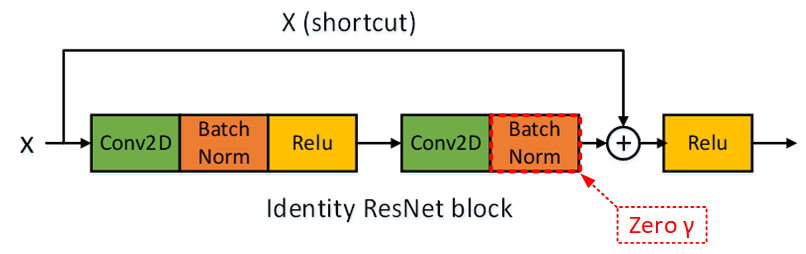
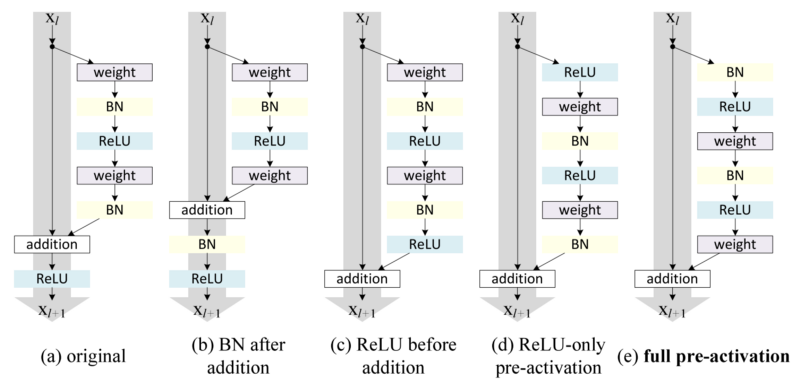
안녕하세요.
앞서 CNN 구조를 구성했다면 최종적으로 model.compile 함수를 이용하여 해당 모델에 적용할 loss function, optimizer, metrics등을 설정해주어야 합니다.
from tensorflow.keras import layers
from tensorflow import keras
from tensorflow.keras import optimizers
###CNN 모델 구축###
input_shape = (150,150,3)
img_input = layers.Input(shape=input_shape)
output1 = layers.Conv2D(kernel_size=(3,3), filters=32, activation='relu')(img_input)
output2 = layers.MaxPooling2D((2,2))(output1)
output3 = layers.Conv2D(kernel_size=(3,3), filters=64, activation='relu')(output2)
output4 = layers.MaxPooling2D((2,2))(output3)
output5 = layers.Conv2D(kernel_size=(3,3), filters=128, activation='relu')(output4)
output6 = layers.MaxPooling2D((2,2))(output5)
output7 = layers.Conv2D(kernel_size=(3,3), filters=128, activation='relu')(output4)
output8 = layers.MaxPooling2D((2,2))(output7)
output9 = layers.Flatten()(output8)
output10 = layers.Dropout(0.5)(output9)
output11 = layers.Dense(512, activation='relu')(output10)
predictions = layers.Dense(2, activation='softmax')(output11)
model = keras.Model(inputs=img_input, outputs=predictions)
###Loss, optimizer, metrics 설정###
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['accuracy'])
이번 글에서는 model.compile에 적용되는 loss, optimizer, metrics 들에 대해 좀 더 자세히 알아보도록 하겠습니다.
1. Loss
1-1. 기본 Loss function
Tensorflow2는 아래링크에서 볼 수 있듯이 기본적인 loss function을 제공해줍니다.
https://www.tensorflow.org/api_docs/python/tf/keras/losses
Module: tf.keras.losses | TensorFlow Core v2.5.0
Built-in loss functions.
www.tensorflow.org
Loss function을 적용하는 방식은 크게 두 가지 입니다.
첫 번째 방식. compile 함수에 있는 loss 속성에 특정 loss를 기재
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['accuracy'])
두 번째 방식. loss instance 생성 후, compile 함수에 있는 loss 속성에 앞서 생성한 loss instance를 기재
loss = CategoricalCrossentropy()
model.compile(loss=loss, optimizer='adam', metrics=["accuracy"])
Q. tf.keras.losses 부분 보면 bianry_crossentropy는 function이고, BinaryCrossentropy는 class로 되어 있는데, 이 두 가지가 어떤 차이가 있는지 모르겠네요. 어느 사이트 보면 function으로 선언한 경우 accuracy가 더 떨어져서 나온다는 말도 있는데, 정확히 어떤 차이가 있는건지...
1-2. 세 가지 기본 Loss function 소개
앞서 tensorflow에서 제공한 기본 loss 함수 중에, 딥러닝 분류 목적으로 사용하는 대표적인 loss function은 3가지 입니다.
1) Binary Crossentropy
Tensorflow에서 제공하는 BinaryCrossentropy는 2가지의 클래스를 구분하는 task에 적용할 수 있는 함수입니다.
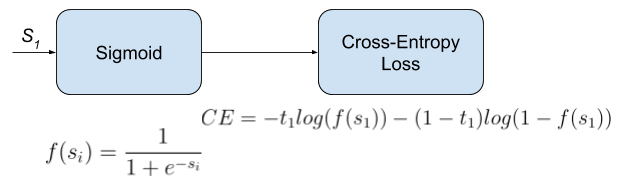
2) Categorical Crossentropy
3개 이상의 클래스를 classification 할 경우 우리는 이를 multiclassification이라고 합니다.
이 경우에는 tensorflow에서 제공하는 CategoricalCrossentropy를 적용해주어야 합니다.

3) SparseCategorical Crossentropy
10개의 클래스를 분류한다고 한다는 가정하에 아래 그림에 있는 기호를 간단히 표현하면 다음과 같습니다.
- t → label=answer → [0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
- y → probability = predict → [0.1, 0.05, 0.05, 0.1, 0.1, 0.3, 0.1, 0.05, 0.05, 0.1]
아래의 CategoricalCrossentropy 수식을 보면 사실 6번째 해당하는 class를 제외하면 모든 t는 0이기 때문에 loss function에 아무런 영향도 미치지 않습니다. 사실상 6번째에 해당하는 t, y 값만 고려해주고 나머지는 무시해줘도 되는 것이죠.
예를 들어, if 문을 이용하여 정답에 해당하는 label에 대해서만 "loss=-t×log(y)" 를 적용해주면 속도도 더 빨라지게 되는데, 이러한 방식의 loss function을 SparseCategoricalCrossentropy 라고 합니다. (실제로 DNN을 hardcoding 했을 때, CategoricalCrossentropy와 SparseCategoricalCrossentropy 학습 결과에는 변함이 없었습니다. 또한, 실제로 돌려보면 SparseCategoricalCrossentropy 방식으로 hardcoding 했을 때 좀 더 학습 속도가 빨랐습니다)

1-3. Label smoothing
Tensorflow 기본 loss API에서는 label smoothing을 쉽게 적용할 있게 구현해 놨습니다.

loss = CategoricalCrossentropy(label_smoothing=0.1)
model.compile(loss=loss, optimizer='adam', metrics=["accuracy"])
For example, if 0.1, use (0.1 / num_classes) for non-target labels and (0.9 + (0.1 / num_classes)) for target labels. (참고로 non-target labels의 확률값은 uniform distribution을 따릅니다)

참고로 앞서 설명한 SparseCategoricalCrossentropy의 기본전제는 hard label이기 때문에, label smoothing 속성이 왜 없는지 쉽게 파악할 수 있습니다.
- hard label: 실제 정답외에 모든 label 값은 0으로 설정하는 방식

1-4. Extra loss functions by Tensorflow addons
Tensorflow 기본 loss API외에 SIG라는 곳에서 추가적인 loss function 들을 구현해 tensorflow에 contribution하고 있습니다. 예를 들어, 최근에 contrastive loss 도 주목을 받고 있는데, 이러한 loss를 Tensorflow Addons (by SIG) 에서 제공하는 API를 이용해 사용할 수 있습니다.
https://www.tensorflow.org/addons/api_docs/python/tfa/losses
Module: tfa.losses | TensorFlow Addons
Additional losses that conform to Keras API.
www.tensorflow.org

1-5. Custom Loss function
우리가 사용할 loss function이 앞서 소개된 기본 loss function에 없다면 우리가 스스로 만들어야 합니다.
대부분 정해진 task에 의해 기본적인 loss function을 쓰는 것이 보편적이지만, 종종 자신만의 loss function을 만들어 사용하는 경우도 있습니다. 예를 들어, Semi-supervised loss function, focal loss function과 같은 경우는 tensorflow에서 기본적으로 제공되는 loss function이 아니기 때문에 사용자가 직접 함수를 만들어 사용해야 합니다.
예를 들어, hubber loss라는 것을 만들어 사용하려면 아래와 같이 작성해주면 됩니다.
def my_huber_loss(y_true, y_pred):
threshold = 1
error = y_true - y_pred
is_small_error = tf.abs(error) <= threshold
small_error_loss = tf.square(error) / 2
big_error_loss = threshold * (tf.abs(error) - (0.5 * threshold))
return tf.where(is_small_error, small_error_loss, big_error_loss)
model.compile(optimizer='sgd', loss='my_huber_loss')
(↓↓huber loss 수식 설명↓↓)
https://mypark.tistory.com/14?category=1007621
[Tensorflow 2][Keras] Week 2 - Custom loss functions
본 포스팅은 다음 과정을 정리 한 글입니다. Custom Models, Layers, and Loss Functions with TensorFlow www.coursera.org/specializations/tensorflow-advanced-techniques 지난 시간 리뷰 2021.03.13 - [Artif..
mypark.tistory.com
2. Optimizer
2-1. 기본 optimizer
Tensorflow2는 아래링크에서 볼 수 있듯이 기본적인 Optimizer를 제공해줍니다.
https://www.tensorflow.org/api_docs/python/tf/keras/optimizers
Module: tf.keras.optimizers | TensorFlow Core v2.5.0
Built-in optimizer classes.
www.tensorflow.org
위링크에서 자신이 적용시키고 싶은 optimizer를 클릭하면 해당 optimizer에 어떤 속성들(ex: learning rate, etc...)이 있는지 알 수 있습니다.

optimizer도 아래와 같이 두 가지 패턴으로 선언이 가능합니다.
첫 번째 방식
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['accuracy'])
두 번째 방식
opt = SGD(lr=INIT_LR, momentum=0.9)
loss = CategoricalCrossentropy(label_smoothing=0.1)
model.compile(loss=loss, optimizer=opt, metrics=["accuracy"])
2-2. Extra optimizers by Tensorflow addons
앞서 loss functionn에서 언급한 것 처럼, 기본 tensorflow API에서 제공되는 optimizer 외에 SIG에서 제공하는 다양한 optimizer들이 있습니다.
(↓↓↓supported by SIG↓↓↓)
https://www.tensorflow.org/addons/api_docs/python/tfa/optimizers
Module: tfa.optimizers | TensorFlow Addons
Additional optimizers that conform to Keras API.
www.tensorflow.org
2-3. 최신 optimizer
앞서 제공한 기본적인 optimizer 외에도 현재 개발중인 다양한 optimizer들이 등장하고 있습니다. 예를 들어, 작년에 NeurIPS에서 Adabelief라는 optimizer를 발표한바 있습니다.
https://arxiv.org/abs/2010.07468
AdaBelief Optimizer: Adapting Stepsizes by the Belief in Observed Gradients
Most popular optimizers for deep learning can be broadly categorized as adaptive methods (e.g. Adam) and accelerated schemes (e.g. stochastic gradient descent (SGD) with momentum). For many models such as convolutional neural networks (CNNs), adaptive meth
arxiv.org
보통 이런 최신 optimizer는 논문이 나오면 github에 등록하여 일반 사용자들이 쉽게 사용할 수 있도록 기록해놓습니다.
https://github.com/juntang-zhuang/Adabelief-Optimizer
juntang-zhuang/Adabelief-Optimizer
Repository for NeurIPS 2020 Spotlight "AdaBelief Optimizer: Adapting stepsizes by the belief in observed gradients" - juntang-zhuang/Adabelief-Optimizer
github.com
위의 사이트에 접속하면 아래와 같이 tensorflow에서 어떻게 사용하면 되는지 설명되어 있습니다.

아래 글을 보면 tensorflow 기반의 keras 에서는 호환이 안된다고 했는데,
https://github.com/juntang-zhuang/Adabelief-Optimizer/issues/2
Tensorflow implementation doesn't work · Issue #2 · juntang-zhuang/Adabelief-Optimizer
TF 2.3 from tensorflow.keras.layers import Dense from tensorflow.keras.models import Sequential import numpy as np from adabelief_tf import AdaBeliefOptimizer x = np.random.random_sample((5,)) y = ...
github.com
"Make it compatiable with tensorflow and keras"라는 부분을 검색해보면 해당 부분이 수정된 것으로 보입니다 (아직 적용해보지 않아 실제로 잘 동작하는지 아닌지는 확인해봐야합니다 (Pytorch 버전은 잘 돌아가네요).

2-4. Learning rate schedule
학습이 진행 될 수록 점점 global minimum에 접근한다고 가정했을 때, learning rate도 천천히 줄여주는 것이 학습에 효과적이라고 알려져있습니다. 즉, schedule대로 learning rate를 변경해가며 사용하는 것이죠.

예를 들어, 위의 이미지에서는 exponential learning rate decay 방식을 표현하고 있는데, 이를 tensorflow 2 코드로 적용시키면 아래와 같습니다.
initial_learning_rate = 0.1
lr_schedule = keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=100000,
decay_rate=0.96,
staircase=True)
optimizer = keras.optimizers.RMSprop(learning_rate=lr_schedule)
Tensorflow 2에서는 "opimizer.schedules"을 통해 여러 learning rate decay 기법을 제공해줍니다.

https://www.tensorflow.org/api_docs/python/tf/keras/optimizers/schedules
Module: tf.keras.optimizers.schedules | TensorFlow Core v2.5.0
Public API for tf.keras.optimizers.schedules namespace.
www.tensorflow.org
예를 들어, CosineAnnealing 방식을 적용하고 싶다면 아래와 같이 코드를 작성해주면 됩니다.
tf.keras.optimizers.schedules.CosineDecayRestarts(
initial_learning_rate, first_decay_steps, t_mul=2.0, m_mul=1.0, alpha=0.0,
name=None
)- initial_learning_rate : 최초의 학습률
- first_decay_steps : (첫 주기의 감쇄가 진행되는 총 스텝 수) 최초의 주기 길이
- t_mul : 주기 T를 늘려갈 비율 (첫 주기가 100step이면 그 다음은 200step, 그 다음은 400step...)
- m_mul : 최초 학습률로 설정한 값에 매 주기마다 곱해줄 값 (0.9라면 매 주기 시작마다 initial_learning_rate에 (i는 주기 인덱스)만큼 곱한 값을 주기 시작 학습률로써 사용한다.)
- alpha : 학습률의 하한을 설정하기위한 파라미터로 학습률의 감소 하한은 initial_learning_rate * alpha가 된다.
- 레퍼런스 사이트

(↓↓↓위에서 언급한 learning rate decay 구현 및 시각화한 사이트↓↓↓)
https://www.programmersought.com/article/96553631082/
The tricks of learning rate decay in Tensorflow - Programmer Sought
The method of parameter update in deep learning must be very clear to everyone-sgd, adam, etc., and the discussion about which is better is also extensive. but,learning rate decay strategyHas anyone paid special attention? When training neural networks, th
www.programmersought.com
2-4. Learning rate warm-up
※Learning rate warm-up도 굉장히 자주쓰이는 트릭인데, tensorflow에서 기본적으로 제공해주는 방식은 없는 듯합니다. Github에서 다운받거나 아래 사이트를 참고하여 직접구현해주면서 사용해야 할 듯 합니다 (Pytorch는 굉장히 쉽게 사용할 수 있게 되어 있는데, tensorflow로 쓰려니 참...)
(↓↓↓아래 사이트에서 learning rate warm up 코드 부분을 참고해주세요!↓↓↓)
Bag of Tricks for Image Classification with Convolutional Neural Networks in Keras | DLology
Posted by: Chengwei 2 years, 6 months ago (Comments) This tutorial shows you how to implement some tricks for image classification task in Keras API as illustrated in paper https://arxiv.org/abs/1812.01187v2. Those tricks work on various CNN models like
www.dlology.com
지금까지 model.compile의 속성들 중인 loss function, optimizer, learning rate schedule 에 대해서 살펴보았습니다.
다음 글에서는 마지막 남은 속성인 metrics에 대해 소개하도록 하겠습니다.
'Tensorflow > 2.CNN' 카테고리의 다른 글
| 5.Pre-trained model 불러오기 (feat. Transfer Learning and .h5 파일) (0) | 2021.06.30 |
|---|---|
| 4. 평가지표(Metrics ) visualization (0) | 2021.06.29 |
| 2.CNN 모델 구현 (Feat. Sequential or Function API) (0) | 2021.06.29 |
| 1.Data Load 및 Preprocessing (전처리) (0) | 2021.06.28 |
| 코드참고 사이트 (0) | 2021.06.28 |