3-1. Training 과정 Visualization (Feat. WandB)
안녕하세요.
이번 글에서는 training 과정을 visualization 해주는 패키지를 소개하려고 합니다.
기본적으로 pytorch에서는 tensorboard를 사용하여 loss, accuracy 등 다양한 metrics와 weight, gradient 값들을 histogram으로 볼 수 있도록 summarywriter라는 가능을 제공하고 있습니다.
torch.utils.tensorboard import SummaryWriter
(↓↓↓SummaryWriter 사용법↓↓↓)
https://pytorch.org/docs/stable/tensorboard.html
torch.utils.tensorboard — PyTorch 1.9.0 documentation
torch.utils.tensorboard Before going further, more details on TensorBoard can be found at https://www.tensorflow.org/tensorboard/ Once you’ve installed TensorBoard, these utilities let you log PyTorch models and metrics into a directory for visualization
pytorch.org
하지만, 이외에 많은 분들이 "Weight and Biases"에서 제공하는 wandb 패키지를 이용해 학습과정들을 visualization하기도 하는데요. 이번 글에서는 wandb 패키지를 이용해 어떻게 visualization 할 수 있는지 살펴보도록 하겠습니다.
※이전 글에 있는 코드에 wandb 패키지를 적용하는 법을 설명하도록 할테니, 중간중간 코드가 이해안되시는 분들은 꼭 이전 글들을 봐주세요!
[필자의 개발환경]
OS: Window
가상환경: 아나콘다
딥러닝 프레임워크: Pytorch
IDE: Visual Studio Code
1. 회원가입 및 wandb 연동하기
1-1. wandb 패키지 설치하기
먼저, 제 경우에는 아나콘다 가상환경을 VS Code interpreter에 연동시켜 사용하고 있기 때문에 아나콘다에 wandb 패키지를 설치하도록 하겠습니다.
(↓↓↓ 아나콘다 가상환경에 다양한 패키지 설치 및 VS code 연동 방법↓↓↓)
https://89douner.tistory.com/74
5. 아나콘다 가상환경으로 tensorflow, pytorch 설치하기 (with VS code IDE, pycharm 연동)
안녕하세요~ 이번시간에는 아나콘다를 통해 2개의 가상환경을 만들고 각각의 가상환경에서 pytorch, tensorflow를 설치하는법을 배워볼거에요~ Pytorch: Python 3.7버전/ CUDA 10.1 버전/ Pytorch=1.4버전 Tensorf..
89douner.tistory.com
우선 "anaconda wandb"라고 검색하니 아래 사이트가 나옵니다. 해당 사이트에 접속해보겠습니다.
https://anaconda.org/conda-forge/wandb
Wandb :: Anaconda.org
anaconda.org
접속하니 아래와 같은 화면이 뜹니다. 아나콘다로 wandb를 설치하는 명령어를 알려주네요.
해당부분을 복사합니다.
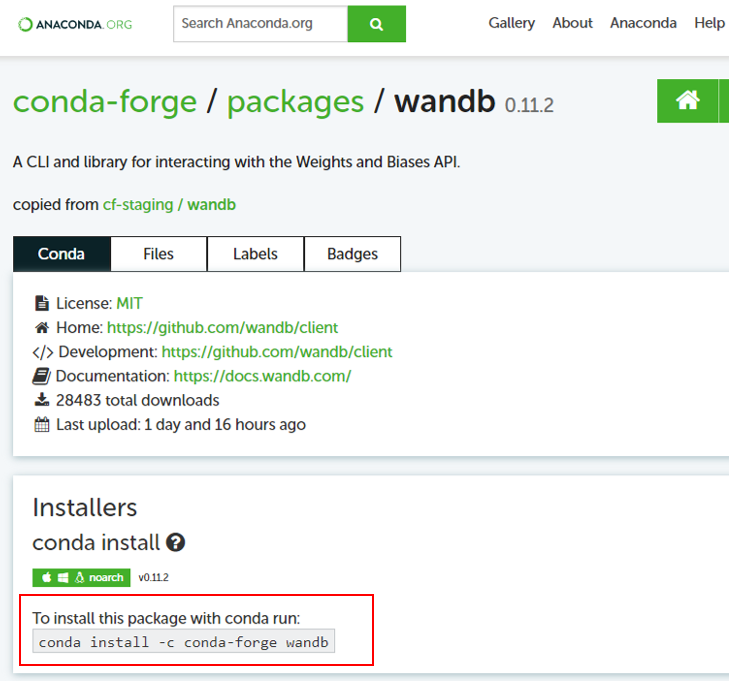
우선 저는 대부분의 패키지(pytorch 등)가 아나콘다 base라는 가상환경에 설치되어 있기 때문에, base 가상환경에 복사한 명령어를 입력하여 설치를 진행해주겠습니다.

1-2. Wandb (Weight and Biases) 회원가입
wandb 패키지를 이용하려면 "Weight and Biases"에 회원가입이 되어 있어야 합니다.
그래야 "Weight and Biases" 웹 사이트와 연동하여 visualization 결과들을 살펴볼 수 있기 때문이죠.
그럼 "Weight and Biases"에 회원 가입을 해보도록하겠습니다.
우선 아래 "Weight and Biases" 사이트에 접속합니다.
Weights & Biases – Developer tools for ML
A central dashboard to keep track of your hyperparameters, system metrics, and predictions so you can compare models live, and share your findings.
wandb.ai
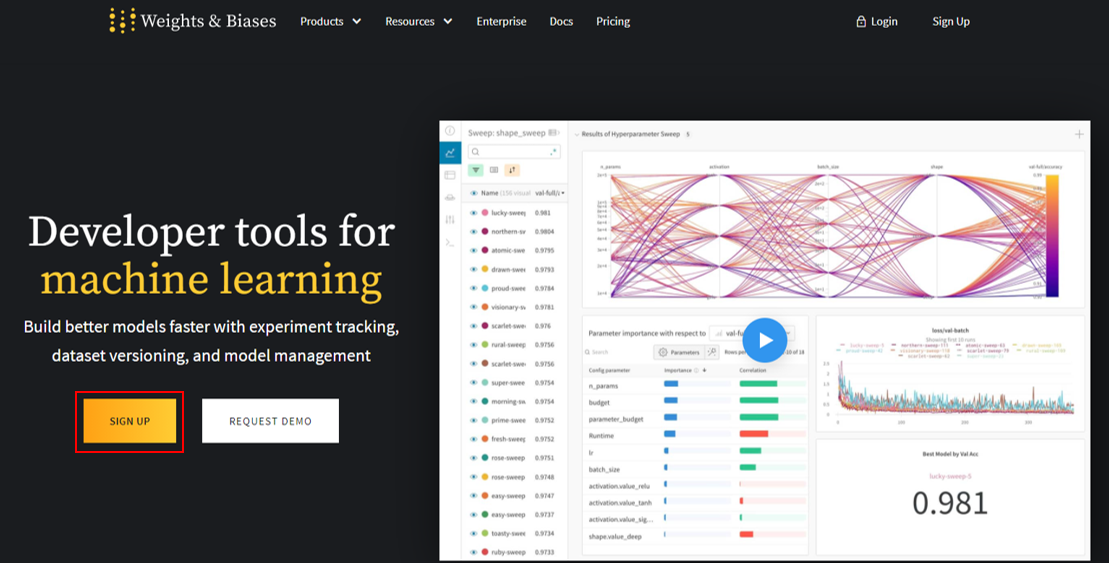
접속을 하시면 아래화면이 처음 등장하게됩니다. 그리고 회원가입 버튼 "Sign up"을 클릭해줍니다.
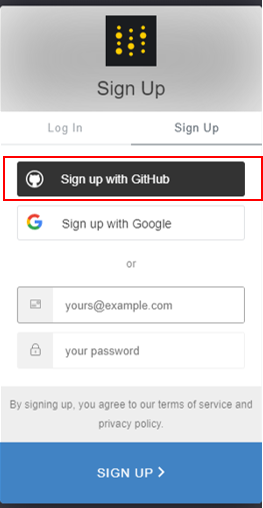
그럼 아래와 같이 회원가입 창이 뜹니다. 제 경우에는 github과 연동해서 사용하려 하기 때문에, "Sign up with GitHub"을 클릭해서 사용하도록 하겠습니다.
그리고 "Authorize wandb" 을 클릭해줍니다.

마지막으로 아래와 같이 계정생성에 필요한 정보를 입력하시면 회원가입이 완료가 됩니다.

회원가입 후, 로그인을 하시면 아래와 같은 화면이 나타납니다.
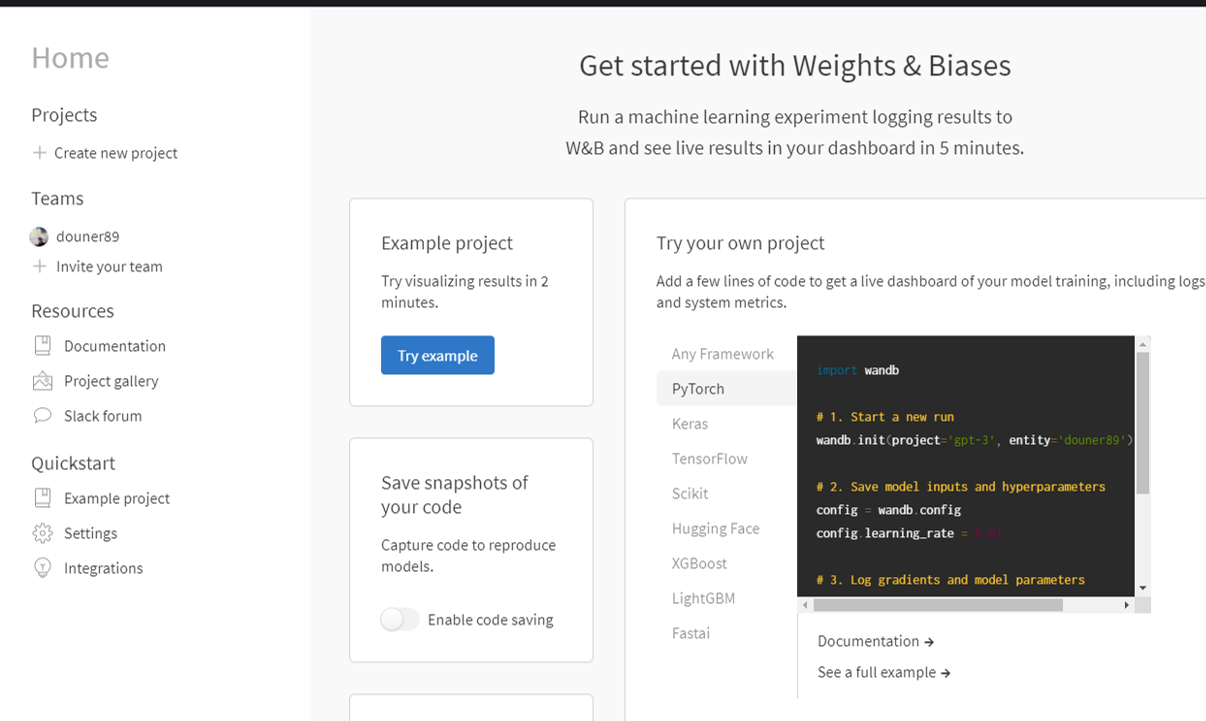
우선 이 화면은 대기해 놓고 아나콘다 가상환경과 wandb를 연동하는 작업부터 하겠습니다.
2. 아나콘다 가상환경과 wandb 연동하기
앞서 언급했듯이 "아나콘다 가상환경을 VS Code interpreter에 연동시켜 사용하고 있고", Weight and Biases 웹 사이트와 연동하여 visualization 결과"를 볼 수 있기 때문에, 아나콘다 가상환경에서 Weight and Biases 웹 사이트와 연동시켜주어야 합니다.
연동 방식은 간단합니다.
먼저 아래와 같이 순서를 진행합니다.
- base 가상환경 프롬프트 열기
- wandb login 명령어 입력
- 아래 빨간색 박스 사이트 복사

- 위에서 복사한 사이트 접속시 아래 화면이 출력 해당 인증키 복사

- 복사한 인증키 아래 빨간색 밑줄 부분에 붙여넣기하고 엔터 (참고로 저는 복붙이 잘 안돼서 메모장에 복붙한다음 하나씩 인증키를 입력했습니다;;;;)

연동이 완료 되었습니다!

3. Project 생성해주기
VS Code에서도 task 마다 별도의 project를 만들게 됩니다. 그렇다면 각각의 task마다 visualization 하려는 정보들도 모두 다르겠죠? 그래서, task 별로 wandb의 visualization project를 만들어 주는것이 좋습니다. (그래야 task 마다 visualization 기록들을 용이하게 관리 할 수 있어요.)
그럼 WandB(=W&B) project를 생성해보겠습니다.
먼저 좌측 상단 "Home" 부분에 "Projects"→"Create new project"를 클릭 해주세요
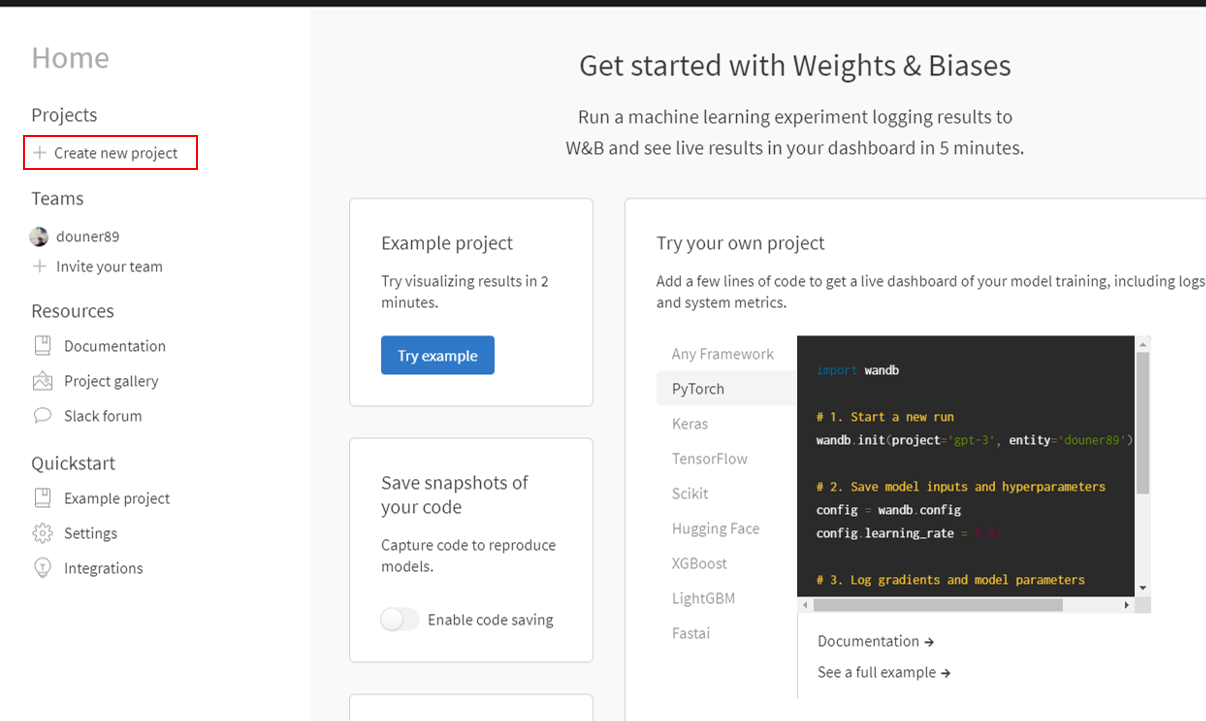
아니면 아래 사이트(="wandb.ai/username")에 직접 접속해서 우측에 있는 "Create new project"를 클릭해주세요.
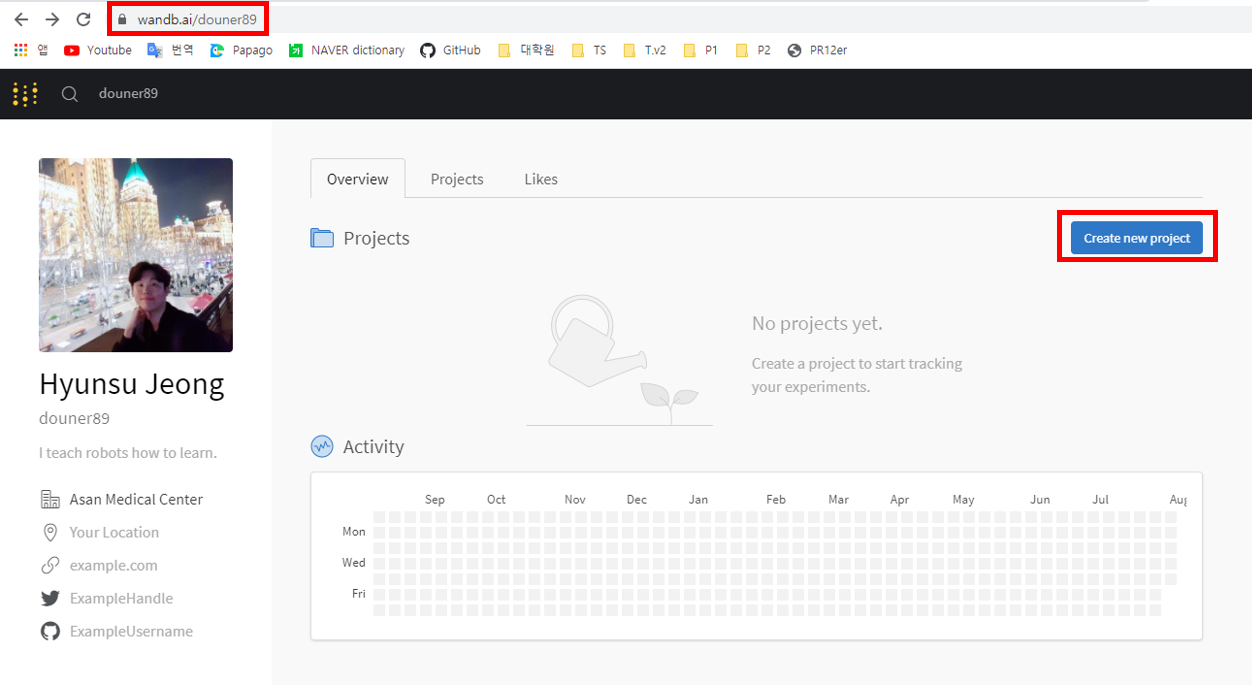
Project name을 설정하고 생성해줍니다.
우선 저는 개인용으로 사용할 거라 "private" 버전으로 만들었습니다.
Project가 생성되면 아래 화면이 출력됩니다.
이제 VS code에서 wandb 패키지로 visualization 관련 코드를 입력하고 실행시키면, 아래 화면에 visualization 결과들이 생성됩니다. 그럼 이제 VS code에서 관련 코드들을 입력해볼까요?
3. VS code에 visualization을 위한 wandb 관련 코드 입력하기
제일 먼저 할 것은 wandb 패키지를 import 시켜주는 것입니다.
현재 "alb_train2.py"에 train 관련 코드가 들어가 있습니다.
("alb_train2.py" 파일은 VS code 상에서 UNet segmentation project에 속해있는데, 해당 project가 base 아나콘다 가상환경 interpreter에 연동되어 있습니다. 앞서 base 아나콘다에 wandb 패키지를 설치했기 때문에 에러없이 import wandb 를 수행할 수 있습니다.)
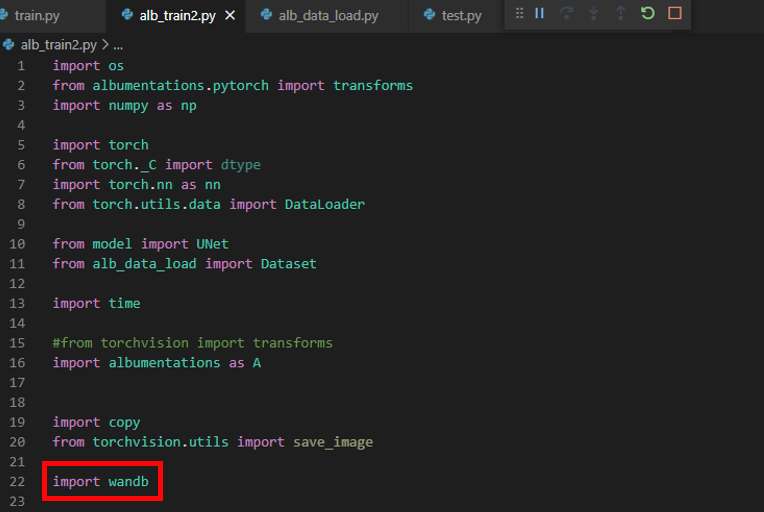
그리고 train_model 함수 부분에 먼저 두 개의 코드를 입력해줍니다.
- wandb.init()
- wandb.watch()
def train_model(net, fn_loss, optim, num_epoch):
wandb.init(project='test', entity='douner89') #추가된 코드
wandb.watch(net, fn_loss, log="all", log_freq=10) #추가된 코드
since = time.time()
best_model_wts = copy.deepcopy(net.state_dict())
best_loss = 100
3-1. wandb.init()
먼저, wandb.init() 함수에 대해 설명해보도록 하겠습니다.
(↓↓↓ wandb.init() API ↓↓↓)
https://docs.wandb.ai/ref/python/init
wandb.init
docs.wandb.ai
먼저 위의 사이트를 접속한 후, 제일 먼저 눈에 보이는 문장은 아래와 같습니다.
"you could add wandb.init() to the beginning of your training script as well as your evaluation script"
위와 같은 설명을 토대로 train 함수 첫 번째 부분에 wandb.init() 함수를 구현해놨습니다.
wandb.init() 함수 인자들은 아래와 같이 설명이 나와있습니다.
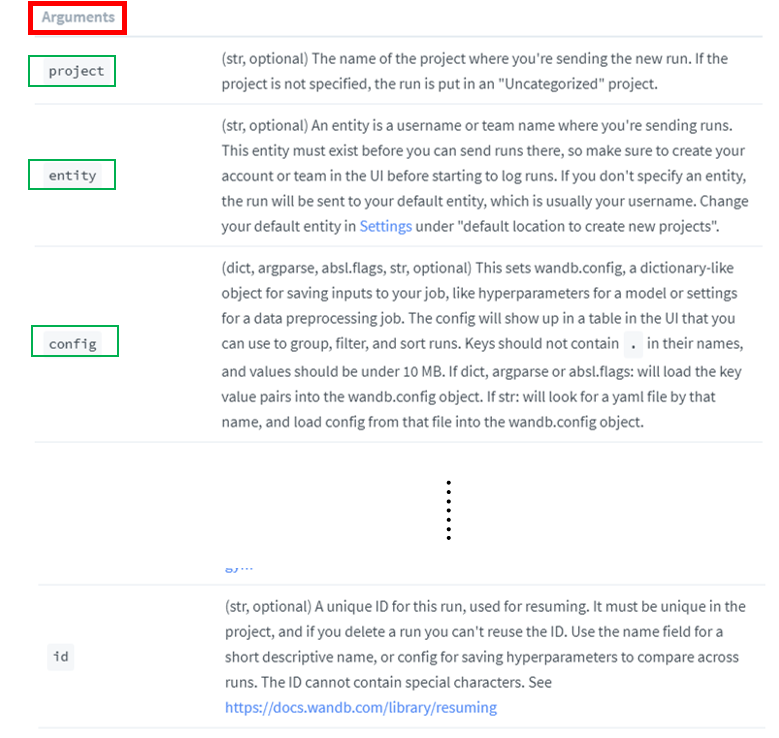
이 중에서 우선 두 가지 argumetns만 설명하도록 하겠습니다.
- project: 앞서 생성한 project 명 (←"그림14" 참고)
- entity: 앞서 계정 생성시 설정한 user name (←"그림14" 참고)
해당 project, entity 명을 제대로 입력 해주어야 연동된 weight and biases 사이트에 정보들이 전송이됩니다.
3-2. wandb.watch()
이번엔 wandb.watch() 함수에 대해서 알아보겠습니다.
(↓↓↓ wandb.watch() API ↓↓↓)
https://docs.wandb.ai/ref/python/watch
wandb.watch
docs.wandb.ai
해당 API reference를 살펴보면 아래와 같은 문구가 나옵니다.
"Hooks into the torch model to collect gradients and the topology."
즉, gradient, topology와 관련 정보를 visualization 해주기 위해 입력해주는 코드라고 하네요.
결국 이 코드로 인해 gradient, topology 값들을 visualization 해줄 수 있게 됩니다.
아래 argument에서 3가지 정도만 설명하겠습니다.
- models: 딥러닝 모델
- criterions: loss function
- log: all이라고 설정하면, gradient, parameters와 관련된 값들을 visualization 해서 볼 수 있습니다.

3-3. wandb.log()
train_model 함수의 "#추가된 코드3" 부분을 보면 "wandb.log"라는 코드를 볼 수 있으실 겁니다.
(↓↓↓ wandb.log() API ↓↓↓)
https://docs.wandb.ai/ref/python/log
wandb.log
docs.wandb.ai
위의 API에서 설명하듯이, wandb.log 함수에 내가 visualization 하고 싶은 argument를 넘겨줄 수 있습니다. 아래 코드에서는 epoch과 training loss를 visualization 해주기 위해 아래와 같이 입력했습니다.
wandb.log({'Epoch': epoch, 'loss': np.mean(loss_arr)})
(※wandb.log() API를 보면 알 수 있듯이 다양한 정보들을 visualization (ex: gradient 'histogram', image, etc...) 를 할 수 있으니 참고해주세요)
# TRAIN MODE
def train_model(net, fn_loss, optim, num_epoch):
wandb.init(project='test', entity='douner89') #추가된 코드1
wandb.watch(net, fn_loss, log="all", log_freq=10) #추가된 코드2
since = time.time()
best_model_wts = copy.deepcopy(net.state_dict())
best_loss = 100
for epoch in range(st_epoch + 1, num_epoch + 1):
net.train()
loss_arr = []
batch_order=0
for batch, data in enumerate(loader_train, 1):
batch_order=batch_order+1
data['label'] = data['label']/255.0
input = data['input']
label = data['label']
# forward pass
label = data['label'].to(device)
input = data['input'].to(device)
output = net(input)
# backward pass
optim.zero_grad()
loss = fn_loss(output, label)
loss.backward()
optim.step()
# 손실함수 계산
loss_arr += [loss.item()]
print("TRAIN: EPOCH %04d / %04d | BATCH %04d / %04d | Batch LOSS %.4f" %
(epoch, num_epoch, batch, num_batch_train, np.mean(loss_arr)))
print("#############################################################")
print("TRAIN: EPOCH %04d | Epoch LOSS %.4f" %
(epoch, np.mean(loss_arr)))
print("#############################################################")
wandb.log({'Epoch': epoch, 'loss': np.mean(loss_arr)}) #추가된 코드3
with torch.no_grad():
net.eval()
loss_arr = []
for batch, data in enumerate(loader_val, 1):
data['label'] = data['label']/255.0
# forward pass
label = data['label'].to(device, dtype=torch.float32)
input = data['input'].to(device, dtype=torch.float32)
output = net(input)
# 손실함수 계산하기
loss = fn_loss(output, label)
loss_arr += [loss.item()]
print("VALID: EPOCH %04d / %04d | BATCH %04d / %04d | LOSS %.4f" %
(epoch, num_epoch, batch, num_batch_val, np.mean(loss_arr)))
epoch_loss = np.mean(loss_arr)
# deep copy the model
if epoch_loss < best_loss:
best_loss = epoch_loss
best_model_wts = copy.deepcopy(net.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val loss: {:4f}'.format(best_loss))
net.load_state_dict(best_model_wts)
return net
4. Visualization 결과보기
다시 weight and biases 사이트 화면으로 돌아오겠습니다.
4-1. wandb.log() 부분 visualization 하기
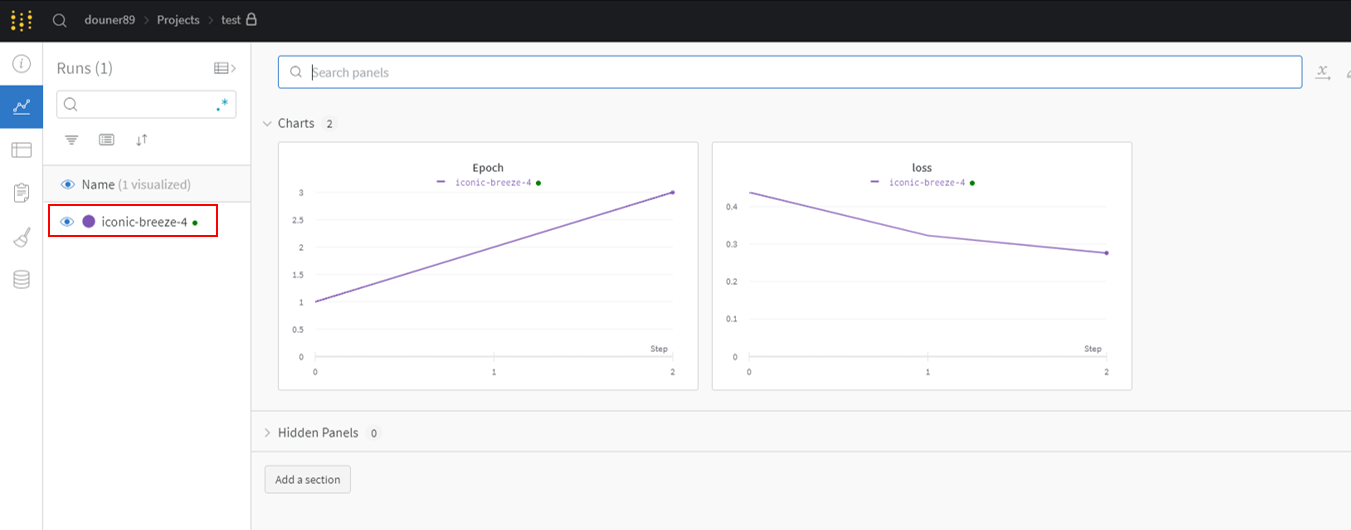
하지만, 코드를 실행시킨 후, charts 부분을 보면 아래와 같이 wandb.log()에 설정했던 log들이 기록됨을 알 수 있습니다. "wandb.log()"에 epoch과 loss를 설정했기 때문에 epoch, loss값이 visualization 되는 것을 볼 수 있습니다.
4-2. wandb.watch() 부분 visualization 하기 (Feat. gradient)
또한, 앞서 "wandb.watch()" 함수를 통해 gradient, parameters 값을 visualization 할 수 있다 언급한 바 있습니다.
먼저, gradient 값부터 확인해보겠습니다.

아래 그림에서 X, Y축의 의미하는 바는 다음과 같습니다.
- X축: epoch (필자의 코드에서는 epoch=30으로 설정되어 있음)
- Y축: gradient 값

앞서 구현한 model의 변수명을 기반으로 해당 위치에 있는 layer에 전파되는 gradient 값을 확인해 볼 수 있습니다.

5 epoch에 마우스 포인터를 올려놓으면 해당 epoch 단계에서 얻는 gradient 값들의 분포 (histogram) 를 알 수 있습니다.

그리고 특정 epoch 부분들의 gradient 값을 디테일하게 보고 싶으면 해당 부분을 drag 하면 됩니다.

또 다른 layer들의 gradient 값을 확인하고 싶다면, 아래 화면의 우측 하단 빨간색 부분을 클릭해주시면 됩니다.
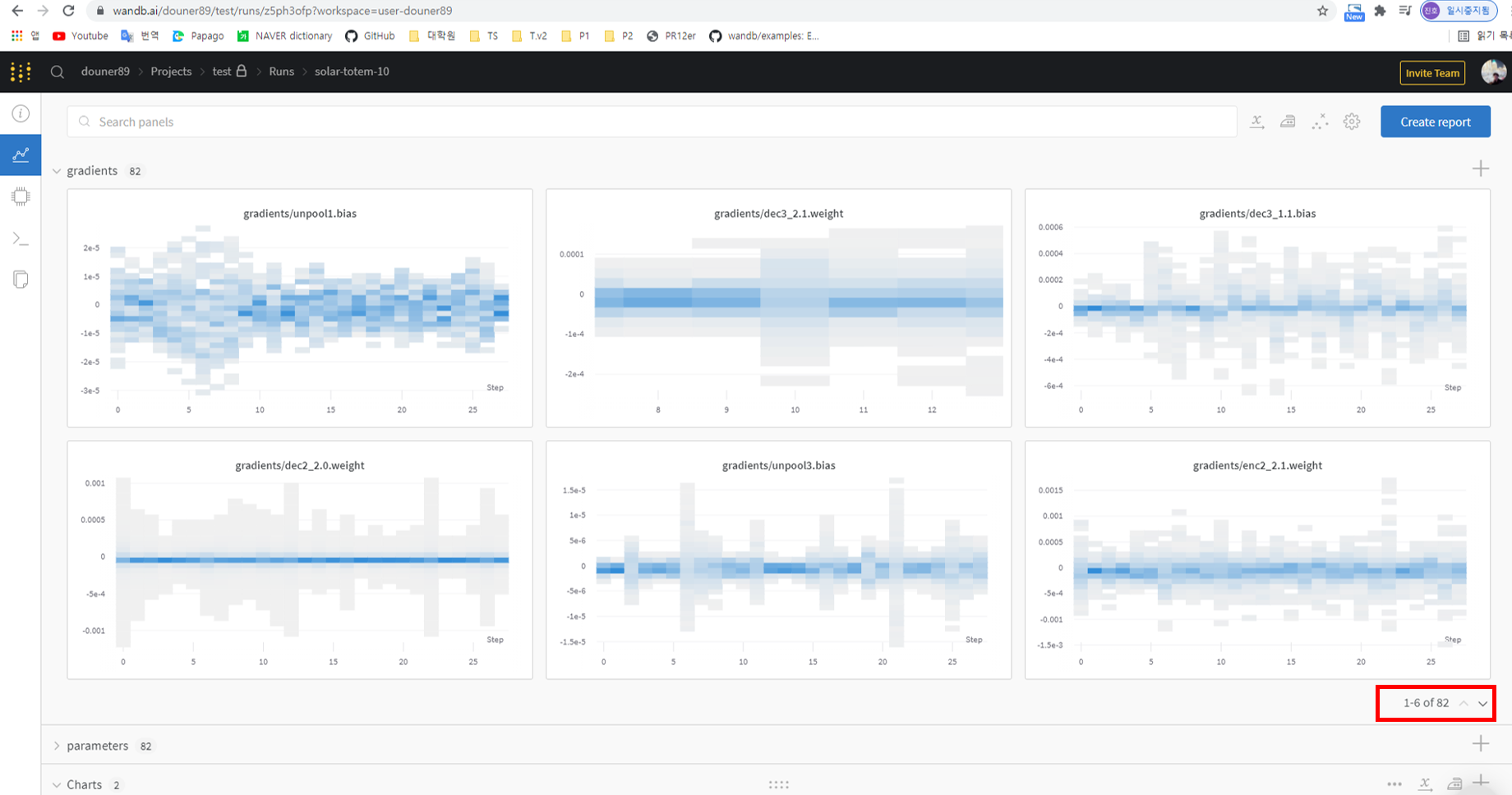
이러한 gradient 값은 다양하게 이용될 수 있지만, 그 중에 가장 대표적인 것이 exploding gradient, vanishing gradient를 확인해보는 것입니다.
예를 들어, conv2 weight의 gradient 값도 대략 10^5로 굉장히 큰데, conv1 weight의 gradient 값이 대략 10^7 이면 exploding gradient를 의심해볼 수 있겠죠?
- 3e+5 → 3*10^5 → 대략 10^5

(↓↓↓ W&B를 이용해 exploding gradient, vanishing gradient를 보여주는 사례 ↓↓↓)
Debugging Neural Networks with PyTorch and W&B Using Gradients and Visualizations on Weights & Biases
by Ayush Thakur — Debugging Neural Networks with PyTorch and W&B Using Gradients and Visualizations
wandb.ai
4-3. wandb.watch() 부분 visualization 하기 (Feat. parameters)
gradient 값 외에, conv filter 값들도 확인해 볼 수 있습니다.
이러한 Conv filter 값들을 통해 유의미한 통계분석도 해볼 수 있겠네요

5. ETC
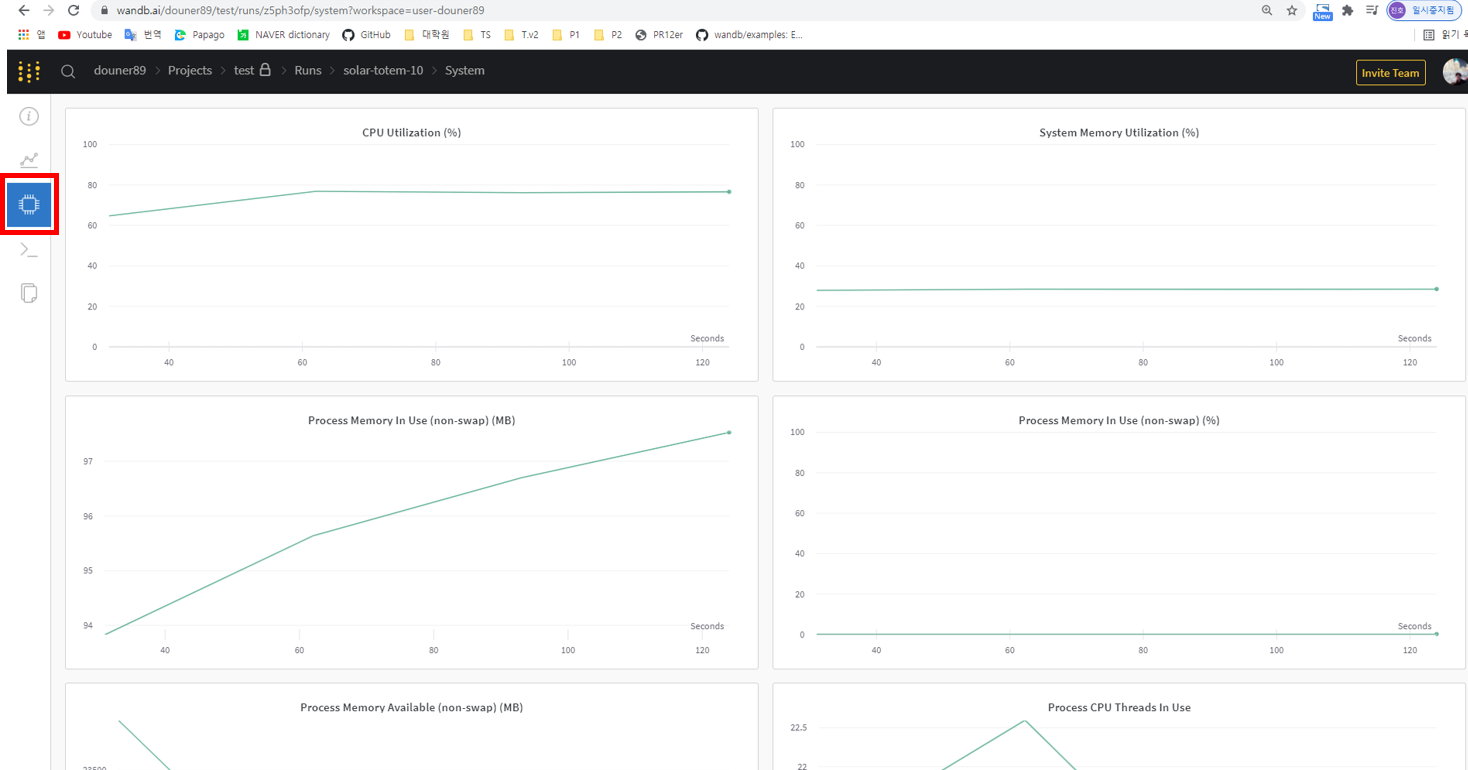
위에서 설명한 것 외에 다양한 정보들을 visualization 해서 볼 수 있습니다.
먼저, 왼쪽 빨간색 박스 부분을 클릭하면 system 즉, hardward (CPU, Memory, GPU) 관련 정보들을 살펴 볼 수 있습니다.
아래 빨간색 네모 박스는 log 관련 정보를 보여주는 곳인데, 학습 시 vs code에 기록되는 log 들을 그대로 볼 수 있습니다.

6. 다른 결과들과 비교하기
실험을 하다보면 다양한 hyper-parameter 조합을 통해 결과를 내야하는 경우가 많습니다.
앞에서는 learning rate 부분을 1e-3으로 설정하고 실행했습니다.
그렇다면 이번에는 le-2로 설정하고 실행해보겠습니다.

왼쪽 빨간색 네모 부분에 새로운 process가 실행되는 것을 볼 수 있고, 이전 실험 결과(="solar-toterm-19")와 중첩으로 visualization해서 볼 수 있으니, 비교가 수월할 수 있겠네요.

하지만 위와 같은 경우 어떠한 hyper-parameter 조합으로 실험한 결과인지 모르기 때문에, 아래와 같이 해당 hyper-parameter 조합에 대한 정보를 process name으로 설정해주면 좋습니다.

위에서 설명한 방법 외에 다양한 visualization 기능들이 있습니다. 예를 들어, line plot, scatter plot 형태로도 보여 줄 수 있고, GAN 관련한 정보들을 visualization 해줄 수 도 있고, hyper-parameter 중에 중요한게 무엇인지도 알려주는 기능도 있습니다. 이와 관련된 부분은 추후 다루도록 하겠지만, 아래 영상을 보시면 상당 부분 혼자서 하실 수 있을거라 생각됩니다.
https://www.youtube.com/watch?v=91HhNtmb0B4
그 외 참고하면 좋을 사이트를 아래 링크해두겠습니다.
https://theaisummer.com/weights-and-biases-tutorial/
A complete Weights and Biases tutorial | AI Summer
Learn about the Weights and Biases library with a hands-on tutorial on the different features and visualizations.
theaisummer.com
https://analyticsindiamag.com/hands-on-guide-to-weights-and-biases-wandb-with-python-implementation/
사실 wandb 패키지의 가장 강력한 기능은 다양한 hyper-parameter 조합을 자동으로 실행해주고 관련 결과들을 visualization 하여 어떤 parameter가 중요한지 보여주는 것입니다. 이러한 기능은 wandb의 sweep을 통해 구현할 수 있는데, 이 부분은 정리가 되는데로 업로드 하겠습니다.
감사합니다.