표안녕하세요.
지난 글에서 통계학에 대한 제 개인적인 정의를 내린바 있습니다.
"나의 주장(가설)을 보편 타당하게 증명하는 과정"
- 가설설정(Statistical hypothesis setting) = 내가 주장하려고 하는 바 → ex)A백신은 효과가 있다
- 데이터 수집 (조사: survey) → ex)실험군, 대조군 표본조사 표본집단 형성
- 기술통계 (Descriptive statistics; 기술 통계량) → ex) 표본집단으로부터 표본 통계량 획득
- 추론통계
- 추정 → ex) 표본 통계량으로부터 모수(parameter=모집단의 통계량) 추정
- 가설검정(Statistical hypothesis test) → ex) 귀무가설을 통해 내가 세운 (대립)가설이 맞는지 증명
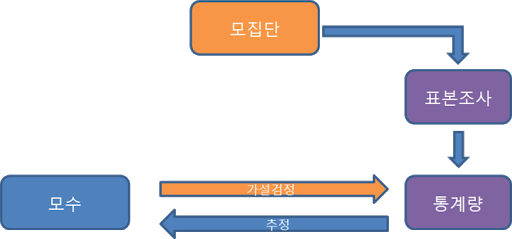
이번 글에서는 표본 데이터들이 수집되었다는 가정하에 표본 데이터(집단)로부터 (표본) 통계량 중 표본평균, 표본분산, 표준오차를 구하는 방법에 대해 알아보도록 하겠습니다.
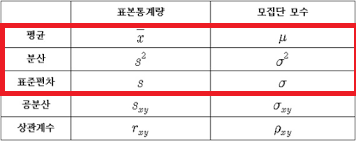
1. 표본평균
- 표본평균을 설명하기 위해 예를 들어보겠습니다.
- 대한민국 국민들의 키 평균을 구하기 위해 지역별로 표본조사한다고 가정해보겠습니다.
- 지정된 지역별로 각각 100명의 사람들을 선별하여 키를 측정하면, 지역별 키 평균이 나오게 됩니다.
- 이때, A지역, B지역, C지역 등등이 있는데, 각 지역이 개별 표본집단들이 됩니다.
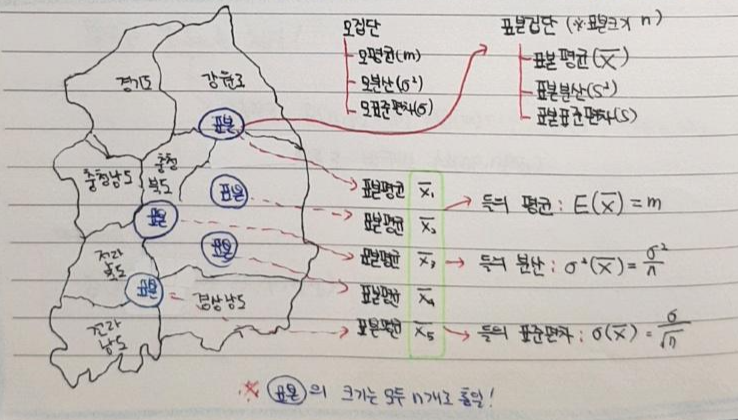
- 위와 같은 예시 들었을 때, 표본 평균은 말 그대로 각각의 표본집단들의 평균을 뜻합니다.

표본평균을 구할 때, 아래와 같이 확률변수 X들을 모두 더 해주는 것으로 되어 있는데, 위에서 가정한 바에 따르면 아래 수식의 \(\X_{1}\) 은 특정 지역에서 키를 측정한 첫 번째 사람이 됩니다.
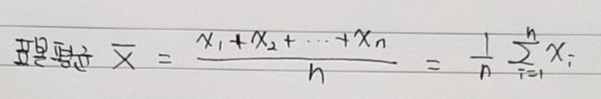
1-1. 표본평균들의 평균은 모평균과 같다 (객관적인 해석 VS 주관적인 해석)
1-1-1. 객관적 해석
- 이 부분은 예시를 통해 설명해보겠습니다.
- 먼저, 한 부족국가에 총 4명인 사람이 있다고 해보겠습니다. 그리고, 이 부족국가의 부족원키는 170, 160, 170, 180이라고 해보겠습니다. → 하나의 부족국가의 부족원들을 모집단이라고 가정합니다.
- 해당 부족원들의 키를 확률변수 X라 하면, X의 확률분포는 아래와 같습니다.

- 확률변수 X의 모평균과 모분산은 아래와 같습니다. → 수학적 확률
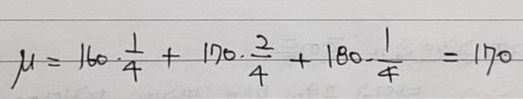
- 이번에는 "부족원={170, 160, 170, 180}"라는 모집단에서 2개씩 표본을 (복원)추출하여 표본집단을 구성한다고 해보겠습니다.
- 첫 번째 뽑는 사람의 키를 \(X_{1}\), 두 번째 뽑는 사람의 키를 \(X_{2}\) 라고 한다면, 표본집단의 경우의 수는 아래의 테이블 처럼 16가지가 됩니다.
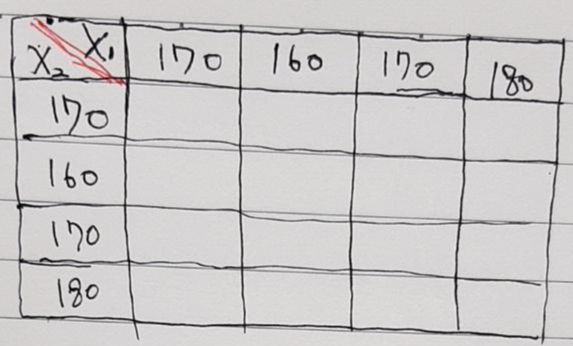
- 그렇다면 이번엔 "표본평균들의 평균은 모평균과 같다"는 것을 아래 순서대로 증명해보겠습니다.

- 개인적으로 중요하다고 생각하는 부분은 아래와 같습니다.
- 위에서 가정한 표본집단의 경우의 수는 모집단에서 2명을 뽑을 때 표현할 수 있는 모든 조합입니다.
- 그런데 현실에서는 이러한 경우의 수를 모두 포함하지 못할 수도 있죠.
- 그렇다면, 어느정도의 경우의 수를 고려해야할까요? → 이에 대한 해답은 '중심극한정리'편에서 하도록 하겠습니다.
(↓↓↓표본평균들의 평군과 모평균이 같다는 것을 설명해주는 유튜브 링크↓↓↓)
https://www.youtube.com/watch?v=Dc_lavvuvko
1-1-2. 주관적 해석
※ 직관적인 이해를 위해 '큰 수의 법칙'과 연동시켜 이해해보려고 했으나, 정확하지 않을 가능성이 높으니 이상하다고 생각하시는 부분은 지적해주시면 감사하겠습니다. (아래 설명에서 나오는 큰 수의 법칙은 아래 "1-2. 큰 수의 법칙 (대수의 법칙: Law of large numbers)" 부분을 참고해주세요)

(무수히 많이 뽑다보면 = K→∞)
- 위의 예시를 통해 크기가 1인 표본평균의 평균은 모집단의 평균과 같다는 것을 알게 되었습니다. 이러한 사실을 기반으로 표본평균의 평균이 모집단 평균과 같다는 사실을 입증해보겠습니다.

(↓↓↓ 표본평균 설명 유튜브 채널↓↓↓)
https://www.youtube.com/watch?v=mUnKM-XAA7g&list=PLmljWRabIwWBxh8V6eIODIz--B802mdLt&index=7
https://www.youtube.com/watch?v=Je62uPML0L0&list=PLmljWRabIwWBxh8V6eIODIz--B802mdLt&index=3
1-2. 큰 수의 법칙 (대수의 법칙: Law of large numbers)
- 큰 수의 법칙을 다루는 이유는 정규분포와 관계가 없지만, 정규분포와 관련있는 중심극한 정리와 혼동하는 경우가 많이 따로 설명을 하려고 합니다.
- 우선 큰 수의 법칙은 '어떠한 확률분포'와도 관계가 없는 개념입니다.
- 확률에는 수학적 확률과 통계적(경험적) 확률이 있는데, '대수의 법칙'은 "통계적(경험적) 확률은 시행횟수가 많아지면 많아질수록 수학적 확률에 가까워진다"는 이론입니다.
- 이에 대한 이해를 위해 두 가지 예시를 설명해 보도록 하겠습니다.
[예시1-동전]
- 동전을 던졌을 때 1이 나올 수학적 확률은 1/6 입니다.
- 하지만, 우리가 6번을 던졌을 때 경험적으로 1이 한 번도 안나올 수도 있죠.
- 이때 시행 6번의 경험으로 1이 뽑힐 확률은 0/6 = 0 입니다.
- 하지만, 대수의 법칙에 따르면 한 120번 정도 던졌을 때는, 18번 정도 나올 것이고, 시행 120번의 경험으로 봤을 때 거의 1/6에 가까워진다고 합니다.
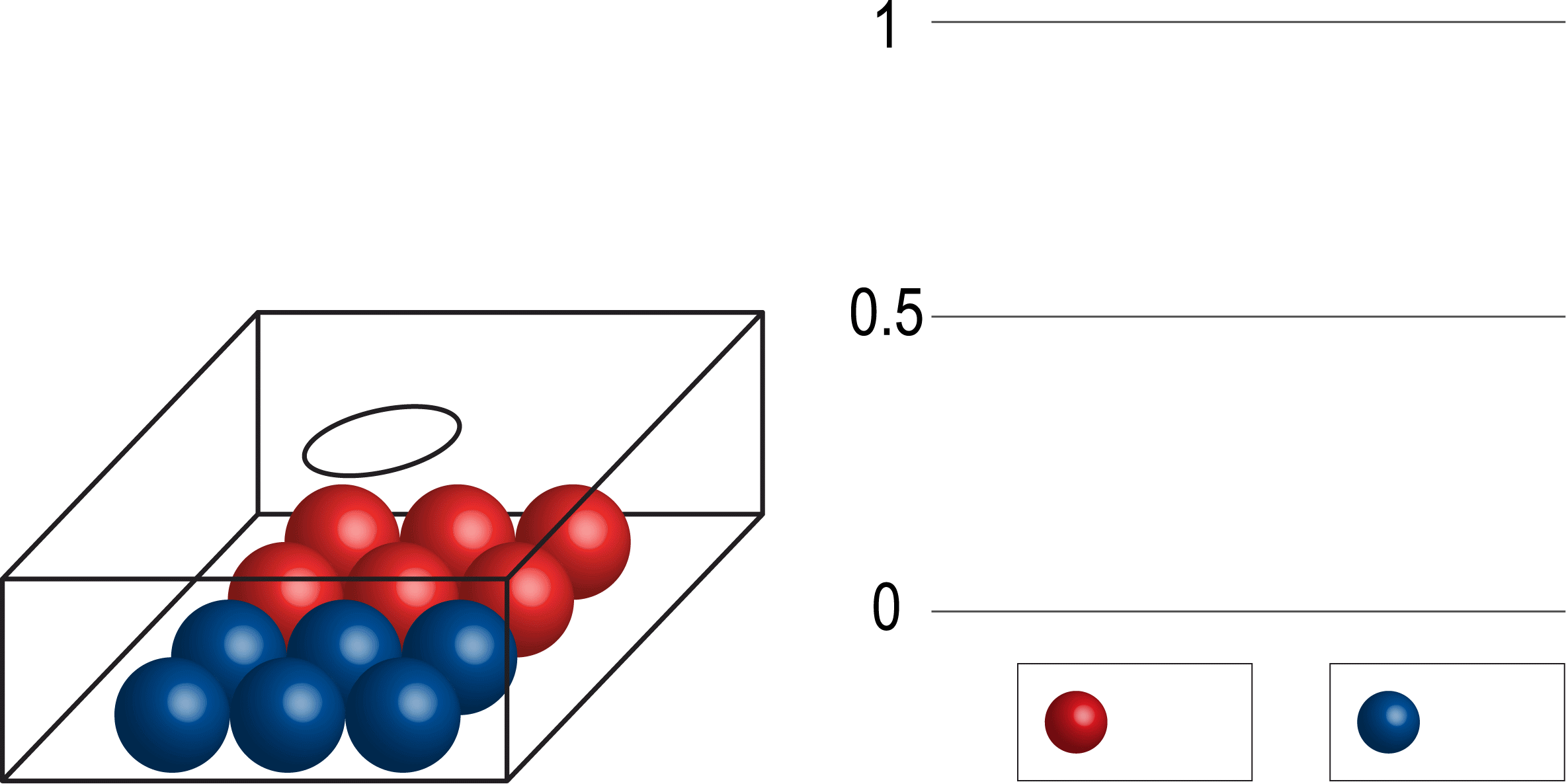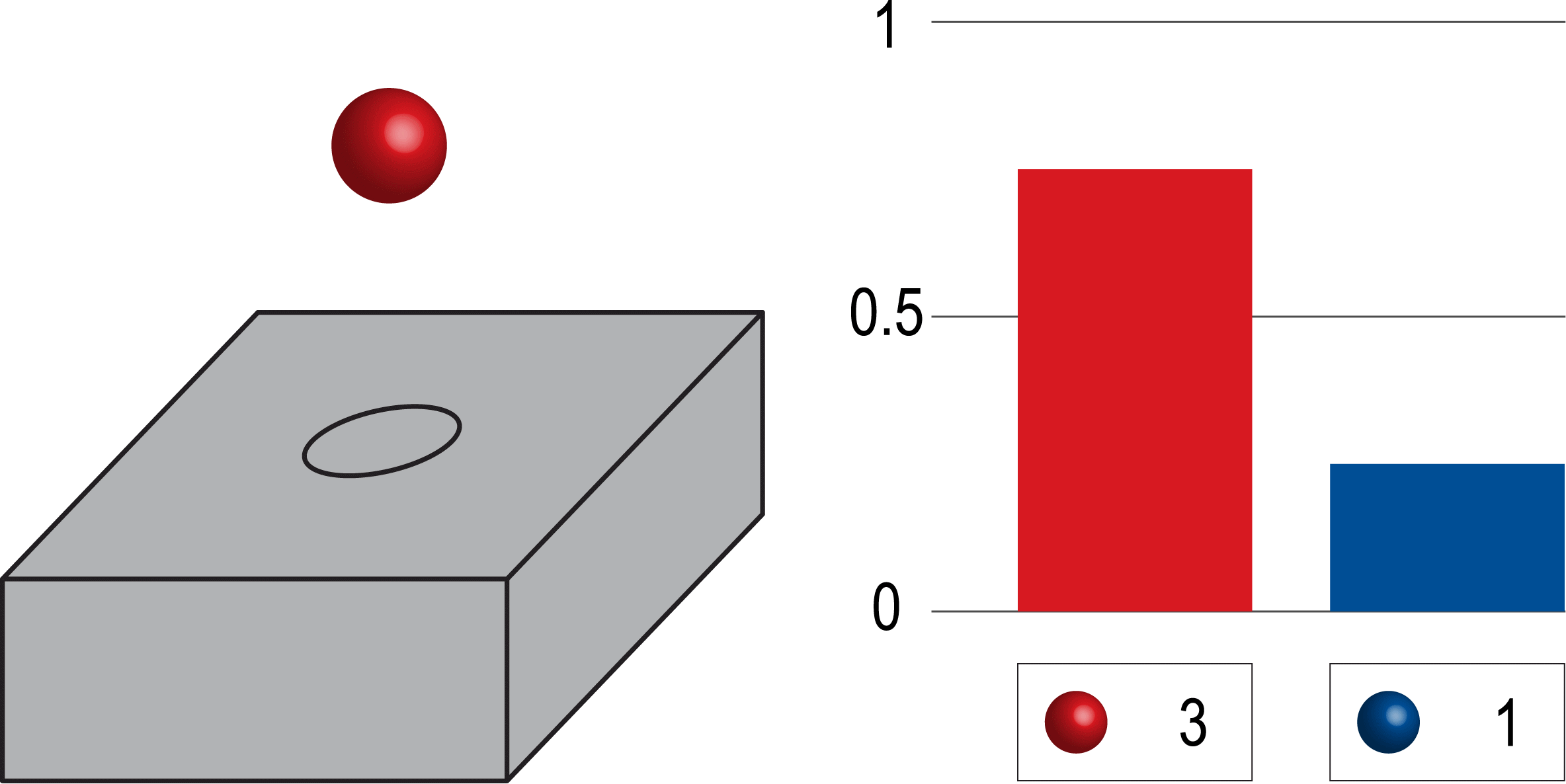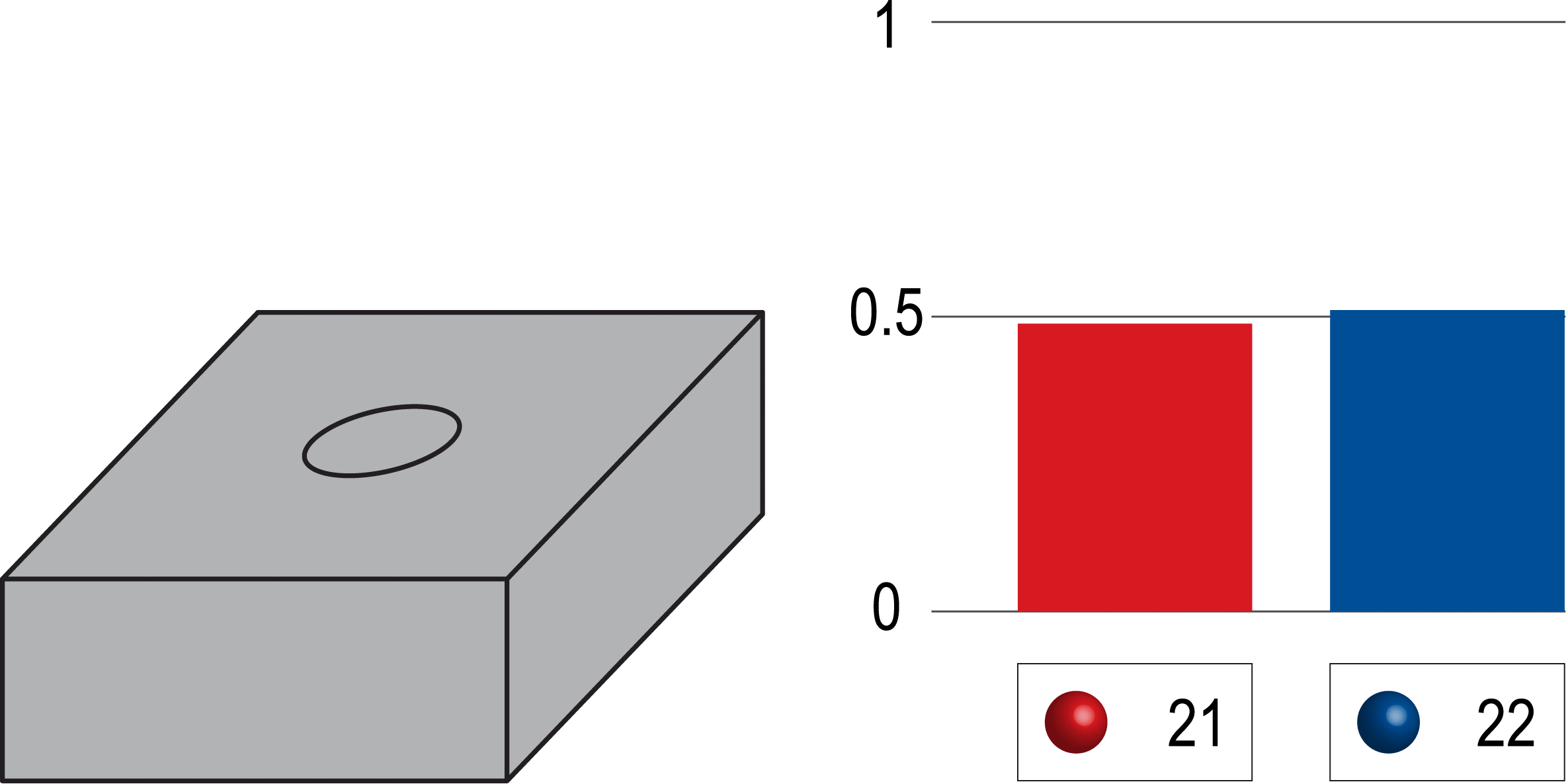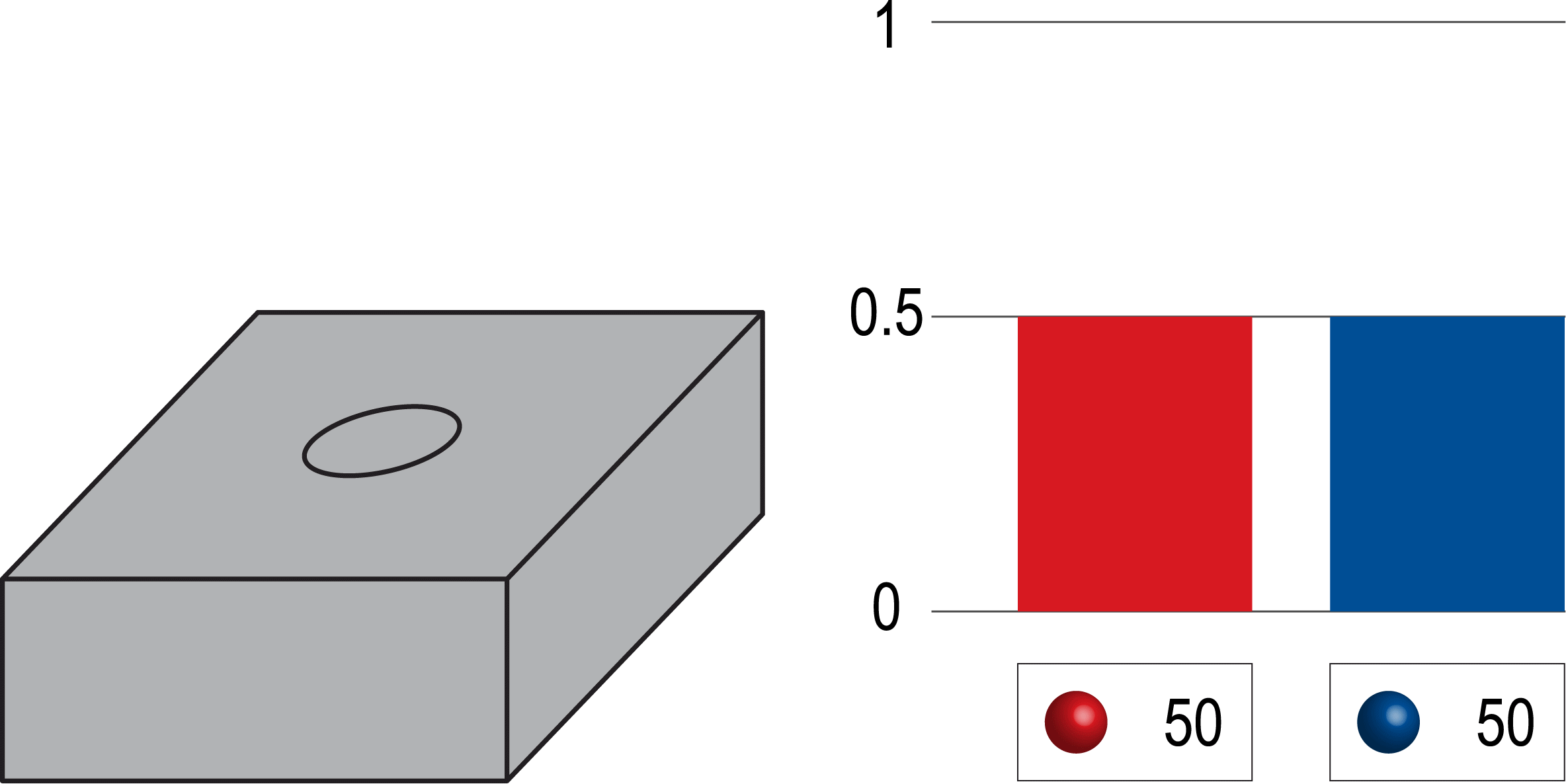
[예시2-상자]
- 아래 상자에 파란공 6개, 빨간색공 6개가 있다고 가정해보겠습니다.
- 해당 상자에서 파란공이 뽑힐 확률은 6/12=1/2, 빨간공이 뽑힐 확률은 6/12=1/2 입니다.
- 하지만, 실제로 4번 정도 뽑아보면 파란색 공이 뽑힐 확률과 빨간색 공이 뽑힐 확률은 각각 다릅니다.
- 그런데, 시행횟수를 100번 정도 늘리면 결국 파란색 공이 뽑힐 확률과 빨간색 공이 뽑힐 확률이 상자안에서 빨간색, 파란색 공을 뽑을 수학적 확률에 근사하게 된다고 합니다. → 이것을 큰 수의 법칙이라 합니다.
(↓↓↓클릭해서 보세요!↓↓↓)
- 큰 수의 법칙을 다른 관점에서 보면, "표본집단의 크기가 커지면 그 표본평균이 모평균에 가까워진다"는 말과 같습니다.
- 예를 들어, 대한민국 국민 4천명(=모집단) 중 선별된 100명의 키 평균과 천만명의 키 평균을 비교해보면, 천만명을 선별했을 때 측정된 평균 키가 대한민국 국민의 전체 평균과 더 근접할 것 입니다.
1-1. 수학적 정의
- 지금까지 설명한 '큰 수의 법칙'을 수학적으로 정의하면 아래와 같습니다.
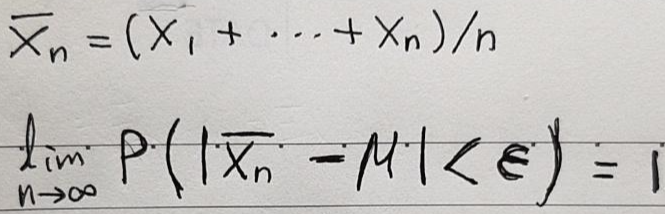
- 위의 수식에 대한 예시를 보여드리겠습니다.
- 표본의 크기인 n이 많아질 수록 경험적으로 수학적 확률에 근사합니다 (by 주사위 예시)

- 즉, 큰 수의 법칙 수식을 다시보면, 시행(표본)횟수가 많아질 수록 통계적 평균과 수학적 평균의 차이가 매우작을 확률(=입실론일 확률=0.00000000001)이 100%라는 의미를 내포하고 있습니다.
(↓↓↓ 대수의 법칙을 보험에 적용한 사례↓↓↓)
https://www.youtube.com/watch?v=XrpoHF8JZXs
2. 표본평균의 분산
- 표본평균의 분산은 모분산을 n으로 나눈 것과 같다. (아래 Notation은 위에 적어놓은 표본평균의 평균에서 설명한 notation을 기반으로 설명했으니, 꼭 표본평균의 평균을 읽고 보시는걸 추천합니다)

(↓↓↓ 표본평균의 분산 설명↓↓↓)
https://www.youtube.com/watch?v=WfiRjHATlrg&list=PLmljWRabIwWBxh8V6eIODIz--B802mdLt&index=5
3. 표본분산와 자유도(degree of freedom)
- 앞서 표본평균과 모평균을 구하는 수식이 동일한 것을 알 수 있었습니다.
- 그렇다면, 모분산을 구하는 수식과 표본분산을 구하는 수식도 동일할까요?
- 먼저, 모분산식을 보면 이전에 배웠던 분산식과 동일합니다. 그렇다면, 표본분산식도 동일할까요?

- 결론부터 말하자면, 표본분산식과 모분산식은 서로 다릅니다.
- 왜 표본분산식은 n-1로 나누게 될까요? 이에 대한 해답을 찾기 위해 '불편 추정량(unbiased estimator)'이라는 개념을 알아보도록 하겠습니다.
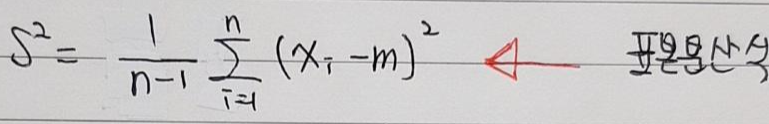
2-1. 불편 추정량(unbiased estimator)
불편추정량을 알기 위해서는 '불편(unbias)'라는 뜻과, 추정량(estimator)라는 뜻을 알아야 합니다.
- 추정량(estimator)이란 통계량을 의미합니다. 왜냐하면, 우리는 모집단의 모수를 알고 싶은데, 현실적으로 불가능 하기 때문에, 통계량을 통해 모수를 추정하기 때문이죠. 즉, 통계량이 모수를 추정하기 위한 estimator가 되는 거죠.
- 그렇다면, 불편(unbias) 하다는 것은 무엇을 의미할까요? 아래의 사진을 통해 알아보도록 하겠습니다.


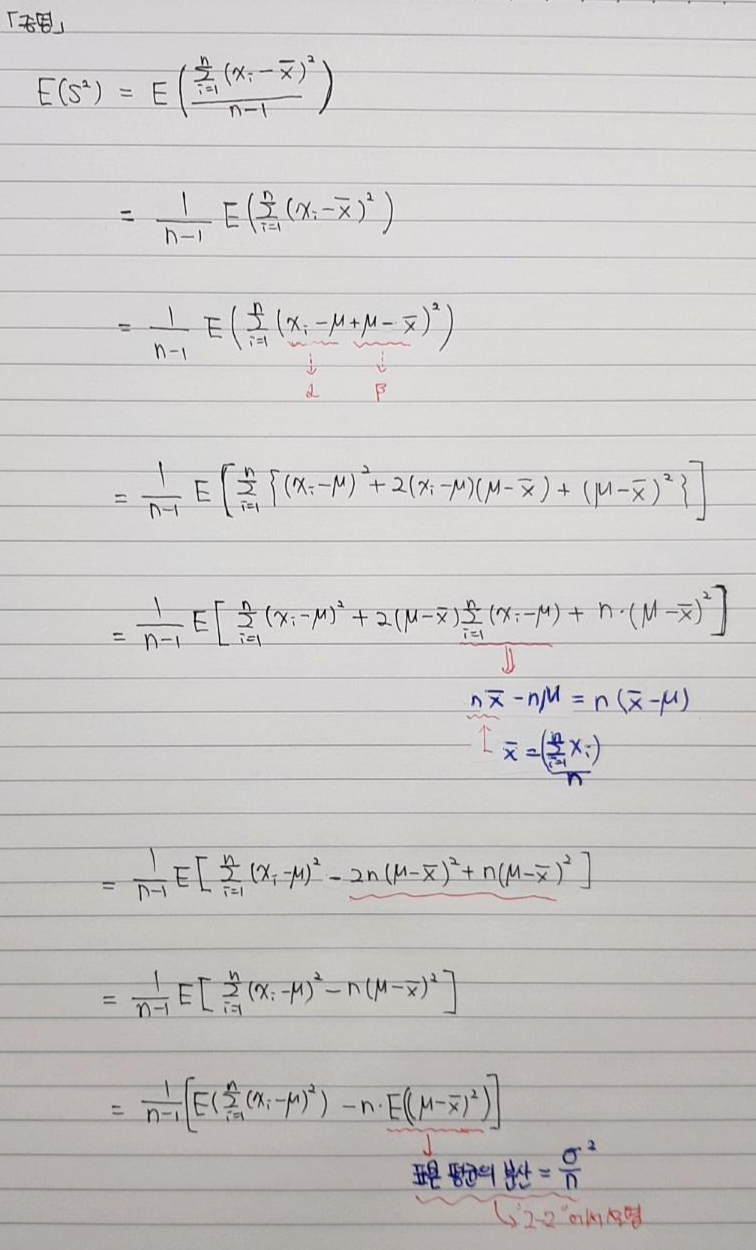

2-2. 표본분산식과 자유도의 관계
- 먼저, 자유도가 무엇인지 살펴보겠습니다.
- 자유도는 독립변수의 개수를 의미합니다.
- "f(x,y,z) = x+y+z = 3"이라고 했을 때, 독립변수는 2개입니다. 왜냐하면 x, y 값을 알게되면 z값은 종속적으로 알 수 있기 때문이죠.
- 그렇다면, 표본분산식과 자유도는 어떤 관계가 있을까요?
- 결과부터 말하자면, 표본분산의 자유도는 n-1인데, 결국 불편추정량을 위해 변경된 표본분산의 분모 부분이 곧 표본분산의 자유도입니다. (어떤 특별한 개념이 있는 것이 아니고, 정말 말 그대로 분모 부분이 표본분산의 자유도일 뿐이죠).

(↓↓↓ 표본분산 설명 유튜브 채널↓↓↓)
https://www.youtube.com/watch?v=faVIwae-wkw
https://www.youtube.com/watch?v=CLrUbG4ASQo&list=RDCMUCVrs4KiLQz_gvVWWK1pKR1g&index=4
https://www.youtube.com/watch?v=WfiRjHATlrg&list=PLmljWRabIwWBxh8V6eIODIz--B802mdLt&index=5
3. 표준오차 (Standard error) = 표본평균들의 오차

(↓↓↓ 표준편차 설명 블로그↓↓↓)
https://hsm-edu.tistory.com/794
표준오차가 뭔가요? 표준편차랑 다른건가요?
모집단이 있습니다. 모집단의 평균을 μ(뮤), 표준편차를 σ(시그마)라고 합시다. 모집단의 평균이 궁금한데 모집단이 너무 커서 구할 수가 없었습니다. 모집단의 평균을 추정하기 위해 모집단
hsm-edu.tistory.com
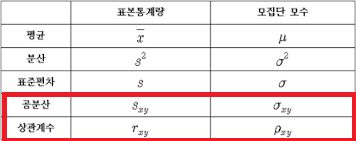
지금까지 표본통계량인 '표본평균, 표본분산, 표준편차' 그리고 '표준오차'에 대해서 알아보았습니다.
다음글에서는 나머지 표본통계량에 해당하는 '공분산과 상관계수'에 대해서 알아보도록 하겠습니다.
4. 엑셀을 이용한 평균, 분산, 표준편차 구하는 방법↓↓↓)
https://www.youtube.com/watch?v=SUzBIYQB794
'딥러닝수학 > 확률-통계학' 카테고리의 다른 글
| [통계학]3.정규분포를 따른다는 의미 (Feat. 중심극한정리) (0) | 2021.05.26 |
|---|---|
| [통계학]2-2.표본통계량(공분산, 상관계수) (0) | 2021.05.25 |
| [통계학]1. 통계학의 전체 구성도 (Feat. 기술통계, Box plot, 추론통계) (0) | 2021.05.23 |
| [확률]4-1. 연속확률분포 (feat. Probability Density Function) (feat.평균(기댓값), 분산(variance), 표준편차(Standard deviation)) (1) | 2021.05.17 |
| [확률]3-2. 이산확률 분포 종류들 (feat. 베르누이 분포, 이항분포, 기하분포, 음이항 분포, 초기하 분포, 포아송 분포 (1) | 2021.05.15 |