14. Object Detection Trend (2019~2021.08)
안녕하세요.
이번 글에서는 2019년도 이후 부터 현재 글을 쓰고 있는 시점인 2021년 (9월) 까지의 object detection (based on deep learning) 모델에 대해서 소개하려고 합니다.
현재 제 블로그에 작성한 Object detection 모델은 YOLOv3까지입니다. 그 이유는 제가 2018.05월에 석사 졸업논문을 쓸 당시 주로 사용되던 최신모델이 YOLOv3, SSD, RetinaNet이었기 때문이죠. (RetinaNet은 아직 업로드가 안되어 있는데, 추후에 빠르게 업로드 하도록 하겠습니다!)
그럼 지금부터 2021년까지의 Object Detection model trend 변화를 설명해보도록 하겠습니다.
Note1. 참고로 모델의 trend만 설명드리는거라 디테일한 설명은 하지 않을 예정입니다. 디테일한 기술부분은 차후에 따로 해당 모델에 대한 논문을 리뷰하는 방식으로 업로드 하도록 하겠습니다!
Note2. 이 글에서 trend라고 설명되는 모델들은 저의 주관과 paperwithcode를 기반으로 선택된 모델들임을 미리 말씀드립니다!
1. Object Detection History (From 2013 ~ 2019)
2013년에 최초의 딥러닝 기반 object detection 모델인 R-CNN이 등장했습니다. 이 후, R-CNN 계열의 object detection 모델인 Fast R-CNN, Faster RCNN 모델들이 좋은 성과를 보여주고 있었죠. 그러다, 2016년에는 YOLO와 SSD가 등장하면서 새로운 계열의 딥러닝 기반 object detection 모델이 등장하게 됩니다. 2017년에는 RetinaNet이 등장하면서 높은 성능을 보여주기도 했죠. (Mask-RCNN 모델도 등장하긴 했지만, Mask-RCNN 모델은 segmentation 분야에서 더 설명할 수 있는게 많은 모델이라 여기에서는 따로 object detection 모델의 mile stone으로 언급하진 않겠습니다)

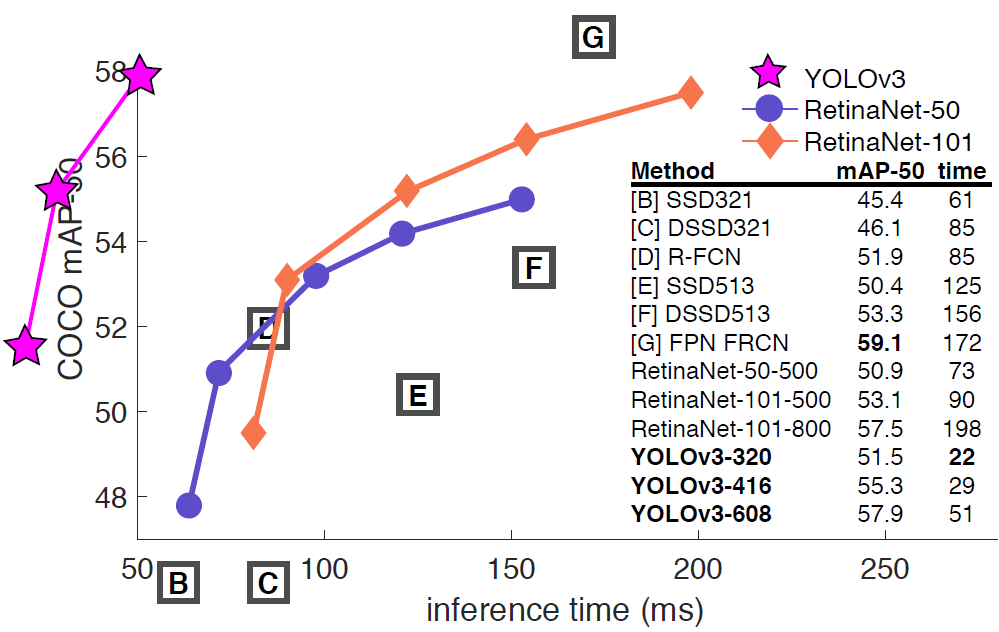
2018.04월 치매환자 행동패턴 분석연구를 하기 위해 이용했던 딥러닝 모델들이 SSD, RetinaNet, YOLOv3 정도가 있었던거 같습니다. (당시에 TF 1.5 버전을 쓰면서 좋아했던 기억이.... )
"그럼 언제부터 새로운 object detection 모델들이 등장하기 시작했나요?"
앞서 언급했던 모델들이 오랜 시간동안 사용되다가 2019년 후반부터 새로운 object detection model이 등장하기 시작했습니다. 2019년부터 CNN 모델에 다양한 변화가 일어나기 시작했는데, 이러한 변화가 object detection 모델에 영향을 주었습니다. (Object detection 모델은 classification task와 bounding box regression task가 결합된 multi-task loss로 구성되어 있기 때문에 CNN의 변화가 생기면 classification task에 영향을 주게 되겠죠? 만약 좋은 영향을 주면 그만큼 object detection 모델의 성능도 좋아질테니까요!)
그럼 지금부터 해당 모델들을 순차적으로 설명해보도록 하겠습니다.
2. EfficientDet (2020 CVPR)
2-1. EfficientNet
2019.03월 arXiv에 EfficientNet이라는 논문이 등장합니다.
- 2019.03.28 arXiv 등록
- 2019 ICML accept
https://arxiv.org/abs/1905.11946
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing n
arxiv.org
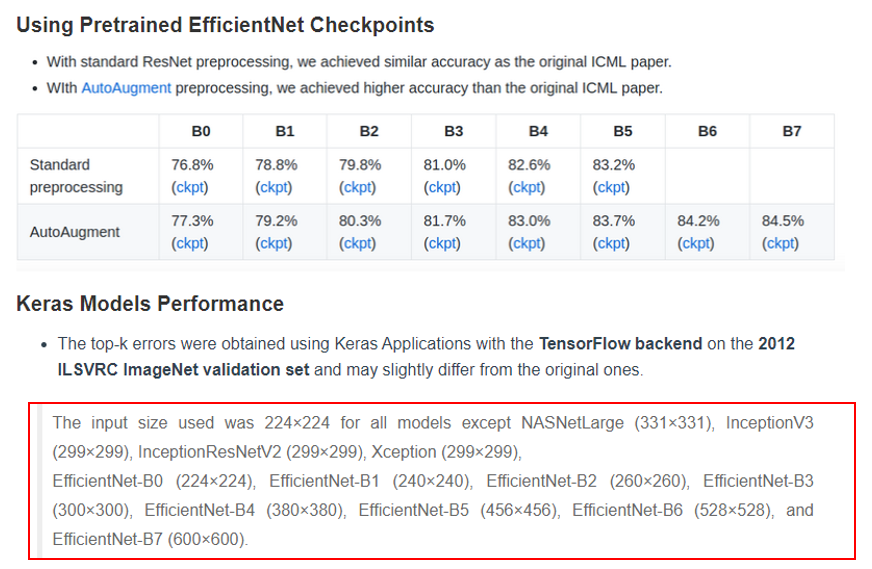
보통 CNN은 224×224 크기로 training&evaluation을 진행했는데, CNN의 입력크기를 키워줄 수록, 성능이 좋아진다는 사실을 알게 됐습니다. 입력 크기를 키워주려면 CNN의 규모(scale) 자체를 크게 키워야 하는데, 어떻게 하면 적절하게 규모를 키워 줄 수 있을지에 대한 방법론이 연구되었습니다. 이 과정에서 AutoML 기법을 도입하여 적절한 CNN 모델을 만들게 되었고, 이것을 EfficientNet이라고 부르게 되었습니다. 드디어 EfficientNet의 등장으로 CNN 모델이 84% top-1 accuracy를 넘어서는 성능을 보여주기 시작했죠
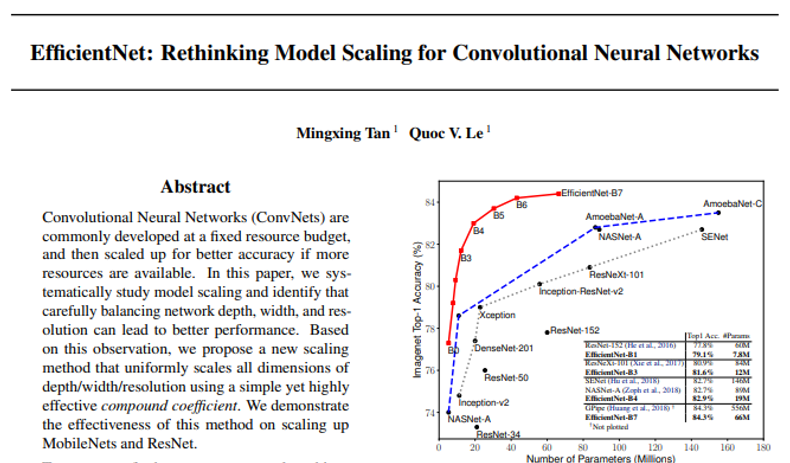
(↓↓↓입력이미지 크기에 따라 Efficient 모델 버전(ex: B0, B1, ..., B7)을 나눈 것↓↓↓)
2-2. EfficientDet
2019.03 EfficientNet 모델이 등장하고 8개월 후, EffcientNet을 backbone (for classification task)으로 한 EfficientDet이 등장하게 됩니다.
- 2019.11.20 arXiv 등록
- 2020 CVPR accept

https://arxiv.org/abs/1911.09070
EfficientDet: Scalable and Efficient Object Detection
Model efficiency has become increasingly important in computer vision. In this paper, we systematically study neural network architecture design choices for object detection and propose several key optimizations to improve efficiency. First, we propose a w
arxiv.org
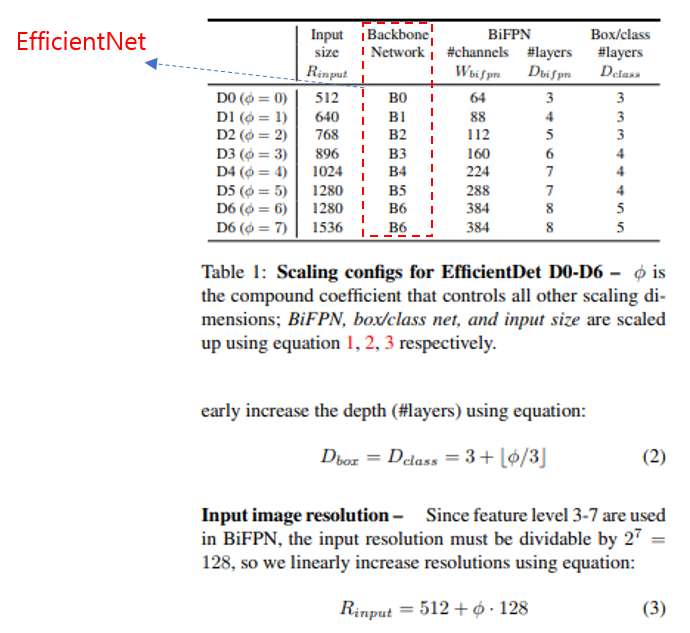
(↓↓↓EfficientDet 논문을 보면 Bacbone Network로 EfficientNet을 사용한 걸 확인할 수 있습니다↓↓↓)
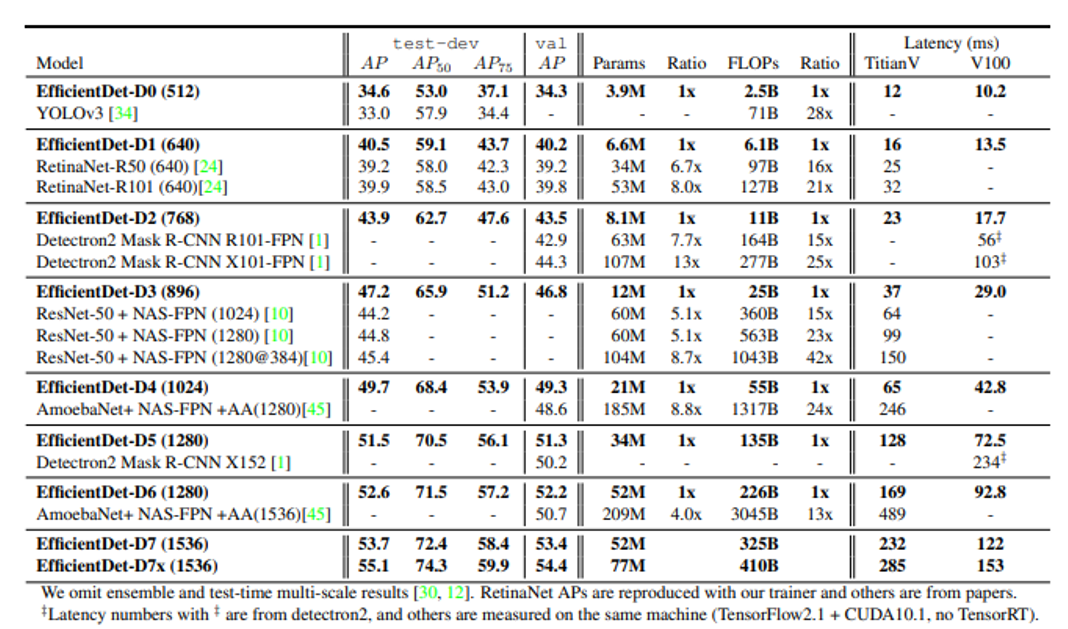
EfficientDet의 등장으로 50 AP넘는 object detection 모델이 등장하기 시작했고, EfficientDet 모델은 2020년 초반까지 object detection SOTA 모델의 자리를 유지합니다.

3. Deformable DETR
기존 object detection은 CNN을 기반으로 다양한 bounding box regression 기법을 연구하는 방향으로 진행되어왔습니다. 하지만, 2020년 초반부터 NLP 분야에서 사용되던 attention기반의 transformer 기법을 object detection에 적용해보려는 시도가 이루어지면서 새로운 object detection 모델들이 등장하게 됩니다.
3-1. Transformer (Feat. Attention)
2017.06월에 Google은 NLP(자연어처리) 분야에서 attention mechanism을 기반으로한 Transformer 모델을 소개합니다.
- 2017.06.12 arXiv 등록
- 2017 NIPS accept

https://papers.nips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
Attention is All you Need
Attention is All you Need Part of Advances in Neural Information Processing Systems 30 (NIPS 2017) Authors Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, Illia Polosukhin Abstract The dominant seque
papers.nips.cc


3-2. DETR
2020.03월에 Facebook은 NLP (자연어처리) 분야에서 사용하던 Transformer 기술들을 CV (컴퓨터 비전)에 적용하기 시작합니다.
- 2020.03.22 arXiv 등록
- 2020 ECCV accept

https://arxiv.org/abs/2005.12872
End-to-End Object Detection with Transformers
We present a new method that views object detection as a direct set prediction problem. Our approach streamlines the detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression procedure or anchor gene
arxiv.org

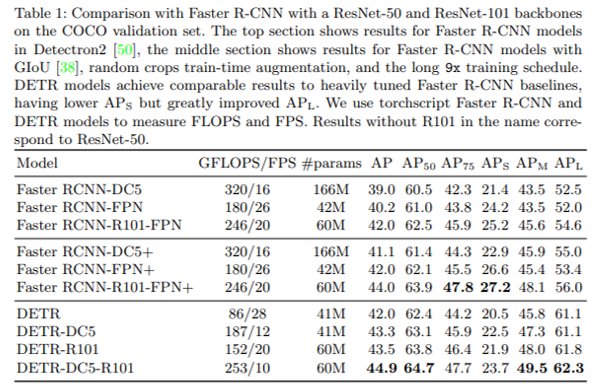
하지만, 성능자체는 기존 object detection 모델의 성능보다 높게 나오지는 않았습니다. 사실 EfficientDet(←2019.11월 출현 & 50 AP)에 비하면 성능이 많이 뒤쳐지는 편이죠. 여기서 인지해야 하는 부분이 DETR에서 transformer를 사용했다는걸 ViT모델을 사용했다는 걸로 착각하시면 안된다는 점입니다. (참고로 ViT 모델은 DETR가 나오고 7개월 후인 2020.10월에 등장합니다. )
3-3. Deformerable DETR
DETR 모델이 등장하고 7개월 후에, DETR 모델의 후속연구로 Deforma DETR가 출현합니다.
- 2020.10.08 arXiv 등록
- 2021 ICLR accept
https://arxiv.org/abs/2010.04159
Deformable DETR: Deformable Transformers for End-to-End Object Detection
DETR has been recently proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance. However, it suffers from slow convergence and limited feature spatial resolution, due to the limitation of Tra
arxiv.org
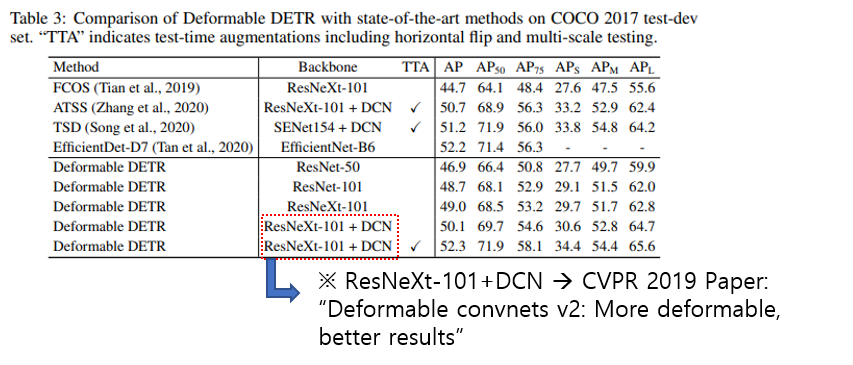
Deformable DETR에서는 deformable attention module을 이용하여 성능을 높이려고 시도했습니다.

Deformable DETR의 성능이 EfficientDet보다 조금씩 더 나은 것을 볼 수 있었습니다. 이것을 통해 Transformer를 CV에 접목하려는 연구가 주목을 받기 시작했죠.
4. YOLOS
2020.10월 ViT 모델의 등장으로 object detection 모델의 backbone을 기존 CNN에서 Transformer 계열로 바꾸려는 시도가 이루어지기 시작합니다.
4-1. ViT
2020.10월 Deformable DETR로 인해 object detection 분야에서 Transformer의 관심을 보이기 시작했다면, 동시에 classification 분야에서는 2020.10월 ViT 모델의 등장으로 Transformer에 대한 관심이 뜨거워졌습니다. (Transformer라는 개념을 처음 소개한 것도 google이고, Transformer를 object detection에 처음 접목시킨 DETR도 google이고, Transformer를 (vision) classification에 처음 접목시킨 것도 google이네요 ㅎㄷㄷ...)
- 2020.10.22 arXiv 등록
- 2021 ICLR accept

https://arxiv.org/abs/2010.11929
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org


하지만, ViT의 단점 중 하나는 모델이 지나치게 크기 때문에 학습을 시키기 위해서 방대한 양의 데이터를 필요로 한다는 점이었죠. (물론 모델이 크기 때문에 transfer learning에 적합하지 않다는 지적도 받았습니다.)

4-2. DeiT (Data-efficient Image Transformer)
기존에 ViT에서 지적된 것 중 하나가 방대한 양의 데이터셋을 필요로 한다는 점이었습니다. Transfer learning 관점에서 보면 pre-training을 위해 방대한 양의 데이터셋이 필요한 것이라고 볼 수 있죠. 이러한 단점을 극복하기 위해 Facebook이 DeiT이라는 classification 모델을 제안하게 됩니다.
- 2020.12.23 arXiv 등록
- 2021 ICML accept

https://arxiv.org/abs/2012.12877
Training data-efficient image transformers & distillation through attention
Recently, neural networks purely based on attention were shown to address image understanding tasks such as image classification. However, these visual transformers are pre-trained with hundreds of millions of images using an expensive infrastructure, ther
arxiv.org
DeiT 모델 구조 자체는 ViT와 유사합니다. 대신, vision transformer 계열의 모델을 학습 시킬 때 기존의 CNN 방식과 다른 학습 기법을 적용했다는 것이 ViT와 큰 차이라고 볼 수 있습니다. 예를 들어, vision transformer 모델에 적합한 augmentation, optimization, regularization 등의 기법을 찾으려고 시도했고, 효율적인 학습을 위해 knowledge distillation 기법을 transformer 모델에 적용 (←Transformer-specific distillation) 하려는 노력도했습니다. (참고로 knowledge distillation을 적용했을 시에 teacher 모델로 RegNet을 이용했다고 하네요)

위와 같은 ViT와 같이 방대한 양의 학습 데이터 없이도 EfficientNet 보다 classification 성능이 좋은 vision transformer 모델을 선보이게 됩니다.

4-3. YOLOS
Note1. 기존에 알고 있는 YOLO 모델 계열과 전혀 관계가 없다는 것을 알아두세요!
2021년에 들어서자 object detection 모델의 backone으로써 vision transformer 계열의 모델을 사용하는 연구가 진행됩니다.
- 2021.06.01 arXiv 등록
- 2021 ICML accept

https://arxiv.org/abs/2106.00666
You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection
Can Transformer perform $2\mathrm{D}$ object-level recognition from a pure sequence-to-sequence perspective with minimal knowledge about the $2\mathrm{D}$ spatial structure? To answer this question, we present You Only Look at One Sequence (YOLOS), a serie
arxiv.org
항저우 대학은 앞서 소개되었던 DeiT이라는 classification 모델을 object detection 모델의 backbone으로 사용하여 YOLOS라는 object detectioin 모델을 만듭니다. 하지만, 기존 object detection 모델에 비해 좋은 성과를 거두지는 못합니다 (오히려 EfficientNet, Derformalbe DETR 성능이 더 좋은 것 같네요).

5. Scaled YOLO v4
YOLO계열의 object detection 모델은 real-time이라는 측면에서 많은 사랑을 받아왔습니다. 하지만, 상대적으로 낮은 AP 성능으로 인해 YOLO v3 이후 많은 외면을 받아오기도 했는데요. 올해 제안된 YOLO 계열의 object detection 모델이 56 AP 성능을 기록하면서 다시 한 번 주목을 받고 있습니다.
5-1. YOLO v1, YOLO v2, YOLO v3
2015년 첫 real-time object detection 모델인 YOLO v1이 출현합니다. 하지만, real-time에 초점을 맞춘 나머지 정확도 측면에서 많은 아쉬움을 주었죠.
- 2015.06.08 arXiv 등록
- 2016 CVPR accept

https://arxiv.org/abs/1506.02640
You Only Look Once: Unified, Real-Time Object Detection
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabili
arxiv.org
그리고, 1년 뒤 YOLO v1의 정확성을 보완한 YOLO v2 모델이 등장합니다. 이때부터 YOLO 계열의 object detection 모델이 많은 연구자들에게 관심을 받기 시작하죠.

https://arxiv.org/abs/1612.08242
YOLO9000: Better, Faster, Stronger
We introduce YOLO9000, a state-of-the-art, real-time object detection system that can detect over 9000 object categories. First we propose various improvements to the YOLO detection method, both novel and drawn from prior work. The improved model, YOLOv2,
arxiv.org
YOLO v2의 개발자 Joseph Redmon은 Ted 나가서도 자신의 모델을 강연하는 등 대중들에게 YOLO 라는 모델을 각인시키는 노력도 합니다.

https://www.youtube.com/watch?v=Cgxsv1riJhI
Joseph Redmon은 YOLO v2가 나온 후 2년이 지난 2018년에 YOLO v3를 보여줍니다.
- 2018.04.08 arXiv 등록
https://arxiv.org/abs/1804.02767
YOLOv3: An Incremental Improvement
We present some updates to YOLO! We made a bunch of little design changes to make it better. We also trained this new network that's pretty swell. It's a little bigger than last time but more accurate. It's still fast though, don't worry. At 320x320 YOLOv3
arxiv.org
YOLO v3는 다른 학회에 제출하지는 않고 Tech Report 형식으로 arXiv에 올리기만 했는데 그 이유는 다음과 같습니다. 사실, Joseph Redmon은 YOLO v3 Tech Report에서도 computer vision 분야에서 object detection 모델을 개발하는 것에 대한 윤리적 책임감을 강조했습니다. 어떤 이유가 결정적이었는 지는 모르겠지만, YOLO v3 모델을 개발하고 2년 후 자신은 object detection 모델을 개발하는 것을 그만두겠다는 트윗을 올리게 되죠. 그 이유는 아래와 같이 군사적 목적으로 쓰이는걸 원치않았기 때문이라고 합니다.

5-2. YOLO v4
2018년 석사시절에 필자는 YOLO v3를 사용할 때, Joseph Redmon의 official site를 이용하지는 않았습니다. (질문을 올려도 답을 잘 안해줬던 기억이...) 이 당시에 Alexey라는 russian reseacher의 github에서 YOLO v3를 자주 이용했습니다.

질문하면 정말 빠르게 피드백 해주어서 연구할 때 많은 도움을 받았던 기억이 있네요...ㅎ (사실, 설치나 코드 파악하기에도 Alexey의 코드가 더 보기 편했던 것 같습니다.)
2020.02월에 Joseph Redmon이 YOLO v4에 대한 개발 포기를 선언하자, 2달뒤 2020.04월에 Alexey가 YOLO v4 모델을 개발합니다.
- 2020.04.23 arXiv 등록
- 2020 CVPR accept

https://arxiv.org/abs/2004.10934
YOLOv4: Optimal Speed and Accuracy of Object Detection
There are a huge number of features which are said to improve Convolutional Neural Network (CNN) accuracy. Practical testing of combinations of such features on large datasets, and theoretical justification of the result, is required. Some features operate
arxiv.org
EfficientDet에 비교하면 아직 아쉬운 수준이었지만, 기존 YOLO v3보다는 더 좋은 성능을 보여주었습니다. 아래 figure1을 보면 GPU V100 모델 기준으로의 높은 FPS 성능을 보여주고 있기 때문에 충분히 낮은 GPU 성능이 장착된 작은 device에 임베딩해서도 사용될 수 있음을 예상 할 수 있습니다.
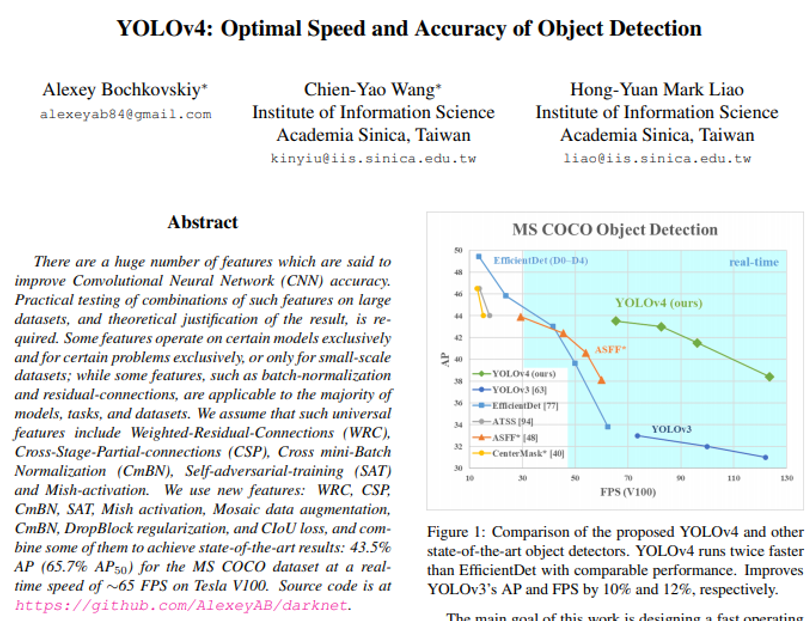
5-3. YOLO v5
YOLO v4라는 논문이 2020.04월에 나온 후, 곧바로 한 달뒤인 2020.05월에 YOLO v5가 나왔습니다. 그런데, YOLO v5는 arXiv와 같은 paper형식이 아닌 blog site에 소개가 됩니다.
https://blog.roboflow.com/yolov5-is-here/
YOLOv5 is Here
State of the art object detection at 140 FPS.
blog.roboflow.com
YOLOv5 Documentation
Introduction To get started right now check out the Quick Start Guide What is YOLOv5 YOLO an acronym for 'You only look once', is an object detection algorithm that divides images into a grid system. Each cell in the grid is responsible for detecting objec
docs.ultralytics.com

AP와 FPS 측면에서 모두 성능향상을 이루긴 했지만, machine learning commuity에서 여러 의견이 있었던 것 같습니다. 특히, YOLO v4의 저자인 Alexey가 성능을 측정하는 것에 대해 여러 문제점을 제기했다고 합니다. (자세한 내용은 아래 사이트의 "Controversy in machine learning community" section에서 확인해주세요!)
https://towardsdatascience.com/yolo-v4-or-yolo-v5-or-pp-yolo-dad8e40f7109
YOLO v4 or YOLO v5 or PP-YOLO?
What are these new YOLO releases in 2020? How do they differ? Which one should I use?
towardsdatascience.com
5-4. Scaled YOLO v4
Alexey는 YOLO v4를 개발하고 7개월 뒤 (2020.11) 후속연구인 Scaled YOLO v4를 발표합니다.
- 2020.11.16 arXiv 등록
- 2021 CVPR

https://arxiv.org/abs/2011.08036
Scaled-YOLOv4: Scaling Cross Stage Partial Network
We show that the YOLOv4 object detection neural network based on the CSP approach, scales both up and down and is applicable to small and large networks while maintaining optimal speed and accuracy. We propose a network scaling approach that modifies not o
arxiv.org
YOLO 모델이 EfficientDet의 AP 성능을 뛰어 넘는 것 까지 보여줌으로써 object detection 모델이 FPS, accuracy 모두 잡을 수 있다는 것을 보여주게됩니다. (YOLO 계열의 모델이 SOTA를 기록할 수 있다는 것을 보여준 것이죠.)
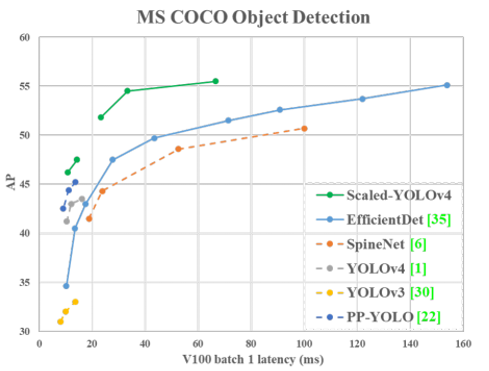

5-5. YOLOR
YOLO v4 때부터 같이 개발에 참여한 팀원들은 Taiwan의 nataional academy인 Sinica academy 소속이었습니다. (참고로 Alexey의 약력은 아래와 같습니다)
[Alexey]
- 2001~2008: MISIS University
- 2019.11~현재: Lead Machine Learning Engineer: Academica Sinica, Taiwan
- 2020.07~현재: Intel Research Engineer
해당 팀원들이 Scaled YOLO v4를 같이 개발 한 후, 6개월 뒤 후속 연구로써 YOLOR 라는 논문을 arXiv에 등록하게 됩니다.
- 2021.05.10 arXiv 등록

https://arxiv.org/abs/2105.04206
You Only Learn One Representation: Unified Network for Multiple Tasks
People ``understand'' the world via vision, hearing, tactile, and also the past experience. Human experience can be learned through normal learning (we call it explicit knowledge), or subconsciously (we call it implicit knowledge). These experiences learne
arxiv.org

논문의 결과나 paperwithcode에서 살펴봤을 때, 모델의 성능 자체는 크게 개선되지 않았던것 같습니다.


하지만, Scaled YOLO v4 모델을 좀 더 representation 관점에서 다양한 해석을 시도하려고 했기 때문에 이를 기반으로 후속 연구들이 나오지 않을까 기대하고 있습니다.
6. Soft Teacher+Swin-L
2021년에 들어서면서 Transformer 계열의 object detection 모델이 CNN 계열의 object detection 모델을 밀어내고 독주하기 시작합니다. 필자가 조사를 했을 당시 (2021.08) paperwithcode에서 object detection SOTA 모델이 Soft Teacher+Swin-L 이었는데, 이 모델 역시 Transformer 계열의 objecte detection 모델이었습니다.
6-1. Swin Transformer
2021.03월에 Microsoft Reseaerch Asia에서 새로운 vision Transformer 모델인 Swin Transformer 모델을 선보입니다.
- 2021.03.25 arXiv 등록
- 2021 ICCV accept
- 2021.10.11~2021.10.17 온라인 개최 예정
- Oral 3 Strong Accepts
https://arxiv.org/abs/2103.14030
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as
arxiv.org
Swin Transformer는 사실 semantic segmentation 분야에 Transformer 모델을 적용시키기 위해 고안되었습니다. Segmentation은 dense prediction을 해야하기 때문에 계산량이 많은데, 기존 Transformer 모델 자체도 계산량이 많기 때문에 sementic segmentation과 Transformer 기술 까지 같이 접목시키면 intractable 문제로 바뀐다고 합니다. 이러한 intractable 문제를 극복하기 위해서 Swin Transformer 논문은 hierarchical feature map와 Shifted window (Swin) block을 이용했다고 합니다.



Swin Transformer 모델은 2021.03월에 58 AP를 기록하면서 object detection SOTA 모델로 등극하게 됩니다.

6-2. Soft Teacher+Swin-L
Swin Transformer 모델이 나온 후 3개월 뒤 후속 연구로써 Soft Teacher+Swin-L 모델이 등장합니다.
- 2021.06.16 arXiv 등록
- 2021 ICCV (제출예정)

https://arxiv.org/abs/2106.09018
End-to-End Semi-Supervised Object Detection with Soft Teacher
This paper presents an end-to-end semi-supervised object detection approach, in contrast to previous more complex multi-stage methods. The end-to-end training gradually improves pseudo label qualities during the curriculum, and the more and more accurate p
arxiv.org
Swin Transformer의 저자 중 한 명이 Soft Teacher+Swin-L 모델 연구 개발에 참여한 것으로 보이고, Micro Soft와 항저우 과기대 (HUST) 팀원들이 같이 참여 한 것으로 보이네요. (올해는 항저우 과기대라는 이름을 더 자주 보는 듯합니다)
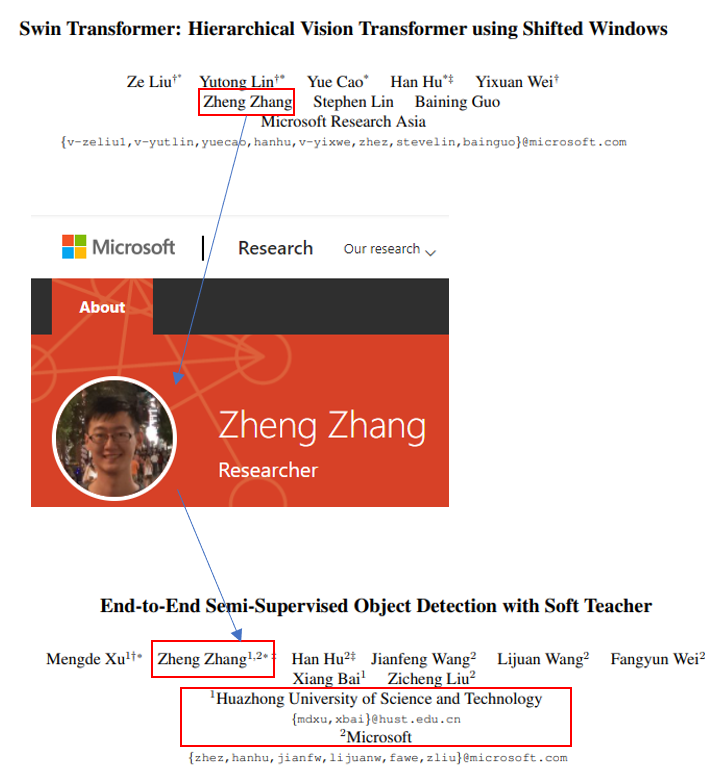
Pseudo label 기반의 Semi-Supervised Learning 방식을 Swin Transformer에 적절히 잘 적용한 Soft Teacher+Swin-L 모델이 제안됩니다

기존에는 Semi-Supervised Learning이 Supervised Learning의 성능을 뛰어 넘지 못했던 것과 달리, Soft Teacher+Swin-L 모델에 Semi-Supervised Learning을 적용했을 때는 더 좋은 성과를 보여준 것이 고무적입니다. 또한, 드디어 60 AP 고지를 돌파한 object detection 모델을 선보이기도 했죠.
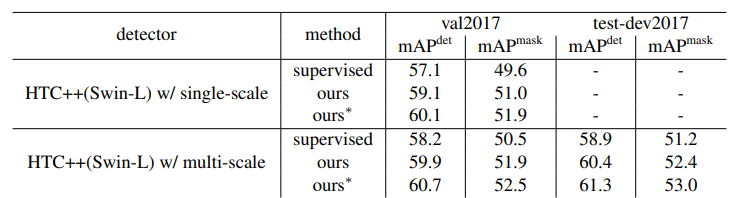
7. ETC
2021.08월을 기준으로 현재 paperwithcode에서 object detection 1, 2, 3등 모델 모두 Swin Tranformer를 기반으로 하고 있습니다.
- DyHead
- 2021.06.15 arXiv 등록
- 2021 CVPR accept
- Dual-Swin-L
- 2021.07.01 arXiv 등록
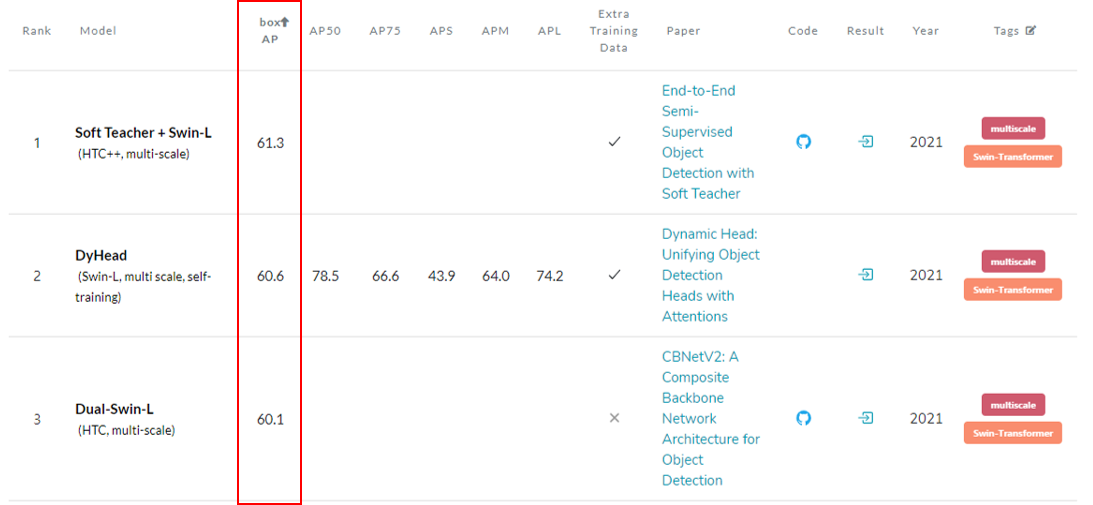
1, 2 3등을 기록한 연구들은 서로 별개의 독립적인 연구였던 것 같습니다.

지금까지 2021.08월까지 object detection 모델의 trend에 대해서 소개해드렸습니다.
앞으로 object detection 관련 글을 쓰게 되면 Swin Transformer 또는 EfficientDet 부터 쓰게되지 않을까 싶습니다.
읽어주셔서 감사합니다!
[Reference Site]
1) Vision Transformer 관련 글
https://hoya012.github.io/blog/Vision-Transformer-1/
Transformers in Vision: A Survey [1] Transformer 소개 & Transformers for Image Recognition
“Transformers in Vision: A Survey” 논문을 읽고 주요 내용을 정리했습니다.
hoya012.github.io