죠.(※CNN과 같은 discriminative model은 feature extraction하고, GAN과 같은 generative model은 feature generation한다고 보면 될 것 같네요)
"즉, generative model 입장에서는 어떤 이미지를 생성하기 위해 filter들을 최적화해야 합니다."
하지만, 이 논문에서 딥러닝의 미래는 이렇게 어떤 이미지를 분류하는 것이 아닌 어떤 데이터들을 그대로 표현(representation)해 줄 수 있는 모델을 만드는 것에 있다고 주장합니다. (어떤 데이터들을 그대로 표현해줄 수 있다면 해당 데이터들 또한 생성 할 수 있게 됩니다. 이에 대한 구체적인 설명은 논문을 리뷰해가면서 자세히 알아가도록 하겠습니다)
[1-1-2. First paragraph & Second, Third sentence]
이 논문의 저자는 CNN(=discriminative model)과 같은 딥러닝 모델이 성공한 이유를 세 가지 측면에서 설명하고 있습니다.
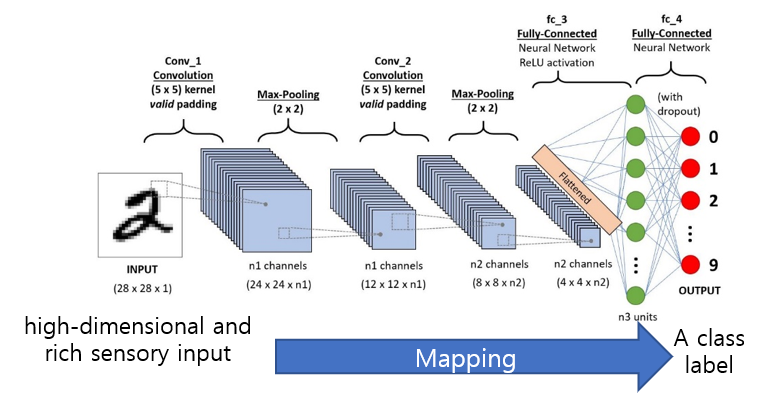
Map a high-dimensional, rich sensory input to a class label. ← discrimination(or classification)을 위해 저차원 vector(=FC layer의 neuron들)를 선별해줌 (Curse of dimensionality 극복)
Backpropagation and dropout algorithms ← Neural network의 첫 번째 겨울을 극복하게 해준 알고리즘
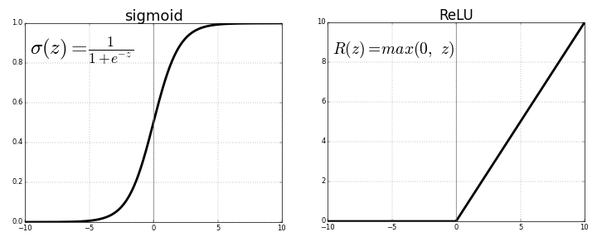
Piecewise linear units ← Neural network의 두 번째 겨울을 극복하게 해준 ReLU (Vanishing gradient 극복)
ReLU는 0을 기점으로 구분적으로 linear한 성격을 갖고 있습니다. Sigmoid보다 piecewise linear units (ReLU)에 의해 gradient가 더 잘 작동되었습니다.
piecewise 뜻: [수학] 구분적으로
<그림 출처: https://sanghyu.tistory.com/102>
[1-1-3. First paragraph & Fourth, Fifth sentence]
[영어단어]
sidestep: If you sidestep a problem, you avoid discussing it or dealing with it.
Deep generative model은 CNN 만큼 큰 임팩트를 주지는 못했는데, 그 이유는 deep generative model의 계산 복잡성 때문입니다. Deep generative model과 같은 확률모델을 생성하기 위해 maximum likelihood 계산을 할 때는 (보통) 계산시스템 관점에서 intractable problem 문제에 부딪히는 경우가 많습니다. 예를 들어, VAE와 같은 deep generative model은 본래 intractable problem이었는데, variational inference라는 mathematical trick을 이용하여 tractable problem으로 변경해주었죠. (VAE 관련 글은 짧은 시간내에 다루도록 하겠습니다. 정리는 해놨는데 시간 때문에 옮겨적고 있지 못하고 있어서ㅜ...;;)
VAE에서 와 같은 variational inference (approximate inference) 기법이나, 전통적인 생성모델에 쓰이던 Markov chains 같은 거 안써도된다는 것이GAN의 큰 장점이라고 합니다. (앞서 언급했듯이, VAE와 Markov chains은 나중에 따로 글을 작성하여 설명하도록 하겠습니다)
3. Adversarial nets
"3.Adversarial nets" 부분도 문단(paragraph) 별, 문장(sentence) 별로 설명할 내용들이 많아 따로따로 나누어서 설명하도록 하겠습니다.
[3-1-1. First paragraph & Second sentence]
논문에서는 uniform distribution으로 input noise를 sampling 했다고 합니다. 그 외 설명은 아래 이미지로 대신할 수 있을 것 같습니다.
여기서 한 가지 질문을 해보도록 하겠습니다.
"앞서, uniform sampling을 했다고 했는데, gaussian sampling을 하는건 안되나요?"
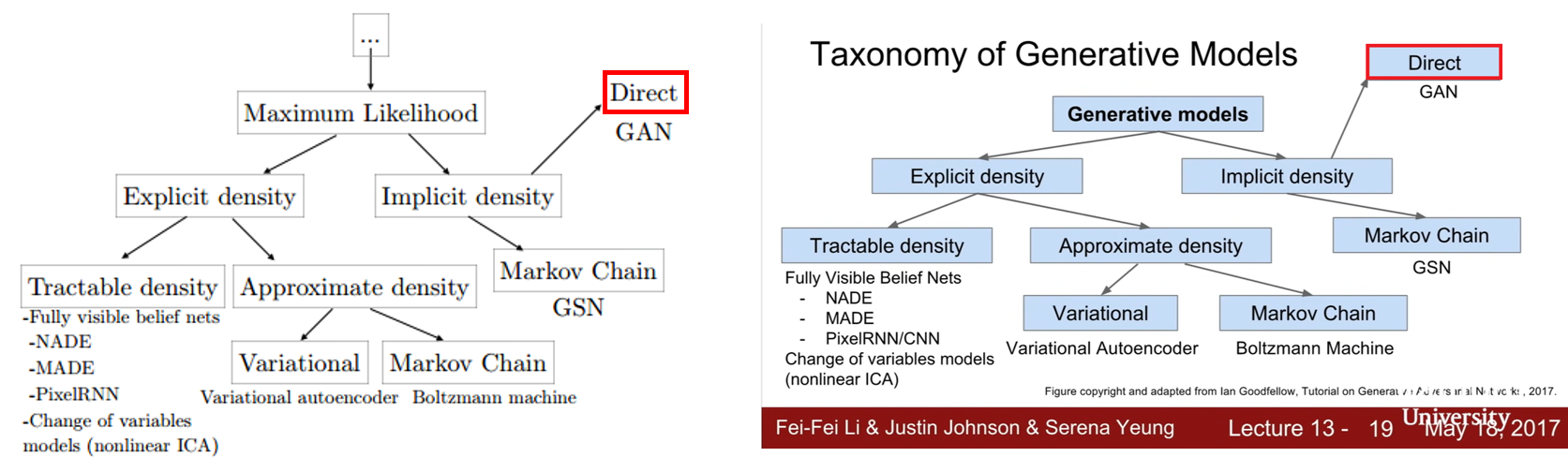
지금부터 이에 대한 답을 간단히 하기 위해 generative model의 taxonomy를 살펴보도록 하겠습니다.
앞서 "[0-3. Estimating generative models]"에서도 언급했듯이 우리는generative model이 이미지 데이터의 확률분포를 maximum likelihood 하기를 원합니다. 하지만, 이미지 데이터를 표현(representation)하는 확률분포를 단 번에 아는 것은 쉬운일이 아니죠. 그래서, 학습을 통해 generative model을 이미지 데이터의 확률분포에 maximum likelihood 하도록 estimation(추정)하게 되는 것입니다. 이렇게 추정을 하는 방식에는 크게 두 가지로 나눌 수 있습니다.
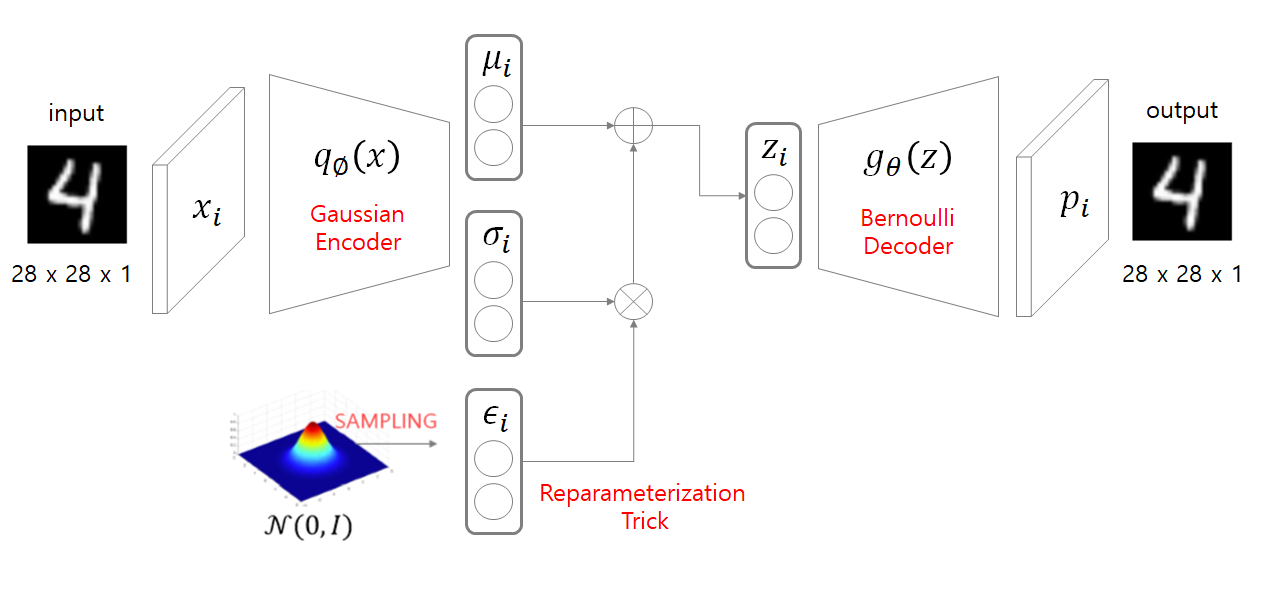
첫 번째 방식은 explicit desnity입니다. 예를 들어, VAE에서는 이미지 데이터 확률분포 \(x\sim~p_{x}(x)\) or \(p_{x\sim~data}(x)\) 를 표현(representaiton)해주기 위해 이상적인 z 값을 sampling하기를 원합니다. 즉, 이상적인 z의 확률분포인\(z\sim~p_{z}(z)\) or \(p_{z\sim~latent}(z)\)를 알아내고 싶은 것이죠. 그래서, VAE 모델은 사전에 명시적(explicit)으로 z의 확률분포인\(p_{z\sim~latent}(z)\)가 특정 probability distribution인 gaussian distribution을 따를 것이라 가정합니다. 특히, VAE에서 초기에 설정한 density estimation 수식은 intractable했기 때문에 이를 variational inference를 이용해 approximation하도록 하여 tractable하게 바꾸게 됩니다. (← 이 부분에 대한 자세한 설명에서는 VAE paper 리뷰하면서 하도록 하겠습니다)
두 번째는 GAN과 같은 implicit density 방식입니다. 앞서 VAE에서 언급한 것 처럼 explicit density(명시된 사전 확률분포)를 이용하는 방식아닌 사전에 어떠한 확률 분포도 명시하지 않습니다. 이것의 의미하는 바는 z의 확률 분포가 특정 확률분포를 따라야 한다는 가정이 없어도 된다는 뜻입니다. 그래서 앞서 input noise에 해당하는 z를 sampling 할 때, z가 uniform distribution을 따른 다는 가정하에 sampling을 해도 되고, gaussian distribution을 따른 다는 가정하에 sampling을 해도됩니다. 즉, GAN 방식에서의 generative model은 (z의 확률분포가 무엇인지와는 별개로) 알아서 이미지 데이터의 확률 분포를 estimation할 수 있게 됩니다.
앞서 VAE에서 intractable하다고 했던 이유는 사전에 명시적(explicit)으로 정의된 z의 probability distribution(=density function) 때문이라고 했는데, GAN에서는 z의 probability distribution에 대한 제약이 없으니 애초에 intractable density funciton을 approximating 할 필요가 없게 되는 것이죠.
"Since an adversarial learning method is adopted, we need not care about approximating intractable density functions."
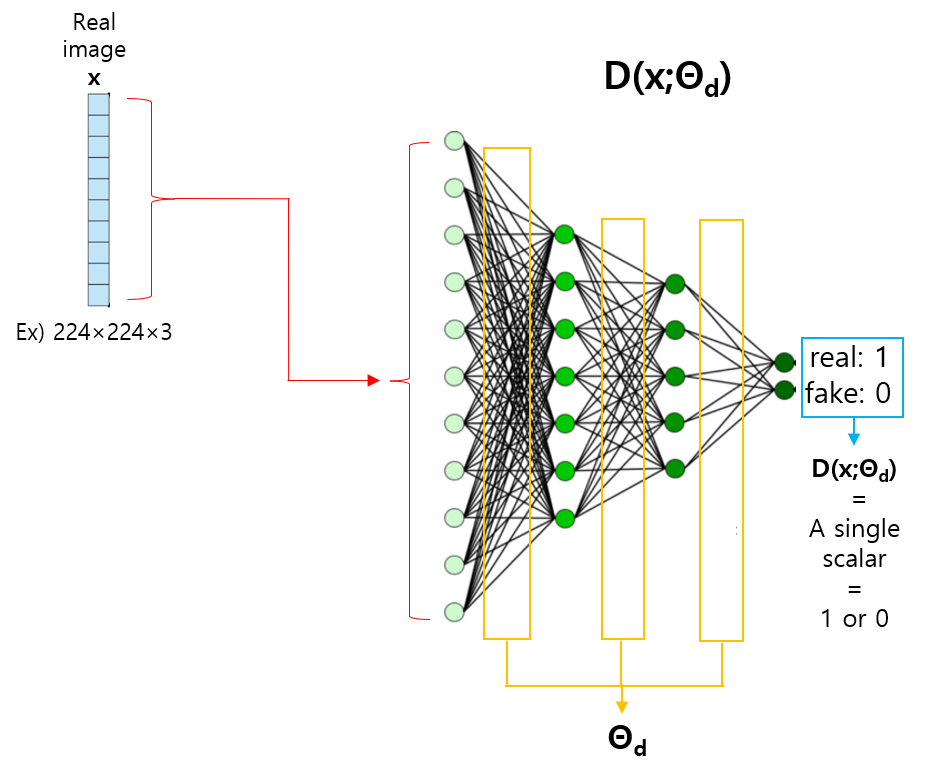
"Discriminator 관점에서는 real data인 x가 들어왔을 때 true=1 이라고 판별해줘야 하고 (→D(x)=1), z로부터 생성된 fake data인 G(z)가 들어왔을 때는 fake=0 이라고 판별해줘야 합니다(→D(G(z))=0)."
Discriminator가 이상적으로 작동하게 되면 D(x)=1, D(G(z))=0이기 때문에 V(D,G) 값은 0이 출력됩니다. 반대로, discriminator가 제 기능을 하지 못 하면 D(x)=0, D(G(x))=1 과 같은 값을 출력합니다. 이 때는, V(D,G) 값이 -∞로 흘러가죠. (D(x)=1, D(G(x))=1), (D(x)=0, D(G(x))=0) 다양한 조합을 생각해 보더라도 V(D,G)의 max 값은 0이고, min 값은 -∞ 인것을 알 수 있죠. 그래서 V(D,G) 함수가 갖는 range는 0 ~ -∞ 가 됩니다.
즉, discriminator 관점에서 봤을 때 V(D,G)를 maximization한다는 것은, 0값에 수렴한다는 뜻과 같습니다.
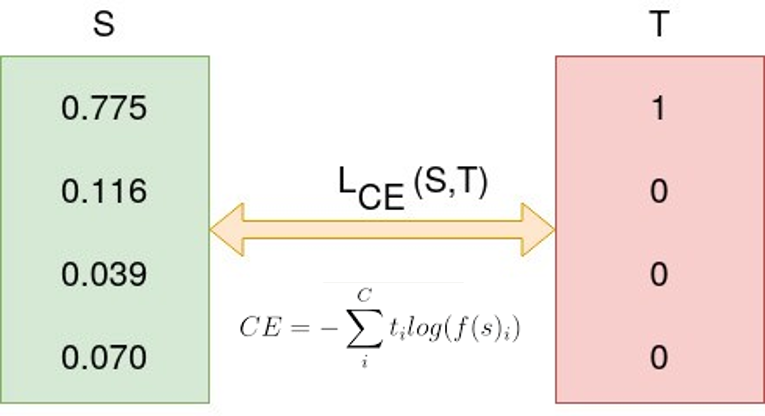
사실 위와 같은 수식은 어떤 새로운 개념이 아니라, binary cross classification (real or fake)을 위해 binary cross entropy 수식을 이용한 것이라고 보시면 됩니다.
[Generator 관점]
Generator 관점에서는 Value function(=V(D,G))이 minimization되어야 합니다.
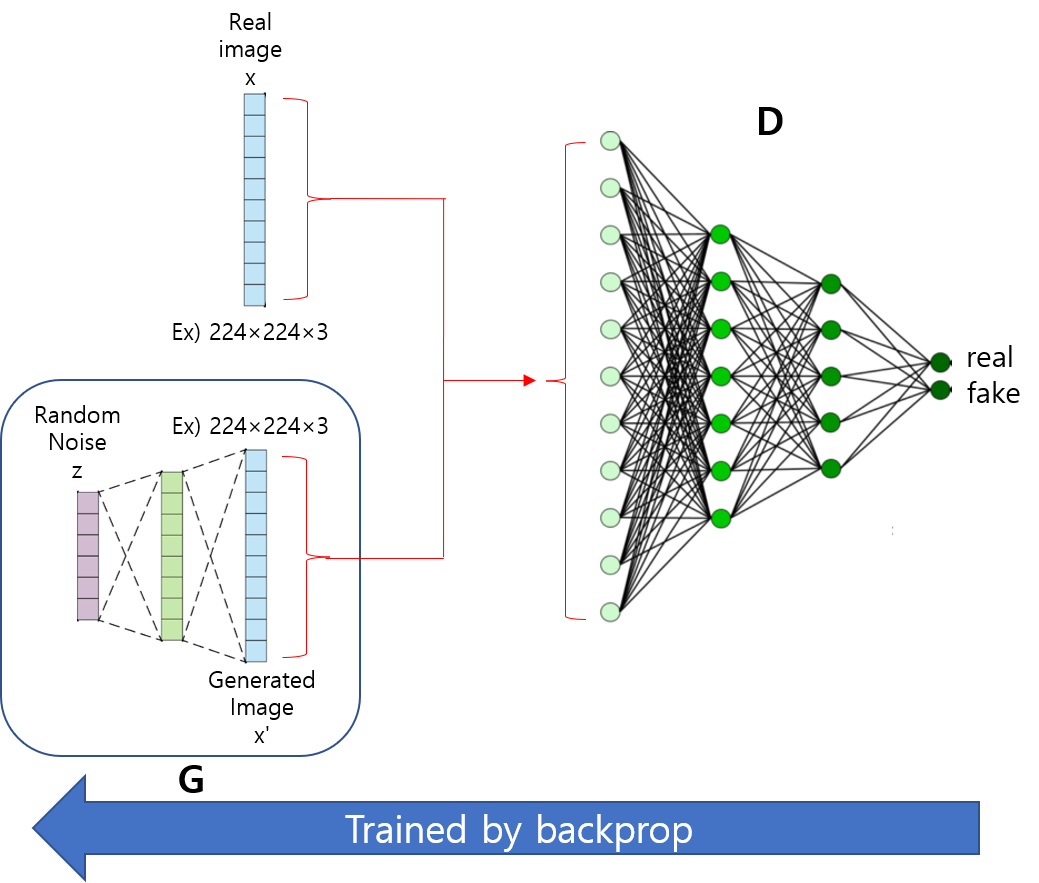
V(D,G)가 두 식으로 구성된다고 봤을 때, generator 관점에서 좌측 식은 고려 대상이 아닙니다. 왜냐하면, generator는 단지 z만을 입력으로 받기 때문이죠. (아래 그림 참고)
Generator는 discriminator를 속여야 하기 때문에 D(G(z))=1 방향으로 학습을 진행하게 됩니다. 이러한 방향으로 학습이 되다보면, 우측식에 의해 Value function(=V(D,G)은 min 값인 -∞ 으로 수렴하게 되기 때문에,V(D,G)를 minimize 하는 방향으로 학습하게 됩니다.
즉 이렇게 Generator를 학습시기키기 위해 Generator와 Discriminator가 상반된 (Adversarial) 목적을 갖는 다는 특성이 있기 때문에 Generative Adversarial Network 라고 부르게 됩니다.
<그림 출처: cs231n. lecture 14. Generative models>
수식에서 평균이 의미하는 바는 간단합니다.
X: Real image dataset, G(z): Fake image dataset
V(D,G)라는 objective function은 결국 GAN이 어떠한 방향으로 학습하길 원하는지를 의미합니다. 만약, E라는 수식이 없으면 V(D,G)를 통해 GAN이 학습 할 때, 하나의 X 데이터, 하나의 G(z) 데이터만을 고려해서 학습하게 됩니다. 이렇게 되면 GAN이 굉장히 불안정하게 학습을 하게 되죠. 왜냐하면 다음에 학습할 X데이터와 G(z) 데이터가 이전 X, G(z) 데이터들과 확연히 다를 수 있기 때문입니다.
이는, 우리가 batch를 크게 잡아주지 않을 때와, 크게 잡아줄 때의 차이점을 생각해보면 더 이해가 쉬울 듯 한데, 아래 링크에서 “3-1.large batch training”&”3-1-1.linear scaling learning rate” 부분을 참고하시면 좋을 것 같습니다.
다시말해, 다수의 X데이터, 다수의 G(z) 데이터를 평균적으로 고려할 수 있게 학습해야 GAN이 하나의 X real data, 하나의 G(z) 데이터가 아닌 X real dataset, G(z) fake dataset모두를 고려하여 학습하게 되죠. 이렇게 모든 dataset을 고려한다는 표현에 평균과 distribution이라는 개념이 동시 내포되어 있는것이라고 생각합니다. (흔히 우리가 알고 있는 mini-batch 관점에서 해석해볼 수 있을 것 같습니다.)
[3-2-1. Second paragraph & First sentence]
다음 section인 4장(="4.Theoretical Results")에서는 GAN이라는 모델을 이론적으로 분석하는 내용들에 대해서 소개합니다.
위의 문장 중 아래 부분에 해당되는 내용을 잠깐 설명드리겠습니다.
"the training criterion allows one to recover the data generating distribution as G and D are given enough capacity, i.e, in the non-parametric limit"
Discriminator가 충분히 학습이 되면, generator를 recover할 수 있다고 표현하는데,이 때 recover라는 뜻은 아래 의미 중 세 번째 의미로 쓰인 것 같습니다. 즉,discriminator를 먼저 학습을 시킴으로써 초기에 어려운 상황에 놓인 generator가 성장할 수 있다는 의미를 내포하고 있는 것 같습니다.
Machine learning book에서는 parametric과 non-parametric의 차이를 아래와 같이 정의하고 있습니다.
"Does the model have a fixed number of parameters, or does the number of parameters grow with the amount of training data? The former is called a parametric model, and the latter is called a nonparametric model."
GAN이라는 모델은 데이터셋의 크기에 따라 generator, discriminator를 구성하는 parameter들의 수가 달라야 합니다. 그렇기 때문에, 신경망을 사용하는 GAN 모델을 non-parametric model로 보는 것 같네요.
개인적으로는 아래 인용구 처럼 Yann LeCun이 페이스북에서 언급했던 내용이 직관적으로 받아드리기 좀 수월했던 것 같습니다.
"In general, a model that you cannot "saturate" as you increase training dataset is non parametirc."
또한, 책에서는 parametric model과 non-parametric model의 장단점을 아래와 같이 정의하고 있습니다.
Parametric model
장점: faster to use
단점: stronger assumptions about the nature of the data distribution → 예를 들어, parameter 수가 고정 된 어떤 모델에 사전 확률 분포를 미리 설정하여 generative model을 만든다는건, data distribution이 설정된 사전 확률 분포를 따를 것이라고 가정하는 것 → 하지만, 현실 세계에서 data distribution이 앞서 설정한 강력한 가정(="사전확률 분포를 따를 것이다")을 따르는 경우가 많지 않음
Non-parametric model
장점: flexible → 굳이 사전확률 분포같은 것을 안정해도 됨
단점: often computationally intractable for large datasets. → 큰 데이터셋에서는 많은 parameter들이 필요하므로 종종 계산 시스템 관점에서 intractable할 수 있음
"the training criterion allows one to recover the data generating distribution as G and D are given enough capacity, i.e, in the non-parametric limit"
논문의 문장을 다시 한 번 살펴보겠습니다.
Non-parametric (model의) limit(한계)은 computaionally intractable 문제를 늘 갖고 있습니다. 그래서 이러한 computationally intractable을 다룰 수 있는 enough capacity가 주어진다면, GAN training이 잘 될 수 있을거라 보고 있습니다.
(사실 앞서 GAN이 generative model에서 겪는 intractable 한 것을 해결했다고 하지만, 엄밀히 말해 "enough capacity"에 따라서 다시 intractable해질 수 있는 듯 합니다. )
(↓↓↓machine learning book에서 언급하는 parametric VS non-parametric models; "1.4.1 parametric vs non-parametric models" 참고↓↓↓)
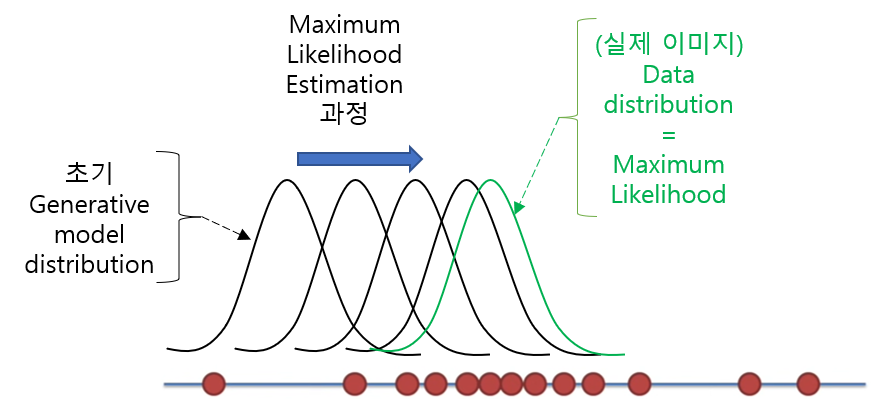
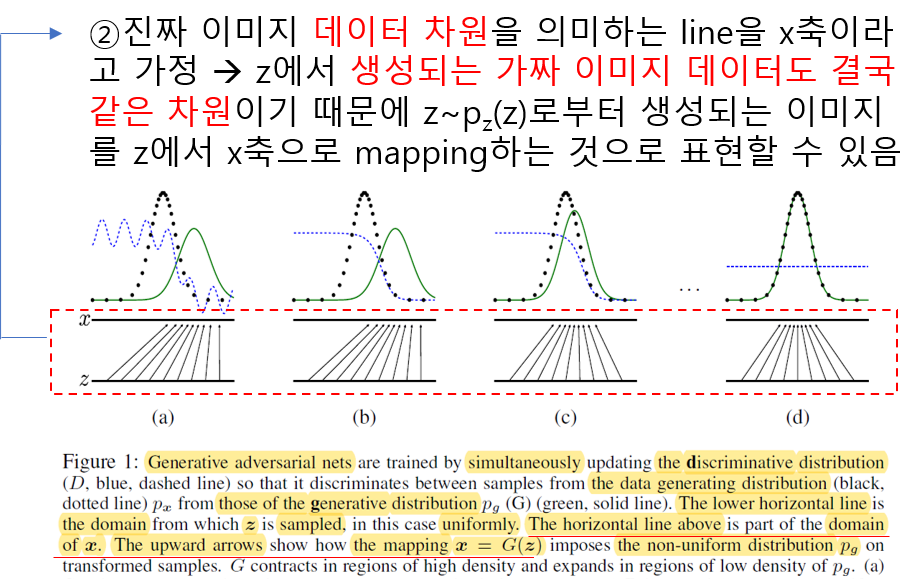
\(D\): Dashed blue line = discriminative distribution
\(p_{x}\): Dotted block line = data distribution
\(p_{g}(G)\): Solid green line = generative distribution
이미지를 표현할 수 있는 저차원 latent space를 z차원으로 간주하고, z차원에서 sampling할 때 사전확률 분포를 uniform distribution \(z\sim~p_{z}(z)\)으로 설정하면 아래와 같이 일정한 간격으로 sampling됩니다. 추출된 각각의 sample들로부터 generated image가 생성 됩니다.
(실제로 z축의 차원과 x축의 차원은 다르기 때문에 1차원 개념으로 표현하는건 엄밀히 말하자면 잘 못 된 이지만, 이해를 돕기 위해 이렇게 한 듯 합니다. 그래서, “a less formal, more pedagogical explanation of the approach”라는 표현을 쓴게 아닌가 싶기도 하네요..)
위에서 설명한 내용을 아래와 그림과 같이 표현 할 수 있을 것 같습니다.
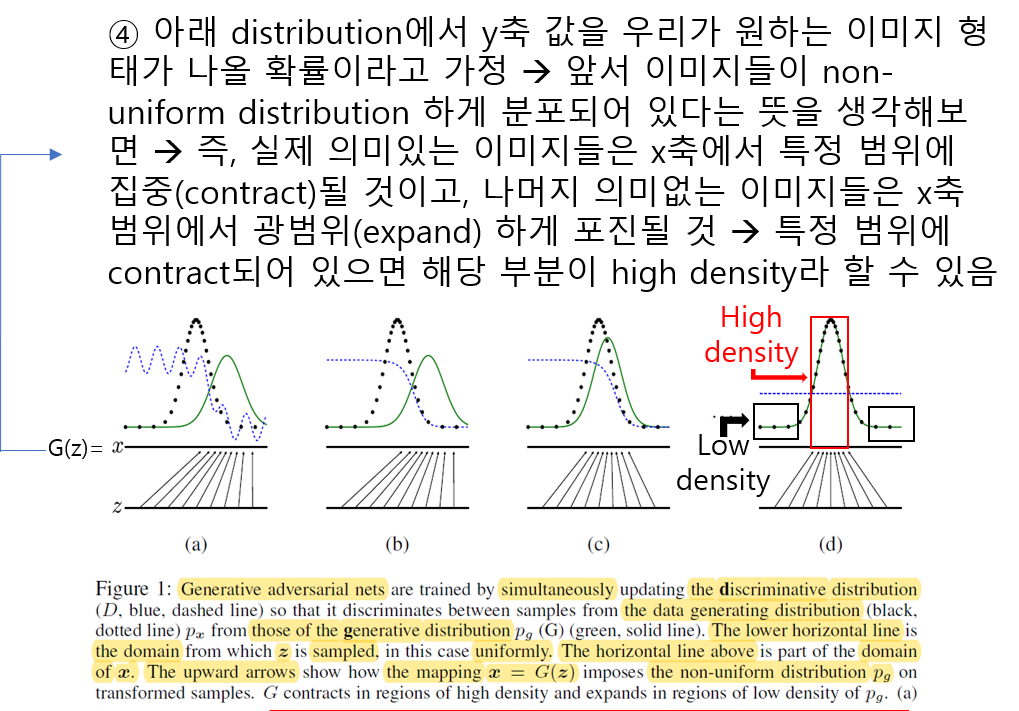
위 ③에서는 이미지 같은 데이터가 non-uniform distribution으로 표현(representation)될 수 있음을 언급하고 있습니다. 여기서의 포인트는 이미지 데이터의 차원에서 이미지 데이터들의 분포를 표현할 때는 uniform distribution으로 표현하기 어렵다(or 표현할 수 없다)라는 사실 입니다. 그러므로, 정규분포가 아닌 다른 non-uniform distribution으로 볼 수 있습니다.
\(D\): Dashed blue line = discriminative distribution
\(p_{x}\): Dotted block line = data distribution
\(p_{g}(G)\): Solid green line = generative distribution
(a): data distribution과 generative distribution이 어느 정도 유사한 상태 (pgis similar to pdata) → D가 아직까지는 잘 구분해주긴 하나, 조금 불안정한 상태
(b): D가 잘 학습이 된 상태 → 예를 들어, (b) 그림상 해당 지점에서 왼쪽 값이면 real data로 구분, 오른쪽 값이면 fake data로 구분 → D분포(관점)에서 x축 상의 값이 왼쪽일 수록 fake이미지라고 판단할 확률(y값)이 높아짐 → D*관련 식은 뒤에서 설명
(c): G를 업데이트 한 후, 학습이 잘 된 D분포의 gradient가 G(z)가 좀 더 의미있는 이미지를 생성할 수 있게 유도 함→ 이 부분은 문장에 어떤 숨어 있는 뜻이 있는지 잘 이해를 못했는데, 그냥 학습이 잘 된 D로 인해 \(p_{g}(G)\)분포가 업데이트 되면서 점점 \(p_{x}\)분포에 가까워진다는 것으로 이해함
(d): G와 D가 충분히 학습되면 결국, G의 성능이 매우 높아져 D가 real data와 fake data를 전혀구분하지 못함 → 1/2 uniform distribution이 형성 됨
[3-2-3. Second paragraph & The rest]
[3-3-1. Third paragraph & First, Second, Third, Fourth sentence]
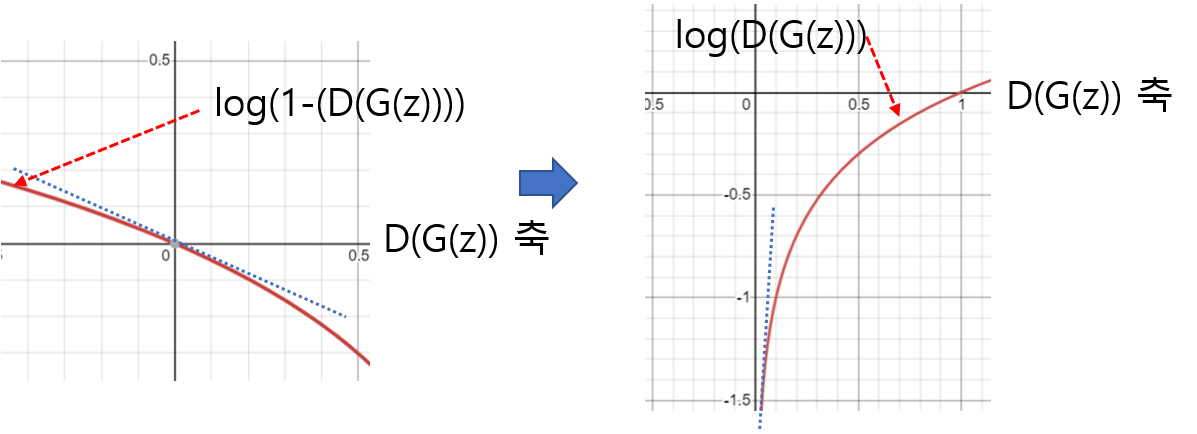
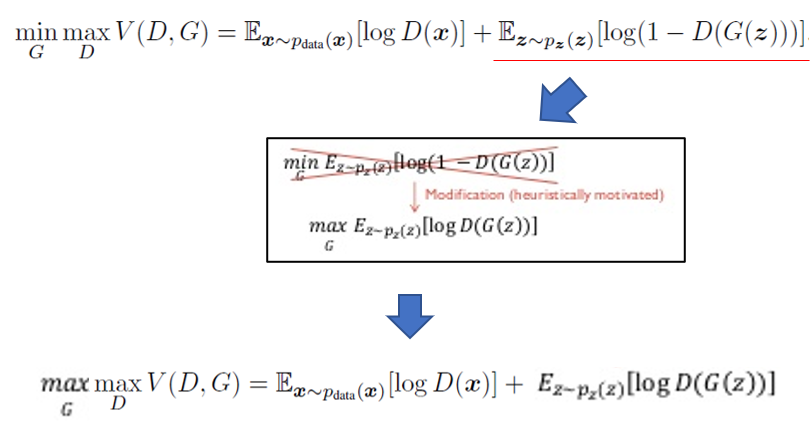
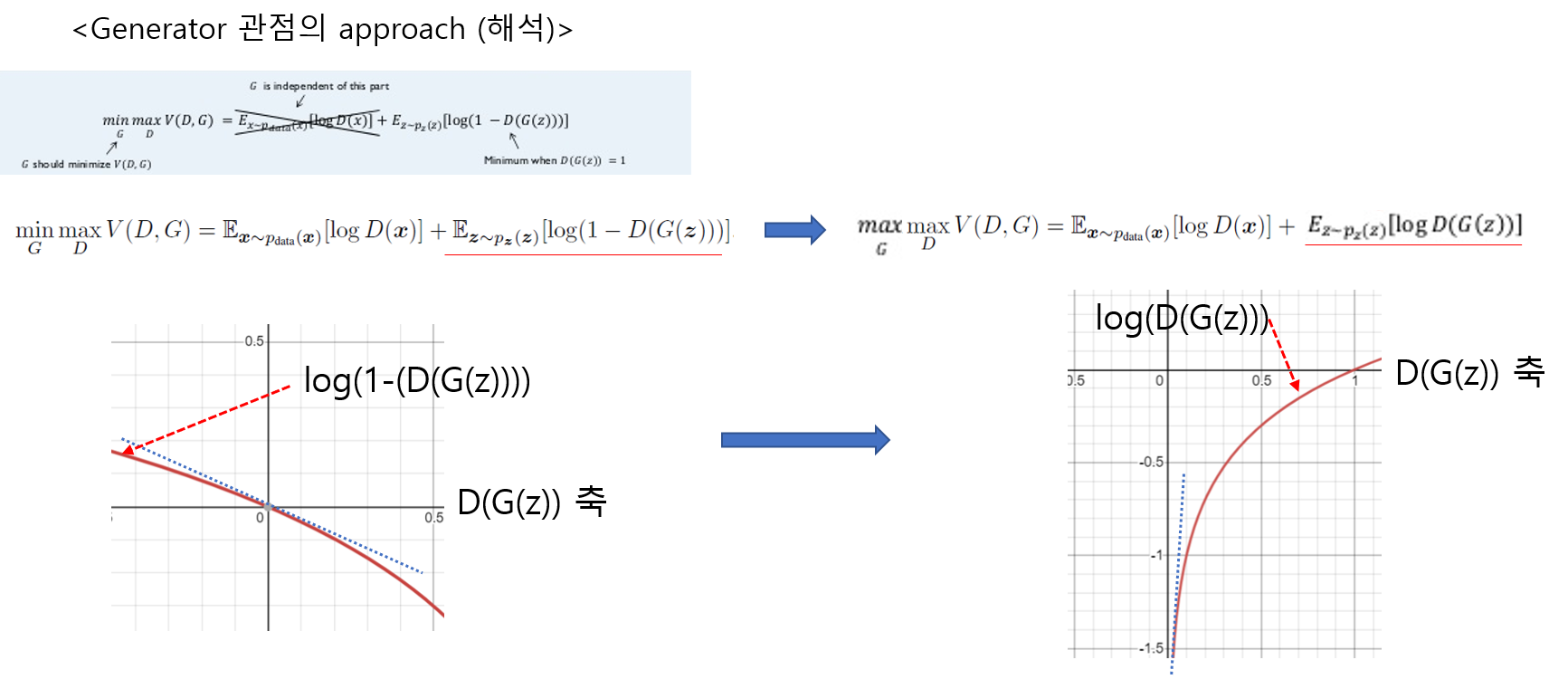
초기에는 D(G(z))=0 이나옵니다. 왜냐하면 초반에는 “G:Generative model”이 정교하지 않은 fake 이미지를 생성하기 때문에, discriminator가 G(z)로 생성된 이미지를 fake라고 잘 판별(D(G(z))=0)하게 됩니다. 그런데, log(1-(D(G(z)))) 꼴의 함수에서 초기 D(G(z)) 값이 0이 나온다면 gradient 값 자체가 saturation 된 상태이기 때문에, 업데이트가 더딜 수 있습니다.
그래서, G를 학습시키는 관점을 log(1-D(G(z)))을 minimization 하는 방향이 아니라, log(D(G(z)))를 maximization 하는 방향으로 학습시키게 하기 위해 term을 변경해 줍니다.이렇게 term 변경이 가능한 이유는 아래와 같습니다.
"log(1-D(G(z)))를 minimization 한다 = D(G(z))=1 을뱉어내도록G를 학습시키기만 하면된다=log(D(G(z)))를 maximization 하게 학습시킨다 = D(G(z)))=1을 뱉어내도록G가 학습된다."
위와 같은 이유로 인해 실제 학습에 쓰이는 Value function (=V(D,G))는 아래와 같이 변경됩니다.
[3-3-2. Third paragraph & The last sentence]
위의 문장을 이해하기 위한 핵심 키워드는 "the same fixed point of the dynamics" 입니다. 이 키워드에 대한 개념을 세 가지 부분으로 나누어 차례대로 설명하겠습니다.
Numerical Analysis
Fixed point iteration (with 경사하강법(Steepest Gradient Descent))
Dynamics
[Numerical Analysis]
수치해석학(numerical analysis)은 해석학 문제에서 수치적인 근삿값을 구하는 알고리즘을 연구하는 학문입니다. 현대의 수치해석 역시 정확한 해를 구하지는 않습니다. 왜냐하면 현실에서 많은 문제들을 접했을 때, 실제로 정확한 해를 구하는 것이 불가능한 경우가 많기 때문입니다. 그대신 대다수의 경우, 수치해석을 이용해 합리적인 수준의 오차를 갖는 근사값을 구하는 것에 집중합니다.
그래서, 수치해석에서 optimization 이라는 용어가 쓰입니다. 최적화(optimization)라는 뜻 자체가 “완벽”하지 않다는 것을 가정하에 어느 정도의 오류를 수용하면서 최적의 값을 얻어내는 과정을 의미합니다.
수치해석 응용분야 예시
미분방정식: 수치적으로 미분 방정식을 푼다는 것은 주어진 미분 방정식의 근사해를 찾는 것 → Ex) Euler’s Methods
확률미분방정식과Markov Chain
선형대수
최신 한양대 응용수학과 커리큘럼을 보면 수치해석을 위한 선수과목이 무엇인지 알 수 있습니다. (최적화이론에 convex optimization 같은게 들어있는 것 같은데..., 평소에 인공지능 하면서 부족하다거나 배우고 싶어했던 수학과목들이 체계적으로 잘 정리되어 있다는 느낌을 받았습니다)
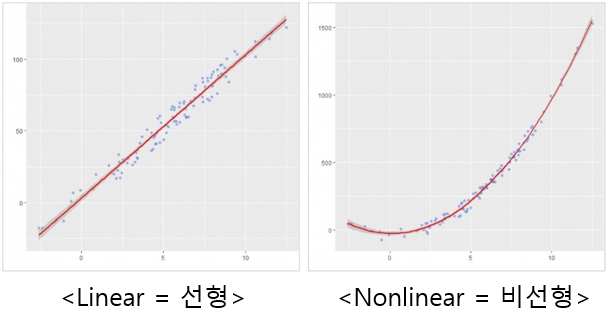
"딥러닝을 학습한다는 concept을 non-linear (loss) equation을 푸는(solving; solution) concept으로 이해할 수 있습니다."
이 때, x를 입력 데이터라고 하면 non-linear (loss) equation = f(x) = 0 의 값을 찾는 것이 목적이 됩니다. 하지만, 현실에서 loss=0 값을 찾는건 불가능에 가깝기 때문에 0에 가까운 loss 값을 찾기 위해 반복(iteration)하여 학습을 하게 되는 것이죠.
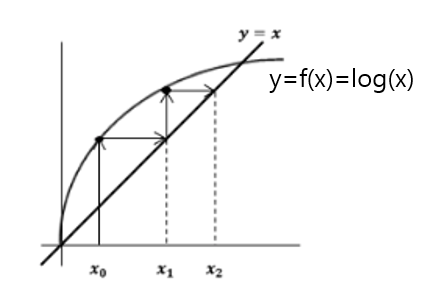
"이렇게 반복적인 방법으로 0의 (허용오차 범위 내에 있는) 근사값을 찾는 방법 중에 하나가 fixed-point iteration이라는 방법입니다."
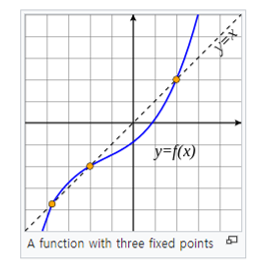
Fixed-point iteration을 알아보기에 앞서 fixed-point의 수학적 정의가 무엇인지 살펴보겠습니다.
"In mathematics, a fixed point (sometimes shortened to fixpoint, also known as an invariant point) of a function is an element of the function's domain that is mapped to itself by the function."
Fixed point iteration에 대해 알아봤으니 이것이 딥러닝에서 사용되는 경사하강법과 어떠한 연관이 있는지 알아보겠습니다.
먼저, 아래 내용은 위스콘신 대학 computer science 부서의 Stephen J. Wright 교수의 수업교재 중 일부를 발췌한 내용입니다.
우리가 deep learning을 통해 배운 경사하강법 (Steepest Descent method) 방식은 Fixed point iteration 으로 간주할 수 있습니다. 앞서 배운 fixed point iteration과 조금 다른 점은 아래와 같습니다.
함수는 convex 조건을 만족해야 최적해를 구할 수 있다.
기존 f(x)=0 방식이 아닌 (앞선 설명에서는 g(x)=0로 표기했습니다), gradient 관점에서 ∇f(x)=0 의 최적해를 구하기 위해 iteration 방식을 적용한다.
(아래 x*는 실제 해라고 가정하는 x의 근사값(=최적값)으로 볼 수 있습니다)
다시 논문으로 돌아와 해당 문장을 살펴보겠습니다.
앞서 설명한 내용을 요약하면 generator 부분의 초기 학습 시, log(1-D(G(z)))의 gradient값이 굉장히 낮기 때문에 saturation되는 현상을 보여줍니다. 그래서 G 입장에서는 log(1-D(G(z))의 gradient 값으로 학습해야 하는데, 충분한 gradient가 backpropagation되지 않기 때문에 초기 학습에 어려움을 느낍니다. 그래서, 아래 그림과 같이 log(D(G(z)))와 같은 형태로 변경시켜주었죠. (←이렇게 변경이 가능한 이유는 "3-3-1. Third paragraph & First, Second, Third, Fourth sentence"에서 설명드렸습니다)
문맥상에서 보면 log(D(G(z))로 변경시켜 주기 전에는 "the same fixed point of the dynamics of G and D" 가 아니었다고 생각하는데, 구체적으로 dynamcis와 same fixed point간의 관계를 파악하진 못했습니다. 여기서 말하는 dynamics라는 것도 결국에는 dynamic optimization(or programming) 관점에서 해석할 수 있고, "chain rule + dynamic programming = neural network"이기 때문에 여기서 언급하는 dynamics가 gradient를 내포하고 있는 듯 합니다. 그래서, log(D(G(z))로 변경되면 같은 gradient가 전파가 되고, 이것이 the same fixed point"와 연관이 있을 것 같긴한데, 아직까지 정확한 연결고리를 찾진 못했네요. 혹시 아시는 분 있으면 알려주세요!
지금까지 GAN에 대한 구조적인 부분에 대해서 설명해보았습니다.
설명이 잘 못 됐다고 생각되는 부분은 언제든 댓글을 남겨주세요!
다음에는 GAN이라는 모델이 numerical, iterative 방식으로 최적해(optimum)을 구할 수 있는지 증명하는 "4.Theoretical Results"에 대해설명하도록 하겠습니다.
딥러닝 뿐만 아니라 컴퓨터를 통해 연구를 할 때, 자신이 설계한 모델이 컴퓨터 상에 돌아갈 수 있는지 없는지를 알아내는 것은 굉장히 중요한 문제입니다.
"왜냐하면, 어렵게 어렵게 모델을 설계했는데, 해당 모델이 계산 불가능하다면 컴퓨터 상에서 쓸 수 없기 때문이죠."
컴퓨터 과학에서는 보통 계산 불가능하다는 것을 intractable하다고 표현합니다.
"그렇다면, 계산 불가능하다는 것을 어떻게 정의할 수 있을까요? "
지금부터 위의 질문에 대한 답을 찾아가면서 intractable에 대한 개념을 이해해보도록 하겠습니다.
※Note. 참고로 intractable computation을 설명하기 위해서는 필연적으로 수학 역사를 다루어야 합니다. 하지만, 제가 수학과가 아니기 때문에 잘 못 된 설명이 있을 수 있으니 발견 시 꼭 댓글 달아주시면 감사하겠습니다!!!!!
1.무한이라는 개념의 등장
식탁에 있는 오렌지 하나와 냉장고에 있는 오렌지 하나를 가져와 제 접시에 놓았습니다. 그렇다면, 제 접시에는 두 개의 오렌지가 있을 겁니다. 이것을 수식으로 표현하면 아래와 같죠.
1 + 1 = 2
오렌지라는 물체를 하나의 단위(unit) 즉 수(number)로 간주하기 때문에 위와 같은 식이 성립하죠. 이것은 우리 눈으로 직관적으로 확인 할 수 있기 때문에 매우 자명하다고 할 수 있습니다.
"그런데, 여러분은 무한이라는 개념을 직관적으로 설명하실 수 있으신가요?"
"우리 주변에 무한이라는 개념을 관찰할 수 있는 것이 무엇이 있죠?"
처음에 이런 질문들을 듣는다면 굉장히 혼란스러우실 겁니다. 어떤 분들은 무한대(∞)를 세상에서 가장 큰 수라고 이야기 하기도 하지요. 그런데, 수라는 관점에서 무한대(∞)를 해석하면 "1+무한대>무한대"가 되어야 하는데, 수학적 정의에 따르면 "1+무한대=무한대" 이죠. 그래서, 무한대(∞)라는 것을 수라는 관점으로 제한하기에는 무리가 있어보입니다.
"그렇다면, 무한대라는 개념을 어떤 관점에서 이해하면 되는 것일까요?"
먼저, 아래 영상을 살펴보도록 하겠습니다!
"위 영상에서 살펴봤듯이 무한이라는 개념은 "과정(process)"이라는 관점에서 이해할 수 있습니다."
아래 영상에서 아르키메데스(Archimedes; BC.287)는 삼각형의 변의 무한이 작게 만들어가는 과정을 통해 원의 둘레를 정의하기도 했죠. 이때, 한 변의 길이가 무한히 작게 간다는 것은 0에 가까워 지는 것과 같은데, 이러한 과정을 설명하기 위해 무한소(infinitesimal)라는 개념이 등장하게 됩니다. (반대로, 무한대는 무한히 커지는 과정을 의미하겠죠?)
이 후, 아이작 뉴턴(Isaac Newton; 1642), 라이프니츠(Gottfried Wilhelm Leibniz; 1646) 는 무한소(infinitesimal)라는 개념을 이용해 미적분학을 발전시키게 됩니다.
하지만, 당시 미적분학은 체계가 갖춰지지 않은 상태였기 때문에 베르나도 볼차노(Bernard Placidus Johann Nepomuk Bolzano; 1781), 오귀스탱 루이 코시(Augustin Louis Cauchy; 1789), 카를 바이어슈트라스(Karl Theodor Wilhelm Weierstraß; 1815) 등의 수학자들이 엡실론-델타 논법을 발명했고, 이를 통해 극한, 미분, 적분 등의 개념들을 엄밀화하기 시작합니다. 예를 들어, 극한이라는 개념은 "x가 한없이 커질 때, f(x)가 한 없이 어떤 값에 가까워지면 그 값을 극한 값"이라고 하는데, 이때 "한없이"라는 개념과 "가까워진다"라는 개념을 공리(axiom), 정리(definition)를 이용해 수학적으로 엄밀하게 정의한 것이죠. 그리고, 이러한 노력들을 통해초기 해석학(analysis)이 탄생합니다.
(↓↓↓코시의 엡실론-델타 논법 설명↓↓↓)
(↓↓↓ 해석학 탄생의 역사↓↓↓)
또한, 칸토어(Georg Ferdinand Ludwig Philipp Cantor; 1845)는 무한이라는 개념을 집합의 관점에서 정리하였고, 데데킨트(Julius Wilhelm Richard Dedekind; 1831)는 실수체계를 엄밀하게 정리함으로써 무한이라는 개념을 체계화시켰습니다. 결국 해석학을 통해 대수학, 기하학에 대한 개념을 엄밀하게 하려는 시도까지 하게 되죠.
그림 출처: https://dm19sky.tistory.com/59
이렇게 무한이나 극한에 대한 개념을 체계화 함으로써 미적분학, 해석학이 발전해갔습니다. 하지만, 이러한 분야가 발전하는 것을 마음에 들지 않았던 수학자도 있었죠. "라위천 에흐베르튀스 얀 브라우어르(Luitzen Egbertus Jan Brouwer: 1881)"는 18~19세기 미적분학, 해석학의 발전이 기존 수학에 많은 문제점을 야기했다고 주장하는데 그 이유는 아래와 같습니다.
"수학이라는 것은 철저하게 공리(axiom)과 정리(definition)에 의해 견고하게 구축되어야 하는 분야인데, 무한이나 극한 같이 관찰하기 어려운 개념들을 추상화 되면서 이러한 체계들이 무너지고 있다"
라위천 에흐베르튀스 얀 브라우어르
예를 들어, 이 당시 집합론은 모든 수학의 근간이었는데, 러셀(Bertrand Arthur William Russell; 1872)이 집합론에 모순이 있다고 주장합니다. (러셀의 역설(Bertrand Russel's paradox)이라고 알려져있죠)
러셀
"이렇게 수학의 체계가 흔들리려고 할 때즘 독일의 수학자 힐베르트(David Hilbert; 1862)가 등장합니다."
2.힐베르트와 괴델의 불완전성 정리
"힐베르트(David Hilbert;1862)는 공리계를 잘 설계할 수 있다면 '러셀의 역설' 이 해결 될 수 있다고 주장했습니다."
즉, 당시 수학 개념들은 충분히 체계화 시킬 수 있다고 본 것이죠.
힐베르트
힐베르트는 1928년 볼로냐 세계 수학자대회에서 한 가지 문제를 던집니다.
"현재 존재하는 모든 수학 문제들을 풀 수 있는 일반적인 알고리즘(기계)이 존재하는가?"
이러한 질문을 던진 이유는 "모든 수학 문제들을 풀 수 있는 일반적인 알고리즘 또는 기계가 있다면 모든 수학 체계를 형식화 할 수 있다는 것을 의미"했기 때문입니다.
만약 모든 수학 문제들을 풀 수 있는 일반적인 알고리즘 또는 기계가 등장한다면 수학자들이 찾아내는 모든 수학 공식들을 계산 할 수 있을 것이고, 그렇게 되면 수학자들은 모두 실직할 것이라고 봤죠.
또한, 앞서 언급한 알고리즘(or 기계)이 등장하면 수학의 '무모순성', '완전성', 그리고 '결정가능성'을 증명할 수 있다고 주장합니다.
미국의 수학자 괴델(Kurt Gödel; 1906)은 힐베르트가 궁금해 했던 "모든 수학 문제들을 풀 수 있는 일반적인 알고리즘"은 없다고 주장합니다. 아무리 공리 체계가 잘 설계되더라도 러셀의 역설은 피할 수 없다고 주장하죠. 자신의 주장을 증명하기 위해 "괴델의 불완전성 정리(Gödel's incompleteness theorems)"를 발표합니다.
괴델
또한 괴델의 주장을 뒷 받침한 수학자가 있었습니다. 바로, Alan Turing인데요.
"지금부터 Alan Turing에 대해 설명하면서 좀 더 intractable이라는 개념에 다가가도록 하겠습니다."
3.Alan Turing 그리고 Halting problem
Alan Turing(1921)은 1934년 케임브리지 수학과를 졸업하고, 학업을 더 연장하게 됩니다.
"1935년 Max Newman 교수의 수업 중 "괴델의 불완정성 법칙"에 대한 이야기를 듣게 됩니다."
그리고 힐베르트가 말한 "모든 수학문제를 풀 수 있는 일반적인 기계"에 대해서 관심을 갖게 됩니다. 결국, 1936년 "On Computable Numbers, with an Application to the Entscheidungsproblem" 이라는 논문에서 앞서 언급한 기계를 고안하게 되죠. 그리고, 오늘날 이 기계를 Turing Machine이라 부릅니다. (해당 논문에서는 universal mahince이라고 표현된 것을 오늘날 Turing Machine이라고 부르게 된 것이죠)
힐베르트가 말한 "모든 수학문제를 풀 수 있는 일반적인 기계"는 바꿔말해 "모든 연산(=계산; computation)이 가능한 가상의 기계"라는 것과 같습니다. 왜냐하면 결국 "수학문제를 푼다는 것"은 "계산을 한다는 것"과 같으니까요.
"그렇다면, 이러한 Turing Machine을 이용해 어떻게 괴델의 주장을 뒷받침 했을까요?"
이에 대한 답을 하기 위해서 Turing Machine에 대해서 잠깐 설명해보도록 하겠습니다.
[Turing machine 작동원리]
Turing machine 작동원리는 아래 영상들을 참고해주세요!
[Hibert's Decision Problem & Halting Problem]
힐베르트는 "'모든 수학 문제들을 풀 수 있는 일반적인 알고리즘 또는 기계'가 존재하면 '모든 수학적 문제에 대해서 그 문제가 참인지 거짓인지를 확실하게 결정해 줄 명확한 방법이 존재할 수 있는지'" 궁금해했습니다.
이러한 질문을 "힐베르트의 결정 문제(Hilbert's Decision Problem)"라고 합니다. 이 문제에 답을 하기 위해서는 수학 문제가 참인지 거짓인지 증명이 되어야 합니다. 앞서 Turing 머신은 모든 연산을 할 수 있기다고 배웠습니다. 그렇다면, 모든 수학적 문제를 Turing 머신에 넣었을 때 참인지 거짓인지 판명하면 수학의 '결정가능성'을 입증할 수 있게 되는 것이죠.
"그런데 반대로, 수학의 '결정가능성'을 반증하려면 어떻게 해야할까요?"
Turing machine이 수학 문제를 입력 받았을 때, 참 또는 거짓과 같은 답을 내놓지 않는다면 '결정가능성'을 반증할 수 있을겁니다. 참 또는 거짓과 같은 답을 내놓지 않는다는건 Turing Machine이 어떤 결론에 도달하지 않고, 즉 멈추지 않고 계속해서 돌아간다는 뜻이죠. 그래서 Turing은 힐베르트의 결정 문제(Hilbert's Decision Problem)를 "(수학 계산이 가능한) Turing machine에 데이터를 입력했을 때, 해당 machine이 궁극적으로 정지하는지 정지하지 않는지"에 대한 문제인 Halting Problem으로 바꿔 생각합니다. 만약, 정지하지 않으면 수학의 '결정가능성'을 반증하게 되는 것이죠.
[Turing Machine과 오늘날 컴퓨터]
Turing Machine은 계산이 가능한 시스템을 갖고 있습니다. 폰 노이만(John von Neumann; 1903)은 이러한 Turing machine을 확장하여 폰 노이만 구조를 설계하죠. 그리고, 오늘날 폰 노이만 구조를 오늘날 컴퓨터의 prototype으로 보고 있습니다.
"바꿔 말해, 모든 컴퓨터는 Turing Machine을 기반으로 하고 있다고 할 수 있습니다."
예를 들어서, 슈퍼컴퓨터가 할 수 있는 계산은 일반 컴퓨터에서 할 수 있습니다. 왜냐하면 모두 CPU, GPU 같은 장치들로 연산이되기 때문이죠. 단지 일반 컴퓨터에서는 시간이 더 오래걸릴 뿐입니다. 다시말해, 계산 능력자체는 동일한 것이라 할 수 있습니다. 이와 같은 맥락으로, 일반 컴퓨터의 계산 능력은 Turing machine과 동일하다고 할 수 있는 것이죠.
4. Intractable & Tractable (Feat. NP & P 문제)
Turing machine은 다른 말로 "결정론적 튜링 기계(Deterministic Turing Machine: DTM)"라고도 합니다.
결정론적이라는 표현이 붙은 이유는 Turing Machine 작동원리 영상에서 언급됐듯이 "테이프의 symbol이 s이고, 현재 상태가 q라면 알고리즘에 의해 다음 명령어가 유일하게 결정"되기 때문이죠.
Deterministic Turing Machine은 현대 모든 계산 기능을 갖춘 기계들 (ex: 컴퓨터, 스마트폰, 슈퍼 컴퓨터 등)을 대표합니다. 그래서, "어떤 문제를 컴퓨터를 사용해 다항시간(polynomial time) 내에 답을 구할 수 있냐?"는 질문을 "어떤 문제를 Deterministic Turing Machine을 사용해 다항시간내에 답을 구할 수 있냐?"라는 문제로 치환할 수 있는 것이죠.
"어떤 문제를 Deterministic Turing Machine을 사용해 다항시간내에 답을 구할 수 있냐?"
이 치환된 질문은 굉장히 중요합니다. 왜냐하면, 이 질문을 기준으로 intractable computation(problem)인지 tractable computation(problem)인지 구분하기 때문이죠. Deterministic Turing Machine을 이용하여 어떤 문제를 polynomial time(다항시간) 안에 풀 수 있으면 "해당 문제는 polynomial time complexity을 갖는다"라고 말할 수 있게되고, 해당 문제를 tractable problem으로 간주하게 됩니다. 반대로, polynomial time 안에 풀 수 없으면 intractable problem으로 간주하게 되죠.
[P문제]
컴퓨터 과학에서는 tractable computation(problem)을 Polynomial의 P를 따서 P문제라고 정의합니다. 다시 말해, polynomial time complexity를 가지면, tractable(=풀만한; feasible) 문제라고 여기며, 이러한 문제들의 집한을 P라고 나타내는 것이죠.
현실에서는 어떤 문제를 풀 때 이용되는 알고리즘이 (차수가) 2차 이하의 time complexity를 가진다면 유효한 알고리즘이라고 합니다. 이러한 알고리즘으로 풀리는 문제들을 P 문제 또는 tractable problem이라고 하죠. 예를 들어, shortest path 같은 최단거리를 다루는 다양한 알고리즘은 이미 P문제, 즉 tractable problem이라는 것이 증명되었죠.
그림 출처: https://www.joyk.com/dig/detail/1608665582509127
[NP문제]
반대로 None-Polynomial time complexity를 가진다면 intractable computation(problem)으로 여기며, 이러한 문제들의 집합을 NP라 합니다.
현실적에서는 3차 이상의 time complexity를 갖고 있을 경우 NP로 정의합니다.
"정리하자면, P, NP 문제는 Turing machine과 같은 계산 시스템 관점에서 풀기 어려운 (=intractable; NP) 문제인지 그래도 현실적으로 풀기 수월한 (=tractable; P) 문제인지에 따라 결정되는 것입니다."
5. 왜 P, NP 문제를 구분하는 것이 중요한가요?
현재 딥러닝을 연구하는 사람들에게 컴퓨터는 빼놓을 수 없는 장비입니다. 설계한 딥러닝 모델을 컴퓨터에서 학습시키고 그 결과를 도출해야하기 때문이죠. 새로운 딥러닝 모델을 설계하기 위해서는 기존에 쓰이지 않은 개념들을 접목시켜야 합니다.
"그런데, 이러한 새로운 모델을 설계하고 연구 할 때 중요한 것이 "기존에 쓰이지 않은 개념"을 접목시킨 새로운 딥러닝 모델이 계산 가능해야 한다는 것입니다."
만약, 새로 설계된 새로운 딥러닝 모델이 계산 불가능하다면, 해당 모델을 학습시키는건 현실적으로 불가능하다고 볼 수 있겠죠?
예를 들어서, 초기에 딥러닝이 막 나왔을 때에는 mutual information이라는 개념이 접목되지 않은 상태였습니다. 그렇기 때문에 연구자들은 mutual information을 접목시켜 새로운 딥러닝 모델을 만들려고 했죠. 하지만, mutual information이라는 개념을 딥러닝에 적용하여 수식화해보니 intractable computation(problem) 인 것으로 판명됐습니다. (←이 부분에 대한 자세한 설명은 Self-Supervised Learning 카테고리에서 글을 작성한 후 링크를 걸어두도록 하겠습니다)
그렇다면, 연구자들은 mutual information이라는 개념을 적용하는 것을 포기해야 할까요?
컴퓨터 분야(or 딥러닝 분야)에서는 이와같이 intractable computation 문제를 tractable computation하게 바꿔주는 mathematical trick이 사용되기도 합니다. 예를 들어, VAE에서는 generative model을 만들기 위해 variational inference를 사용해 intractable generative model을 tractable generative model로 바꿔 주었고, Self-Supervised Learning 분야에서는 contrastive learning을 하기 위해 intractable mutual information 문제를 tractable하게 바꿔주기도 합니다.
"앞서 색상관련해서는 정해진 차원(1차원 or 3차원)이 필요하다고 했는데, 그렇다면 이미지를 표현하기 위해서도 정해진 차원이 필요한가요?"
결론부터 말씀드리면, 이미지에 대한 차원은 "이미지 크기에 따라 달라진다"입니다. 아래 gray scale의 튜링 이미지의 크기가 200×200이라고 한다면, 이러한 이미지를 표현하기 위해서는 40000 차원이 필요합니다. 왜 이렇게 고차원이 나오는지 설명해보도록 하겠습니다. (사실 엄밀히 말하면 색상도 R,G,B외에 다른 요소들로 표현할 수 있으면 색상의 차원은 또 달라질 수 있습니다)
200×200 gray scale 이미지를 표현한다고 하면 어떻게 생각해볼 수 있을까요? 먼저, 이미지라는 것은 pixel의 조합으로 이루어져 있습니다. 그리고, 하나의 픽셀에는 하나의 색 표현이 가능하죠. Gray scale인 경우에는 하나의 pixel에 0~255 사이 값 중 하나가 할당될 수 있습니다.
그럼 40000개의 pixel이 나올 것입니다. 이때, 각각의 pixel들은 0~255개의 값을 지니고 있죠. 이를 다른 관점에서 보면, 40000개의 독립된 변수로 볼 수 있고, 각각의 변수는 0~255 값의 범위를 갖고 있다고 할 수 있죠. 40000개의 독립된 변수로 하나의 이미지가 구성될 수 있기 때문에, 200×200 gray scale 이미지는 40000차원을 갖는다고 할 수 있습니다. 200×200 이미지는 40000 차원의 독립된 변수들이 갖는 고유의 값들에 의해 표현될 수 있는 것이죠.
"그렇다면, 200×200 gray scale 이미지를 표현할 수 있는 모든 경우의 수는 어떻게 될까요?"
정답은 아래에서 구한 것 처럼 \(10^{96329}\) 경우의 수가 됩니다.
2. 이미지와 분포간의 관계
앞서 200×200 gray scale 이미지의 차원은 40000차원이고, 표현할 수 있는 이미지의 개수(경우의 수)는 대략 \(10^{96329}\) 라고 했습니다.
"그렇다면, 200×200 gray scale 에서 표현될 수 있는 모든 경우의 수에 해당하는 이미지들은 의미가 있다고 할 수 을까요?"
예를 들어, \(10^{96329}\) 경우의 조합들 중에서는 아래 왼쪽과 같이 의미 없는 이미지(noise image)들도 있을 것이고, 오른쪽 같이 사람이 구별할 수 있는 의미 있는 이미지가 있을 수 있습니다.
"200×200 gray scale 즉, 40000차원 상에서 의미있는 이미지들은 고르게 분포(uniform distribution)하고 있을까요? 아니면 40000차원이라는 공간의 특정 영역에 몰려있거나 특정 패턴으로 분포(non-uniform distribution)하고 있을까요?"
이러한 질문에 답을 하는 방법 중 하나는 200×200 gray scale 이미지들을 uniform distribution으로 수 없이 샘플링 해봐서 경험적으로 보여주는 것입니다. 만약, uniform distribution을 전제로 수 없이 샘플링 했을 때, 의미있는 이미지들이 종종 보인다면 의미있는 이미지들이 40000차원 상에 고르게 분포한다고 볼 수 있겠죠.
(※ 직관적으로 이해하기 위해 편의상 40000차원을 아래 이미지 처럼 3차원으로 표현했습니다. (즉, 아래 그림은 '본래 40000차원이다'라고 간주하시면 될 것 같습니다))
"오토인코더의 모든 것"이라는 영상에서 이활석님은 20만번 샘플링한 결과 의미없는 이미지(noisy image)만 추출된 것을 확인 할 수 있었다고 합니다. 이러한 실험을 통해 의미있는 이미지들은 40000차원에서 특정 패턴 또는 특정 위치에 분포해 있다고 경험적으로 결론내릴 수 있게 되는 것이죠.
(↓↓↓아래 영상 1:01:25초 부터↓↓↓)
지금까지 AutoEncoder, VAE, GAN을 배우기 위한 기본 지식들을 정리해봤습니다.
다음 글에서는 AutoEncoder에 대해서 다루면서 dimension reduction에 대한 개념을 소개하도록 하겠습니다. 왜냐하면 VAE, GAN 같은 논문들을 살펴보려면 "latent"말을 이해하기 중요하기 때문이죠!
이번 글에서는 앞으로 GAN에 대한 글을 어떠한 방식으로 작성해나갈지 간단히 설명하려고 합니다.
AutoEncoder
VAE (paper review)
GAN (paper review)
DCGAN (paper review)
이외 다른 GAN 모델들 (paper review 위주)
첫 번째로 AutoEncoder를 다루는 이유는 VAE라는 모델을 설명하기 위해서 입니다.
AutoEncoder는 본래 generative model concept 목적으로 연구된 것이 아니라, dimension reduction 연구를 위해 사용되던 모델입니다. 하지만, VAE라는 모델이 AutoEncoder 기반으로 이루어져있기 때문에 VAE를 배우면서 AutoEncoder 관련 용어들이 종종 등장합니다. 그렇기 때문에 AutoEncoder를 제일 먼저 다루려고 합니다.
두 번째로는 VAE를 다룰 예정입니다. 기존에 generative model을 만들기 위해서는 여러 어려움이 존재했습니다. 대표적으로 intractable computation 문제가 있었죠. 쉽게 말해, 컴퓨터로 generative model을 만들려고 하면 계산이 불가능할 정도의 복잡한 수식을 풀어내야 합니다. VAE는 이러한 intractable computation 문제를 tractable computation 문제로 전환시키는 기법을 도입하여 generative model을 만드는 시도를 했습니다. Generative model을 자주 다루다 보면 intractable이라는 용어와 probabilistic 이라는 용어가 자주 사용되는데, VAE 논문을 리뷰하면서 이러한 용어들에 대한 설명을 하려고 합니다.
세 번째로는 GAN을 다룰 예정입니다. Ian J. Goodfellow의 논문을 리뷰하면서 GAN에 대해서 알아보려고 합니다. 그리고, 네 번째로 DCGAN을 다루면서 vision 분야에서 GAN을 어떻게 적용했는지 알아보겠습니다.
처음 GAN을 접하시는 분들이라면 지금 말씀드린 내용이 모두 이해가 안되시는게 당연합니다.
앞으로 포스팅 하는 글을 최대한 열심히 작성하여 다시 이 글을 보셨을 때, 이해하실 수 있게 노력해보도록 하겠습니다!
이번 글에서는 2019년도 이후 부터 현재 글을 쓰고 있는 시점인 2021년 (9월) 까지의 object detection (based on deep learning) 모델에 대해서 소개하려고 합니다.
현재 제 블로그에 작성한 Object detection 모델은 YOLOv3까지입니다. 그 이유는 제가 2018.05월에 석사 졸업논문을 쓸 당시 주로 사용되던 최신모델이 YOLOv3, SSD, RetinaNet이었기 때문이죠. (RetinaNet은 아직 업로드가 안되어 있는데, 추후에 빠르게 업로드 하도록 하겠습니다!)
그럼 지금부터 2021년까지의 Object Detection model trend 변화를 설명해보도록 하겠습니다.
Note1. 참고로 모델의 trend만 설명드리는거라 디테일한 설명은 하지 않을 예정입니다. 디테일한 기술부분은 차후에 따로 해당 모델에 대한 논문을 리뷰하는 방식으로 업로드 하도록 하겠습니다!
Note2. 이 글에서 trend라고 설명되는 모델들은 저의 주관과 paperwithcode를 기반으로 선택된 모델들임을 미리 말씀드립니다!
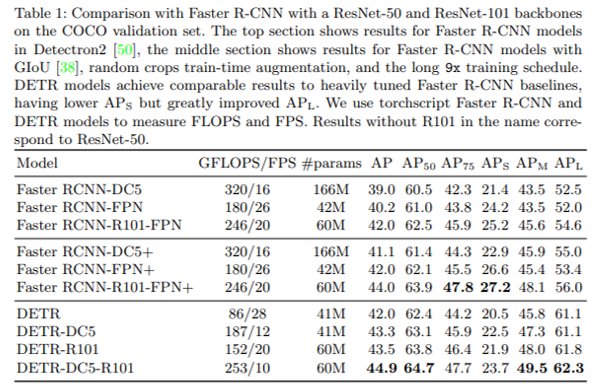
1. Object Detection History (From 2013 ~ 2019)
2013년에 최초의 딥러닝 기반 object detection 모델인 R-CNN이 등장했습니다. 이 후, R-CNN 계열의 object detection 모델인 Fast R-CNN, Faster RCNN 모델들이 좋은 성과를 보여주고 있었죠. 그러다, 2016년에는 YOLO와 SSD가 등장하면서 새로운 계열의 딥러닝 기반 object detection 모델이 등장하게 됩니다. 2017년에는 RetinaNet이 등장하면서 높은 성능을 보여주기도 했죠. (Mask-RCNN 모델도 등장하긴 했지만, Mask-RCNN 모델은 segmentation 분야에서 더 설명할 수 있는게 많은 모델이라 여기에서는 따로 object detection 모델의 mile stone으로 언급하진 않겠습니다)
2018.04월 치매환자 행동패턴 분석연구를 하기 위해 이용했던 딥러닝 모델들이 SSD, RetinaNet, YOLOv3 정도가 있었던거 같습니다. (당시에 TF 1.5 버전을 쓰면서 좋아했던 기억이.... )
"그럼 언제부터 새로운 object detection 모델들이 등장하기 시작했나요?"
앞서 언급했던 모델들이 오랜 시간동안 사용되다가 2019년 후반부터 새로운 object detection model이 등장하기 시작했습니다. 2019년부터 CNN 모델에 다양한 변화가 일어나기 시작했는데, 이러한 변화가 object detection 모델에 영향을 주었습니다. (Object detection 모델은 classification task와 bounding box regression task가 결합된 multi-task loss로 구성되어 있기 때문에 CNN의 변화가 생기면 classification task에 영향을 주게 되겠죠? 만약 좋은 영향을 주면 그만큼 object detection 모델의 성능도 좋아질테니까요!)
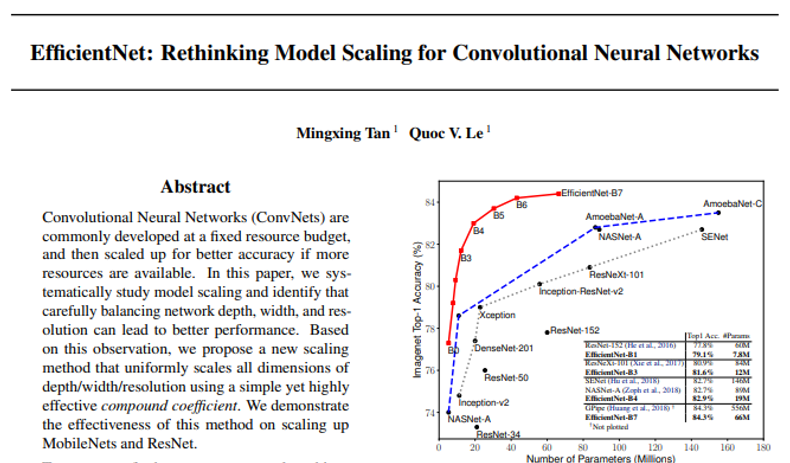
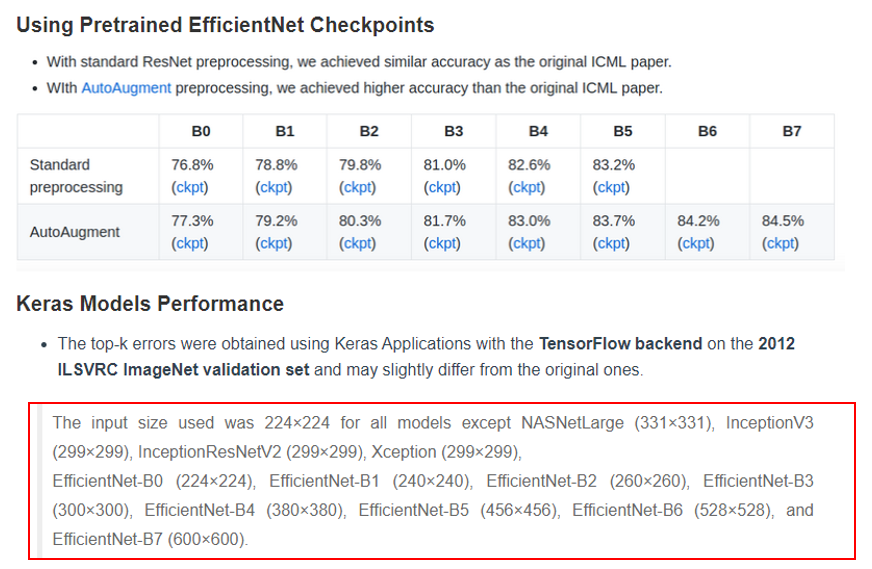
보통 CNN은 224×224 크기로 training&evaluation을 진행했는데, CNN의 입력크기를 키워줄 수록, 성능이 좋아진다는 사실을 알게 됐습니다. 입력 크기를 키워주려면 CNN의 규모(scale) 자체를 크게 키워야 하는데, 어떻게 하면 적절하게 규모를 키워 줄 수 있을지에 대한 방법론이 연구되었습니다. 이 과정에서 AutoML 기법을 도입하여 적절한 CNN 모델을 만들게 되었고, 이것을 EfficientNet이라고 부르게 되었습니다. 드디어 EfficientNet의 등장으로 CNN 모델이 84% top-1 accuracy를 넘어서는 성능을 보여주기 시작했죠
(↓↓↓입력이미지 크기에 따라 Efficient 모델 버전(ex: B0, B1, ..., B7)을 나눈 것↓↓↓)
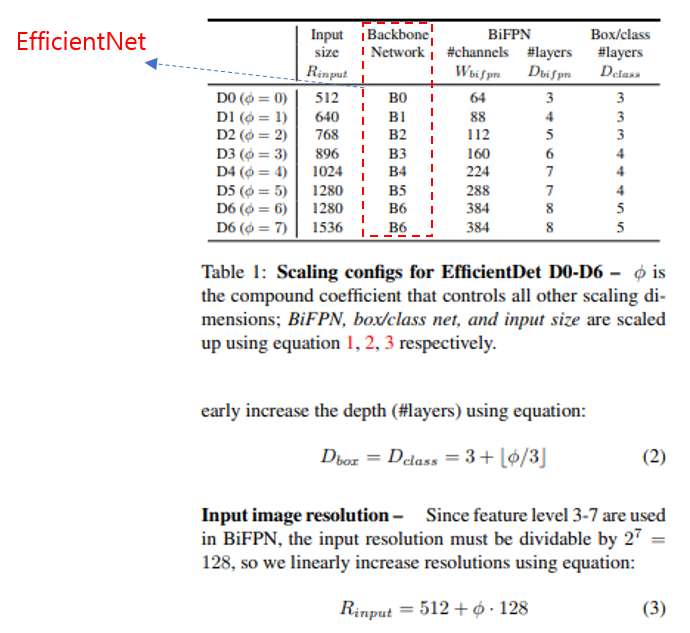
(↓↓↓EfficientDet 논문을 보면 Bacbone Network로 EfficientNet을 사용한 걸 확인할 수 있습니다↓↓↓)
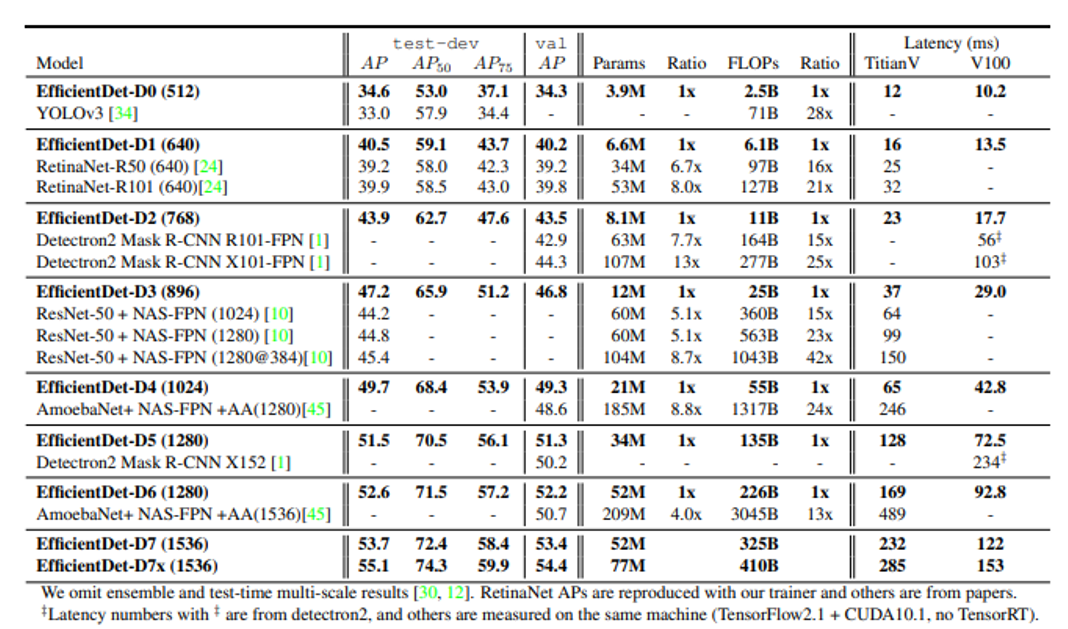
EfficientDet의 등장으로 50 AP넘는 object detection 모델이 등장하기 시작했고, EfficientDet 모델은 2020년 초반까지 object detection SOTA 모델의 자리를 유지합니다.
3. DeformableDETR
기존 object detection은 CNN을 기반으로 다양한 bounding box regression 기법을 연구하는 방향으로 진행되어왔습니다. 하지만, 2020년 초반부터 NLP 분야에서 사용되던 attention기반의 transformer 기법을 object detection에 적용해보려는 시도가 이루어지면서 새로운 object detection 모델들이 등장하게 됩니다.
3-1. Transformer (Feat. Attention)
2017.06월에 Google은 NLP(자연어처리) 분야에서 attention mechanism을 기반으로한 Transformer 모델을 소개합니다.
하지만, 성능자체는 기존 object detection 모델의 성능보다 높게 나오지는 않았습니다. 사실 EfficientDet(←2019.11월 출현 & 50 AP)에 비하면 성능이 많이 뒤쳐지는 편이죠. 여기서 인지해야 하는 부분이 DETR에서 transformer를 사용했다는걸 ViT모델을 사용했다는 걸로 착각하시면 안된다는 점입니다. (참고로 ViT 모델은 DETR가 나오고 7개월 후인 2020.10월에 등장합니다. )
3-3. Deformerable DETR
DETR 모델이 등장하고 7개월 후에, DETR 모델의 후속연구로 Deforma DETR가 출현합니다.
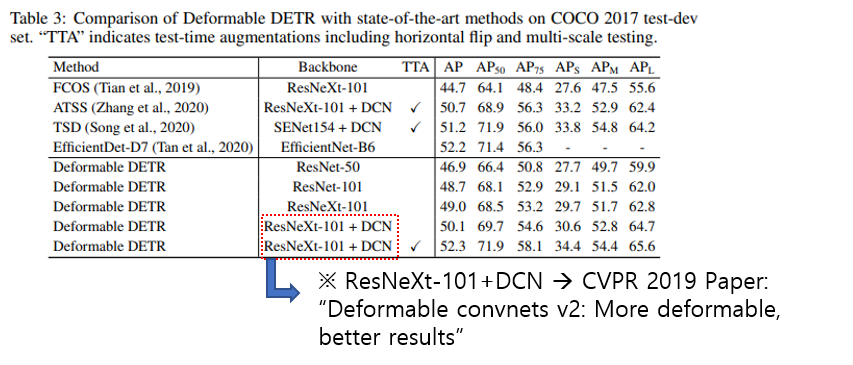
Deformable DETR에서는 deformable attention module을 이용하여 성능을 높이려고 시도했습니다.
Deformable DETR의 성능이 EfficientDet보다 조금씩 더 나은 것을 볼 수 있었습니다. 이것을 통해 Transformer를 CV에 접목하려는 연구가 주목을 받기 시작했죠.
4. YOLOS
2020.10월 ViT 모델의 등장으로 object detection 모델의 backbone을 기존 CNN에서 Transformer 계열로 바꾸려는 시도가 이루어지기 시작합니다.
4-1. ViT
2020.10월 Deformable DETR로 인해 object detection 분야에서 Transformer의 관심을 보이기 시작했다면, 동시에 classification 분야에서는 2020.10월 ViT 모델의 등장으로 Transformer에 대한 관심이 뜨거워졌습니다. (Transformer라는 개념을 처음 소개한 것도 google이고, Transformer를 object detection에 처음 접목시킨 DETR도 google이고, Transformer를 (vision) classification에 처음 접목시킨 것도 google이네요 ㅎㄷㄷ...)
하지만, ViT의 단점 중 하나는 모델이 지나치게 크기 때문에 학습을 시키기 위해서 방대한 양의 데이터를 필요로 한다는 점이었죠. (물론 모델이 크기 때문에 transfer learning에 적합하지 않다는 지적도 받았습니다.)
4-2. DeiT (Data-efficient Image Transformer)
기존에 ViT에서 지적된 것 중 하나가 방대한 양의 데이터셋을 필요로 한다는 점이었습니다. Transfer learning 관점에서 보면 pre-training을 위해 방대한 양의 데이터셋이 필요한 것이라고 볼 수 있죠. 이러한 단점을 극복하기 위해Facebook이 DeiT이라는 classification 모델을 제안하게 됩니다.
DeiT 모델구조 자체는 ViT와 유사합니다. 대신, vision transformer 계열의 모델을 학습 시킬 때 기존의 CNN 방식과 다른 학습 기법을 적용했다는 것이 ViT와 큰 차이라고 볼 수 있습니다. 예를 들어, vision transformer 모델에 적합한 augmentation, optimization, regularization 등의 기법을 찾으려고 시도했고, 효율적인 학습을 위해 knowledge distillation 기법을 transformer 모델에 적용 (←Transformer-specific distillation) 하려는 노력도했습니다. (참고로 knowledge distillation을 적용했을 시에 teacher 모델로 RegNet을 이용했다고 하네요)
위와 같은 ViT와 같이 방대한 양의 학습 데이터 없이도 EfficientNet 보다 classification 성능이 좋은 vision transformer 모델을 선보이게 됩니다.
4-3. YOLOS
Note1. 기존에 알고 있는 YOLO 모델 계열과 전혀 관계가 없다는 것을 알아두세요!
2021년에 들어서자 object detection 모델의 backone으로써 vision transformer 계열의 모델을 사용하는 연구가 진행됩니다.
항저우 대학은 앞서 소개되었던 DeiT이라는 classification 모델을 object detection 모델의 backbone으로 사용하여 YOLOS라는 object detectioin 모델을 만듭니다. 하지만, 기존 object detection 모델에 비해 좋은 성과를 거두지는 못합니다 (오히려 EfficientNet, Derformalbe DETR 성능이 더 좋은 것 같네요).
5. Scaled YOLO v4
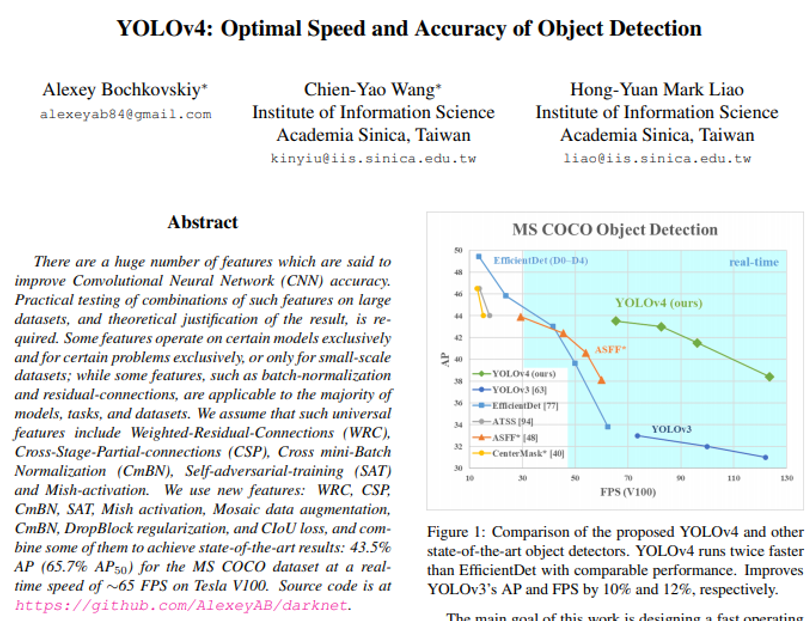
YOLO계열의 object detection 모델은 real-time이라는 측면에서 많은 사랑을 받아왔습니다. 하지만, 상대적으로 낮은 AP 성능으로 인해 YOLO v3 이후 많은 외면을 받아오기도 했는데요. 올해 제안된 YOLO 계열의 object detection 모델이 56 AP 성능을 기록하면서 다시 한 번 주목을 받고 있습니다.
5-1. YOLO v1, YOLO v2, YOLO v3
2015년 첫 real-time object detection 모델인 YOLO v1이 출현합니다. 하지만, real-time에 초점을 맞춘 나머지 정확도 측면에서 많은 아쉬움을 주었죠.
YOLO v3는 다른 학회에 제출하지는 않고 Tech Report 형식으로 arXiv에 올리기만 했는데 그 이유는 다음과 같습니다. 사실, Joseph Redmon은 YOLO v3 Tech Report에서도 computer vision 분야에서 object detection 모델을 개발하는 것에 대한 윤리적 책임감을 강조했습니다. 어떤 이유가 결정적이었는 지는 모르겠지만, YOLO v3 모델을 개발하고 2년 후 자신은 object detection 모델을 개발하는 것을 그만두겠다는 트윗을 올리게 되죠. 그 이유는 아래와 같이 군사적 목적으로 쓰이는걸 원치않았기 때문이라고 합니다.
5-2. YOLO v4
2018년 석사시절에 필자는 YOLO v3를 사용할 때, Joseph Redmon의 official site를 이용하지는 않았습니다. (질문을 올려도 답을 잘 안해줬던 기억이...) 이 당시에 Alexey라는 russian reseacher의 github에서 YOLO v3를 자주 이용했습니다.
질문하면 정말 빠르게 피드백 해주어서 연구할 때 많은 도움을 받았던 기억이 있네요...ㅎ (사실, 설치나 코드 파악하기에도 Alexey의 코드가 더 보기 편했던 것 같습니다.)
2020.02월에 Joseph Redmon이 YOLO v4에 대한 개발 포기를 선언하자, 2달뒤 2020.04월에 Alexey가 YOLO v4 모델을 개발합니다.
EfficientDet에 비교하면 아직 아쉬운 수준이었지만, 기존 YOLO v3보다는 더 좋은 성능을 보여주었습니다. 아래 figure1을 보면 GPU V100 모델 기준으로의 높은 FPS 성능을 보여주고 있기 때문에 충분히 낮은 GPU 성능이 장착된 작은 device에 임베딩해서도 사용될 수 있음을 예상 할 수 있습니다.
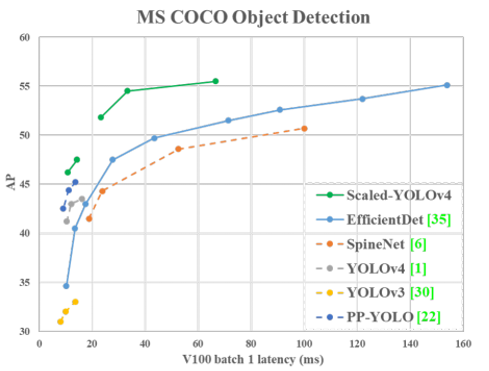
5-3. YOLO v5
YOLO v4라는 논문이 2020.04월에 나온 후, 곧바로 한 달뒤인 2020.05월에 YOLO v5가 나왔습니다. 그런데, YOLO v5는 arXiv와 같은 paper형식이 아닌 blog site에 소개가 됩니다.
AP와 FPS 측면에서 모두 성능향상을 이루긴 했지만, machine learning commuity에서 여러 의견이 있었던 것 같습니다. 특히, YOLO v4의 저자인 Alexey가 성능을 측정하는 것에 대해 여러 문제점을 제기했다고 합니다. (자세한 내용은 아래 사이트의 "Controversy in machine learning community" section에서 확인해주세요!)
논문의 결과나 paperwithcode에서 살펴봤을 때, 모델의 성능 자체는 크게 개선되지 않았던것 같습니다.
하지만, Scaled YOLO v4 모델을 좀 더 representation 관점에서 다양한 해석을 시도하려고 했기 때문에 이를 기반으로 후속 연구들이 나오지 않을까 기대하고 있습니다.
6. Soft Teacher+Swin-L
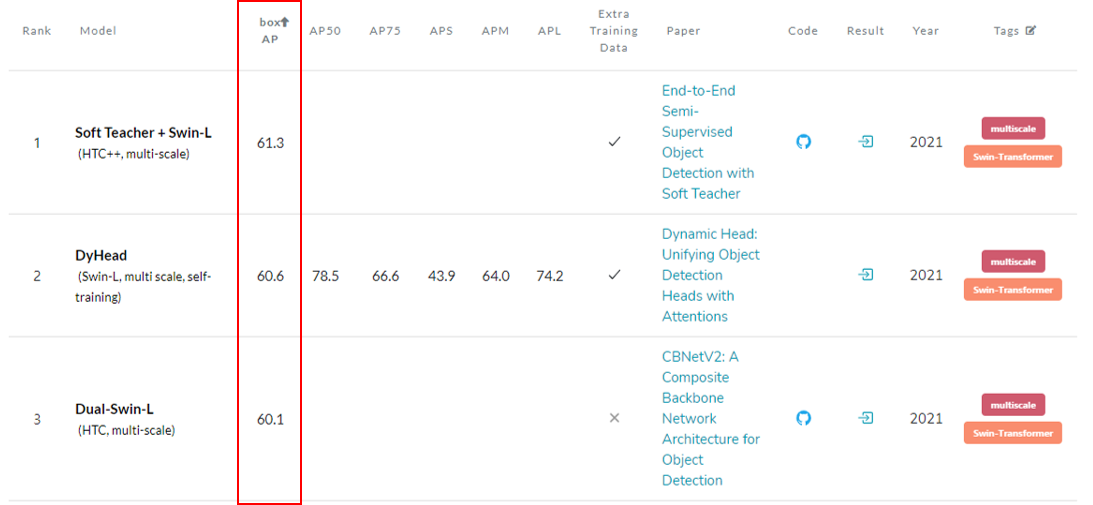
2021년에 들어서면서 Transformer 계열의 object detection 모델이 CNN 계열의 object detection 모델을 밀어내고 독주하기 시작합니다. 필자가 조사를 했을 당시 (2021.08) paperwithcode에서 object detection SOTA 모델이 Soft Teacher+Swin-L 이었는데, 이 모델 역시 Transformer 계열의 objecte detection 모델이었습니다.
6-1. Swin Transformer
2021.03월에 Microsoft Reseaerch Asia에서 새로운 vision Transformer 모델인 Swin Transformer 모델을 선보입니다.
Swin Transformer는 사실 semantic segmentation 분야에 Transformer 모델을 적용시키기 위해 고안되었습니다. Segmentation은 dense prediction을 해야하기 때문에 계산량이 많은데, 기존 Transformer 모델 자체도 계산량이 많기 때문에 sementic segmentation과 Transformer 기술 까지 같이 접목시키면 intractable 문제로 바뀐다고 합니다. 이러한 intractable 문제를 극복하기 위해서 Swin Transformer 논문은 hierarchical feature map와 Shifted window (Swin) block을 이용했다고 합니다.
Swin Transformer 모델은 2021.03월에 58 AP를 기록하면서 object detection SOTA 모델로 등극하게 됩니다.
6-2. Soft Teacher+Swin-L
Swin Transformer 모델이 나온 후 3개월 뒤 후속 연구로써 Soft Teacher+Swin-L 모델이 등장합니다.
Swin Transformer의 저자 중 한 명이 Soft Teacher+Swin-L 모델 연구 개발에 참여한 것으로 보이고, Micro Soft와 항저우 과기대 (HUST) 팀원들이 같이 참여 한 것으로 보이네요. (올해는 항저우 과기대라는 이름을 더 자주 보는 듯합니다)
Pseudo label 기반의 Semi-Supervised Learning 방식을 Swin Transformer에 적절히 잘 적용한 Soft Teacher+Swin-L 모델이 제안됩니다
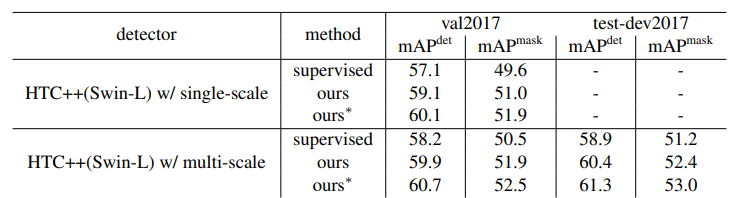
기존에는 Semi-Supervised Learning이 Supervised Learning의 성능을 뛰어 넘지 못했던 것과 달리, Soft Teacher+Swin-L 모델에 Semi-Supervised Learning을 적용했을 때는 더 좋은 성과를 보여준 것이 고무적입니다. 또한, 드디어 60 AP 고지를 돌파한 object detection 모델을 선보이기도 했죠.
7. ETC
2021.08월을 기준으로 현재 paperwithcode에서 object detection 1, 2, 3등 모델 모두 Swin Tranformer를 기반으로 하고 있습니다.
DyHead
2021.06.15 arXiv 등록
2021 CVPR accept
Dual-Swin-L
2021.07.01 arXiv 등록
1, 2 3등을 기록한 연구들은 서로 별개의 독립적인 연구였던 것 같습니다.
지금까지 2021.08월까지 object detection 모델의 trend에 대해서 소개해드렸습니다.
앞으로 object detection 관련 글을 쓰게 되면 Swin Transformer 또는 EfficientDet 부터 쓰게되지 않을까 싶습니다.
이번 글에서는 실행파일에 대해서 설명한 후, 파이썬으로 실행파일을 만드는 방법에 대해서 말씀드리도록 하겠습니다.
[Note]
실행파일 만드는 순서만 따로 보고싶으시다면 맨 아래 "6. python으로 작성된 딥러닝 실행파일을 만드는 방법 정리"만 참고하시면 될 것 같습니다.
1. 딥러닝 개발을 하는데 실행파일이 왜 필요한가요?
학계에서 딥러닝을 연구하시는 분들은 보통 파이썬으로 train 코드와 evaluation 코드를 작성하고, "train.py" or "test.py" 파일형태로 github에 올립니다. 특히 요즘 같이 top-tier 딥러닝 학회에 논문을 낼 때에는 자신의 코드를 github에 올린 후, 논문에 기재하기도 하죠. 이렇게 코드를 올리면 다운받아서 실제로 잘 돌아가는지도 확인할 수 있겠죠?
그렇다면 딥러닝을 비지니스에서 사용하려고 할 때는 어떨까요?
학계에서는 많은 연구자들에게 어필해야하므로 관련 코드를 github에서 볼 수 있게 해줍니다. 물론 연구자들은 전문가이기 때문에 언제든 github을 통해 돌려볼 수 도 있습니다. 논문도 훌륭하고 코드도 잘 돌아가면 그만큼 저자의 명성이 높아지겠죠.
비지니스에서는 어필해야할 사람들이 누굴까요?
바로, 투자자들입니다. 우리가 학계에서 처럼 투자자들에게 코드를 github에서 다운받아서 돌려보라고 할 수 있을까요? 투자자들이 모델학습에 관심이 있을까요?
학계와 달리 투자자들은 개발에 대해서 전혀 모르고 있을 가능성이 큽니다. 또한, 투자자들의 관심은 단지 모델이 잘 돌아가는지 눈으로 확인하는 것이죠.
그래서, 프로젝트 마무리 단계에 진입하면 자신들의 성과를 보여주기 위해 투자자들에게 개발한 모델을 시연합니다.
예를 들어, 우리가 숫자를 인식하는 딥러닝 프로그램을 만들었다고 해보겠습니다. 투자자들은 간단한 GUI 프로그램을 통해 숫자 인식을 제대로 하는지에만 관심이 있을거에요.
이러한 GUI 프로그램을 만들기 위해 필요한 것이 실행파일입니다. 즉, .exe 라는 확장자명을 가진 실행파일을 클릭하기만 하면 자동으로 GUI 프로그램이 실행되도록 해주는 것이죠. 이러한 실행파일을 실행시키기 위해서는 단지 학습이 완료된 모델들과 테스트 이미지만 있으면 됩니다.
(파이썬으로 간단한 GUI 프로그램을 만드는 방법은 "pyqt5" 모듈 or "tkinter" 모듈을 이용하면 됩니다. 이 내용은 따로 다루도록 하겠습니다.)
2. PyInstller 모듈
파이썬으로 실행파일을 만드는 과정은 간단합니다.
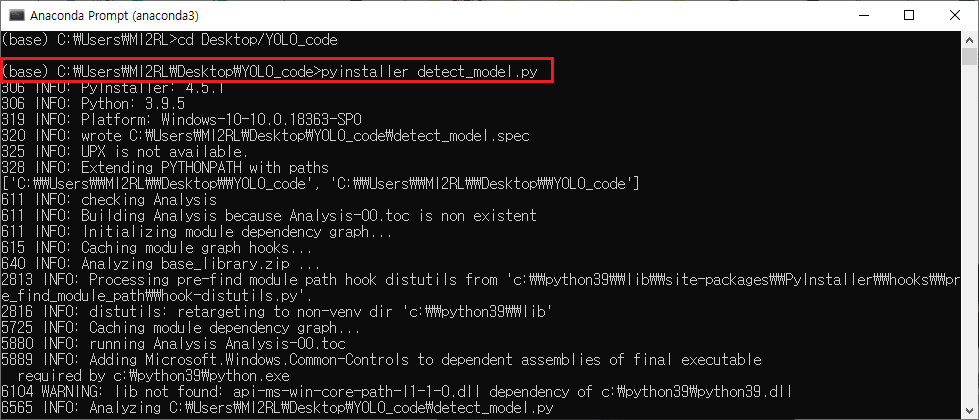
첫 번째, PyInstller 모듈을 설치해줍니다.
필자는 개발환경으로 anaconda를 이용하고 있기 때문에, anaconda 명령어로 설치해주었습니다.
conda install -c conda-forge pyinstaller
두 번째, 아래 명령어를 이용해 원하는 python파일(.py)을 실행파일(.exe)로 만들어 줍니다.
pyinstaller 원하는파일.py
[예시]
1. VS code 편집기에 YOLOv3를 구현해 놓습니다.
2. YOLOv3를 구현해 놓은 코드를 돌리면 __pycache__ 폴더가 생성됩니다.
(__pycache__ 폴더에는 컴파일되어 실행 준비가 된 Python 3 바이트 코드들이 저장됩니다)
3. 원하는 python 파일을 실행파일로 바꿔주기 위한 명령어를 입력합니다.
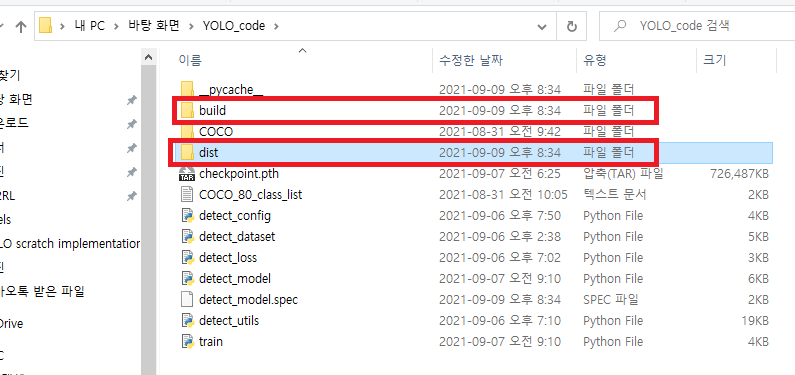
4. 명령어를 실행하면 아래와 같이 두 개의 폴더가 생성됩니다.
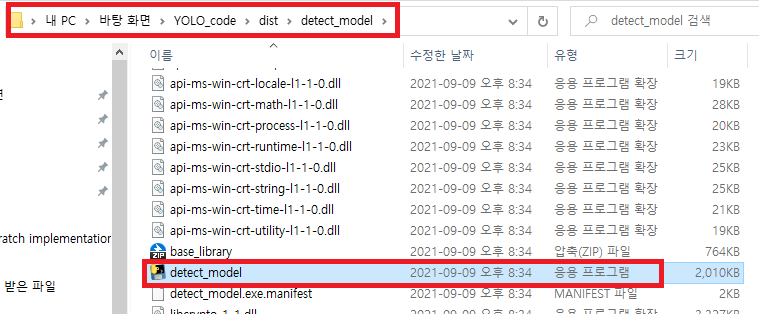
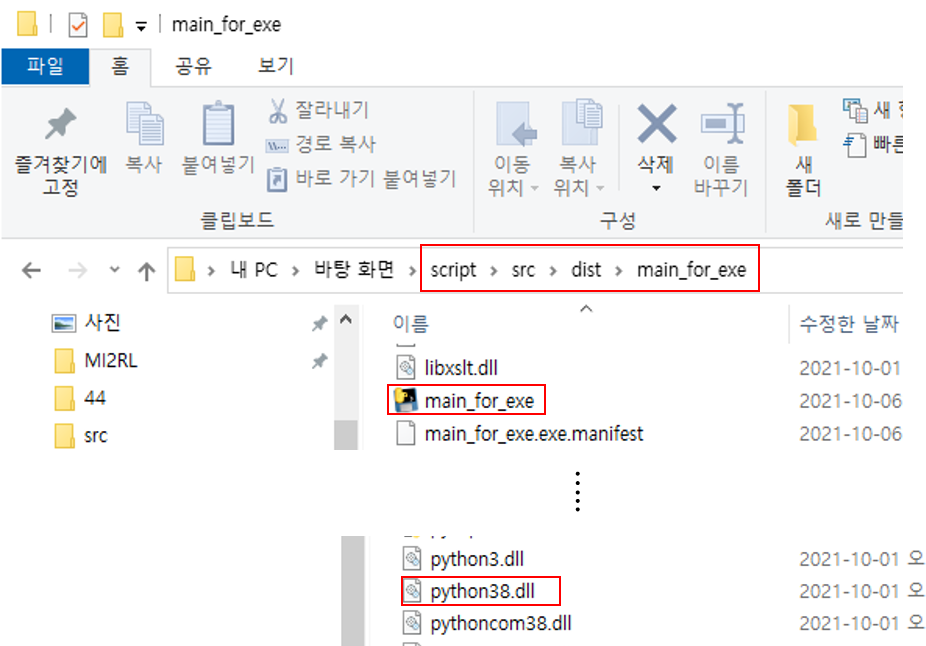
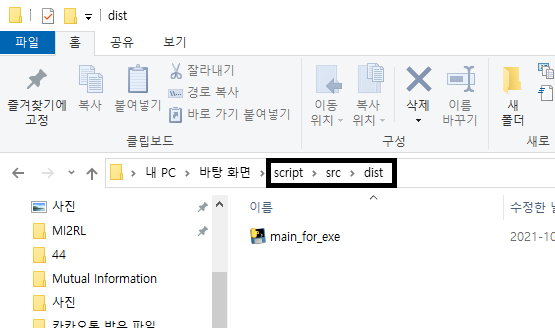
dist 폴더: distribute(배포)의 약자입니다. 즉, 배포되는 파일이 들어 있는 디렉토리라고 보시면 됩니다. dist 폴더에 실행파일이 만들어졌음을 확인할 수 있습니다. 나중에 시연할 때에는 아래의 실행파일이용하면 됩니다.
3. pyinstaller 업데이트 (Feat. No module named)
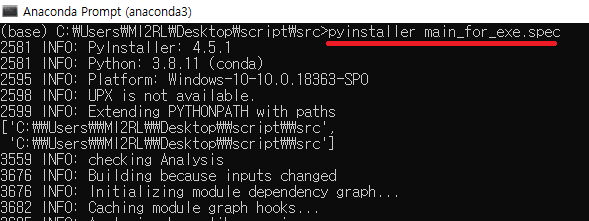
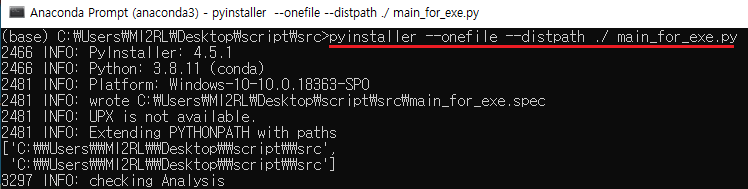
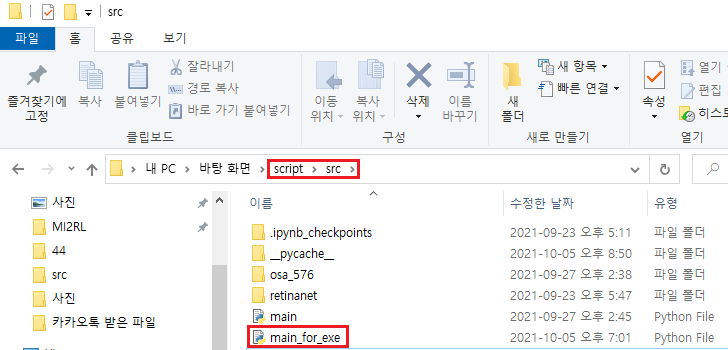
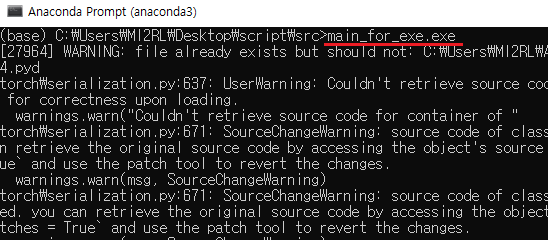
지금부터는 아래와 같이 'main_for_exe.py' 파일을 실행파일로 만들어보겠습니다.
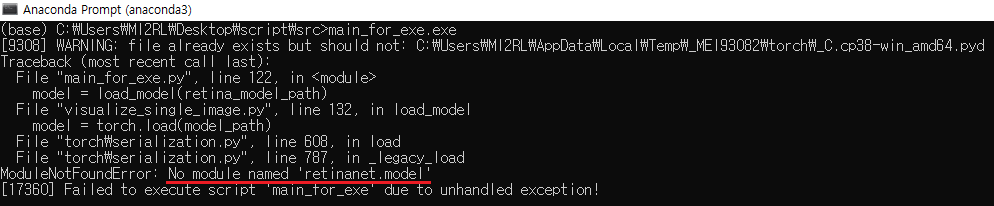
만약 pyinstaller를 처음 설치하고 바로 실행파일을 만들고 실행('main_for_exe.exe')하면, 아래와 같이 "No module named"라는 에러 메시지가 뜰 가능성이 있습니다. 제가 사용하고 있는 vscode에서는 문제 없이 잘 돌아갔는데, 왜 실행파일을 실행시키면 에러가 날까요?
이유는 간단합니다.
vscode의 interpreter는 anaconda or pip로 설치한 패키지들이 저장되어 있는 디렉토리의 path를 잘 잡아주고 있는 반면, 업그레이드 하지 않은 초기 버전의 pyinstaller 를 이용하면 해당 디렉토리를 못잡아주기 때문에 anaconda 명령어로 설치한 'torch' 모듈을 load 할 수 없게 되는 것이지요.
(↓↓↓anaconda or pip로 설치한 패키지들이 저장되어 있는 디렉토리↓↓↓)
위와 같은 문제를 해결해주는 방법은 아래와 같이 pyinstaller를 업그레이드 해주는 것입니다. (사실, 최근에 설치했다면 위와 같은 오류가 생성되지는 않을 것입니다.)
pip install --upgrade pyinstaller
위와 같이 업그레이드를 시켜주고 다시 실행파일을 만들면 아래와 같이 hook path로써 "anaconda or pip로 설치한 패키지들이 저장되어 있는 디렉토리"를 잡아주는 것을 확인할 수 있습니다.
4. hidden module (Feat. hidden import)
만약 anaconda or pip로 설치한 모듈이 아닌 다른 github에서 다운 받는 모듈들을 사용하게 되면 추가적인 작업을 해주어야 합니다.
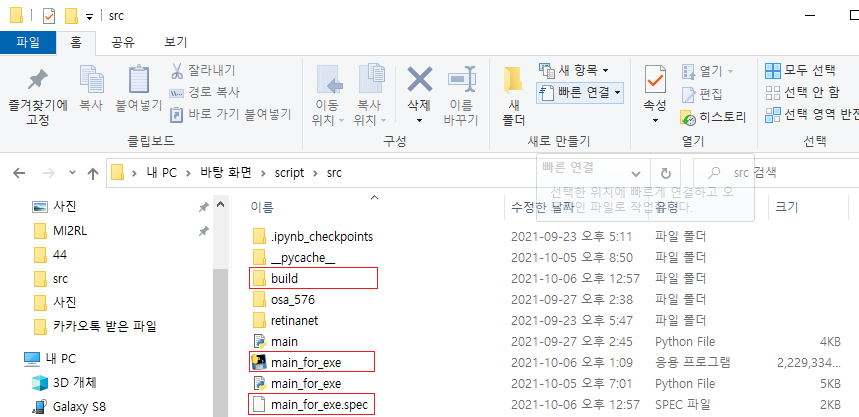
예를 들어, github에서 아래와 같이 'retinanet'이라는 모듈을 다운을 받았다고 가정해보겠습니다.
이때, 'main_for_exe.py'의 실행파일을 만들기 위해서는 추가된 retinanet 모듈의 path도 잡아주어야 합니다.
path를 잡아주는 방법은 간단합니다.
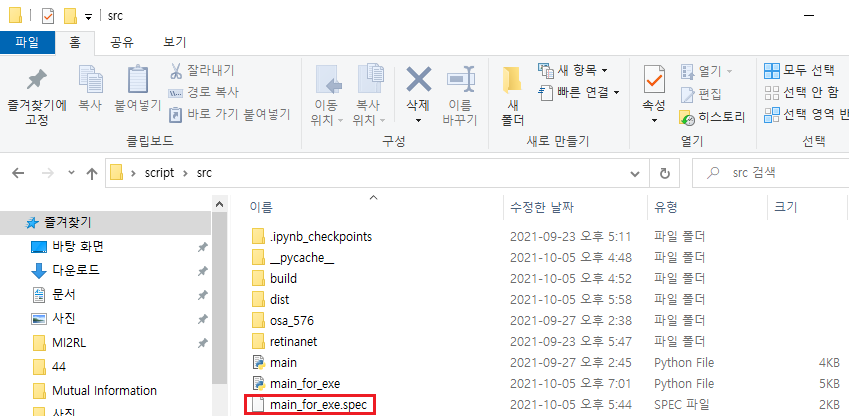
1. 실행파일을 생성했다면 동시에 spec 파일도 생성될 것 입니다.
2. vscode(or 다른 IDE)로 해당 spec 파일을 열어 줍니다.
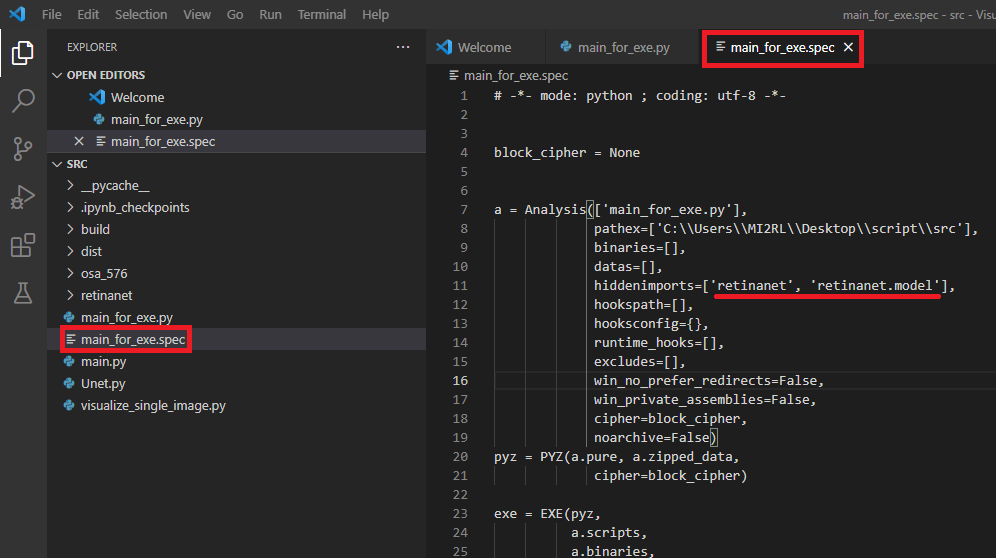
3. hiddenimports 부분에 추가할 module을 입력 해줍니다.
retinanet.model 모듈을 추가해준 이유는 retinanet만 추가해줬을 때 아래와 같은 에러가 출력됐기 때문입니다.
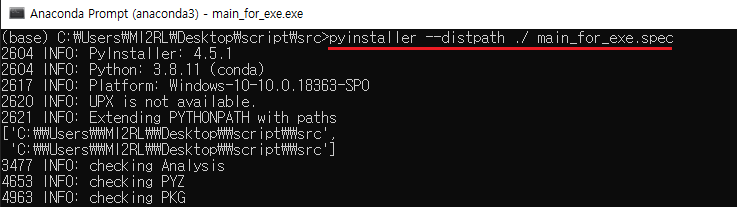
4. hiddenimports를 추가해주었다면 spec 파일을 아래와 같이 다시 빌드해줍니다.
이렇게 하면 'no module name'과 같이 모듈을 인식하지 못하는 문제는 해결할 수 있을 것입니다.
(사실 pyinstaller 명령어에서 --hidden-import 라는 옵션이 있긴 한데, 위에서 언급한 대로 에러를 잡아가는게 더 정확했던것 같습니다.)
5. 실행파일과 script파일 경로 차이 해결
vscode에서는 문제없이 돌아간 파일을 실행파일로 만들면 아래와 같이 경로에러를 발생시키는 경우가 있습니다.
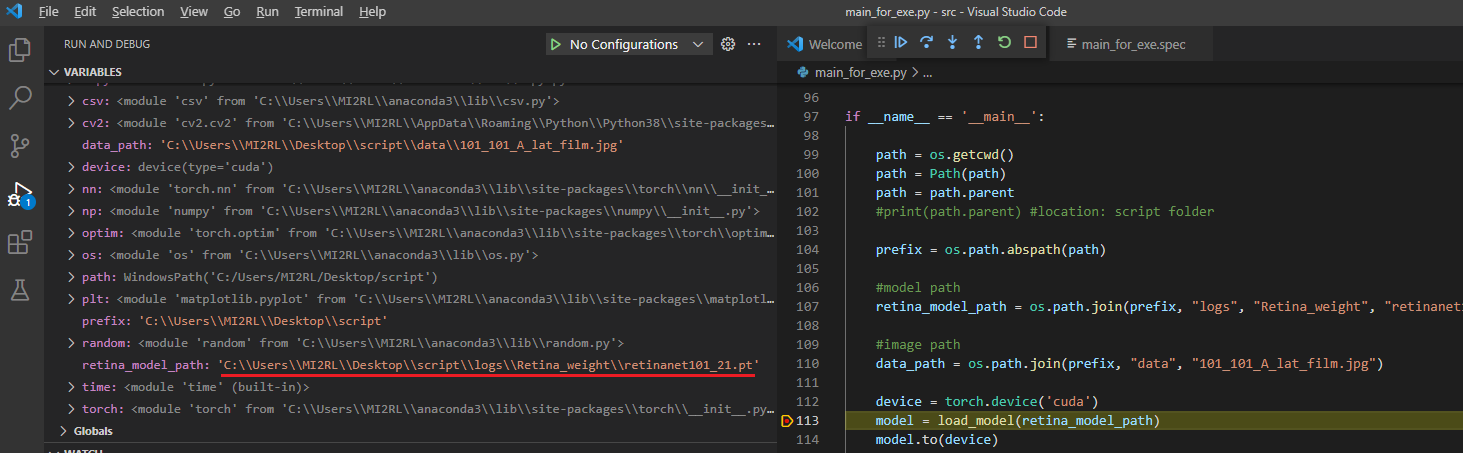
위의 에러가 난 이유를 아래 코드 디버깅을 통해 살펴보니 retina_model_path 경로 때문인 것으로 파악할 수 있었습니다. 아래 vscode 상에서는 "C:\\Users\\MI2RL\\Desktop\\script\\logs\\Retina_weight\\retinanet101_21.pt"로 잘 설정되어 있지만, 위의 Anaconda Prompt에서는 엉뚱한 경로를 설정하고 있는걸 확인할 수 있었습니다.
아래 디렉토리를 확인해 보니, main_for_exe.exe 실행 파일을 수행하면 현재 실행시킨 경로를 기준으로 파일경로가 재설정되는 듯했습니다. 자세히 말하자면, vscode 상에 'retina_model_path를 설정하는 코드를 보면 'prefix' 변수명에 'logs\Retina_weight\~' 경로를 합쳐주는걸로 되어있는데, vscode 상에서는 script 폴더에서부터 접근하는 반면,
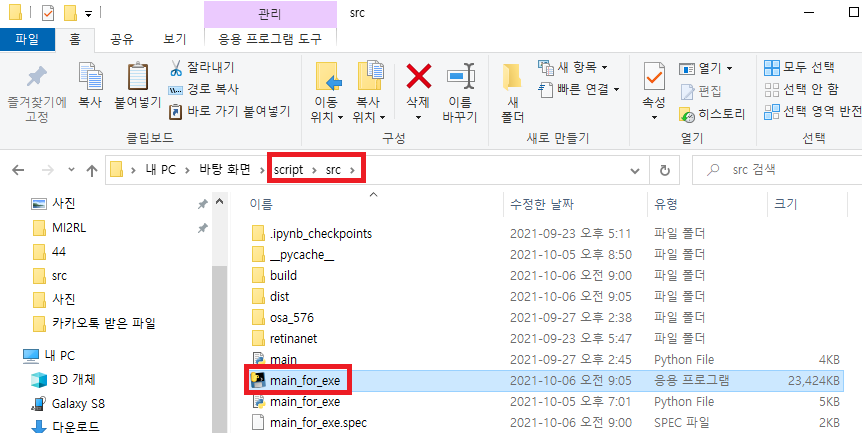
실행파일을 돌리면 script\src\dist 폴더에서부터 접근하는 것으로 보였습니다.
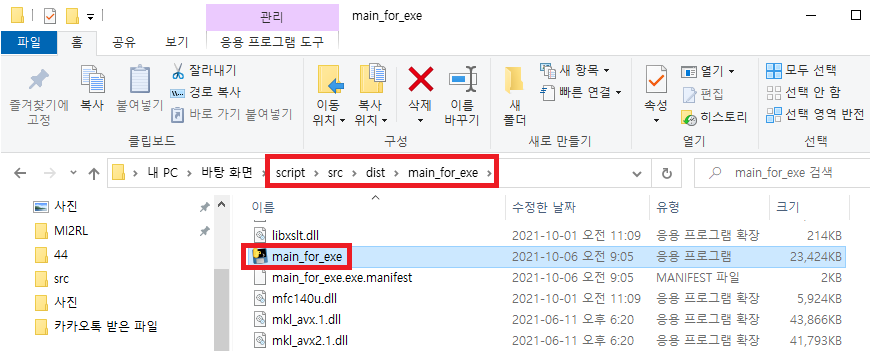
그래서, vscode에서 main_for_exe.py을 실행시켰던 src 디렉토리로 main_for_exe.exe 파일을 옮겨준 후 다시 실행시켜보았습니다.
그러자, 앞서 언급한 경로문제는 해결되었지만, src\dist\main_for_exe 폴더에 main_for_exe.exe가 생성될 때 같이 생성된 다른 모듈들과의 호환문제가 발생했습니다.
위의 에러메시지를 보면 main_for_exe.exe 파일이 생성되는 디렉토리에 관련 모듈들도 동일한 디렉토리에 생성되는데, main_for_exe.exe 파일만 따로 빼내어 실행시키다보니 에러메시지가 나타났습니다.
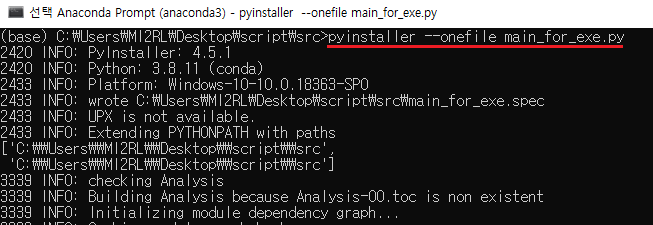
그래서, src\dist 폴더에 main_for_exe.exe 파일에 모든 모듈을 통합하도록 --onefile 옵션을 주어 파일을 다시 컴파일을 해줍니다.
앞서 --onefile 옵션을 통해 아래와 같이 하나의 exe 파일로 생성됐습니다. 그리고, 해당 파일을 복사한 후
아래 폴더 위치에 다시 옮겨 놓습니다.
[Note]
만약, 위와 같이 main_for_exe.exe 파일을 src\dist 폴더에서 빼내지 않고, 애초에 main_for_exe.exe 파일을 main_for_exe.py 폴더가 위치한 src 폴더에 생성시키려면 아래와 같이 distpath 옵션에 src 폴더경로를 입력해주면 됩니다.
그리고, src 디렉토리에서 main_for_exe.exe 파일을 실행시키면, 아래와 같이 warning 메시지만 뜨고 문제 없이 실행되는 걸 확인 하실 수 있습니다.
6. 다른 local에서 실행파일 테스트하기
자신의 local 컴퓨터에서 문제 없이 돌아갔다면, 다른 사용자의 local 컴퓨터에서도 문제 없이 돌아갔는지 확인해야 합니다.
위의 예시를 기준으로 확인순서를 말씀 드리겠습니다.
다른 사용자의 local 컴퓨터에 script 폴더를 다운받습니다.
src 폴더의 main_for_exe.exe를 실행시켜 줍니다.
만약 아래와 같은 에러가 생긴다면 CUDA를 설치하시고 다시 실행시키면 됩니다.
OSError: [WinError 126] 지정된 모듈을 찾을 수 없습니다. Error loading "C:\Users\MI2RL-JW\AppData\Local\Temp\_MEI260802\torch\lib\caffe2_detectron_ops_gpu.dll" or one of its dependencies.
[32] Failed to execute script 'test_OP_exe' due to unhandled exception!
(에러 원인을 찾아보니 아래와 같은 문구가 있어서 CUDA를 다시 설치하니 다른 local에서도 문제 없이 돌아가네요. 아마 코드자체가 gpu를 사용하겠금 구현되어 있어서 그런듯 합니다...)
1. pyinstaller 설치 및 업그레이드 (최근에 설치하는 것이라면 아래 명령어 중 하나만 선택하기만 해도 됨)
conda install -c conda-forge pyinstaller
pip install --upgrade pyinstaller
2. vscode 실행했던 디렉토리에 (모듈이 통합 된) exe 파일 및 spec 파일 생성 하기
pyinstaller --onefile --distpath 디렉토리명 실행파일명.py
(↓↓vscode에서 실행했던 main_for_exe.py 파일과 동일한 경로에 --distpath가 설정되어있는지 확인↓↓)
(↓↓↓아래와 같이 새 폴더 또는 파일이 생성됐는지 확인↓↓↓)
3. github으로 다운 받은 모듈이 있다면 hiddenimports 추가 && spec 파일 다시 빌드
[Note]
--distpath 설정해주어야 이전에 --distpath 경로에서 만들어진 exe 실행파일에 hiddenimports가 추가된 내용이 overwrite됩니다.
pyinstaller --distpath 디렉토리명 실행파일명.spec
4. 실행하기
실행파일.exe
5. 다른 local 컴퓨터에서 실행파일 테스트 (시연) 하기
다른 사용자의 local 컴퓨터에 script 폴더를 다운받습니다.
src 폴더의 main_for_exe.exe를 실행시켜 줍니다.
만약 아래와 같은 에러가 생긴다면
OSError: [WinError 126] 지정된 모듈을 찾을 수 없습니다. Error loading "C:\Users\MI2RL-JW\AppData\Local\Temp\_MEI260802\torch\lib\caffe2_detectron_ops_gpu.dll" or one of its dependencies.
[32] Failed to execute script 'test_OP_exe' due to unhandled exception!
Pytorch + CUDA를 설치하시고 다시 실행시킵니다.
1번이 안되면 spec 파일에 아나콘다\torch\lib 경로를 pathex에 추가시켜주고 다시 실행파일로 만들어줍니다
※만약, 해당 파일이 계속해서 실행이 안된다면 아래의 사항을 확인해주세요!
실행하려는 Local에서 GPU가 있는지 확인합니다.
만약, GPU가 없다면 코드에 try ~ except 문을 이용하여 GPU가 없을 시, CPU 코드로 돌아갈 수 있게 구현해 놓습니다.
(보통 딥러닝 모델을 inference 용도로만 사용하는 경우 해당 local에는 GPU가 없을 가능성이 있습니다. 클라우드 서버에서 돌리면 더더욱 그러한데, 그 이유는 클라우드에서 GPU 사용시 돈이 굉장히 많이 소요되기 때문이라고 합니다.)
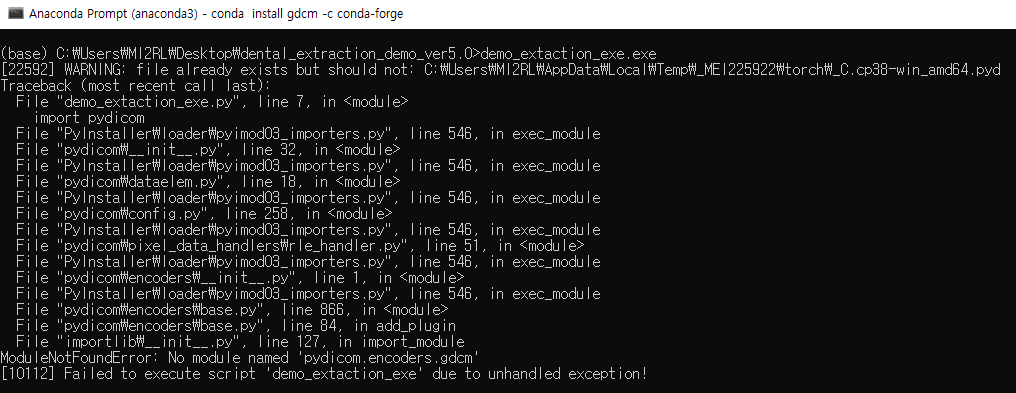
[Note. pydicom 에러]
만약 pydicom 모듈이 포함된 실행파일을 만들었다면 아래와 같은 에러 메시지가 출력 될 수 도 있습니다.
1. 위 문제를 해결할 수 있는 한 가지 방법은 pydicom 모듈을 simpleITK 모듈로 바꿔주어 dicom 파일을 읽도록 하는 것이 있습니다.
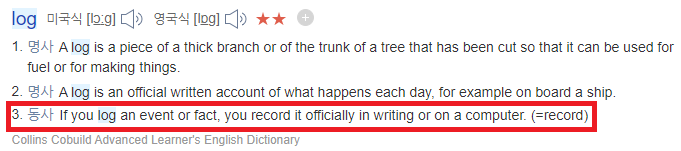
"In computing, a log file is a file that records either events that occur in an operating system(or other software runs) or messages between different users of communication software. Logging is the act of keeping a log."
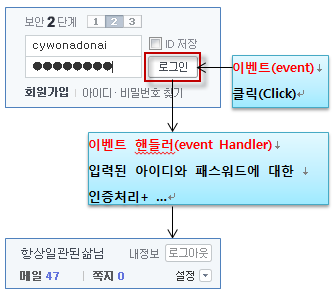
컴퓨팅에서 event란 프로그램에 의해 감지되고 처리될 수 있는 동작이나 사건을 말합니다. 예를 들어, 마우스를 클릭 하거나 키보드를 입력하면 이벤트가 발생합니다. 마우스를 예로 들어 이벤트 기반 시스템이 수행되는 과정을 설명하면 아래와 같습니다.
(마우스) 장치로부터 입력이나 내부 경보를 계속해서 기다립니다.
마우스 클릭 시, 이벤트 발생 시 정보들(ex: 언제, 어디서, 어떤 이벤트가 발생 했는지 등)을 이벤트 핸들러 (event handler)로 보냅니다.
그리고, 이벤트 핸들러 (event handler) 에서 발생 한 이벤트를 어떻게 처리해 줄 지 프로그래밍 해줍니다.
<그림1 출처. https://fromyou.tistory.com/546>
위 그림에서 마우스를 클릭하여 event를 발생시키면 event handler를 통해 사이트에 접속하는 과정이 실행됩니다.
이때, 접속한 시간을 따로 기록할 수 있도록 프로그래밍을 할 수 도 있습니다. 이렇게 접속한 시간을 따로 기록해두면 나중에 내가 한달에 몇 번 사이트에 접속했는지 알 수 있겠죠?
2. Log란 무엇인가요?
앞서 설명한 "접속시간을 기록하는 행위"를 "log"라고 합니다. 좀 더, 일반화 해서 말하자면 "무언가를 기록하는 행위"를 log라고 하지요. (computer 분야에서는 log라는 것 자체를 동사 개념으로 사용하고 있는데, 보통 logging이라는 용어로 대체되어 사용되기도 합니다)
그리고, 이렇게 "무언가를 기록하는 행위"를 한다는 것은 "기록에 대한 파일을 만드는 것"으로 볼 수 있는데, 이때 만들어진 파일을 log파일이라고 합니다. 접속시간에 대한 내용만 기록을 했다면 "접속시간 log 파일"이라고 부르죠.
마우스나 키보드와 같은 이벤트를 통해서만 log라는 행위를 하거나 (log)파일을 얻을 수 있는 건 아닙니다.
프로그램 명령어를 통해 log라는 행위를 할 수 도 있습니다
3.logging 모듈이란?
Python에서는 명령어를 통해 log를 할 수 있게 해줍니다.
즉, 특정 명령어를 이용하면 프로그램이 실행되는 동안 일어나는 모든 정보를 기록으로 남길 수 있죠.
기록된 정보들은 의미있는 분석을 위해 사용될 수 도 있습니다.
log를 이용하는 또 다른 목적은 개발 단계에서 프로그램이 제대로 동작하는지 확인하기 위함입니다.
프로그램이 제대로 동작하는지 확인하는 단계는 크게 5가지 단계로 나눌 수 있는데, 이것을 logging level이라고 합니다.
3.1. logging level
Level
Numeric value
의미
DEBUG
10
어떤 문제가 발생했을 경우 해당 문제를 진단하고 싶을 때 필요한 자세한 정보를 기록
INFO
20
작업이 정상적으로 작동하고 있음을 메시지를 통해 확인하고 싶은 경우
WARNING
30
소프트웨어가 동작하고 있지만, 예상치 못한 일이 발생했거나 가까운 미래에 문제가 발생할 수 도 있음을 경고 Ex1) 디스크 공간 부족 → 프로그램은 잘 동작되지만 앞으로 문제가 발생할 수 도 있음
ERROR
40
문제가 발생했으며 소프트웨어 일부가 기능을 수행하지 못했다는 뜻
CRITICAL
50
심각한 에러 → 프로그램 자체가 실행되지 않을 수 있다는 것을 뜻함
DEBUG < INFO < WARN < ERROR < FATA
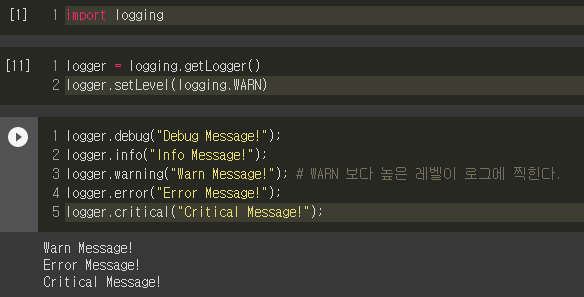
"setLevel"이라는 명령어를 이용하여 위와 같은 5단계의 logging level 중 하나를 설정해 줄 수 있습니다.
만약, WARN을 로그 레벨로 지정을 하게 되면 WARN보다 높은 level에 대한 logging message만 출력되는 것을 볼 수 있습니다.
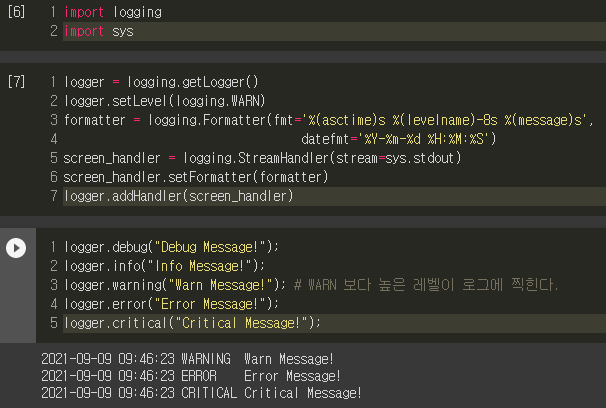
3.2. logging.Formatter
logging.Formatter를 이용하면 추가적인 정보를 더해 logging message를 출력할 수 있습니다.
logging.Formatter를 이용하려면 4가지 단계를 거쳐야 합니다.
logging.Formatter를 이용하여 원하는 logging message 출력형태를 결정해줍니다.
logging message를 출력하는 방법은 총 2가지 입니다. 첫 번째는 console 창에 logging message를 띄우는 방법이 있고, 두 번째는 특정 파일에 logging message를 보내 저장시키는 방법이 있습니다. 이때, console 창에 출력하고 싶다면 "logging.StreamHandler()"함수를, 특정 파일에 출력하고 싶다면 "logging.FileHandler()"함수를 이용하면 됩니다.
앞서 설정한 logging message 형태와 출력방식을 "setFormatter(formatter)" 함수로 세팅해줍니다.
마지막으로 "addHandler"를 통해 logging 객체(=logger)에 추가시켜 줍니다.
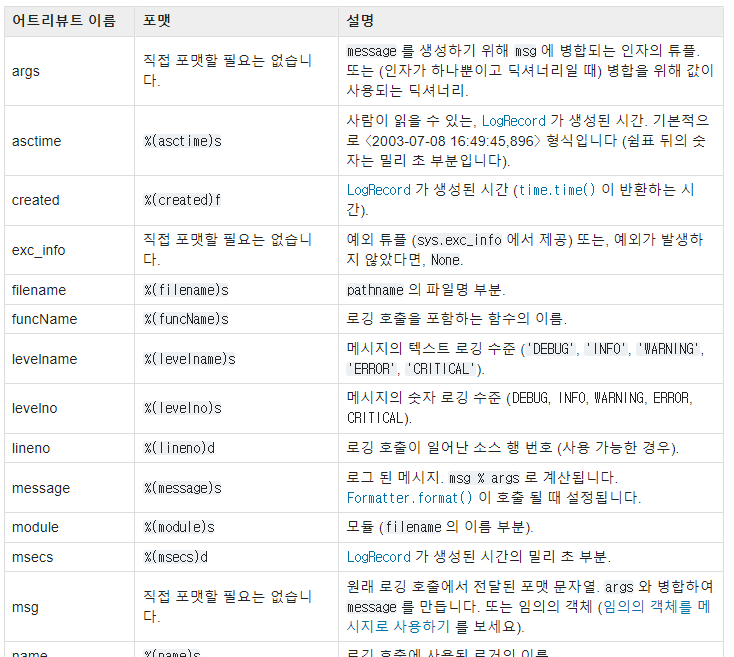
참고로 logging.Formatter의 attribute에 대한 설명은 아래 사이트를 참고 하시는걸 추천합니다.
이번 글에서는 YOLO V3 object detection "TECH REPORT"를 설명하려고 합니다.
지금까지 리뷰한 object detection 모델은 어떤 학회나 저널에 제출된 논문들이었습니다.
하지만, YOLO V3 저자는 YOLO V3가 YOLO V2를 약간 업데이트한 버전이라서 논문이 아닌 TECH REPORT 개념으로 작성한다고 언급했습니다.그래서, 현재 어떤 학회에 제출되지 않고 arXiv에만 올라와 있는 상태 입니다.
그렇게 때문에 YOLO V2를 잘 이해하고 있으시다면 어렵지 않게 이해하실 것으로 판단됩니다.
그럼, 지금부터 YOLO V3 TECH REPORT를 리뷰해보도록 하겠습니다.
Paper: YOLOv3: An incremental Improvement
2018. 04. 08 arXiv
[영어단어 및 표현 정리]
Incremental: Incremental is used to describe something that increases in value or worth, often by a regular amount.
0. Abstract
YOLO V3는 YOLO(V2)의 디자인을 약간씩 변경했다고 언급하고 있습니다. 대표적으로 변경한 부분은 새로운 네트워크 부분인데, 뒤에서 자세히 언급하겠지만 YOLO V2에서 사용했던 darknet19을 darknet53으로 발전시켜 YOLO V3의 backbone 네트워크로 사용했습니다.
이러한 변경들로 인해 YOLO V2에 비해 모델이 약간 커지긴 했지만 정확성이 높아졌다고 합니다.
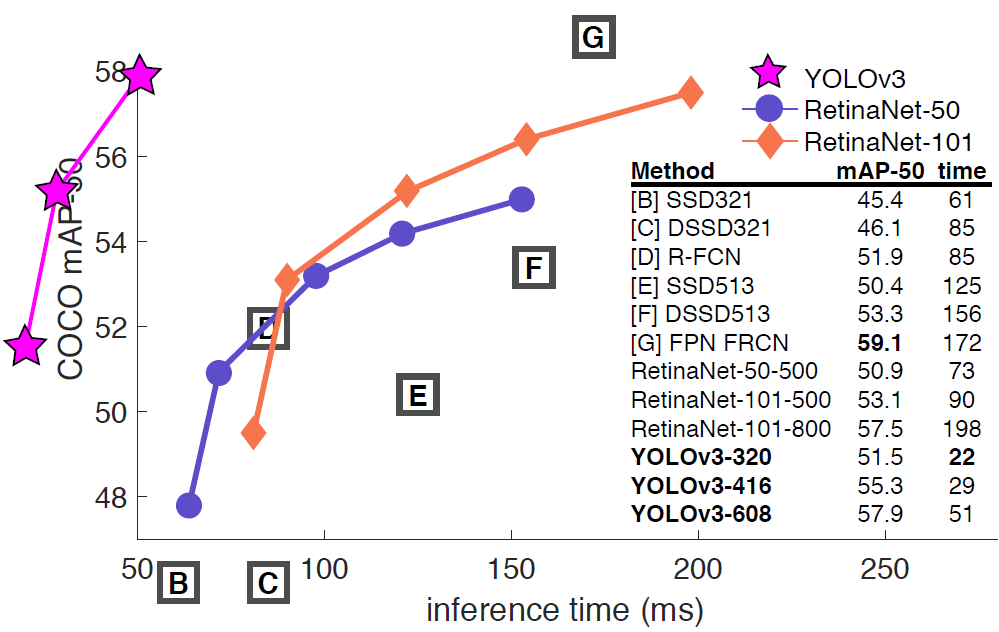
320×320 (input resolution) YOLO V3 performance
Speed1 (mAP 기준): 22ms ← three times faster than SSD
Accuracy1 (mAP 기준): 28.2 mAP ← same as SSD
Speed2 (\(AP_{50}\) 기준):: 51ms (on Titan X) ← about four times faster than RetinaNet
Accuracy 2 (\(AP_{50}\) 기준):: 57.9 \(AP_{50}\) ← same as RetinaNet
이 논문에서는 YOLO V3를 mAP가 아닌 \(AP_{50}\)를 강조하고 있는데요. 이 이유에 대해서는 뒤에서 자세히 설명하도록 하겠습니다.
[영어단어 및 표현 정리]
swell: an old word that basically means fantastic, generally used by old people or hipstersto try to sound hip.
YOLO V3 글 자체가 TECH REPORT다 보니까 슬랭(slang)어를 자주 사용하는 경우가 있습니다. 그래서, 공식사전같은 곳에서 swell의 뜻을 대입해 해석하면 이상해지는 경우가 많죠. 보통 영어 슬랭어는 Urban dictionary 라는 사전을 이용하면 잘 찾을 수 있습니다.
역시 official paper가 아니기 때문에 처음에 친숙한 어투로 글 전개를 시작 하는것 같습니다.
"가끔 그냥 너도 1년 동안 다른 짓만 할때도 있잖아? 나도 올해에는 research 많이 안하고 트위터만 한 듯... 뭐 물론 GAN 같은 것도 조금 해보긴 했지만...."
"그래도 여력이 조금 남아있어서 YOLO (V2) 성능을 조금 개선시키긴 했어~"
"근데 뭐 막 엄청 interesting한 기법을 쓴건 아니고, 조금씩 변화만 줘서 실험했어~"
[영어단어 및 표현 정리]
kinda: (구어) kind of ((발음대로 철자한 것))
momentum: If a process or movement gains momentum, it keeps developing or happening more quickly and keeps becoming less likely to stop. (=impetus)
[두 번째 문단]
대부분 학회에서는 "Camera ready due"가 있습니다.
학회같은 곳에서 다루는 paper 종류는 두 가지 입니다.
Accepted paper
Camera-ready paper
아래 그림1을 보면 "Paper Submission Deadline"이라고 나와있을 겁니다. 일반적으로 학회에 제출하여 논문에 accept되면 이를 "Accepted paper"라고 합니다.
그런데, "accepted paper"를 최종 인쇄하기 위해서는 "폰트 종류, 크기", "대소문자" 등의 양식을 다시 통일시켜주어야 합니다. 이때 최종 인쇄를 위해 통일된 양식으로 바꾼 paper를 "Camera-ready paper"라고 보시면 됩니다.
그림1. CVPR (2021) Submission Timeline
YOLO V3 저자가 Camera-ready를 하긴했지만, "a source"가 없어서 TECH REPORT로 내기로 했다고 한 것 같네요. (정확히 "a source"가 무엇을 의미하는지는 모르겠습니다....)
[세 번째 문단]
이 tech report는 크게 세 가지 section으로 구성되어 있습니다.
Deal: Method (YOLO V3에 대한 전반적인 architecture를 설명)
How we do: Experiment (YOLO V3 결과 해석)
Things we tried that didn't work: Ablation Study 개념
What this all means: Conclusion + 기존 evaluation 방식 불만 제기
[영어단어 및 표현 정리]
intros: an introduction의 복수형
y'all: you-all의 축약형
contemplate: 생각하다
2. Deal
Section2("2. The Deal) 에서는 YOLOv3의 아키텍처에 대해 설명합니다. Secion2 구성을 미리 설명하면 다음과 같습니다.
2.1. Bounding Box Prediction: 제목 그대로 bbox prediction 할 때 사용되는 수식들을 설명합니다 (미리 말씀드리면, 이 부분은 YOLOv2와 동일합니다.
2.2. Class Prediction
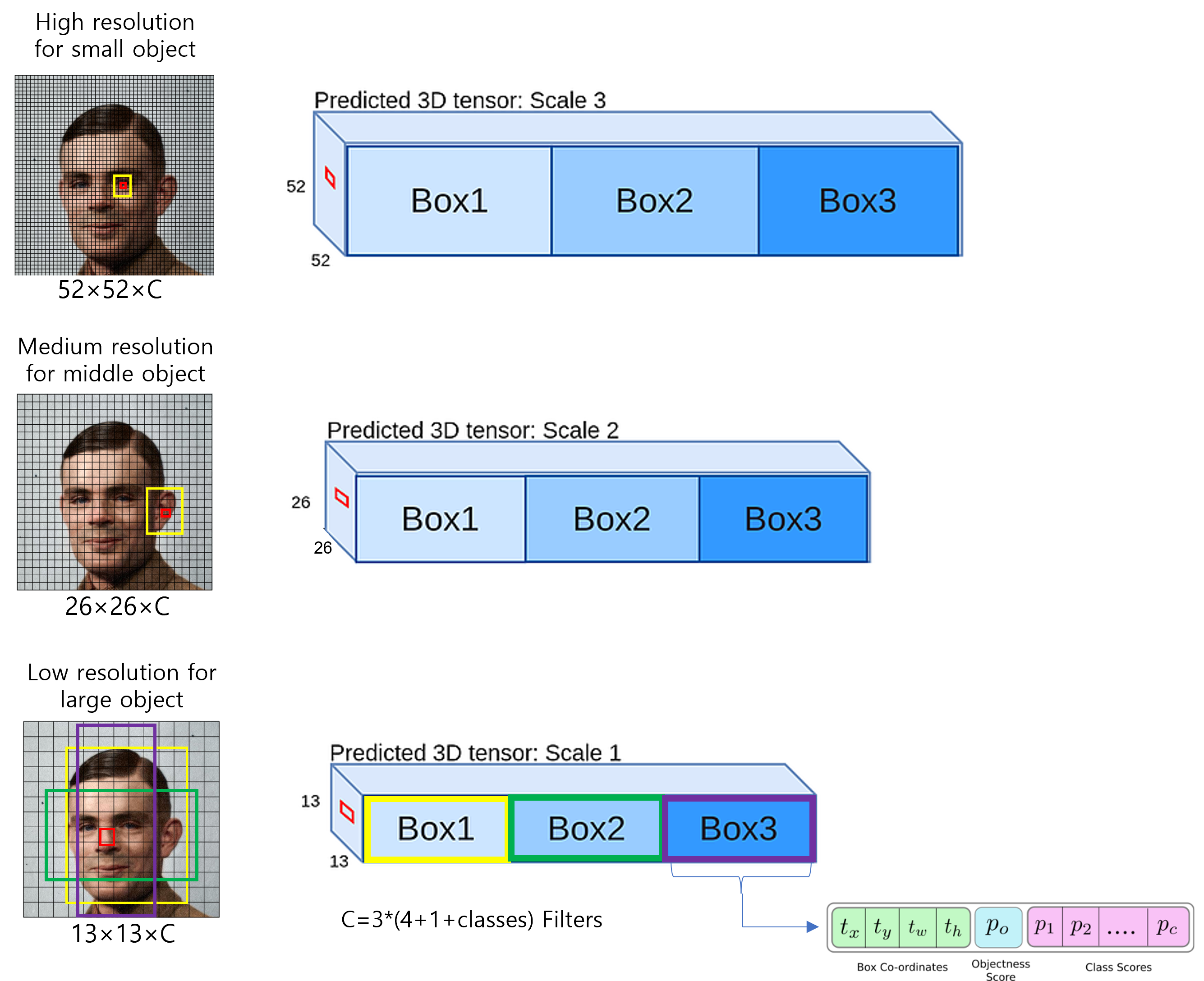
2.3. Predicitons Across Scales: darknet-53으로 feature extraction 한 후, bounding box를 찾을 때 다양한 resolution에서 boundinb box를 찾는 방식을 설명합니다. 이 부분이 YOLOv2와 다른 첫 번째 특징입니다.
2.4. Feature Extractor: YOLOv2에서 feature extractor로 사용한 darknet-19를 업그레이드 한, new classifier인 darknet-53을 소개 합니다. 이 부분이 YOLOv2와 다른 두 번재 특징입니다.
2.5. Training: YOLOv3를 어떻게 학습시켰는지 설명합니다.
제가 글을 읽어보면서 순서를 조금 변경시키면 좋겠다고 판단하여, 이 블로그에서는 순서를 아래와 같이 변경하여 설명하려고 합니다.
2.4. Feature Extractor
2.3. Predictions Across Scales
2.2. Class Prediction
2.1. Bounding Box Prediction
2.5. Training
2-4. Feature Extractor
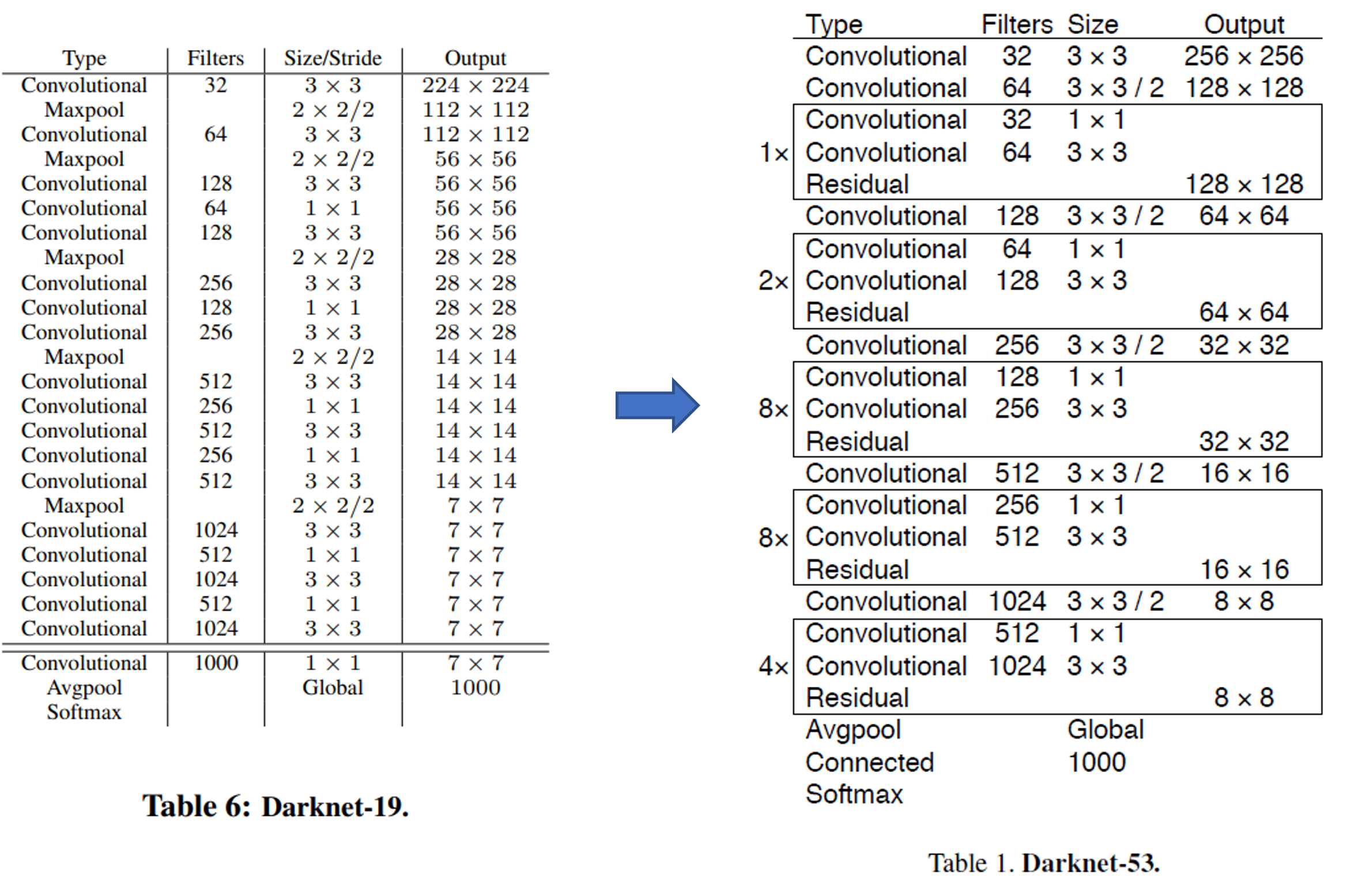
YOLO V2에서는 feature extractor로써 darknet-19를 사용했었습니다. 아래 그림(테이블)에서 darknet-19를 보면 convolutional layer가 19개인 것을 확인할 수 있습니다. YOLO V3에서는 residual connection을 이용하여 layer를 더 deep하게 쌓게 되었고, 그 결과 darknet-53을 만들 수 있게 되었습니다. 아래 그림에서 darknet-53은 convolutional layer가 총 52개인데, 아마 Avgpool(=average pooling layer) 직전에 1×1×1000 convolutional layer가 생략된 듯 합니다. 이렇게 추측한 이유는 다음과 같습니다.
Connected가 softmax 직전에 위치한 것을 보면 logit인 것을 알 수 있습니다.
Connected는 average pooling 결과라고 볼 수 있는데, 아래 그림상으로는 average pooling에 들어가기 직전의 convolutional channel 수 는 1024개 입니다.
Average pooling 연산 후 1000개의 neuron을 출력하기 위해서는 입력 직전의 convolutional channel 수가 1000개여야 하기 때문에, 1000개의 채널을 갖는 1×1 convolutional layer가 생략되었다는걸 추측 할 수 있습니다.
즉, 아래 그림의 convolutional layer 총 개수와 Avgpool 직전에 생략된 하나의 1×1 convolutional layer를 더하면 총 convolutional layer 개수가 53개인 것을 확인할 수 있습니다.
(참고로, Size 부분에 "/2"라고 되어 있는 부분은 convolution filter의 stride=2라는 뜻입니다. Pooling이 아닌 conv filter의 stride를 통해 downsampling을 진행했네요)
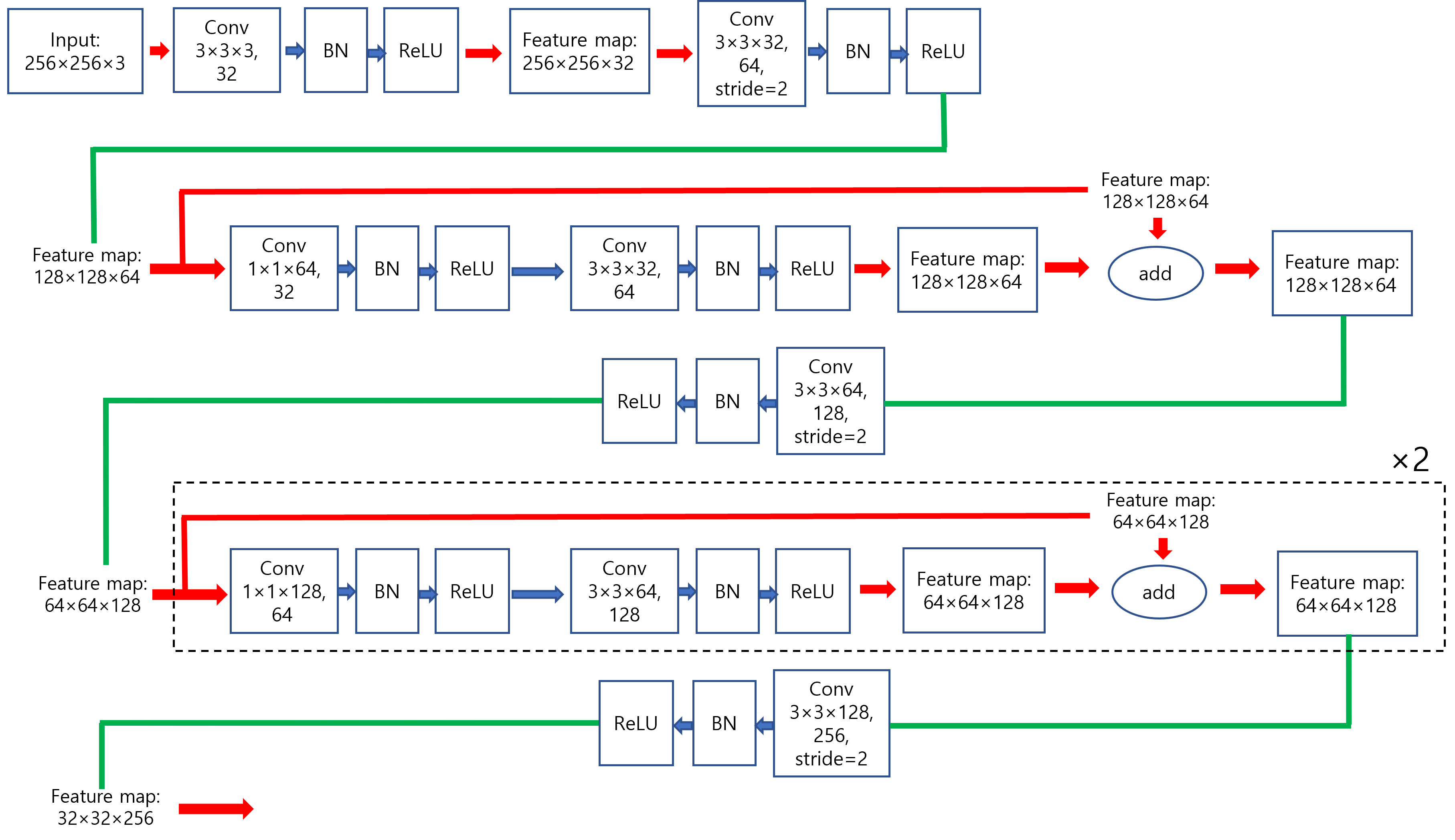
Darknet-53을 자세히 도식화하면 다음과 아래 그림과 같이 표현할 수 있습니다. (제가 임의대로 그린거라 틀린부분이 있으면 말씀해주세요!)
그림2
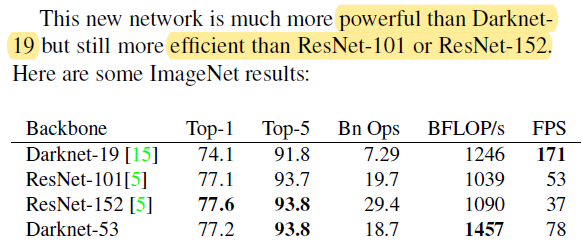
위의 결과표를 보면 darknet-53이 darknet-19보다 좋은 accurcay를 기록하고 있다는걸 알 수 있습니다. ResNet-152보다는 accuracy가 조금 떨어지기는 하지만 더 효율적이라고 하는데, 이 부분은 바로 다음 문단에서 설명하도록 하겠습니다.
Darknet-53이 ResNet 모델들 보다 efficient하다고 하는 이유는 FPS, BFLOP/s 에 있습니다 (BFLOP의 B는 Billion의 약자입니다. FLOPS에 대한 설명은 아래 글을 참고해주세요!)
컴퓨터가 초당 연산할 수 있는 능력을 "BFLOP/s"로 나타내는데, "BFLOP/s"가 높을 수록 GPU가 1초에 더 많은 연산을 실행해준다는 것과 같으니 GPU utilization을 잘 활용한다는 것을 뜻하기도 합니다. 결국, darknet-53이 ResNet-152보다 성능이 약간 떨어지긴 해도 (개인적으로는 0.4%의 오차는 편차에 따라서 큰 의미가 없을 수 있다고 생각하긴 합니다만...), FPS (or GPU utilization)이 월등이 높기 때문에 더 "efficient"하다고 주장하는 것이지요.
[영어단어 및 표현 정리]
newfangle
형용사로 쓰이는 경우: Eager for novelties; desirous of changing
동사로 쓰이는 경우: To change by introducing novelties
2-3. Predictions Across Scales
위의 두 문단을 정리한 그림을 도식화해서 보여드리겠습니다. (아래 그림에서 "conv[3,3,32,64]/2"라고 되어 있는 부분에서 "/2"가 의미하는 바는 conv filter의 stride가 2라는 뜻힙니다 (즉, conv filter의 stride를 크게 설정함으로써 downsampling을 해주겠다는 뜻이죠))
<그림3 이미지 출처: https://arxiv.org/ftp/arxiv/papers/1812/1812.10590.pdf>
<그림4 이미지 출처: https://blog.paperspace.com/how-to-implement-a-yolo-object-detector-in-pytorch/>
우선 저 "We perform the same design~ " 문단은 정확히 무엇을 의미하는 내용들인지 모르겠네요.
"We still use k-means ~" 문단은 YOLOv3가 학습 전에 bounding box의 aspect ratio를 각 scale마다 어떻게 설정해 줄 지 사전정의한 hyper-parameter 입니다. (제 생각으로는, (10×13), (16×30), (33×23) 이렇게 3개는 small object (52×52 feature map과 관련된 bounding box 정보인듯 합니다. 아니라면 답변주세요!)
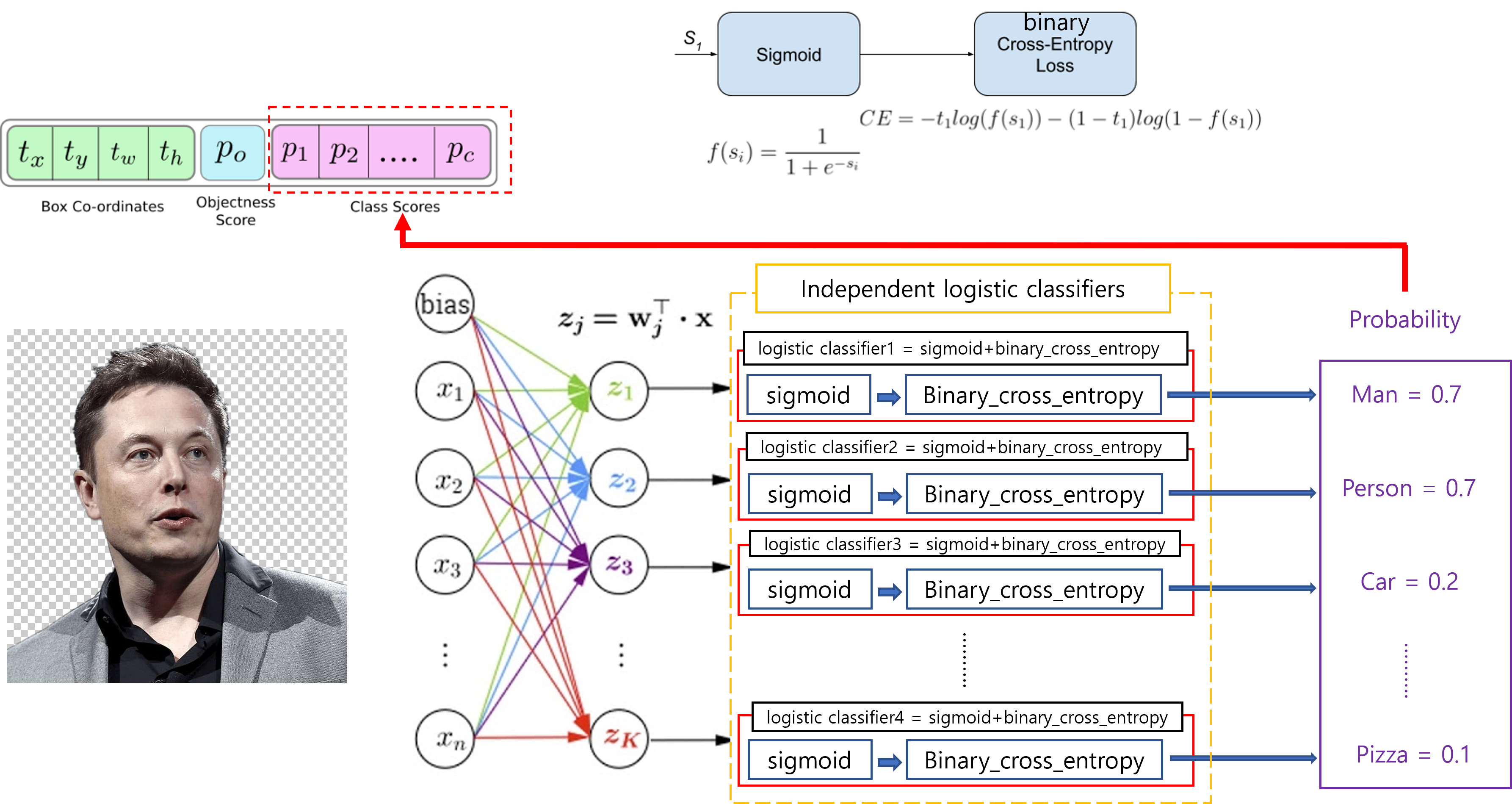
2-2. Class Prediction
우선 위의 문장에서 의미하는 바들을 이해하기 쉽게 풀어서 설명해보도록 하겠습니다.
COCO dataset은 80개의 클래스를 갖고 있습니다. 즉, COCO dataset의 이미지들을 분류하겠다는 것은 80개의 class들을 분류하는 multi-classification task인 것이죠. 그런데, 80개의 클래스들이 모두 서로 전혀관계가 없는 것은 아닙니다. 예를 들어, 80개에 "Person", "Man"이라는 클래스가 포함될 수 도 있는데, 이 두 클래스는 서로 독립적인 클래스가 아니죠. 왜냐하면, "Man"은 "Person"의 부분집합 개념이기 때문입니다. 그래서, '앨론 머스크' 이미지를 classification하면 "Man"이 나올 수 도 있고, "Person"이 나올 수 도 있는 것이죠. (보통 이러한 관계를 지닌 클래스들은 서로 hierarchy한 구조를 갖고 있다고 합니다)
일반적으로 classification 방식은 softmax를 취해준 후, cross entropy를 계산하는 경우가 대부분입니다. 그런데, softmax를 취해주면 logit값(=softmax 입력 값: \(z_{i}\))이 제일 높은 하나의 클래스 확률 값만 지나치게 높게 설정해주는 경우가 있습니다. 이렇게 하나의 클래스 확률 값만 높여주는 이유는 입력 이미지에는 하나의 클래스만 있을 것이라는 가정을 하기 때문입니다.
<그림5 이미지 출처: https://gombru.github.io/2018/05/23/cross_entropy_loss/>
그런데, 앞서 설명했듯이 위의 '앨론 머스크' 이미지는 두 가지 클래스(=레이블)를 갖고 있을 수 있다고 했습니다. 즉, muti-label 이미지인 것이죠. 그래서, 이 경우는 multi-label을 모두 정확하게 예측하기 위해서 independent logistic classifiers를 사용합니다.
<그림6>
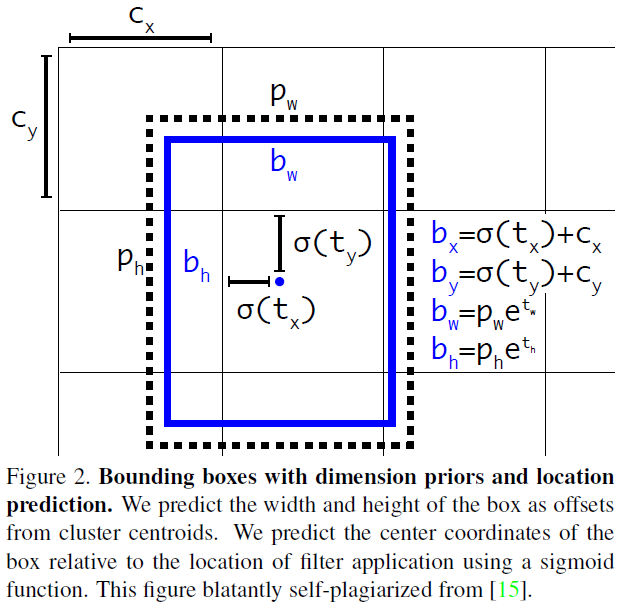
2-1. Bounding Box Prediction
※"2-1.Bounding Box Prediction" 파트는 총 두 문단으로 구성되어 있는데, 여기에서는 문단 순서를 바꾸어 설명하도록 하겠습니다.
위의 문장을 요약하면 아래 그림으로 표현할 수 있습니다.
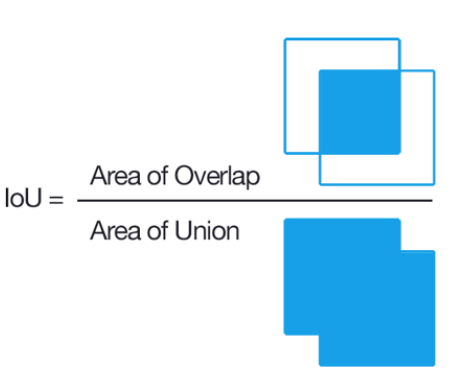
YOLOv3는 한 번 연산할 때, feature map의 한 cell당 총 3개의 box에 해당하는 3d-tensor들을 출력합니다. 이론적으로, 한 번 학습 시 생성되는 bounding box 개수는 (10647=52×52×3+26×26×3+13×13×3) 일겁니다. 여기서 IOU가 제일 높은 box의 3d-tensor만 loss function을 위해 사용하게 됩니다. 또한, IOU가 제일 높은 3d-tensor의 objectness score(=confidence score)를 1로 설정해줍니다. (이 과정을 굉장히 간단하게 설명했지만, 실제로 bounding box 후보군을 가려내는 작업은 훨씬 복잡합니다. 이 부분은 코드 구현 부에서 좀 더 자세히 다루도록 하겠습니다)
<그림7>
YOLOv3에서는 IOU의 threshold를 0.5로 설정하고 있습니다. 그렇기 때문에, 초기에는 10647개 box들의 IOU가 모두 0.5가 넘지 않을 수 도 있습니다. 이 경우에는 아래 YOLO loss에서 objectness loss 부분을 제외한 regression loss, classification loss를 발생시키지 않습니다. (아마, loss를 발생시키지 않는다는 것은 loss 값을 0으로 할당시켜준다는 뜻 같은데, 이 부분은 코드를 리뷰하면서 더 자세히 살펴보도록 하겠습니다. (사실 엄밀히 말하면 아래 수식은 YOLOv1의 loss function입니다. 실제로는 시그마 부분이 좀 변경되어야 할 것 같네요.)
<그림8>
이 부분은 YOLOv2와 똑같기 때문에 설명을 더 하지는 않겠습니다.
(↓↓↓아래 글에서 "3-3) Direct location prediction" 부분을 참고해주세요!↓↓↓)
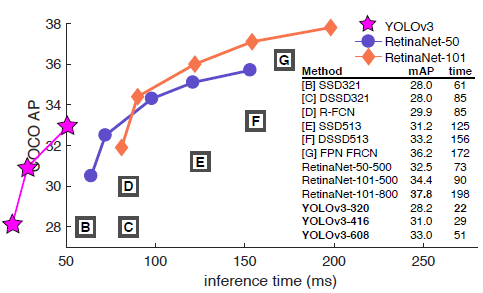
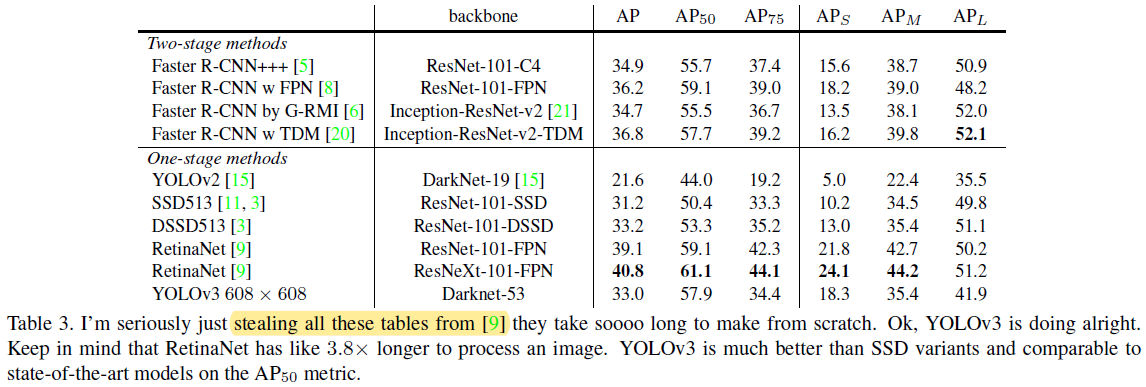
COCO dataset의 mAP 성능을 살펴보니 SSD variants (SSD513, DSSD513)와 동일한 반면 속도는 3배더 빨랐다고 합니다. 하지만, 여전히 RetinaNet의 mAP 성능을 뛰어넘진 못했네요. (YOLO v3 저자는 mAP 방식의 evaluation 방식이 "weird"하다고 표현했는데, 그 이유는 "5.What This All Means"에서 설명드리도록 하겠습니다)
[영어단어 및 표현 정리]
on par with: ~와 동등(대등)한
(※아래 "stealing all these tables from [9]" 표현은 RetinaNet 모델 결과는 RetinaNet 논문 [9]에서 그냥 가져온거라고 합니다. RetinaNet을 Scratch로 구현하려면 너무 오래 걸린기 때문에 이렇게 했다고 하네요)
그림?
[두 번째 문단]
하지만, \(AP_{50}\)을 기준으로하면 YOLOv3의 성능은 RetinaNet과 동등해집니다. 하지만, IOU의 threshold를 올리면 AP 성능이 급격히 떨어지는데, 이러한 것으로 보아 YOLOv3 모델이 어떤 객체를 완전히 "fit"(정확)하게 detect하지 못하는걸 알 수 있습니다.
그림?+1
[영어단어 및 표현 정리]
on par with: ~와 동등(대등)한
excel at ~ing: ~하는 것이 뛰어나다
[세 번째 문단]
위의 그림?(Table 3)을 보면 예전 YOLO(v2) 같은 경우에는 small object에 대한 성능이 매우 안좋았음을 알 수 있습니다. "2.3. Predictions Across Scales"에서 언급된 multi-scale predictions을 이용해 small object에 대한 AP (\(AP_{S})\)를 향상시킬 수 있었습니다.
하지만, medium, large size objects의 detection 성능 향상 정도가 small object 성능 향상 정도에 미치지 못했다고 합니다. (개인적으로는 뭐... 당연한거 같다는 생각이... YOLO V2에서 multi-scale을 쓰지 않았으면 small object를 아예 놓치는 경우가 있을 수 있을테니, 이런 경우에 mAP를 성능을 크게 깍아먹지 않았었을까라는 생각이 드네요.)
[영어단어 및 표현 정리]
get to the bottom of it: 진상을 규명하다; 진짜 이유를 찾아내다.
"get to the bottomof ~"의 본래 뜻은 ~의 바닥까지 본다입니다. 진상을 확인 하는 것도 보이지 않는 밑바닥까지 살펴보는 행위라고 볼 수 있기 때문에, 관용어구로 사용됩니다.
[세 번째 문단]
(논문에서 "see figure 5"라고 했는데, 제가 봤을 땐 오타 같습니다. "see figure 3"이 맞는듯 하네요.)
확실히 mAP보다 mAP-50 지표로 보면 YOLOv3의 성능이 굉장히 좋게 보입니다.
mAP-50 기준 결과mAP 기준 결과
4. Things We Tried That Didn't Work
이 부분은 오히려 설명을 하는게 YOLOv3를 이해하는데 더 혼동시킬 수 도 있다고 생각하여 따로 글을 올리진 안았습니다. 아래 영상 "24:38~27:00"를 참고하시는게 더 좋을 듯 합니다.
5. What This All Means
[첫 번째 문단]
저자는 YOLOv3가 mAP와 \(AP_{50}\) 간의 성능차가 심하게 나는 것을 강조하고 있습니다.
[두 번째 문단]
mAP 성능이 안좋아서 그런지.... ,mAP를 evaluation 지표로 사용하는 것에 대한 불만을 제기하는데, 그 이유는 아래와 같습니다.
"사람도 50% IoU와 30% IoU를 잘 구분하지 못하는데, 즉 20% 차이나는 IOU gap도 구별을 못하는데, 50%, 55%, 60%, ..., 95%씩 나눠서 평가하고 mAP을 구하는게 무슨 의미가 있는거냐"
저자는 추가적인 (좀 더 근본적인) 이유도 이야기를 하는데, 그 내용은 뒤에 "6.Rebuttal"에서 설명하도록 하겠습니다.
[영어단어 및 표현 정리]
cryptic: A cryptic remark or message contains a hidden meaning or is difficult to understand.
[세 번째, 네 번째, 다섯 번째 문단]
그리고, 자신이 개발 중인 기술에 대한 근원적인 질문을 합니다.
"우리가 object detection 기술을 가졌으니, 그걸로 뭘 할거냐?"
이 질문과 함께 자신이 개발한 기술이 privacy를 침해하는 데 사용될 수 있고, 사람을 죽이는 military 목적으로 사용될 수 있다는 것을 우려하고 있습니다. 해당 기술 (Object Detection)은 동물원의 얼룩말 수를 세는 것이나, 자신들의 애완동물을 잘 찾을 수 있는 용도로 사용되어야 한다고 강조합니다. 그리고, 이러한 방향으로 기술이 개발되도록 책임의식을 갖어야 한다고 주장하면서 글을 마무리합니다. (트위터도 끊을 거라고 하네요.. 근데, 2020년에 트위터 내용을 보니 못 끊은건지... 다시 가입한건지..)
6. Rebuttal
Reference 뒷 부분을 보면 "Rebuttal"이라는 section이 있습니다. 일반적으로 저자가 논문이나 자신의 article을 제출하면 reviewer들이 comment를 남깁니다. 그럼, 저자는 해당 comment에 대한 답변을 해야하는데 이러한 답변을 보통 "Rebuttal Letter"라고 부릅니다. 보통 답변을 할 때는 두 가지의 제스처를 취할 수 있습니다.
수락: reviewer들로부터 피드백 받은 comment들 기반으로 잘 내용들을 업데이트 하겠다.
반박: reviewer들이 comment한 것을 동의하기 어려운 경우도 있습니다. 이 때는 동의하지 않는 이유를 설명합니다.
YOLO V3 tech report에서는 저자가 따로 comment 받은 내용과 자신의 rebuttal letter를 "Rebuttal" section으로 만들어 공개했습니다. (첫 번째 문단을 보면 ICCV에 제출한건지......)
첫 번재 문단은 따로 설명하지 않겠습니다. YOLO랑 크게 관련 없는 내용이라....
[첫 번째 문단 관련 영어단어 및 표현 정리]
shouts: shout이 보통 복수형으로 쓰이면 '외침'이라는 뜻으로 쓰이긴 하는데, 슬랭의 의미로 사용할 때는 누군가가 좋은 아이디어를 낼 때 "that's shouts'라고 사용한다고 하네요.
heartfelt: 진심어린
invariably: 변함없이, 언제나
[첫 번째 Reviewer: Dan Grossman]
첫 번째로 받은 comment는 "Figure 1, 3"에 대한 지적입니다. "Figure1", "Figure3" 두 그림을 보면 YOLOv3 그래프의 X축이 0부터 시작하지 않습니다.
그래서, 이러한 comment를 받아들여, 아래와 같은 "Figure 4"를 만들어 제공했습니다.
[첫 번째 Reviewer관련 용어]
AKA: 일명 ~로 알려진 (as known as ~)
throw in ~: ~를 덧 붙이다.
[두 번째 Reviewer: JudasAdventus]
JudasAdventus라는 사람이 "the arguments against the MSCOCO metrics seem a bit weak."라고 comment 해준 것 같은데, 뭔가.. YOLO v3 저자가 굉장히 기분 안좋은 것 같은 반응을....(제가 해석을 잘 못 하고 있는건지...) 아마, reviewer가 "COCO 데이터 셋은 segmentation 관련 label도 진행하기 때문에 더 정확한 bounding box 정답 좌표를 갖고 있을 것이기 때문에 COCO metric을 쓰는 것에 대한 반문은 "bit weak"하다고 한 것 같습니다. 그러자, 저자는 그런게 문제가 아니라 mAP 쓰는 것에 대한 정당성 자체에 문제를 제기하고 있는 거라고 반문합니다. (그 이유는 아래 문단에서...)
YOLO v3 저자가 지적하는 바는 다음과 같습니다. Objecet detection 모델은 bounding box loss와 classification loss로 구성된 multi-task learning (← classification 학습도 하고, bounding box regression 학습도 하기 때문에 multi-task learning이라고 부름) 을 하는데, 기본적으로 bounding box regression 부분을 지나치게 강조하면 classification 학습이 잘 안될 수 있다는 것이 문제임을 제기합니다. 현실적으로도 물체를 잘 classification하는게 중요한거지 bounding box의 IoU를 50%, 55%, 60% 이런식으로 타이트하게 맞추는게 더 중요하지 않다고 주장하고 있습니다. (예를 들면, 보행자에서 지나가는 물체가 사람임을 인식하는게 중요한거지 사람에 대한 bounding box를 정확히 치는것이 중요하지 않다는 논리인것 같습니다)
또한, mAP라는 성능 지표자체가 갖고 있는 치명적인 결함은 다음과 같습니다. 아래 그림에서 누가봐도 "Detection #1"의 결과가 "Detection #2"의 결과보다 좋은거 같은데, 실제 "Detection #1"과 "Detection #2"의 mAP 값이 동일하게 나옵니다. 그 이유는 다음과 같습니다.
그 이유는 아래글에서 object detection에서의 precision 개념을 살펴보시면 이해할 수 있으실 겁니다! (간단하게만 말하자면, Detector2의 경우 FN이 많아진 것일 뿐, TP, FP의 개수에는 변함이 없습니다. 그래서, Precision=TP/(TP+FP) 수식 관점에서는 precision은 변하지 않는 것이죠)
위와 같은 이유를 들어 저자는 mAP 성능 지표를 쓰는 것이 현실적으로 의미가 있는거냐라는 질문을 다시 한 번 하고 있습니다.
7. Joseph Redmon quits CV research
YOLO V1부터 YOLO V3까지 개발해왔던 Joseph Redmon은 2020년이 되자 더 이상 CV (Computer Vision) 연구를 진행하지 않겠다고 선언합니다. 자기가 개발하는 CV 기술들이 군사목적으로 사용되는 것도 원치 않고 privacy 문제도에도 영향을 미치는 것 같다고 합니다 (뭐 드론 같은데에 잘 못 쓰이면 심각한 privacy 문제가 생길 수 있죠). 그래서 YOLO를 더 이상 개발하지 않습니다.
하지만, Alexey Bochkovskiy라는 러시아 연구원이 이전부터 YOLO 연구를 계속하고 있었기 때문에, Joseph Redmon이 YOLO 개발 중지 선언한 두 달 뒤 (2020.04.23) YOLO V4를 개발하고 논문화합니다. YOLO V4는 다른 글에서 설명하도록 하겠습니다.
접속을 하시면 아래화면이 처음 등장하게됩니다. 그리고 회원가입 버튼 "Sign up"을 클릭해줍니다.
그림3
그럼 아래와 같이 회원가입 창이 뜹니다. 제 경우에는 github과 연동해서 사용하려 하기 때문에, "Sign up with GitHub"을 클릭해서 사용하도록 하겠습니다.
그림4
그리고 "Authorize wandb" 을 클릭해줍니다.
그림5
마지막으로 아래와 같이 계정생성에 필요한 정보를 입력하시면 회원가입이 완료가 됩니다.
그림6
회원가입 후, 로그인을 하시면 아래와 같은 화면이 나타납니다.
그림7
우선 이 화면은 대기해 놓고 아나콘다 가상환경과 wandb를 연동하는 작업부터 하겠습니다.
2. 아나콘다 가상환경과 wandb 연동하기
앞서 언급했듯이 "아나콘다 가상환경을 VS Code interpreter에 연동시켜 사용하고 있고", Weight and Biases 웹 사이트와 연동하여 visualization 결과"를 볼 수 있기 때문에, 아나콘다 가상환경에서 Weight and Biases 웹 사이트와 연동시켜주어야 합니다.
연동 방식은 간단합니다.
먼저 아래와 같이 순서를 진행합니다.
base 가상환경 프롬프트 열기
wandb login 명령어 입력
아래 빨간색 박스 사이트 복사
그림8
위에서 복사한 사이트 접속시 아래 화면이 출력 해당 인증키 복사
그림9
복사한 인증키 아래 빨간색 밑줄 부분에 붙여넣기하고 엔터 (참고로 저는 복붙이 잘 안돼서 메모장에 복붙한다음 하나씩 인증키를 입력했습니다;;;;)
그림10
연동이 완료 되었습니다!
그림11
3. Project 생성해주기
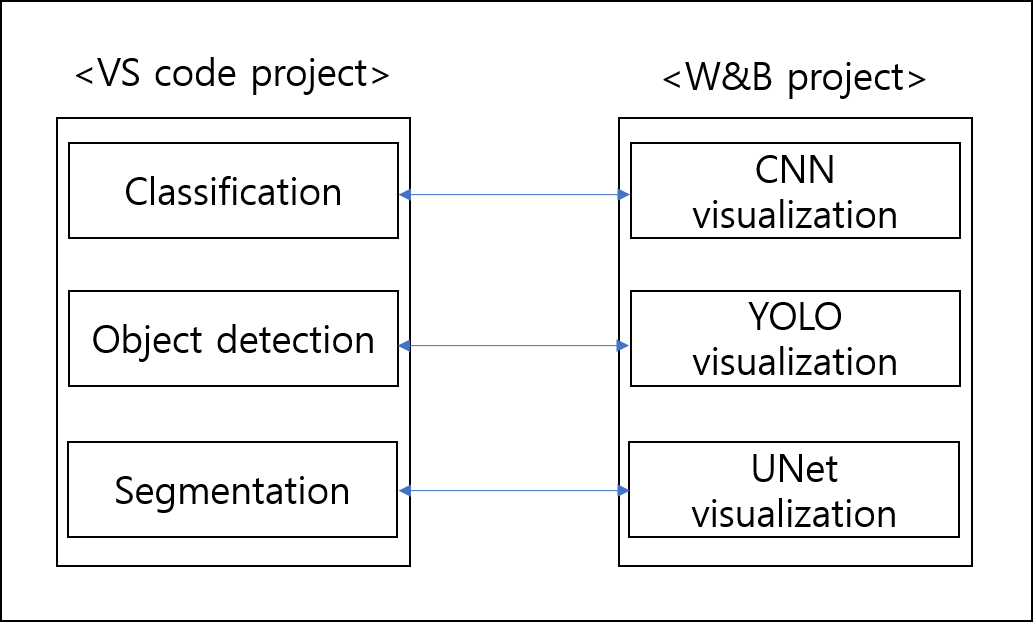
VS Code에서도 task 마다 별도의 project를 만들게 됩니다. 그렇다면 각각의 task마다 visualization 하려는 정보들도 모두 다르겠죠? 그래서, task 별로 wandb의 visualization project를 만들어 주는것이 좋습니다. (그래야 task 마다 visualization 기록들을 용이하게 관리 할 수 있어요.)
그림12
그럼 WandB(=W&B) project를 생성해보겠습니다.
먼저 좌측 상단 "Home" 부분에 "Projects"→"Create new project"를 클릭 해주세요
그림7
아니면 아래 사이트(="wandb.ai/username")에 직접 접속해서 우측에 있는 "Create new project"를 클릭해주세요.
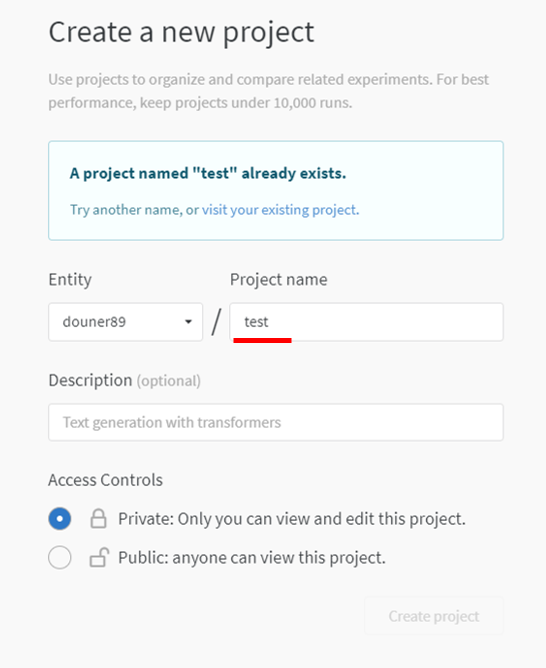
그림13
Project name을 설정하고 생성해줍니다.
우선 저는 개인용으로 사용할 거라 "private" 버전으로 만들었습니다.
그림14
Project가 생성되면 아래 화면이 출력됩니다.
이제 VS code에서 wandb 패키지로 visualization 관련 코드를 입력하고 실행시키면, 아래 화면에 visualization 결과들이 생성됩니다. 그럼 이제 VS code에서 관련 코드들을 입력해볼까요?
그림15
3. VS code에 visualization을 위한 wandb 관련 코드 입력하기
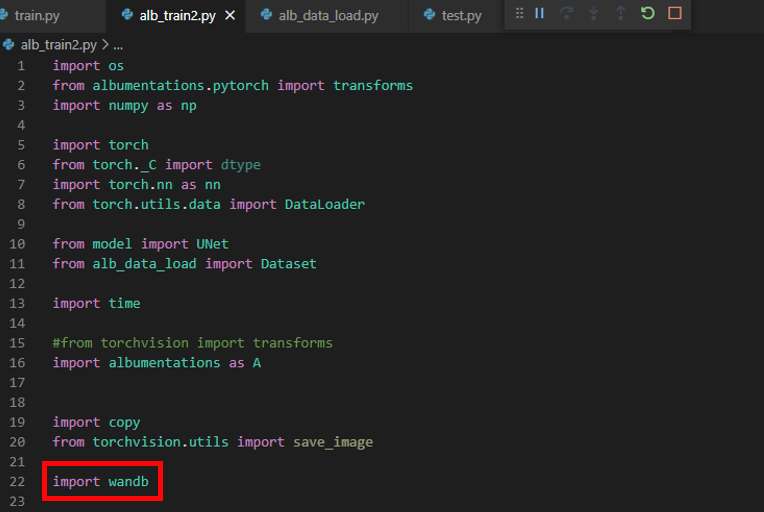
제일 먼저 할 것은 wandb 패키지를 import 시켜주는 것입니다.
현재 "alb_train2.py"에 train 관련 코드가 들어가 있습니다.
("alb_train2.py" 파일은 VS code 상에서 UNet segmentation project에 속해있는데, 해당 project가 base 아나콘다 가상환경 interpreter에 연동되어 있습니다. 앞서 base 아나콘다에 wandb 패키지를 설치했기 때문에 에러없이 import wandb 를 수행할 수 있습니다.)
그림16
그리고 train_model 함수 부분에 먼저 두 개의 코드를 입력해줍니다.
wandb.init()
wandb.watch()
def train_model(net, fn_loss, optim, num_epoch):
wandb.init(project='test', entity='douner89') #추가된 코드
wandb.watch(net, fn_loss, log="all", log_freq=10) #추가된 코드
since = time.time()
best_model_wts = copy.deepcopy(net.state_dict())
best_loss = 100
(※wandb.log() API를 보면 알 수 있듯이 다양한 정보들을 visualization (ex: gradient 'histogram', image, etc...) 를 할 수 있으니 참고해주세요)
# TRAIN MODE
def train_model(net, fn_loss, optim, num_epoch):
wandb.init(project='test', entity='douner89') #추가된 코드1
wandb.watch(net, fn_loss, log="all", log_freq=10) #추가된 코드2
since = time.time()
best_model_wts = copy.deepcopy(net.state_dict())
best_loss = 100
for epoch in range(st_epoch + 1, num_epoch + 1):
net.train()
loss_arr = []
batch_order=0
for batch, data in enumerate(loader_train, 1):
batch_order=batch_order+1
data['label'] = data['label']/255.0
input = data['input']
label = data['label']
# forward pass
label = data['label'].to(device)
input = data['input'].to(device)
output = net(input)
# backward pass
optim.zero_grad()
loss = fn_loss(output, label)
loss.backward()
optim.step()
# 손실함수 계산
loss_arr += [loss.item()]
print("TRAIN: EPOCH %04d / %04d | BATCH %04d / %04d | Batch LOSS %.4f" %
(epoch, num_epoch, batch, num_batch_train, np.mean(loss_arr)))
print("#############################################################")
print("TRAIN: EPOCH %04d | Epoch LOSS %.4f" %
(epoch, np.mean(loss_arr)))
print("#############################################################")
wandb.log({'Epoch': epoch, 'loss': np.mean(loss_arr)}) #추가된 코드3
with torch.no_grad():
net.eval()
loss_arr = []
for batch, data in enumerate(loader_val, 1):
data['label'] = data['label']/255.0
# forward pass
label = data['label'].to(device, dtype=torch.float32)
input = data['input'].to(device, dtype=torch.float32)
output = net(input)
# 손실함수 계산하기
loss = fn_loss(output, label)
loss_arr += [loss.item()]
print("VALID: EPOCH %04d / %04d | BATCH %04d / %04d | LOSS %.4f" %
(epoch, num_epoch, batch, num_batch_val, np.mean(loss_arr)))
epoch_loss = np.mean(loss_arr)
# deep copy the model
if epoch_loss < best_loss:
best_loss = epoch_loss
best_model_wts = copy.deepcopy(net.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val loss: {:4f}'.format(best_loss))
net.load_state_dict(best_model_wts)
return net
4. Visualization 결과보기
다시 weight and biases 사이트 화면으로 돌아오겠습니다.
그림15
4-1. wandb.log() 부분 visualization 하기
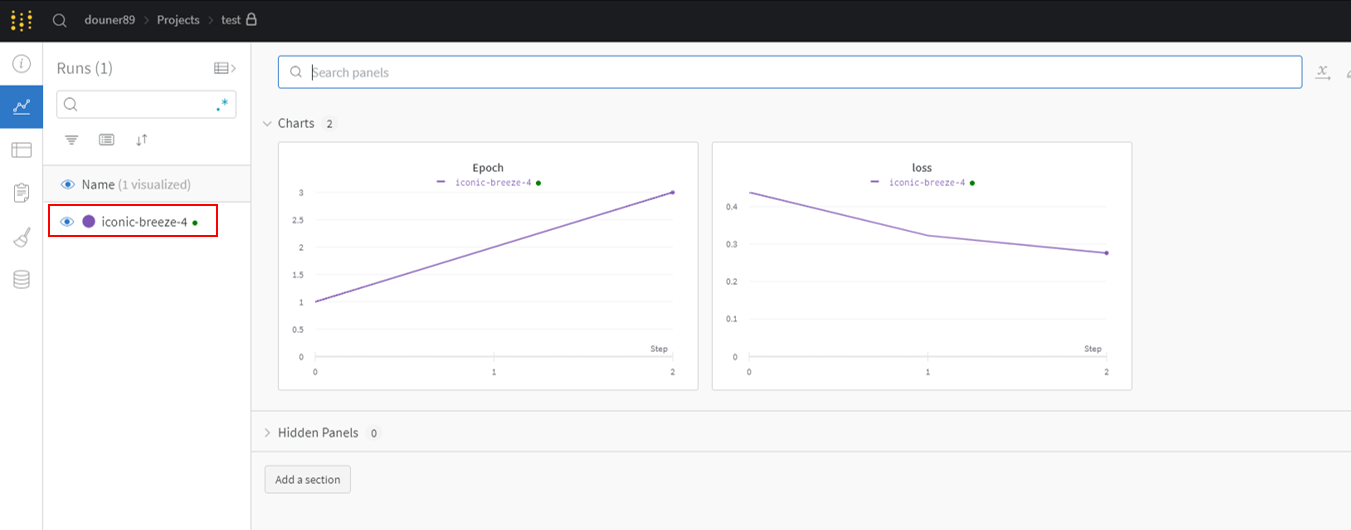
하지만, 코드를 실행시킨 후, charts 부분을 보면 아래와 같이 wandb.log()에 설정했던 log들이 기록됨을 알 수 있습니다. "wandb.log()"에 epoch과 loss를 설정했기 때문에 epoch, loss값이 visualization 되는 것을 볼 수 있습니다.
그림19
4-2. wandb.watch() 부분 visualization 하기 (Feat. gradient)
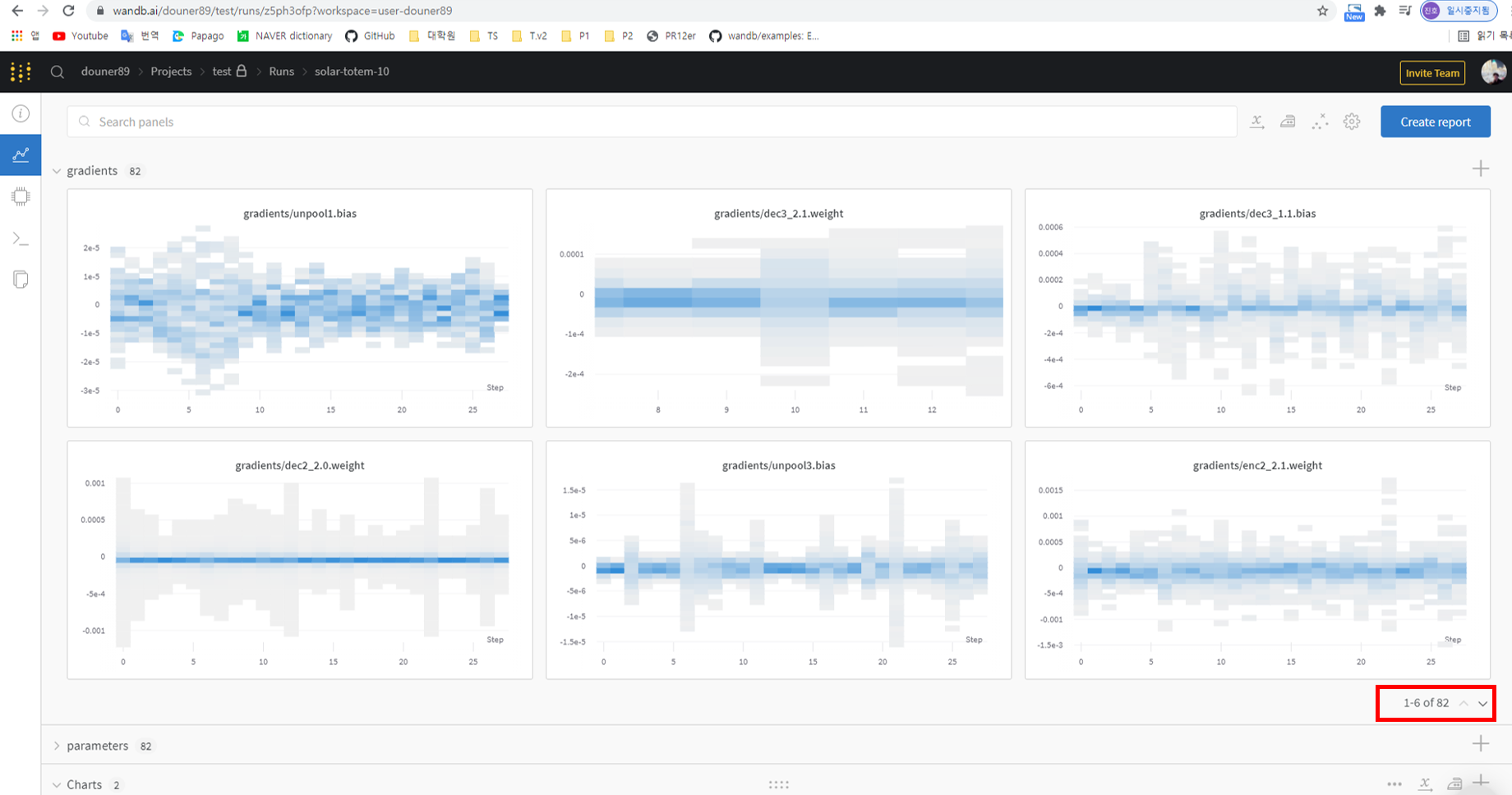
또한, 앞서 "wandb.watch()" 함수를 통해 gradient, parameters 값을 visualization 할 수 있다 언급한 바 있습니다.
먼저, gradient 값부터 확인해보겠습니다.
그림20
아래 그림에서 X, Y축의 의미하는 바는 다음과 같습니다.
X축: epoch (필자의 코드에서는 epoch=30으로 설정되어 있음)
Y축: gradient 값
그림21
앞서 구현한 model의 변수명을 기반으로 해당 위치에 있는 layer에 전파되는 gradient 값을 확인해 볼 수 있습니다.
그림22
5 epoch에 마우스 포인터를 올려놓으면 해당 epoch 단계에서 얻는 gradient 값들의 분포 (histogram) 를 알 수 있습니다.
그림23
그리고 특정 epoch 부분들의 gradient 값을 디테일하게 보고 싶으면 해당 부분을 drag 하면 됩니다.
그림24
또 다른 layer들의 gradient 값을 확인하고 싶다면, 아래 화면의 우측 하단빨간색 부분을 클릭해주시면 됩니다.
그림25
이러한 gradient 값은 다양하게 이용될 수 있지만, 그 중에 가장 대표적인 것이 exploding gradient, vanishing gradient를 확인해보는 것입니다.
예를 들어, conv2 weight의 gradient 값도 대략 10^5로 굉장히 큰데, conv1 weight의 gradient 값이 대략 10^7 이면 exploding gradient를 의심해볼 수 있겠죠?
4-3. wandb.watch() 부분 visualization 하기 (Feat. parameters)
gradient 값 외에, conv filter 값들도 확인해 볼 수 있습니다.
이러한 Conv filter 값들을 통해 유의미한 통계분석도 해볼 수 있겠네요
그림27
5. ETC
위에서 설명한 것 외에 다양한 정보들을 visualization 해서 볼 수 있습니다.
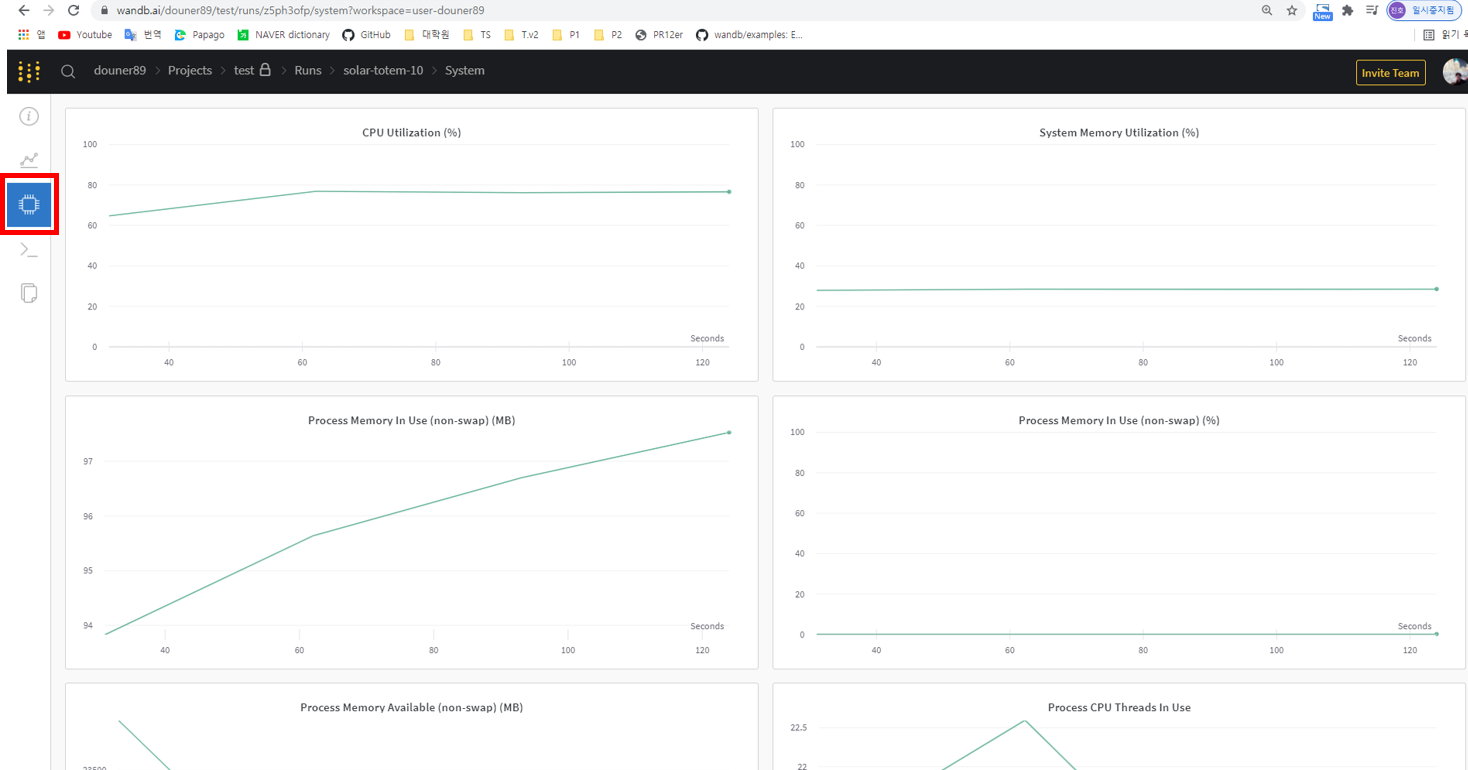
먼저, 왼쪽 빨간색 박스 부분을 클릭하면 system 즉, hardward (CPU, Memory, GPU) 관련 정보들을 살펴 볼 수 있습니다.
그림28
아래 빨간색 네모 박스는 log 관련 정보를 보여주는 곳인데, 학습 시 vs code에 기록되는 log 들을 그대로 볼 수 있습니다.
그림29
6. 다른 결과들과 비교하기
실험을 하다보면 다양한 hyper-parameter 조합을 통해 결과를 내야하는 경우가 많습니다.
앞에서는 learning rate 부분을 1e-3으로 설정하고 실행했습니다.
그렇다면 이번에는 le-2로 설정하고 실행해보겠습니다.
그림30
왼쪽 빨간색 네모 부분에 새로운 process가 실행되는 것을 볼 수 있고, 이전 실험 결과(="solar-toterm-19")와 중첩으로 visualization해서 볼 수 있으니, 비교가 수월할 수 있겠네요.
그림31
하지만 위와 같은 경우 어떠한 hyper-parameter 조합으로 실험한 결과인지 모르기 때문에, 아래와 같이 해당 hyper-parameter 조합에 대한 정보를 process name으로 설정해주면 좋습니다.
그림34
위에서 설명한 방법 외에 다양한 visualization 기능들이 있습니다. 예를 들어, line plot, scatter plot 형태로도 보여 줄 수 있고, GAN 관련한 정보들을 visualization 해줄 수 도 있고, hyper-parameter 중에 중요한게 무엇인지도 알려주는 기능도 있습니다. 이와 관련된 부분은 추후 다루도록 하겠지만, 아래 영상을 보시면 상당 부분 혼자서 하실 수 있을거라 생각됩니다.
사실 wandb 패키지의 가장 강력한 기능은 다양한 hyper-parameter 조합을 자동으로 실행해주고 관련 결과들을 visualization 하여 어떤 parameter가 중요한지 보여주는 것입니다. 이러한 기능은 wandb의 sweep을 통해 구현할 수 있는데, 이 부분은 정리가 되는데로 업로드 하겠습니다.