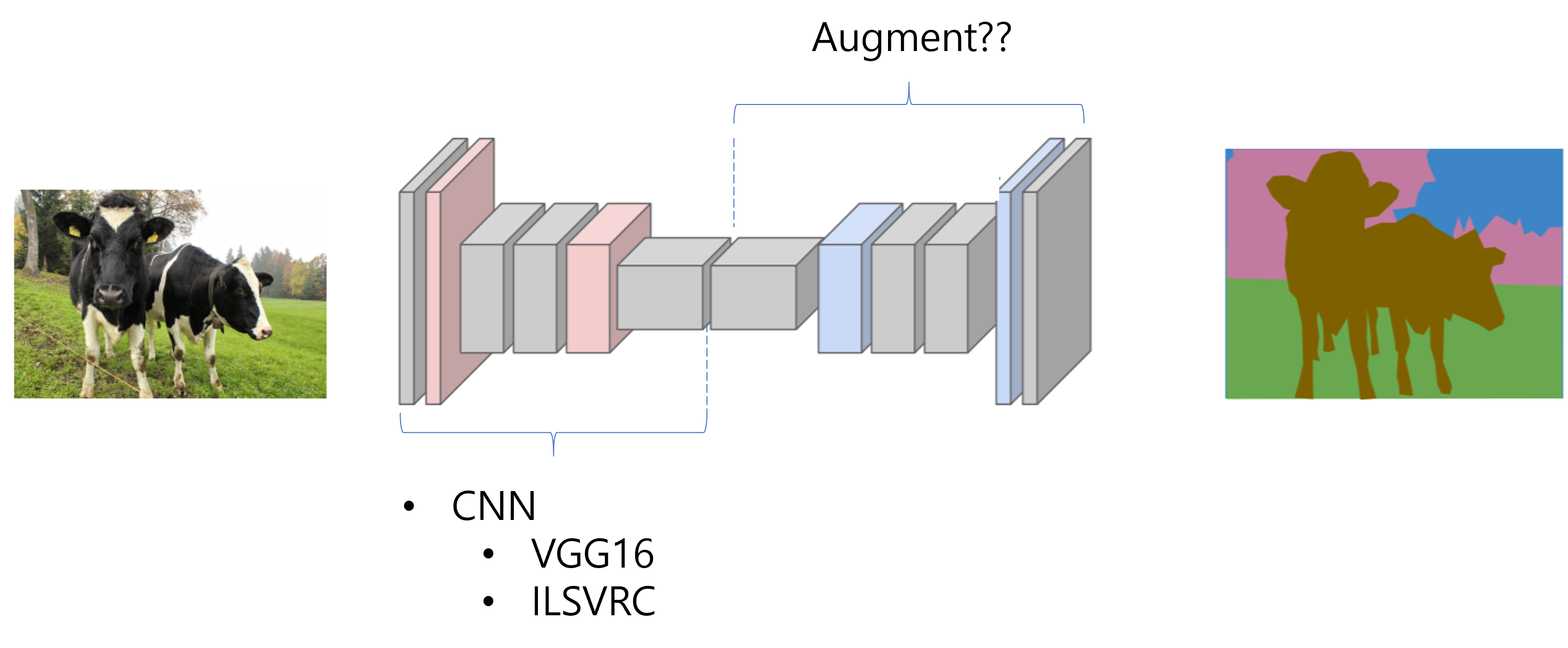
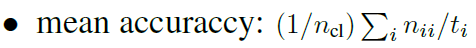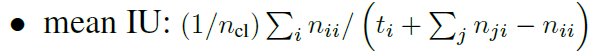지난 글에서 torchvision.transforms를 설명하면서 pytorch가 기본적인 augmentation 기법을 제공해준다고 언급한바 있습니다.
하지만, 기본적인 augmentation 외에도 다양한 영역에서 특수하게 사용하는 독특한 augmentation 기법들이 존재합니다. 예를 들어, Chest X-ray 데이터에는 N-CLAHE라는 독특한 전처리 기법이 있는데, 이러한 전처리 기법은 pytorch에서 기본으로 제공되고 있지 않습니다.
그러므로 별도의 augmentation 패키지를 이용하여 pytorch에 적용해야 합니다. (← transforms.Compose에 연동)
from torchvision import datasets, models, transforms
위의 코드를 보면 torchvision에서 transforms, datasets 이라는 패키지가 사용되었다는걸 확인할 수 있습니다. Pytorch에는 torchvision이라는 패키지를 이용해 다양한 computer vision 관련 task를 수행할 수 있습니다. 각각의 패키지들 (datasets, transforms, models) 에 대해서는 위의 코드를 분석하면서 같이 설명하도록 하겠습니다.
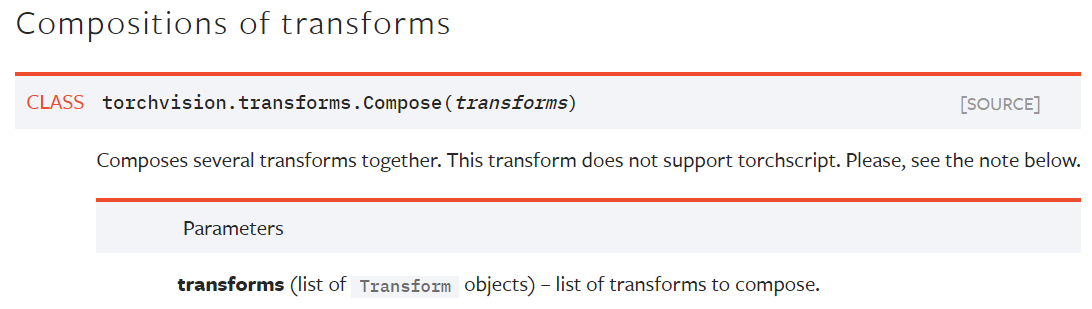
위의 코드를 살펴보면 compose 함수인자에 transforms 객체들의 list를 입력 받습니다.
이것이 의미하는 바가 무엇일까요? 계속해서 알아보도록 하겠습니다.
그림2
그림3
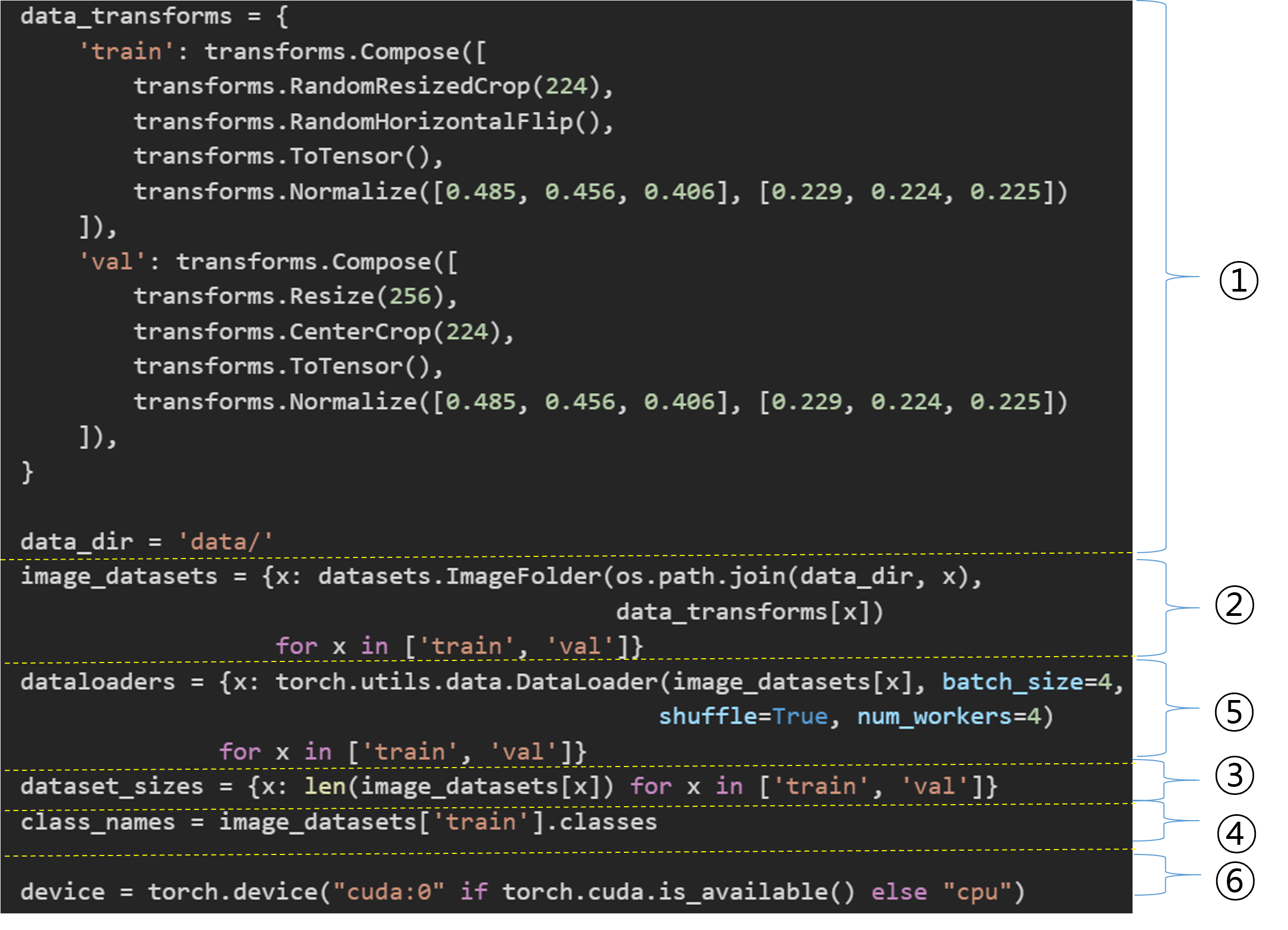
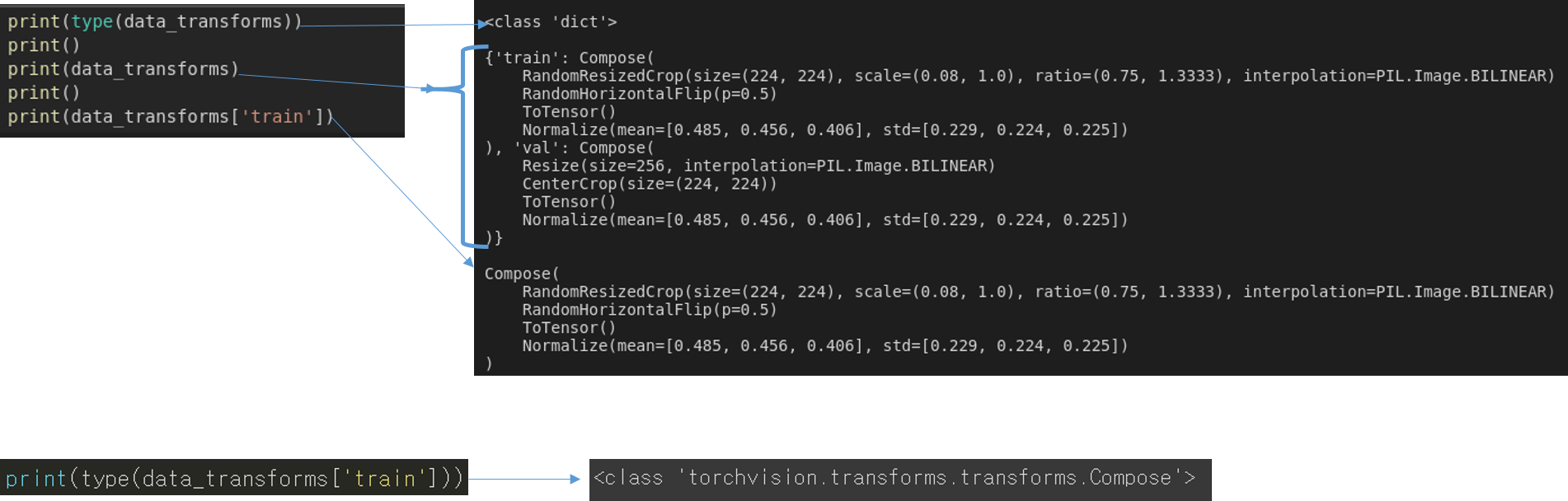
data_transforms 자체는 dictionary로 정의되었습니다.
그리고 각 key에 해당 하는 value 값은 클래스 객체 Compose인 것을 알 수 있습니다.
Compose 객체에 다양한 인자 값들이 포함되어 있는데, 이 인자 값들이 augmentation이 적용되는 순서라고 보시면 됩니다.
EX) data_tranforms['train']의 경우
RandomResizedCrop 수행
scale→ Specifies the lower and upper bounds for the random area of the crop, before resizing. The scale is defined with respect to the area of the original image.
ratio → lower and upper bounds for the random aspect ratio of the crop, before resizing.
RandomHorizontalFlip 수행
p=0.5 → 50%의 확률로 RandomHorizontalFlip 실행
ToTensor 수행
처음 로드되는 이미지 형태를 딥러닝 학습 format에 맞는 tensor 형태로 변경
Converts a PIL Image or numpy.ndarray (H x W x C) in the range [0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0]
Normalize 수행
이미지 전처리 (Preprocessing)
Normalization에 들어가는 값들이 어떻게 계산되는지는 아래 PPT를 참고해주세요.
dataset_size 변수는 딥러닝 모델(CNN)을 학습 시킬 때 epoch 단위의 loss or accuracy 산출을 위해 이용됩니다. (자세한 설명은 train을 구현하는 함수에서 설명하도록 하겠습니다)
그림9
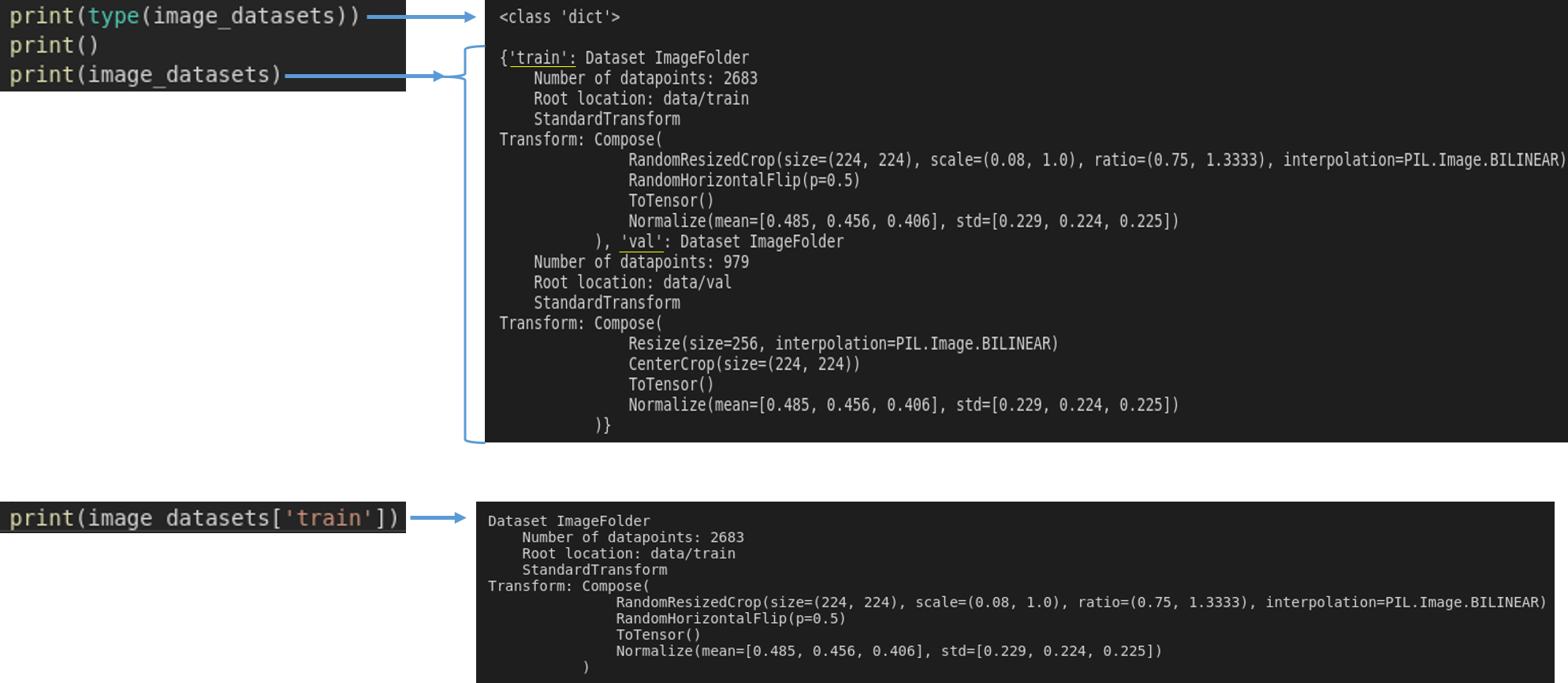
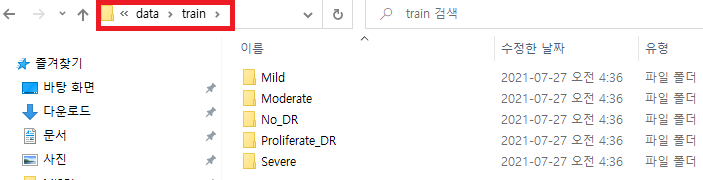
train 폴더를 보면 총 5개의 class가 있다는걸 확인 할 수 있습니다.
image_datasets['train'].classes을 이용하면 아래 폴더를 기준으로 class 명들을 string 형태로 사용할 수 있게 됩니다.
그림10
그림11
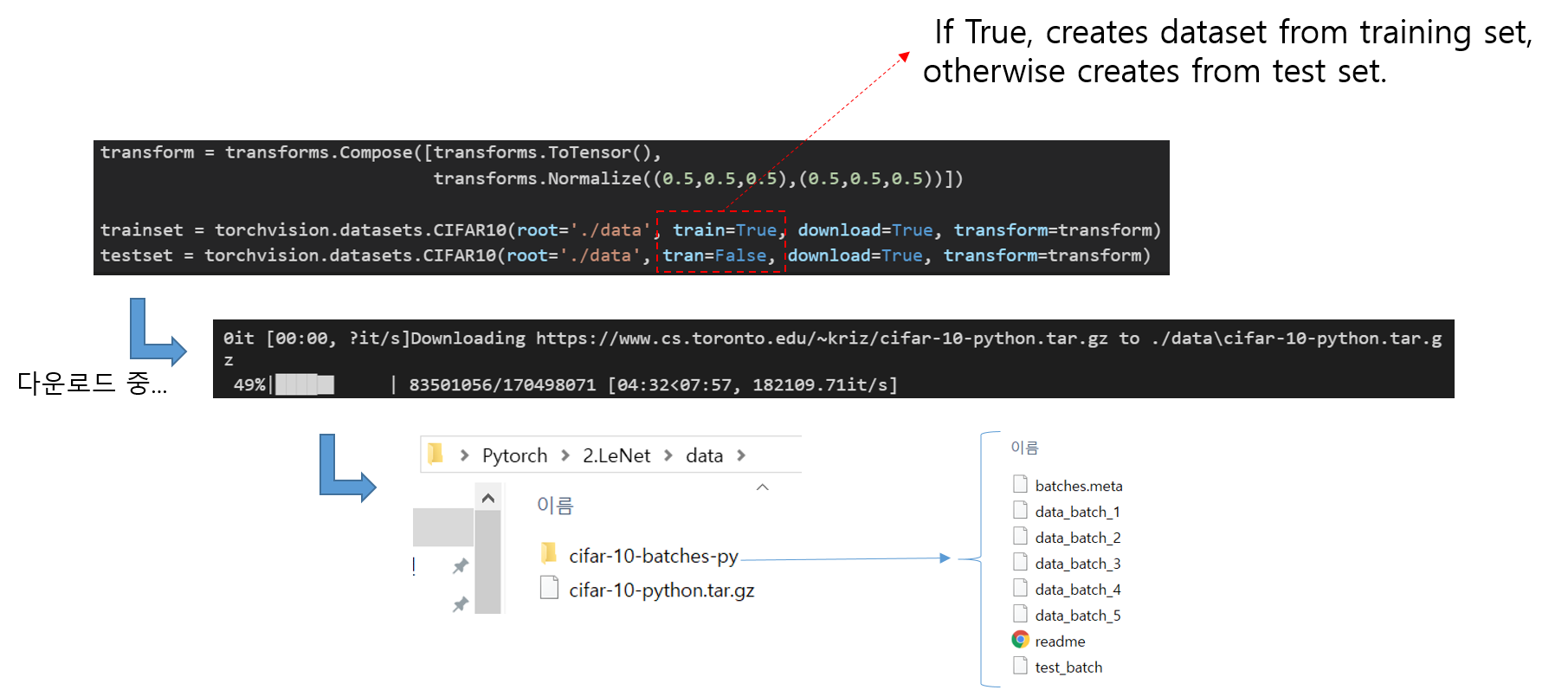
※이번 코드에서는 포함되어 있진 않지만, datasets 패키지의 첫 번째 활용도는 cifar10, caltech101, imagenet 과 같이 범용적으로 쓰이는 데이터를 쉽게 다운로드 받아 이용할 수 있게 해준다는 점입니다. 상식으로 알아두시면 좋습니다!
그림12
3. DataLoader
At the heart of PyTorch data loading utility is the torch.utils.data.DataLoaderclass.
딥러닝에서 이미지를 load 하기 위해서는 batchsize, num_workers 등의 사전 정보들을 정의해야합니다. (※torch.utils.data.DataLoader가 이미지를 GPU에 업로드 시켜주는 코드가 아니라, 사전 정보들을 정의하는 역할만 한다는 것을 알아두세요!)
image_datasets[x]: 예를 들어, image_datasets['train']인 경우 train 폴더에 해당하는 클래스들의 이미지 경로를 설정해줍니다.
batch_size: 학습을 위한 batch size 크기를 설정해줍니다.
shuffle: 이미지 데이터를 불러들일 때, shuffle을 적용 여부를 설정해줍니다.
num_workers: 바로 아래에서 따로 설명
아래 코드 역시 dataloaders라는 dictionary 형태의 변수를 for 문으로 생성하는 코드 입니다.
그림13
[num_workers]
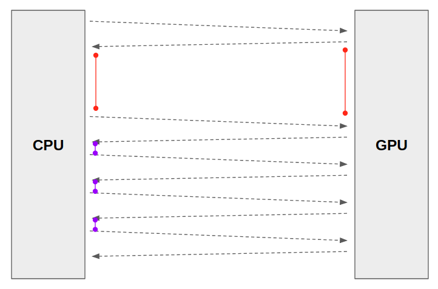
학습 이미지를 GPU에 할당시켜 주기 위해서는 CPU의 조력이 필요합니다. 즉, CPU가 학습 이미지를 GPU에 올려주는 역할을 하는 것이죠.
좀 더 구체적으로 말하자면, CPU에서 process 생성해 학습 이미지를 GPU에 업로드 시켜주는 방식입니다.
num_workers는 CPU가 GPU에 이미지를 업로드 할 때, 얼마나 많은 subprocess를 이용할지를 결정하는 인자(argument)라고 생각하시면 됩니다.
howmanysubprocessesto use for data loading. 0 means that the data will be loaded in the main process. (default: 0)
num_workers를 0으로 설정했을 때 (=a main process), CPU가 하나의 이미지를 GPU에 업로드 하는 시간을 1초라고 가정해보겠습니다.
이 때, 업로드된 이미지를 GPU에서 처리 (for CNN training) 를 하는 것이 0.1초라고 가정한다면, 다음 이미지를 업로드 할 때 까지 0.9초 동안 GPU는 놀게(idle)됩니다. (아래 "그림14"에서 빨간색 간격 → CPU에서 GPU로 이미지 데이터를 넘기기 위해 수행되는 전처리 과정)
결국 CPU에서 GPU로 이미지를 넘겨주는 작업을 빠르게 증가시키기 위해서는 여러 subprocess를 이용해 이미지들을 GPU에 업로드 시켜주어야 합니다. 다시 말해, 다수의 process를 이용해서 CPU에서 GPU로 이미지 데이터를 넘기기 위한 전처리 시간을 축소시켜주는 것이죠.
이렇게 num_workers를 증가하여 GPU에 이미지를 업로드 시키는 속도가 빨라지면, GPU가 놀지 않고 열심히 일하게 될 것입니다. → GPU 사용량(이용률)이 증가하게 된다고도 할 수 있습니다.
More num_workers would consume more memory usage but is helpful to speed up the I/O process.
그림14. 이미지 출처: https://jybaek.tistory.com/799
하지만, CPU가 GPU에 이미지를 업로드 시켜주는 역할은 수 많은 CPU의 역할 중 하나입니다.
즉, num_workers를 너무 많이 설정해주어 CPU코어들을 모두 dataload에 사용하게 되면, CPU가 다른 중요한 일들을 못하게 되는 상황이 발생되는 것이죠.
보통 코어 개수의 절반 정도로 num_workers를 설정하는 경우도 있지만, 보통 batch size를 어떻게 설정해주냐에 따라서 num_workers를 결정해주는 경우가 많습니다.
경험적으로 batch_size가 클 때, num_workers 부분도 크게 잡아주면 out of memory 에러가 종종 발생해서, num_workers 부분을 줄이거나, batch_size 부분을 줄였던 것 같습니다. (이 부분은 차후에 다시 정리해보도록 하겠습니다.)
torch.utils.data.Dataloader를 통해 생성한 dataloaders 정보들을 출력하면 아래와 같습니다.
그림15
4. GPU에 업로드 될 이미지 확인하기
앞서 "torch.utils.data.DataLoader"를 통해 이미지를 GPU에 올릴 준비를 끝냈으니, 어떤 이미지들의 GPU에 올라갈 지 확인해보겠습니다.
그림16
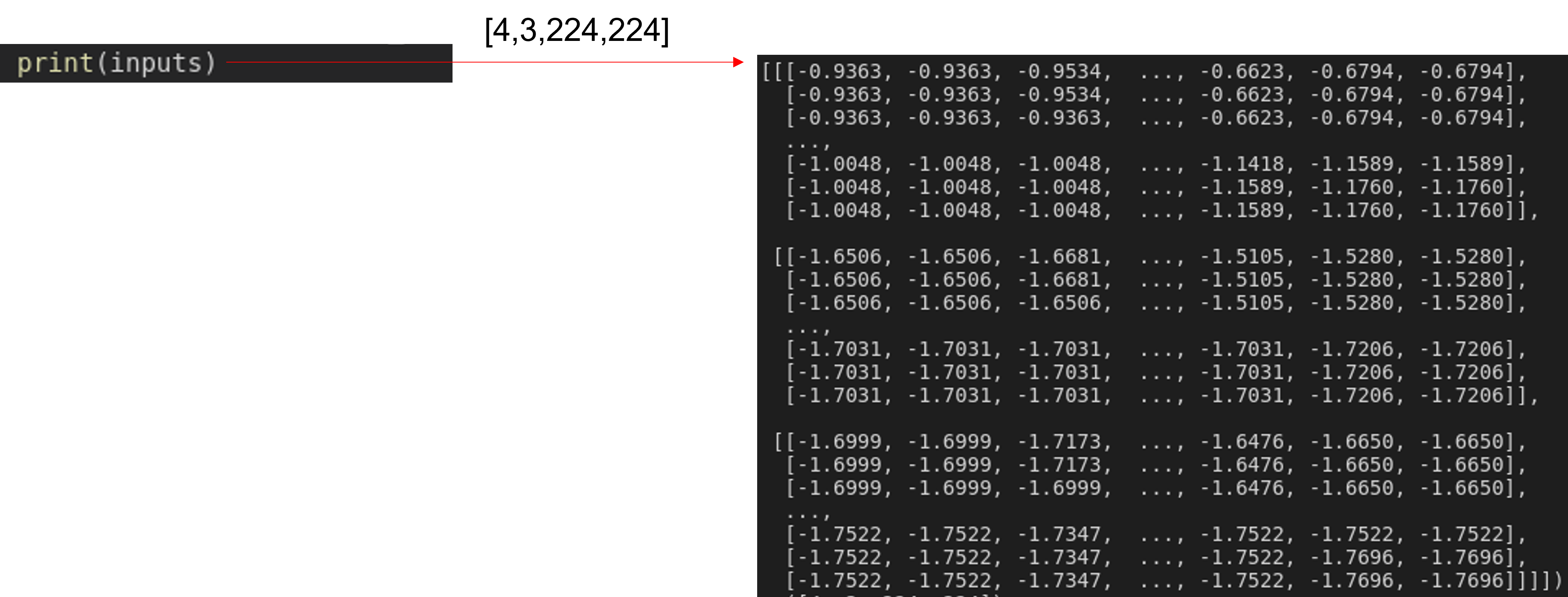
inputs에 어떤 정보들이 저장되어 있는지 알아보도록 하겠습니다.
그림17
그림18
그림19
inputs 데이터에는 batch 단위로 이미지들이 저장되어 있는 것을 확인할 수 있습니다.
그림20
앞서 dataset_sizes['train'] 에서 확인 했듯이, train 원본 이미지 개수는 ‘2683’개 입니다.
transformer.compose()를 통해 생성된 train 이미지 개수도 ‘2683’개 이다.
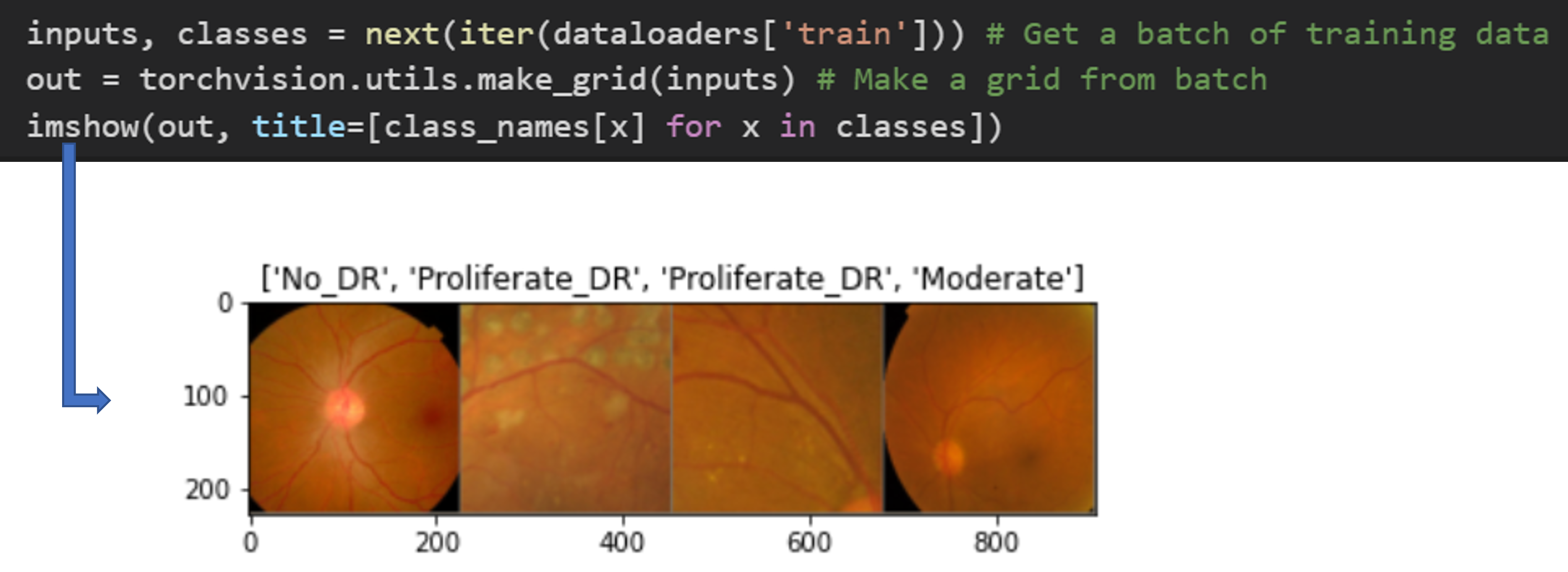
imshow를 통해 생성된 이미지를 봤을 때, data augmentation에 의해 데이터 수가늘어난게아니라, 본래 2683개의 데이터 자체내에서 augmentation이 적용된 것 같습니다. 다시 말해, training dataset의 (절대)개수는 data augmentation을 적용했다고 해서 늘어나는 것이 아닙니다. (imshow 함수는 이 글 제일 아래 있습니다)
결국, (inputs, classes) 가 CNN 입장에서 (학습 이미지 데이터, 라벨) 정보를 담고 있다고 볼 수 있겠네요.
그림21
하지만, 딥러닝 입장에서 중복된 데이터는 학습을 위해 큰 의미가 없을 가능성이 높습니다. 그래서 이미지A 5장이 있는것과, 이미지 A에 5가지 augmentation 적용된 것을 학습한다고 했을 때, 딥러닝 입장에서는 후자의 경우 더 많은 데이터가 있다고 볼 수 있습니다.
그래서 위와 같이 첫 번째 epoch의 첫 번째 iteration에서 잡힌 4개(batch) 이미지에 적용된 augmentation과, 두 번째 iteration에서 잡힌 4개(batch) 이미지에 적용된 augmentation과 다르기 때문에 결국 epoch을 여러 번 진행해주게되면, 다양한 조합으로 data augmentation이 적용되기 때문에 데이터수가 늘어났다고 볼 수 있게 됩니다.
그래서 이와 같은 방식에서 data augmentation을 적용해 (딥러닝 관점에서 봤을 때) 데이터 개수를 늘리려면 epoch을 늘려줘야합니다. (왜냐하면 앞서 transforms.compose에서 봤듯이 augmetnation이 적용될 때 augmetnation의 정도가 random or 확률적으로 적용되기 때문입니다.)
5. Upload to GPU (Feat. torch.cuda)
앞서 "torch.utils.data.DataLoader"를 통해 이미지를 GPU에 올릴 준비를 끝냈으니, 이번에는 실제로 GPU에 이미지를 올리는 코드를 소개하겠습니다.
Pytorch는 torch.cuda 패키지를 제공하여 pytorch와 CUDA를 연동시켜 GPU를 이용할 수 있게 도와줍니다.
CUDA가 정상적으로 pytorch와 연동이 되어 있는지 확인하기 위해서는 아래 코드로 확인해봐야 합니다.
그림22
torch.cuda: "torch.cuda" is used to set up and run CUDA operations.
It keeps track of the currently selected GPU, and all CUDA tensors you allocate will by default be created on that device. ← 아래 그림(코드)에서 설명
torch.cuda.is_avialable(): CUDA 사용이 가능 하다면 true값을 반환해 줍니다.
메인보드에는 GPU slot이 있습니다. 만약 slot이 4개가 있으면 4개의 GPU를 사용할 수 있게 됩니다. 해당 slot의 번호는 0,1,2,3 인데, 어느 slot에 GPU를 설치하느냐에 따라 GPU 넘버가 정해집니다. (ex: GPU 0 → 0번째 slot에 설치된 GPU)
cuda:0 이 의미하는 바는 0번째 slot에 설치된 GPU를 뜻합니다.
if 문에 의해 CUDA 사용이 가능하다면 torch.device("cuda:0")으로 세팅됩니다.
torch.device: "torch.device" contains a device type ('cpu' or 'cuda') and optional device ordinal for the device type.
torch.device("cuda:0") 을 실행하면 0번째 slot에 있는 GPU를 사용하겠다고 선언하게 됩니다.
device
train 함수에 있는 일부 코드를 통해 미리 device의 쓰임새를 말씀드리겠습니다.
앞서 "inputs"이라는 변수에 (batch_size, 3, 224, 224) 정보가 있다는 걸 확인할 수 있었습니다.
inputs 변수를 GPU에 올리기 위해 아래와 같은 "to(device)" 함수를 이용하면 됩니다. (한 가지 더 이야기 하자면 학습을 위해 딥러닝 모델도 GPU에 올려야 하는데, 이때도 "to(device)" 함수를 이용합니다. 이 부분은 나중에 model 부분에서 설명하도록 하겠습니다)
그림23. 이미지 출처: https://jeongwookie.github.io/2020/03/24/200324-pytorch-cuda-gpu-allocate/
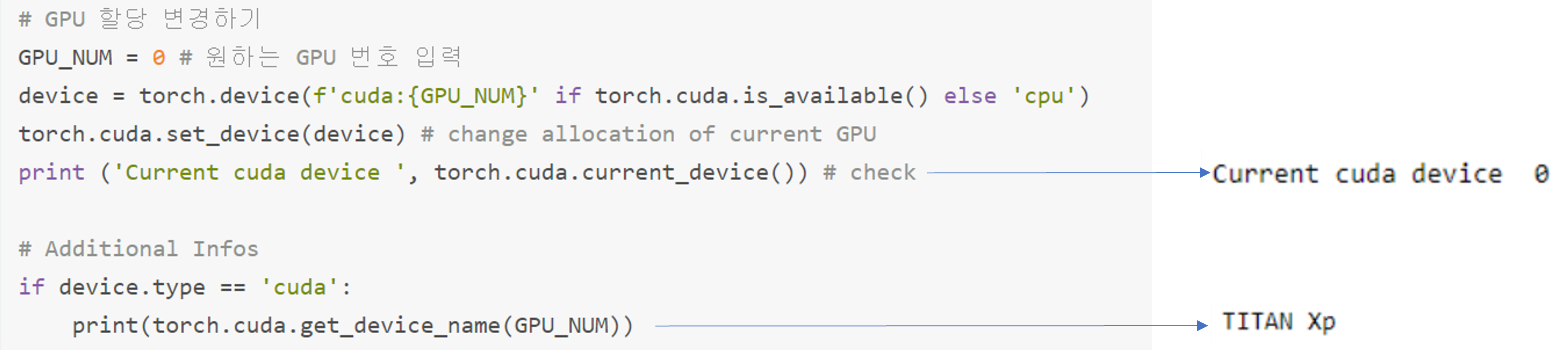
torch.cuda.device_count(): 현재 메인보드에서 이용가능한 GPU 개수
torch.cuda.current_device(): 현재 사용중인 GPU 정보
Current cuda device:2 → 3번째 slot에 있는 GPU 사용중
torch.cuda.get_device_name(device): 현재 사용하고 있는 GPU 모델명
3) 사용할 GPU 변경하기 (or 사용한 GPU 수동 설정하기)
그림24. 이미지 출처: https://jeongwookie.github.io/2020/03/24/200324-pytorch-cuda-gpu-allocate/
torch.cuda.set_device(device): 사용할 GPU 세팅
"그림23"과 비교하면, 사용중인 GPU index가 0번으로 변경된 것을 확인 할 수 있습니다 ← 첫 번째 slot에 있는 GPU 사용
지금까지 설명한 내용이 pytorch에서 이미지 데이터를 로드할 때 필요한 내용들이었습니다.
최종코드는 아래와 같습니다.
# Data augmentation and normalization for training
# Just normalization for validation
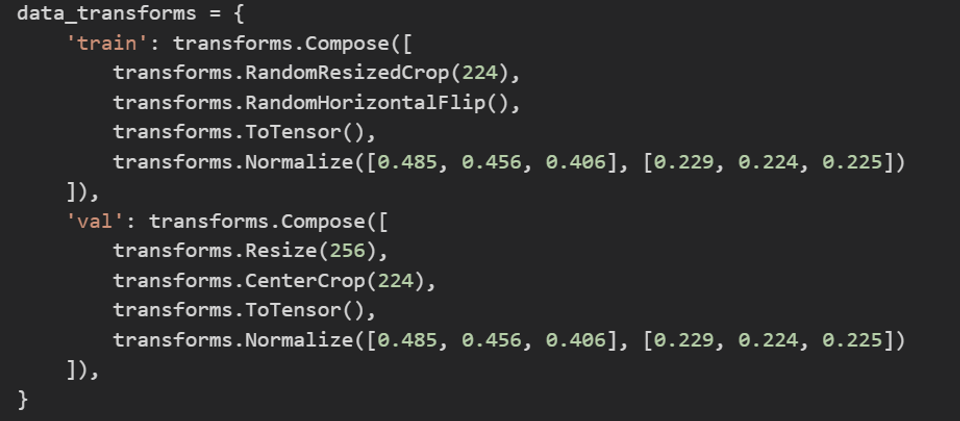
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = 'data/hymenoptera_data'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# Get a batch of training data
inputs, classes = next(iter(dataloaders['train']))
# Make a grid from batch
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])
실제로 많은 의료분야에서 UNet을 베이스 모델로 하여 병변들을 segmentation 하고 있습니다.
그러므로 의료분야에서 딥러닝 기반 segmentation 모델을 이용해보려는 분들은 UNet 구조를 이해하고 UNet논문에서 언급하고 있는 여러 용어들에 친숙해 질 필요가 있습니다.
그럼 지금부터 UNet 논문을 리뷰해보도록 하겠습니다.
0. Abstract
UNet에서 강조하고 있는 부분 중 하나는 강력한 data augmentation을 이용했다는 점입니다.
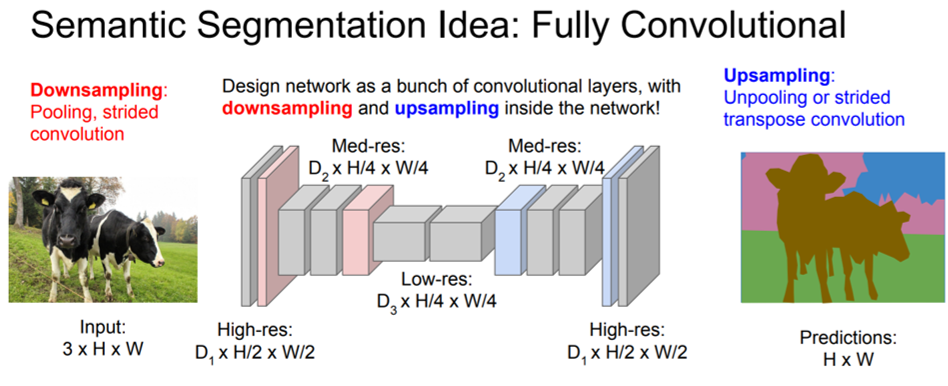
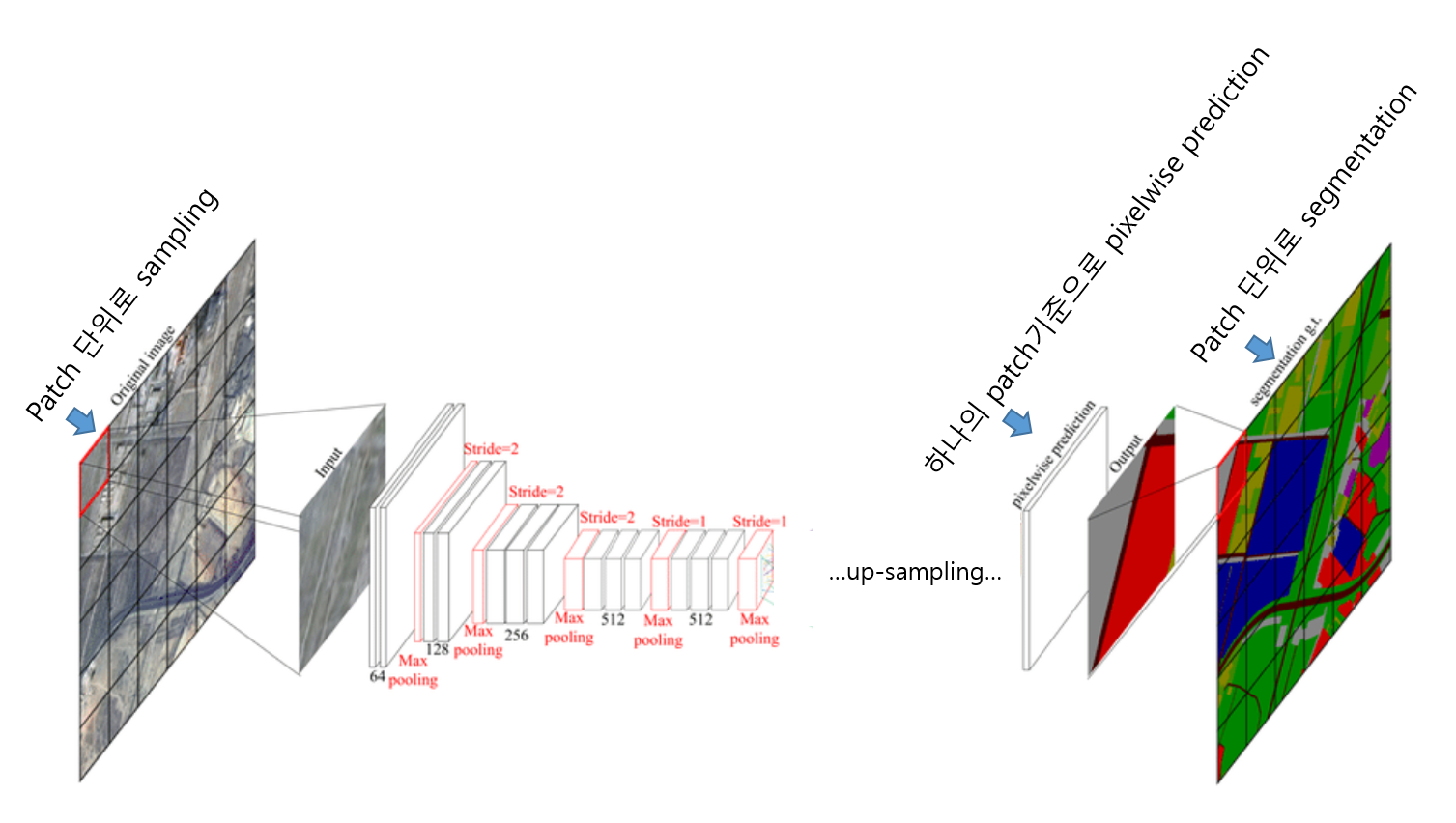
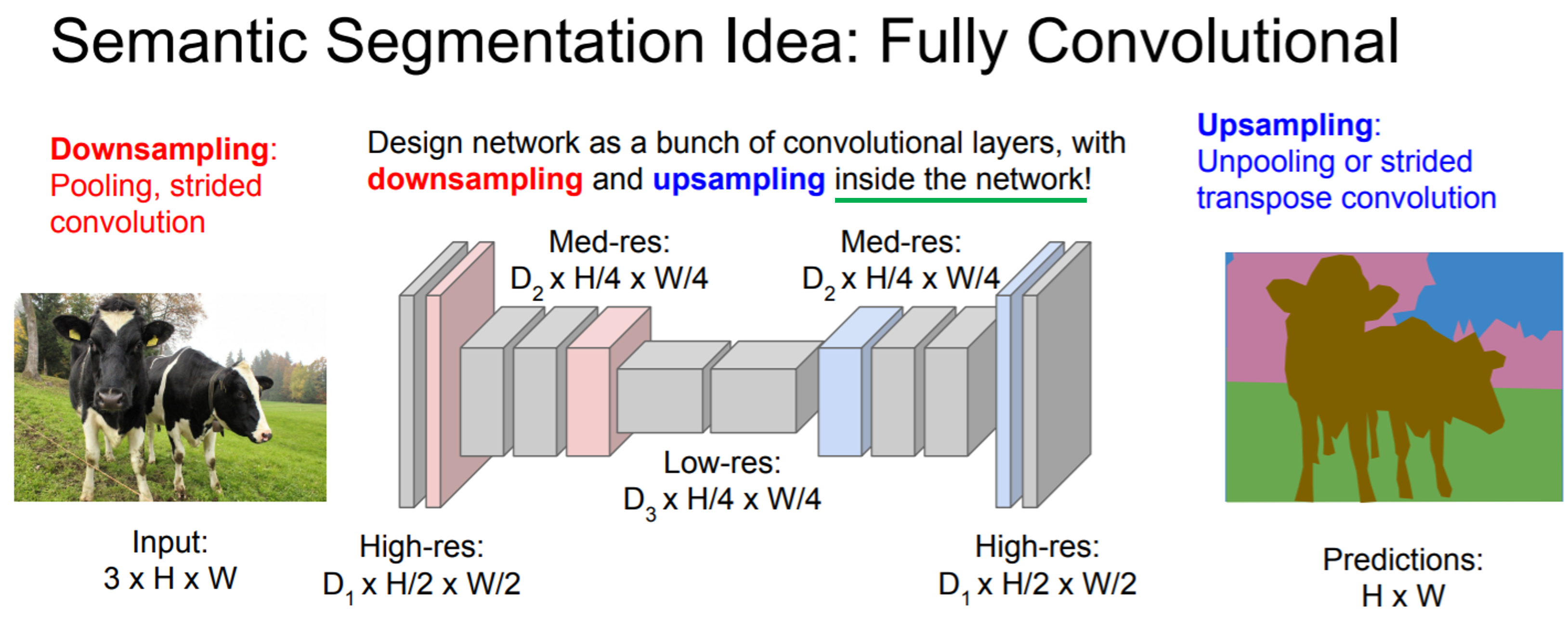
"contracting path to capture context and a symmetric expanding path"라는 문장은 아래와 "그림1"을 그대로 설명한 문장입니다. 아래 "그림1"을 보면 contracting path를 통해 context 정보(=features from almost last layers)를 구하고, contracting path 부분과 symmetric 한 expanding path를 통해 다시 원본 이미지 크기에 맞도록 (upsampling 후) segmentation (for precise localization) 을 진행하는 작업이 수행됩니다 (사실 이 부분은 FCN과 거의 다른 부분이 없습니다.)
FCN과 UNet의 차별점은 아래 "그림1"에서 같은 층(ex: contracting path 568×568×64 & expanding path 392×392×128)끼리 이어붙여주는 연산의 유무입니다. (좀 더 자세한 설명은 UNet 구조를 설명하는 부분에서 자세히 다루도록 하겠습니다.
"segmentation of neuronal structures in electron microscopic stacks" → "segmentation for stacks of serial images generated by EM (Electron Microscopy(=전자 현미경)).
그림1
UNet 모델은 ISBI cell tracking challenge 2015에 참가하여 주목을 받은 모델이기 때문에 해당 challenge 대회에서 사용한 데이터 셋을 사용했습니다. 해당 데이터 셋의 간단한 정보는 아래와 같습니다 (ISBI challenge에 대해서는 FCN 관련 글에서도 설명해놨으니 참고해주세요!)
Training time: 10 hours → "5. Conclusion"에서 알 수 있는 정보
GPU: NVidia Titan (6 GB) → "5. Conclusion"에서 알 수 있는 정보
1. Introduction
기존 CNN에 대해서 짧게 설명하고 있습니다.
AlexNet 소개
VGGNet 소개
2015년 당시에 CNN 최신 모델은 VGGNet 또는 GoogLeNet이었습니다.
기존 CNN은 보통 single classification task에 사용되었습니다.
하지만 biomedical image processing 분야에서는 한 이미지 내에 모든 pixel을 classification을 하는 segmentation task가 중요하게 사용되기도 합니다. (예를 들어, 암의 위치 또는 크기를 segmentation 할 필요가 있겠죠?)
ImageNet에 비해 (biomedical tasks을 위한) biomedical image 수가 충분하지 않다는 문제가 있습니다.
by reach = 손이 닿지 않는 곳에 = "가능성이 없는" 늬앙스
이러한 데이터 수 문제를 해결하기위해 (UNet 이전에) patch 기반의 학습 기법("Ciresan et al"="Sliding-window setup")을 이용해 data 수를 늘리려는 시도를 했습니다.
Sliding-window setup 방식은 FCN 글에서 설명해 놨으니 참고해주세요.
Sliding window 기반 딥러닝 segmentation 모델이 EM (Electron Microscopy: 전자현미경) segmentation 종류인 ISBI 2012 challenge 우승했습니다.
"Ciresan et al"="Sliding-window setup" 방식은 2가지의 문제점이 있는데, 이 부분도 FCN 글을 참조해주시길 바랍니다!
이 문단은 FCN에 대한 설명이므로 FCN 글을 참조해주세요!
successive layers = deconv layers
"그림1"에서 볼 수 있듯이 expanding path(=upsampling part) 를 보면 기존 FCN 보다 더 많은 conv filter channel들이 사용되었다는걸 확인 할 수 있습니다. 이를 통해 저자는 "propagate context information to higher resolutioin layer" 가 가능하다고 주장하고 있네요.
그림1
"segmentation map only contain ~ in the input image"→ segmentation map (=아래 "그림1"을 보면 최종 output결과를 segmentation map이라고 부름) 에는 입력 영상에서 전체 context를 "available"할 수 있는 pixel만 포함(=segmentation)된다고 합니다. → 이 부분은 그냥 segmentation map 결과가 context (의미 or 객체) 단위로 표현된다는 것으로 이해했습니다. 예를 들어, 아래 그림처럼 입력 이미지는 고양이의 질감이나 다양한 정보들을 확인 할 수 있는데 반해, segmentation map에서는 오로지 context 정보만 확인할 수 있습니다.
Valid part에 대한 정확한 의미는 잘 모르겠네요. Valid part만 보면 segmentation map을 의미하는거 같다가도, "valid part of each convolution"을 보면 convolution과 연관지어 해석해야 할 것 같기도합니다. Segmentation map에 적용되는 각각의 convolution이라고 해석해야하는건지.....
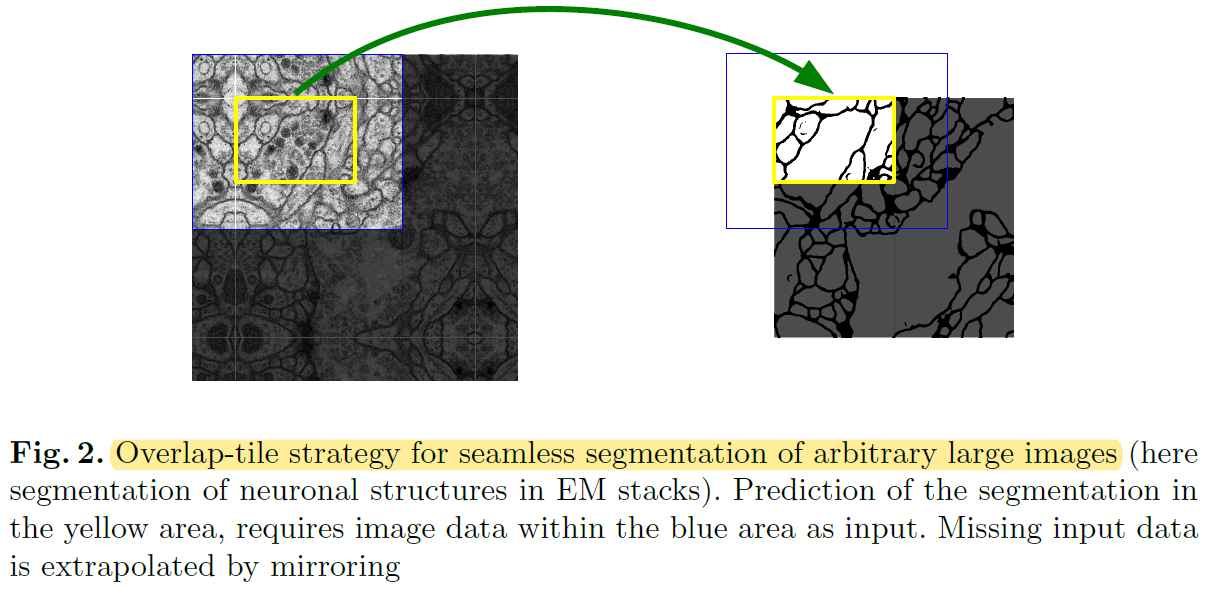
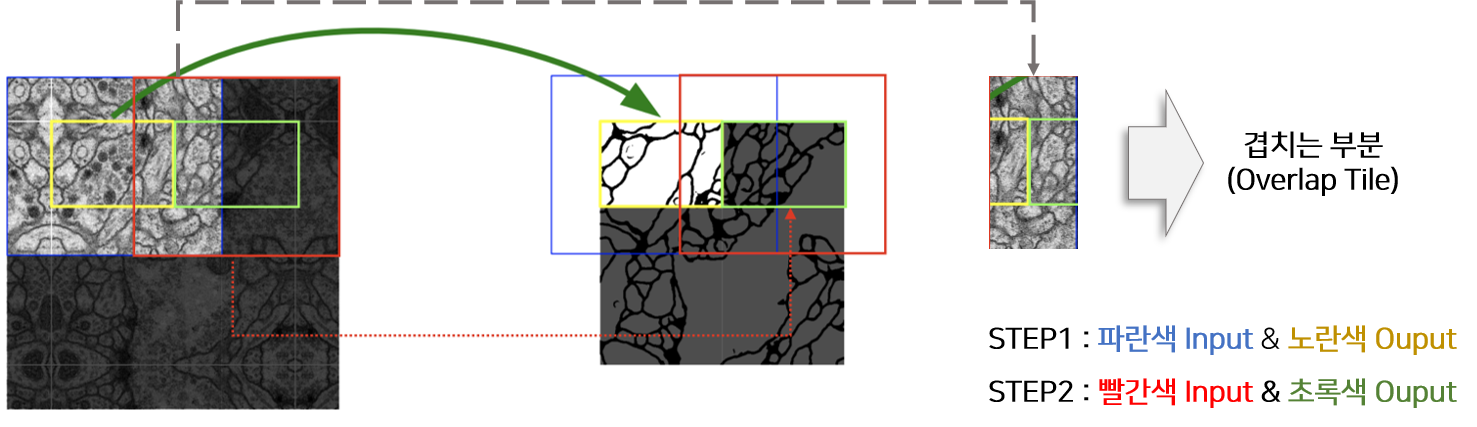
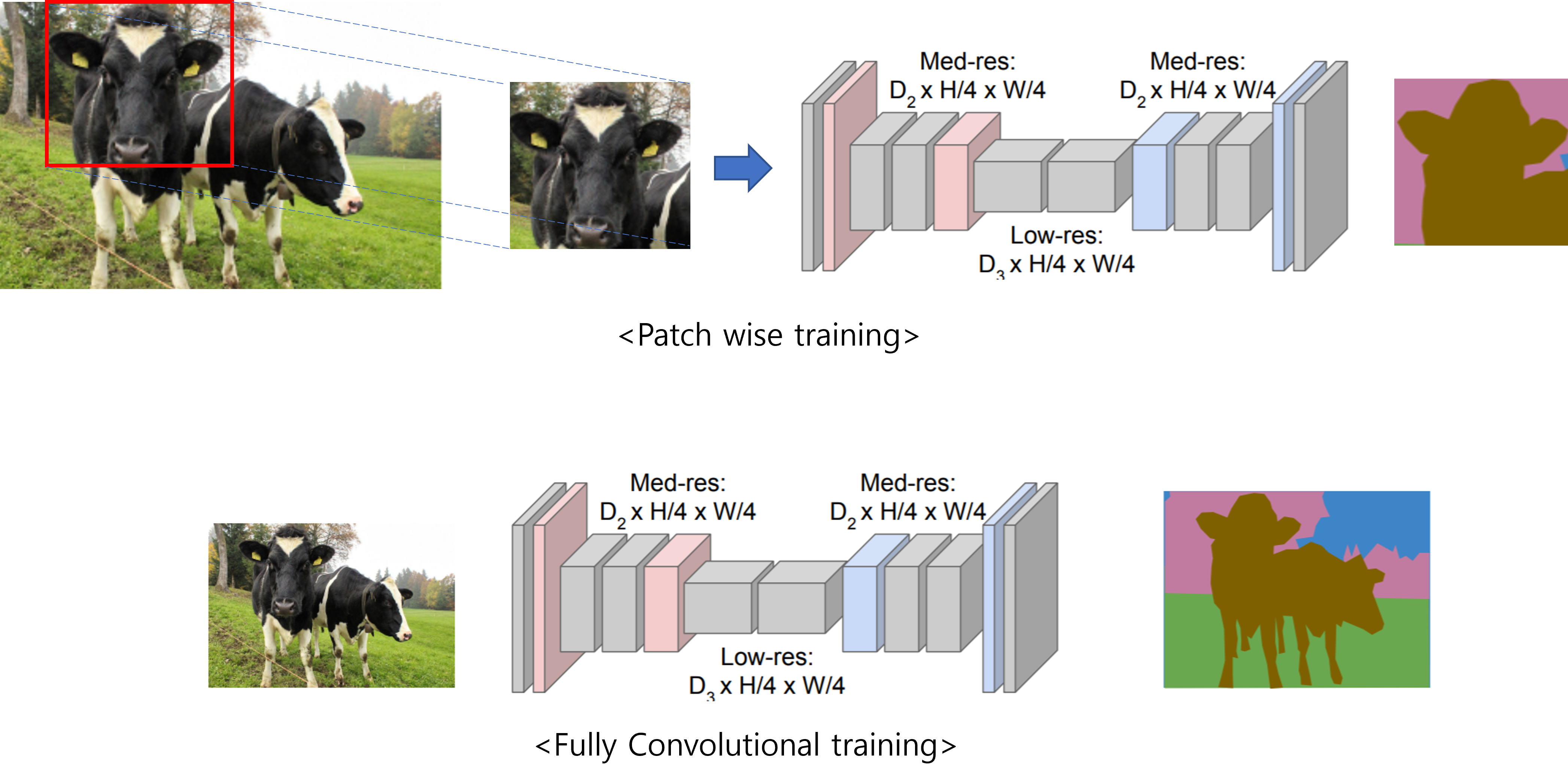
This strategy(=not using FC layer)는 입력 이미지 크기에 제한 받지 않고 (=arbitrarily large images) segmentation이 가능하게 만들었는데, over-tile strategy를 이용해 좀 더 seamless(=매끄러운) segmentation이 가능하게 만들었습니다.
지금부터 아래 "그림2(=over-tile strategy)"에 대해서 좀 더 자세히 설명 해보도록 하겠습니다.
그림2
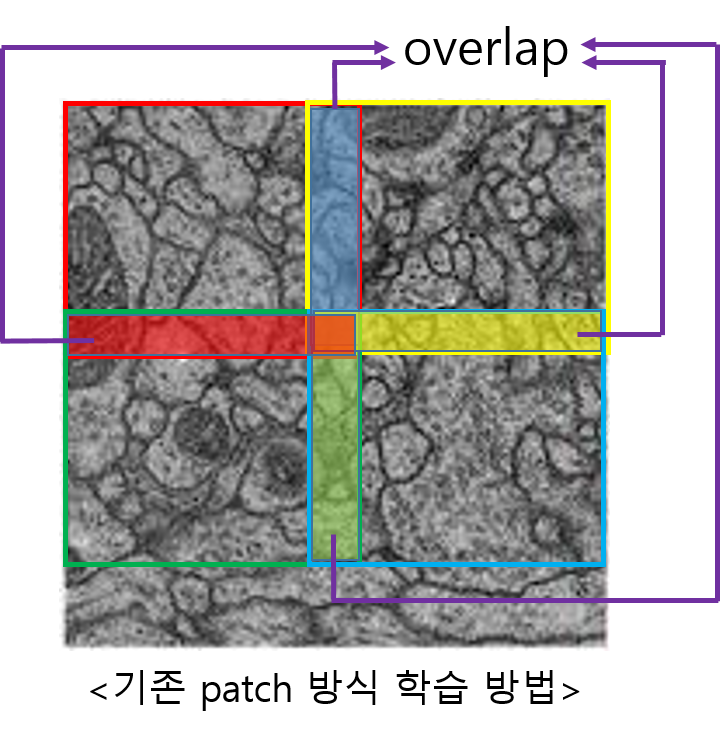
아래 "그림3"과 같이 기존의 patch 방식으로 학습하면overlapping되는 부분이 많이 생깁니다.
이러한 문제는computation의 redundancy를 증가시키기도 합니다.
Unet에서는 이러한 문제를 해결하기 위해 overlap-tile strategy를 적용시켰습니다.
그림3. 이미지 출처: http://brainiac2.mit.edu/isbi_challenge/home
Over-tile strategy를 설명하기에 앞서 “그림1”의 Unet구조를 보면 input size와 output size가 다릅니다.
다시 말해, 실제 segmentation 되는 부분은 input image의 일부분이라는 말과 같습니다. (→ 아래 "그림6"의 오른쪽 이미지 참고)
그림6
Overlap-tile strategy 을 이용하면 실제 segmentation 되는 부분은 overlapping이 안 되는 것을 알 수 있습니다. (이 부분 때문에 “seamless segmentation”이라는 표현을 쓴 건지....)
그림7
To predict the pixels in the border region of the image, the missing context is extrapolated by mirroring the input image.
the pixels in the border region of the image → input image의 주황색bounding box(=the border region)내부(in) pixel들
실제 segmentation되는 부분(=오른쪽 그림에서 “원본 이미지“)이 ground truth의 크기이기 때문에, input으로 들어가는 이미지에 추가 작업을 진행해줘야 합니다.
이 논문에서는 input size에 해당하는 빨간색 bounding box와 실제 segmentation size에 해당하는 주황색 bounding box를 뺀 나머지 부분을 “missing context”라 언급하고, mirroring 기법을 이용해 missing context 부분을 extrapolation(=추론) 하여 input image를 만들어 준다고 합니다.
그림8
이러한 over-tile strategy를 이용해서 input image resolution에 제한받지 않고 segmentation 학습이 가능해졌다고 말하고 있습니다.
그림9. 이미지출처: https://kuklife.tistory.com/119
Segmentation 학습을 위해 제한적인 training dataset을 갖고 있었기 때문에 excessive data augmentation을 진행해 학습 데이터 수를 증가시켰다고 합니다.
여기에서는 elastic deformation augmentation 방식을 설명했지만 "3.1. Data augmentation" 파트에서 실제로 학습에 적용된 다양한 augmentation 방식들을 소개하고 있기 때문에 추가적인 설명은 "3.1. Data augmentation" 파트에서 하도록 하겠습니다.
최근에는 "As for our tasks ~ the available training images"라는 말이 상식적이라 최근 논문에는 굳이 사용하지 않지만, 이 당시 (2015) 까지만 하더라도 data augmentation에 대한 언급을 한 문단으로 따로 해줬나보네요.
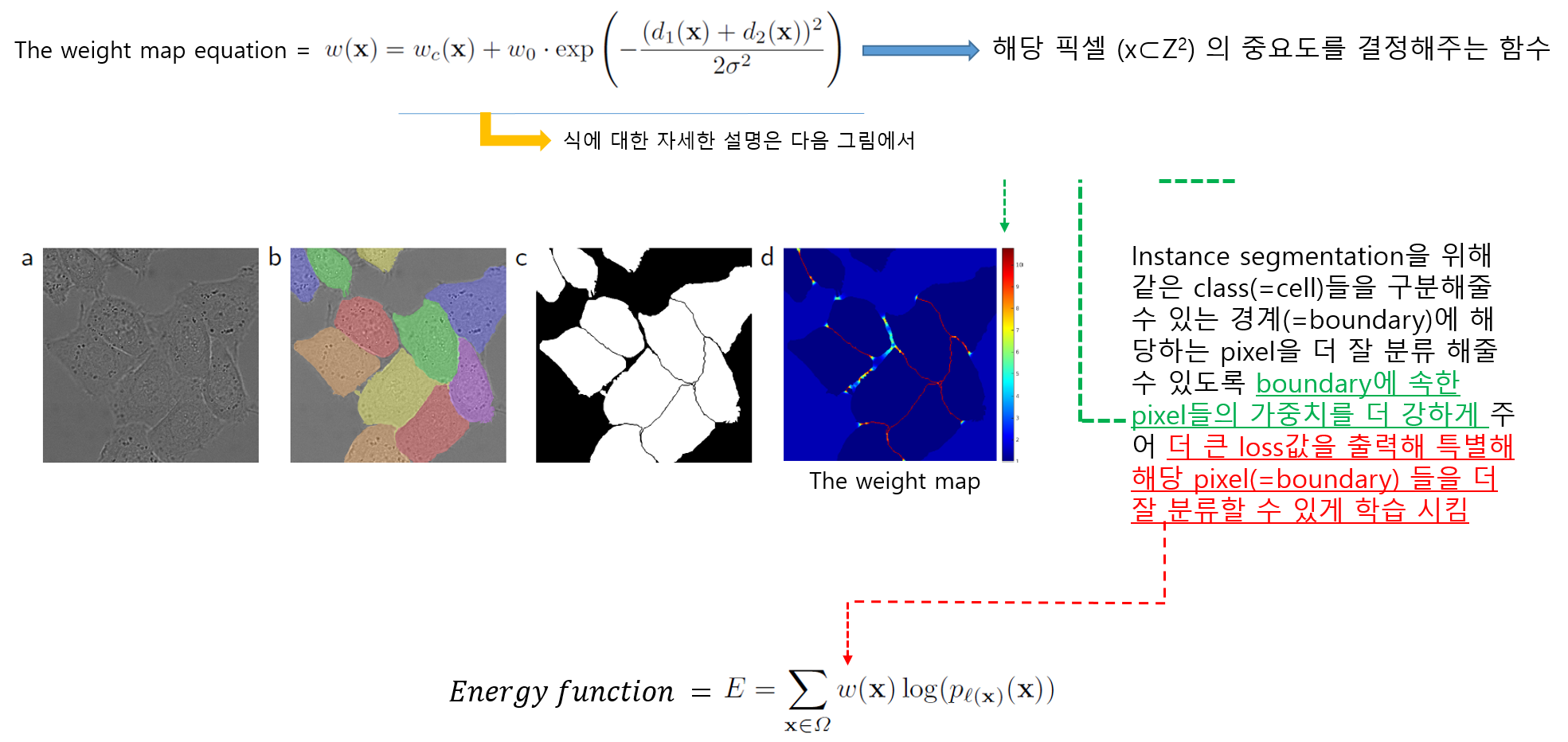
biomedical image segmentation (ex: cell segmentation) 같은 경우는 인접한 세포들간을 분리하는 segmentation을 적용하는 것이 쉽지 않습니다. (→ Instance segmentation)
(↓↓↓ Instance segmentation VS Semantic segmentation↓↓↓)
이 논문에서는 인접한 cell들 사이에 경계가 될 수 있는 background (=the separting background labels) 를 잘 segmentation 해줄 수 있도록 별도의 loss function을 사용했다고 합니다 (해당 부분은 "3.Training" 파트에서 자세히 설명하도록 하겠습니다)
UNet은 2D transmitted light datasets을 기반으로하는 (대표적인) 두 challenging 대회에서 기존 모델들과 큰 격차(=by a large margin)로 우승을 했다고 합니다. (Transmitted light microscopy = 투과 광선 현미경검사)
A 대회: Segmentation of neuronal structures in EM (Electron Microscopy: 전자현미경) stacks at ISBI 2012
B 대회: Light microscopy (=광선 현미경검사) images from the ISBI cell tracking challenge 2015
2. Network Architecture
UNet 구조는 앞에서 추상적으로 설명했기 때문에 이 부분에서는 좀 더 구체적으로 설명하도록 하겠습니다.
Contracting path
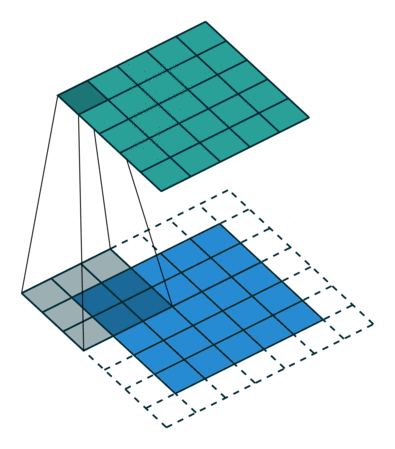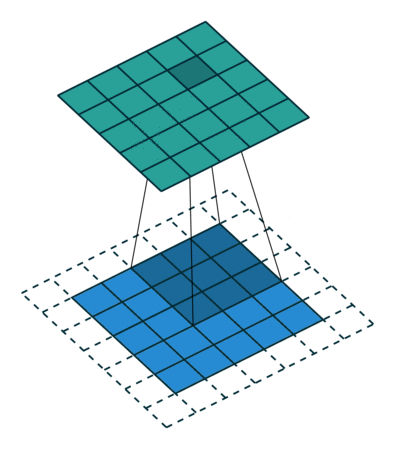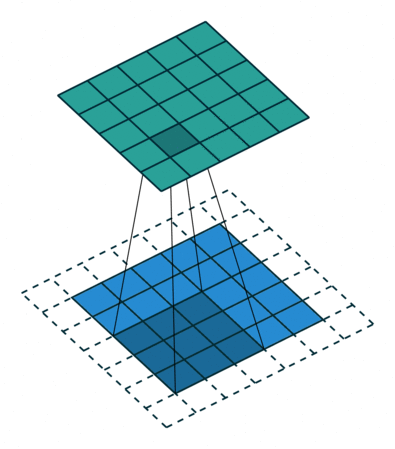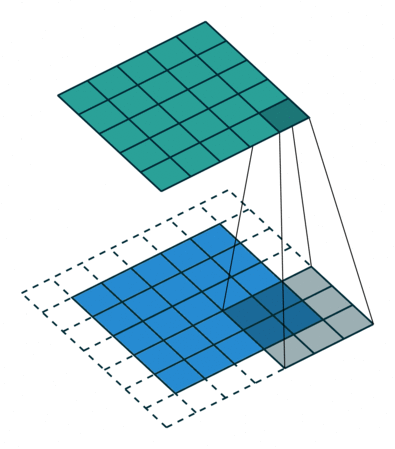
Two 3×3 Conv filter (stride=1) with zero padding of input feature map → feature map size-reduction → 2×2 max-pooling → feature map size-reduction (to Half)
이 과정을 반복해서 적용
Expansive path (Expansive path는 크게 세 단계로 나눌 수 있습니다.)
2x2 De-Conv filter that halves the number of feature channels. (아래 "그림10"에서 보라색 점선 화살표를 보면 input channel (=512)을 256으로 줄여주는걸 확인할 수 있습니다.)
Copy and Crop a → "concatenation with the correspondingly cropped feature map from the contracting path"
정확한건 아니지만 이 과정에서 앞서 언급한 mirroring이 적용된 부분이 제거 되는 것으로 추론됩니다. (어떻게 crop하는지 코드를 살펴봐야겠네요)
Copy and Concatentation: Contracting path에서 crop된 (104×104)×256 feature map을 Copy → 아래 "그림10" 기준으로 같은 층에 존재하는 expansive path의 (104×104)×256 feature map에 concatenation → Concatenation 결과: (104×104)×512 feature map 생성
Final layer: 388×388×64 feature map을 output segmentation map으로 만들어주기 위해, 1×1 conv filter를 이용해 388×388×2 feature map으로 만들어줌 (=mapping)
아래 "그림10"을 기준으로 보면 2는 classification해야 할 class 개수인 것 (binary classification: cell인지 아닌지(=background)) 같은데 아니라면 댓글 달아주시면 감사하겠습니다!
2×2 max-pooling을 적용하기 위해서 conv layer에 입력으로 들어오는 feature map size가 x, y축 모두 짝수가 되도록 고려해서, input title size를 설정해줘야 over-tile strategy가 잘 적용될 수 있다는 것을 언급하는 듯 합니다.
3. Training
Optimizer
Stochastic Gradient Descent (SGD)
Momentum: 0.99
Deep learning framework: Caffe
Batch: A single image
1) Loss function
UNet은 아래와 같은 loss function을 사용하고 있습니다.
논문에서 글로 설명하는 내용들을 그림으로 대체해서 설명해보도록 하겠습니다.
1-1) SoftMax
그림11. 이미지 출처: https://medium.com/hyunjulie/1%ED%8E%B8-semantic-segmentation-%EC%B2%AB%EA%B1%B8%EC%9D%8C-4180367ec9cb
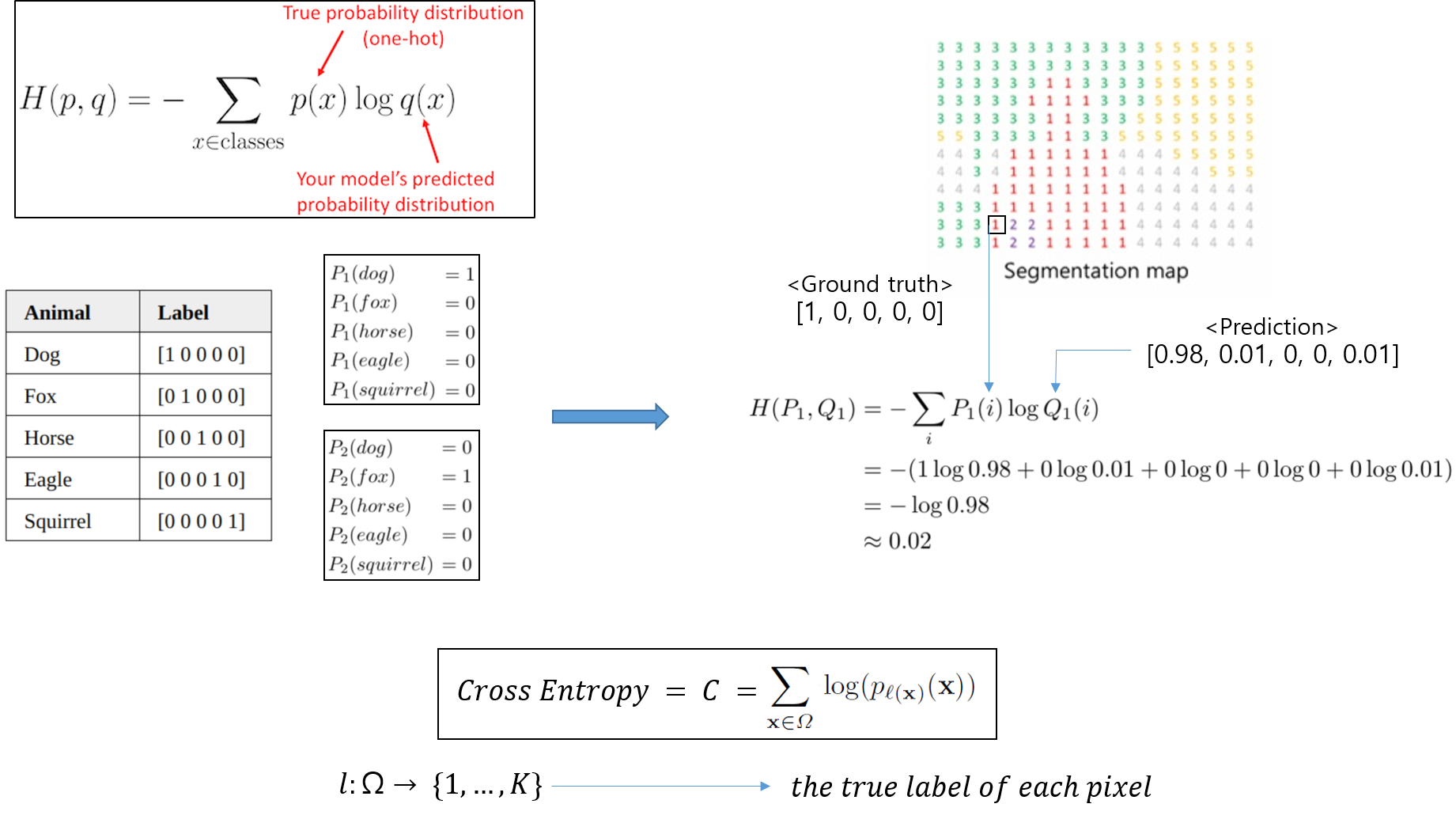
1-2) Cross-Entropy
그림12. 이미지 출처: https://naokishibuya.medium.com/demystifying-cross-entropy-e80e3ad54a8
1-3) Weight Map
먼저 weight map equation 식 자체에 대한 concept 부터 이해하도록 하겠습니다.
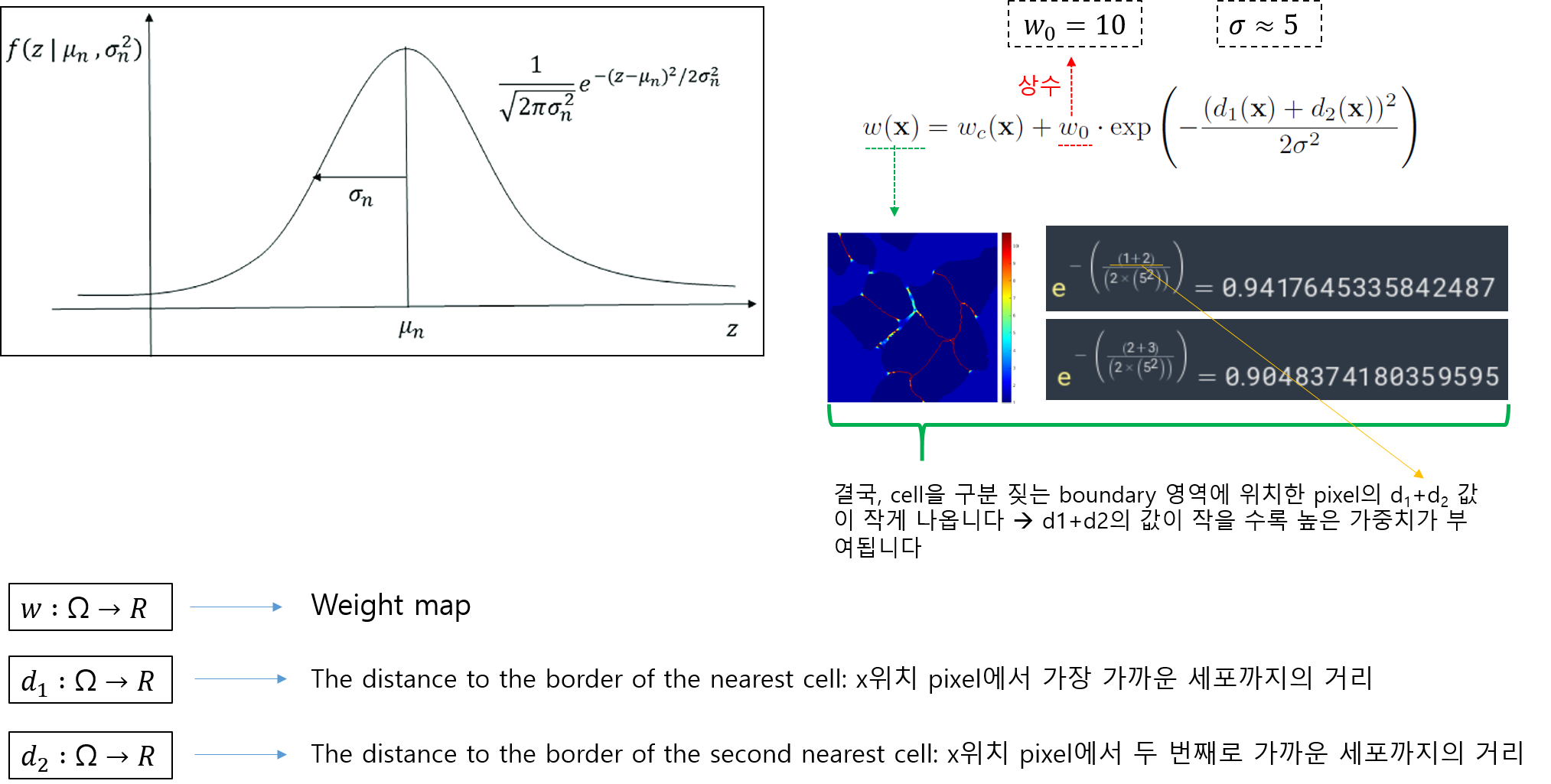
weight map equation 수식의 오른쪽 수식은 guassian distribution과 유사합니다.
개인적으로 gaussian function 수식과 weight map equation 수식의 오른쪽 수식이 어떤 관계가 있을 거라 생각 하는데, 그 이유는 이 논문에서는 σ 개념을 도입했기 때문입니다. 하지만, 좀 더 구체적인 설명은 하지 않고 있어서 해당 exp 수식이 정말 guassian function 개념을 기반으로 설명 될 수 있는지 잘 모르겠네요... (exp 수식을 왜 사용했는지 좀 더 알고 싶은데.... 시간이... 혹시 아시는 분 있으면 답글 달아주세요!)
그림15
2) Weight initialization
Gaussian distribution initialization (=standard deviation distribution)
Standard deviation: \(\sqrt{\frac{2}{N}}\)
N = conv filter size × conv filter channel
3.1 Data Augmentation
이 논문에서 언급하고 있는 data augmentation 방식은 총 가지 입니다.
Shift
Rotation
Gray value
Random elastic deformation
Random elasstic deformation에 대해서 다양하게 설명하고 있는데, 해당 설명은 아래 그림으로 대체하도록 하겠습니다.
이미지 출처: https://www.researchgate.net/figure/Training-data-augmentation-through-random-smooth-elastic-deformation-a-Upper-left-Raw_fig5_329716031
4. Experiments
이 부분에서는 UNet을 적용한 세 가지 task (3가지 dataset 종류)에 대해서 소개합니다. 세 가지 task에 대한 설명은 그냥 논문에 있던 글들을 요약해서 정리해 놓았습니다. 대신에 성능평가를 위해 사용한 evaluation 종류에 대해 자세히 설명하도록 해보겠습니다.
이 논문에서 UNet 모델을 이용해 3가지 segmentation task에 적용해봤다고 합니다.
First task: The segmentation of neuronal structures in electron microscopic (EM) recordings
Dataset: the EM segmentation challenge (at ISBI 2012)
20 training images "512×512" (from serial section transmission electron microscopy of the Drosophila first instar larva ventral nerve cord (VNC))
Drosophila: 초파리
Instar larval: 어린 유충
Ventral nerve cord: 복부 신경 코드
Other tasks: A cell segmentation task in light microscopic images (=A part of the ISBI cell tracking challenge 2014 and 2015)
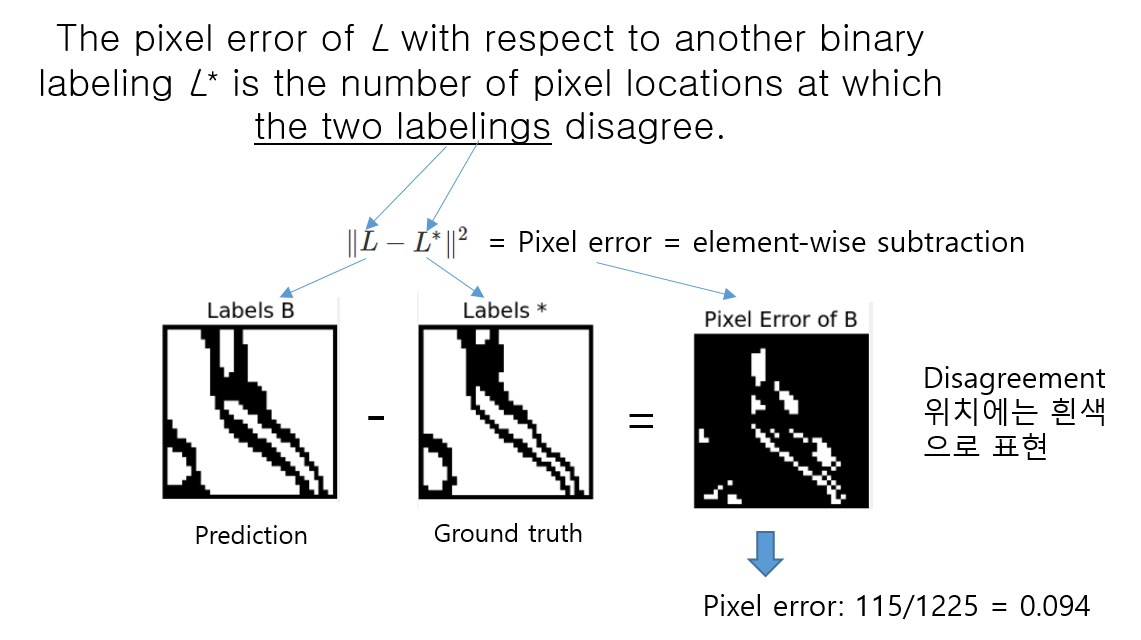
Pixel error는 prediction과 ground truth에 pixel마다 할당된 class들끼리 불일치하는 pixel들의 개수가 전체 pixel들을 기준으로 어느정도 비율이 되는지 알려주는 metric입니다.
이미지 출처: https://imagej.net/plugins/tws/topology-preserving-warping-error
Warping error와 Rand error는 digital topology error과 관련이 있는듯 합니다. 이 부분은 topology(위상수학)에 대한 이해를 기반으로 해석해야 하는데, 시간상 해당 부분을 살펴보지 못했습니다. 좀 더 디테일한 설명을 원하신다면 아래 reference를 참고해주시고, 추후에 시간이나면 설명해 놓도록 하겠습니다!
물론 FCN 이전에 딥러닝을 사용한 segmentation 모델이 있긴 했지만, 현재 대부분의 segmentation 모델들이 FCN을 베이스로 사용하고 있기 때문에 FCN을 최초의 딥러닝 기반 segmentation 모델로 간주하고 있습니다.
FCN 논문이 중요한 이유는 두 가지로 요약할 수 있습니다.
앞으로 딥러닝 기반의 segmentation 논문들을 읽으실 때, FCN 논문에서 언급되는 다양한 용어들이 자주 등장하기 때문입니다.
대부분의 딥러닝 기반 segmentation 모델들이 FCN 구조를 기반으로 하고 있기 때문입니다.
그럼 지금부터 FCN 모델을 리뷰해보도록 하겠습니다.
(중간중간에 설명이 더 필요한 부분은 "CS231n Lecture 11. Detection and Segmentation"강의를 참고했습니다)
0. Abstract
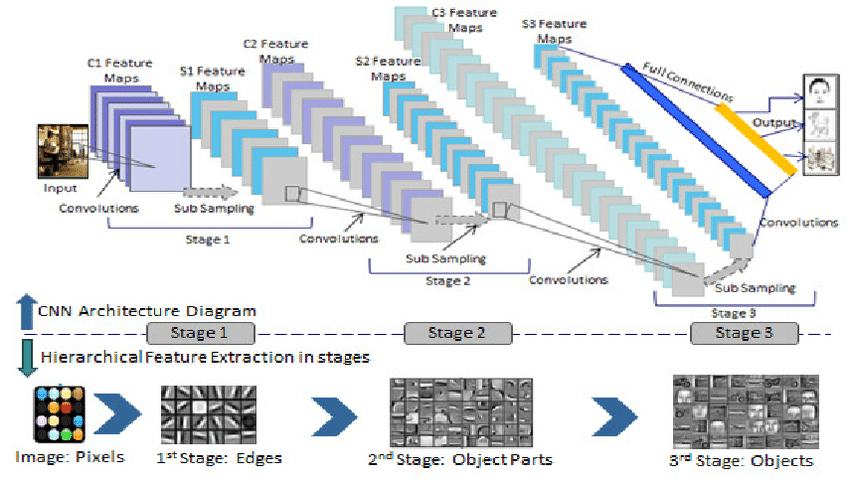
Convolutional (neural) network는 아래 그림과 같이 단계별로(=stage) hierarchical feature를 뽑아 내는 강력한 visual model 입니다.
그림1 이미지 출처: https://www.researchgate.net/figure/Learning-hierarchy-of-visual-features-in-CNN-architecture_fig1_281607765
이 논문에서는 convolutional network를 이용하여 "end-to-end", "pixel-to-pixel" 학습을 기반으로 semantic segmantation을 학습한다고 언급했습니다.
end-to-end로 학습을 시킨다는 말을 이해하기 위해서는 "end-to-end"가 아닌 모델을 이해해야 합니다. 우선 "그림2", "그림3"을 통해 설명하도록 하겠습니다.
그림2
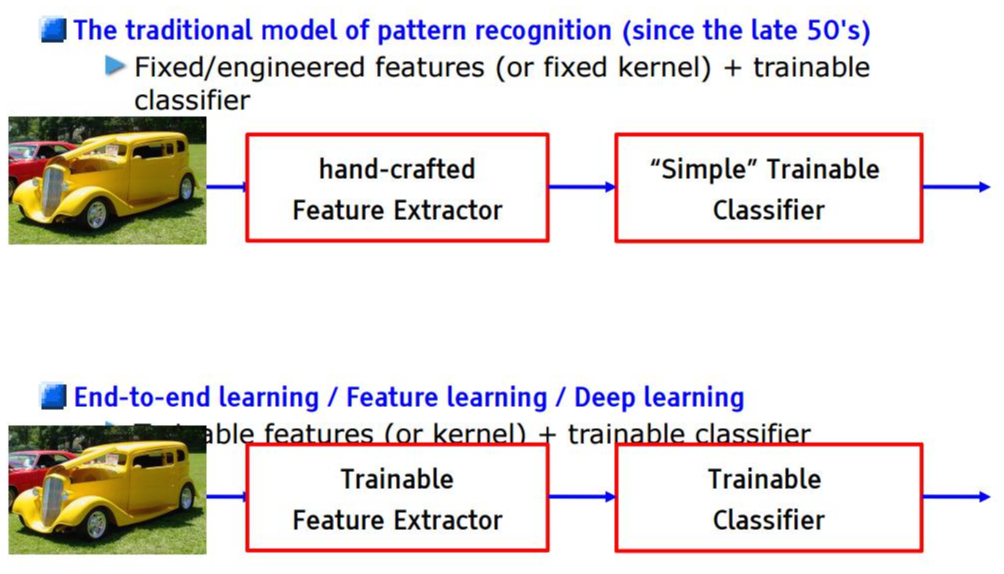
첫 번째로 end-to-end가 아닌 모델은 전통적인 pattern recognition 모델입니다.
딥러닝에서는 이미지의 특징을 추출해주는 filter(=conv filter)들이 학습 가능 (learnable) 하지만, 전통적인 pattern recognition 모델은 사람이 미리 (fixed) filter를 설계하는 방식으로 디자인 됩니다.
예를 들어, 자동차를 잘 분류할 수 있을 것 같은 filter를 설계하여 feature를 뽑은 뒤, 자동차 객체를 잘 분류할 수 있도록 분류기 부분을 학습시키는 것이지요.
이렇게 하면 classifier만 학습이 되는데, 만약 분류하려는 객체가 바뀌면 filter를 또 수동적으로 바꿔줘야 합니다.
이러한 전통적인 pattern recognition 모델은 "hand-crafted feature extractor(=filter)"와 "trainable classifier" 두 부분으로 구성되어 있다고 할 수 있는데, 실제로 학습을 하는건 classifier 부분 뿐입니다.
다시말해, 입력이 들어오면 "hand-crafted feature extractor 부터 classifier까지" = "처음부터 끝까지" ="end-to-end "로 학습하는 것이 아니기 때문에, end-to-end 모델이 아닙니다.
그림3
두 번째로 "end-to-end"가 아닌 모델은 cascade 방식의 모델입니다.
Cascade는 폭포라는 사전적 의미가 있지만 순차적 단계적인 늬앙스를 내포하고 있습니다.
예시1 (그림3-1)
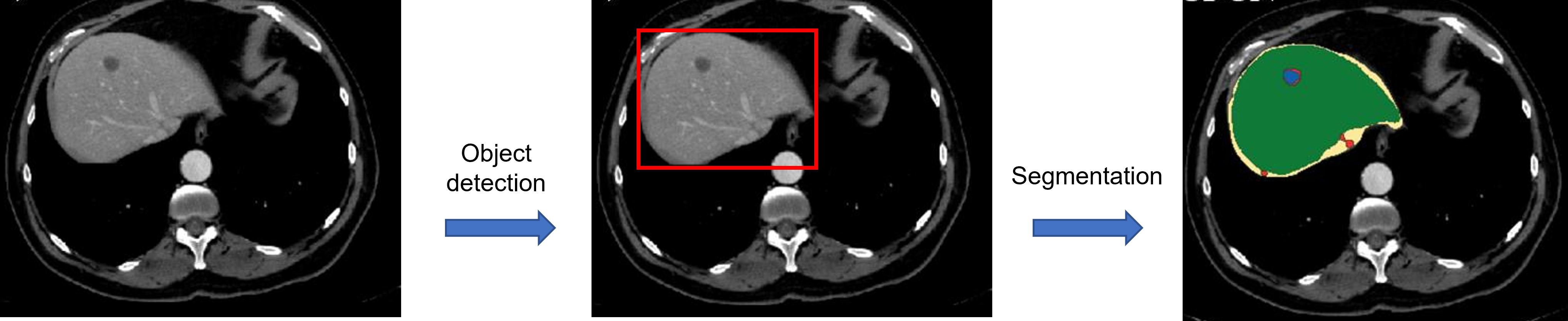
먼저, Segmentation 작업을 cascade 방식으로 진행할 수 있습니다.
Segmentation 작업을 진행할 때, 우선 관심 영역을 detection 하고 (RoI detection), 해당 RoI 영역을 segmentation 하도록 설계할 수 있습니다.
즉, object detection 모델과, segmenation 모델을 각각 독립적으로 사용하는 것이죠.
반면에, Mask RCNN은 하나의 모델에 같이 개별 task를 수행하는 loss들을 결합시킨 multi-task learning 방식(=classification loss+bouding box loss+mask loss)을 사용합니다. 즉, RoI detection과 segmentation이 동시에 end-to-end로 학습이 되는 방식이라 할 수 있겠습니다.
예시2 (그림3-2)
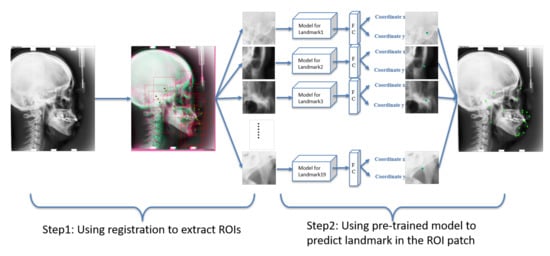
어떤 이미지의 key point (or landmark)를 찾아야 한다고 가정해보겠습니다.
이때, 처음부터 큰 이미지에서 key point를 찾는 것은 굉장히 어려운 문제입니다.
그러므로 먼저 object detection 모델을 이용해 key point가 있을 만한 RoI를 선별(=RoI detection)하고, 선별된 RoI를 CNN 모델에 입력해 해당 key point를 찾아주도록 합니다(=이때 CNN모델의 loss function은 해당 key point의 x,y 좌표값을 학습하는 regression loss를 이용합니다).
이 경우 object detection 모델과 CNN 모델은 독립적으로 이용됩니다.
그림2 이미지 출처: https://stackoverflow.com/questions/40552928/what-is-meant-by-end-to-end-fashion-convolutional-neural-networkcnn
그림3-1. 이미지 출처: https://www.programmersought.com/article/21122704833/
그림 3-2 이미지 출처: https://www.mdpi.com/journal/applsci/special_issues/Machine_Learning_Biomedical
FCN segmentation 모델은 아래와 같은 이유로 "end-to-end" 방식을 취하고 있다 할 수 있습니다.
Segmentation을 위해 사용되는 filter들이 learnable 합니다.
독립적인 딥러닝 모델들을 이용하지 않고(=not cascade), 하나의 딥러닝 모델에서 segmentation 작업을 진행 합니다.
FCN 모델은 segmentation을 위해 사용되는 filter들이 전부 conv filter (=Fully Convolution Network)로 구성되어 있기 때문에, 구조적으로 봤을 땐 input image size 크기를 고정될 필요가 없습니다 (=arbitrary). → FC layer가 제거 되었기 때문에 입력 이미지 크기가 고정될 필요는 없겠죠.
Correspondingly-sized output는 "3.Fully convolutional networks"를 봐야 자세히 이해가 가능한데, 간단히 설명하면 segmentation 결과가 input size와 같은 spatial dimensions을 지닌다고 할 수 있겠네요.
"3.Fully convolutional networks" ← "An FCN naturally operates on an input of any size, and produces an output of corresponding (possibly resampled) spatial dimensions."
Pixels-to-Pixels를 짧게 설명하면 이미지의 pixel마다 classification 학습을 진행한다는 뜻으로 이해하면 될 것 같습니다. 그렇기 때문에 이 논문에서는 최종 segmentation 결과가 모든 pixel을 classification 하는 방식인 dense prediction task라고 설명하고 있습니다.
먼저 위의 문장에서 나오는 semantic information, coarse layer, appearance information, fine layer와 같은 용어들만 정리하도록 하겠습니다.
Appearance information
Appearance는 말 그대로 "외관"이라는 뜻입니다 (appearance: the way a person or thing looks to other people).
사람들의 외관을 파악할 때 보통 전체적인 shape(or 윤곽선)들을 보고 판단하게 됩니다.
CNN의 첫 번째 layer에 있는 filter들은 보통 edge feature들을 추출하기 때문에 "그림 4"에서 볼 수 있듯이 사람의 윤곽과 관련된 feature들이 잘 추출되는 것을 확인 할 수 있습니다.
이러한 세밀한 feature들(=edge)을 잘 추출한다고 하여 CNN의 초기 layer들을 fine layer라고도 합니다.
반대로 마지막 layer에서 추출된 feature들만 보면 이 물체의 외관(appearance)이 어떤지 알기 힘들다는걸 확인할 수 있습니다.
Semantic information
Semantic은 "의미론적"이라는 뜻을 지니고 있습니다.
"그림 4"에서 볼 수 있듯이, 보통 CNN에서 제일 deep한 위치에 있는 layer들이 뽑는 feature들을 보면 객체의 외관을 파악하기 힘든 반면, feature들이 활성화된 부분들을 보면 옷과 같이 하나의 의미를 갖는 정보들을 보여준다는걸 알 수 있습니다.
Coarse는 (fine과 반의어로 사용될 때) 굵다라는 뜻을 갖고 있습니다.
앞서 언급한 fine(=미세한; edge) feature들을 뽑은 초기 layer들과 비교해서 생각하면 여기서 언급하는 coarse의 의미가 어떻게 쓰인건지 파악하실 수 있을거라 생각됩니다. (Coarse: rough and not smooth or soft, or not in very small pieces)
그림 4 이미지 출처: https://www.researchgate.net/figure/Visualization-of-hierarchical-deep-features-Convolutional-layers-of-a-typical-CNN-model_fig1_318392516
(↓↓↓CNN구조에서 layer의 깊이에 따라 conv filter가 뽑는 feature들이 다르다는걸 설명한 내용↓↓↓)
FCN은 semantic information과 appearnace information을 combining(결합)하여 사용 한다고 하는데, 이 부분은 "4.2 Combining what and where"에서 더 자세히 설명하도록 하겠습니다.
1. Introduction
CNN의 등장으로 인해 classification task, local task(ex: object detection, key-point detection (or landmark detection), local correspondence와 같은 분야에서 엄청난 발전을 이룰 수 있었습니다.
Local correspondence는 따로 task라기 보다는 , CNN은 conv filter는 구조상 주변 pixel들을 고려하여 최종 값을 도출하기 때문에 local corresponence를 상대적으로 잘 고려해준다고 하여 local correspondence에 advance가 있었다고 표현한 것 같습니다. (CNN이전 모델들(ex: ML모델, SIFT, DNN(Deep Neural Network) 구조)에서는 pixel간의 local 정보를 무시하면서 학습하는 경향이 있었습니다)
이 논문이 나올 당시에는 아직 CNN 베이스의 segmentation 모델이 없었기 때문에, 앞서 object detection, classification과 같이 전체 이미지(=coarse)를 기반으로 task를 수행하는 것이 아닌, 이미지의 pixel(=fine)들 마다 classification 해주는 dense prediction을 수행할 수 있도록 연구가 되어야 한다고 주장하고 있습니다.
이러한 task를 위해서는 pixel마다 labeling을 해줘야 한다는 것을 보니, supervised learning 기반으로 학습할 것이라고 추론할 수 있습니다.
앞서 언급한대로 FCN은 end-to-end 방식으로 학습을 진행하며, pixel 별로 classification 작업을 수행하기 때문에 pixel-to-pixel (=dense prediction) 기반의 semantic segmentation을 수행한다고 할 수 있습니다. (참고로 semantic segmentation과 대비되는 개념으로는 instance segmentation이 있는데, instance segmentation은 다음 글인 UNet에서 더 자세히 설명하도록 하겠습니다)
(↓↓↓ semantic segmentation VS instance segmentation↓↓↓ )
또한 supervised pre-training을 이용하는 것으로 언급이 되어 있는데 pre-training을 어떻게 이용할 것인지는 뒷 부분을 봐야 더 명확히 이해할 수 있을 듯 합니다.
FCN은 모두 convolutional layer로 구성되어 있기 때문에 입력 이미지 사이즈에 제약을 받지 않으며 (=arbitrary-sized inputs), dense prediction하기 위해 dense outputs을 출력한다고 설명하고 있습니다.
그외 dense feedforward computation, backpropagation, upsampling, pixel-wise prediction, learning with subsampling pooling라는 개념들은 뒤에서 FCN architecture를 상세히 설명하는 부분을 보고 어떻게 연계되는지 파악하는 것이 좋을 것 같습니다.
asymptotically (점진적으로), absolutely 효과적이라고 표현하고 있는데 뒷 부분에도 따로 부가 설명을 하고 있지 않아 정확한 의미를 파악하진 못했습니다. (그냥 개인적으로 유추했을 때 이전 CNN 기반이 아닌 segmentation 모델이 CNN처럼 hierarchical 하지 않거나, 성능적으로 좋지 않기 때문에 "asymptotically, absolutely"라는 표현을 사용한게 아닌가 싶습니다. 혹시 아시는 분이 있으면 댓글 달아주세요!)
사실 FCN이 나오기 전에도 딥러닝 방식이 사용되긴 했으나 이것을 최초의 딥러닝 기반 segmentation 모델로 보고 있진 않습지만, FCN 모델의 우수성을 설명하기 위해 대비되는 개념으로 자주 등장하기 때문에 정확히 이해하고 있을 필요가 있습니다.
그럼 지금부터 FCN 이전에 나왔던 두 가지 방식 segmentation 학습 방법론을 설명하면서 이 논문에서 제기하고 있는 FCN 이전 모델들의 단점을 좀 더 자세히 설명해보도록 하겠습니다.
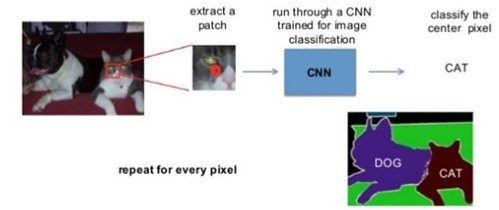
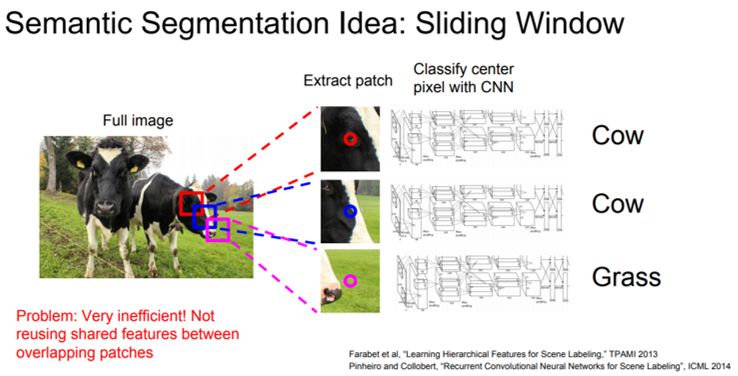
FCN이전에 고안된 첫 번째 segmentation 학습 방법론은 patchwise(≠pixelwise) 학습 방식입니다.
Patchwise learning 방식은 아래와 같습니다.
특정 크기의 patch를 설정해주고 CNN에 입력해 줍니다.
입력으로 들어간 patch는 CNN에 의해 classification이 됩니다.
이때 특정 class로 분류가 되었다면, 해당 patch 중앙에 위치한 pixel을 해당 class로 분류해줍니다.
이러한 과정을 슬라이딩 윈도우 (sliding window) 방식으로 반복하게 됩니다.
그림5. 이미지 출처: https://www.slideshare.net/xavigiro/image-segmentation-d3l1-2017-upc-deep-learning-for-computer-vision
그림6. sliding window 방식
이러한 Patchwise learning 방식에는 여러 문제들이 있었습니다.
문제점1: 모든 Patch들을 CNN에 넣고 일일이 분류하는 작업을 수행하면 너무 많은 계산량을 요구하게 됩니다.
문제점2: Patch 크기를 키우면하나의 patch에 두 개의 class가 동시에 들어가 있을 확률이 크기 때문에 어떻게 classification 해줄지 애매한 경우가 생깁니다. 또한, patch 끼리 겹치는 부분이 커지므로 중복계산이 진행되는 경우가 많아지겠죠.
문제점3: 그렇다고, 다시 patch 크기를 줄여주면 low resolution을 갖게 되는 문제가 발생합니다. (CNN에 input image로 들어가는 patch가 low resolution이라면 classification accuracy가 떨어질 가능성이 크겠죠? → 보통 CNN의 입력 크기가 클 수록 classification accuracy, object detection accuracy가 높아집니다)
그림7 출처: Patch 방식
FCN이전에 고안된 두 번째 학습방법론은 pixelwise 방식입니다. FCN이전 pixelwise 방식은 아래와 순서로 진행됩니다.
전체 이미지를 CNN에 넣어줍니다.
Pooling 과정 없이 feature를 추출해줍니다.
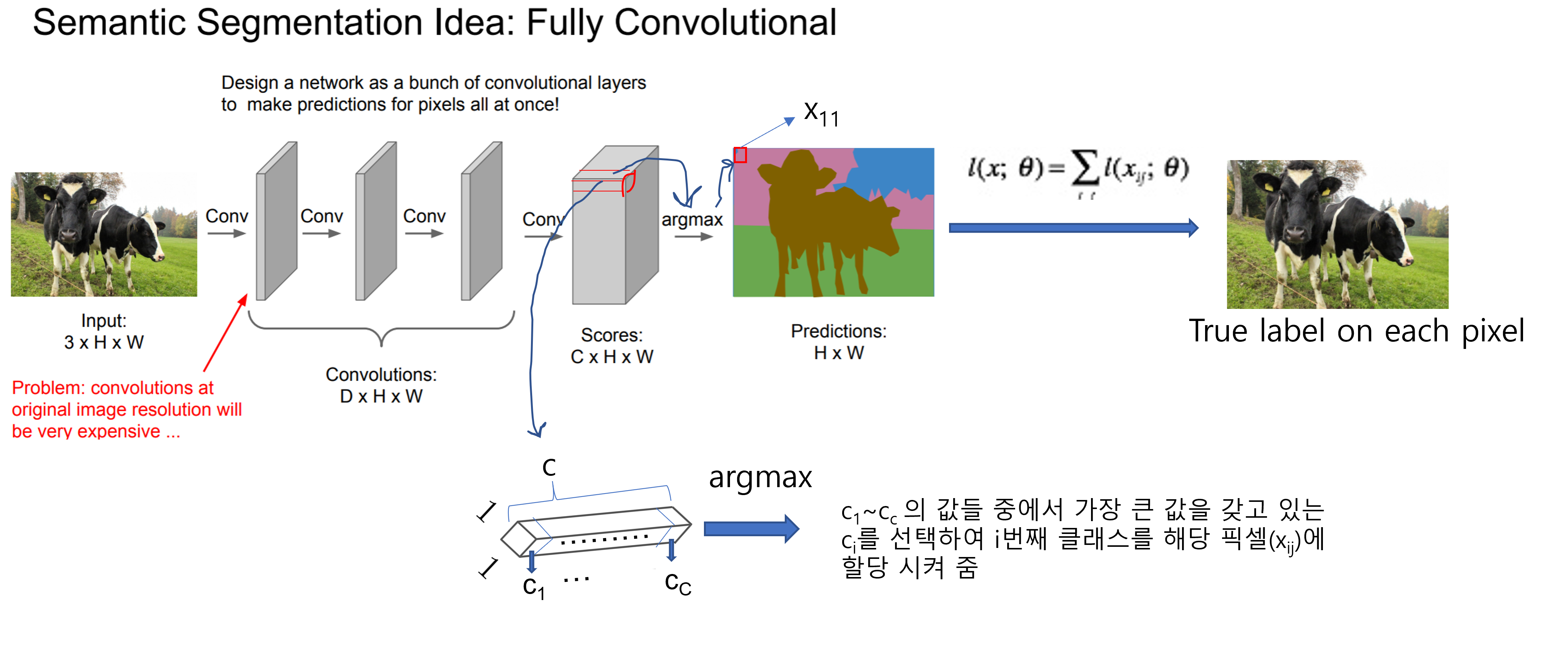
최종결과로 나온 "C×H×W" 형태(=아래 그림에서 "Scores:C×H×W"부분)의 tensor에서 C는 우리가 classification하고 싶은 class의 총 개수를 의미합니다. 다시말해, 최종 결과로 나온 "C×H×W" 형태의 tensor는 classification scroes (map)이라고 할 수 있습니다.
각 픽셀 위치(\(x_{ij}\))에 해당하는 score map (=C×1×1)에서 제일 높은 i번째 class score를 지닌 \(c_i\)에 맞는 색을 할당시켜줍니다.
이미지 상의 모든 pixel에 대해 할당작업이 끝나면 최종적으로 prediction 결과 (prediction map=H×W)가 나옵니다.
Supervised learning 방식으로 학습이 진행되기 때문에 ground truth로 설정된 H×W의 true pixel들 정보가 존재합니다. Prediction (H×W)와 True label (H×W)에 대한 정보를 이용해 각각의 위치에 mapping되는 pixel들끼리 (classification) loss function을 적용시켜 줍니다. 이때, 각각의 위치에 해당되는 prediction과 true label pixel들간 계산되는 loss function은 cross entropy로 진행됩니다. 이러한 loss function 방식을 pixelwise loss function이라고 합니다.
아래 "그림8"에서는 각각의 pixel들의 loss를 총합하여 최종 loss값을 출력해주고 있는데, 각각의 pixel에서 계산된 loss의 총합(sum)으로 최종 loss를 출력할 수도 있고, 평균값(=sum/total number of pixels)으로 최종 loss값을 출력할 수 있습니다.
그림8 출처: pixelwise 방식
위에서 설명한 내용을 CS231n에서는 아래와 같이 표현합니다.
You could see this tensor (C,H,W) as just giving our classification scores for every pixel in the input image at every location in the input image.
You can imagine training this thing by putting a classification loss at every pixel of this output, taking an average over those pixels in space, and just training this kind of network through normal, regular back-propagation.
Q.Whatis loss function?
Since we’re making a classification decision per pixel, then we put a cross-entropy loss on every pixel of the output.
Sowe have the ground truth category label for every pixel in the output, then we compute across entropy loss between every pixel in the output. And the ground truth pixels and then take either a sum or an average over space and then sum or average over the mini-batch.
앞서 언급한 FCN 이전의 pixelwise segmentation 방식은 방대한 계산량과 구조적인 feature를 뽑지 못한다는 문제점을 갖고 있습니다.
일반적인 CNN구조와 비교하면 쉽게 알 수 있습니다.
일반적인 CNN 구조(아래그림=VGG)는 layer가 깊어질 수록 더 많은 channel depth를 갖게 됩니다.
그렇기 때문에, 증가하는 channel depth에 맞게 feature map size도 (pooling 연산을 통해) 줄여줌으로써 일정한 계산량을 유지시켜 줍니다.
하지만, 앞선 방식에서는 pooling 연산을 적용시키지 않기 때문에 layer가 깊어질 수록 계산량이 굉장히 많아진다는 문제와 hierarchical feature(←글 앞 부분에서 설명함)를 뽑지 못하는 문제점을 갖고 있습니다.
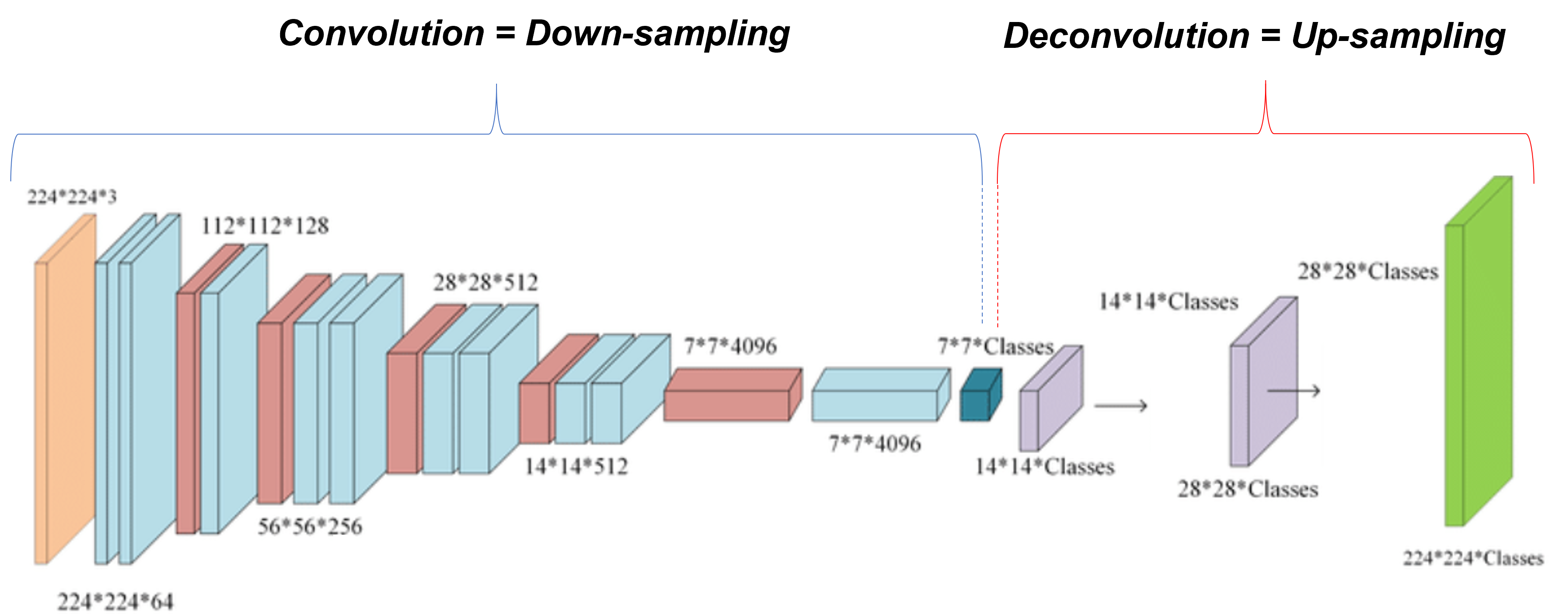
결과부터 이야기하자면 위와 같은 문제로인해 FCN이 고안됩니다. 즉, FCN의 encoder 부분을 기존 CNN 방식처럼 수행하고, decoder(=upsampling) 부분을 붙여 segmentation 작업을 수행해줍니다. 자세한 설명은 FCN 모델 구조를 다루는 파트("3.Fully convolutional network"~"4.Segmentation Architecture")에서 하도록 하겠습니다.
그림9 출처: CS231n
위에서 언급한 문제들 외에 FCN 이전 segmentation 모델을 사용할 때 또 다른 문제는 superpixels, proposals, post-hoc refinement와 같은 전,후처리를 수행해야 했어서 번거로움이 있었다고 합니다.
여기에서 "fine-tuning from their learned representations"라는 표현이 있는 것으로 보아, classification에서 사용됐던 CNN conv filter들이 pre-trained model로써 FCN에 적용된 것을 확인할 수 있습니다. (더 정확한건 뒷 부분에서 설명해야 하지만, 결과적으로 먼저 말씀드리면 "FCN=Encoder+Decoder" 구조에서 encoder 부분이 ImageNet으로 학습한 pre-trained CNN model을 사용합니다 → 해당 논문에서 "imageNet"을 검색해보세요!)
FCN이 등장하기 전에 semantic segmentation 모델들은 semantics한 정보와 location 정보들을 어떻게 잘 조합하여 이용할지에 대한 걱정이 있었습니다.
FCN 이전 모델인 "그림 8"을 살펴보면 pooling 연산이 없기 때문에 conv filter가 전체 이미지에서 local 부분에 대한 feature만 뽑기 때문에 local information에 대한 정보만 획득하게 됩니다. 즉, semantic (or context) information을 알아내기는 힘들겠죠.
반대로 input size와 feature map size가 애초에 작으면 local information 에 대한 정보를 뽑을 수 없게 됩니다.
즉, pooling 연산을 적용하지 않는다는 가정하에 보면 semantic information과 local information의 trade-off(=inherent tension)가 발생하겠네요.
하지만 개인적으로 여기까지만 봐서는 왜 local information을 기반으로 "where"를 알 수 있는건지 잘 모르겠어서 "4.2 Combining what and where" 부분을 살펴 본 후 다시 설명해보도록 하겠습니다.
CNN 구조를 이용하면 계층적인 정보(edge→texture→object) 들을 얻을 수 있는데 마치 이것이 feature map size가 작아지면서 encode하는 과정과 같아서 "deep feature hierarchies jointly encode location and semantics in a local-to-global pyramid(=featuer map)"이라고 설명한 듯 합니다.
"skip" architecture를 이용하여 deep layer의 coarse=semantic information와 shallow layer의 fine=appearance 정보를 잘 혼합하여 segmentation에 사용할 수 있다고 설명하고 있습니다. 이 부분이 FCN 논문의 핵심인데 이 부분 역시 "3.Fully convolutional network"~"4.Segmentation Architecture" 파트에서 하도록 하겠습니다.
이후 논문을 전개할 방향성에 대해서 설명하고 있습니다.
마지막 부분에서 PASCAL VOC, NYUDv2, and SIFT Flow 데이터셋을 기반으로 성능을 측정했다는 것을 알 수 있습니다. (일반적으로 NYUDv2, SIFT Flow 데이터 셋은 다른 논문에서 보지 못한듯 하여 따로 설명하진 않겠습니다)
3. Fully convolutional networks
CNN의 기본적인 구조에 대해서 설명하고 있습니다.
첫 번째 layer의 d는 color channel인데 보통 color image는 R,G,B 채널로 구성되어 있으니 d=3이 됩니다.
그리고 location과 receptive fields 부분에 대한 설명은 아래 그림을 표현하고 있습니다.
The receptive field in Convolutional Neural Networks (CNN) is the region of the input space that affects a particular unit of the network.
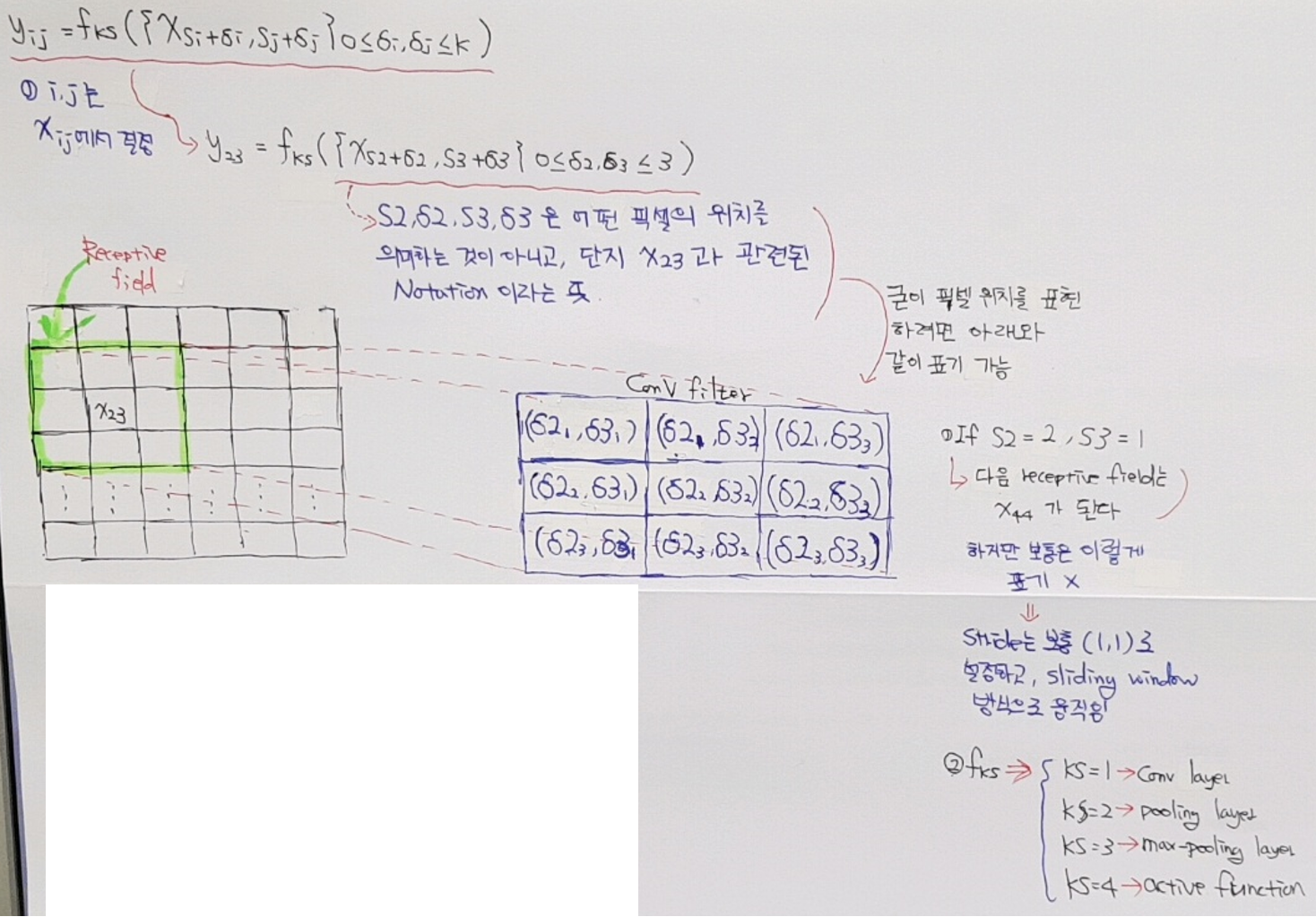
다음은 CNN에서 진행되는 연산들을 \(f_{ks}\)라는 함수 하나로 표현하고 있습니다.
\(x_{ij}\)
\(k\): kernel size
\(s\): stride or subsampling factor
\(f_{ks}\): layer type
convolutional layer
pooling layer (average or max)
activation function(layer)
\(y_{ij}\)
사실 위의 수식은 여러 연산종류(convolution, pooling, activation)를 한 번에 표현하려다 보니 위와같이 표현하려 한 것인데, 제 경우에는 사실 혼동을 줄 우려가 있을 수 있겠다고 생각했습니다.
그래서 제 나름대로 아래와 같이 해석하긴 했는데, 잘 못된 부분이 있으면 말씀해주세요!
앞서 언급했던 \(f_{ks}\) 함수는 위에 있는 합성함수꼴로 대체될 수 있다는 뜻인 듯 합니다 (아니라면 댓글달아주세요!). FC layer 없이 모든 layer가 convolutional layer로 구성(=Fully Convolutional network)되어 있기 때문에 위와 같이 모두 convolution 연산으로 이루어진 합성함수 꼴로 나타낼 수 있는게 아닌가 싶습니다.
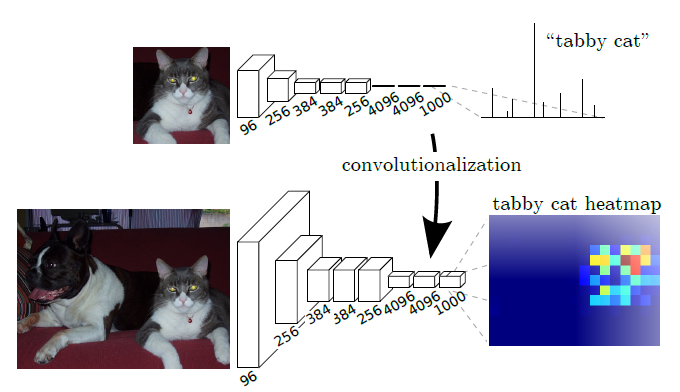
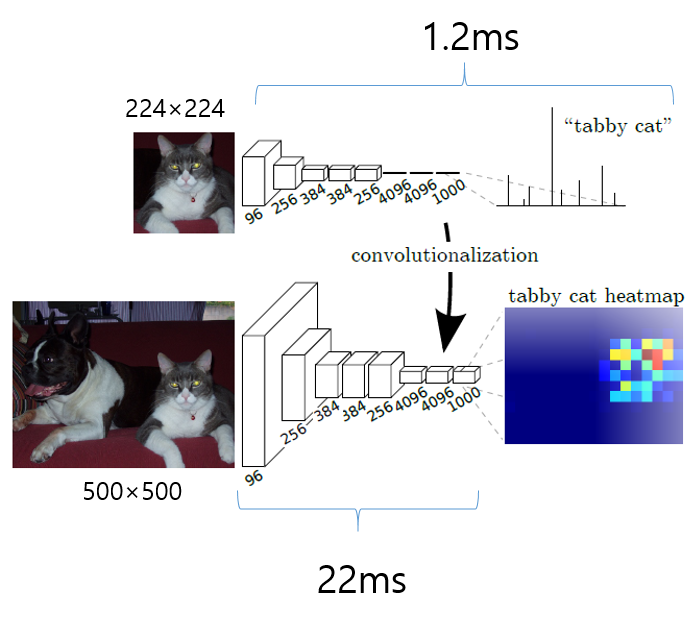
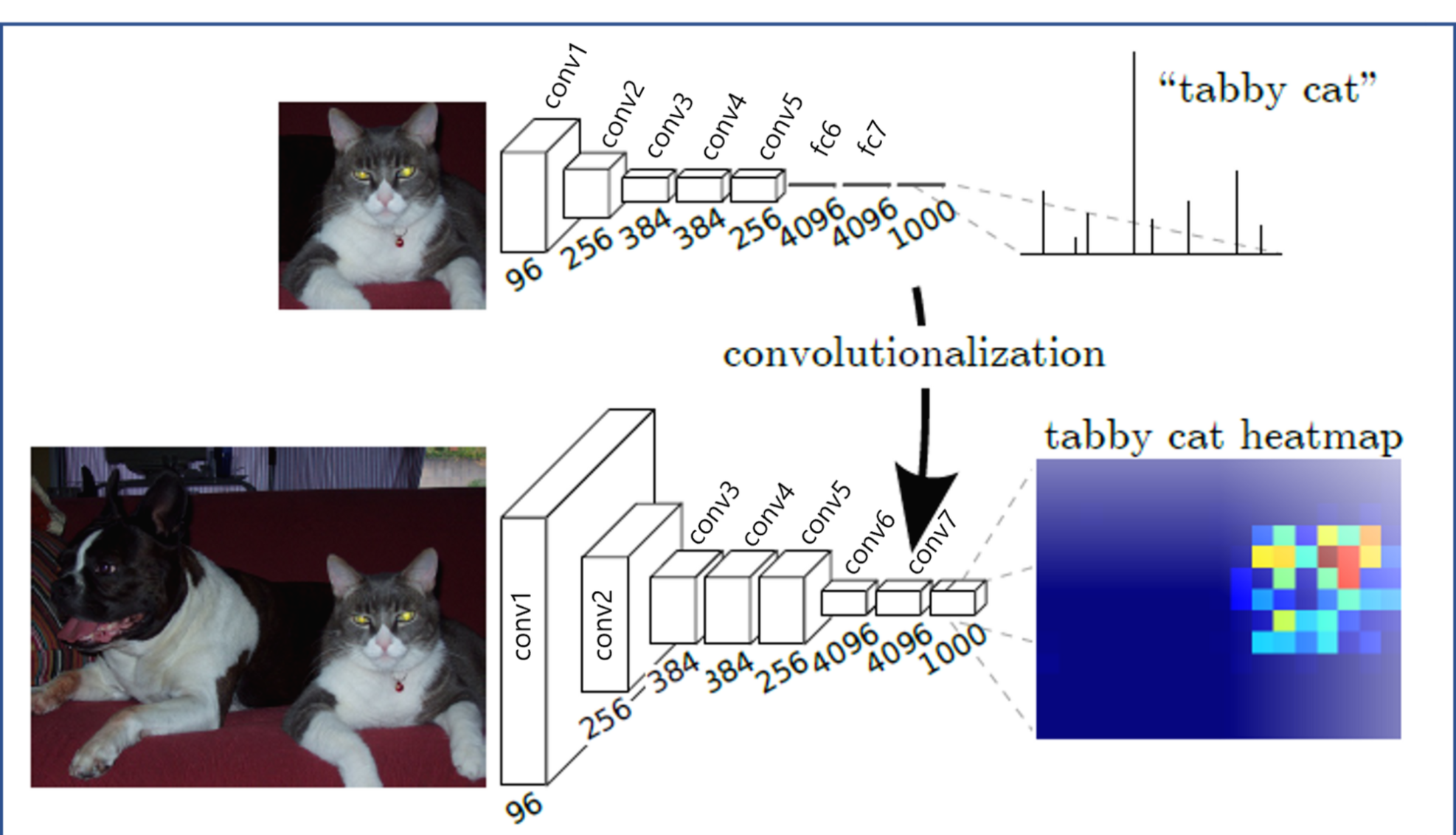
아래 "그림 11"에서 윗 쪽에 있는 CNN을 deep net으로 표현한듯 합니다. 윗 쪽 그림의 deep net을 보면 FC layer를 통해 연산이 prediction 연산이 진행되는데 이 부분에서 non-linear function이라고 표현한 듯하고, FC layer를 convolutionalization을 한 아래 FCN 구조에서는 모두 convolutional filter로 구성되어 있기 때문에 deep filter or nonlinear (conv) filter라고 표현한 듯 합니다 (아마 non-linear라고 한 것을 보아 activation function까지 포함한 의미인듯 합니다). 그림을 자세히 보면 convolutionalization이 적용되기 전의 (전형적인) CNN의 4096이라고 표현된 부분은 FC layer로 인해 flatten된것처럼 표현되어 있는데, convolutionalization이 적용된 FCN의 4096 부분은 N×N의 feature map size에 4096개의 conv filter가 적용된 것 처럼 표현이된 것을 확인할 수 있습니다.
아래 "그림11"을 기준으로 보면 FCN 구조에서는 heatmap 형태로 출력(=output)합니다. 이러한 heatmap을 곧 spatial dimension이라고 할 수 있습니다. (FC layer를 사용하면 feature map의 spatial information이 다 사라지겠죠?)
이러한 spatial dimension을 가지고 resample을 할 수 있다고 설명하고 있는데 이 부분은 "3.3. Upsampling is backwards strided convolution"을 봐야 어떻게 resampling(or upsampling) 하는지 명확히 알 수 있을 듯 합니다. (검색해보니 resampling에는 보통 2가지 종류가 있는데, 그 중 하나가 upsampling하는거라고 하네요. 아마 FCN 구조의 decoder 부분을 말하려고 한게 아닌가 싶습니다)
그림 11. FCN paper
※참고로 위의 그림(그림11)을 자세히 살펴보면 convolutionalization이 적용되기 전의 CNN 구조 입력 데이터는 전체 이미지의 일부 patch라는걸 알 수 있고 flatten되어 FC layer가 적용된 것을 볼 수 있습니다. 반면, convolutionalization이 적용된 CNN 구조는 전체 이미지를 입력으로 받고 flatten 없이 conv filter를 통해 feature map 형태를 그대로 유지하고 있는걸 확인할 수 있습니다. 이 부분이 갖는 장점을 뒷 부분에서 설명하도록 하겠습니다.
FCN에서 사용한 loss function에 대해 설명하고 있습니다.
"그림8" or "FCN이전에 고안된 두 번째 학습방법론" 부분에서 설명한 loss function과 같은 내용이니 해당 부분을 참고하시면 될 것 같습니다.
Gradient descent 부분은 학습 시 사용되는 일반적인 개념을 말로 풀어쓴 내용이니 CNN 구조에서 backpropagation 부분을 함축적으로 설명하고 있구나 생각하시면 될 것 같습니다.
앞서 patch 방식의 학습방법론이 갖는 문제점을 통해 FCN 구조의 장점을 이야기하는 문장입니다.
Conv filter가 receptive field에 많이 중첩(ex: stride=1인 경우)돼서 계산 될 때, 앞서 설명한 아래 그림7 처럼 path-by-path 방식으로 (독립적으로 by indivisual CNN) 계산하는 것보다, 그림9의 layer-by-layer 계산하는 것이 (계산량 측면에서) 더 효율적입니다.
그림7 출처: CS231n
그림9 출처: CS231n
지금까지의 내용은 어떻게 보면 FCN의 알고리즘을 설명했다기 보다는 기존 CNN에 대한 설명과 FCN이 나오기전의 모델들을 살펴보면서 FCN 모델의 우수성을 추상적으로 설명했습니다.
이 후부터는 이전 모델보다 왜 성능이 뛰어날 수 있었는지 FCN의 알고리즘을 구체적으로 살펴보면서 알아보도록 할 예정입니다.
먼저, "section 3.1"에서는 "그림11"처럼 어떻게 classification nets을 fully convolutional nets으로 바꿀지 설명할 예정입니다.
그림 11. FCN paper
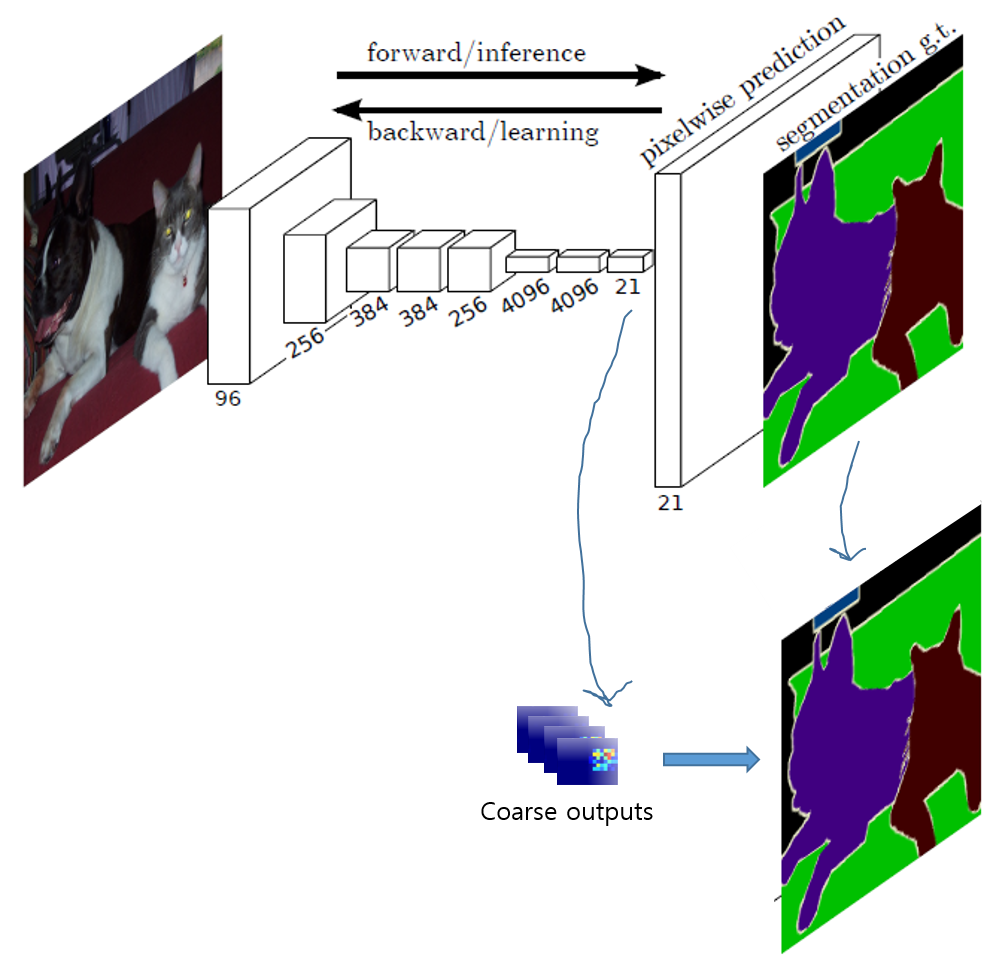
앞서 "그림8" or "FCN이전에 고안된 두 번째 학습방법론" 부분에서 설명했듯이 loss function (for pixelwise prediction)을 계산하기 위해서는 원본 이미지 사이즈와 같은 prediction (map)과 정답 이미지가 있어야 합니다 (FCN이 중간과정(encoding+decoding)이 다를 뿐 결국 동일한 loss function 계산을 한다고 언급했습니다. ←"FCN에서 사용한 loss function에 대해 설명" 이 부분 참고). 이를 위해서 F×F heat map (="coarse output maps") 을 원본 이미지 사이즈만큼 키워줘야 하는데 이를 위해 "Section 3.3"에서 up-sampling이라는 기법을 설명합니다.
"Section 3.2"에서는 OverFeat에서 사용한 trick (="shift-and-stitch")을 설명합니다. 여기서 언급하는 "reinterpreting it as an equivalent network modification"의 의미는 Section 3.2를 봐야 구체적으로 파악할 수 있을 듯 합니다. → 결과부터 말씀드리면 "shift-and-stitch" 방식을 FCN 모델에서 사용하지는 않았다고 합니다.
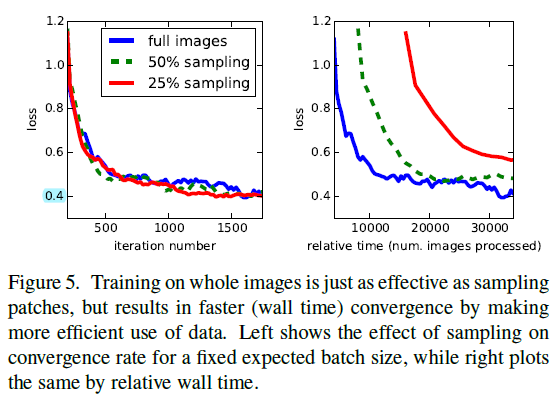
"Section 3.4"에서 pathwise sampling에 의한 training을 했다고 하는데 이 부분도 해당 section을 통해 더 자세히 살펴보도록 하겠습니다. (대략적인 개념은 아래 "그림12"와 같습니다) → 결과부터 말씀드리면 patchwise sampling 방식으로 학습시키는 것보다 그냥 전체 이미지를 이용해 segmentation 학습을 시키는 것이 더 효과적이라고 합니다.
그림12 이미지 출처: https://www.researchgate.net/figure/The-architecture-of-the-patch-wise-convolutional-network-This-paper-splits-the-large_fig3_327941585
3.1 Adapting classifiers for dense prediction
여기서 언급하는 recognition nets이라는건 CNN을 말합니다. 이 논문이 나올 당시 (global average pooling이나 fully convolutional layer와 같은 기법들이 적용되지 않았었기 때문에) input 이미지 크기가 제한된 상태로 CNN 학습이 가능했습니다. 그 이유는 FC layer에 도달하게 되면 직전 feature map이 flatten되어야 하는데, FC layer는 고정된 입력크기(=neuron)를 받아야 하는 구조이기 때문입니다.
예를 들어, 아래 "그림13"을 봤을 때 layer의 수와 conv filter에 적용되는 모든 hyper-parameter(=stride, padding 등)가 고정되어 있다는 가정하에, 입력 이미지의 크기가 매번 다르면 마지막 feautre map을 flatten 시켰을 때 최종 neuron 수들이 이미지 입력 크기에 비례해 다를 것 입니다.
FC layer로 넘어가는 과정에서 feature map이 flatten되면 위치에 대한 정보가 손실된다고 간주하기 때문에 spatial coordinate을 잃어버린다고 표현합니다.
위 "그림13"에서 FC layer 부분을 convolution 으로 바꿔줄 수 도 있습니다.
예를 들어, 아래 "그림11"에서 윗 부분의 CNN을 기준으로 256개의 dimension(=channel)에 해당하는 feature map size가 F×F라고 가정해봅시다. F×F×256개의 neuron이 4096개의 neuron들과 Fully Connection이 되는데, 이때 spatial coordinate을 모두 잃어버립니다. 그런데 FC layer를 적용시키지 않으려면 어떻게 해야할까요?
우선, 아래 "그림11"에서 아래 부분(=convolutionalization 적용된 CNN)의 CNN을 기준으로 256 dimension(=channel)에 해당하는 feature map size가 T×T라고 가정해봅시다. 여기서 flatten 시키지 말고 다시 한 번 conv filter를 적용해 4096 dimension을 갖는 F×F feature map을 출력했다고 해봅시다. 이 후에 "1×1×4096" Conv filter 4096개를 적용시키고, "1×1×4096" Conv filter 1000개를 순차적으로 적용시켰다고 해보겠습니다. 그럼 최종적으로 "F×F×1000"의 output feature map이 출력 됩니다. 위에서 언급한 "cover their entire input regions" 이 부분은 1×1 conv filter가 (sliding window 방식으로) 적용되면서 결국 feature map을 모두 커버하므로 entire input regions를 커버하는 것이라고 표현한 듯 합니다. (아니라면 댓글달아주세요!)
"take input of any size" 이 부분은 사실 upsampling을 봐야 명확히 이해되는건데, 미리 말씀드리자면 (구조적인 관점에서 봤을 때) 결국 아래 "그림14"처럼 output feature map size가 F×F이던지 M×M이던지 상관 없이 해당 output feature map (F×F×21 or M×M×21)을 기반으로 각 upsampling을 진행할 수 있기 때문에 segmentation을 위한 입력 이미지의 크기는 문제가 되지 않는다는 것을 의미합니다.
그림14
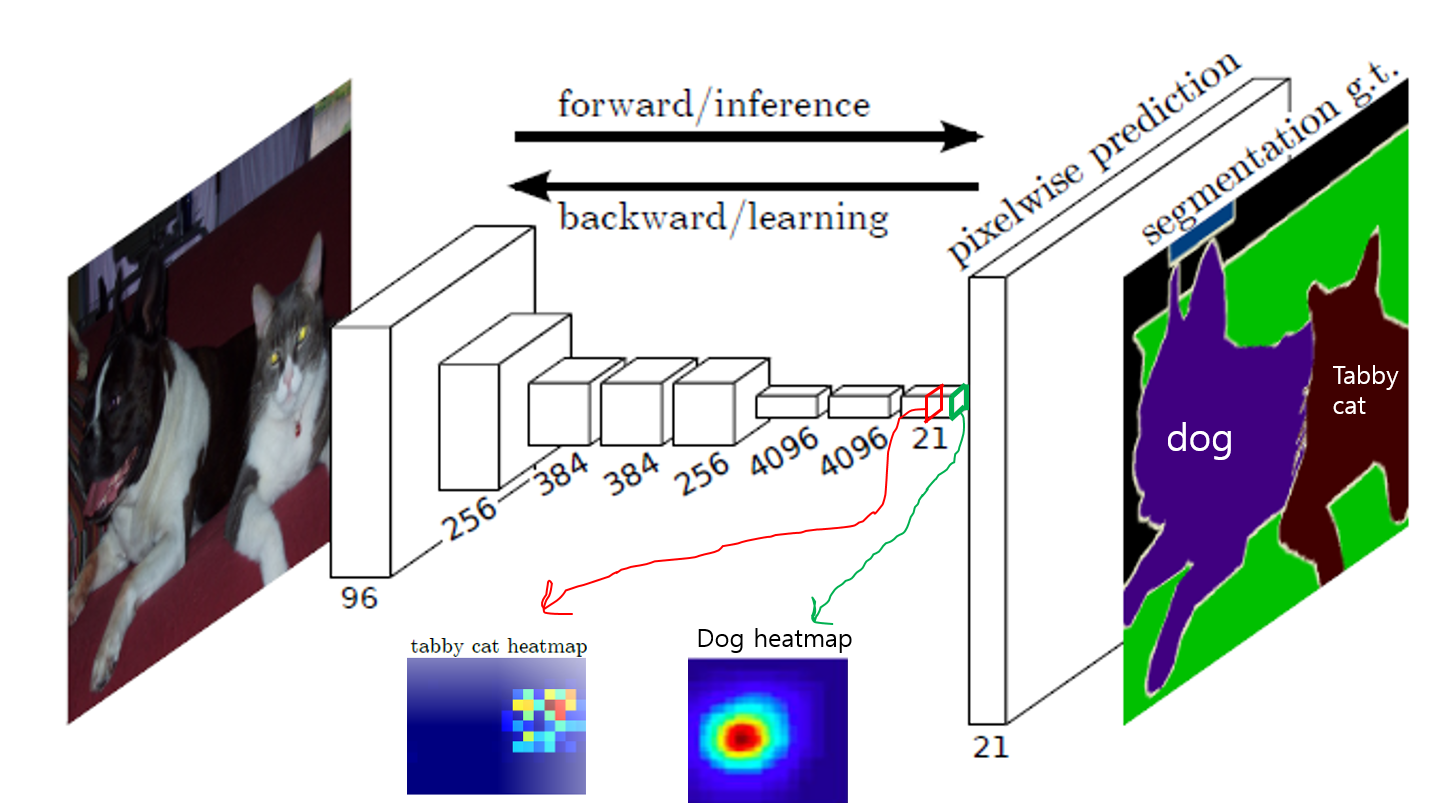
그림 11. FCN paper
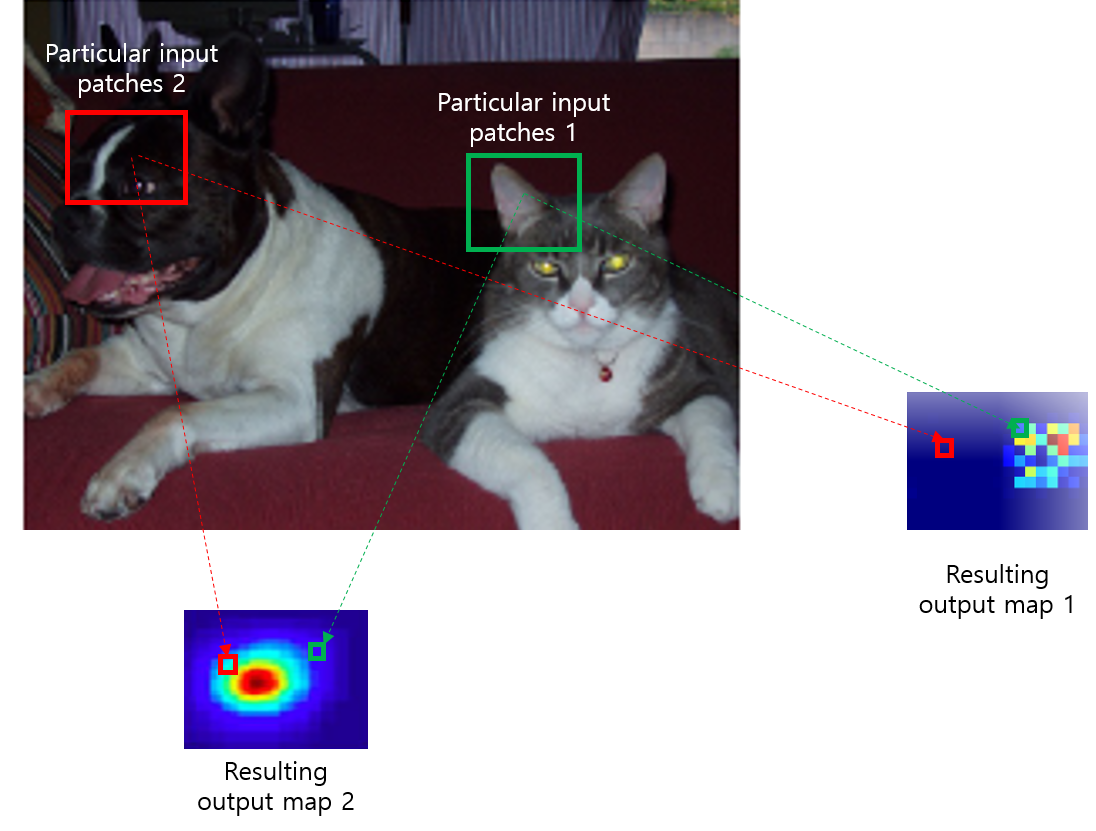
아래 "그림15"를 보면 resulting(=heat) map에 해당하는 특정 위치(pixel)가 input image의 특정 patch상의 CNN evaluation 결과라고 볼 수 있습니다.
그림14그림15
"the computation is highly amortized over the overlapping regions of those patches"라는 표현은 아래 그림과 같이 진행하는 방식보다 FCN으로 할때 더 계산효율성이 뛰어나다는 식으로 이해했습니다. FC layer를 이용한 AlexNet을 기반으로 segmentation하려면 아래와 같이 고정된 input size를 이용하는 patch(=224×224)를 이용해야하는데, convolutionalization된 FCN을 이용하면 input size에 영향을 받지 않으므로 굳이 patch 방식으로 training or inference 할 필요가 없습니다.
그림7 출처: CS231n
아래 그림(그림11)을 보면 convolutionalization이 적용되지 않고 FC layer를 사용하면 patch 단위로 입력이됩니다. 이렇게 되면 위의 그림7처럼 patch(=receptive field)에 속한 pixel(=해당 patch의 중간이 되는 pixel) 부분에 해당 class에 속한 색을 할당해주면서 segmentation을 진행해줍니다.
Q. 보통 FCN이 naive approach보다 5배 빠르다면, naive approach가 110ms 이상된다는 건데, AlexNet 기준으로 1.2ms가 걸린다는 가정하에 500×500 기준으로 patch 방식을 적용하면 100의 patch 별로 계산이 되어야 한다. 그런데, 그림7에서 설명한 방식을 기준으로 하면 100개보다 훨씬 많은 patch가 필요해서 naive approach가 정확히 뭔지 레퍼를 봐야 판단 할 수 있을 듯 하다... 아니면 patch 개수와 위치를 선별적으로 고르는건가.....(혹시 아시는 분이 있으면 댓글달아주세요!)
그림16
이 부분도 앞서 언급한대로 naive approach를 알아야 구체적으로 설명할 수 있습니다.
맥락만봤을 때는 backward 할때 전통적인 segmentation 방식(=여러 patch에 AlexNet(with FC layer)를 적용시킨 것) 보다 FCN 방식이 계산양과 시간적인 측면에서 훨씬 효율적이라는 이야기를 하고 있습니다.
전형적인 CNN 구조에서 output dimension(←이 논문에서 dimension을 검색해보니 spatial dimension으로 언급된 부분도 있어서 subsampling과 같이 사용된걸 보고 spatial dimension을 언급하고 있는거라고 생각했습니다)을 줄여주기 위해서는 pooling과 같은 연산을 통해 subsampling을 적용시켜줍니다. 그래야 다음 conv layer에 적용될 feature map size가 줄어들고, 이로 인해 filter size를 키워줄 필요없이 3×3 conv filter size(=small size)를 유지해줄 수 있게 됩니다. 물론, (더 많은 conv filter도 사용하면서) GPU가 견딜만한 연산량도 유지할 수 있죠.
FCN에서는 이러한 output dimension을 줄여주기 위해 pooling대신 conv filter의 stride를 조절하여 subsampling 했다고 언급하고 있습니다.
3.2 Shift-and-stitch is filter rarefaction
앞선 "3.1. Adapting classifiers for dense prediction" 부분은 FCN 구조에서 encoder 부분을 설명한 것과 같습니다. 즉, 기존 CNN 방식에서 FC layer 부분을 convolutionalization 해주고 최종 output map (or heat map) = coarse output을 얻는 과정을 설명했습니다.
그럼 지금부터 아래 "그림17"처럼 coarse outputs으로 부터 어떻게 dense precition을 하는지 알아보도록 하겠습니다.
※사실 "3.2"에서 설명하고 있는 "shift-and-stitch" 방식이 FCN에 사용되지 않았습니다. 결과적으로 말하자면 이러한 "3.2"와 같은 기법을 이용해 dense prediction을 하려고 했지만 "4.2 section"에서 설명하는 skip architecture 방식이 더 효율적이여서 skip architecture 방식의 upsampling 기법을 사용했다고 합니다.
그래서 여기에서는 shift-and-stitch가 어떻게 동작하는지 알아보기만 하겠습니다.
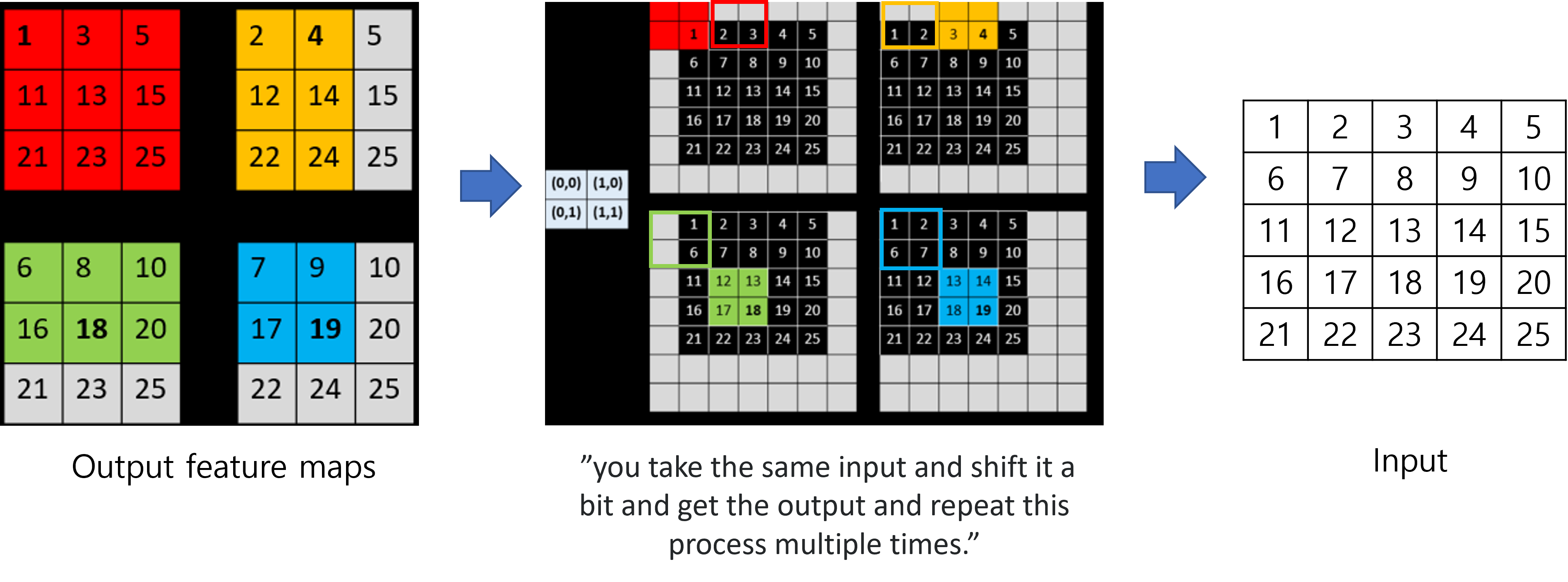
그림17
우선 위에 있는 문장을 말로 설명하는 것보다 아래와 같이 그려서 설명하겠습니다.
위의 설명은 아래 그림 두 개로 대체하도록 하겠습니다.
그림 출처: https://stackoverflow.com/questions/40690951/how-does-shift-and-stitch-in-a-fully-convolutional-network-work
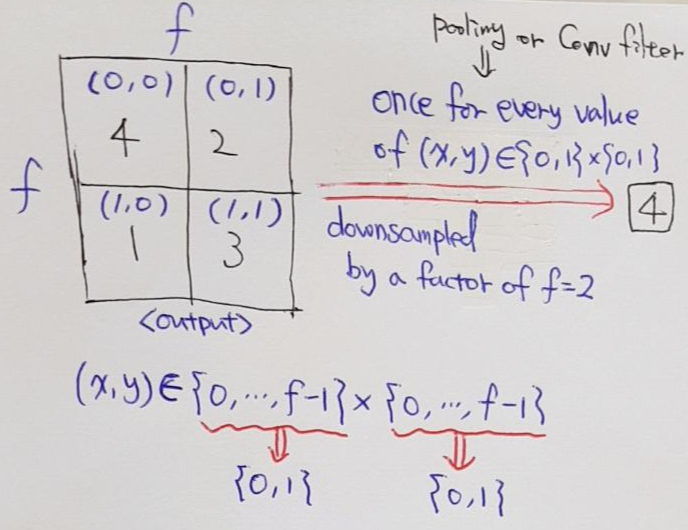
pooling or convolution 을 통해 feature map size를 downsampling 하는 행위 or 정도를 줄여주면 (ex: 행위=pooling or convolution layer 수를 적게 설정 or 정도=pooling or convolution layer의 stride를 작게 설정) trade off가 발생합니다. 다시 말해, downsampling 행위를 줄여주면서 얻는 장점과 단점이 있다는 뜻이죠.
Downsampling이 적용되지 않을 수록 입력 이미지의 크기가 클 것이고 상대적으로 고정된 conv filter (ex: 3×3)가 커버하는 범위 (=receptive field)가 작을 것입니다. 이로인해 computation 시간도 더 오래 걸릴 것입니다. 반면에, downsampling이 적용이 되지 않을 수록 conv filter는 좀 더 finer한 정보를 얻게 됩니다.
Shift-and-stitch trick을 적용시킬 때도 trade-off가 존재 합니다.
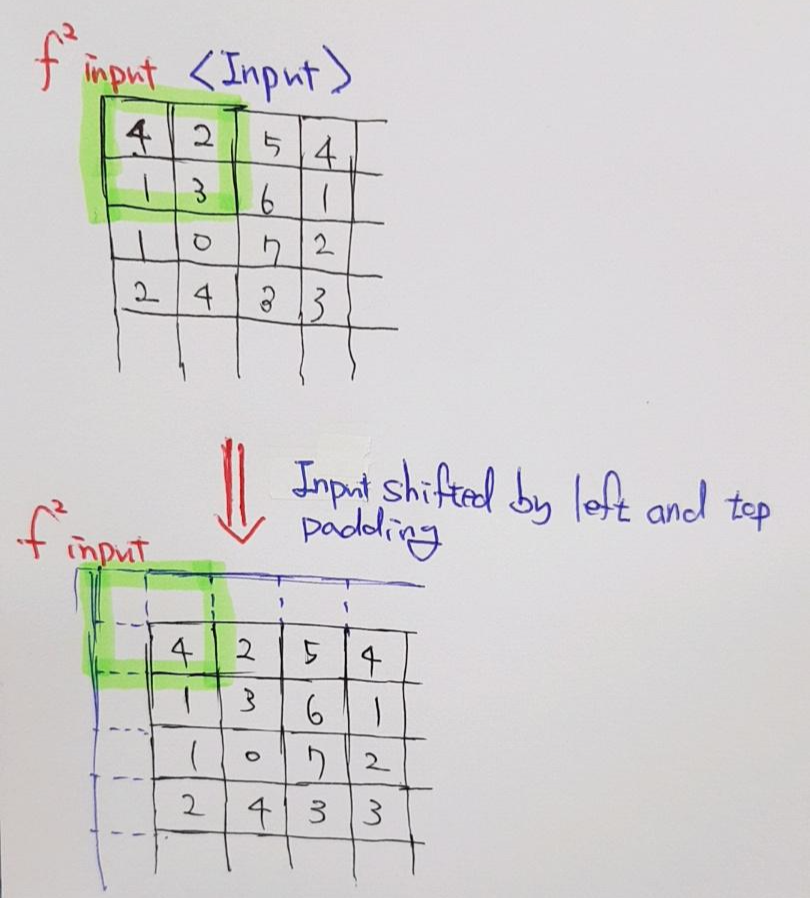
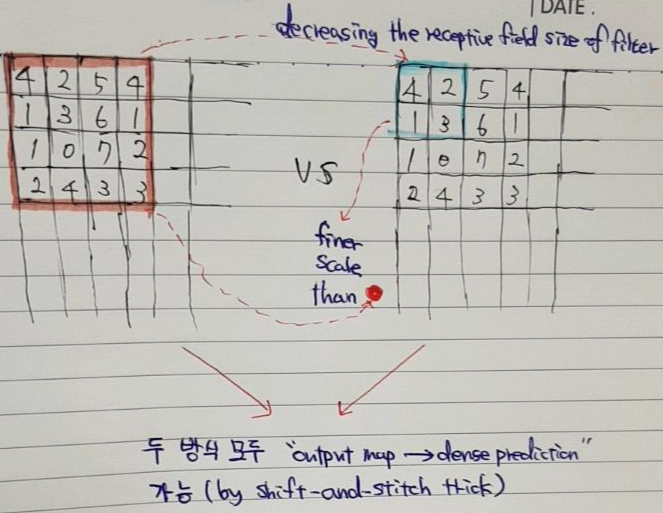
"The receptive field sizes of the filters" (convolution or pooling size) 의 감소 없이도 coarse한 output map을 dense 하게 (for dense prediction) 만들어 줄 수 있지만, "The receptive field sizes of the filters"의 크기가 클 수록 finer scale한 객체 or information에 접근하는 것이 제한이 될 수 있습니다.
앞서 언급했듯이 이 논문에서는 shift-and-stitch trick 방식을 사용하진 않았다고 합니다.
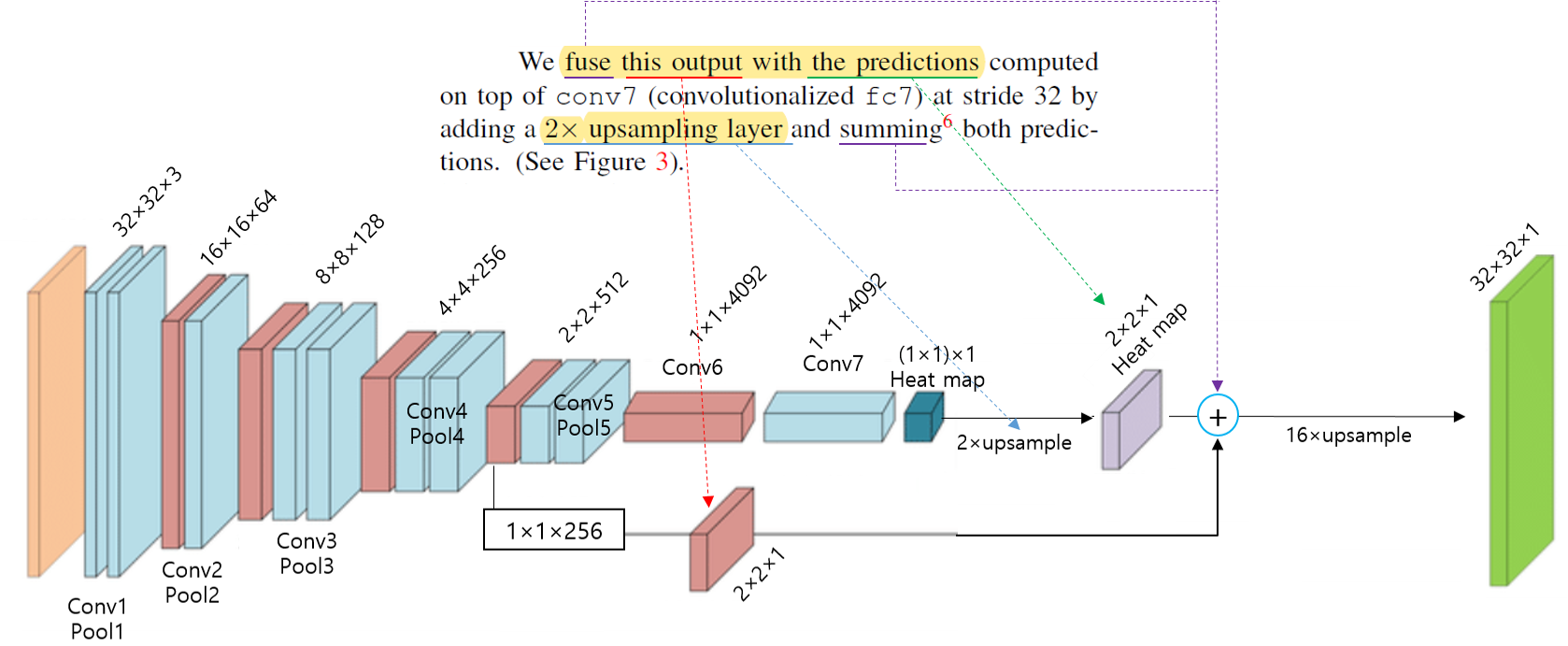
이 논문에서는 upsampling을 위한 방법으로 skip layer fusion을 사용했다고 하는데 이 부분은 "3.3. Upsampling is backwards strided convolution"과 "4.2. Combining what and where" 부분에서 더 자세히 설명하도록 하겠습니다.
3.3 Upsampling is backwards strided convolution
앞서 언급한 shift-and-stitch 방법이 아닌, "Section 3.3"에서 설명하는 기법과 "Section 4.2"의 skip architecture를 결합시켜 upsampling을 진행했습니다.
그럼 지금부터 Section 3.3의 upsampling 방식에 대해서 설명하도록 하겠습니다.
앞서 언급한 shift-and-stitch 방식 외에 사용되는 upsampling 방식은 크게 두 가지가 있습니다.
Interpolation 기법
Deconvolution 기법
1) Interpolation 기법
Interpolation 종류 중 간단한 방식인 bilinear interpolation입니다.
예를 들어, 2×upsampling을 적용 할 시, 10과 30사이에 두 가지 pixel이 들어가게 됩니다. 이 때, 등차수열 개념을 도입해 적용합니다. 만약 10과 20사이에 완벽히 등차수열이 적용되지 않으면 약간의 미세한 조정을 두어 pixel값을 적용시킵니다.
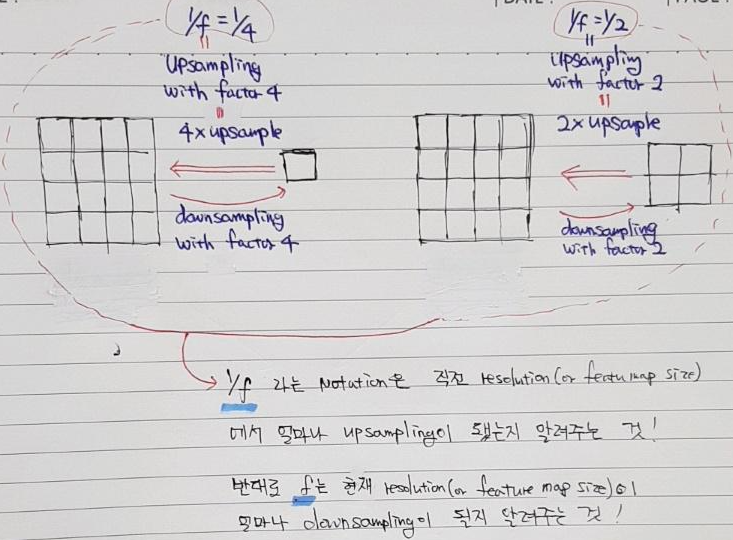
Upsampling하는 방법은 convolution 연산을 이용해서도 할 수 있습니다. (←"a fractional input stride of \(\frac{1}{f}\), "output stride of \(f\)"와 같은 개념을 이용해 정확히 어떻게 연산이 되는지는 "4.2. Combining what and where" 파트에서 설명하고, 이곳에서는 결과적인 부분만 설명하도록 하겠습니다.)
결과적인 측면에서보면 결국 upsampling이라는 것을 deconvolution을 통해 할 수 있습니다. 여기에서는 deconvolution과 backwards convolution이라는 용어를 동의어로 사용하고 있습니다.
convolution이라는 것이 본래 신호처리에서 사용된 개념이라 continuous한 상황을 가정하면 integral 수식을 이용하게 되고, discrete한 상황을 가정하면 sigma 수식을 이용하게 됩니다.
위 논문에서 표현한 integral이라는 표현은 continuous한 개념에서 차용한 것 같고, 실제로 딥러닝 CNN 기반으로 연산이 진행되는 것을 보면 discrete convolution인 것을 알 수 있습니다.
Discrete convolution도 미분 가능 (by chain-rule) 하기 때문에 학습이 가능합니다.
또한 cascade 방식이 아닌 기존 network (내부)에 upsampling과 관련된 deconvolution layer를 붙일 수 있기 때문에 (=in-network), end-to-end 방식으로 학습이 가능합니다.
앞서 언급했던 bilinear upsampling 같은 경우는 upsampling시등차수열로 인해 미리 정의된 값이 할당 됩니다. 즉, 누구나 예측가능한 값(=fix)이 할당되는 것이죠. 하지만, deconvolution filter를 이용해 upsampling을 적용하면, upsampling 적용 시 학습된 deconvolution filter에 의해 우리가 예측하지 못한 값들이 할당됩니다.
deconvolution layer 역시 activation function(=ex: ReLuU ← nonlinear function)이 적용되어 nonlinear upsampling을 배울 수 있다고 할 수 있습니다.
in-network upsampling이라는 표현을 쓴 이유는 deconvolution network(=decoder or upsampling)을 기존 convolution network(=encoder)에 포함(or 결합)시켰시켰기 때문인 듯 합니다.
Deconvolution으로 인해 기존 segmentation 방식보다 좀 더 효율적으로 dense prediction (for segmentation) 할 수 있다고 설명해놨네요.
사실 upsampling이 정확히 어떻게 되는지 여기에서 설명을 하고 있지 않습니다. 그렇기 때문에 추가적으로 deconvolution을 이용해 upsampling하는 방법을 기술하도록 하겠습니다.
[Upsampling by decovnolution]
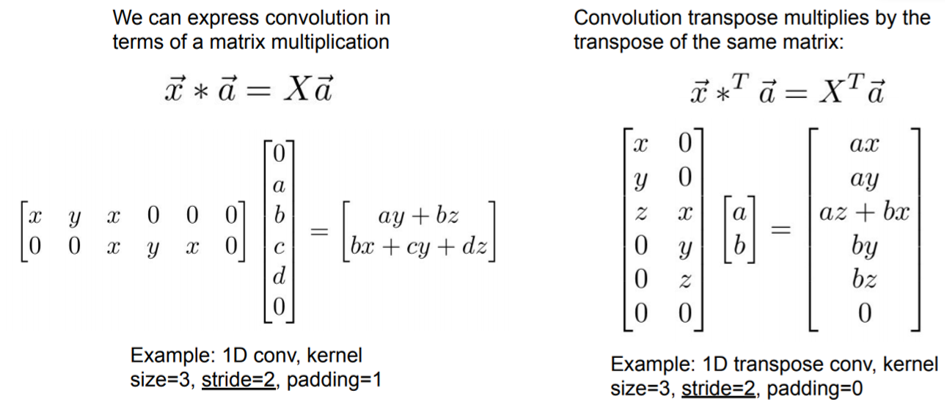
Convolution 연산이 어떻게 되는지 살펴본 후, 역으로 deconvolution이 어떻게 되는지 살펴보겠습니다.
※참고로 여기에서는 deconvolution이라고 설명하고 있는데 pytorch tutorial 구현 코드를 보면 upsampling 시 transposed convolution으로 되어 있습니다. 결국, transposed convolution 방식과 deconvolution을 유사하게 본것이라고 할 수 있겠는데. 엄격히 말하면, transposed convolution과 deconvolution은 같은 개념이 아닙니다. 이러한 부분을 DCGAN 논문에서 지적하고 있는데, 해당 부분은 DCGAN 논문에서 설명하도록 하겠습니다.
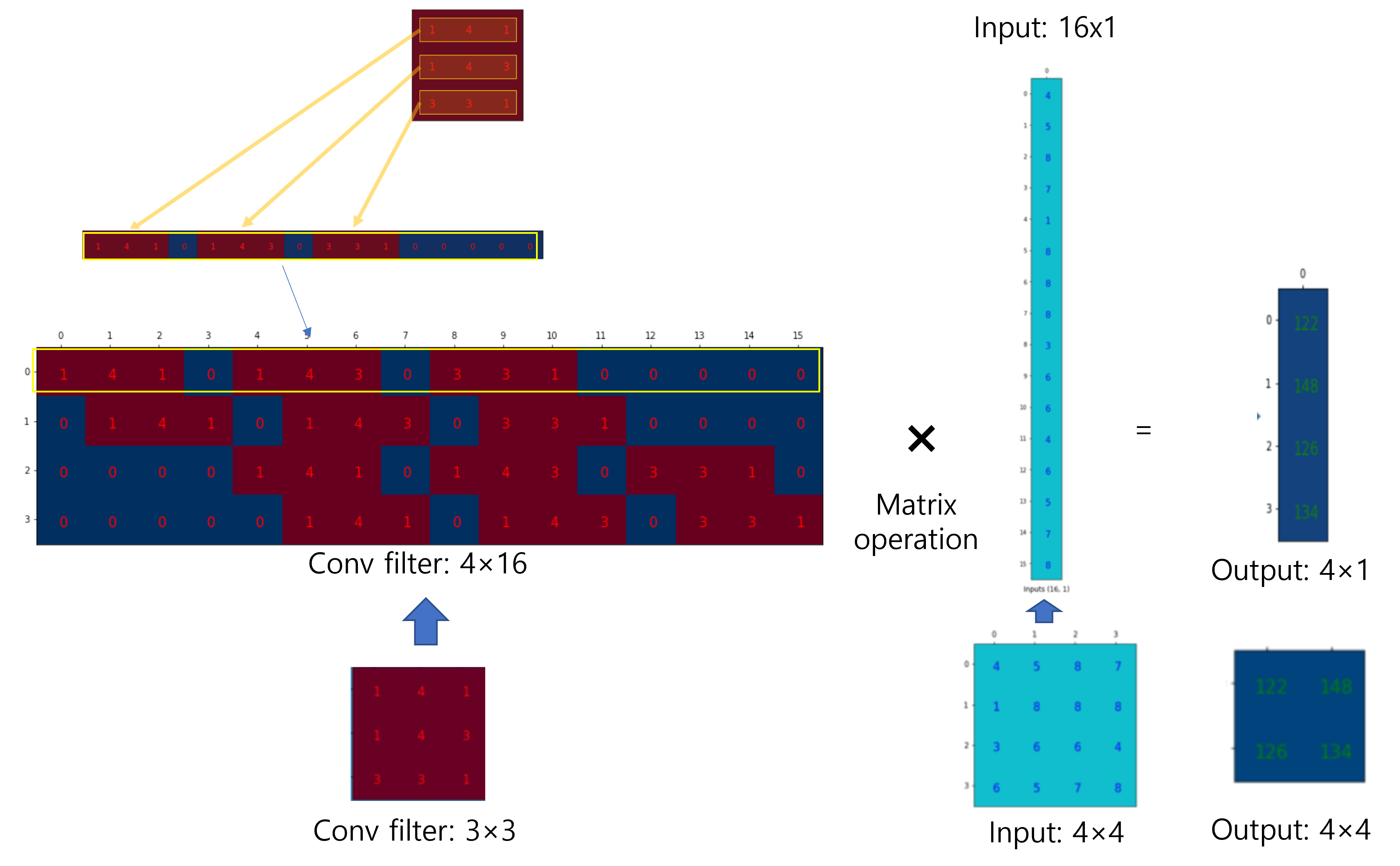
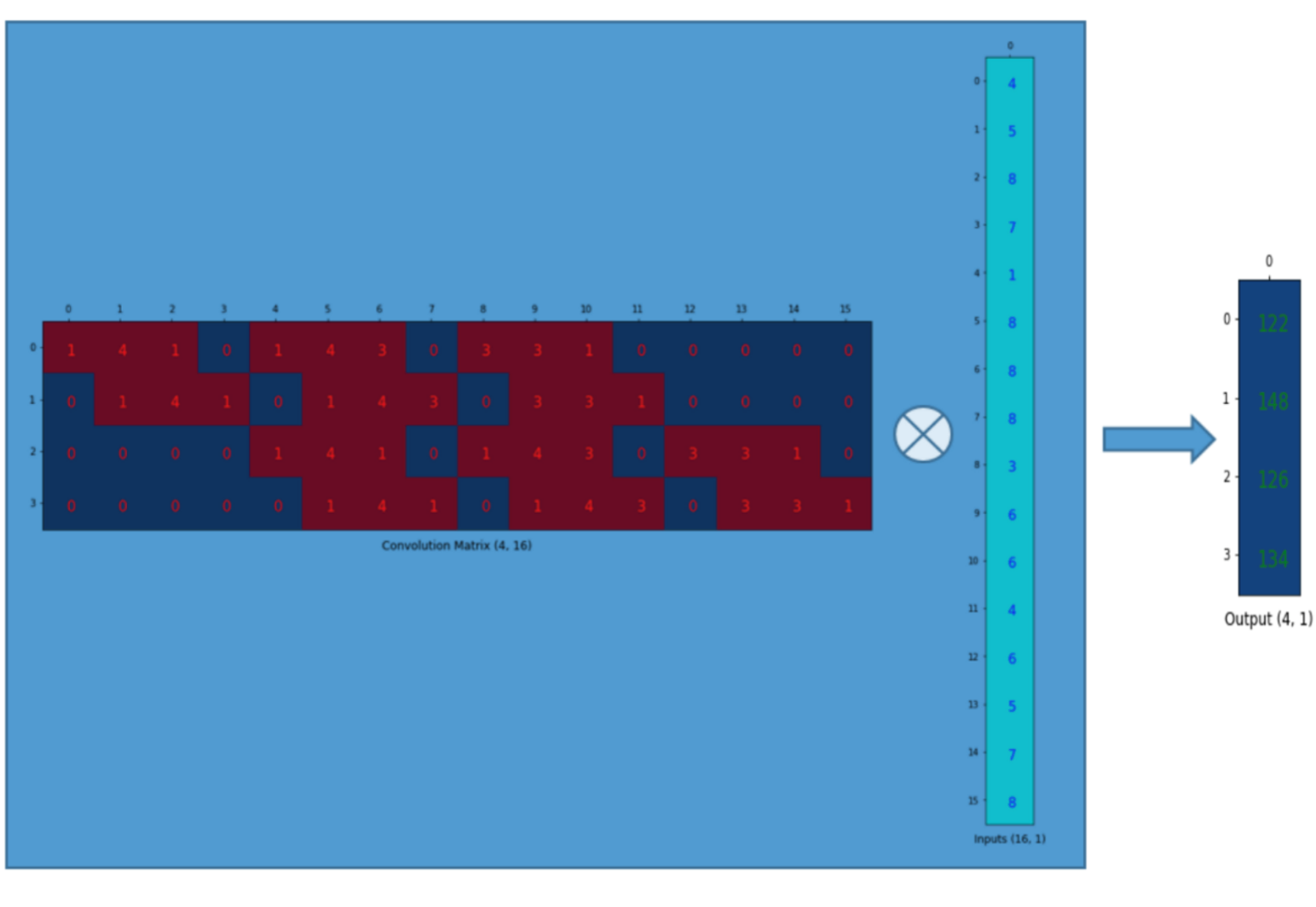
<Step1. Convolution 연산을 matrix 연산으로 변환>
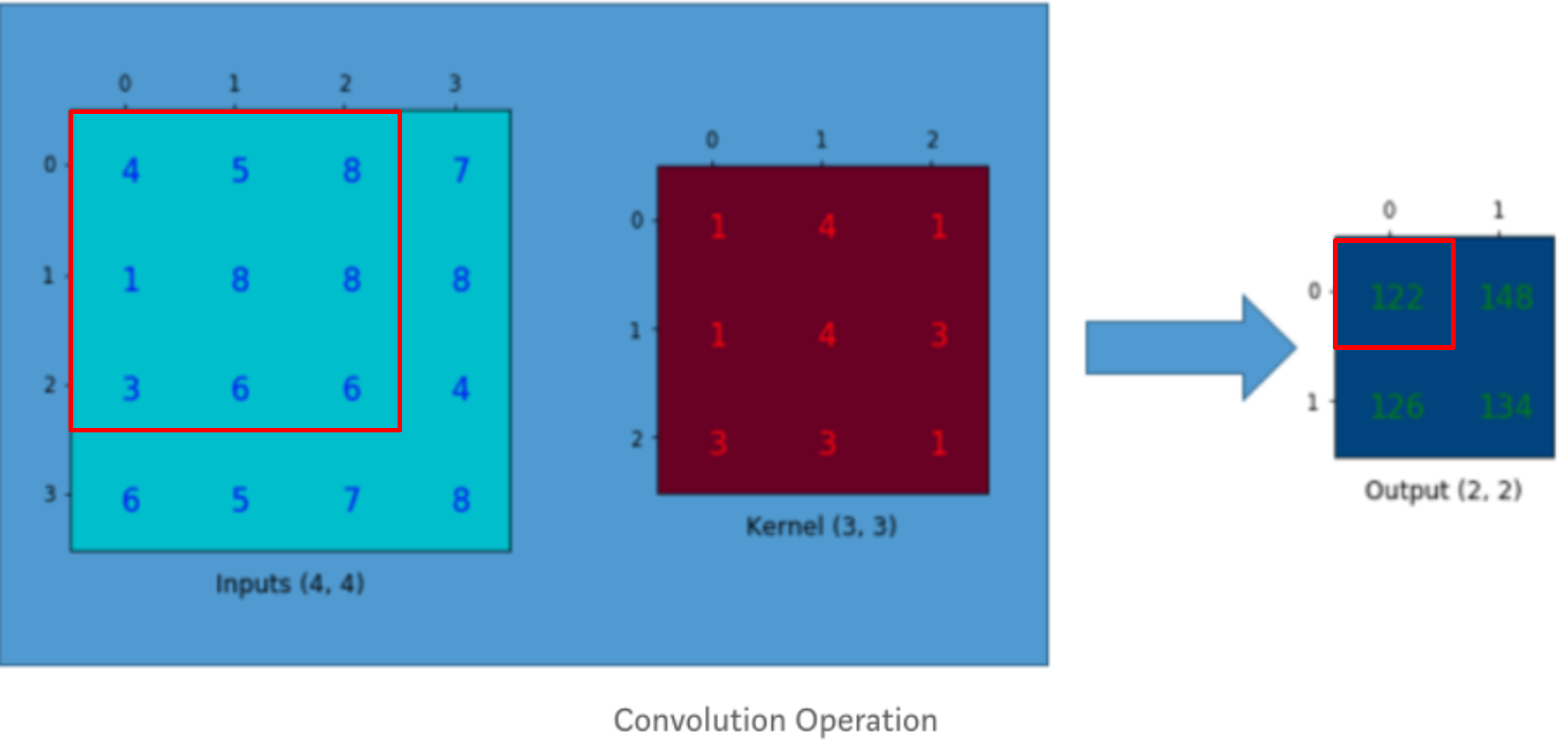
먼저 convolution 연산이 진행되는 방식을 그림으로 표현하면 아래와 같습니다.
그림19
다음은 위의 convolution연산을 matrix연산으로 바꾸어주도록 합니다.
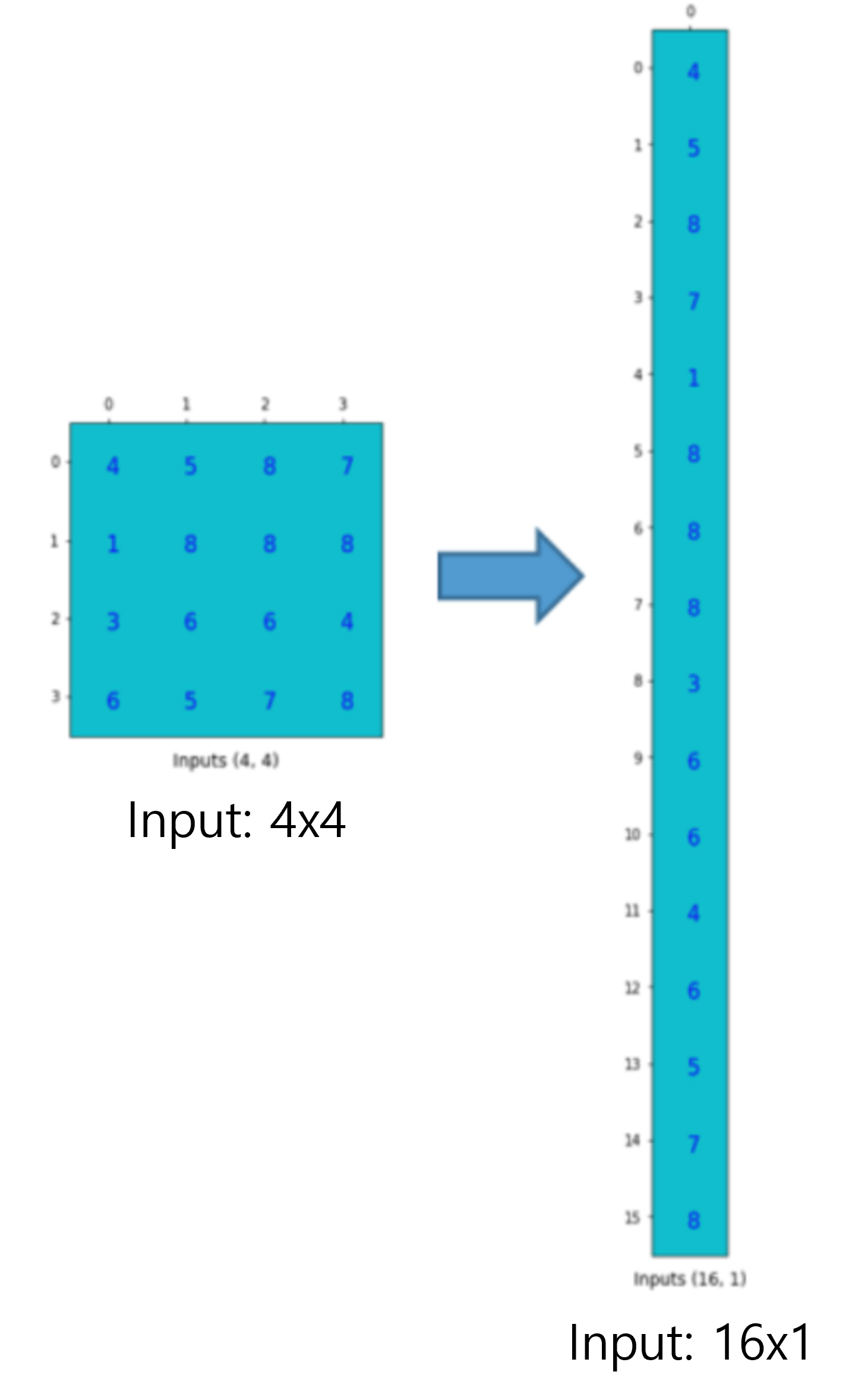
먼저, 입력차원을 (\(N×N\))에서 (\(N^{2}×1)\)로 변경해 줍니다.
그림20
Convolution 연산을 matrix 연산으로 바꿔줘야 하기 때문에 이에 맞게 convolution filter에 해당하는 부분도 convolution 연산 결과와 동일하게 나오도록 알맞는 matrix 형태로 변경해줘야 합니다.
그림21
위의 그림을 간략히 표현하면 아래와 같습니다.
그림22
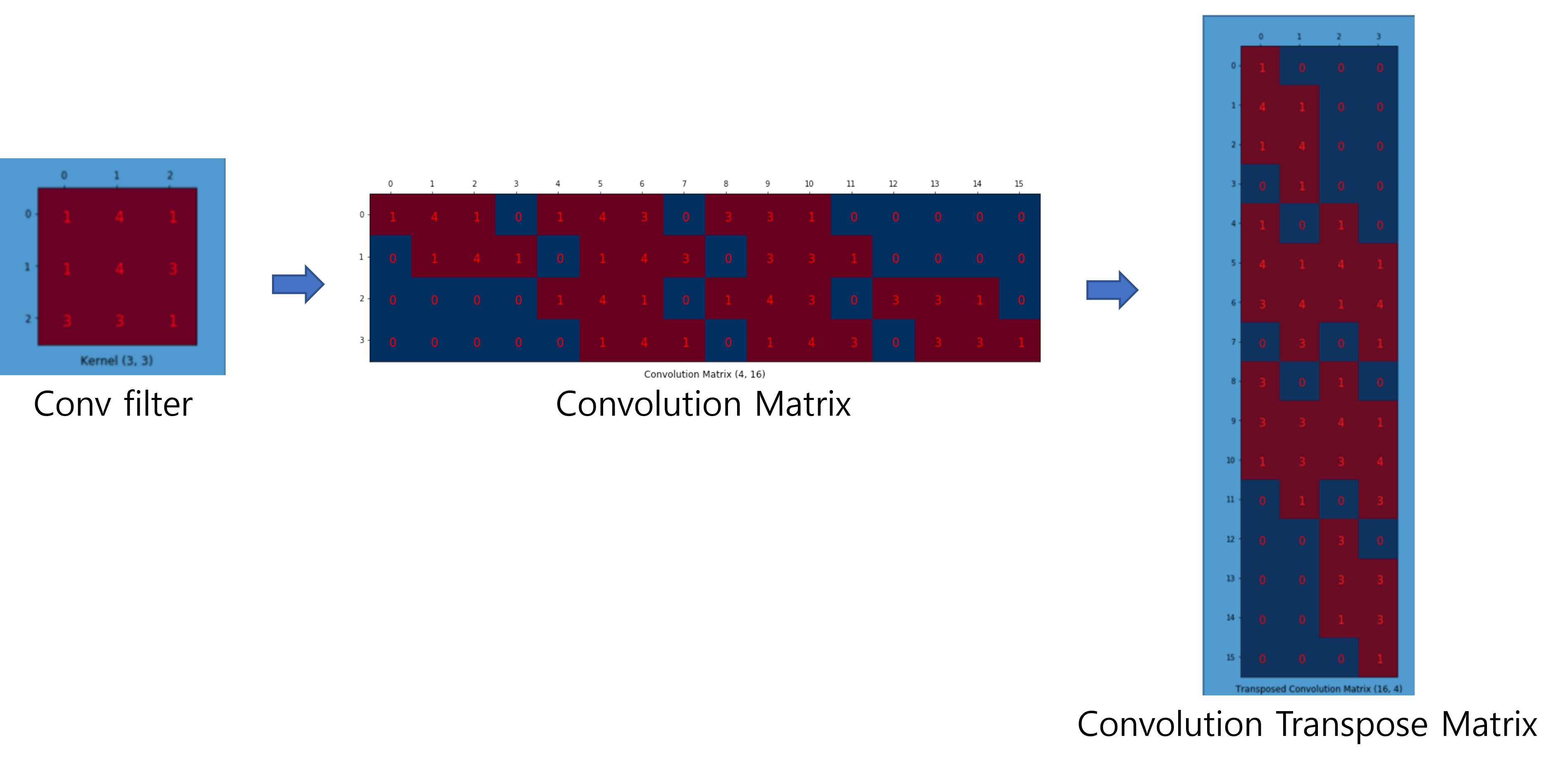
<Step2. Deconvolution 연산>
Convolution filter에 해당하는 matrix (=Convolution Matrix) 를 Transpose 한 Transpose (Convolution) Matrix를 만들어 줍니다.
그림23
위에서 얻은 Convolution Trasnpose Matrix에 맞는 deconvolution filter를 matrix연산에 맞게 바꿔준 후 upsampling을 해줍니다. 이때, deconvolution filter는 "segmentation loss function (with backprogation)"에 따라 segmentation을 최대한 잘 해줄 수 있도록 학습됩니다.
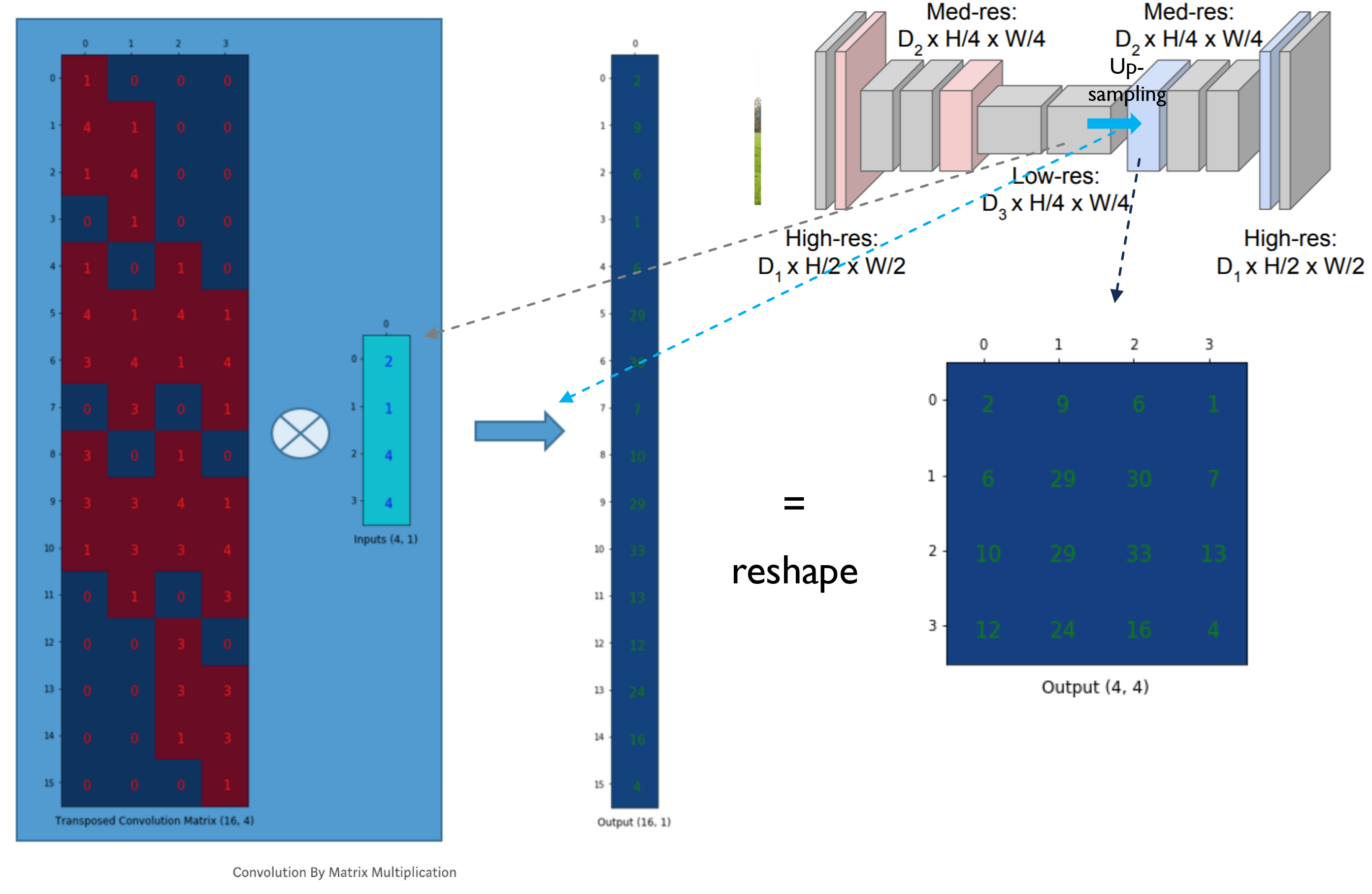
그림24
앞서 설명한 convolution 연산과 deconvolution 연산의 matrix 수식을 아래와 같이 표현할 수 있을 것 같습니다.
결국 upsampling은 위와 같은 deconvolution 연산에 의해 이루어지고, 지금까지 설명한 대로 FCN을 도식화하면 아래와 같습니다.
※하지만, 아래 "그림25"가 최종적인 FCN 모델은 아닙니다. 아래"그림25"에서 skip architecture가 적용되어야 하는데, 이 부분은 "4.2. Combining what and where"에서 더 자세히 설명하도록 하겠습니다.
여기에서는 distriibution이라는 말을 썻는데 그냥 data라고 해석해도 될 듯 합니다. 결국 data가 어떤 distribution을 형성 할 것이기 때문입니다.
Patchwise 방식으로 학습 할 경우 patch들간에 overlap이 많이되면 불필요한 computation양이 많아질 것입니다. 반면에 아래 "그림19"처럼 전체 이미지를 입력받는 fully convolutional training 방식은 전체 이미지 크기가 큰 경우 GPU 메모리를 상당 부분 차지하기 때문에 충분한 minibatch size를 잡기 힘듭니다.
"whole image ~" 이 부분은 그냥 pathwise 방식에서 patch가 전체 이미지가 되면 'whole image fully convolutional training'이 된다는 의미로 받아들였는데 확실하진 않습니다 (혹시 정확한 개념을 알고 있으시면 댓글달아주세요!)
그림19
이 부분은 DropConnect mask 부분을 이해하면 좋을 것 같은데, 다로 볼 시간이 없어서 위의 내용이 정확히 이해가 안되네요;;; (혹시 아시는 분은 댓글 부탁드립니다!)
이 부분은 patch 방식으로 학습시킬 경우 발생할 수 있는 현상에 대해서 기술 한 듯 합니다.
논문 앞 부분에서 "그림7"을 통해 설명한 것 처럼 한 이미지 내에서 두 patch의 중첩되는 영역이 많다면 당연히 fully convolutional computation으로 학습시키는 것이 더 빠를 것 입니다.
mini-batch 단위로 학습시키면 다른 이미지들로 부터 얻은 다 수의 patch를 기반으로 multiple backward pass를 계산한뒤 각각의 patch에서 얻은 gradeint값을 축적한 후 weight update를 위해 사용하게 됩니다.
Patch 방식의 training을 적용했을 때 더 빠르게 학습한다거나 loss가 잘 수렴한다던지의 장점은 없었다고 합니다. (앞서 patchwise sampling이라는 말이 있는데 위에서 언급하는 sampling은 patchwise sampling을 언급하는 듯 합니다)
Fully convolution training 방식으로 전체 이미지를 입력으로 받아 traning 시키는 것이 효과적이고 효율적이라고 합니다.
4. Segmentation Architecture
FCN 모델 구조를 보면 downsampling 부분은 기존 classification task에 사용되었던 CNN 구조와 동일함을 알 수 있습니다.
위와 같은 이유로 인해 ILSVRC 데이터 셋으로 학습된 CNN 모델들 (ex: AlexNet, VGG16, GooLeNet) 등을 FCN 모델의 downsampling을 위한 pre-trained model로 사용했습니다.
이 후, segmentation을 학습시킬 때 downsampling에 적용된 pre-trained 부분을 fine-tuning 시켰다고 합니다.
Segmentation의 성능을 높이기 위해 "novel skip architecture"를 적용했다고 하는데, 이 부분은 "4.2. Combining what and where" 에서 더 자세히 설명드리겠습니다.
앞서 segmentation 학습을 위해 fine-tuning 시킨다고 언급했는데, PASCAL VOC 2011 데이터 셋으로 fine-tuning 시킨것으로 추측됩니다.
Perforamnce measurement로는 "mean pixel intersenction over union"이 사용되었습니다. Performance measurement는 "5. Results" 부분에서 더 자세히 설명하도록 하겠습니다.
그림8 출처: CS231n
Segmentation을 위한 loss function은 pixel 마다 multinominal logistic loss가 사용되었습니다.
(↓↓↓multinominal logistic loss와 cross entropy의 관계를 설명한 글입니다.↓↓↓)
앞서 그림 11에서 기존 CNN을 어떻게 convolutionalization 해주는지에 대해 언급하고 있습니다.
이 부분은 앞에서 충분히 설명했으니 넘어가도록 하겠습니다. (대략적으로 설명하면 마지막 layer 부분 (=classifier layer)을 제거하고 1×1 conv filter를 적용시켰다는 이야기 입니다)
그림 11. FCN paper
이 논문에서 실험한 segmentation 모델 (FCN with AlexNet, FCN with VGG, FCN with GoogLeNet) 중에 가장 성능이 나쁜 모델 조차도 당시 conventional segmentation 모델 중 SOTA에 해당하는 모델의 75% 정도 성능을 보여줬다고 합니다.
특히 FCN-VGG16 모델은 segmentation 결과 SOTA 성능을 기록했는데, 추가적인 training을 진행 했을 때, 그 성능이 더 올라갔다고 합니다.
VGG-16과 GoogLeNet의 기존 classifciation 성능이 비슷함에도 불구하고, segmentation과 같이 사용했을 때는 FCN-GoogLeNet이 FCN-VGG 모델을 따라오지 못했다고 하네요.
결론부터 말하자면 위에 있는 FCN 구조(without skip architecture)로는 segmentation 성능이 좋지 않기 때문에, "4.2. Combining what and where"에서 설명하는 skip architecture 기법을 적용하여 최종 FCN 모델 구조를 고안했다고 합니다. 그럼 지금부터 해당 논문 내용과 skip architecture에 대해 설명해보도록 하겠습니다.
Combine과 refine의 의미를 정확히 이해하기 위해서는 지금부터 설명할 skip architecture 를 이해해야 합니다.
Fine-tuning 관련한 부분은 4.1에서 언급했다고 하는데, 좀 더 구체적으로 어떻게 fine-tuning을 했는지는 "4.3. Experimental framework" 부분의 "fine-tuning" 부분을 보셔야 합니다. 그렇기 때문에 fine-tuning과 관련된 자세한 설명은 "4.3.Experimental framework"에서 자세히 설명하도록 하겠습니다.
우선 "Section 4.2"는 논문에 있는 순서 그대로 해석하기 보다는 먼저 skip architecture에 대해서 간단히 설명한 후 해당 논문들의 문단 순서를 변경해가며 해석을 해보도록 하겠습니다.
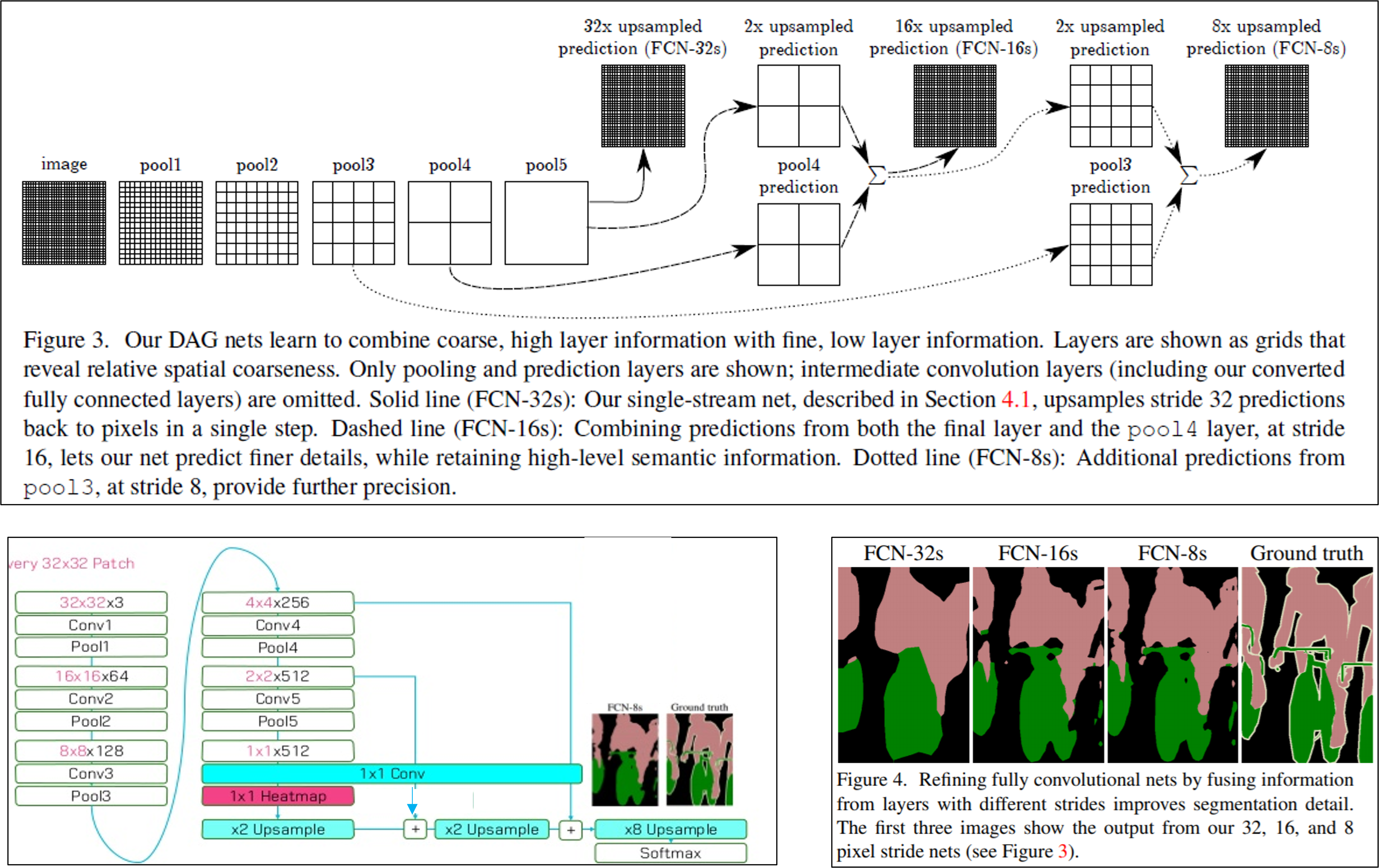
1) Skip architecture 관련 용어 및 notation
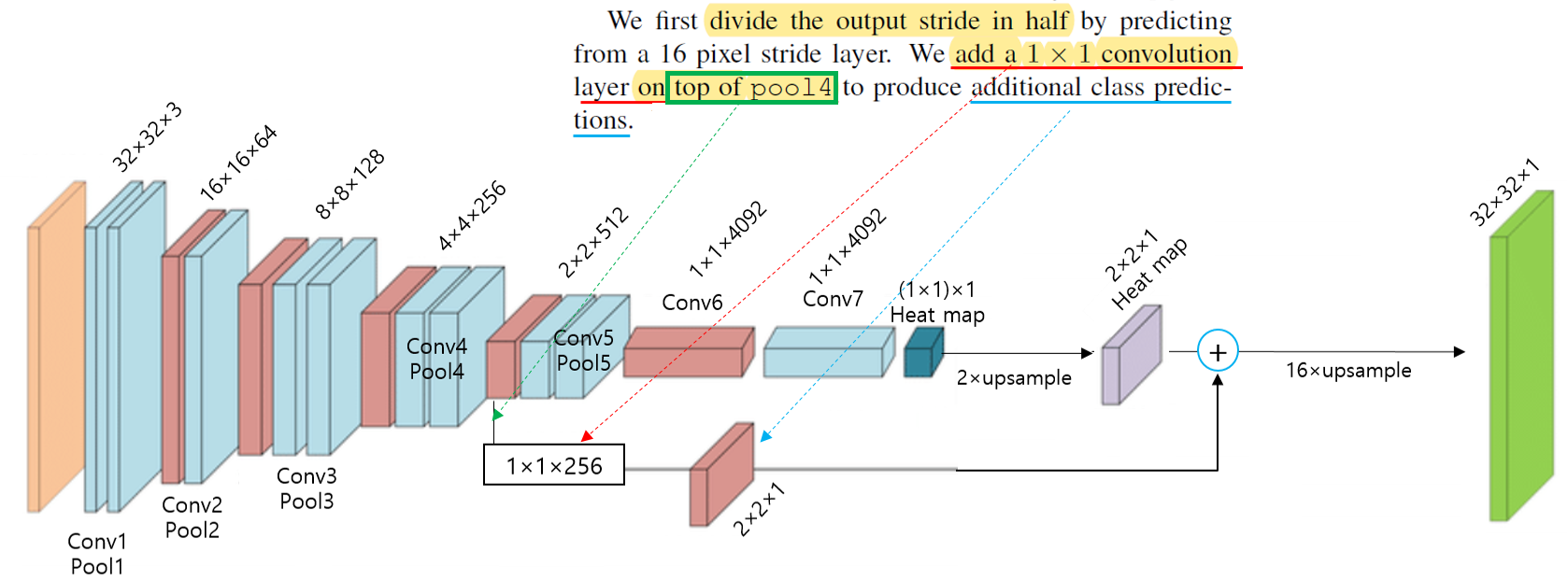
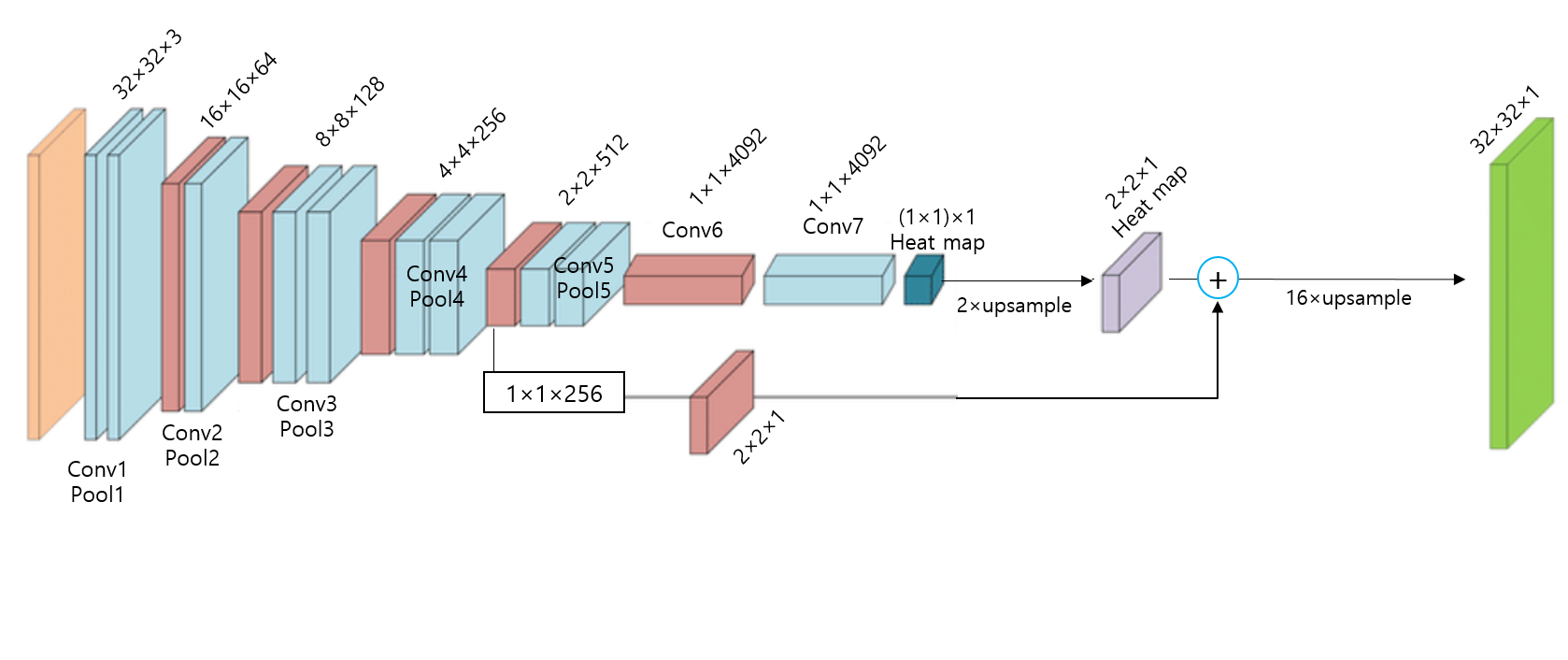
논문에서 제시한 FCN-32결과는 224이미지를 받아 들인 것이 아닌 32×32 이미지를 입력이미지로 하고 1x1 heat map (입력이미지 224×224 기준으로는 heat map 크기가 7×7)을 본래 입력 이미지 크기인 32×32에 맞게 up-sampling한 결과를 보여주고 있습니다. 1x1 heat map을 원본이미지 크기에 맞게 up-sampling해주기 위해서는 32배 up-sampling해야 하기 때문에 FCN-32s 라는 이름을 붙였습니다.
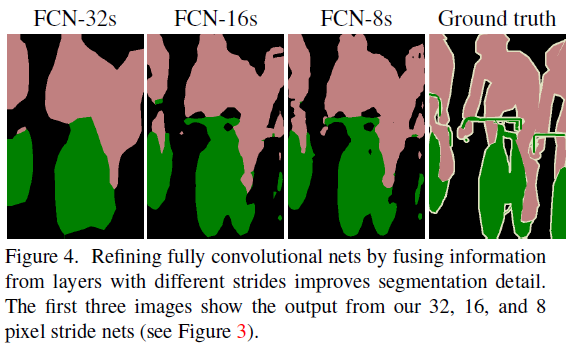
Ground truth와 비교하면 결과가 생각보다 좋지 못하다는 사실을 발견할 수 있습니다.Pooling 과정을 많이 거치다 보면 feature들의 정보가 손실되는데, 결국 마지막 heat map은 pooling layer를 제일 많이 거쳐서 나온 feature map이라고 할 수 있습니다. 즉, feature 정보가 많이 손실된 feature map으로 up-sampling을 진행하게 되면 당연히 제약사항이 많아지거나 제대로 up-sampling 할 수 없게 되고, 이에 따라 좋지 않은 결과를 얻게됩니다. (특히 fine scale object들을 이미 정보가 손상이 되니 fine scale object들을 segmentation하긴 굉장히 어렵겠죠?)
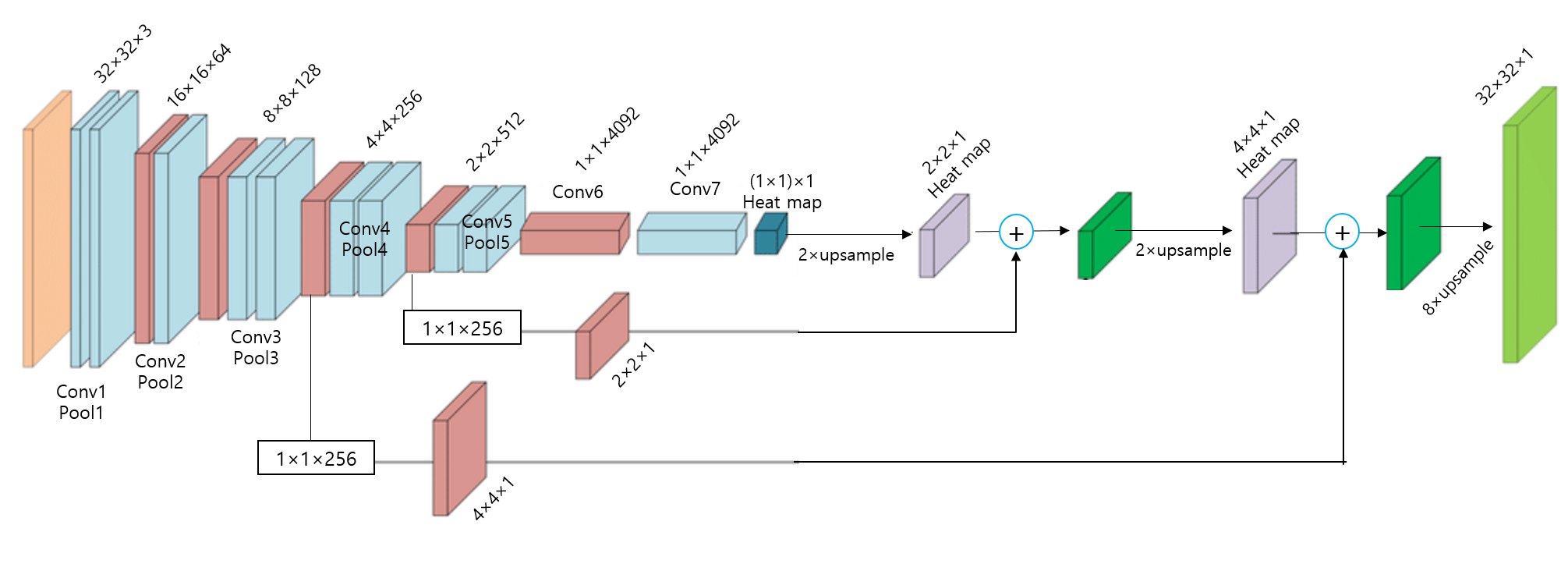
그래서 이 논문에서는 1x1 외에 2x2, 4x4 와 같이 pooling 과정을 덜 거친 feature map들을 잘 이용하는 skip architecture 방식을 이용해 위와 같은 문제를 해결하고자 했습니다.
앞서 언급한 skip architecture 방식을 "lower layer의 prediction map과 final prediction layer의 prediction map을 합산하여 연산하는 것"이라고 표현하며, 이렇게 합산하는 것을 통해 "combining 한다"고 표현합니다.
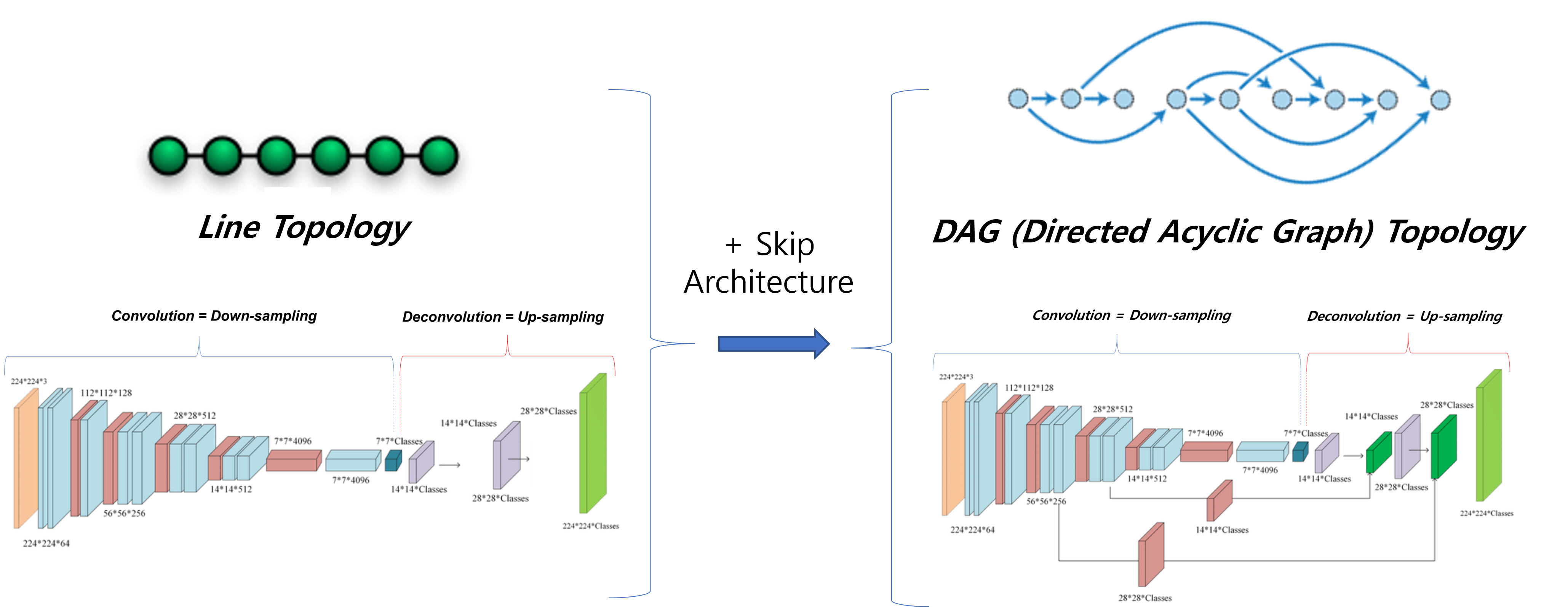
Topology는 수학에서 사용되던 용어인데 여기에서는 graph 정도르 이해하면 좋을 것 같습니다.
Skip architecture가 적용되지 않은 FCN구조는 line topology라고 표현할 수 있으며, skip architecture가 적용된 FCN구조는 DAG topology라고 표현할 수 있습니다. 이 논문에서 말하는 edge는 graph에서 말하는 edge를 말하는 것 같습니다 (edge들을 이으는 선을 vertex라고 합니다)
그림
Skip architecture를 적용시키지 않고 "32pixel stride at final prediction layer" 만을 이용하면 "the scale of detail" 부분이 문제가 되어 아래 그림처럼 (FC-32s) 결과가 좋지 못하다고 합니다.
4.2. Experimental framework
Optimizer
SGD
Momentum: 0.9
Minibatch size: 20 images
Learning rate
FCN-AlexNet: \(10^{-3}\)
FCN-VGG16: \(10^{-4}\)
FCN-GooLeNet: \(10^{-5}\)
Weight decay
\(5^{-4}\) or \(2^{-4}\)
위에서 언급하고 있는 "biases, these parameters" 들이 weight decay를 언급하고 있는것인지 잘 모르겠네요;;;;;; 맞다면 weight decay 정도에 따라 learning rate을 두 배 증가시켜 사용했다고 해석할 수 있을텐데.... (정확하게 아시는 분은 댓글달아주세요!)
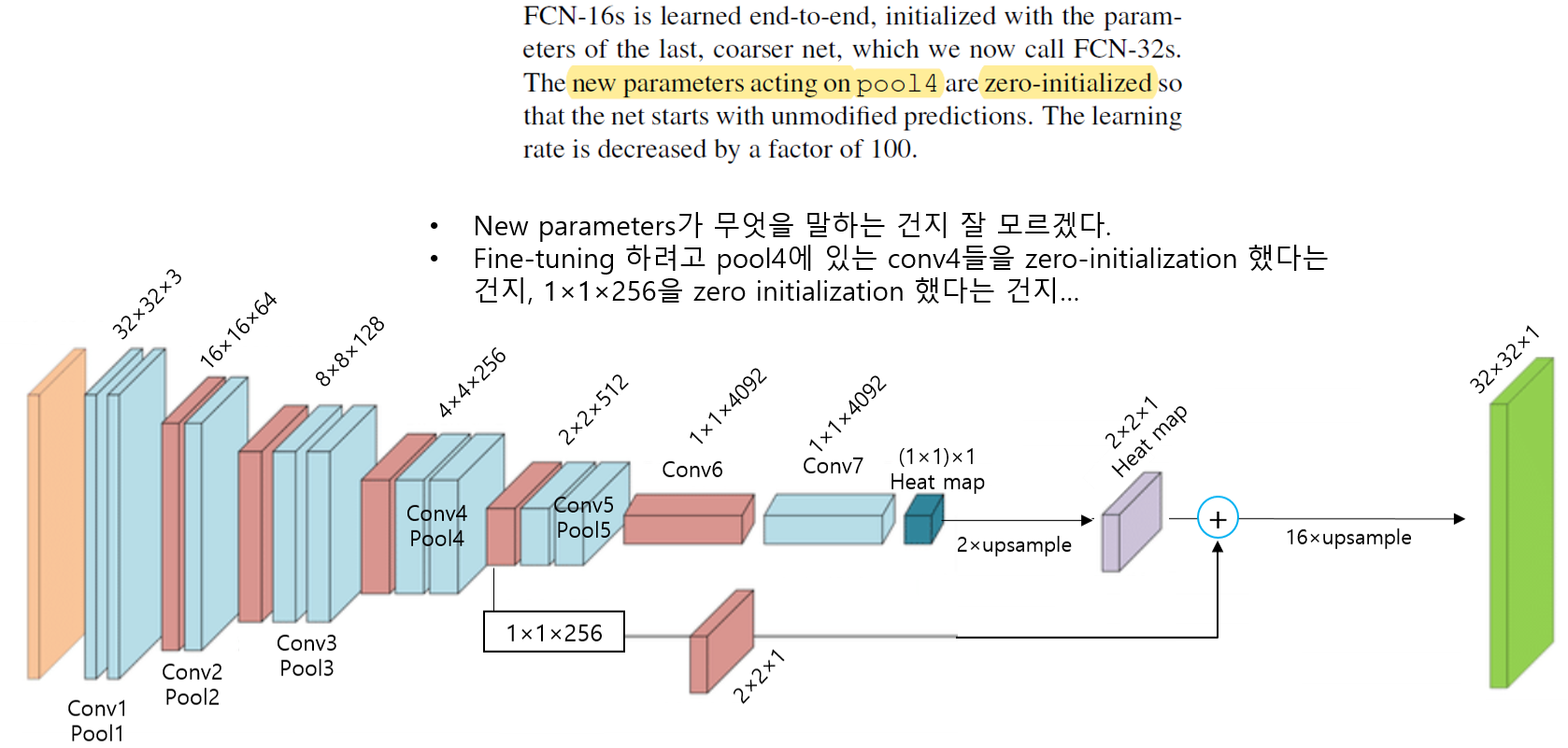
zero-initialization 부분은 아마 downsampling 부분에서 pre-trained 모델을 불러와서 사용할 시, fine-tuning을 위해 class score에 해당 부분을 초기화 시켜주기 위한 방법인듯 합니다 (아니라면 댓글 달아주세요!). 논문에서는 Random initialization 하는 것 보다 zero initialization을 하는게 더 좋다고 합니다.
Drop out은 downsampling을 위해 사용된 pre-trained 모델에 구현되어있는 drop out을 segmentation 학습시킬 때에도 변경시키는 것 없이 그대로 사용했다고 합니다.
이 논문에서 3가지 방식으로 학습을 시켰습니다.
Fine-tuning all layers: 제일 결과가 좋음
Fine-tuning the output layers: "Fine-tuning all layers"결과의 70%정도 performance 밖에 내지 못함
Scratch training: FCN의 downsampling 하는 부분이 보통 pre-trained CNN 모델을 사용합니다. 만약 segmentation을 scratch training 하려면 downsampling 부분(=pre-trained CNN)도 scratch training이 되어야 합니다. 그러므로 시간상 비효율적이라고 언급하고 있네요 (사실 시간적인 부분도 그렇고 pre-training 한 후, transfer learning을 통해 학습한 filter들이 scratch training을 통해 학습된 filter들 보다 더 다양할 것 같아 성능면에서도 transfer learning을 적용하는게 더 좋을 것 같다는게 제 개인적인 생각입니다).
앞서 patch sampling 방식이 더 좋지 않다고 설명해서 이 부분은 따로 언급하지 않도록 하겠습니다.
이 논문에서 사용된 training dataset의 labeling pixel들 대부분(3/4)은 background이기 때문에 다른 클래스들과 background 사이에 class imbalance 문제가 발생할 수 있습니다.
그래서 weighting or sampling loss 를 통해 class imbalance 문제를 해결하려고 했는데 크게 향상된 부분이 없어서 그런건지는 몰라도 class balancing이 불필요하다고 합니다. (weighting or sampling loss에 대한 별도의 수식은 없으나 불필요하다고 언급하고 있어 따로 찾아보진 않았습니다)
앞서 언급한 upsampling 방식에 대해서 설명하고 있습니다.
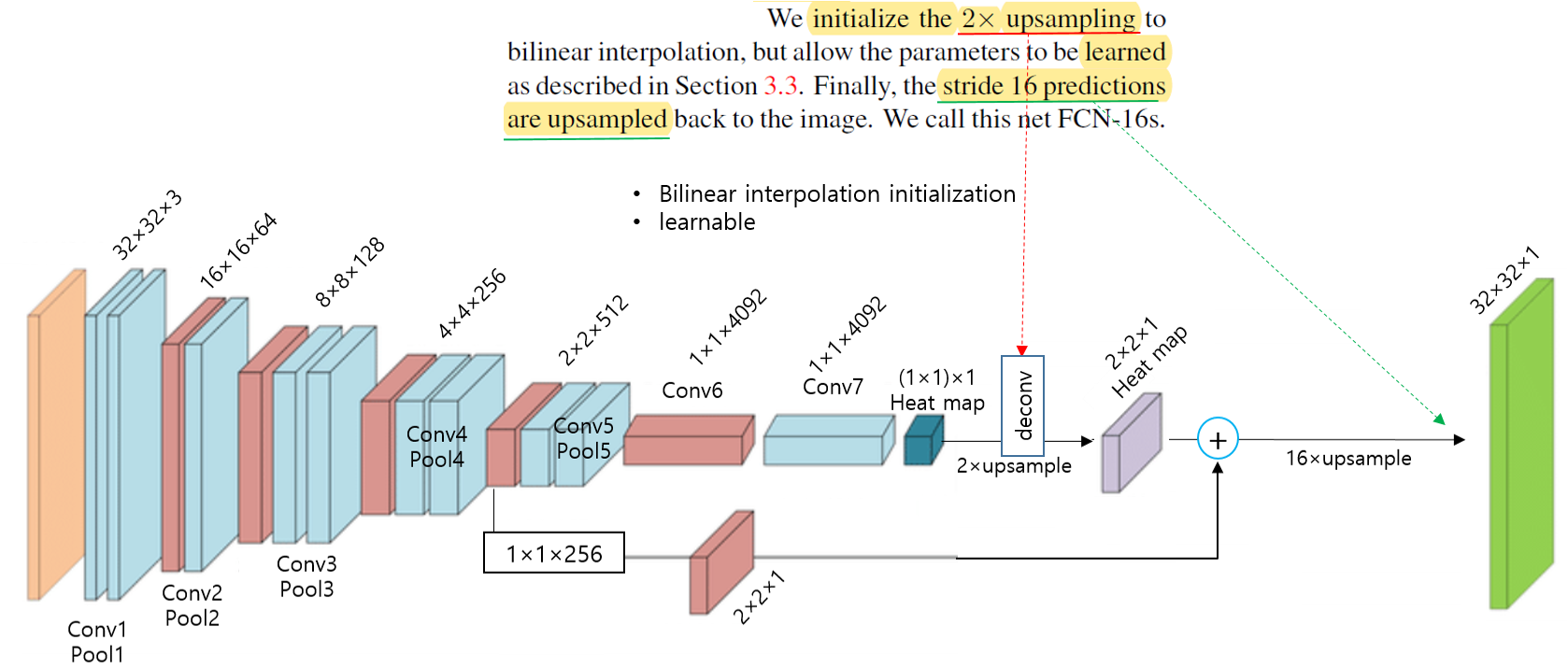
Deconvolutional layer 부분에서 마지막 layer에 해당하는 부분은 bilinear interpolation 방식을 이용하는 filter 값들이 고정된 값으로 지정됩니다.
반면, deconvolutional layer 부분의 중간 layer들은 bilinear upsampling으로 초기화 되지만 학습이 가능하게 설정되었습니다.
그리고 앞서 "section 3.2"에서 설명한 또 다른 upsampling 방식들은 FCN에 사용되지 않았다고 언급하고 있습니다.
여기서 언급한 augmentation 방식은 3가지가 있습니다.
Mirroring: Horizontal Flip
Jittering과 translation이 각자 따로 적용됐다고 생각했는데, 문장을 보니 translation 하는 방식으로 jittering을 했다고 보여집니다. 정확히 어떻게 했는지는 잘 모르겠네요. 코드를 봐야 알 것 같습니다.
결론적으로 이러한 augmentation 방식이 눈에 띄게 향상을 불러오진 않았다고 합니다.
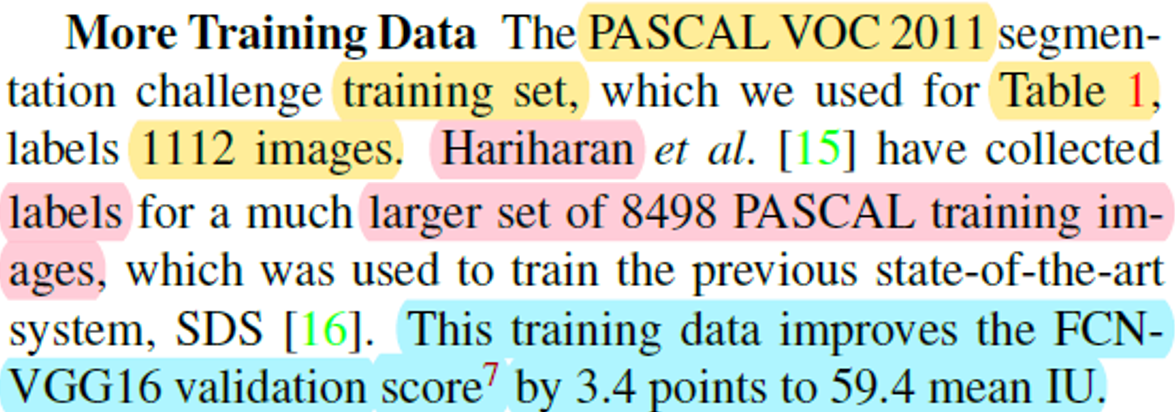
앞서 언급한 training dataset 외에 Hariharan 이 쓴 논문에서 사용된 8498 PASCAL training image 데이터셋을 더 활용했다고 합니다.
추가된 training dataset을 이용해 기존 FCN-VGG16의 validation 성능을 3.4% 향상시켰다고 하네요.
구현에 사용된 GPU장비 및 딥러닝 프레임워크를 소개하고 있습니다.
Framework: Caffe
GPU: NVIDIA Tesla K40c
5. Results
Result 부분은 따로 풀어서 설명하지 않고, performance measurement를 위해 사용되는 metrics를 설명하는 차원에서 마무리하도록 하겠습니다.
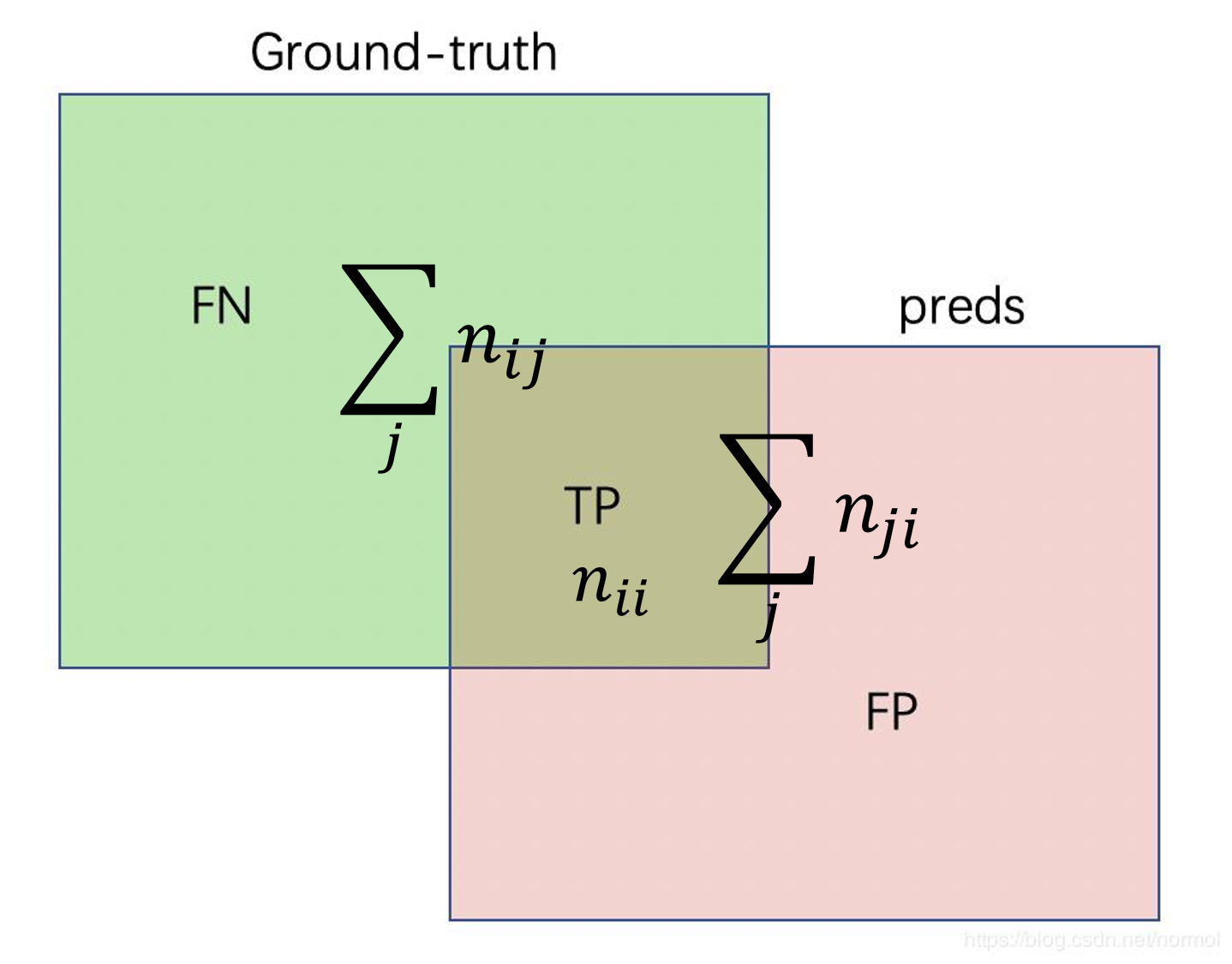
Matrics를 설명하기 전에 내용들을 아래와 같이 간단히 정리해보도록 하겠습니다.
그림 출처: 그림 출처: https://www.programmersought.com/article/5001878564/
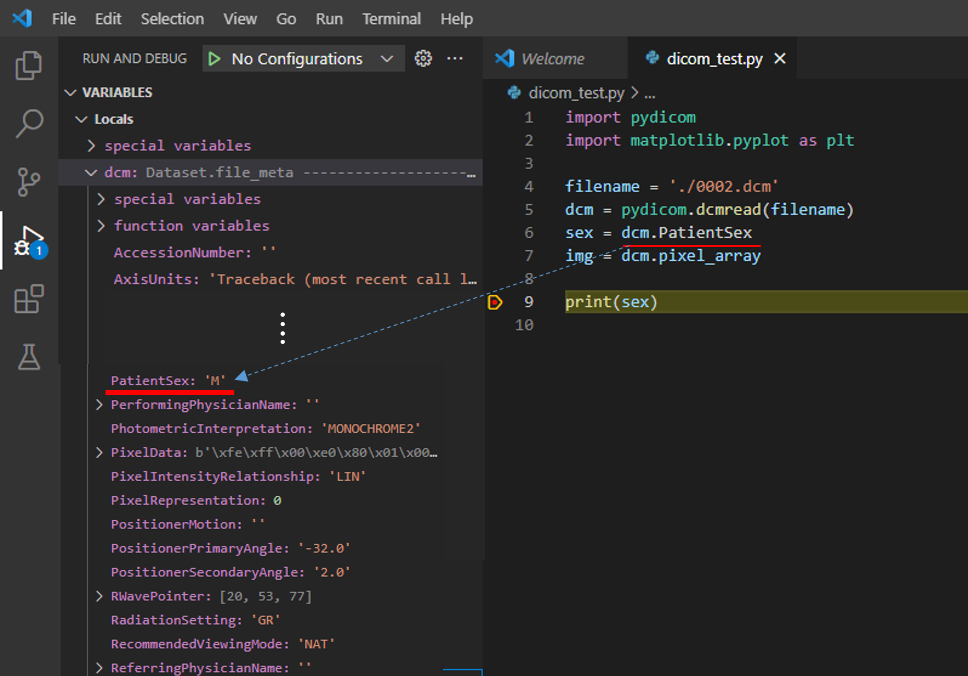
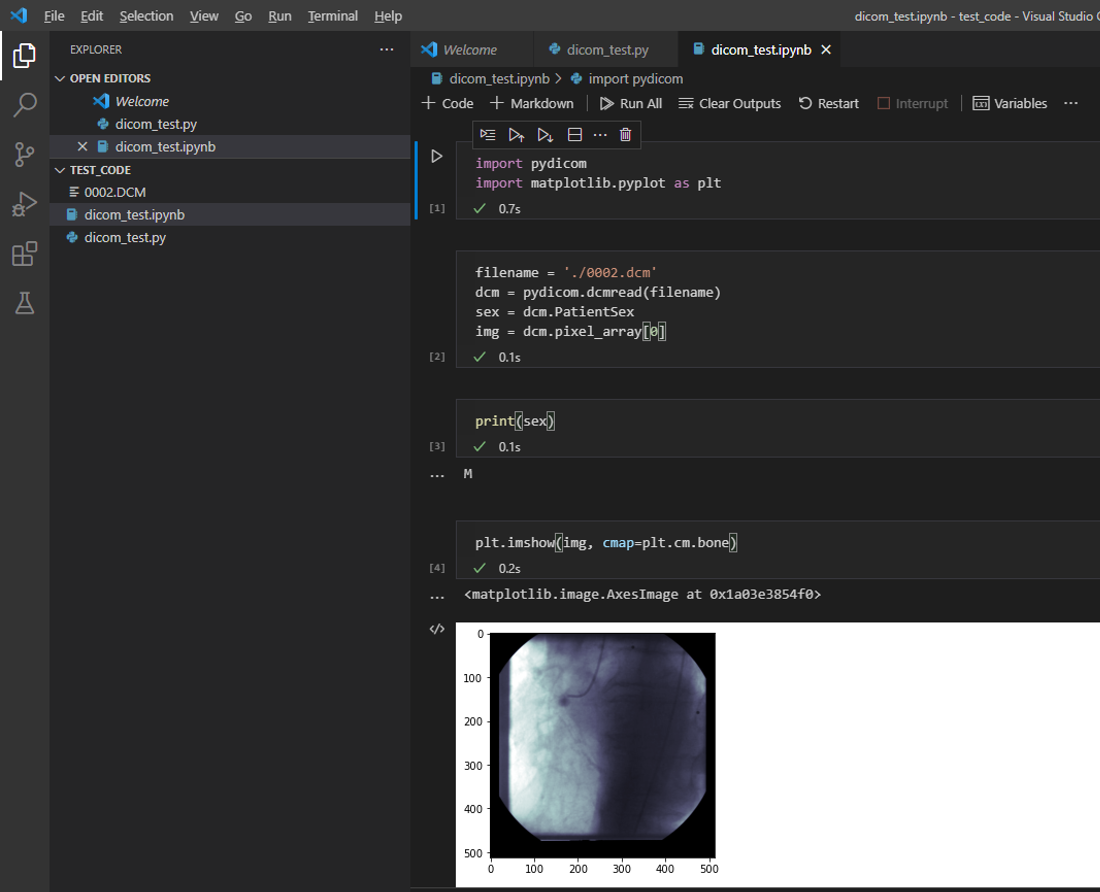
파일을 읽어들인 후, 특정 attribute에 접근하면 관련 데이터 값을 얻을 수 있습니다.
예를 들어. "dcm.PatientSex"에 접근하면 성별(M or F) 데이터 값을 얻을 수 있고,
"dcm.pixel_array"에 접근하면 이미지 데이터 값을 얻을 수 있습니다.
위의DICOM 이미지 shape은 (96,512,512)=(channel, width, height)인데, channel이 의미하는 바는 시간 축이라고 보시면 됩니다. 예를 들어, "pixel_array[0] -> pixel_array[1] -> ... -> pixel_array[95]" 시간 순서대로 (512,512) gray scale 이미지가 변한다고 생각하시면 됩니다 (영상 관점에서 설명하면 pixel_array[0], pixel_array[1], ..., pixel_array[95]가 모두 frame이라고 볼 수 있습니다)
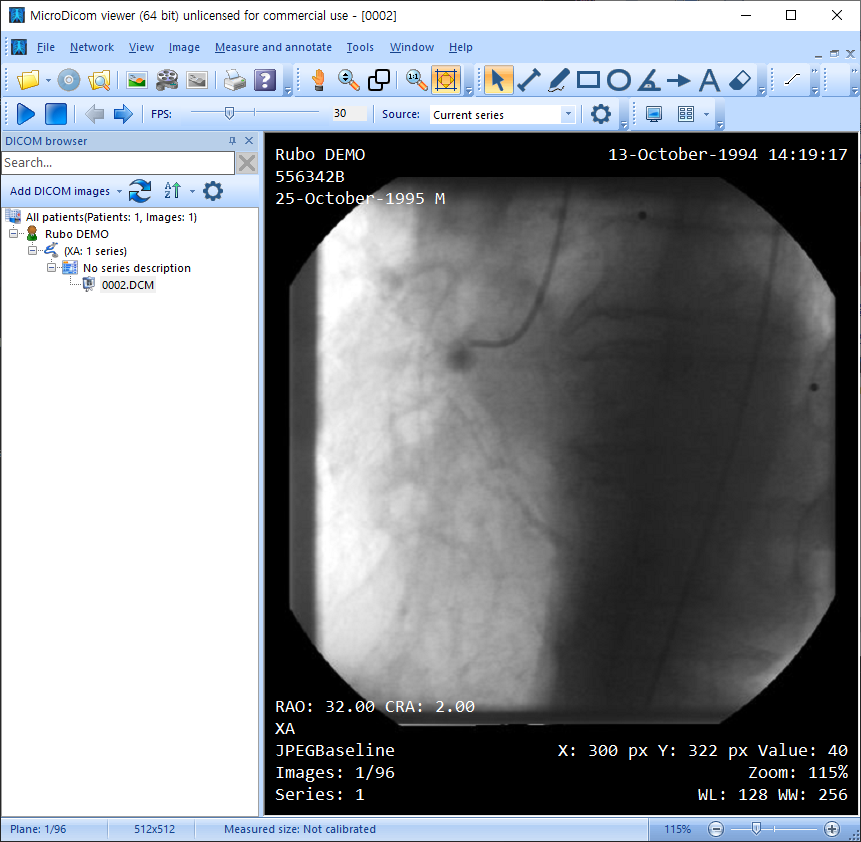
※DICOM viewer에서 마우스 휠을 사용하면 dicom 이미지가 연속적으로 변하는걸 보실 수 있으실 겁니다! (image가 하나로만 구성될 수 도 있으니 알아두세요! ex: "Images: 1/1")
특정 시간대의 dicom 파일의 (gray scale) 2d 이미지 값을 얻으려면 아래와 같이 (=dcm.pixel_array[0]) 접근하면 됩니다. ipynb 파일에서 interactive mode를 사용하면 matpotlib를 이용해 실제 이미지를 visualization하여 확인할 수 있습니다.
4. SimpleITK 모듈로 dicom 파일 데이터 읽기
파이썬에서는 pydicom 외에도 SimpleITK 모듈을 이용해 dicom 파일에 접근할 수 있습니다.
5. 그 외 dicom 파일 다루는 방법
아래 사이트에 접속하여 crtl+F 한다음 DICOM 이라고 검색하면 "Chapter10. Combining data sources into a unified dataset)" section이 나옵니다. (책(76p) or pdf페이지(106)) 해당 section의 내용을 참고하시면 dicom 파일을 다루는 또 다른 방법도 소개하고 있으니 참고하시면 좋을 듯 합니다!
또한, DICOM 파일로 부터 영상 이미지를 추출하는 방법에 대해서도 알아보도록 하겠습니다.
(DICOM은 저도 본지 얼마 안돼서 잘 못 된 부분이 있을 수 있으니 해당 부분을 꼭 댓글로 말씀해 주시면 감사하겠습니다!)
1. DICOM format (.dcm)
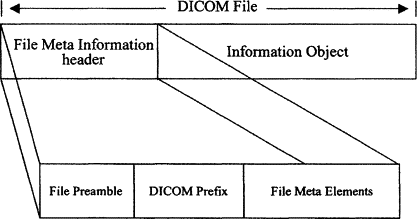
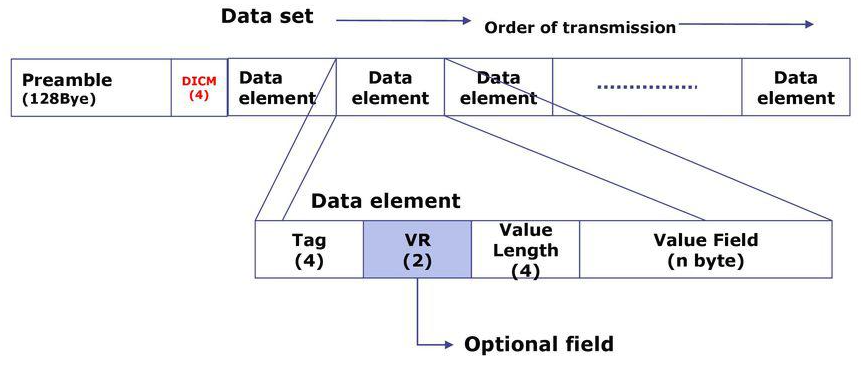
DICOM file(.dcm 파일)은 아래와 같이 크게 두 파트(File Meta Information + Object Instance)로 구성되어 있습니다.
이미지 출처: https://www.opswat.com/blog/opswat-deep-cdr-now-supports-dicom-file-format
먼저, File Meta Information 즉, Header라고 불리는 부분이 어떻게 구성되어 있는지 알아보도록 하겠습니다.
이미지 출처: https://www.sciencedirect.com/topics/computer-science/formatted-file
1) File Meta Information
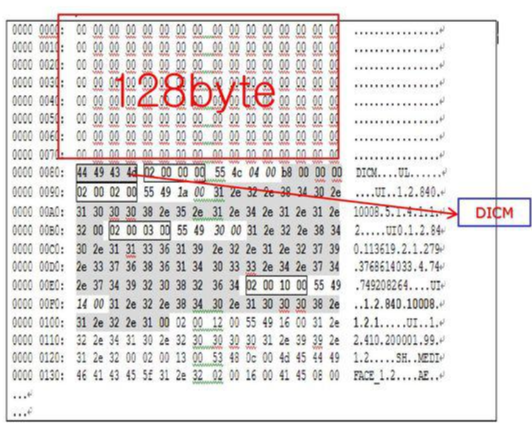
Preamble: 128 byte로 구성된 dummy byte입니다. 주로 zero 값으로 구성되어 있는데, 필요시 특별한 정보를 담을 수 도 있습니다.
DICOM prefix: Preamble 다음에 곧 바로 "D", "I", "C", "M"라는 글자가 나와야 DICOM 파일임을 알 수 있습니다. 쉽게 말해 이 파일이 DICOM 파일이다라는 인증 마크와 같다고 보면 될 것 같습니다.
File Meta elements: This section specifies the File Meta Elements needed to support the formatting of the File Meta Information of the DICOM File Format.
(↓↓↓Preamble&Prefix↓↓↓)
이미지 출처: https://slidesplayer.org/slide/12934045/
(↓↓↓File Meta Elements↓↓↓)
ex) Transfer Syntax: 데이터를 보내는 데 사용되는 인코딩 → bit dendian, JPEG compression, ETC...
이미지 출처: http://dicom.nema.org/dicom/2013/output/chtml/part06/chapter_7.html
2) Information Object
이미지 출처: https://www.sciencedirect.com/topics/computer-science/formatted-file
Information object 부분은 Data Element로 구성되어 있는데, Data Element가 실질적인 dataset이라고 보시면 됩니다.
이미지 출처: https://www.leadtools.com/help/sdk/v21/dicom/api/overview-basic-dicom-file-structure.html
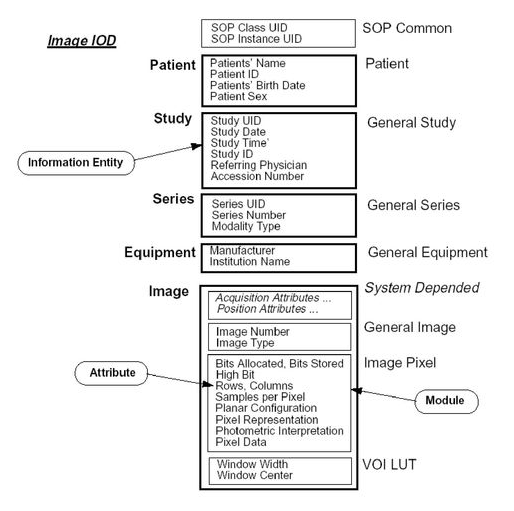
Information Object의 구성요소라 할 수 있는 Data Set은 IOD (Information Object Definition) 형식을 따릅니다. IOD는 Entity-relationship model을 중심으로 information entities, modules, attributes로 구성되어 있습니다.
예를 들어, MRI(=MR Image)라는 것을 하나의 객체(information object)라고 설정하고, 해당 객체를 여러 entitiy를 이용해 표현합니다. 환자정보를 나타나는 entity, 검사정보를 나타내는 entity, 이미지정보를 나타내는 entity 등이 있습니다.
그리고 각각의 entity는 해당 entity에 어울리는 데이터 종류(=Module)들로 구성됩니다. 예를 들어, 환자정보에는 나이, 체중, 이름과 같은 데이터 종류 등이 있을거에요. 그리고 실질적으로 부여되는 구체적인 값들을 attribute라고 합니다.
이미지 출처: https://libertegrace.tistory.com/m/entry/Medical-Image-DICOMDigital-Imaging-and-Communications-in-Medicine?category=905970
앞서 잠시 언급했듯이, Information entity 종류는 굉장히 많습니다. 아래 그림을 보면 진하게 칠해진 가장 바깥쪽 테두리 부분이 entity입니다.
이번 글에서는 의료 영상(Medical imaging)에서 사용하는 DICOM 파일이 어떻게 생겨났는지, 어떻게 이용되고 있는지 알아보도록 하겠습니다.
또한 DICOM이라는 것이 digital image이기 때문에, 기본적으로 digital image가 어떻게 습득이 되는지에 대해서도 알아보도록 하겠습니다.
1. 기존 딥러닝 분야에서의 이미지 데이터 format
보통 딥러닝에서 이미지를 다룰 때, 보통 한 픽셀에 0~255의 pixel value를 갖는 파일형식(ex: jpg, png 등)을 이용합니다.
이미지 출처: https://ai.stanford.edu/~syyeung/cvweb/tutorial1.html
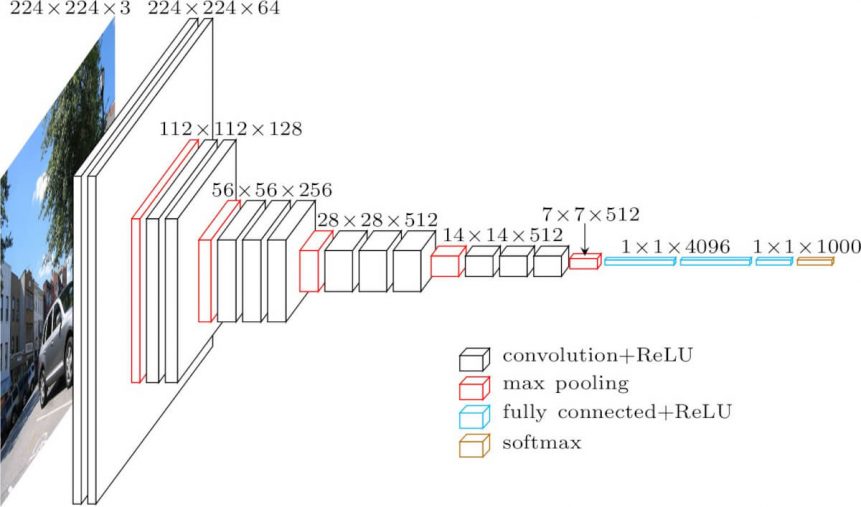
또한, 우리가 알고 있는 딥러닝 CNN 논문들을 보면 224×224 또는 448×448 같이 이미지 크기를 표준으로 하고 있다는 것을 볼 수 있습니다.
이미지 출처: https://neurohive.io/en/popular-networks/vgg16/
물론 최근에는 GAP(Global Average Pooling) 덕에 입력 사이즈를 제한하고 있진 않지만, 보통 1000×1000을 넘는 test를 하진 않죠. 왜냐하면, 1000×1000 크기의 이미지는 학습시키기 어려울 수 있기 때문입니다.
예를들어, 이미 1000×1000×3 이미지 자체만으로도 엄청난 대용량인데, 이러한 큰 사이즈의 이미지를 학습시키려면 딥러닝 모델이 좀 더 deeper해져야 좋은 결과를 얻을 수 있거라 생각됩니다 (물론 아닐 수 도 있습니다). 이처럼 이미지 크기에 비례해서 딥러닝 크기도 커지는 것이 일반적이기 때문에, GPU memory가 "딥러닝 모델용량+한 장의 대용량 이미지"을 감당할 수 없게 됩니다.
만약, 운 좋게 한 장의 이미지 정도는 감당할 수 있다고 하더라도, 8개 이상의 batch를 잡아주고 학습시키는 건 불가능하겠죠. 물론 이 부분도 분산처리 학습 (ex: horovod) 같은 방법을 이용하면 어느정도 해결할 수 있지만, 여전히 batch size를 크게 설정할 수 없기 때문에 딥러닝 모델을 학습시키는데 여러 불안요소를 가져갈 수 밖에 없습니다.
하지만, DICOM format의 의료 영상이미지들은 한 장에 엄청난 용량을 차지하고 있습니다. 3000×3000 resolution을 사용하는 경우도 있죠. 만약, 이러한 DICOM 데이터들의 이미지 크기를 기존 딥러닝에서 사용하는 이미지 크기(ex: 224×224) 만큼 줄여버린다면 굉장한 이미지 정보의 손실이 있을 수 있습니다. 그렇기 때문에 DICOM에서 제공하는 resolution에 기반한 딥러닝 모델 연구가 또 필요한 것이죠.
DICOM은 이미지 정보외에 다양한 메타 데이터들을 담고 있습니다. 이러한 메타 데이터에는 나이나 성별 등이 포함이 되는데, 실제로 의료 영역에서 성별과 나이는 굉장히 중요한 정보입니다.
예를 들어, 어떠한 Chest X-ray를 볼 때도 나이, 성별에 따라 진단방식이 달라질 수 있습니다. Chest X-ray에서 어떠한 소견이 있을 때, 나이가 있으신 분이라면 일반적인 현상이라고 해석할 수 있는 반면에 해당 소견이 젊은 사람에게 발생한거라면 조금 문제가 있다고 판별할 수 있습니다.
이러한 메타 데이터와 의료 이미지 데이터를 잘 이용하면 multimodal 딥러닝 모델도 만들 수 있게 됩니다.
결국 의료 영상(medical imaging) 분야에서 딥러닝 모델을 만들기 위해 알아야할 가장 기본이 되는 데이터가 DICOM입니다. 그럼 지금부터 DICOM에 대한 정의와 기원부터 알아보도록 하겠습니다.
2. DICOM (Digital Imaging and COmmunication in Medicine)의 정의와 기원
전기전자를 다루는 분야(IEEE)에서도 여러 표준규약들이 있습니다. 예를 들어, USB 같은 경우도 출시하는 회사마다 규격이 다 다르면 사용자들 입장에서 제품 중 어떤 제품을 사용 할지 혼란이 올거에요. 그래서 보통 국제단체(ex: IEEE)에서는 범용적으로 많이 쓰일 것 같은 제품에 사용되는 기술들에 한해 표준(protocol)을 만들어 이를 따르도록 합니다.
이미지 출처: http://coewww.rutgers.edu/www1/linuxclass2006/lessons/lesson4/sec_3.1.html
위와 같은 이유로 의료분야 또한 수 많은 표준들이 존재합니다. DICOM은 의료분야에서 사용되는 수 많은 표준 중 하나인데, 의료용 기기에서 디지털 영상자료를 표현하거나 디지털 영상자료을 이용해 통신할 때 (→디지털 영상자료를 주고 받을 때) 지켜야할 표준이라고 보시면 됩니다.
"의료용 디지털 영상 및 통신(Digital Imaging and Communications in Medicine, DICOM)표준은 의료용 기기에서 디지털 영상표현과 통신에 사용되는 여러 가지 표준을 총칭하는 말"
그렇다면, DICOM 표준은 어떻게 해서 만들어 졌을까요?
간략하게 DICOM 표준을 만들기 위해 어떤 단체들이 참여했는지 알아보도록 하겠습니다.
1) 1983: ACR(American College of Radiology; 미국 방사선 학회)&NEMA(National Electrical Manufacturers Association; 미국 전기 공업회)에서 ACR-NEMA 디지털 영상전송 표준 위원회를 발족
이미지 출처: https://academic-accelerator.com/Impact-Factor-IF/kr/Radiology
3) 1988: ACR-NEMA 표준 버전 2.0이 RSNA에서 발표
4) 1992: RSNA 회의에서 DICOM 명칭의 표준이 제안
5) 1993: DICOM 첫 데모 버전이 발표
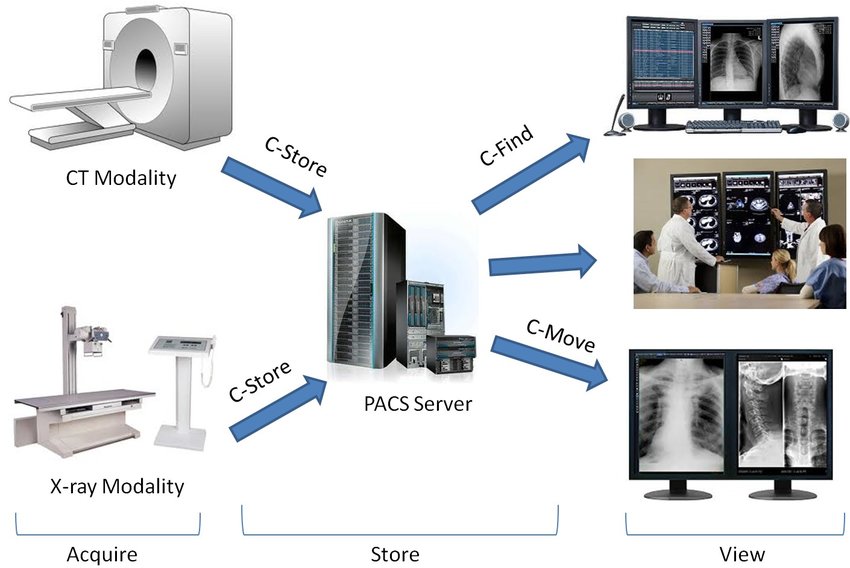
3. PACS (Picture Archiving and Communication System)
앞서 언급했듯이 DICOM은 기본적으로 디지털 영상 자료입니다. 그렇다면 이러한 디지털 자료들은 네트워크 통신을 통해 서로 주고 받을 수 도 있겠죠?
병원에서는 디지털 의료영상 이미지(Chest X-ray, CT, MRI) 같은 것을 촬영하게 되면 병원의 PACS 서버로 전송되고, 의사들이 client system을 이용해서 영상을 판독하게 됩니다.
PACS는 디지털 의료영상이미지를 DICOM이라는 국제표준규약에 맞게 저장,가공,전송하는 시스템입니다.
이미지 출처: https://www.researchgate.net/figure/Major-PACS-components-and-sample-DICOM-messages_fig1_268195635
X-ray, CT, MRI같은 디지털 의료영상 (digital medical imaging)장비를 사용하여 획득된 의료영상이미지는 DICOM형식으로 저장되게 되며 판독결과와 진료기록이 추가될 수 있습니다. 또한 네트워크를 통해서 병원 내, 외의 단말로 전송이 가능합니다.
4. Digital image 습득
앞서 정의한 DICOM에 대해서 다시 한 번 살펴보도록 하겠습니다.
"의료용 디지털 영상 및 통신(Digital Imaging and Communications in Medicine, DICOM)표준은 의료용 기기에서 디지털 영상표현과 통신에 사용되는 여러 가지 표준을 총칭하는 말"
결국, 의료용 디지털 영상이라는 것도 기본적으로 digital image이기 때문에, digital image가 어떻게 습득되는지를 알고 있어야 합니다.
그럼 지금부터 디지털 이미지가 어떻게 얻어 지는지 알아보도록 하겠습니다.
이미지 출처: https://www.insilicogen.com/blog/archive/202009
1) Source
어떠한 object(객체)를 이미지로 표현해주기 위해 가장 먼저 요구되는 요소가 energy source 입니다. 예를 들어, 우리가 카메라로 어떤 물체를 찍는 것은 빛(light source)에 반사되는 객체를 capture하는 것과 같습니다.
의료 영상(medical imaging)에서도 특정 객체를 디지털 이미지로 표현하기 위해서는 energy source가 필요한데, 방사선을 사용할 경우 X-ray, CT, PET 영상 이미지를 얻을 수 있고, 자기장을 이용하면 MRI 영상 이미지를 얻을 수 있습니다.
이미지 출처: https://en.wikipedia.org/wiki/Projectional_radiography
특정 energy source로 부터 어떤 이미지(아래 그림의 맨 왼쪽 부분)를 획득했다고 가정해보겠습니다.
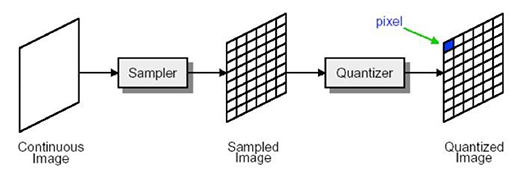
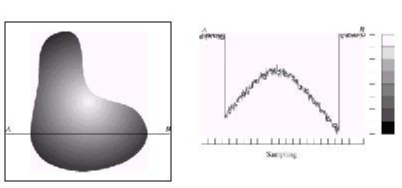
아래 그림의 맨 왼쪽 부분에 표시된 object에서 A에서 B까지 색의 변화를 표현하면 오른쪽 이미지 처럼 continous한 그래프 형태를 띄는 것을 알 수 있습니다. 이러한 continuous한 이미지를 디지털화 시켜주기 위해서 가장먼저 하는 것은 sampling 작업입니다.
이미지 출처: https://slidetodoc.com/image-processing-digital-image-fundamentals-by-dr-ferda/
[Sampling 작업]
우선 A에서 B까지의 continous한 그래프에서 일정 간격을 두고 값들을 sampling(표본추출)을 합니다.
sampling한 수가 결국 x축에서 discrete 범위가 됩니다.
예를 들어, 아래의 그림 같은 경우는 23개의 영역이 되는데, 위에서 언급한 A에서 B까지의 영역이 23개의 pixel이 존재한다는 말과 동일합니다. (보통 2D에서는 pixel로 표현되고, 3D에서는 voxel로 표현됩니다)
즉, sampling 과정에서 추출한 sampling 수가 digital image의 resolution을 결정한다고 볼 수 있습니다.
그리고 이때 sampling을 통해 생겨난 각각의 pixel들의 값(=y축)을 intensity라고 합니다.
여기서 중요한 것은 아직 이때의 pixel값이 우리가 흔히 알고 있는 discrete(0~255)의 범위를 갖는것이 아닌 continuous한 범위를 갖고 있다는 것을 인지해야 합니다 (아래 이미지에서는 sampling된 요소들의 값들(=파란색 points)이 discrete하게 표현되어 있으나 실제로는 sampling된 y값은 실수 값을 갖을 수 있습니다. 아래 파란색 points들은 quantization이 적용된 결과 입니다. quantization은 바로 뒤에서 설명하겠습니다.)
이미지 출처: https://commons.wikimedia.org/wiki/File:4-bit-linear-PCM.svg
3) Quantization
앞서 언급했듯이, sampling 단계에서 얻은 intensity는 continous 특성을 갖는 실수 범위를 갖습니다. 이러한 continous한 값을 디지털화 시켜주기 위해 quantization이라는 기법이 적용됩니다.
"The continuous range of light(energy) intensity (0<x<i) received by the digital image acquisition system need to be quantized to gray level (0~255)"
이미지 출처: https://www.google.com/url?sa=i&url=https%3A%2F%2Fwww.slideshare.net%2FPournamyRameez%2Fimage-processing-presentation-6969121&psig=AOvVaw1EGZyQbsmINkTSnvo1xldb&ust=1625389599778000&source=images&cd=vfe&ved=0CAoQjRxqFwoTCJjJ1KPGxvECFQAAAAAdAAAAABAJ
우리가 흔히 알고 있는 pixel 값은 8비트 기준으로 0~255의 범위(2^8)로 표현합니다.
이미지 출처: https://www.processing.org/tutorials/color/
하지만 꼭 8bit로 표현할 필요는 없습니다. 때에 따라서는 16bit의 범위(2^16)로 표현할 수도 있고, 1bit의 범위로 표현할 수 도 있습니다. 즉, 사용되는 bit에 따라 표현하려는 색의 범위가 결정됩니다.
이때, 색의 범위를 위해 사용되는 bit 수를 bit depth라고 합니다.
이미지 출처: https://digamation.wordpress.com/2008/07/18/understanding-bit-depth/
표현하려는 범위가 커질 수록 bit depth 또한 커지고, 이에 따라 디테일한 색정보를 표현할 수 있습니다.
이미지 출처: https://slidetodoc.com/image-processing-digital-image-fundamentals-by-dr-ferda/
이미지 출처: https://www.google.com/url?sa=i&url=https%3A%2F%2Fwww.slideshare.net%2FAmnaakhaan%2Fimage-acquisition-and-representation&psig=AOvVaw2T0C6Z5qpYDoJkmnBMWi22&ust=1625391253561000&source=images&cd=vfe&ved=0CAoQjRxqFwoTCPCF3rfMxvECFQAAAAAdAAAAABAP
지금까지 DICOM에 대한 설명과 digital image를 습득하는 과정에대해 알아보았습니다.
다음 글에서는 지금까지 배운 내용을 기반으로 DICOM file format이 어떻게 구성되어 있는지 알아보도록 하겠습니다.
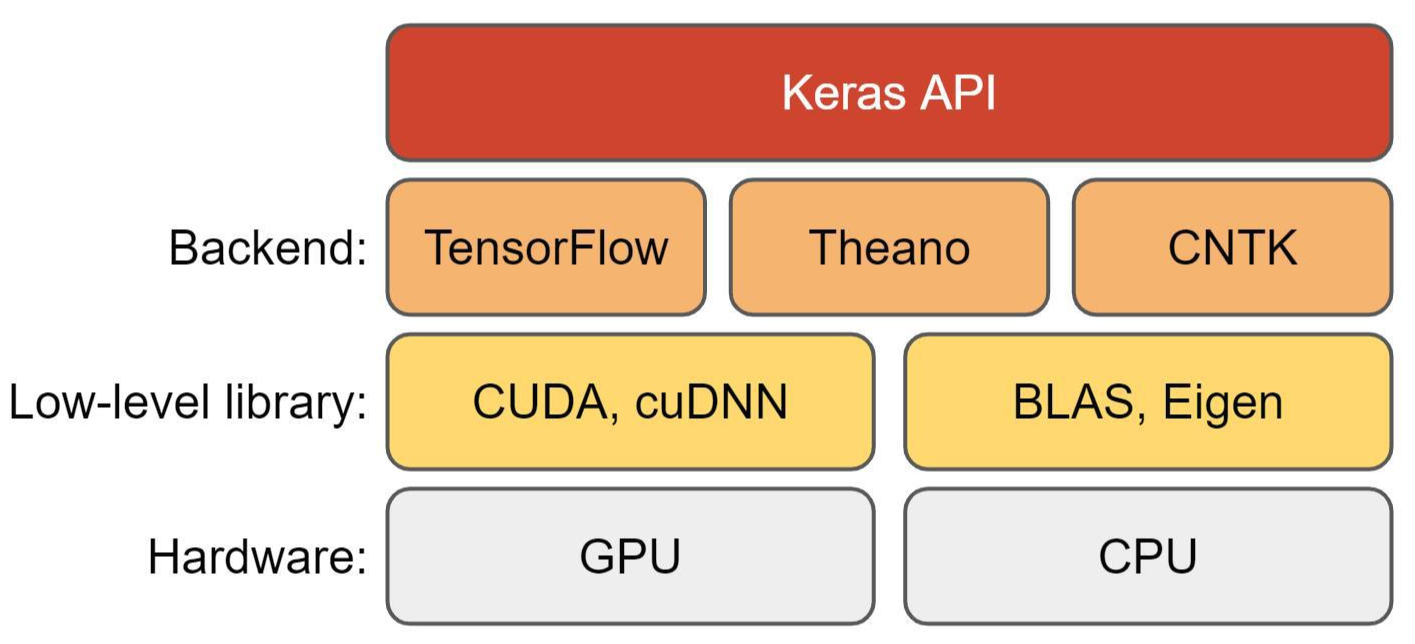
Keras는 기본적으로 high level API 입니다. 아래 링크에서 언급하고 있듯이 딥러닝의 아주 기본적인 연산들(ex: tensor들의 연산 or 미분)이나 CPU, GPU, TPU 같은 hardware를 동작시키는 같은 작업(ex: CUDA)들은 Keras에서 구현하지 않습니다.
하지만, Keras가 딥러닝 학습을 하려면 앞서 언급한 딥러닝의 기본적인 연산을 해야하는데, 이를 어떻게 사용할 수 있을까요?
Keras는 backend engine에서 제공하는 특화된 tensor library를 사용함으로써 딥러닝의 기본적인 연산을 수행합니다. 예를 들어, tensorflow, theano, CNTK 라는 딥러닝 프레임워크를 backend로 사용합니다. 다양한 backend (tensorflow, theano, CNTK) 를 사용한다고 하여 아래와 같이 표현하기도 합니다.
"Kerass는 multi-backend(멀티 백엔드)를 지원합니다"
Theano: developed by LISA Lab at Université de Montréal → http://deeplearning.net/software/theano
Tensorflow: developed by Google→ https://www.tensorflow.org
CNTKL: developed by Microsoft→ http://github.com/Microsoft/CNTK
이미지 출처: https://www.digikey.de/en/maker/projects/getting-started-with-machine-learning-using-tensorflow-and-keras/0746640deea84313998f5f95c8206e5b
2. Tensorflow와 Keras의 관계 (Tensorflow 2.5 & Keras 2.4)
예전에는 기존 케라스 사용자들이 Keras API를 사용하면서 backend로 종종 tensorflow를 사용했습니다.
하지만, 2020.06.18에 케라스가 2.4 버전을 release 하면서 아래와 같은 말을 했습니다. (현재(2021.06.30)까지도 keras 최신 버전은 2.4입니다)
"We have discontinued multi-backend Keras to refocus exclusively on the TensorFlow implementation of Keras."
"In the future, we will develop the TensorFlow implementation of Keras in the present repo, atkeras-team/keras. For the time being, it is being developed intensorflow/tensorflowand distributed astensorflow.keras. In this future, thekeraspackage on PyPI will be the same astf.keras."
결국 multi-backend를 더 이상 지원하지 않고 오로지 tensorflow backend만을 지원할 것이라고 선언했습니다. 기존에는 Keras-team/keras라는 repo에서 다양한 backend를 지원하는 keras API를 업데이트하고 있었는데, 이제는 tf.keras에서 keras 관련 기능들을 업데이트 할거라고 명시했습니다.
다시 말해,keras-team/keras 저장소는 오로지 tensorflow만을 위한 tensorflow 백엔드 전용 Keras 되고 tf.keras가 keras-team/keras를 사용할 것으로 예상되었습니다.
3. Keras separate from Tensorflow 2.6 (2021.06.30)
아래 박혜선님의 글을 인용하면 올해(2021) 초부터 keras-team/keras 저장소의 코드가 다시 채워지고 있었다고 합니다. 당시에는 tf.keras 코드를 기반으로 keras-team/keras에 코드를 그대로 복사 붙여넣기 하여 싱크를 맞추는 작업(복붙)이 대부분이였다고 하네요. 그래서 tensorflow 2.5를 설치하면 keras-nightly 패키지(←복사붙여넣기된 keras-team/keras)도 같이 설치가되어 별도의 패키지로써 제공했다고 합니다.
그리고, 2021.06.30일에 Tensorflow 2.6 버전이 release 되면서, tensorflow 진영에서 아래와 같은 선언을 하게 됩니다.
Keras has been split into a separate PIP package (keras), and its code has been moved to the GitHub repository keras-team/keras. → Tensorflow 2.6 버전부터 keras는 tensorflow 패키지에서 분리가 됩니다. 앞으로 tensorflow 2.6 이후 부터 업데이트되는 Keras 관련 코드들은 다시 keras-team/keras로 옮겨진다고 하니 앞으로 "import keras"를 다시 사용해야 할 것 같습니다.
The API endpoints fortf.kerasstay unchanged, but are now backed by thekerasPIP package. All Keras-related PRs and issues should now be directed to the GitHub repository keras-team/keras.