1-1. Data Load (Feat. torchvision transform)
안녕하세요.
이번 글에서는 "UNet (딥러닝 segmentation모델)" 학습을 위해 해당 모델에 입력으로 들어갈 데이터들이 어떤 과정을 통해 load 되는지 알아보도록 하겠습니다.
코드는 아래 사이트를 기반으로 수정하였으니 아래 영상을 먼저 참고하시면 글을 이해하시는데 도움이 될 것으로 생각됩니다.
https://www.youtube.com/watch?v=1gMnChpUS9k
위의 강의에서는 augmentation 부분을 직접구현해주었는데, 이번 글에서는 torchvision에서 augmentation을 위해 제공해주는 torchvision.transform 모듈을 적용하여 data load 하는 내용을 설명하려고 합니다.
[data_load.py]
import os
import numpy as np
import glob
import torch
import torch.nn as nn
## 데이터 로더를 구현하기
class Dataset(torch.utils.data.Dataset):
def __init__(self, data_dir, transform=None, seed=None):
self.data_dir = data_dir
self.transform = transform
self.seed = seed
self.data_dir_input = self.data_dir + '/input'
self.data_dir_label = self.data_dir + '/label'
lst_data_input = os.listdir(self.data_dir_input)
lst_data_label = os.listdir(self.data_dir_label)
self.lst_label = lst_data_label
self.lst_input = lst_data_input
def __len__(self):
return len(self.lst_label)
def __getitem__(self, index):
label = np.load(os.path.join(self.data_dir_label, self.lst_label[index]))
input = np.load(os.path.join(self.data_dir_input, self.lst_input[index]))
if label.ndim == 2:
label = label[:, :, np.newaxis]
if input.ndim == 2:
input = input[:, :, np.newaxis]
data = {'input': input, 'label': label}
if self.transform:
torch.manual_seed(self.seed)
data['input'] = self.transform(data['input'])
if self.transform:
torch.manual_seed(self.seed)
data['label'] = self.transform(data['label'])
return data
[train.py]
import os
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from model import UNet
from data_load import *
import time
from torchvision import transforms
import copy
from torchvision.utils import save_image
data_dir = 'data'
batch_size= 2
data_load_seed = 10
transform_train = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=0.5, std=0.5)])
transform_val = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=0.5, std=0.5)
])
dataset_train = Dataset(data_dir=os.path.join(data_dir, 'train'), transform=transform_train, seed=data_load_seed)
loader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=False, num_workers=0)
dataset_val = Dataset(data_dir=os.path.join(data_dir, 'val'), transform=transform_val, seed=data_load_seed)
loader_val = DataLoader(dataset_val, batch_size=batch_size, shuffle=False, num_workers=0)
# 그밖에 부수적인 variables 설정하기
num_data_train = len(dataset_train)
num_data_val = len(dataset_val)
num_batch_train = np.ceil(num_data_train / batch_size)
num_batch_val = np.ceil(num_data_val / batch_size)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
## 네트워크 생성하기
net = UNet().to(device)
## 손실함수 정의하기
fn_loss = nn.BCEWithLogitsLoss().to(device)
## Optimizer 설정하기
optim = torch.optim.Adam(net.parameters(), lr=1e-3)
## 네트워크 학습시키기
st_epoch = 0
num_epoch = 30
# TRAIN MODE
def train_model(net, fn_loss, optim, num_epoch):
since = time.time()
best_model_wts = copy.deepcopy(net.state_dict())
best_loss = 100
for epoch in range(st_epoch + 1, num_epoch + 1):
net.train()
loss_arr = []
for batch, data in enumerate(loader_train, 1):
data['label'] = data['label']*0.5+0.5 #denormalization -> X*std+mean
label = data['label']
input = data['input']
# first_batch_input = input[0]*0.5+0.5
# save_image(first_batch_input, 'first_batch_input.jpg')
# first_batch_label = label[0]
# save_image(first_batch_label, 'first_batch_label.jpg')
# forward pass
label = data['label'].to(device)
input = data['input'].to(device)
output = net(input)
# backward pass
optim.zero_grad()
loss = fn_loss(output, label)
loss.backward()
optim.step()
# 손실함수 계산
loss_arr += [loss.item()]
print("TRAIN: EPOCH %04d / %04d | BATCH %04d / %04d | LOSS %.4f" %
(epoch, num_epoch, batch, num_batch_train, np.mean(loss_arr)))
with torch.no_grad():
net.eval()
loss_arr = []
for batch, data in enumerate(loader_val, 1):
data['label'] = data['label']*0.5+0.5 #denormalization -> X*std+mean
# forward pass
label = data['label'].to(device)
input = data['input'].to(device)
output = net(input)
# 손실함수 계산하기
loss = fn_loss(output, label)
loss_arr += [loss.item()]
print("VALID: EPOCH %04d / %04d | BATCH %04d / %04d | LOSS %.4f" %
(epoch, num_epoch, batch, num_batch_val, np.mean(loss_arr)))
epoch_loss = np.mean(loss_arr)
# deep copy the model
if epoch_loss < best_loss:
best_loss = epoch_loss
best_model_wts = copy.deepcopy(net.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val loss: {:4f}'.format(best_loss))
# load best model weights
net.load_state_dict(best_model_wts)
return net
model_ft = train_model(net, fn_loss, optim, num_epoch)
torch.save(model_ft.state_dict(), './model_log/model_weights.pth')
위에 있는 코드들 중에서 핵심적인 코드 또는 수정한 코드에 대해서만 설명 하도록 하겠습니다 (좀 더 구체적인 설명을 듣고 싶으신 분은 위에 링크를 걸어둔 유튜브 강의를 참고해주시면 감사하겠습니다)
0.Dataset 클래스
from torchvision import transforms
transform_train = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=0.5, std=0.5)])
dataset_train = Dataset(data_dir=os.path.join(data_dir, 'train'), transform=transform_train)
loader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True, num_workers=0)
Dataset()에 넘겨주는 인자를 보면 두 가지 입니다.
- train 디렉토리
- 적용할 augmentation 기법들 → transform
그럼 Dataset에 구현되있는 부분 중에 train 디렉토리에 해당하는 부분들을 살펴보도록 하겠습니다.
1. train 디렉토리와 관련된 부분
## 데이터 로더를 구현하기
class Dataset(torch.utils.data.Dataset):
def __init__(self, data_dir, transform=None):
self.data_dir = data_dir
self.transform = transform
self.data_dir_input = self.data_dir + '/input'
self.data_dir_label = self.data_dir + '/label'
lst_data_input = os.listdir(self.data_dir_input)
lst_data_label = os.listdir(self.data_dir_label)
self.lst_label = lst_data_label
self.lst_input = lst_data_input
def __len__(self):
return len(self.lst_label)
def __getitem__(self, index):
label = np.load(os.path.join(self.data_dir_label, self.lst_label[index]))
input = np.load(os.path.join(self.data_dir_input, self.lst_input[index]))
if label.ndim == 2:
label = label[:, :, np.newaxis]
if input.ndim == 2:
input = input[:, :, np.newaxis]
data = {'input': input, 'label': label}
위의 코드를 살펴보면 train 디렉토리가 Dataset의 인자로 넘어가게 되면 아래 그림1에 있는 디렉토리의 numpy 데이터에 접근한다는 것을 확인할 수 있습니다.
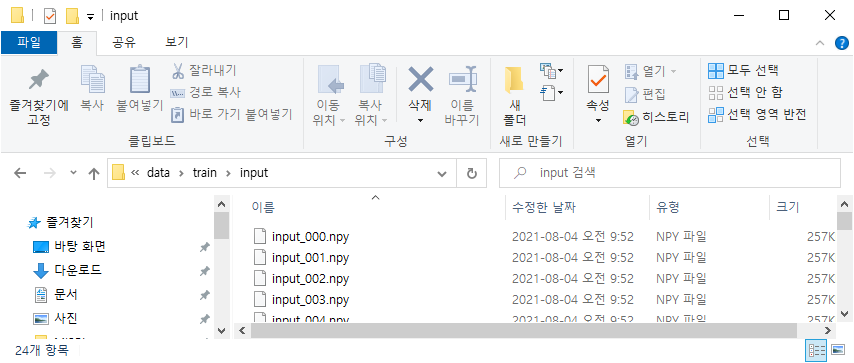
실제로 breakpiont를 통해 살펴보면 input, label 이라는 변수에 모든 numpy 데이터들이 리스트 형태로 저장되는 것을 확인할 수 있습니다.
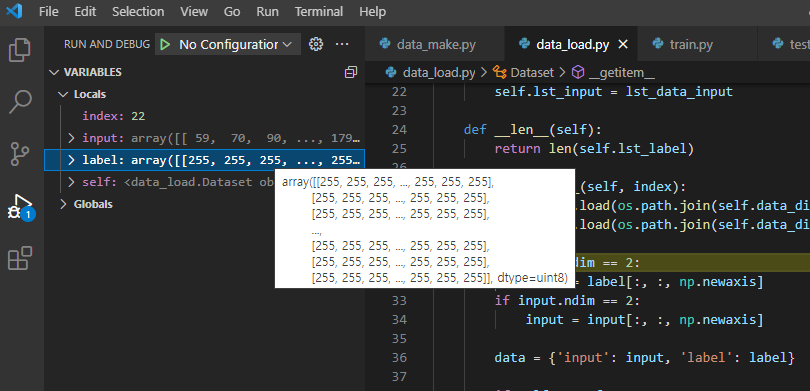
앞선 글에서 저장된 데이터의 형태가 (H,W) 임을 확인할 수 있었습니다.
또한, 딥러닝 모델의 학습을 위해서 (H,W)의 2차원 구조가 (H,W,C)의 3차원 구조로 변경되어야 한다고도 말씀드렸습니다.
(↓↓↓ 아래 글에서 "2-3) numpy 형태로 저장하는 이유" 부분을 참고해주세요↓↓↓)
https://89douner.tistory.com/298?category=1001221
0.DataSet 마련하기 (Feat. ISBI 2012 EM segmentation)
안녕하세요. 이번 글에서는 Segmentation을 하기 위해 데이터셋을 어떻게 세팅해놓는지에 대해 설명하려고 합니다. 코드는 아래 사이트를 기반으로 수정하였으니 아래 영상을 먼저 참고하시면 글
89douner.tistory.com
(아래 "그림3"처럼 shape 부분을 살펴보면 label, input 변수에 저장된 데이터는 numpy형식의2차원 데이터입니다.)
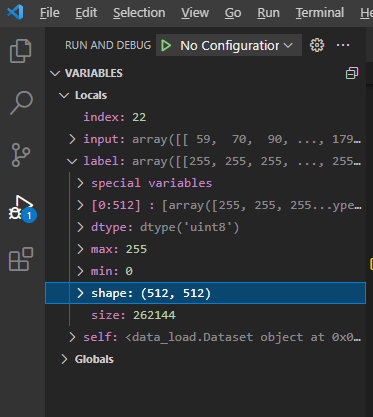
위와 같은 2차원 구조를 3차원으로 늘려주기 위해 아래 코드가 실행됩니다.
[data_load.py]
if label.ndim == 2:
label = label[:, :, np.newaxis]
if input.ndim == 2:
input = input[:, :, np.newaxis]
2. torchvision.transform
앞서 설명드린 내용은 아래 코드에서 'if self.transform' 직전까지 부분입니다.
## 데이터 로더를 구현하기
class Dataset(torch.utils.data.Dataset):
def __init__(self, data_dir, transform=None):
self.data_dir = data_dir
self.transform = transform
self.data_dir_input = self.data_dir + '/input'
self.data_dir_label = self.data_dir + '/label'
lst_data_input = os.listdir(self.data_dir_input)
lst_data_label = os.listdir(self.data_dir_label)
self.lst_label = lst_data_label
self.lst_input = lst_data_input
def __len__(self):
return len(self.lst_label)
def __getitem__(self, index):
label = np.load(os.path.join(self.data_dir_label, self.lst_label[index]))
input = np.load(os.path.join(self.data_dir_input, self.lst_input[index]))
if label.ndim == 2:
label = label[:, :, np.newaxis]
if input.ndim == 2:
input = input[:, :, np.newaxis]
data = {'input': input, 'label': label}
if self.transform:
torch.manual_seed(10)
data['input'] = self.transform(data['input'])
if self.transform:
torch.manual_seed(10)
data['label'] = self.transform(data['label'])
return data
그렇다면, 지금부터는 self.transform 과 관련된 내용에 대해서 설명하도록 하겠습니다.
self.transform 부분은 Dataset 클래스에서 두 번째로 살펴볼 인자인 transform과 관련이 있습니다.
(transform은 torchvision에서 제공해주는 모듈로 사용하고 있습니다.)
from torchvision import transforms
transform_train = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=0.5, std=0.5)])
dataset_train = Dataset(data_dir=os.path.join(data_dir, 'train'), transform=transform_train)
loader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True, num_workers=0)
2-1) transforms.ToPILImage()
우선 위의 코드에서 transforms.Compose 부분을 살펴보겠습니다.
현재 아래코드가 실행되기 직전의 data['input']에 들어 있는 데이터 구조는 3차원 (H,W,C) 형태로 변경된 numpy 데이터 입니다.
if self.transform:
torch.manual_seed(10)
data['input'] = self.transform(data['input'])
그리고, self.transform(data['input'])이 실행되면 transform.Compose에 적힌 순서대로 데이터의 변화가 일어납니다.
먼저, RandomHorizontalFlip과 같이 torchvision에서 제공해주는 augmentation 기법을 사용하기 위해서는 현재 numpy 형식의 데이터가 PIL 이미지 형식의 데이터가 입력값으로 들어와야 합니다.
그렇기 때문에 transform.Compose 부분에서 제일 처음으로 "transforms.ToPILImage()"를 작성해줍니다.
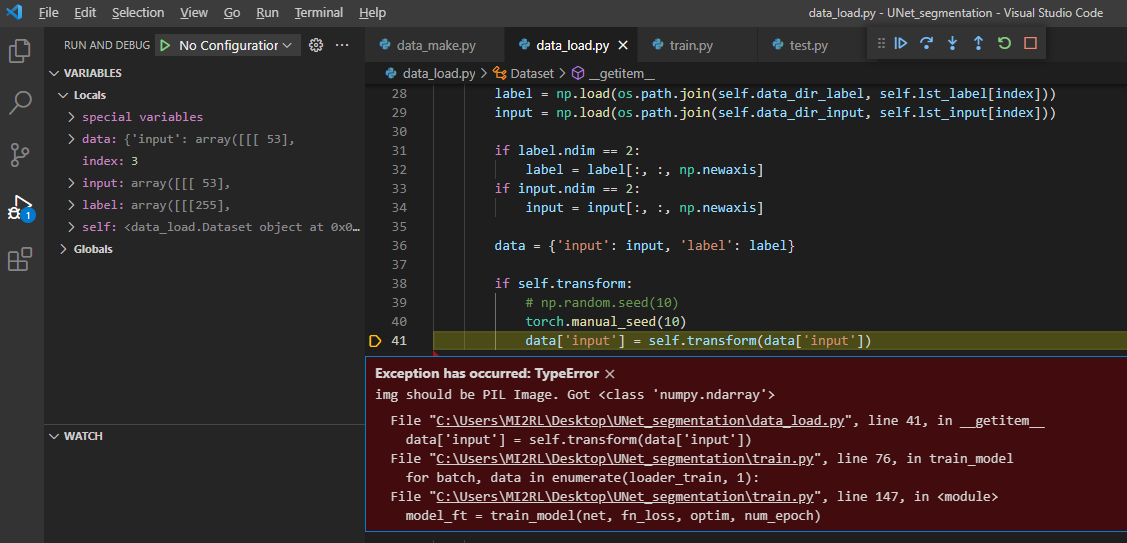
[주의사항1]
만약, ToPILImage() 부분을 작성하지 않으면 아래와 같은 에러가 발생합니다.
에러 메시지 내용은 아래와 같습니다.
"현재 입력 받은 이미지의 형식은 numpy.ndarray 이니까 (="Got <class 'numpy.ndarray'>), PIL 형태로 바꿔주어야 합니다(="img should be PIL Image")"
2-2) transforms.ToTensor, transforms.Normalize 위치
Pytorch에서 제공해주는 transforms.Normalize()를 사용하려면 항상 transforms.ToTensor() 이후에 위치해야 합니다.
이렇게 위치시켜야하는 이유는 Normalize()가 torch tensor 형식을 입력으로 받기 때문입니다.
아래 코드를 기반으로 설명하면, RandomVerticalFlip까지 적용된 데이터 형식은 PIL image 형식 (512x 512x 1) 인데, 이것을 Normalize가 적용되려면 (1x 512x 512) 형식으로 변경되어야 합니다 (pixel range도 0~1로 변경되어야 합니다).
- ToTensor(): Converts a PIL Image or numpy.ndarray (H x W x C) in the range [0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0]
from torchvision import transforms
transform_train = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=0.5, std=0.5)])
dataset_train = Dataset(data_dir=os.path.join(data_dir, 'train'), transform=transform_train)
loader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True, num_workers=0)
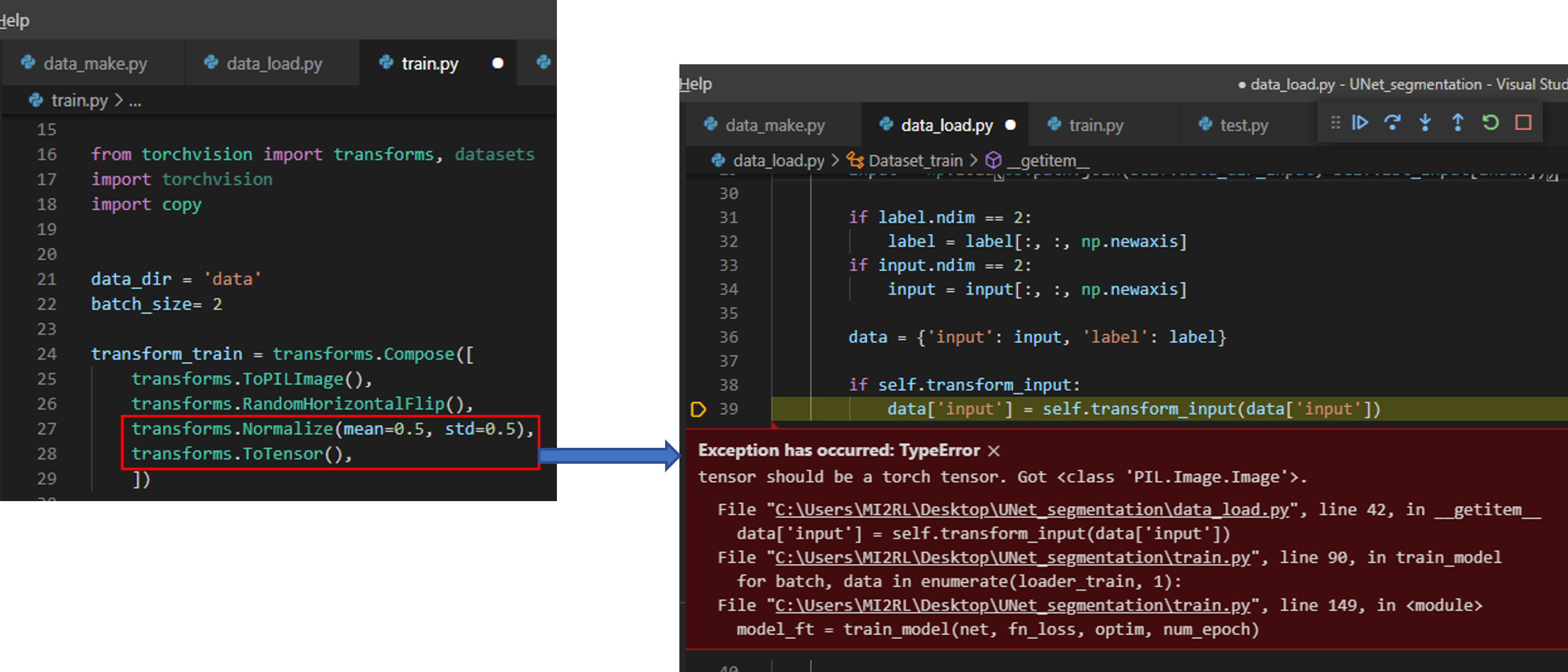
[주의사항2]
만약, 순서를 아래와 같이 위치시켰다면 에러 메시지가 출력됩니다.
- transforms.Normalize
- transforms.ToTensor
에러 메시지의 내용은 다음과 같습니다.
"현재 입력 받은 이미지의 형식은 PIL기반 tensor이니까 (="Got <class 'PIL.Image.Image'>), PIL 형태로 바꿔주어야 합니다(="tensor should be a torch tensor")"
2-3. input, label에 적용되는 transform seed 고정해주기
아래 코드를 살펴보면 "torch.manual_seed(10)"이라는 것이 있습니다.
[data_load.py]
if self.transform:
torch.manual_seed(10)
data['input'] = self.transform(data['input'])
if self.transform:
torch.manual_seed(10)
data['label'] = self.transform(data['label'])
"torch.manual_seed(10)" 코드를 추가하는 이유를 설명하기 위해, "torch.manual_seed(10)"가 없을 때 일어나는 일에 대해서 알아보도록 하겠습니다.
우선 "data_load.py" 부분에서 "torch.manual_seed(10)" 코드를 주석 처리해보겠습니다.
if self.transform:
#torch.manual_seed(10)
data['input'] = self.transform(data['input'])
if self.transform:
#torch.manual_seed(10)
data['label'] = self.transform(data['label'])
그리고, "train.py" 부분에서 딥러닝 모델에 입력되기 직전의 이미지 상태를 알아보도록 하겠습니다.
이전 transforms.Compose에서 input, label에 모두 transforms.Normalize가 적용이 됐다는걸 알 수 있습니다.
그런데, 생각해보면 label에는 Normalize가 적용이 돼서는 안되겠죠? (label에는 0 or 1 값만 들어 있어야 되는데 앞서 mean, std를 이용해 normalize를 하면 1 or -1 값을 갖게됩니다. 하지만, CrossEntropy loss function이 받는 label 값들은 0 or 1 이어야 하죠)
그러므로, 가장 먼저 수정해주어야 하는 부분이 normalize가 적용된 label 이미지 데이터들을 다시 denormalize 해주어야 한다는 점입니다. 그래서 아래 "data['label']*0.5+0.5" 부분이 추가가 되었습니다.
[train.py]
for batch, data in enumerate(loader_train, 1):
data['label'] = data['label']*0.5+0.5 #denormalization -> X*std+mean
label = data['label']
input = data['input']
다음으로는 딥러닝 모델에 들어가기 직전의 데이터들을 저장해서 보겠습니다.
먼저, 아래 부분(89번 line)에 breakpoint를 걸어주어 input 데이터의 shape을 살펴보면, (batch, Channel, Height, Width)와 같은 형태로 구성되어 있는걸 확인하실 수 있습니다.
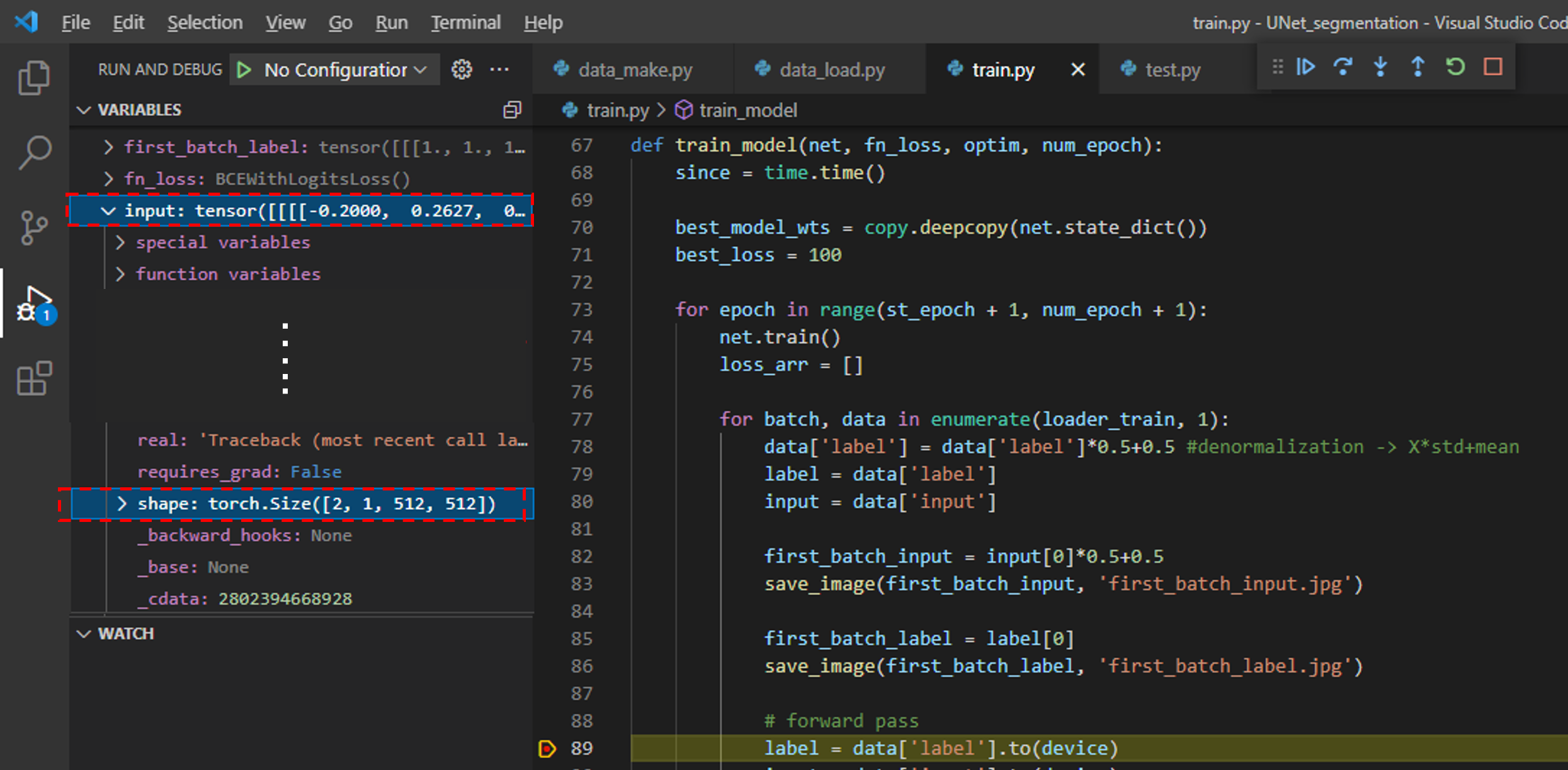
그럼 input, label의 각각 첫 번째 batch 이미지를 따로 저장시킬 코드를 추가하겠습니다.
우선 input 데이터에서도 normalize가 적용된 상태이기 때문에 denormalize를 해줍니다. (←"input[0]*0.5+0.5")
그리고 첫 번째 batch 이미지에 해당하는 데이터 값은 "input[0]*0.5+0.5", "label[0]"인데, 현재 데이터 형식은 torch tensor입니다.
torch tensor 형식에서 곧 바로 이미지를 저장하기 위해서는 "torchvision.utils"에서 제공하는 save_image()를 이용하면 됩니다.
for batch, data in enumerate(loader_train, 1):
data['label'] = data['label']*0.5+0.5 #denormalization -> X*std+mean
label = data['label']
input = data['input']
#################코드가 추가된 부분###################
first_batch_input = input[0]*0.5+0.5
save_image(first_batch_input, 'first_batch_input.jpg')
first_batch_label = label[0]
save_image(first_batch_label, 'first_batch_label.jpg')
#######################################################
코드를 실행하고 저장된 이미지를 살펴보겠습니다.
input 데이터의 이미지와 label 데이터의 이미지가 일치하지 않는게 보이시나요? 어느 한쪽이 flip이 안 됐다는 정도는 파악할 수 있을겁니다.
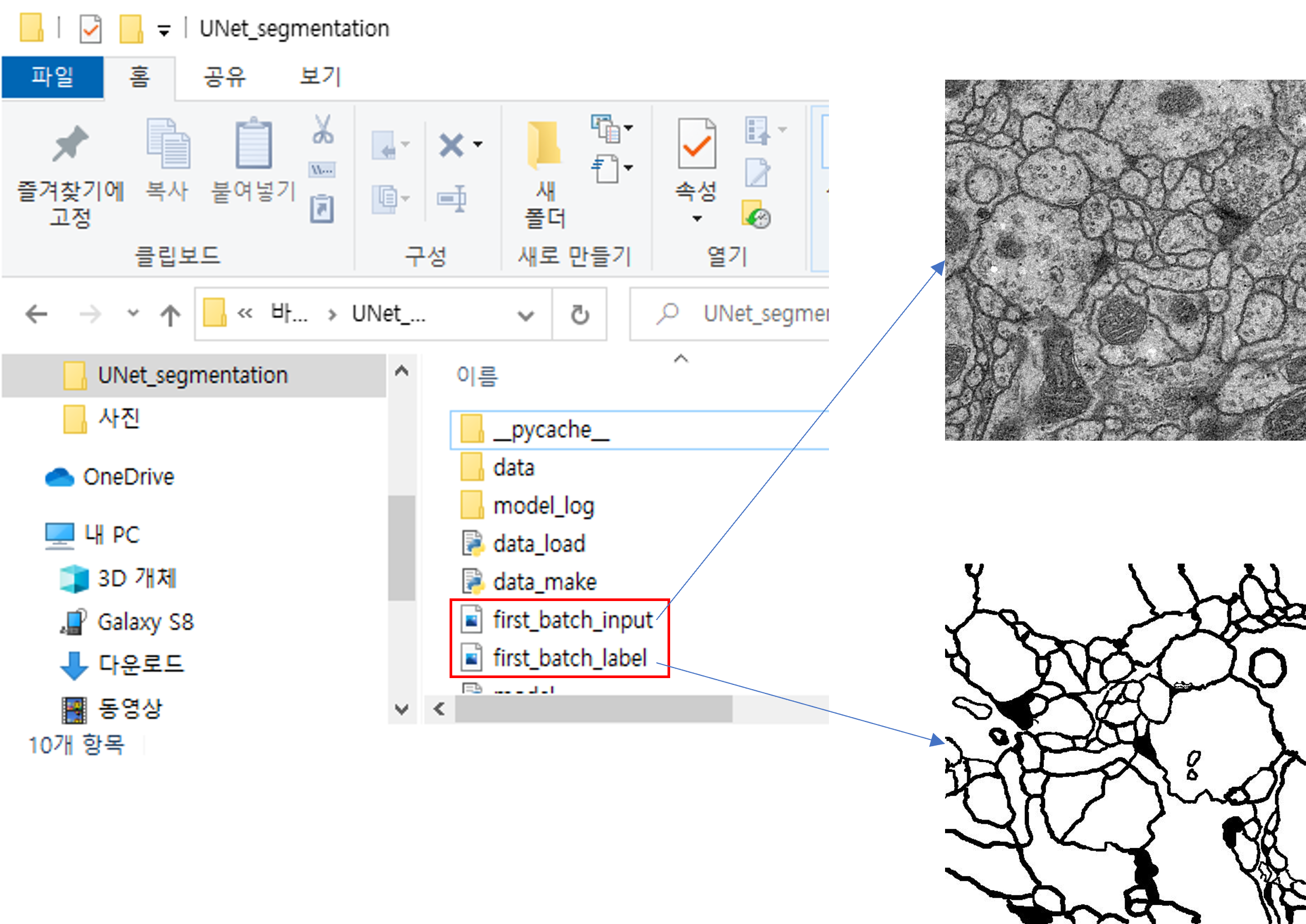
이렇게 나오는 이유를 찾기 위해 transforms.RandomHorizontalFlip 코드를 살펴보았습니다.
(↓↓↓transforms.RandomHorizontalFlip API ↓↓↓)
torchvision.transforms.transforms — Torchvision 0.10.0 documentation
Shortcuts
pytorch.org
해당 API를 차례대로 살펴보겠습니다.
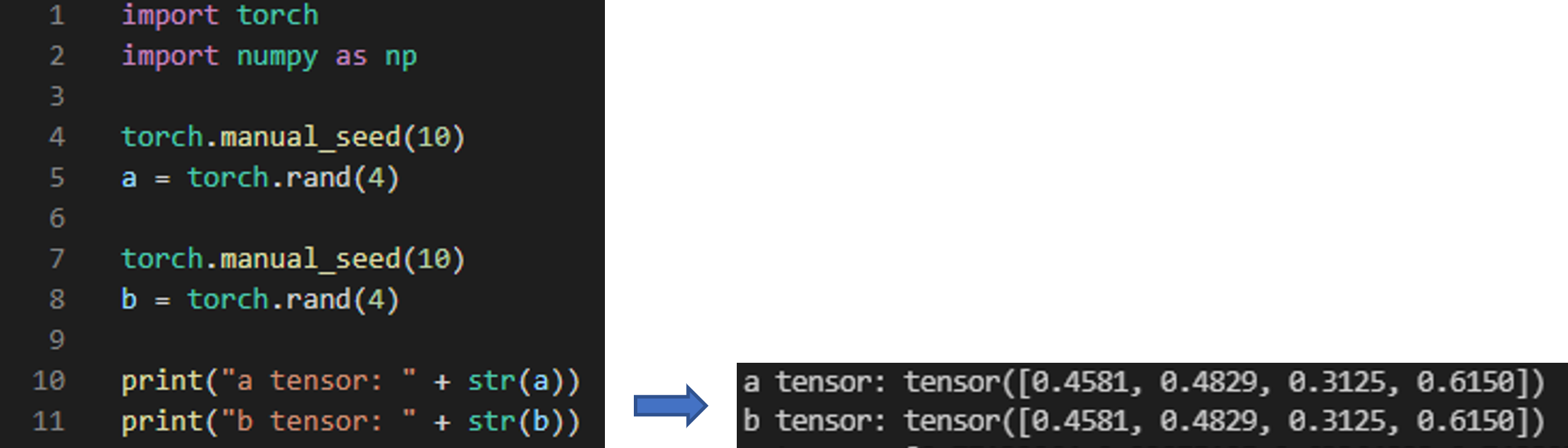
앞서 input, label에 서로다른 augmenation이 적용된 이유는 torch.rand() 때문입니다. 왜 torch.rand() 때문이었는지 좀 더 자세히 설명해보도록 하겠습니다.
torch.rand()이라는 함수에 대한 설명은 아래와 같습니다.
- Returns a tensor filled with random numbers from a uniform distribution on the interval [0, 1)
(↓↓↓torch.rand↓↓↓)
https://pytorch.org/docs/stable/generated/torch.rand.html
torch.rand — PyTorch 1.9.0 documentation
Shortcuts
pytorch.org
torch.rand(1)은 데이터가 1차원 형태이며 0~1 사이의 값 중 하나를 출력한다는 뜻입니다.
만약, 4차원 형태를 나타내려면 아래와 같이 코딩해주면 됩니다.

위의 코드를 결과를 살펴보면 torch.rand를 실행시켜 줄 때 마다 난수가 발생하기 때문에 a, b에 들어가는 값들이 전부다른걸 보실 수 있습니다.
위와 같은 사실을 기반으로 "data_load.py"에 구현되어 있는 아래 코드를 살펴보겠습니다.
우선 data['input']에 해당하는 데이터에 transform이 진행되는 과정을 살펴보겠습니다. → self.transform(data['input'])
if self.transform:
#torch.manual_seed(10)
data['input'] = self.transform(data['input'])
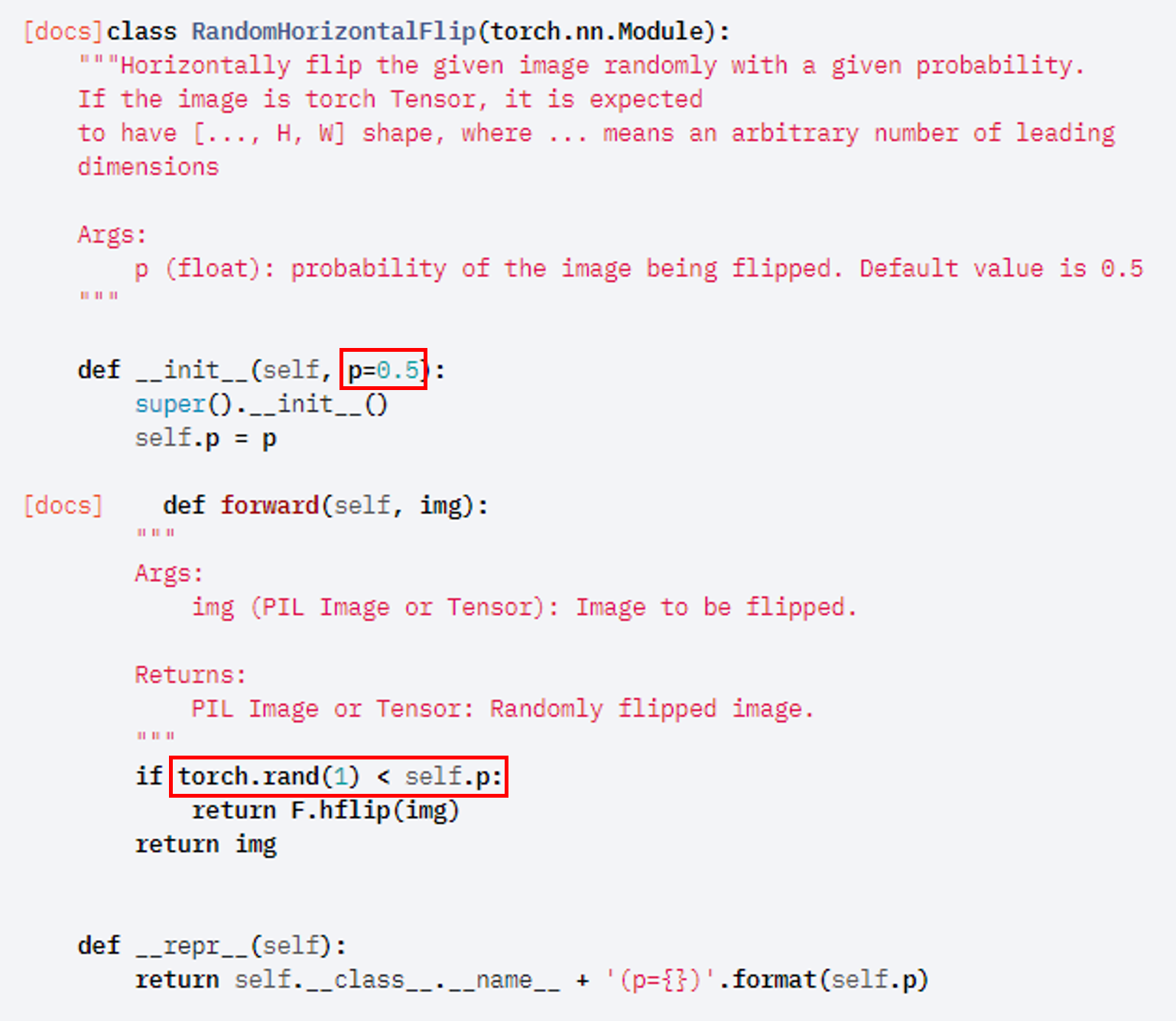
앞서 transforms.Compose에 구현된 것 중하나가 RandomHorizontalFlip()인데, 이 부분이 아래와 같은 코드를 기반으로 수행이 될 겁니다. 그런데 보면, torch.rand(1)를 통해 난수가 발생하는 걸 볼 수 있죠? 만약 여기서 0.3이라는 값이 생성되면 "p=0.5" 기준에 의해 RandomHorizontalFlip() 방식의 augmentation이 진행되지 않을 것입니다.
이때 label 데이터에서도 RandomHorzontalFlip()이 적용이 되는데 (by "self.transform(data['label'])"), torch.rand(1)에서 생성된 값(=난수)가 0.6이면, label에는 RandomHorzontalFlip()이 적용되게 됩니다.
if self.transform:
#torch.manual_seed(10)
data['input'] = self.transform(data['input'])
if self.transform:
#torch.manual_seed(10)
data['label'] = self.transform(data['label'])
그래서 "그림7"과 같은 결과를 보이게 됩니다.
이러한 문제를 해결하기 위해서는 "torch.rand(1)"를 통해 생성되는 난수를 고정시켜주어야 합니다.
난수를 고정시키는 방법은 간단합니다. 아래와 "그림10"처럼 난수가 생성되기 전에 seed 값을 고정시켜주면 됩니다. 그러면, torch.rand()를 통해 생겨나는 난수 값들이 고정됩니다.
위와 같은 방식을 통해 self.transform(data['input']), self.trasnform(data['label'])에서 augmentation 시, 발생되는 난수 값이 (by "torch.rand()") 동일해집니다. 즉, input, label 모두 동일한(일치한) augmentation을 제공해주게 됩니다.
if self.transform:
torch.manual_seed(10)
data['input'] = self.transform(data['input'])
if self.transform:
torch.manual_seed(10)
data['label'] = self.transform(data['label'])
3. freeze_support() 에러
데이터 로드와 관련된 모든 준비가 완료되었습니다.
그럼 "train.py" 코드를 실행해보죠.
만약 앞서 제가 설명드린 코드가 아닌 유튜브 강의에서 설명한 코드로 실행했을 때 리눅스에서 실행하셨다면 큰 문제없이 실행됐겠지만, 만약 윈도우에서 실행시키셨다면 아래와 같은 에러 메시지를 만나실 수 있습니다.
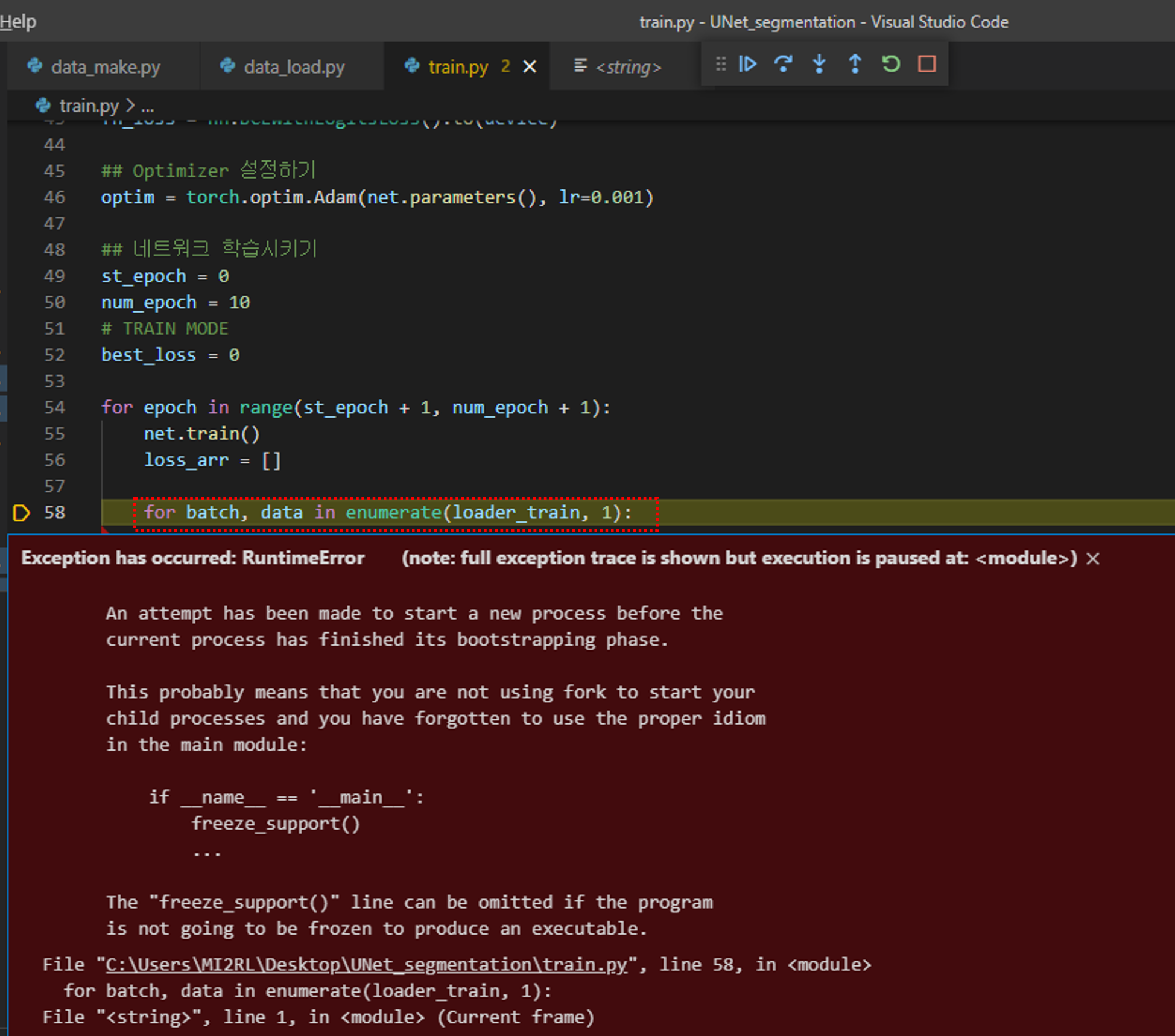
아래 코드를 한 번 살펴보겠습니다.
DataLoader에 num_workers가 보이시나요?
from torchvision import transforms
transform_train = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=0.5, std=0.5)])
dataset_train = Dataset(data_dir=os.path.join(data_dir, 'train'), transform=transform_train)
loader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True, num_workers=0)
num_workers는 GPU에 학습 이미지를 업로드하기 위해서 사용되는 CPU의 process 개수입니다.
쉽게 말해 GPU 학습 이미지를 업로드 하기 위해서는 결국 CPU가 중간 다리 역할을 해줘야 하는데, 이때 num_workers를 크게 설정해주면 GPU에 학습 이미지를 업로드하는데 관여하는 process도 많아지겠죠. 이렇게 되면 결국 학습 이미지 업로드 속도도 빨라질겁니다.
(↓↓↓num_workers에 대해서 설명한 글↓↓↓)
https://89douner.tistory.com/287?category=994842
1. Data Load (Feat. CUDA)
안녕하세요. 이번 글에서는 CNN 모델 학습을 위해 학습 데이터들을 로드하는 코드에 대해 설명드리려고 합니다. 아래 사이트의 코드를 기반으로 설명드리도록 하겠습니다. https://pytorch.org/tutorials
89douner.tistory.com
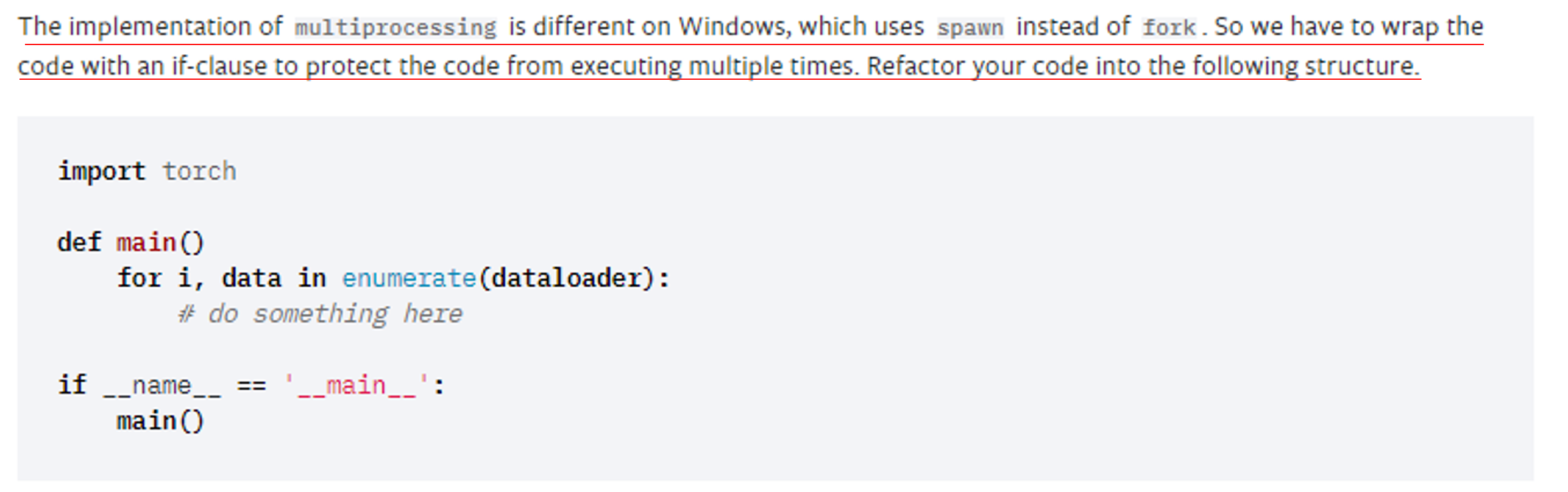
앞서 "그림11"에서 설명한 에러가 발생하는 이유는 아래의 사이트에서 설명하고 있습니다.
https://pytorch.org/docs/stable/notes/windows.html#usage-multiprocessing
Windows FAQ — PyTorch 1.9.0 documentation
Shortcuts
pytorch.org
요약해 설명하자면 "Dataload"를 수행시키기 위해서는 multi-process (by "num_workers")를 이용하는데, 이것이 리눅스가 아닌 window에서 사용하기 위해서는 아래와 같이 특정 작업을 해주어야 한다고 합니다.
3-1) 첫 번째 에러 수정 방법
첫 번째 방식은 매우 간단합니다.
그냥 num_workers 부분을 0으로 세팅해주면 됩니다.
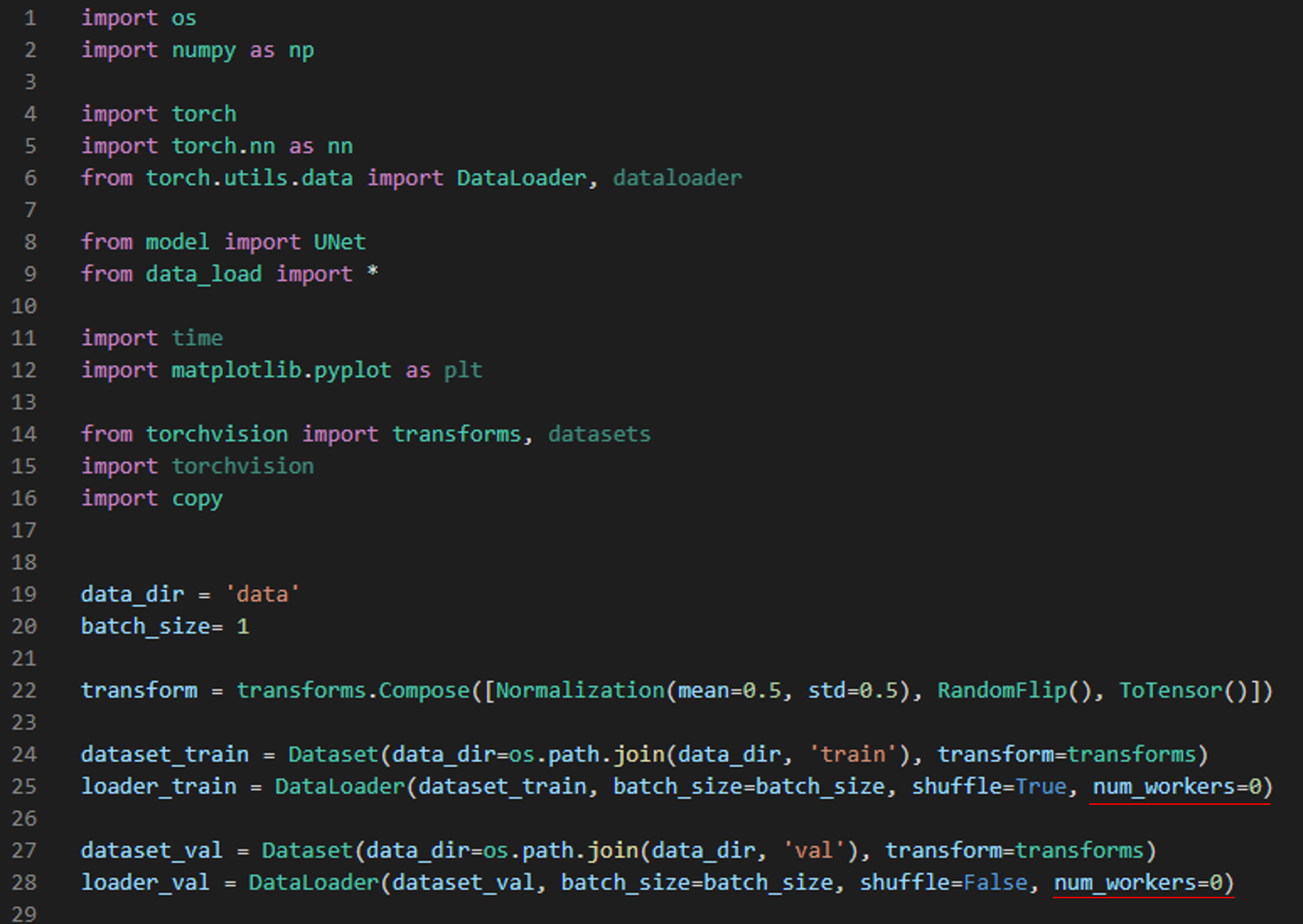
3-1) 두 번째 에러 수정 방법
두 번째 에러 수정 방법은 "그림11"에서 제안한대로 코드를 변경시켜 주면 됩니다.
아래 그림14처럼 "train.py"에서 "def train()"함수 부분을 만들어주고 (←유튜브 강의에서는 train()함수를 따로 정의하진 않고 있습니다) training에 해당되는 코드를 옮겨줍니다. 그리고, 마지막 코드에 추가로 main관련 코드를 작성해줍니다.
import os
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from model import UNet
from data_load import *
import time
from torchvision import transforms
import albumentations as A
import copy
from torchvision.utils import save_image
data_dir = 'data'
batch_size= 2
transform_train = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=0.5, std=0.5)])
transform_val = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=0.5, std=0.5)
])
dataset_train = Dataset(data_dir=os.path.join(data_dir, 'train'), transform=transform_train)
loader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True, num_workers=2)
dataset_val = Dataset(data_dir=os.path.join(data_dir, 'val'), transform=transform_val)
loader_val = DataLoader(dataset_val, batch_size=batch_size, shuffle=False, num_workers=2)
# 그밖에 부수적인 variables 설정하기
num_data_train = len(dataset_train)
num_data_val = len(dataset_val)
num_batch_train = np.ceil(num_data_train / batch_size)
num_batch_val = np.ceil(num_data_val / batch_size)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
## 네트워크 생성하기
net = UNet().to(device)
## 손실함수 정의하기
fn_loss = nn.BCEWithLogitsLoss().to(device)
## Optimizer 설정하기
optim = torch.optim.Adam(net.parameters(), lr=1e-3)
## 네트워크 학습시키기
st_epoch = 0
num_epoch = 30
# TRAIN MODE
def train_model(net, fn_loss, optim, num_epoch):
since = time.time()
best_model_wts = copy.deepcopy(net.state_dict())
best_loss = 100
for epoch in range(st_epoch + 1, num_epoch + 1):
net.train()
loss_arr = []
for batch, data in enumerate(loader_train, 1):
data['label'] = data['label']*0.5+0.5 #denormalization -> X*std+mean
label = data['label']
input = data['input']
# first_batch_input = input[0]*0.5+0.5
# save_image(first_batch_input, 'first_batch_input.jpg')
# first_batch_label = label[0]
# save_image(first_batch_label, 'first_batch_label.jpg')
# forward pass
label = data['label'].to(device)
input = data['input'].to(device)
output = net(input)
# backward pass
optim.zero_grad()
loss = fn_loss(output, label)
loss.backward()
optim.step()
# 손실함수 계산
loss_arr += [loss.item()]
print("TRAIN: EPOCH %04d / %04d | BATCH %04d / %04d | LOSS %.4f" %
(epoch, num_epoch, batch, num_batch_train, np.mean(loss_arr)))
with torch.no_grad():
net.eval()
loss_arr = []
for batch, data in enumerate(loader_val, 1):
data['label'] = data['label']*0.5+0.5 #denormalization -> X*std+mean
# forward pass
label = data['label'].to(device)
input = data['input'].to(device)
output = net(input)
# 손실함수 계산하기
loss = fn_loss(output, label)
loss_arr += [loss.item()]
print("VALID: EPOCH %04d / %04d | BATCH %04d / %04d | LOSS %.4f" %
(epoch, num_epoch, batch, num_batch_val, np.mean(loss_arr)))
epoch_loss = np.mean(loss_arr)
# deep copy the model
if epoch_loss < best_loss:
best_loss = epoch_loss
best_model_wts = copy.deepcopy(net.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val loss: {:4f}'.format(best_loss))
# load best model weights
net.load_state_dict(best_model_wts)
return net
if __name__ == '__main__':
model_ft = train_model(net, fn_loss, optim, num_epoch)
torch.save(model_ft.state_dict(), './model_log/model_weights.pth')
위와 같이 변경해주고 실행시켜주면 num_workers에 따라 subprocess가 발생하는걸 확인하실 수 있습니다.
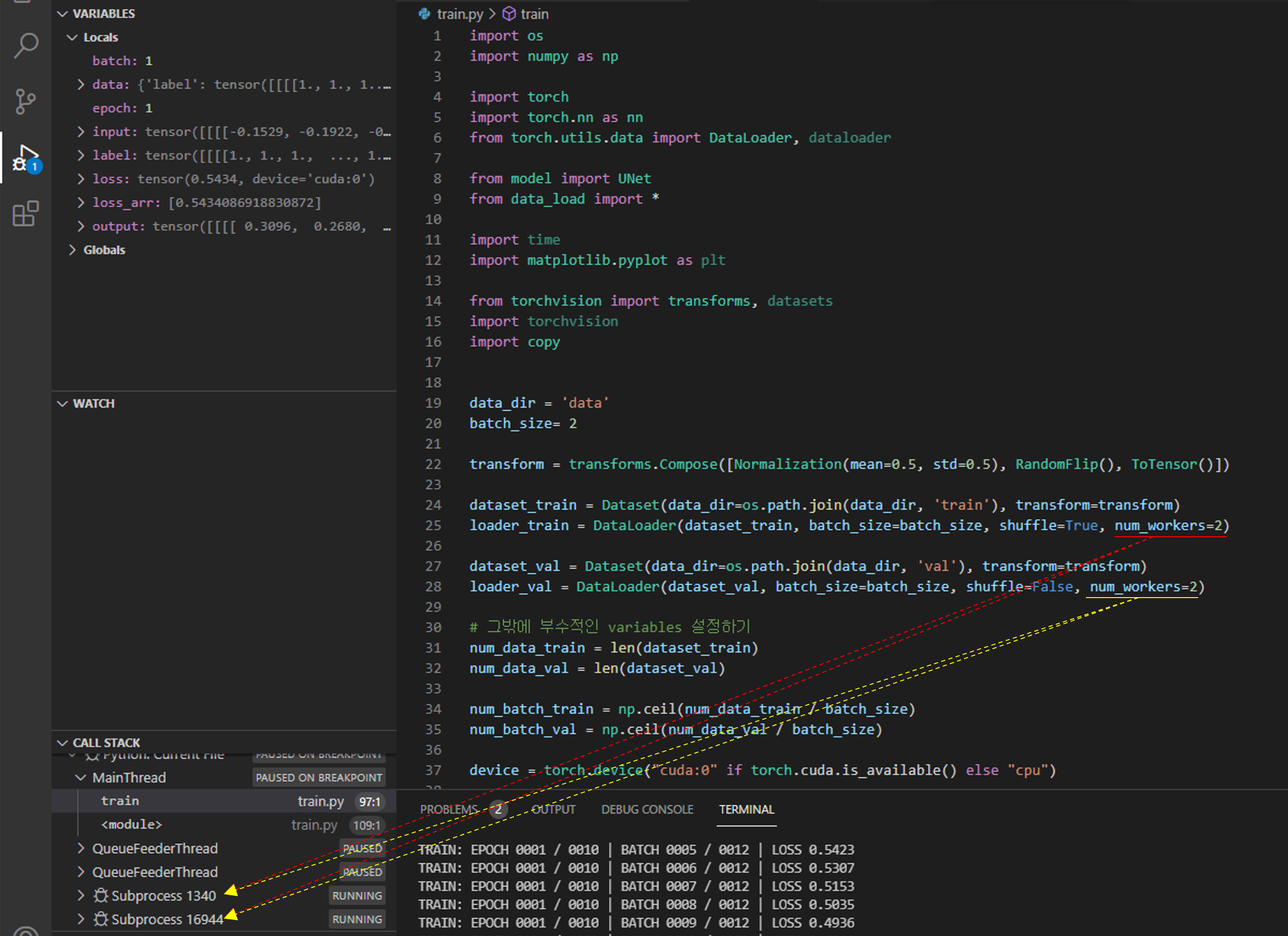
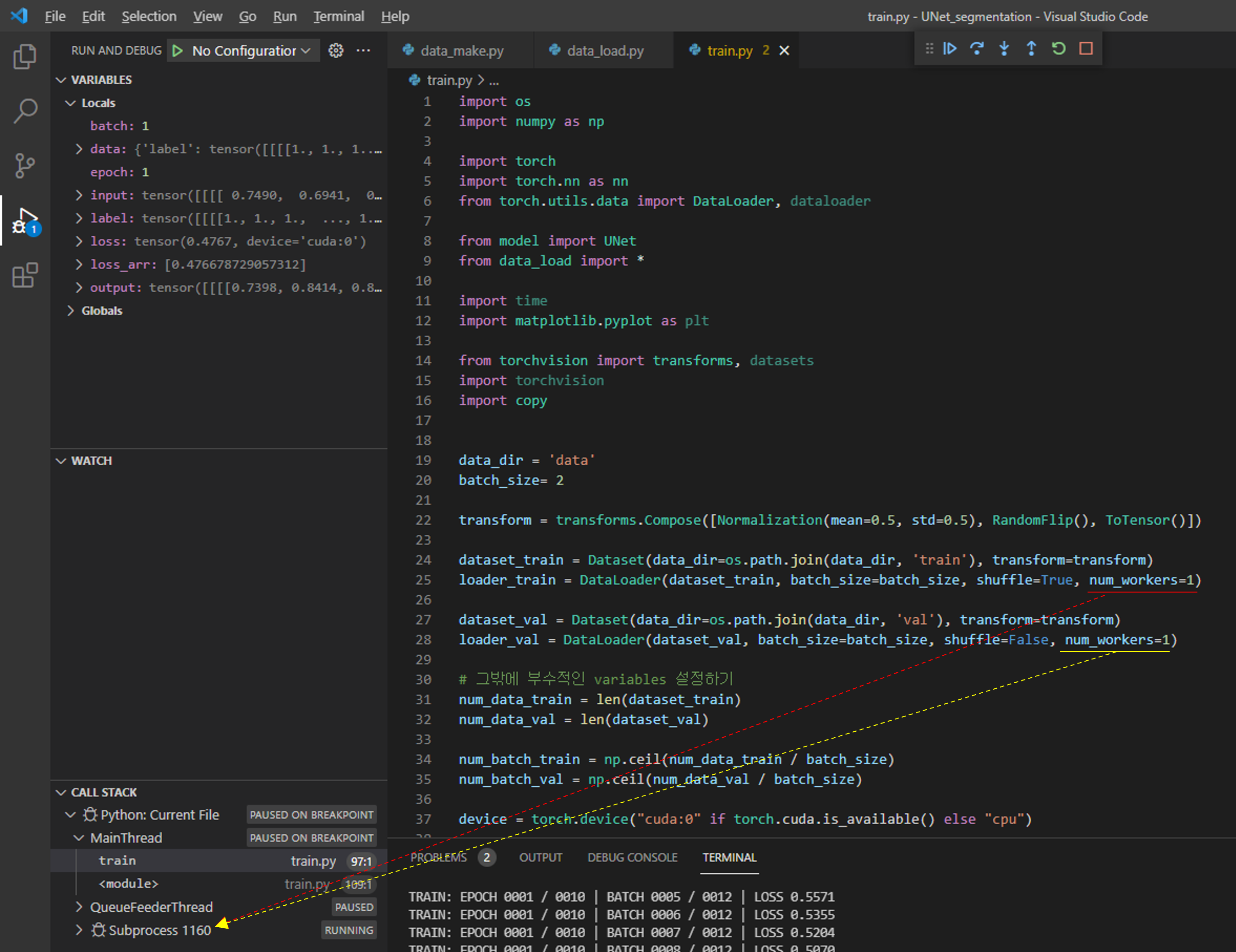
지금까지 pytorch에서 제공해주는 transform을 이용하기 위해 변경시켜야 할 부분들을 설명했습니다.
감사합니다.