일반적으로 생각했을 때는, "A백신이 효과가 있다"라는 것을 바로 검증하려고 시도할 것 입니다.
하지만, 통계적인 관점에서 가설을 검정하는 방식은 조금 다릅니다.
내가 주장한 가설과 반대되는 "A백신이 효과가 없다"라는 가설을 세우고, 이 가설이 틀렸다는 것을 보여줌으로써, 내가 주장한 가설이 참임을 증명하는 방식이 통계적인 가설검정 방식입니다 .
이때, 내가 주장한 가설과 반대되는 가설을 '귀무가설(Null hypothesis, \(H_{0}\))'이라고 하고, 내가 주장하는 가설을 '대립가설(Alternative hypothesis, \(H_{1}\))'이라고 합니다.
귀무가설(Null hypothesis, \(H_{0}\)): 돌아갈 귀, 없을 무 → 처음부터 버릴 것을 예상하는 가설 또는 틀리기를 바라는 가설(?)
대립가설(Alternative hypothesis, \(H_{1}\): → 연구가설또는 유지가설이라고도 부르는데 귀무가설에대립하는 명제 → 귀무가설을 대체하고 싶은 가설 즉, 귀무가설이 틀렸고 내가 세운 가설이 맞기 때문에 귀무가설을 대체할 수 있다 (alternative)고 생각하는 가설
[가설검정 순서]
※ 아래 사진은 가설검정이 이루어지는 순서입니다. 이번글에서는 '귀무가설/대립가설' 부분만 살펴보고, 다음글에서 부터 "유의 수준~검정통계량"에 대해서 알아보도록 하겠습니다.
이미지 출처: https://www.slideshare.net/ssuser64f3dc/ss-72602596이미지 출처: http://blog.naver.com/PostView.nhn?blogId=afterglow25&logNo=110124544645
2. 가설의 종류
앞서 '귀무가설'과 '대립가설'에 대해서 알아보았습니다.
그런데, '가설'의 종류에 따라 검정방식이 달라진다는 것을 알고 있으신가요?
즉, '가설검정'방식은 '가설'의 종류에 따라 굉장히 다양하기 때문에, 가설검정에 있어서 가장 중요하고, 제일 먼저해야 할 일은 '가설'의 종류를 파악하는 것입니다.
예를 들어, 아래와 같은 귀무가설들이 있다고 해보겠습니다.
ex1) "어떤 집단의 키가 (평균적으로) m이다"
ex2) "두 집단의 특징이 (평균적으로) 같다"
ex3) "어떤 집단에 특정 처리를 했을 때, 해당 집단의 특성이 (평균적으로) 전과 후가 같다"
위의 세 가지 가설들은 각각 가설검정 방식이 다릅니다.
그렇다면, '가설'의 종류들을 어떻게 나눌 수 있을까요? 지금부터 알아보도록 하겠습니다.
2-1. 자료형(data type)의 성격
가설의 종류를 살펴보기 전에 배경지식으로 알아두어야 할 것이 가설에 기반이되는 데이터(변수, 자료)의 유형입니다.
[자료형 종류]
범주형 (categorical data) = 질적변수 (qualitatitve variable) → 몇 개의 범주로 나누어진 데이터 → 수량화 불가능
명목형(nominal data) → '순서'에 의미가 없는 분류형 → ex) 성별(남/녀), 성공여부(성공/실패), 혈액형(A/B/O/AB)
순서형(ordinal data) → '순서'에 의미가 있는 분류형 → ex) 교육수준(초졸=1, 중졸=2, 고졸=3, 대졸 이상=4), 간강상태(좋음=3, 보통=2, 나쁨=1)
수치형 (numerical data) = 양적변수 (quantitive variable) → 수량화 가능
이산형(discrete data) → 이산적인 값을 갖는 데이터 (이산확률분포의 이산확률변수) → ex) 연령(10대, 20대, 30대, ....)
연속형(continuous data) → 연속적인 값을 갖는 데이터 (연속확률분포의 연속확률변수) → ex) 신장, 체중, 혈압
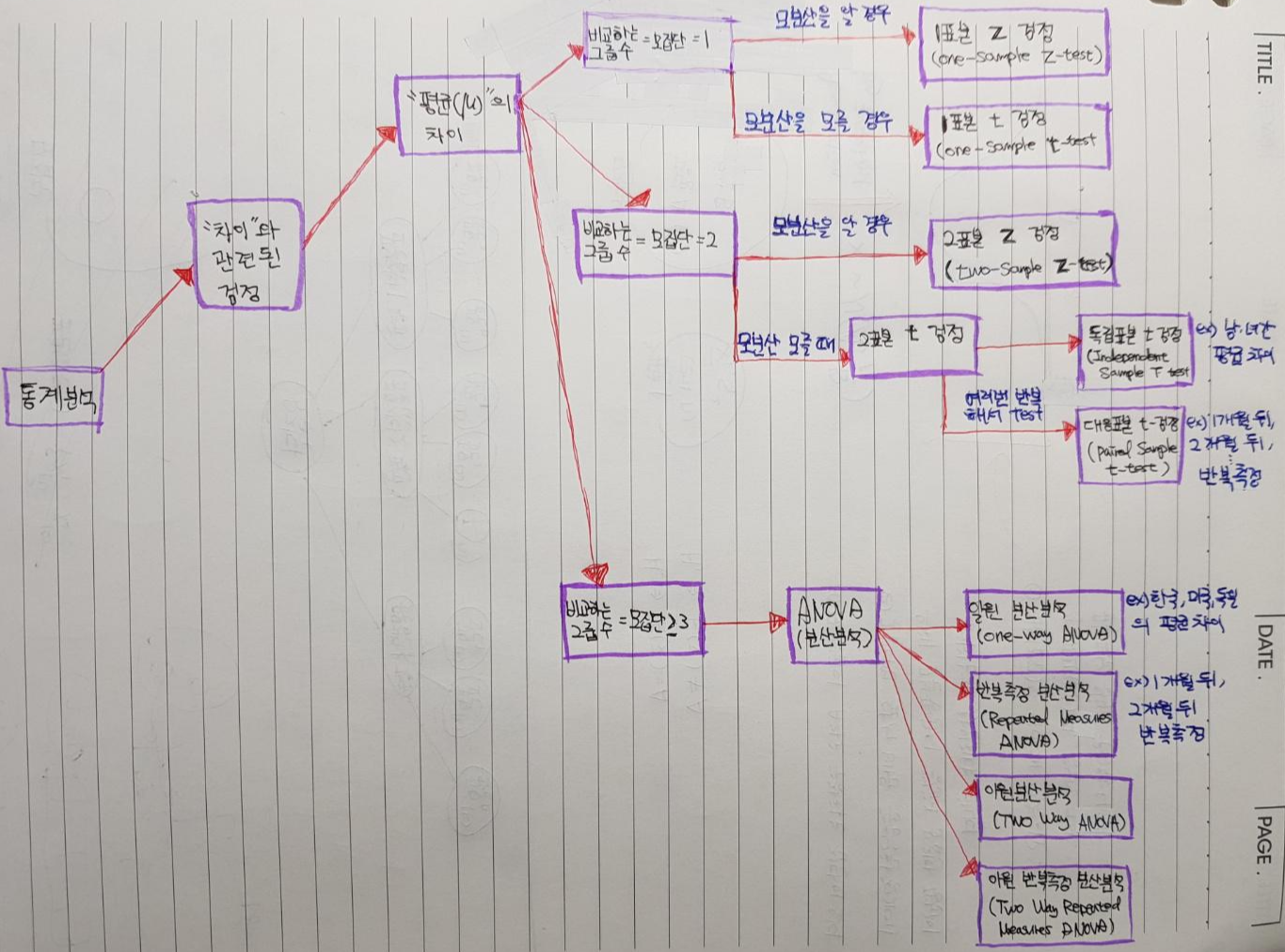
2-2. 가설의 종류에 따른 가설검정 방법들
[↓↓↓위의 그림 텍스트로 정리한 것↓↓↓]
'차이'와 관련된 검정
'평균'의 차이를 검정 하고 싶을 때
1-1. 비교하는 집단이 하나일 때
1-1-1. 모분산을 알고 있는 경우 & 표본이 클 때
일(1)표본 Z 검정 (One-sample Z test) → ex) 귀무가설(\(H_{0}\)): 한국의 평균은 K이다.
1-1-2. 모분산을 모르는 경우 & 표본이 작을 때
일(1) 표본 T 검정 (One-sample T test) → ex) 귀무가설(\(H_{0}\)): 한국의 평균은 K이다.
1-2. 비교하는 집단이 둘일 때
1-2-1. 모분산을 알고 있는 경우 & 표본이 클 때
이(2)표본 Z 검정 (Two-sample Z test) → ex) 귀무가설(\(H_{0}\)): 남, 녀간의 평균에 차이가 없다.
1-2-2. 모분산을 모르는 경우 & 표본이 작을 때
1-2-2-1. 독립표본 T 검정 (Independent Sample T test) → ex) 귀무가설(\(H_{0}\)): 남, 녀간의 평균에 차이가 없다.
1-2-2-2. 대응표본 T 검정 (Paired Sample T test) → ex) 귀무가설(\(H_{0}\)): 남, 녀간의 평균에 차이가 없다 & 해당 차이를 반복해서 검증 (한 달간 간격을 두고 측정: 1개윌 뒤, 2개윌 뒤, 3개윌 뒤, ....)
1-3. 비교하는 집단이 셋 이상일 때
1-3-1. ANOVA (분산분석)
1-3-1-1. 일원 분산분석 (One-way ANOVA) → ex) 귀무가설(\(H_{0}\)): 한국, 미국, 독일의 평균에 차이가 없다
1-3-1-2. 반복측정 분산분석 (Repeated Measures ANOVA) → ex) 귀무가설(\(H_{0}\)): 한국, 미국, 독일의 평균에 차이가 없다 & 해당 차이를 반복해서 검증 (한 달간 간격을 두고 측정: 1개윌 뒤, 2개윌 뒤, 3개윌 뒤, ....)
Chi square (카이검정) → ex) 귀무가설(\(H_{0}\)): 프로야구 선발투수들 직구구속의 분산은 K이다. → 분산이 K이인지 검증
2-2. 비교하는 집단이 둘일 때
F 검정 (F test) → ex) 귀무가설(\(H_{0}\)): LG 선발투수들 직구구속과 삼성 선발투수들 직구구속 분산이 같다.
'관계'와 관련된 검정
범주형변수끼리 비교
1-1. Chi squre (카이제곱 검정)
수치형변수끼리 상관관계 비교
2-1. 상관분석 (Correlation) → 변수 (자료) 들끼리의 '증감'이나 '상관정도'만 나타낼 뿐, 인과관계를 나타내지는 못합니다 → 관련개념: 공분산(covariance), 상관계수(correlation coefficient) → 선형대수 PCA 개념에서 활용되기도 함
변수끼리의 인과관계 비교 (독립변수&종속변수) → 종속변수는 반응변수라고도 함
3-1. 회귀분석 (Regression) → 독립변수들과 종속변수간의 인과관계를 파악하는 분석기법
3-1-1. 변수들이 수치형 변수에 속함
3-1-1-1. 단순 회귀분석 (Linear Regression) → ex) \(Y=aX=f(X)\) → 독립변수, 종속변수간의 선형함수관계를 찾는 것
3-1-1-2. 다중 회귀분석 (Multiple Linear Regression) → ex) \(Y=aX_{1}+bX_{2}+\cdots+zX_{n}=f(X_{1}, X_{2}, \cdots, X_{n})\) → 다수의 독립변수와 단일 종속변수간의 선형함수관계를 찾는 것
3-1-2. (독립변수=범주형 or 연속형 변수) and (종속변수(반응변수) = 명목형 or 이분형 (0 or 1 값을 가짐) 변수)
3-1-2-1. 로지스틱 회귀분석 (Logistic Regression) → ex) 여러 독립변수들로부터 두 범주만 가지는 반응변수를 예측 → (확률 관점으로 봤을 때) 종속변수 값이 0.5보다 크면 반응(1=true)하고 작으면 반응하지 않음(0=false)
이미지 출처: https://blog.naver.com/cjworud/10094919262
200명 정도의 학생 몸무게를 측정하는건 어려운 일이 아니기 때문에 하루면 모두 측정가능하겠죠.
위와 같은 경우, 해당 집단의 전(체의)수를 대상으로 조사하는 것이 가능한데, 이러한 조사를 전수조사라고 합니다.
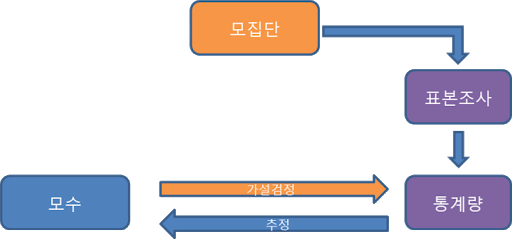
1-2-2. 표본조사 (Sample survey)
그런데, 대한민국 국민들의 몸무게 평균을 측정한다고 해보겠습니다.
어느 세월에 4천만 국민의 몸무게를 측정할 수 있을까요?
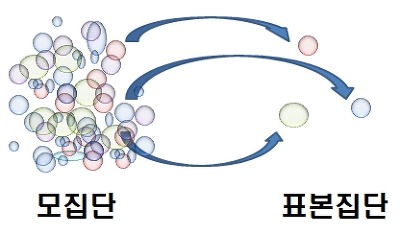
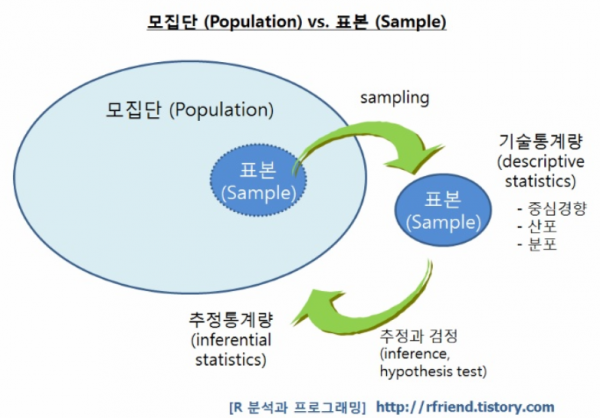
대부분 조사를 할 때, 모든 대상을 조사하는 것에는 현실적 어려움이 있기 때문에 모집단(population)으로 부터 표본집단(sampling)을 선별 하게됩니다.
모집단(populatioin):통계적인 관찰의 대상이 되는 모든 데이터들 (ex: 전 국민) → 모집단에서 '모'는 "어미 모"를 의미하는데, 표본집단의 어머니 격이라는 뜻
표본(sampling) (집단): 모집단을 대표하는 일부 데이터들 (ex: 각 지방별로 선별된 일부 국민들)→ 표본이라는 것은 본보기라는 뜻을 의미하는데, 모집단을 대표할 수 있는 (본보기가 되는) 집단이라는 뜻 → 모집단의 부분집합
표본조사라는 단어에서 '표본'은 앞서 언급한 표본집단을 의미하는 것이고, '조사'라는 용어안에 굉장히 많은 과정들이 함축되어 있습니다. 아래 표본조사에 대한 정의를 살펴보면서 '조사'라는 용어에 어떤 과정들이 포함되어 있는지 살펴보는게 좋을 것 같습니다.
"표본조사란, 모집단(population)에서 표본(sampling)을 뽑아서 표본집단의 통계량을 계산한 후, 표본집단의 통계량을 이용해 모집단의 모수(=모집단의 통계량=parameter)을 추론하고, 이를 이용해 내가 주장한 가설을 통계적으로 검증 (testing)하는 일련의 과정"을 의미합니다.
즉, 우리가 배우는 통계학 대부분은 표본조사를 배우는 과정이라고 볼 수 있죠. 그렇다면 지금부터 표본조사가 어떻게 이루어지는지 알아보도록 하겠습니다.
이미지 출처: https://melissaeh.tistory.com/entry/%EB%AA%A8%EC%A7%91%EB%8B%A8%EA%B3%BC-%ED%91%9C%EB%B3%B8%EC%A7%91%EB%8B%A8%EC%9D%98-%EC%B0%A8%EC%9D%B4%EB%8A%94-%EB%AD%98%EA%B9%8C-%ED%8F%89%EA%B7%A0-%EC%A4%91%EC%95%99%EA%B0%92-%EC%B5%9C%EB%B9%88%EA%B0%92%EC%9D%80-%EB%98%90-%EB%AD%90%EC%95%BC
2. 두 번째 행위: 기술통계
앞서 말했듯이, 현실적으로 모든 사람들을 조사할 수는 없기 때문에, 대부분 표본을 추출 (sampling) 하여 조사를 실시하게 됩니다.
추출된 표본 데이터는 해당 집단의 특성을 규명하기 위해 사용됩니다. 즉, 표본 데이터를 통해 해당 집단을 상징(표현)하는 작업을 하는 것이죠.
측정이나 실험에서 수집한 자료(data)의 특성을 규명하는 것도 표본추출한 표본데이터라고 가정합니다. 왜냐하면, 실험에서 수집한 자료가 해당 그룹에 속하는 전세계 모든 대상(데이터)을 포함하진 않기 때문이죠.
그런데, 왜 해당 (표본)집단의 특성을 규명해야 할까요? 앞서 언급한 백신 예시를 통해 알아보도록 하겠습니다.
[(표본)집단의 특성을 규명해야 하는 이유 - 예시]
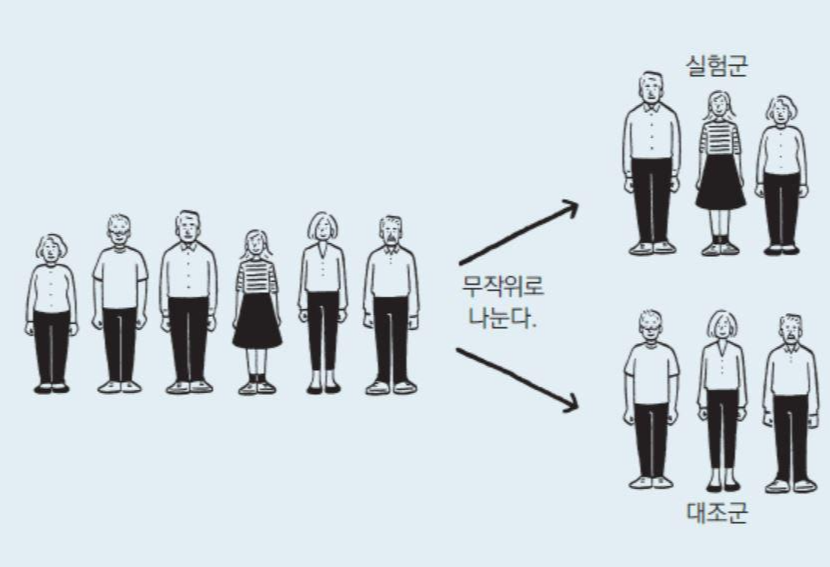
A백신을 투여했을 때 실험군에서 얻어지는 결과들이 있을 것이고, A백신을 투여하지 않았을 때 대조군에서 얻어지는 결과들이 있을 것입니다.
하지만, 실험군에서 얻어지는 결과들이 전부 같지는 않을 것이고, 대조군에서 얻어지는 결과들이 얻어지는 결과들이 전부 같진 않을 것 입니다.
예를들어, 실험군 내에서도 백신을 주입했을 때 효과가 강력한 경우, 미세한 경우, 또는 효과가 없는 경우가 있을 것입니다. 그래도, 대체적으로 효과가 있을 가능성이 있겠죠.
대조군 내에서도 백신을 주입하지 않았지만 우리도 모르는 현상 때문에 코로나에 면역이 있는 사람들도 있겠죠. 하지만, 대부분 코로나 바이러스에 감염이 될 것 입니다.
이미지 출처: http://blog.naver.com/PostView.nhn?blogId=cityeng1&logNo=220028131792&parentCategoryNo=&categoryNo=255&viewDate=&isShowPopularPosts=true&from=search
즉, 실험군과 대조군이라는 집단에 속한 데이터(사람들)를 살펴보면 '실험군 집단은 대체로, 평균적으로 XX하다' or '대조군 집단은 대체로, 평균적으로 XX하다'라는특성을 알아볼 수 있게 되는 것이죠.
결국, "A백신이 효과가 있다"는 나의 가설을 증명하는 과정 속에, 이러한 집단간의 특성들을 비교하는 것이 포함되어 있기 때문에 집단의 특성을 규명하게 됩니다.
앞서 언급한 표본집단의 특성을 통계학에서는 통계량이라고 합니다.
통계량의 정의는 표본집단의 몇몇 특징을 수치화한 값입니다.
표본 데이터를 입력으로 하는 특정한 함수를 계산함으로써 그 값을 계량하게 되는데, 앞서 배운 평균식, 분산식 등이 이에 포함이 되겠죠.
이미지 출처: http://contents.kocw.net/KOCW/document/2014/hanyang/maengseungjin/4.pdf모수에 대한 개념은 뒷 부분에서 설명하도록 하겠습니다.
앞서 언급한 통계량을 이용해 표본집단을 표현(상징)할 수 있도록 그림으로 묘사(descriptive)할 수 있습니다. 이와 같이 수집한 데이터를 통계량을 통해 묘사하고 설명하는 통계기법을 기술통계(Descriptive Statistic)라고 합니다.
기술통계량 종류를 체계적으로 표현하자면 아래와 같습니다. (여기서 나오는 용어들 중 생소한 용어들은 앞으로 게재할 글에서 설명하도록 하겠습니다.)
기술통계량
집중화경향 (Central tendency): 표본 데이터가 어느 위치에 집중되어 있는가를 나타내는 통계량
평균 (Mean)
중앙값 (Median): 자료를 크기순으로 정렬할 때, 가장 중앙에 있는 값
ex) (1, 2, 35, 42, 53) → 35
ex) (1, 2, 35, 42, 53, 60) → (35+43)/2
최빈값 (Mode)
산포도 (Degree of scattering): 표본 데이터가 퍼져 있는 정도를 나타내는 통계량
최댓값: 데이터에서 가장 큰 값
최솟값: 데이터에서 가장 작은 값
범위(Range): 최대값 - 최솟값
분산
사분위편차 (Quartile deviation): 중앙값(Media)을 기반으로 하는 산포도
Q1: 하위에서부터 25%지점에 있는 요소의 값
Q2: 중앙값
Q3: 하위에서 75% 지점에 있는 요소의 값
표준오차
분포 (Distribution; ex: 확률분포)
첨도(kurtosis): 분포의 뾰족한 정도
왜도(skewness): 분포의 기울어진 정도
※ Box Plot
통계량을 이용해 아래와 같이 "Box Plot"을 통해 데이터를 시각화 할 수 도 있습니다. (Box Plot은 중앙값을 기반으로 한다는 것을 알아두세요!)
이미지 출처: https://blog.naver.com/running_p/90178707051
이미지 출처: https://leebaro.tistory.com/entry/%EB%B0%95%EC%8A%A4-%ED%94%8C%EB%A1%AFbox-plot-%EC%84%A4%EB%AA%85
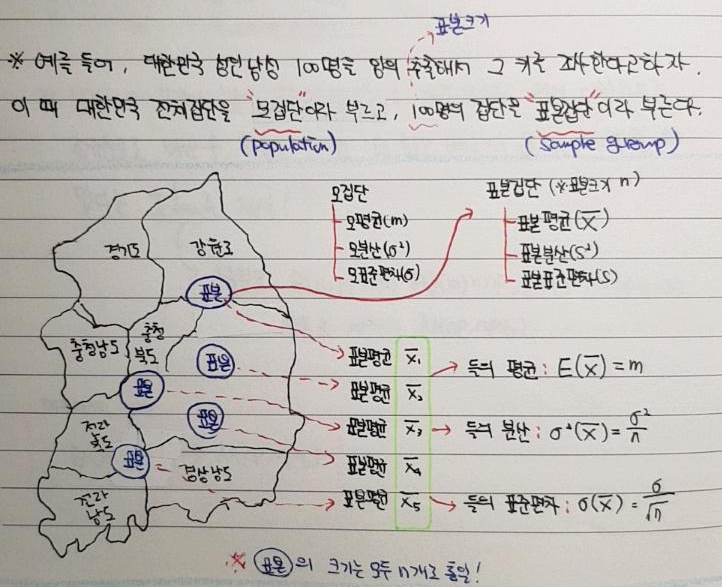
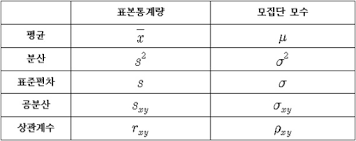
"1-1-2. 표본조사"에서 언급한 것 처럼, 표본집단의 통계량을 알았으니 이를 기반으로 모집단의 모수(←모집단의 통계량)을 알아보아야 합니다.
모집단에서 통계량은 흔히 모수(parameter)라고 합니다. 즉, 표본집단에서의 평균, 분산, 등 개념은 통계량(statistic)이라고 하고, 모집단에서의 평균, 분산 등은 모수라고 부르죠. (모수와 통계량을 표시하는 기호는 서로 다릅니다)
이미지 출처: https://ssacstat.com/default/cs/cs_05.php?com_board_basic=read_form&topmenu=5&left=5&&com_board_search_code=&com_board_search_value1=&com_board_search_value2=&com_board_page=&&com_board_id=12&com_board_idx=283
이미지 출처: http://contents.kocw.net/KOCW/document/2014/hanyang/maengseungjin/4.pdf
앞서 우리가 세웠던 가설 (=가설설정) 이 통계적으로 합당한지 증명하기 위해 이 가설을 검정(test)하게 됩니다.
가설검정이란, 추정을 통해 얻은 모수(parameter)와 관련해 특정한 가설을 세워 놓고, 표본의 정보를 사용해서 가설의 합당성 여부를 판정하는 과정을 의미합니다. ( ← 자세한 설명은 가설검정편과 관련된 글에서 하도록 하겠습니다)
통계적 가설은 통계학에서 사용하는 용어로, 하나의 특정 주장을 모수를 이용해 나타낸 형태를 지칭합니다.
예를 들어, '미국 성인여자의 평균신장은 170cm이다'는 통계적 가설이 될 수 있습니다.
왜냐하면, 평균신장은 모집단 특성을 나타내는 모수의 역할을 수행하기 때문입니다.
통계적 가설은 귀무가설(Null hypothesis ,H0, 영가설)과 이와 반대에 있는 대립가설(Alternative hypothesis,H1)로 나타낼 수 있습니다.
귀무가설: 연구에서 검증하는 가설 (기호는 H0) → ex) A백신은 효과가 없다.
대립가설: 연구자가 연구를 통해 입증되기를 기대하는 예상이나 주장 (기호 Ha 또는 H1) → ex) A백신은 효과가 있다
통계학에서 가설을 검증하는 방법은 아래와 같습니다.
우리가 주장하려고 하는 '대립가설'과 반대되는 '귀무가설'을 설정하고, 이러한 '귀무가설'이 통계적으로 합리적이지 않다는 것을 증명함으로써, '대립가설'이 통계적으로 합리적이다라는 것을 증명하는 방식입니다. (가설설정 단계에서 했던 것은 대립가설이고, 가설검증 단계에서 하는 것은 귀무가설이라는 점을 알아두시면 좋을것 같습니다!)
이미지 출처: https://angeloyeo.github.io/2020/03/25/hypothesis.html
위 그림에서 귀무가설 기각 여부는 아래와 같은 의사결정을 합니다.
대립가설(H1)에 대한 증거가 충분하다면H0를 기각하고H1을 받아들인다.
기각: 그내용이실체적으로이유가없다고판단하여소송을종료하는 알 → 통계적 관점에서 봤을 때, 해당 주장이 "통계적으로" 적합하지 않다고 판단 내리는 것
대립가설(H1)에 대한 증거가 불충분한 경우H0를 기각하지 않는다.
결국, 새로운 내가 주장한 대립가설이 채택이 되면 "나의 주장(가설)이 통계적으로 합당하다는 것이 증명"되게 됩니다.
Introduction - 내가 제안한 가설(연구)이 어떤 측면에서 의미 있는지 광범위한 측면에서 설명
Background - 내가 주장한 가설을 이해하기 위해 필요한 배경지식들 설명
Method - 가설을 증명하기 위해 자신이 고안한 실험 방식
Experiment - 실험을 하기 위해 세팅했던 사항들 설명 → 어떻게 실험이 진행됐는지 설명
Result (and Analysis) - 실험결과가 유의미 했는지 해석 → 내가 실험한 결과를 통계적 (가설검정) 으로 봤을 때, 나의 가설(주장)을 뒷받침 해줄 수 있다고 한다면 (내가 세운 가설 관점에서) 유의미한 실험이 될 수 있음 → 가설검증을 통한 대립가설 채택 과정 → 즉, 유의미한 해석을 하기 위해 통계학이 사용 된 것
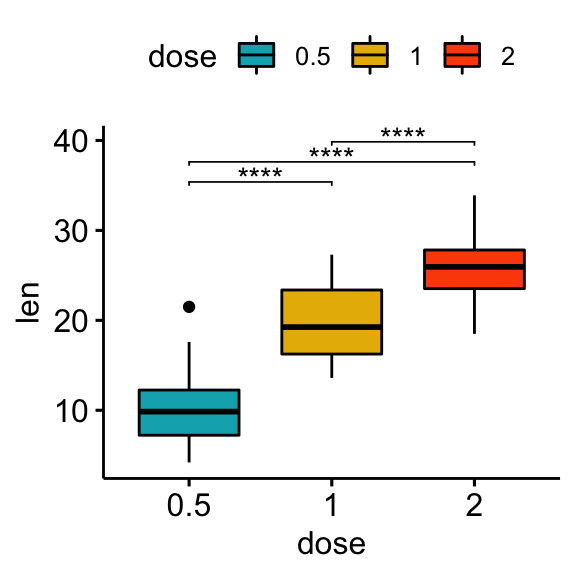
보통 아래 그림을 예로 들어보자면, 귀무가설을 "dose(약)를 0.5비율로 투약한 것과 dose를 1비율로 투약한 것에 큰 변화가 없다"라고 설정한다면 대립가설은 "dose(약)를 0.5비율로 투약한 것과 dose를 1비율로 투약한 것에 큰 변화가 있다"고 설정 할 것입니다.
기술통계를 통해 0.5비율을 투약한 집단과, 1.0비율을 투약한 집단간의 비교가 통계적으로 유의미하게 차이가 있는지 추론통계(추정 및 가설검정)을 통해 판별하게 됩니다. 만약, 유의미한 차이가 있다면, 귀무가설을 기각하고 대립가설을 채택하여 '나의 주장'을 통계적으로 입증하게 됩니다.
이미지 출처: https://www.datanovia.com/en/blog/how-to-add-p-values-onto-basic-ggplots/