안녕하세요.
이번 글에서는 Machine Learning Operations 의 약자인 MLOps라는 개념에 대해 다루어보려고 합니다.
글의 전개 순서는 아래와 같습니다.
- MLOps란?
- Design
- Model development
- Operations
- 머신러닝 or 딥러닝 연구자들이 MLOps에 관심 갖어야 하는 이유 (Feat. Model development)
- AutoML
[Note]
보통 MLOps라고 표현은 하긴 하지만, 딥러닝 역시 ML에 포함되기 때문에 DLOps라는 개념으로도 이해하셔도 좋을 것 같습니다.
1. MLOps란?
Machine Learning (or Deep learning) 기반의 프로젝트를 시작한다고 하면 크게 세 가지 단계로 나눌 수 있습니다.
- Design
- 산업에서 요구하는 바를 기준으로 문제를 정의합니다.
- 예를 들어, 어떠한 데이터가 필요한지, 어떠한 딥러닝 기술이 중요하게 적용되면 좋은지 등을 의논합니다.
- Model Development
- 우리가 design한 실험을 수행하기 위한 개발단계입니다.
- 산업에서 사용할 수 있도록 제품의 안정성을 충분히 검증(verifying) 해야 합니다.
- 그러기 위해서는 굉장히 다양한 실험을 수행해야 하죠.
- Operations
- 이렇게 개발한 모델을 최종 사용자에게 서비스 하기 위한 단계입니다.
- 우리가 만든 모델을 어느 곳에 배포할 지 (ex: 웹, 핸드폰, 컴퓨터 등) 에 따라서 배포방식이 달라집니다.
- 제공된 제품을 지속적으로 모니터링(관리)해야 합니다.

보통 business라는 영역에 제한하여 MLOps라는 개념을 사용하고는 있지만, 제 개인적인 생각으로는 대학원 연구자들 또한 MLOps에 주목해야 한다고 생각합니다. 지금부터 그 이유에 대해 간단히 설명해보겠습니다.
1-1. Design (Feat. 계획)
병원에서 의료인공지능을 하시는 분들의 가장 큰 장점은 design 단계가 훌륭하다는 점입니다. 아무리 IT 업계에서 의료인공지능을 한다고 해도, 의사분들이 "그건 의학적으로 의미가 없습니다"라고 말한다면 모든 프로젝트가 물거품이 될 가능성이 높지요.
Model development, Operations 단계에서 실패하는 것 보다 Design 단계에서 실패할 때 더 많은 시간과 비용을 손해보게 되기 때문에, Design 설계는 ML 프로젝트에서 매우 중요한 일입니다.
병원에서 딥러닝을 연구하시는 분들이 높은 IF를 갖는 저널에 논문을 내는 이유는 그만큼 design이 훌륭하기 때문입니다. 개인적으로 "딥러닝이 사용되면 의사들의 역할이 없어 질 것이다"라는 말에 동의하지 못하는 이유가 여기에 있기도 합니다. 오히려, design이 잘 되지 않는 딥러닝 연구가 많아 질 수 록 딥러닝 or 기계학습 버블이 생겨날 것인데, 이러한 버블을 걷어내는 역할을 의사분들이 하실 수 도 있겠죠.

사실 이렇게 design을 하는 영역은 학계의 역할이라고 할 수 있습니다. 보통 학계는 오랫동안 domain knowledge를 쌓았기 때문에 어떠한 연구가 유의미한 것인지 판단할 수 있죠. 그리고, 매일 현재 기술들이 갖는 문제를 제기하고 이를 해결하기 위해 연구하기 때문에 최신 기법 솔루션들은 대부분 학계로부터 나온다고 볼 수 있습니다. 또한, 어떤 데이터를 이용하면 좋은지 알고 있으며, 특히 병원 같은 곳에서는 자체 의료 데이터를 갖고 있기 때문에 design 측면에서 제약사항이 상대적으로 작다고 할 수 있죠.
구글, 페이스북, 애플, 마이크로소프트, 엔비디아 등 같은 회사들이 딥러닝에서 좋은 결과를 도출할 수 있었던 것도 모두 학계로부터 도움을 받았기 때문입니다.



1-2. Model development
앞서 실험을 design 했으면 이를 실제로 실현(실험)해야 하는 단계를 거쳐야 합니다.
우리가 흔히 머리속에 그리는 실험은 관찰하는 방법입니다. 실험군 대조군을 설정하고 실험장비를 이용하여 지속관찰하면서 상태를 기록하죠.
하지만, machine learning (or deep learning)은 대부분 컴퓨터(Turing machine)에 기반하여 연구를 진행합니다. 그래서, 실험을 design 하기 위해 필요한 이론적 지식 외에도 컴퓨터를 잘 다룰 수 있는 능력이 필요하죠.
예를 들어보겠습니다. Design 한대로 실험을 하기 위해서는 우선 데이터부터 모아야 할 것입니다. 딥러닝에서는 레이블이 되어있는 데이터를 사용해야하는 경우가 많기 때문에 labelling 프로그램 tool을 잘 사용할 줄 아는 것이 중요합니다. 만약 데이터가 방대하면 분산처리 시스템 (ex: Hadoop, Spark 등) 등을 지원해주는 tool도 잘 활용할 줄 알아야 합니다.
"하지만, 보통 model development 단계에서는 Data를 수집하고 관리하는 단계보다는 아래 그림처럼 model dvelopment, training, devaluation을 하기 위한 별도의 tool들을 사용합니다."
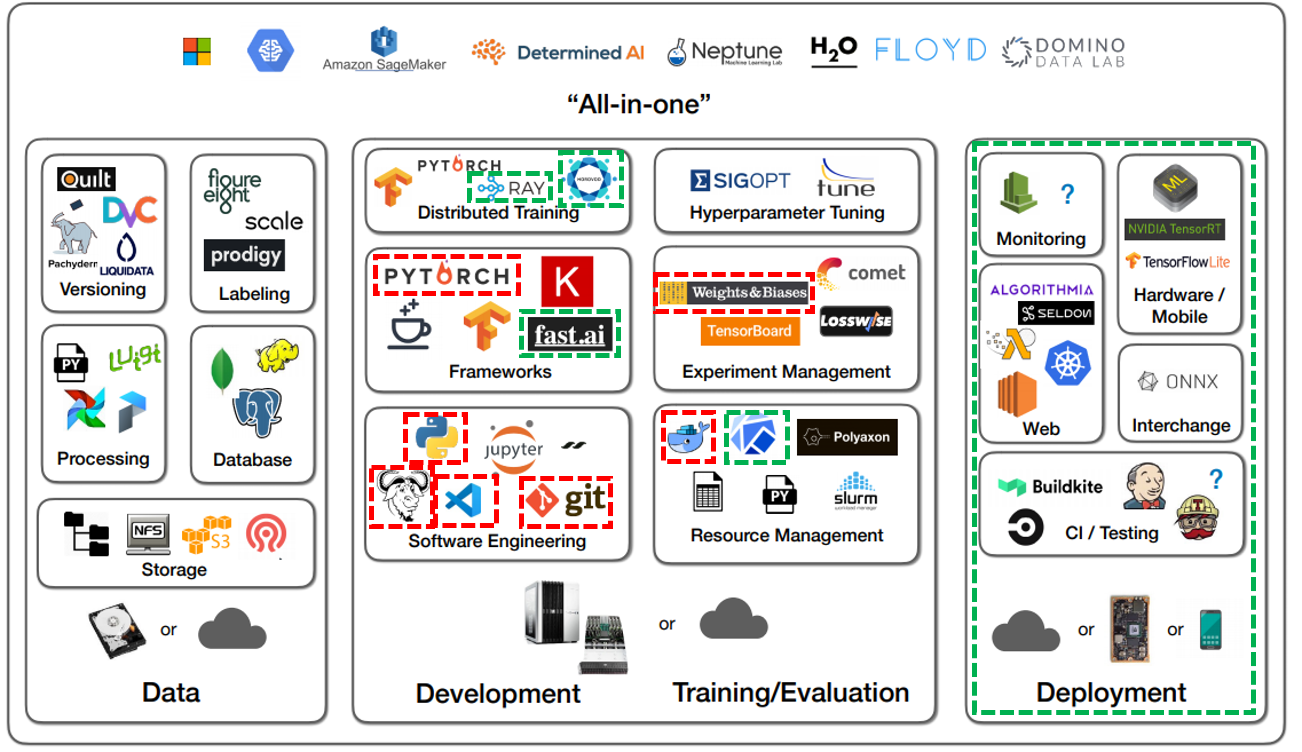
Model development 단계에서 가장 볼 수 있는 것은 frameworks 입니다. 딥러닝 모델을 개발하기 위해서는 딥러닝 라이브러리를 지원해주는 framework를 선택해야 합니다. 예전에는 caffe, theano, keras 등이 사용되었지만, 현재는 pytorch, tensorflow로 통합되고 있습니다. (물론 최근에 keras가 tensorflow로부터 독립하긴했지만....) 최근에는 Fast.ai, pytorch lighting 등 좀 더 간편하게 사용하기 위해 제공되는 framework들이 각광을 받고 있습니다.
또한, 딥러닝은 혼자서 개발하는 것보다 협업하여 개발하는 것이 훨씬 효율적입니다. 그렇기 때문에 최대한 이러한 협업을 지원해주는 software를 잘 사용할 줄 아는 것이 중요합니다. 예를 들어, Github과 같은 software는 여러 사람이 같이 협업할 때 필요한 기능들(ex: 버전관리 기능)을 다수 제공하고 있습니다. 또한, VScode 같이 좋은 기능이 많이 담긴 IDE를 사용하게 되면 github 연동, interactive mode 기능 등을 잘 사용할 수 있기 때문에 개발이 빨라질 수 있습니다.
딥러닝 연구에서 구글, 페이스북, 엔비디아 같은 회사의 리서쳐들이 좋은 성과를 낼 수 있는 이유는 자원을 최대한 잘 활용할 수 있기 때문입니다. Docker, Kubeflow 같은 resource management tool을 이용하면서 자원 관리를 하고, horovod 분산처리 시스템 또는 Mixed precision과 같은 기술 등을 이용하여 자원을 최대한 활용할 수 있도록 하기 때문에 실험을 빠르고 효율적으로 진행할 수 있었죠.
또한 딥러닝 실험들을 관리해주는 weight&biases 와 같은 tool을 이용할 수 있으면 다양한 hyper-parameter들을 automatic하게 search 해줄 수 있으며, 실험 결과들을 매우 용이하게 비교 분석할 수 있게 되죠 (Experiment Management).
"이론적인 design을 하는 것도 매우 중요하지만 이를 구현하고 실험할 수 있는 능력은 또 다른 문제일 수 있습니다. 머리속으로 상상하는 것과 그것을 실현시키는 것이 다른 문제인것 처럼요."
1-3. Operations
MLOps의 마지막 단계라고 할 수 있는 것은 해당 모델을 배포하고 운영하는 단계입니다.
자신의 딥러닝 또는 머신러닝 모델을 웹에 배포할지, 핸드폰 같은 곳에 배포할 지에 따라서 배포 방식도 다양합니다.
보통 배포 및 운영과 관련된 이슈들은 딥러닝 학계에서 주로 신경쓰고 있는 분야는 아닙니다. 주로 computer engineering 분야에서 다루어지는 문제들이죠.
하지만, 최근에는 학계에서도 조차 자신들이 만든 모델을 상용화시키기 위한 노력들을 하고 있습니다. 즉, 딥러닝이 단순히 학문적인 연구에 머무르는 것이 아니라, 자신들이 연구하고 개발한 딥러닝 모델이 어떻게 실세계에 영향을 미치는지 보고 싶은 것이죠. 결국 이를 위해서는 deployment와 관련된 지식들도 습득할 필요가 있습니다. 예를 들어, microsoft의 onnx를 다룰 줄 안다면 배포를 좀 더 쉬운 방법으로 할 수 있겠죠.
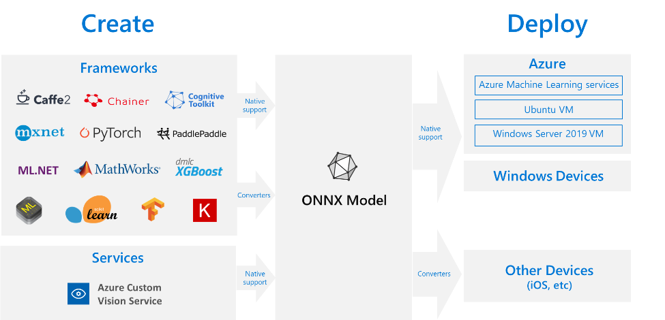
본래 MLOps라는 개념은 아래 논문에서 처음 출현했다고 합니다. 딥러닝을 연구하다보면 딥러닝 학계의 연구들이 굉장히 많은 기여를 하고 있다고 생각합니다. 물론, 딥러닝 기술을 리딩하는 건 학계에서 출발하는게 대부분이죠. 하지만, ML(or DL) system 관점에서 봤을 때, 딥러닝 모델을 연구를 하고 coding을 하여 구현하는 행위가 기여하는 바가 실세계에서 얼마나 많은 부분을 차지하고 있는지 모를 가능성이 큽니다.


"사실 최근에는 연구분야 조차 MLOps를 이용하지 않으면 연구성과를 빠르게 낼 수 없다는 이야기를 합니다. 그럼 지금부터 연구자들이 MLOps에 관심을 갖어야할 이유에 대해서 살펴보도록 하겠습니다."

2. 머신러닝 or 딥러닝 연구자들이 MLOps에 관심 갖어야 하는 이유
결국 machine learning (or deep learning) 제품을 만든다는 것은 위에서 언급한 3가지 단계 과정을 모두 포함합니다.
학계에서는 design, model development, deployment와 같은 단계에 대해 크게 신경쓰진 않았습니다. 보통은 수학, 물리학, 생물학 등의 개념들을 잘 이용하여 새로운 딥러닝 이론을 제시하여 좋은 논문을 내는 것이 목적이었죠. 이러한 연구들이 local 환경에서도 잘 수행되면 복잡한 tool들이 필요가 없습니다. 그냥 데이터를 다운 받고, 딥러닝 모델을 구현하고 학습하고 evaluation하면 그만이죠.
하지만, 산업계에서는 현실적용 가능한 연구를 요구합니다. 그래서, 좋은 논문을 냈더라도 그것이 현실에 잘 적용이 되지 않는다면, 딥러닝 기술들이 거품이라는 이야기를 듣게되죠. 결국, 딥러닝 연구 역시 상용화를 목적에 두어야 더 환영받는 연구분야가 될 것 입니다.
대학원생 역시 졸업을 하고 산업계로 뛰어들 때, 이론만 아는 바보박사 또는 바보석사가 되지 않기 위해 딥러닝과 관련한 다양한 tool에 대해서 알고 있어야 합니다.
2-1. 석사시절 경험 (2017~2018)
2017년 대학원 석사 초기(1학기)에 연구를 하면서 아래와 같은 생각을 했던 적이 있었습니다.
- 딥러닝 이론을 공부하는데도 시간 없는데 MLOps 같은 것 까지 신경쓸 순 없다.
- 학계는 학계가 할 일이 따로 있다. 예를 들어, 학계는 창조적인 이론을 만들고 기존 이론들을 잘 정립하는게 주 된 역할이다.
위와 같은 생각은 석사를 졸업하면서 아래와 같이 바뀌게 됐습니다.
- 구글, 페이스북, 엔비디아, 마이크로 소프트에서 제출한 논문 결과들이 과연 한 번만 테스트 해본 것일까?
- 좋은 결과를 얻기 위해서는 수 많은 실험을 실행할 수 있는 능력을 키워야 하는 것이 아닌가?
- 내가 자원을 더 잘 활용할 수 있었더라면 더 많은 실험을 할 수 있지 않았을까?
- 내가 공부한 내용을 산업계가 관심있어할까?
결국 이러한 질문을 통해서 내린 결론을 다음과 같았습니다.
"실험을 설계(design)할 이론 공부와 실험을 빠르게 실행할 개발(development) 공부를 병행해야겠다"
2-2. 외부연구원 경험 (2020)
2020년 석사시절 지도해주신 분께서 한국교통대 교수님으로 임용되셔서, 한국교통대 외부연구원으로 지내게 되었습니다.
"당시 의료인공지능 관련 연구를 하면서 들었던 생각은 기존의 딥러닝 모델을 실험하고 연구하는 방식에 모순이 많이 있다는 점이었습니다."
특히, 충분한 ablation study를 하지 않고도 논문이 accept이 되는 등 개인적으로 이해가 안가는 부분들이 많이 있었죠.
예를 들어, learning rate, batch size, random seed 등의 hyper-parameter 값에 따라서 실험 결과가 바뀌기도 하는데, 논문에서 단 한번의 실험으로 1%의 성능이 향상되었다, 2%의 성능이 향상되었다는 결론이 받아드려진다는게 이해가되질 않았습니다.
그래서, 종종 "딥러닝 실험을 할 때 필수적으로 해야할 ablation study을 왜 하지 않는것이냐?"라는 질문을 던졌을 때 돌아온 답은 아래와 같았습니다.
"실험할 자원도 없고, 시간도 없으니까요"
이때부터 딥러닝 연구를 위해서 MLOps 지식들이 필요할 수 있겠다라는 생각을 하게 됐습니다. 특히, Model development와 관련된 다양한 toolkit들에 관심을 갖게 되었고, 동시에 아래와 같은 기대를 하게 되었습니다.
"이러한 toolkit들을 잘 이용한다면 탄탄한 실험을 빠른 시간내에 할 수 있지 않을까?"
그래서, MLOps에 기반이 되는 GPU 공부를 시작으로 다양한 toolkit (ex: Github, Mixed precision, Horovod, Weight&Biases, Docker 등) 을 알게 됐습니다.
2-3. 현재 연구실 (2021)
현재는 2020년에 배웠던 몇 가지 MLOps 기법들을 적용해 보면서 연구에 많은 도움을 받고 있습니다.
- Docker: 연구실 내 고사양 GPU 서버를 효율적으로 사용함
- Github: 개별적으로 개발한 후 통합(integration)하여 버전 관리를 진행
- Weigth&Biases: Hyper-parameter tuning, Experiment management를 자동화 하여 실험 및 결과를 빠르고 탄탄하게 분석 (Efficient ablation study)
- Horovod: 다양한 GPU를 이용하여 효율적인 분산처리 시스템을 구축한 후, 학습 속도를 증가시킴
- Mixed precision: 배웠던 GPU 지식을 활용해 문제없이 mixed precision을 적용하여 inference 속도를 증가시킴
(시간이 되는대로 배운 개념들을 잘 글로 정리하고, 비교한 실험 결과들을 설명할 예정입니다.)
3. 내가 생각하는 (연구자들이 특히 관심갖어야 할) MLOps
3-1. GPU 성능의 발전
Samsung, TSMC 의 나노 공정 경쟁이 지속되면서 GPU의 성능은 계속해서 증가할 것입니다. 현재(2021.10월 기준) 최신 GPU RTX 30 series의 나노공정 기술이 8nm인데, 최근(2021.10월 기준)에는 NVIDIA가 TSMC의 5nm 공정을 이용해 새로운 GPU 모델을 생산할 것이다라는 이야기가 돌고 있죠.
만약, 개인 연구자들이 몇 개의 GPU를 살 수 있게 가격이 조정되고, 더 좋은 GPU가 나온다면 GPU, TPU를 극대화 하는 기술들(ex: 분산처리 시스템, Tensor core 이용 기술)을 잘만 이용하면 누구나 좋은 실험을 할 수 있을 것입니다. 예를 들어, 앞으로 horovod와 같이 좀 더 발전된 분산시스템을 잘 이용할 수 있다면 발전된 GPU 자원을 극대화 하여 연구성과를 내는데 큰 일조를 할 수 있을 것입니다.
즉, 우리가 감히 상상도 해보지 못했던 실험들을 할 수 있을 것이고, 방대한 양의 실험들을 통해 좀 더 근거있는 연구 결과를 선보일 수 있을 것입니다. 그런데 지금부터 준비하지 않는다면 결국 나중에 다가오는 기회를 놓칠 가능성이 많아지겠죠.
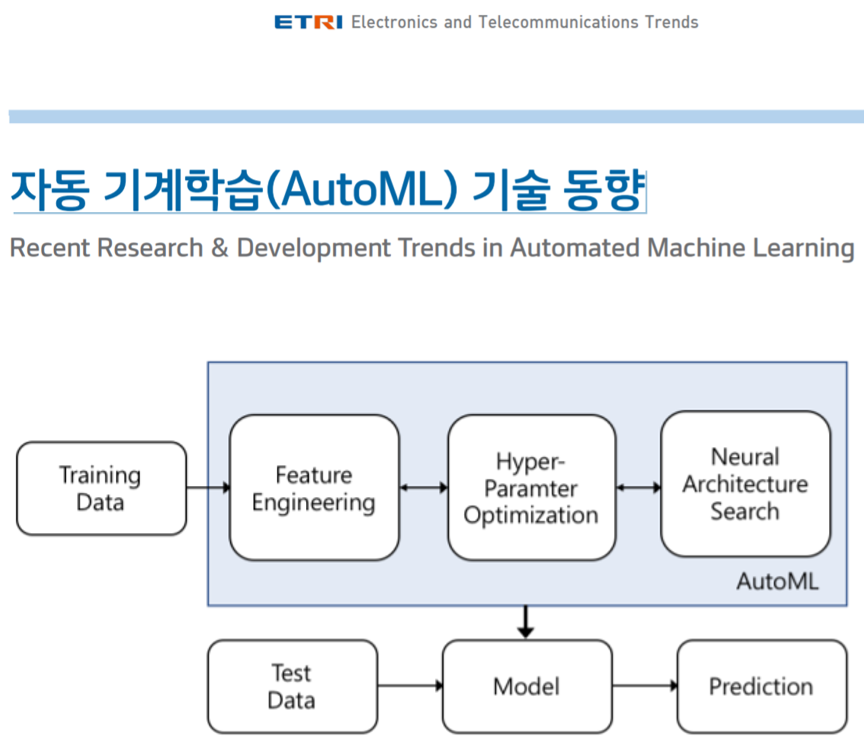
3-2. Auto ML (Feat. Feature Engineering, HPO, NAS)
[3-2-1. NAS (Neural Architecture Search)]
보통 ML (or DL) 연구자들이 하는 많은 일들 중 하나는 새로운 ML(or DL) 모델을 고안하고 구현하는 것입니다. 하지만, 모델을 고안하고 연구하는 것은 쉬운일이 아닙니다. 왜냐하면 특정 모델을 구현하는데 고려해야할 요소도 굉장히 많으며, 해당 모델이 커질 수록 사용해야할 자원도 많아지고 시간도 오래 걸리기 때문입니다. 그래서, 딥러닝이 풀어야할 문제에 최적화 된 모델을 자동으로 만들어주는 NAS라는 기술이 계속 연구되고 있습니다.
[3-2-2. Feature Engineering]
보통 산업계에서는 새로운 ML(or DL) 모델을 고안하지 않는 것 보다, 기존 모델의 성능을 유지보수 하고 빠른 시간내에 향상시키는 방법을 선호합니다. 최근에는 모델링을 중점적으로 하는 model-centric view 연구보다 데이터의 퀄리티를 향상 시키는 data-centric view 연구가 더 많은 관심을 받고 있습니다.
(↓↓↓ Data Centric AI를 강조하는 Andrew ng↓↓↓)
해당내용을 요약하면 아래와 같습니다.
- Model-centric view
- 모델이 좋으면 조금 품질이 떨어지는 데이터로 학습해도 잘 동작한다는 관점
- Good model → Robust for various dataset
- Data-centric view
- 모델링을 하더라도 데이터를 기반으로 만들어야 하는 것이 맞는 방향
- 좋은 모델을 만드는 것보다 좋은 데이터를 만드는 것이 딥러닝 모델 성능에 더 크게 기여
- 대부분의 작업은 데이터를 수집하고 가공하는 일
[생산된 철 제품 중 불량을 검출하는 프로젝트]
- 첫 시도(=baseline)에서는 76.2% 검출율을 보임
- 90% accuracy까지 올리는 것이 목표
- 두 그룹으로 나눠서 프로젝트를 진행함
- Model centric 그룹: 딥러닝 모델 연구
- Data-centric 그룹: data 전처리 (cleansing), 질 좋은 데이터 선별
- Data-centric 그룹에서 성능향상이 뚜렷하게 나타남

앤드류 응은 아래와 같이 딥러닝 연구 트렌드가 변해야 산업의 요구에 빠르게 답할 수 있다고 주장한듯한 느낌을 받았습니다.
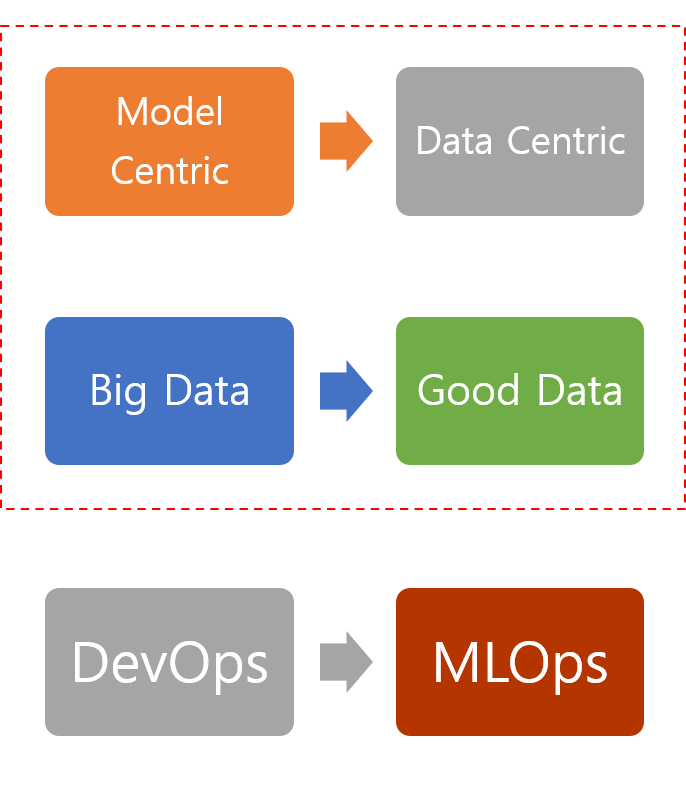
ML에서 data-centric 연구는 feature engineering 분야와 많은 관계가 있습니다.
아래 강의를 보면 raw data에서 어떻게 good data를 선별하는지에 대해 이해하실 수 있으니 참고하시길 바랍니다.
(↓↓↓ 아래에서 4강 수업이 feature engineering, 5강이 Art and Science of ML ↓↓↓)
https://www.coursera.org/specializations/machine-learning-tensorflow-gcp#courses
Machine Learning with TensorFlow on Google Cloud
Google 클라우드에서 제공합니다. Learn ML with Google Cloud. Real-world experimentation with end-to-end ML. 무료로 등록하십시오.
www.coursera.org
(↓↓↓Feature Engineering 관련 설명 ↓↓↓)
https://taeu.github.io/coursera/deeplearning-coursera-featrue-engineering/
[Coursera] 데이터 전처리 : Feature Engineering - Machine Learning with Tensorflow on Google Cloud Platform
목표
taeu.github.io
[Note]
보통 딥러닝에서는 유의미한 feature를 뽑아주는 feature engineering 역할을 DNN이 수행합니다. 아마 이 부분이 MLOps와 DLOps 를 구분짓게 하는 요소가 될 수 있을 것 같네요.

[3-2-3. Hyper-Parameter Optimization (HPO)]
앞서 언급했듯 딥러닝에서는 결과에 영향을 미치는 다양한 hyperparameter들 (ex: batch size, learning rate, random seed 등)이 존재합니다. 그래서 보통 hyper-parameter들에 대한 ablation study가 따로 진행되기도 하죠. 만약에 다양한 hyper-parameter 조합을 학습이 끝날 때 마다 manually 설정해주면 굉장한 시간이 소요될 것 입니다. 예를 들어, 'batch=16, learning=0.1'이라고 설정한 학습이 끝났으면, 'batch=32, learning=0.01'로 설정하고 다시 학습시켜야 하는데, 언제 학습이 끝났는지도 모르고 (물론 요즘은 알람기능이 있긴 합니다만..), 이걸 하나씩 manually 바꿔주는 것도 여간 귀찮은 일이 아닙니다.
또한, hyper-parameter search 방식도 random search, grid search, Bayesian optimization, Tree-structured Parzen Estimators algorithm 등 너무나도 많기 때문에 manually 설정하여 학습한다면 많은 시간이 소요되죠. 그래서, 보통 weight&biases 를 통해 자동으로 hyper-parameter 값을 setting 해주어 테스트하고 결과를 visualization 해주는 tool을 이용하기도 합니다.
지금까지 설명한 내용들을 보통 AutoML이라는 영역안에 포함시키기도 합니다. 즉, AutoML이 잘 작동하면 할 수록 지금처럼 manually 모델링, manually hyper-parameter search 등을 할 필요가 없어지겠죠. 결국, Auto ML에 필요한 software가 MLOps tool로써 나오게 된다면 지금까지 딥러닝을 연구해왔던 방향이 매우 달라질 수 있을 겁니다.
4. MLOps 관련 유용한 자료
UCBerkely 대학은 boot campus를 통해 MLOps를 잘 다루는 것이 ML practioners에게 왜 중요한지 설명하고 있습니다.
https://fullstackdeeplearning.com/spring2021/lecture-6/
Full Stack Deep Learning
Hands-on program for software developers familiar with the basics of deep learning seeking to expand their skills.
fullstackdeeplearning.com
위의 링크는 boot campus에서 다루는 여러 lecture 중 "Lecture 6: MLOps Infrastructure & Tooling" 파트인데, ML practioners에게 아래와 같은 지식이 중요하다는 언급을 하고 있습니다.
- Software Engineering
- ANACONDA
- VScode
- CUDA
- Python
- Compute Hardware
- NVIDIA GPU model
- Cloud Options (ex: AWS, GCP, Azure)
- Resource Management
- Docker
- Kubernetes/Kubeflow
- Frameworks
- Pytorch (lighting)
- Tensorflow
- Keras
- fast.ai
- Distributed Training
- Horovod
- Ray
- Experiment Management
- Weight&Biases
- TensorBoard
- Hyperparameter Tuining
- Weight&Biases: Sweep
- Ray Tune
(↓↓↓ UC Berkeley boot campus lecture note ↓↓↓)
https://fullstackdeeplearning.com/spring2021/lecture-6/
Full Stack Deep Learning
Hands-on program for software developers familiar with the basics of deep learning seeking to expand their skills.
fullstackdeeplearning.com
지금까지 MLOps에 관한 개념 및 개인적인 생각에 대한 글을 작성해봤습니다.
다음 글 부터는 실제로 사용하고 있는 여러 Tool들을 소개해보도록 하겠습니다.
[Reference]
https://fullstackdeeplearning.com/spring2021/lecture-6/
Full Stack Deep Learning
Hands-on program for software developers familiar with the basics of deep learning seeking to expand their skills.
fullstackdeeplearning.com
https://www.coursera.org/specializations/machine-learning-tensorflow-gcp#courses%EF%BB%BF
Machine Learning with TensorFlow on Google Cloud
Google 클라우드에서 제공합니다. Learn ML with Google Cloud. Real-world experimentation with end-to-end ML. 무료로 등록하십시오.
www.coursera.org
https://ml-ops.org/content/mlops-principles
ml-ops.org
Machine Learning Operations
ml-ops.org