안녕하세요.
이번 글에서는 CNN 모델 학습을 위해 학습 데이터들을 로드하는 코드에 대해 설명드리려고 합니다.
아래 사이트의 코드를 기반으로 설명드리도록 하겠습니다.
https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html
Transfer Learning for Computer Vision Tutorial — PyTorch Tutorials 1.9.0+cu102 documentation
Note Click here to download the full example code Transfer Learning for Computer Vision Tutorial Author: Sasank Chilamkurthy In this tutorial, you will learn how to train a convolutional neural network for image classification using transfer learning. You
pytorch.org
우선 데이터를 로드하는 과정을 총 6단계로 나누어 설명하도록 하겠습니다.
from torchvision import datasets, models, transforms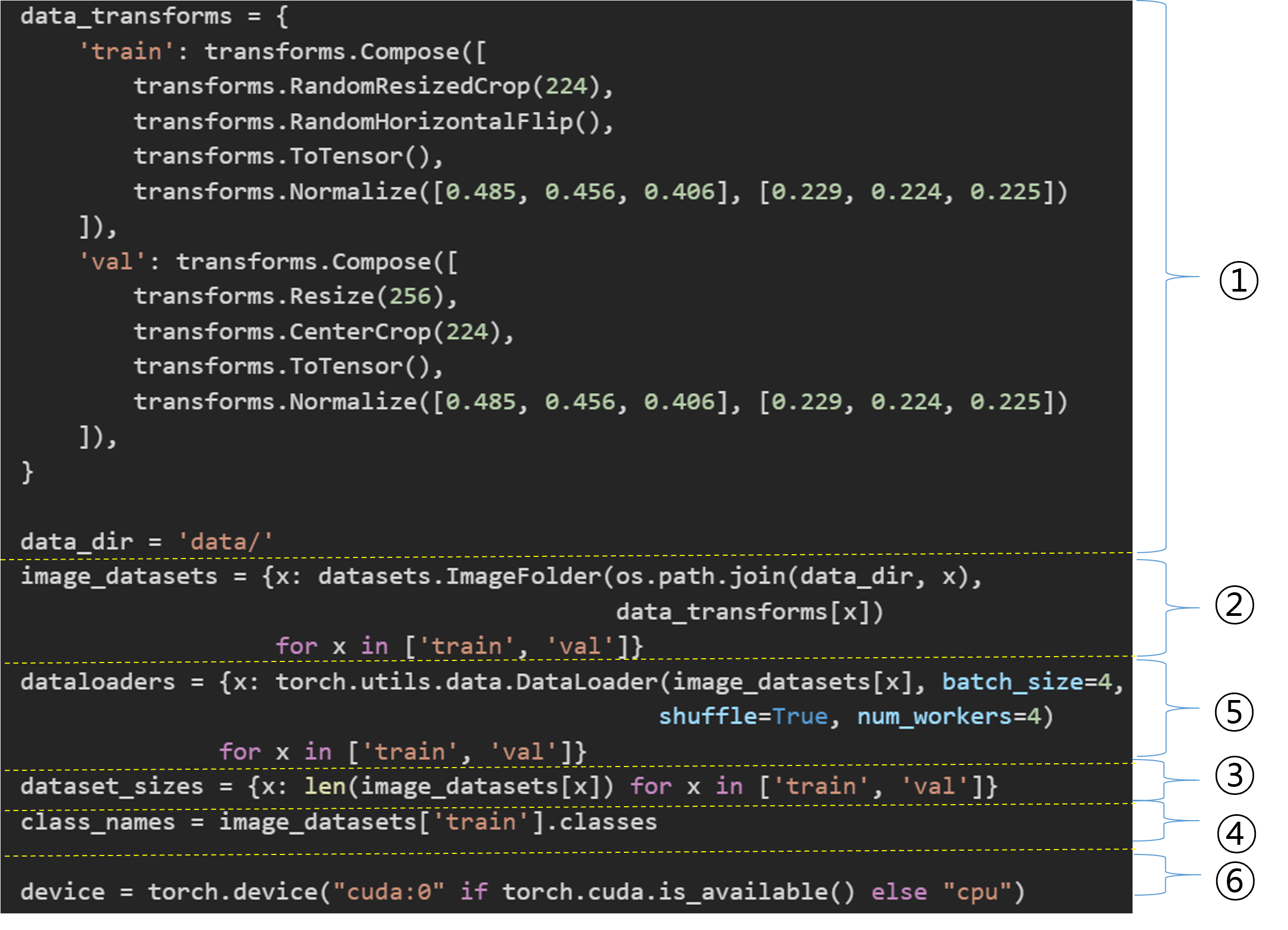
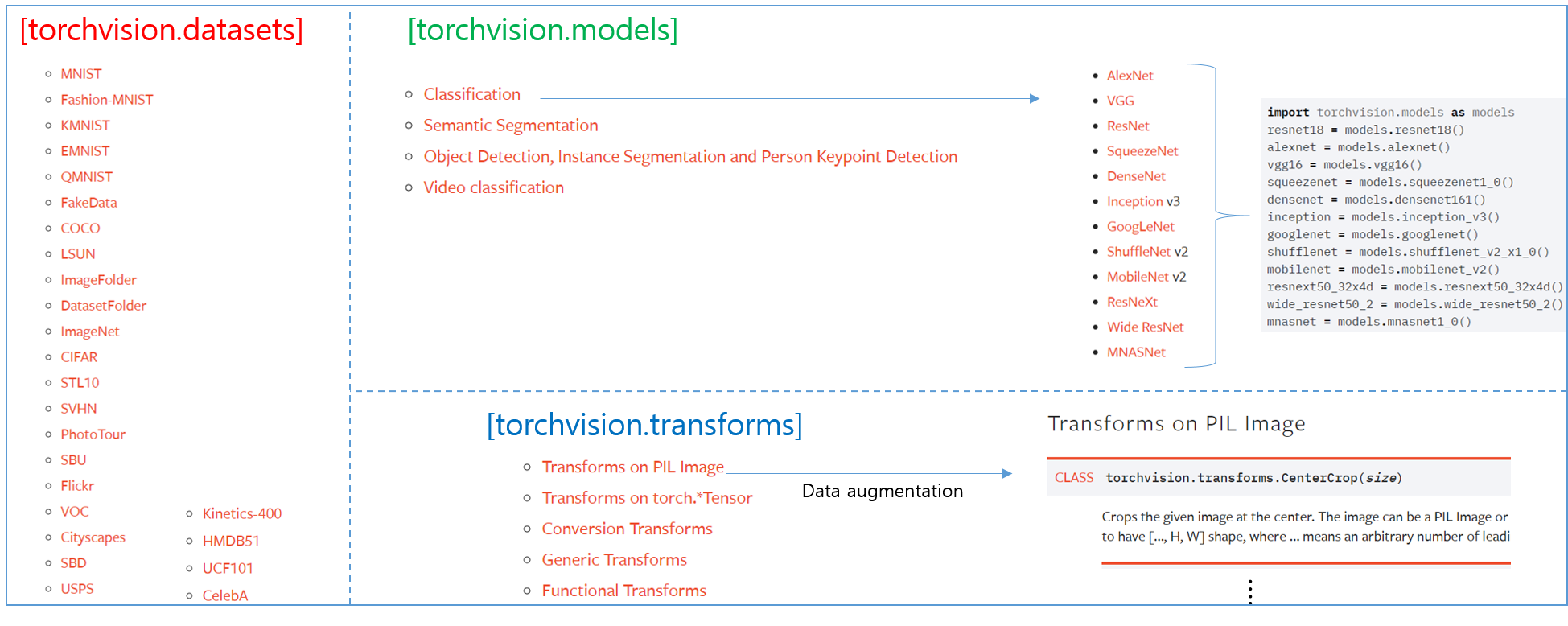
위의 코드를 보면 torchvision에서 transforms, datasets 이라는 패키지가 사용되었다는걸 확인할 수 있습니다. Pytorch에는 torchvision이라는 패키지를 이용해 다양한 computer vision 관련 task를 수행할 수 있습니다. 각각의 패키지들 (datasets, transforms, models) 에 대해서는 위의 코드를 분석하면서 같이 설명하도록 하겠습니다.
https://pytorch.org/vision/stable/index.html
torchvision — Torchvision 0.10.0 documentation
Shortcuts
pytorch.org
1. transforms (Feat. Data Augmentation)
- transforms라는 패키지는 말 그대로 이미지를 transformation (=augmentation) 해주는 기능들을 제공해주고 있습니다.
- 우리가 augmentation을 하기 위한 crop, resize, flip 등은 모두 이미지에 transformation이 적용된 상태입니다.
https://pytorch.org/vision/stable/transforms.html
torchvision.transforms — Torchvision 0.10.0 documentation
torchvision.transforms Transforms are common image transformations. They can be chained together using Compose. Most transform classes have a function equivalent: functional transforms give fine-grained control over the transformations. This is useful if y
pytorch.org
from torchvision import transforms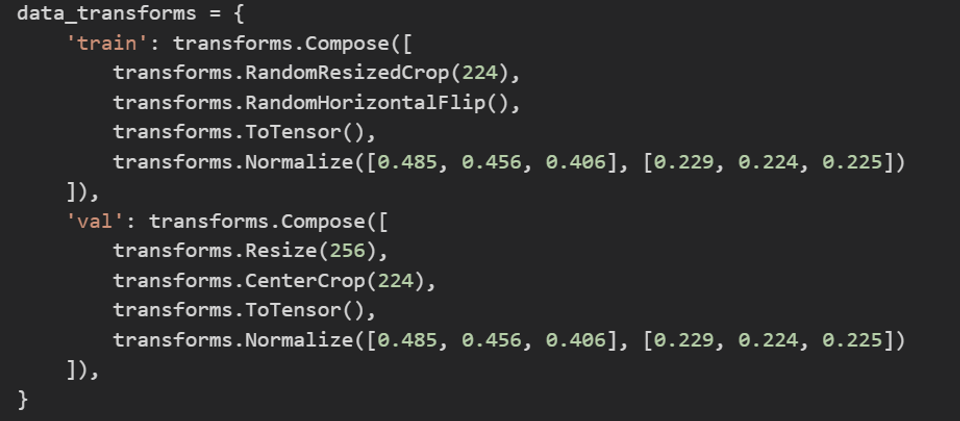
- 위의 코드를 살펴보면 compose 함수인자에 transforms 객체들의 list를 입력 받습니다.
- 이것이 의미하는 바가 무엇일까요? 계속해서 알아보도록 하겠습니다.
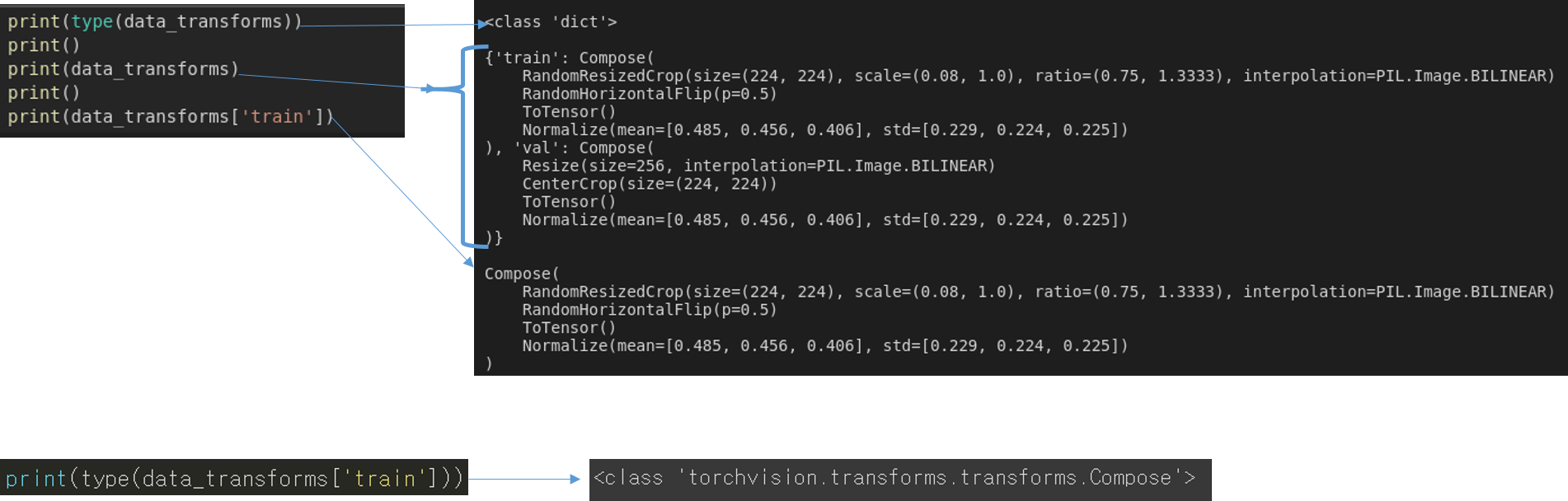
- data_transforms 자체는 dictionary로 정의되었습니다.
- 그리고 각 key에 해당 하는 value 값은 클래스 객체 Compose인 것을 알 수 있습니다.
- Compose 객체에 다양한 인자 값들이 포함되어 있는데, 이 인자 값들이 augmentation이 적용되는 순서라고 보시면 됩니다.
- EX) data_tranforms['train']의 경우
- RandomResizedCrop 수행
- scale → Specifies the lower and upper bounds for the random area of the crop, before resizing. The scale is defined with respect to the area of the original image.
- ratio → lower and upper bounds for the random aspect ratio of the crop, before resizing.
- RandomHorizontalFlip 수행
- p=0.5 → 50%의 확률로 RandomHorizontalFlip 실행
- ToTensor 수행
- 처음 로드되는 이미지 형태를 딥러닝 학습 format에 맞는 tensor 형태로 변경
- Converts a PIL Image or numpy.ndarray (H x W x C) in the range [0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0]
- Normalize 수행
- 이미지 전처리 (Preprocessing)
- Normalization에 들어가는 값들이 어떻게 계산되는지는 아래 PPT를 참고해주세요.
- RandomResizedCrop 수행
2. datasets(Feat. Data Augmentation)
- datasets.ImageFolder를 이용하면 이미지 디렉터리에 존재하는 이미지 메타정보 (ex: 이미지 개수, augmentation 기법들, etc..) 등을 하나의 tuple 형태로 저장할 수 있습니다 ← ImageFolder의 return 형태는 tuple
- 나중에 DataLoader를 이용해 실제 이미지를 load 할 때, 이미지 메타정보(=tuple 형태)들을 이용해 쉽게 load할 수 있습니다 ← 뒤에서 설명
- root: Root directory of dataset
- transforms: A function/transform that takes in an PIL image and returns a transformed version (ex: transforms.RandomCrop)

from torchvision import datasets
import os
※os.path.join 함수 예시 ↓↓↓

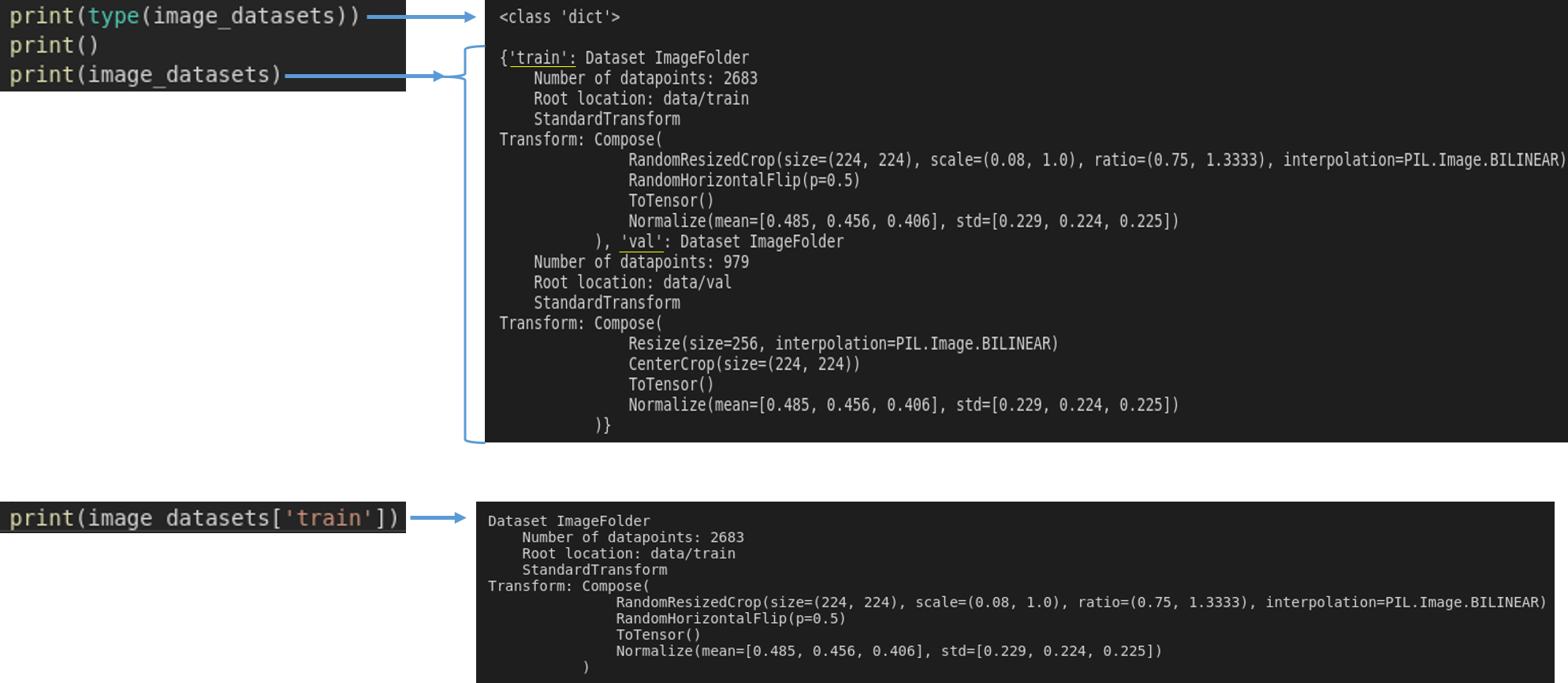
- 아래 결과를 보면 이미지 폴더의 메타정보들을 확인할 수 있습니다.
- 'train': Dataset Image Folder
- Number of datapoints: train 폴더에 들어있는 총 이미지 개수
- Transform: 적용될 augmentation 순서
https://pytorch.org/vision/stable/datasets.html
torchvision.datasets — Torchvision 0.10.0 documentation
torchvision.datasets All datasets are subclasses of torch.utils.data.Dataset i.e, they have __getitem__ and __len__ methods implemented. Hence, they can all be passed to a torch.utils.data.DataLoader which can load multiple samples in parallel using torch.
pytorch.org
- 아래 코드는 dictionary 자료형을 for 문으로 만드는 문법입니다.

- dataset_size 변수는 딥러닝 모델(CNN)을 학습 시킬 때 epoch 단위의 loss or accuracy 산출을 위해 이용됩니다. (자세한 설명은 train을 구현하는 함수에서 설명하도록 하겠습니다)

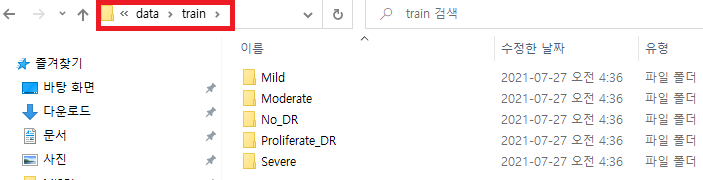
- train 폴더를 보면 총 5개의 class가 있다는걸 확인 할 수 있습니다.
- image_datasets['train'].classes을 이용하면 아래 폴더를 기준으로 class 명들을 string 형태로 사용할 수 있게 됩니다.

※이번 코드에서는 포함되어 있진 않지만, datasets 패키지의 첫 번째 활용도는 cifar10, caltech101, imagenet 과 같이 범용적으로 쓰이는 데이터를 쉽게 다운로드 받아 이용할 수 있게 해준다는 점입니다. 상식으로 알아두시면 좋습니다!
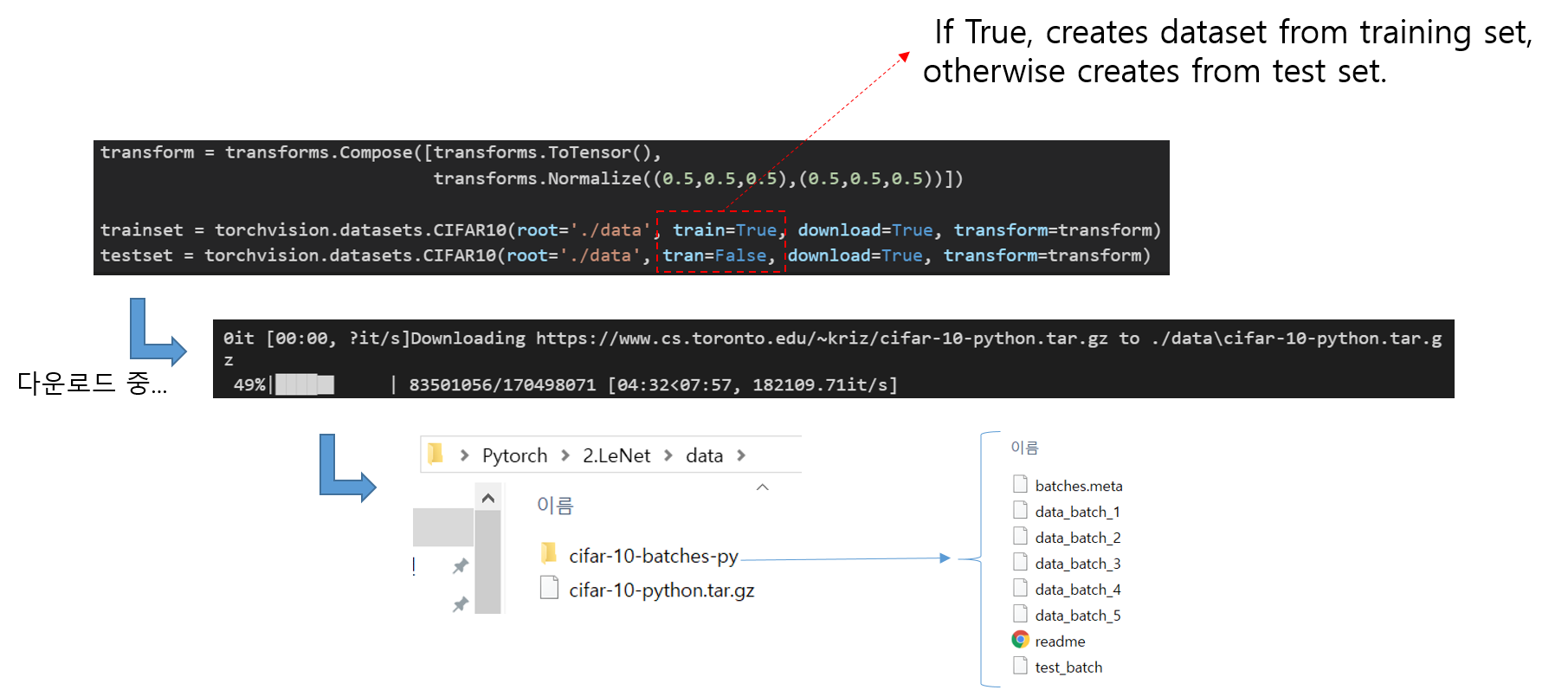
3. DataLoader
- At the heart of PyTorch data loading utility is the torch.utils.data.DataLoader class.
- 딥러닝에서 이미지를 load 하기 위해서는 batchsize, num_workers 등의 사전 정보들을 정의해야합니다. (※torch.utils.data.DataLoader가 이미지를 GPU에 업로드 시켜주는 코드가 아니라, 사전 정보들을 정의하는 역할만 한다는 것을 알아두세요!)
- image_datasets[x]: 예를 들어, image_datasets['train']인 경우 train 폴더에 해당하는 클래스들의 이미지 경로를 설정해줍니다.
- batch_size: 학습을 위한 batch size 크기를 설정해줍니다.
- shuffle: 이미지 데이터를 불러들일 때, shuffle을 적용 여부를 설정해줍니다.
- num_workers: 바로 아래에서 따로 설명
- 아래 코드 역시 dataloaders라는 dictionary 형태의 변수를 for 문으로 생성하는 코드 입니다.

[num_workers]
- 학습 이미지를 GPU에 할당시켜 주기 위해서는 CPU의 조력이 필요합니다. 즉, CPU가 학습 이미지를 GPU에 올려주는 역할을 하는 것이죠.
- 좀 더 구체적으로 말하자면, CPU에서 process 생성해 학습 이미지를 GPU에 업로드 시켜주는 방식입니다.
- num_workers는 CPU가 GPU에 이미지를 업로드 할 때, 얼마나 많은 subprocess를 이용할지를 결정하는 인자(argument)라고 생각하시면 됩니다.
- how many subprocesses to use for data loading. 0 means that the data will be loaded in the main process. (default: 0)
(↓↓↓process 관련해서 정리해 놓은 글↓↓↓)
https://89douner.tistory.com/150
1.Process와 CPU scheduling
안녕하세요~ 이번시간에는 CPU의 스펙중 가장 큰 부분을 차지하는 코어와 스레드라는 개념에 대해서 알아보도록 할게요! 이번 시간은 다른 시간과는 다르게 C언어의 지식이 어느정도 있어야 이
89douner.tistory.com
- 만약 num_workers를 적게 설정하면 어떻게 될까요?
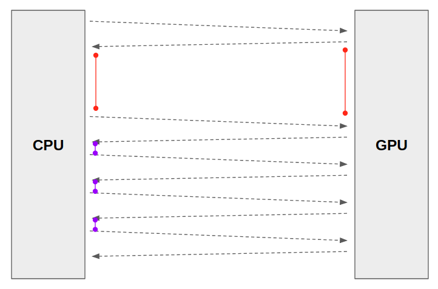
- num_workers를 0으로 설정했을 때 (=a main process), CPU가 하나의 이미지를 GPU에 업로드 하는 시간을 1초라고 가정해보겠습니다.
- 이 때, 업로드된 이미지를 GPU에서 처리 (for CNN training) 를 하는 것이 0.1초라고 가정한다면, 다음 이미지를 업로드 할 때 까지 0.9초 동안 GPU는 놀게(idle)됩니다. (아래 "그림14"에서 빨간색 간격 → CPU에서 GPU로 이미지 데이터를 넘기기 위해 수행되는 전처리 과정)
- 결국 CPU에서 GPU로 이미지를 넘겨주는 작업을 빠르게 증가시키기 위해서는 여러 subprocess를 이용해 이미지들을 GPU에 업로드 시켜주어야 합니다. 다시 말해, 다수의 process를 이용해서 CPU에서 GPU로 이미지 데이터를 넘기기 위한 전처리 시간을 축소시켜주는 것이죠.
- 이렇게 num_workers를 증가하여 GPU에 이미지를 업로드 시키는 속도가 빨라지면, GPU가 놀지 않고 열심히 일하게 될 것입니다. → GPU 사용량(이용률)이 증가하게 된다고도 할 수 있습니다.
- More num_workers would consume more memory usage but is helpful to speed up the I/O process.
- 하지만, CPU가 GPU에 이미지를 업로드 시켜주는 역할은 수 많은 CPU의 역할 중 하나입니다.
- 즉, num_workers를 너무 많이 설정해주어 CPU코어들을 모두 dataload에 사용하게 되면, CPU가 다른 중요한 일들을 못하게 되는 상황이 발생되는 것이죠.
- CPU의 코어 개수는 물리적으로 한정되어 있습니다.
(↓↓↓Core(코어)에 대한 개념을 정리한 글↓↓↓)
https://89douner.tistory.com/151
2.Core 그리고 CPU,Memory,OS간의 관계 (32bit 64bit; x86, x64)
안녕하세요~ CPU를 보시면 x86, x64 아키텍처라는 걸 본적있으시죠? 폴더갖은 곳에서도 x86, x64 폴더가 따로 존재하는것도 본적있으실거에요! 이번 시간에는 x86, x64가 어떤 개념인지 알아보기 위해 C
89douner.tistory.com
- num_workers를 어떻게 설정하면 좋은지에 대해서는 pytorch forum에서도 다양한 의견들이 나오고 있습니다.
https://discuss.pytorch.org/t/guidelines-for-assigning-num-workers-to-dataloader/813
Guidelines for assigning num_workers to DataLoader
I realize that to some extent this comes down to experimentation, but are there any general guidelines on how to choose the num_workers for a DataLoader object? Should num_workers be equal to the batch size? Or the number of CPU cores in my machine? Or to
discuss.pytorch.org
- 보통 코어 개수의 절반 정도로 num_workers를 설정하는 경우도 있지만, 보통 batch size를 어떻게 설정해주냐에 따라서 num_workers를 결정해주는 경우가 많습니다.
- 경험적으로 batch_size가 클 때, num_workers 부분도 크게 잡아주면 out of memory 에러가 종종 발생해서, num_workers 부분을 줄이거나, batch_size 부분을 줄였던 것 같습니다. (이 부분은 차후에 다시 정리해보도록 하겠습니다.)
※num_workers에 대한 설명은 아래 reference를 참고했습니다.
https://jybaek.tistory.com/799
DataLoader num_workers에 대한 고찰
Pytorch에서 학습 데이터를 읽어오는 용도로 사용되는 DataLoader는 torch 라이브러리를 import만 하면 쉽게 사용할 수 있어서 흔히 공식처럼 잘 쓰고 있습니다. 다음과 같이 같이 사용할 수 있겠네요. fr
jybaek.tistory.com
- torch.utils.data.Dataloader를 통해 생성한 dataloaders 정보들을 출력하면 아래와 같습니다.

4. GPU에 업로드 될 이미지 확인하기
앞서 "torch.utils.data.DataLoader"를 통해 이미지를 GPU에 올릴 준비를 끝냈으니, 어떤 이미지들의 GPU에 올라갈 지 확인해보겠습니다.

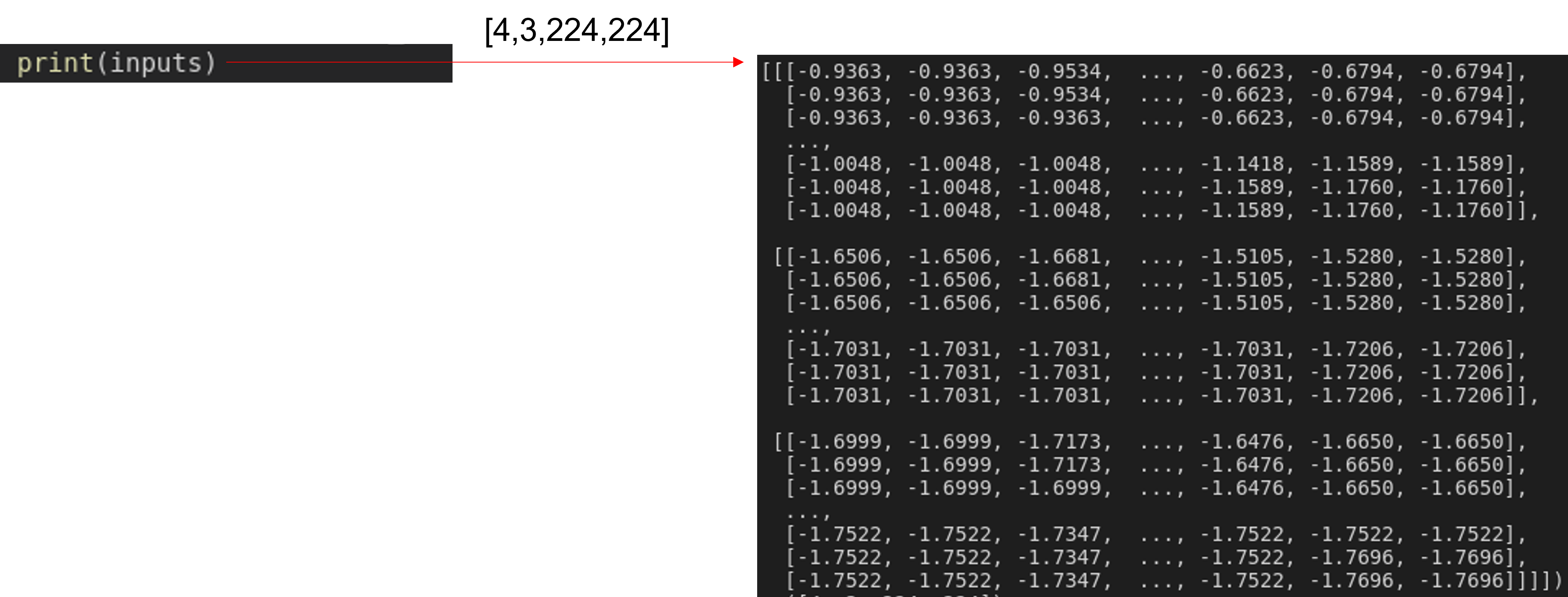
inputs에 어떤 정보들이 저장되어 있는지 알아보도록 하겠습니다.



- inputs 데이터에는 batch 단위로 이미지들이 저장되어 있는 것을 확인할 수 있습니다.
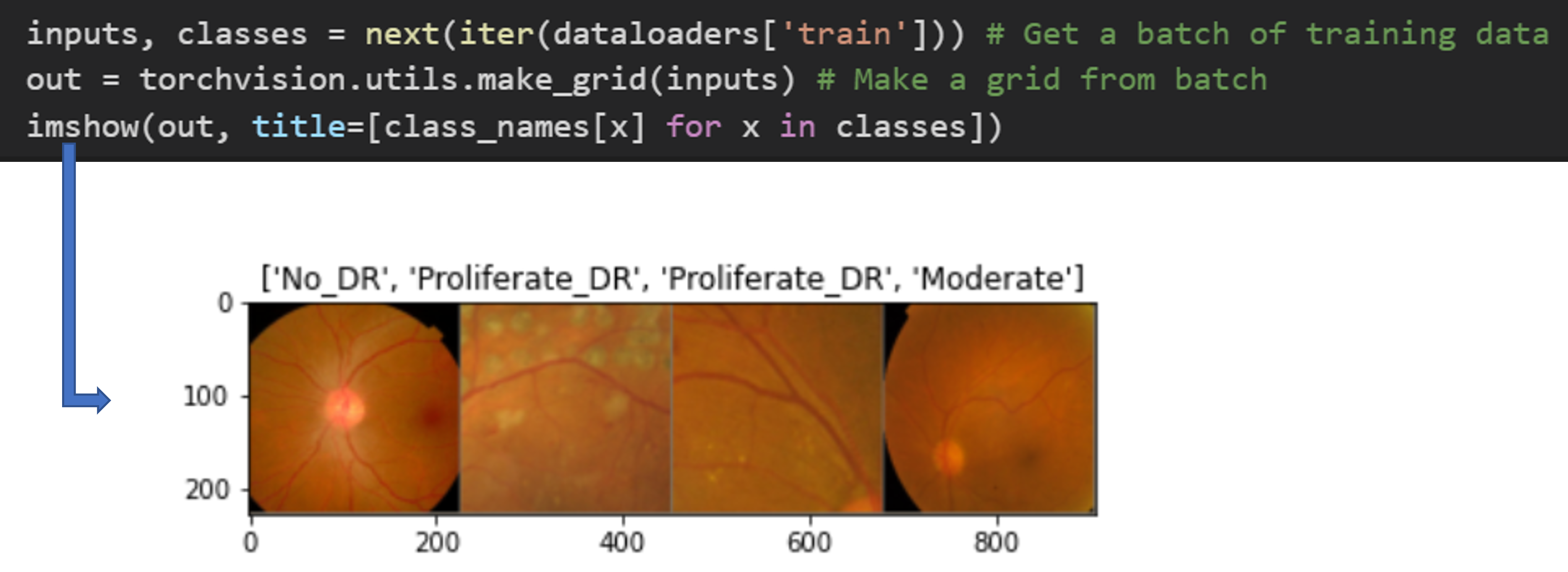
- 앞서 dataset_sizes['train'] 에서 확인 했듯이, train 원본 이미지 개수는 ‘2683’개 입니다.
- transformer.compose()를 통해 생성된 train 이미지 개수도 ‘2683’개 이다.
- imshow를 통해 생성된 이미지를 봤을 때, data augmentation에 의해 데이터 수가 늘어난게 아니라, 본래 2683개의 데이터 자체내에서 augmentation이 적용된 것 같습니다. 다시 말해, training dataset의 (절대)개수는 data augmentation을 적용했다고 해서 늘어나는 것이 아닙니다. (imshow 함수는 이 글 제일 아래 있습니다)
- 결국, (inputs, classes) 가 CNN 입장에서 (학습 이미지 데이터, 라벨) 정보를 담고 있다고 볼 수 있겠네요.
- 하지만, 딥러닝 입장에서 중복된 데이터는 학습을 위해 큰 의미가 없을 가능성이 높습니다. 그래서 이미지A 5장이 있는것과, 이미지 A에 5가지 augmentation 적용된 것을 학습한다고 했을 때, 딥러닝 입장에서는 후자의 경우 더 많은 데이터가 있다고 볼 수 있습니다.
- 그래서 위와 같이 첫 번째 epoch의 첫 번째 iteration에서 잡힌 4개(batch) 이미지에 적용된 augmentation과, 두 번째 iteration에서 잡힌 4개(batch) 이미지에 적용된 augmentation과 다르기 때문에 결국 epoch을 여러 번 진행해주게되면, 다양한 조합으로 data augmentation이 적용되기 때문에 데이터수가 늘어났다고 볼 수 있게 됩니다.
- 그래서 이와 같은 방식에서 data augmentation을 적용해 (딥러닝 관점에서 봤을 때) 데이터 개수를 늘리려면 epoch을 늘려줘야합니다. (왜냐하면 앞서 transforms.compose에서 봤듯이 augmetnation이 적용될 때 augmetnation의 정도가 random or 확률적으로 적용되기 때문입니다.)
5. Upload to GPU (Feat. torch.cuda)
앞서 "torch.utils.data.DataLoader"를 통해 이미지를 GPU에 올릴 준비를 끝냈으니, 이번에는 실제로 GPU에 이미지를 올리는 코드를 소개하겠습니다.
Pytorch는 torch.cuda 패키지를 제공하여 pytorch와 CUDA를 연동시켜 GPU를 이용할 수 있게 도와줍니다.
(↓↓↓CUDA 관련 설명↓↓↓)
https://89douner.tistory.com/158
3.GPGPU와 CUDA (feat.cuDNN)
안녕하세요~ 이번글은 GPGPU라는 개념과 CUDA를 소개하면 GPU구조를 가볍게 살펴볼거에요. CPU는 다양한 시스템 자원(ex; I/O device)를 제어해야하고 복잡한 명령들을 처리해야하기 때문에 연산을 위한
89douner.tistory.com
1) Pytorch와 GPU가 연동되었는지 확인
Pytorch를 설치하실 때 CUDA도 같이 설치하신걸 기억하시나요?
(↓↓↓아나콘다 가상환경에 pytorch 설치하는 방법 (with CUDA) ↓↓↓)
https://89douner.tistory.com/74
5. 아나콘다 가상환경으로 tensorflow, pytorch 설치하기 (with VS code IDE, pycharm 연동)
안녕하세요~ 이번시간에는 아나콘다를 통해 2개의 가상환경을 만들고 각각의 가상환경에서 pytorch, tensorflow를 설치하는법을 배워볼거에요~ Pytorch: Python 3.7버전/ CUDA 10.1 버전/ Pytorch=1.4버전 Tensorf..
89douner.tistory.com
CUDA가 정상적으로 pytorch와 연동이 되어 있는지 확인하기 위해서는 아래 코드로 확인해봐야 합니다.

- torch.cuda: "torch.cuda" is used to set up and run CUDA operations.
- It keeps track of the currently selected GPU, and all CUDA tensors you allocate will by default be created on that device. ← 아래 그림(코드)에서 설명
- torch.cuda.is_avialable(): CUDA 사용이 가능 하다면 true값을 반환해 줍니다.
- 메인보드에는 GPU slot이 있습니다. 만약 slot이 4개가 있으면 4개의 GPU를 사용할 수 있게 됩니다. 해당 slot의 번호는 0,1,2,3 인데, 어느 slot에 GPU를 설치하느냐에 따라 GPU 넘버가 정해집니다. (ex: GPU 0 → 0번째 slot에 설치된 GPU)
- cuda:0 이 의미하는 바는 0번째 slot에 설치된 GPU를 뜻합니다.
- if 문에 의해 CUDA 사용이 가능하다면 torch.device("cuda:0")으로 세팅됩니다.
- torch.device: "torch.device" contains a device type ('cpu' or 'cuda') and optional device ordinal for the device type.
- torch.device("cuda:0") 을 실행하면 0번째 slot에 있는 GPU를 사용하겠다고 선언하게 됩니다.
- device
- train 함수에 있는 일부 코드를 통해 미리 device의 쓰임새를 말씀드리겠습니다.
- 앞서 "inputs"이라는 변수에 (batch_size, 3, 224, 224) 정보가 있다는 걸 확인할 수 있었습니다.
- inputs 변수를 GPU에 올리기 위해 아래와 같은 "to(device)" 함수를 이용하면 됩니다. (한 가지 더 이야기 하자면 학습을 위해 딥러닝 모델도 GPU에 올려야 하는데, 이때도 "to(device)" 함수를 이용합니다. 이 부분은 나중에 model 부분에서 설명하도록 하겠습니다)
inputs = inputs.to(device)
labels = labels.to(device)
※ 배경지식으로 GPU와 관련된 pytorch 코드들 몇 가지를 살펴보도록 하겠습니다.
(↓↓↓아래 링크의 설명을 정리한 글이니 아래 글을 참고하시는게 더 편하실 듯 합니다↓↓↓)
https://jeongwookie.github.io/2020/03/24/200324-pytorch-cuda-gpu-allocate/
Pytorch 특정 GPU 사용하기
나는 많은 딥러닝 프레임워크 중 Pytorch와 MxNet을 자주 사용하는 편이다.그런데, 연구실 사람들과 GPU 서버를 함께 쓰다 보니 어떤 GPU가 현재 available한지 알아야 할 필요가 있었다. 원래는 시간대
jeongwookie.github.io
2) 현재 GPU 개수, 사용중인 GPU 파악

- torch.cuda.device_count(): 현재 메인보드에서 이용가능한 GPU 개수
- torch.cuda.current_device(): 현재 사용중인 GPU 정보
- Current cuda device:2 → 3번째 slot에 있는 GPU 사용중
- torch.cuda.get_device_name(device): 현재 사용하고 있는 GPU 모델명
3) 사용할 GPU 변경하기 (or 사용한 GPU 수동 설정하기)
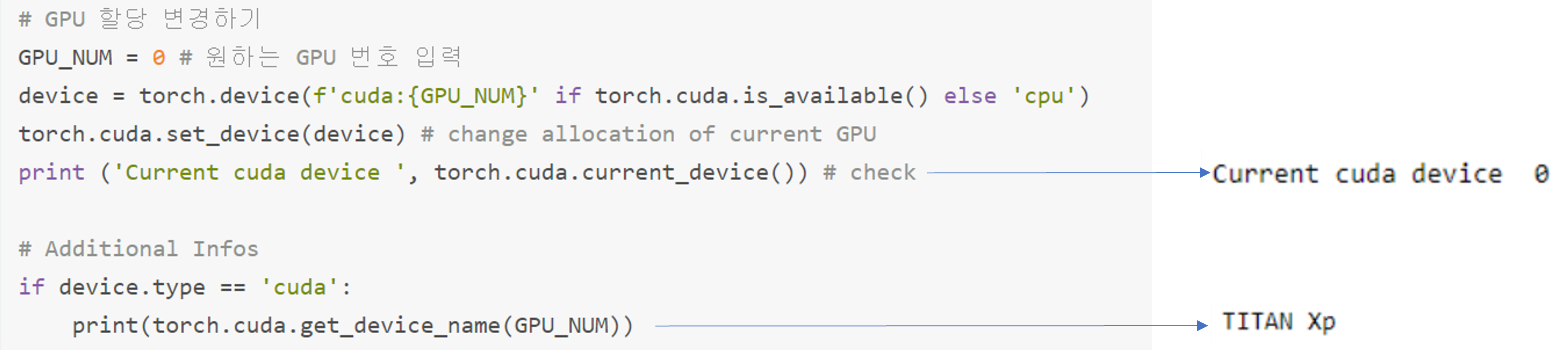
- torch.cuda.set_device(device): 사용할 GPU 세팅
- "그림23"과 비교하면, 사용중인 GPU index가 0번으로 변경된 것을 확인 할 수 있습니다 ← 첫 번째 slot에 있는 GPU 사용
지금까지 설명한 내용이 pytorch에서 이미지 데이터를 로드할 때 필요한 내용들이었습니다.
최종코드는 아래와 같습니다.
# Data augmentation and normalization for training
# Just normalization for validation
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = 'data/hymenoptera_data'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# Get a batch of training data
inputs, classes = next(iter(dataloaders['train']))
# Make a grid from batch
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])
'Pytorch > 2.CNN' 카테고리의 다른 글
| 5.Loss function, Optimizer, Learning rate policy (0) | 2021.07.27 |
|---|---|
| 4. Transfer Learning (Feat. pre-trained model) (0) | 2021.07.27 |
| 3. CNN 구현 (2) | 2021.07.27 |
| 2. Data preprocessing (Feat. Augmentation) (0) | 2021.07.27 |
| 코드 참고 사이트 (0) | 2021.07.02 |