안녕하세요.
이번 글에서는 통계학에 대한 전반적인 틀에 대해서 설명해보도록 하겠습니다.
0. 통계학이란?
0-1. 통계학의 정의
- Statistics is the discipline that concerns the collection, organization, analysis, interpretation, and presentation of data.
- 통계학이라는 개념안에는 데이터를 수집하고, 수집한 데이터를 조직하고, 이러한 데이터를 분석하여, 의미있는 해석을 도출하는 일련의 과정을 의미합니다.

- 오늘날 (수리)통계학에서 배우는 교재들을 살펴보면 "이미 수집되고 조직된(data collection, organization) 데이터"가 있다는 가정하에 시작됩니다.
- 즉, 학교에서는 이미 잘 조직된 데이터(organization)를 기반으로 산술적 방법 (or 확률적 방법)을 기초로 하면서, 해당 데이터를 관찰, 정리, 분석 및 해석하는 방법을 연구하는 수학의 한 분야로써 (수리)통계학을 배우게 됩니다.
※ 오늘날에는 의미있는 데이터 종류를 선별 (ex: 특징값 추출, PCA, 등) 하고, 조직(orgainzation)하는 것이 굉장히 중요해지고 있으니 이러한 분야도 알아두시면 좋을 것 같습니다!
0-2 통계학이 사용되는 이유
- 통계학이 사용되는 이유는 여러가지가 있지만 제가 생각하는 근본적인 이유는 "나의 주장이 통계적으로 합당함을 증명하기 위해서"입니다.
- 기업을 설득하든, 실험연구를 통해 새로운 이론을 증명하든, 우리는 누군가를 설득시켜야하는 상황에 마주치게 됩니다.
- 위와 같이 누군가를 설득시키기 위해선 나의 주장이 보편적으로 타당하다는 것을 증명해야 하는데, 보통 이를 위해서 통계학을 이용하게 됩니다.

- 그렇다면, 통계학은 어떤 과정을 통해 나의 주장이 합당함을 증명할 수 있을까요?
- 이번 글에서는 "나의 주장이 통계적으로 합당하다는 것을 증명"하는 대략적인 과정을 순차적으로 살펴보려고 합니다.
- 가설설정(Statistical hypothesis setting) = 내가 주장하려고 하는 바
- 데이터 수집 (조사: survey)
- 기술통계 (Descriptive statistics; 기술 통계량)
- 추론통계
- 추정
- 가설검정(Statistical hypothesis test)
1. 첫 번째 행위: 가설설정 및 데이터 수집 (조사: Survey)
1-1. 가설설정 (Statistical hypothesis setting)
- 보통 우리가 어떤 주장을 할 때, 가설을 세우게 됩니다. 예를 들어, "A백신은 효과가 있다"라는 가설을 세웠다고 해보겠습니다. 이를 증명하기 위해서는 실험군과 대조군이 있어야 합니다.
- 실험군 (Experimental group): 인위적으로 실험요인을 조작하여 그 결과 어떤 변화가 생기는지 알아보기 위한 집단
- 대조군 (Control group): 변화를 준 실험군과 비교하기 위해 실험 요인에 아무런 변화를 주지않는 집단
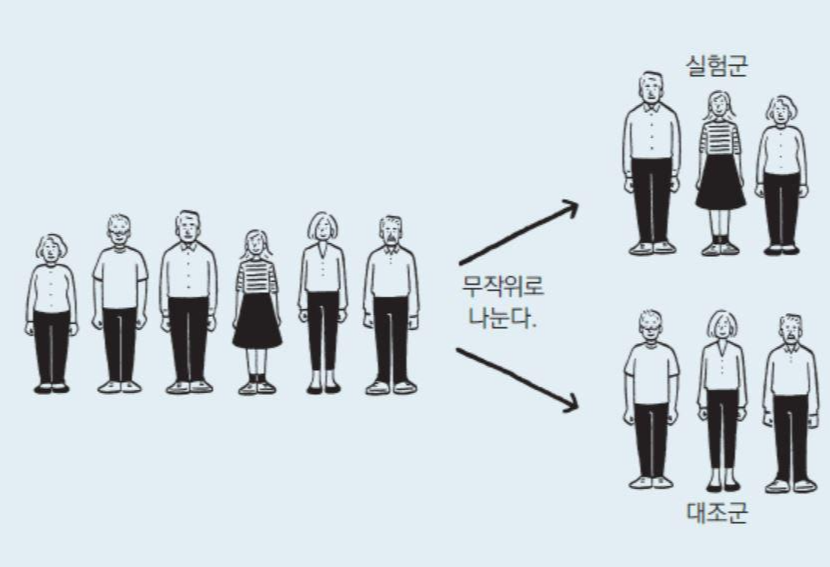
- 그럼 지금부터 A백신을 투여한 실험군과, A백신을 투여하지 않은 대조군을 이용해 실험을 하고, 통계적으로 "A백신이 효과가 있다"는 나의 가설을 증명해보겠습니다.
- 아아!! 잠시만요, 가설 증명을 하기 전에 무심코 지나친 부분이있습니다.
- 바로, 실험군과 대조군 집단에 속한 데이터(실험 대상자)를 모집하는 과정입니다.
- 제대로된 실험을 하기 위해서 전 세계 사람들을 조사해야하지만, 현실적으로 불가능하겠죠?
- 그렇다면, 어떤 방식으로 조사하면 좋을까요? 이에 대한 답을 찾기 위해 '데이터 수집(Survey)'방법에 대해 더 자세히 살펴보도록 하겠습니다.
1-2. 데이터 수집 (survey)
1-2-1. 전수조사 (census) = 전부조사 (complete enumeration)
- 만약 전교생이 200명인 A 초등학교 학생들의 평균 몸무게를 측정한다고 해보겠습니다.
- 200명 정도의 학생 몸무게를 측정하는건 어려운 일이 아니기 때문에 하루면 모두 측정가능하겠죠.
- 위와 같은 경우, 해당 집단의 전(체의)수를 대상으로 조사하는 것이 가능한데, 이러한 조사를 전수조사라고 합니다.
1-2-2. 표본조사 (Sample survey)
- 그런데, 대한민국 국민들의 몸무게 평균을 측정한다고 해보겠습니다.
- 어느 세월에 4천만 국민의 몸무게를 측정할 수 있을까요?
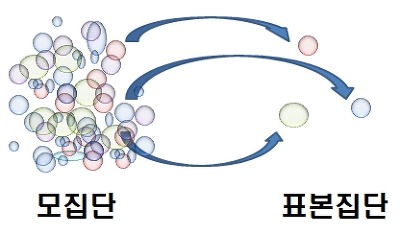
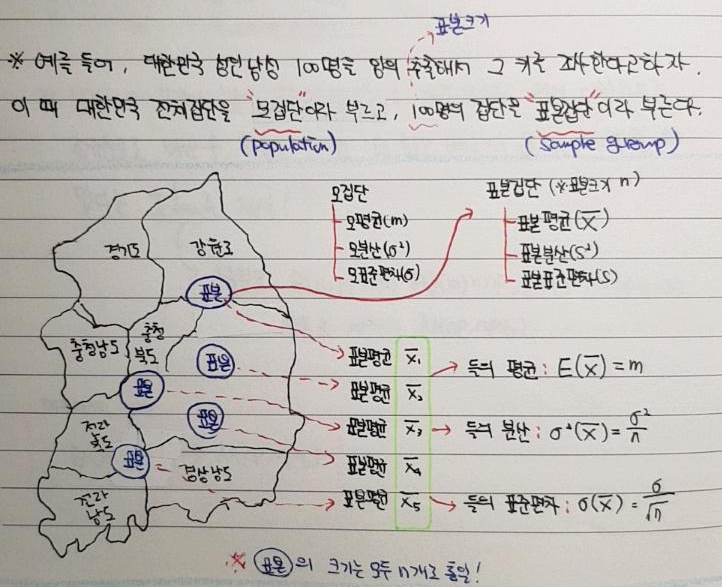
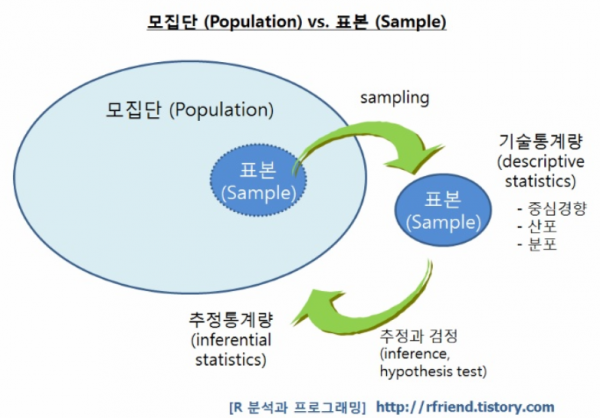
- 대부분 조사를 할 때, 모든 대상을 조사하는 것에는 현실적 어려움이 있기 때문에 모집단(population)으로 부터 표본집단(sampling)을 선별 하게됩니다.
- 모집단(populatioin): 통계적인 관찰의 대상이 되는 모든 데이터들 (ex: 전 국민) → 모집단에서 '모'는 "어미 모"를 의미하는데, 표본집단의 어머니 격이라는 뜻
- 표본(sampling) (집단): 모집단을 대표하는 일부 데이터들 (ex: 각 지방별로 선별된 일부 국민들)→ 표본이라는 것은 본보기라는 뜻을 의미하는데, 모집단을 대표할 수 있는 (본보기가 되는) 집단이라는 뜻 → 모집단의 부분집합
- 표본조사라는 단어에서 '표본'은 앞서 언급한 표본집단을 의미하는 것이고, '조사'라는 용어안에 굉장히 많은 과정들이 함축되어 있습니다. 아래 표본조사에 대한 정의를 살펴보면서 '조사'라는 용어에 어떤 과정들이 포함되어 있는지 살펴보는게 좋을 것 같습니다.
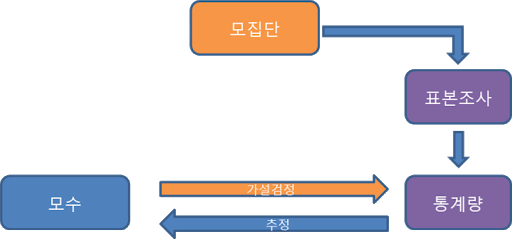
"표본조사란, 모집단(population)에서 표본(sampling)을 뽑아서 표본집단의 통계량을 계산한 후, 표본집단의 통계량을 이용해 모집단의 모수(=모집단의 통계량=parameter)을 추론하고, 이를 이용해 내가 주장한 가설을 통계적으로 검증 (testing)하는 일련의 과정"을 의미합니다.
- 즉, 우리가 배우는 통계학 대부분은 표본조사를 배우는 과정이라고 볼 수 있죠. 그렇다면 지금부터 표본조사가 어떻게 이루어지는지 알아보도록 하겠습니다.
2. 두 번째 행위: 기술통계
- 앞서 말했듯이, 현실적으로 모든 사람들을 조사할 수는 없기 때문에, 대부분 표본을 추출 (sampling) 하여 조사를 실시하게 됩니다.
- 추출된 표본 데이터는 해당 집단의 특성을 규명하기 위해 사용됩니다. 즉, 표본 데이터를 통해 해당 집단을 상징(표현)하는 작업을 하는 것이죠.
- 측정이나 실험에서 수집한 자료(data)의 특성을 규명하는 것도 표본추출한 표본데이터라고 가정합니다. 왜냐하면, 실험에서 수집한 자료가 해당 그룹에 속하는 전세계 모든 대상(데이터)을 포함하진 않기 때문이죠.
- 그런데, 왜 해당 (표본)집단의 특성을 규명해야 할까요? 앞서 언급한 백신 예시를 통해 알아보도록 하겠습니다.
[(표본)집단의 특성을 규명해야 하는 이유 - 예시]
- A백신을 투여했을 때 실험군에서 얻어지는 결과들이 있을 것이고, A백신을 투여하지 않았을 때 대조군에서 얻어지는 결과들이 있을 것입니다.
- 하지만, 실험군에서 얻어지는 결과들이 전부 같지는 않을 것이고, 대조군에서 얻어지는 결과들이 얻어지는 결과들이 전부 같진 않을 것 입니다.
- 예를들어, 실험군 내에서도 백신을 주입했을 때 효과가 강력한 경우, 미세한 경우, 또는 효과가 없는 경우가 있을 것입니다. 그래도, 대체적으로 효과가 있을 가능성이 있겠죠.
- 대조군 내에서도 백신을 주입하지 않았지만 우리도 모르는 현상 때문에 코로나에 면역이 있는 사람들도 있겠죠. 하지만, 대부분 코로나 바이러스에 감염이 될 것 입니다.

- 즉, 실험군과 대조군이라는 집단에 속한 데이터(사람들)를 살펴보면 '실험군 집단은 대체로, 평균적으로 XX하다' or '대조군 집단은 대체로, 평균적으로 XX하다'라는 특성을 알아볼 수 있게 되는 것이죠.
- 결국, "A백신이 효과가 있다"는 나의 가설을 증명하는 과정 속에, 이러한 집단간의 특성들을 비교하는 것이 포함되어 있기 때문에 집단의 특성을 규명하게 됩니다.
- 앞서 언급한 표본집단의 특성을 통계학에서는 통계량이라고 합니다.
- 통계량의 정의는 표본집단의 몇몇 특징을 수치화한 값입니다.
- 표본 데이터를 입력으로 하는 특정한 함수를 계산함으로써 그 값을 계량하게 되는데, 앞서 배운 평균식, 분산식 등이 이에 포함이 되겠죠.

- 앞서 언급한 통계량을 이용해 표본집단을 표현(상징)할 수 있도록 그림으로 묘사(descriptive)할 수 있습니다. 이와 같이 수집한 데이터를 통계량을 통해 묘사하고 설명하는 통계기법을 기술통계(Descriptive Statistic)라고 합니다.
- 기술통계량 종류를 체계적으로 표현하자면 아래와 같습니다. (여기서 나오는 용어들 중 생소한 용어들은 앞으로 게재할 글에서 설명하도록 하겠습니다.)
- 기술통계량
- 집중화경향 (Central tendency): 표본 데이터가 어느 위치에 집중되어 있는가를 나타내는 통계량
- 평균 (Mean)
- 중앙값 (Median): 자료를 크기순으로 정렬할 때, 가장 중앙에 있는 값
- ex) (1, 2, 35, 42, 53) → 35
- ex) (1, 2, 35, 42, 53, 60) → (35+43)/2
- 최빈값 (Mode)
- 산포도 (Degree of scattering): 표본 데이터가 퍼져 있는 정도를 나타내는 통계량
- 최댓값: 데이터에서 가장 큰 값
- 최솟값: 데이터에서 가장 작은 값
- 범위(Range): 최대값 - 최솟값
- 분산
- 사분위편차 (Quartile deviation): 중앙값(Media)을 기반으로 하는 산포도
- Q1: 하위에서부터 25%지점에 있는 요소의 값
- Q2: 중앙값
- Q3: 하위에서 75% 지점에 있는 요소의 값
- 표준오차
- 분포 (Distribution; ex: 확률분포)
- 첨도(kurtosis): 분포의 뾰족한 정도
- 왜도(skewness): 분포의 기울어진 정도
- 집중화경향 (Central tendency): 표본 데이터가 어느 위치에 집중되어 있는가를 나타내는 통계량
※ Box Plot
- 통계량을 이용해 아래와 같이 "Box Plot"을 통해 데이터를 시각화 할 수 도 있습니다. (Box Plot은 중앙값을 기반으로 한다는 것을 알아두세요!)


(↓↓↓Box Plot에 대한 설명↓↓↓)
https://www.youtube.com/watch?v=Wuk17zg-jt8
(↓↓↓Box Plot을 엑셀로 그리는 방법 → 2:30초부터 보시면 됩니다↓↓↓)
https://www.youtube.com/watch?v=fm9zn-MP2As
- 아래 사이트를 가시면 "Box plot"외 더욱 다양한 시각화 종류들을 볼 수 있습니다.
https://kr.mathworks.com/help/stats/statistical-visualization.html?s_tid=CRUX_lftnav
통계적 시각화 - MATLAB & Simulink - MathWorks 한국
다음 MATLAB 명령에 해당하는 링크를 클릭했습니다. 명령을 실행하려면 MATLAB 명령 창에 입력하십시오. 웹 브라우저는 MATLAB 명령을 지원하지 않습니다.
kr.mathworks.com
※ 오늘날의 데이터 시각화 (data visualization) 개념은 아래의 두 개념을 포괄적으로 포함하고 있습니다.
- "데이터 분석 전의 표본집단의 특징"을 시각화 =기술통계
- "데이터 분석 결과"를 시각화
오늘날 Data visualization은 고객을 설득시키는 데 강력한 도구가 되기도 하기 때문에, 데이터 시각화와 관련된 개념들이 주목을 받고 있습니다.
이러한 data visualization을 위해 제공되는 기존 도구 (R programming, Excel 등) 들이 있지만, 최근에 가장 핫하게 이용되는 새로운 도구인 "Tableau"도 있다는 점을 알아두시면 좋을 것 같습니다.
https://www.tableau.com/ko-kr/learn/articles/data-visualization
데이터 시각화 현장 가이드: 정의, 예제, 학습 리소스
데이터 시각화 현장 가이드: 정의, 예제, 학습 리소스
www.tableau.com
https://www.youtube.com/watch?v=YfE9jBq002s
3. 세 번째 행위: 추정(추론)통계 (Statistical inference)
- 기술통계를 통해 통계량 얻었다면, 이번에는 통계량을 통해 의미있는 추론들을 하게됩니다.
- 의미있는 추론을 위해 "통계적 추론(Statistical inference)"이라는 개념들이 이용이 되는데, 먼저 통계적 추론을 구성하는 두 가지 개념들을 하니씩 살펴보도록 하겠습니다.
- 통계적 추론 = 추정 (estimation) + 가설검정 (test of hypotheses)
- 추정 (estimation) = 점 추정 (point estimation) + 구간 추정 (interval estimation)
(↓↓↓추론통계와 관련된 강의 사이트↓↓↓)
https://genome.sph.umich.edu/wiki/Biostatistics_602:_Main_Page
Biostatistics 602: Main Page - Genome Analysis Wiki
Objective In Winter 2013, Biostatistics 602 aims to provide students with a deep understanding of key concepts of statistical inference. Statistical inference methods instruct us how to use data to address substantive questions. In this course, we will stu
genome.sph.umich.edu
3-1. 추정 (Estimation)
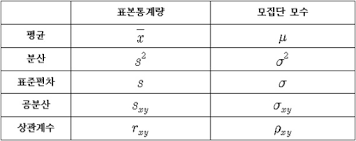
- "1-1-2. 표본조사"에서 언급한 것 처럼, 표본집단의 통계량을 알았으니 이를 기반으로 모집단의 모수(←모집단의 통계량)을 알아보아야 합니다.
- 모집단에서 통계량은 흔히 모수(parameter)라고 합니다. 즉, 표본집단에서의 평균, 분산, 등 개념은 통계량(statistic)이라고 하고, 모집단에서의 평균, 분산 등은 모수라고 부르죠. (모수와 통계량을 표시하는 기호는 서로 다릅니다)

- 추정(estimation)할 때 중요한 포인트 3가지 ( 출처링크)
- 표본집단은 모집단을 대표할 수 있는지?
- 모집단의 일부인 표본을 보고 모집단을 추정하기 때문에 표본의 특성이 모집단을 잘 반영하고 있어야 합니다.
- 표본의 확률분포는 어떠한지?
- 어떤 분포이냐에 따라 추정을 위한 기법이 달라지기 때문에 중요합니다. 다만 표본의 수가 많아질 수록 정규분포에 근사하게 됩니다. (→바로 앞으로 게재될 정규분포관련 글에서 설명할 예정입니다)
- 추정된 결과는 신뢰성이 있는지?
- 추정된 결과를 활용할 수 있는지를 결정하는 요소이기 때문에 중요합니다.
- 표본집단은 모집단을 대표할 수 있는지?
https://kkokkilkon.tistory.com/36
추론통계 - 가설 검정 한번에 정리하기
가설 검정 한번에 정리하기 (1) 추론통계 개요 (2) 가설 검정의 절차 (3) 주요 용어 정리 (4) 가설 검정 예시 (1) 추론통계 개요 추론통계란 모집단에서 샘플링한 표본을 가지고 모집단의 특성을 추
kkokkilkon.tistory.com
3-2. 가설 검정 (새로운 지식을 통계적으로 창출하는 방법)
- 앞서 우리가 세웠던 가설 (=가설설정) 이 통계적으로 합당한지 증명하기 위해 이 가설을 검정(test)하게 됩니다.
- 가설검정이란, 추정을 통해 얻은 모수(parameter)와 관련해 특정한 가설을 세워 놓고, 표본의 정보를 사용해서 가설의 합당성 여부를 판정하는 과정을 의미합니다. ( ← 자세한 설명은 가설검정편과 관련된 글에서 하도록 하겠습니다)
- 통계적 가설은 통계학에서 사용하는 용어로, 하나의 특정 주장을 모수를 이용해 나타낸 형태를 지칭합니다.
- 예를 들어, '미국 성인여자의 평균신장은 170cm이다'는 통계적 가설이 될 수 있습니다.
- 왜냐하면, 평균신장은 모집단 특성을 나타내는 모수의 역할을 수행하기 때문입니다.
- 통계적 가설은 귀무가설(Null hypothesis ,H0, 영가설)과 이와 반대에 있는 대립가설(Alternative hypothesis,H1)로 나타낼 수 있습니다.
- 귀무가설: 연구에서 검증하는 가설 (기호는 H0) → ex) A백신은 효과가 없다.
- 대립가설: 연구자가 연구를 통해 입증되기를 기대하는 예상이나 주장 (기호 Ha 또는 H1) → ex) A백신은 효과가 있다
- 통계학에서 가설을 검증하는 방법은 아래와 같습니다.
- 우리가 주장하려고 하는 '대립가설'과 반대되는 '귀무가설'을 설정하고, 이러한 '귀무가설'이 통계적으로 합리적이지 않다는 것을 증명함으로써, '대립가설'이 통계적으로 합리적이다라는 것을 증명하는 방식입니다. (가설설정 단계에서 했던 것은 대립가설이고, 가설검증 단계에서 하는 것은 귀무가설이라는 점을 알아두시면 좋을것 같습니다!)

- 위 그림에서 귀무가설 기각 여부는 아래와 같은 의사결정을 합니다.
- 대립가설(H1)에 대한 증거가 충분하다면 H0를 기각하고 H1을 받아들인다.
- 기각: 그 내용이 실체적으로 이유가 없다고 판단하여 소송을 종료하는 알 → 통계적 관점에서 봤을 때, 해당 주장이 "통계적으로" 적합하지 않다고 판단 내리는 것
- 대립가설(H1)에 대한 증거가 불충분한 경우 H0를 기각하지 않는다.
- 대립가설(H1)에 대한 증거가 충분하다면 H0를 기각하고 H1을 받아들인다.
- 결국, 새로운 내가 주장한 대립가설이 채택이 되면 "나의 주장(가설)이 통계적으로 합당하다는 것이 증명"되게 됩니다.
3-2-1. 가설 검정 5단계 (←가설검정 파트에서 자세히 다룰 예정입니다)
- 유의수준 결정, 귀무가설(H0)과 대립가설(H1) 설정
- sampling 및 검정통계량의 설정
- 기각역의 설정
- 검정통계량 계산 및 영가설 확인
- 통계적인 의사결정
4. Example (논문: Paper)
- 지금까지 많은 내용들을 적었지만, 통계학을 사용하는 이유는 정말 간단합니다"
"나의 주장(가설)이 보편 타당함을 증명하기 위해서 통계학을 사용한다."
- 우리는 논문을 통해 우리가 세운 가설(연구)이 합리적인지 아닌지 평가받게 됩니다.
- 논문 구성 요소들
- Abstract - Introduction, background, method, experiment, result를 축약해서 설명
- Introduction - 내가 제안한 가설(연구)이 어떤 측면에서 의미 있는지 광범위한 측면에서 설명
- Background - 내가 주장한 가설을 이해하기 위해 필요한 배경지식들 설명
- Method - 가설을 증명하기 위해 자신이 고안한 실험 방식
- Experiment - 실험을 하기 위해 세팅했던 사항들 설명 → 어떻게 실험이 진행됐는지 설명
- Result (and Analysis) - 실험결과가 유의미 했는지 해석 → 내가 실험한 결과를 통계적 (가설검정) 으로 봤을 때, 나의 가설(주장)을 뒷받침 해줄 수 있다고 한다면 (내가 세운 가설 관점에서) 유의미한 실험이 될 수 있음 → 가설검증을 통한 대립가설 채택 과정 → 즉, 유의미한 해석을 하기 위해 통계학이 사용 된 것
- 보통 아래 그림을 예로 들어보자면, 귀무가설을 "dose(약)를 0.5비율로 투약한 것과 dose를 1비율로 투약한 것에 큰 변화가 없다"라고 설정한다면 대립가설은 "dose(약)를 0.5비율로 투약한 것과 dose를 1비율로 투약한 것에 큰 변화가 있다"고 설정 할 것입니다.
- 기술통계를 통해 0.5비율을 투약한 집단과, 1.0비율을 투약한 집단간의 비교가 통계적으로 유의미하게 차이가 있는지 추론통계(추정 및 가설검정)을 통해 판별하게 됩니다. 만약, 유의미한 차이가 있다면, 귀무가설을 기각하고 대립가설을 채택하여 '나의 주장'을 통계적으로 입증하게 됩니다.
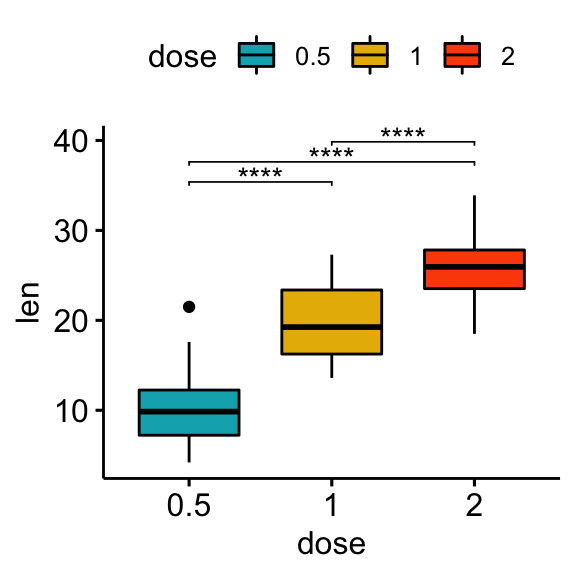
지금까지 통계에 대한 전반적인 가이드라인을 설명해 보았습니다.
그럼, 다음 글부터는 하나씩 자세히 알아보는 시간을 갖도록 하겠습니다.
https://www.youtube.com/watch?v=VM2NUAJUi7s
5. 통계학 기원
아래 영상들은 통계학의 기원을 다룬 영상이니 참고해보셔도 좋을 것 같아 영상 첨부했습니다!
https://www.youtube.com/watch?v=YlGMHmzeW3Y
https://www.youtube.com/watch?v=drhH5Wl419Q