지난 글에서 torchvision.transforms를 설명하면서 pytorch가 기본적인 augmentation 기법을 제공해준다고 언급한바 있습니다.
하지만, 기본적인 augmentation 외에도 다양한 영역에서 특수하게 사용하는 독특한 augmentation 기법들이 존재합니다. 예를 들어, Chest X-ray 데이터에는 N-CLAHE라는 독특한 전처리 기법이 있는데, 이러한 전처리 기법은 pytorch에서 기본으로 제공되고 있지 않습니다.
그러므로 별도의 augmentation 패키지를 이용하여 pytorch에 적용해야 합니다. (← transforms.Compose에 연동)
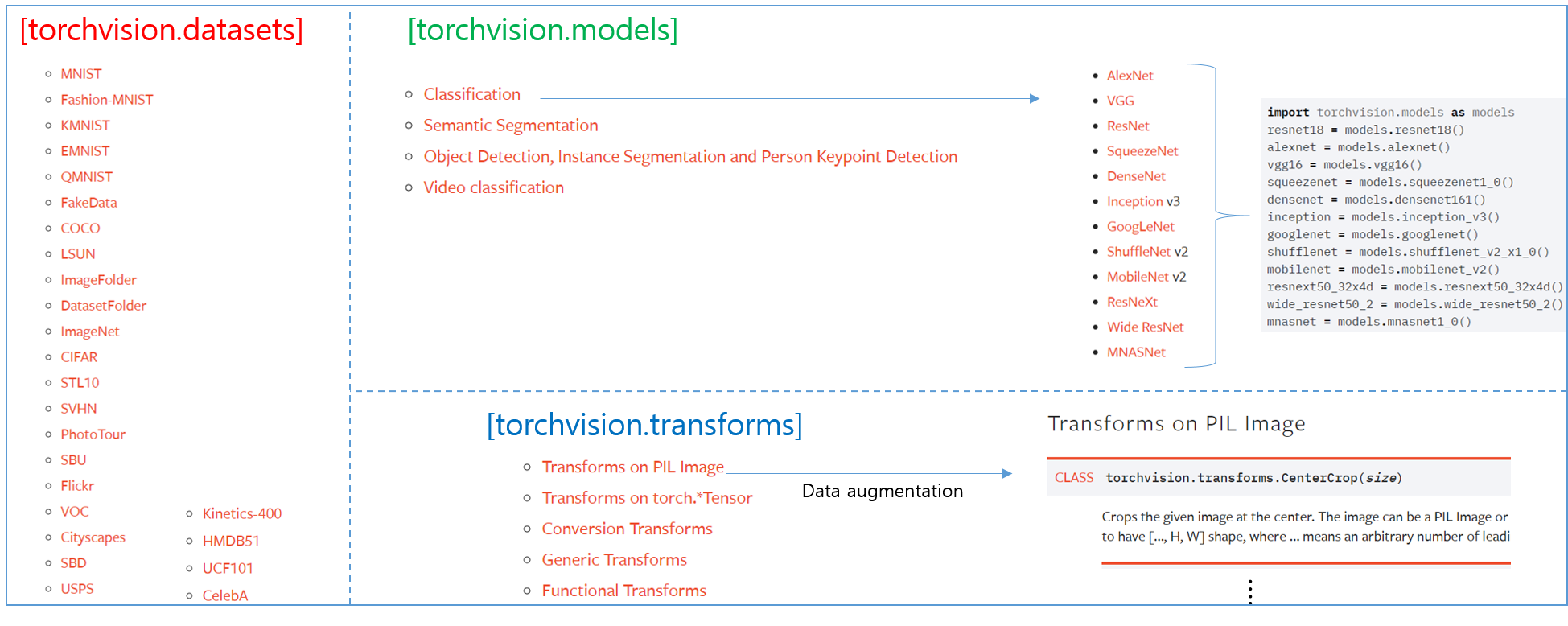
from torchvision import datasets, models, transforms
위의 코드를 보면 torchvision에서 transforms, datasets 이라는 패키지가 사용되었다는걸 확인할 수 있습니다. Pytorch에는 torchvision이라는 패키지를 이용해 다양한 computer vision 관련 task를 수행할 수 있습니다. 각각의 패키지들 (datasets, transforms, models) 에 대해서는 위의 코드를 분석하면서 같이 설명하도록 하겠습니다.
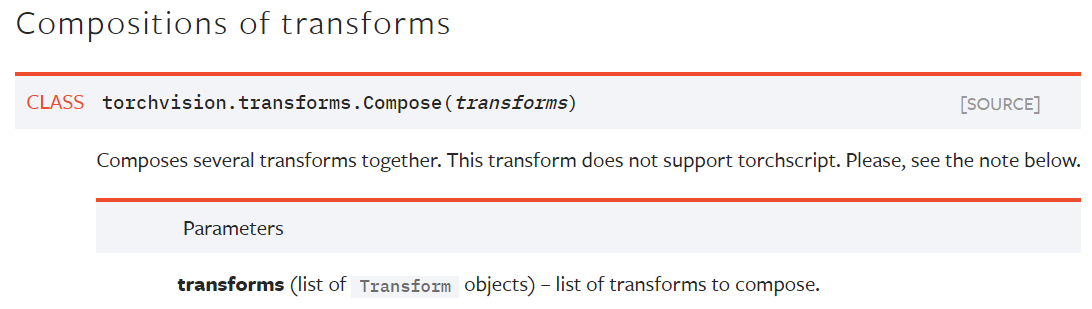
위의 코드를 살펴보면 compose 함수인자에 transforms 객체들의 list를 입력 받습니다.
이것이 의미하는 바가 무엇일까요? 계속해서 알아보도록 하겠습니다.
그림2
그림3
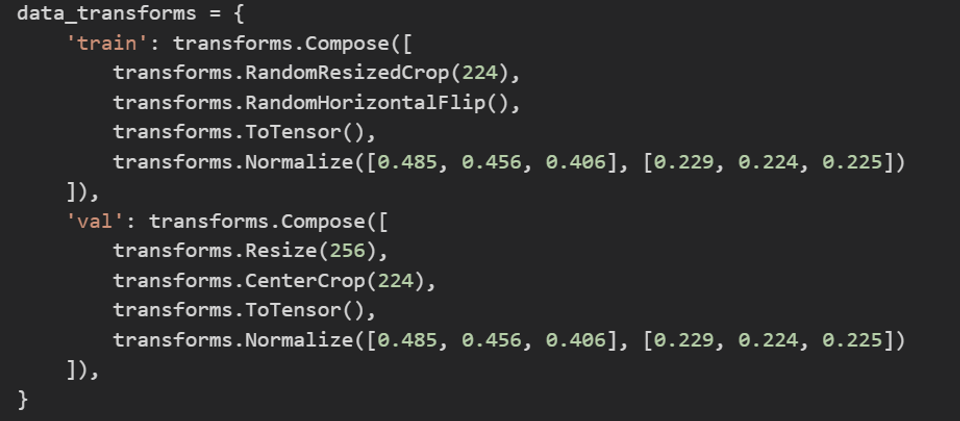
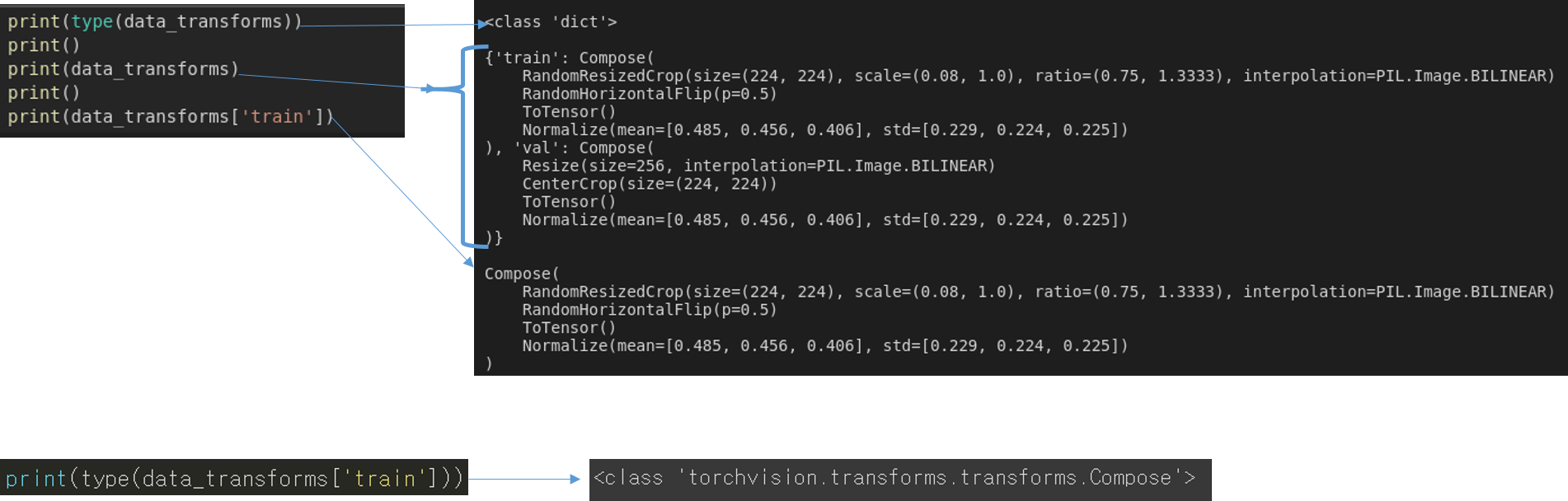
data_transforms 자체는 dictionary로 정의되었습니다.
그리고 각 key에 해당 하는 value 값은 클래스 객체 Compose인 것을 알 수 있습니다.
Compose 객체에 다양한 인자 값들이 포함되어 있는데, 이 인자 값들이 augmentation이 적용되는 순서라고 보시면 됩니다.
EX) data_tranforms['train']의 경우
RandomResizedCrop 수행
scale→ Specifies the lower and upper bounds for the random area of the crop, before resizing. The scale is defined with respect to the area of the original image.
ratio → lower and upper bounds for the random aspect ratio of the crop, before resizing.
RandomHorizontalFlip 수행
p=0.5 → 50%의 확률로 RandomHorizontalFlip 실행
ToTensor 수행
처음 로드되는 이미지 형태를 딥러닝 학습 format에 맞는 tensor 형태로 변경
Converts a PIL Image or numpy.ndarray (H x W x C) in the range [0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0]
Normalize 수행
이미지 전처리 (Preprocessing)
Normalization에 들어가는 값들이 어떻게 계산되는지는 아래 PPT를 참고해주세요.
dataset_size 변수는 딥러닝 모델(CNN)을 학습 시킬 때 epoch 단위의 loss or accuracy 산출을 위해 이용됩니다. (자세한 설명은 train을 구현하는 함수에서 설명하도록 하겠습니다)
그림9
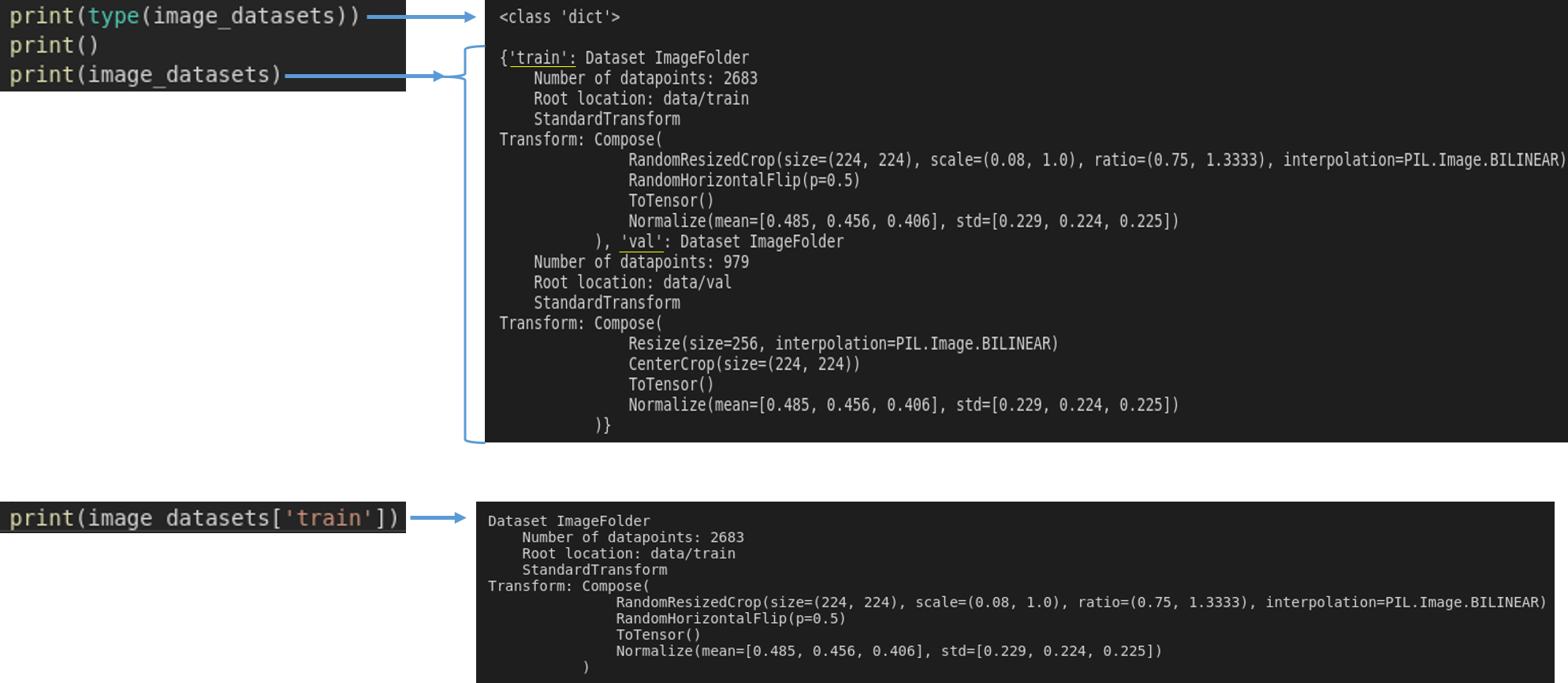
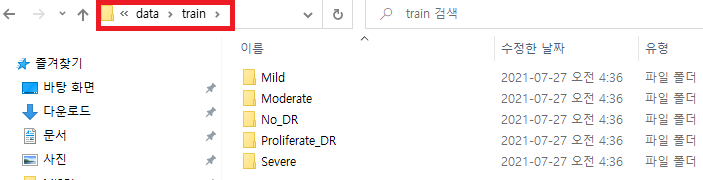
train 폴더를 보면 총 5개의 class가 있다는걸 확인 할 수 있습니다.
image_datasets['train'].classes을 이용하면 아래 폴더를 기준으로 class 명들을 string 형태로 사용할 수 있게 됩니다.
그림10
그림11
※이번 코드에서는 포함되어 있진 않지만, datasets 패키지의 첫 번째 활용도는 cifar10, caltech101, imagenet 과 같이 범용적으로 쓰이는 데이터를 쉽게 다운로드 받아 이용할 수 있게 해준다는 점입니다. 상식으로 알아두시면 좋습니다!
그림12
3. DataLoader
At the heart of PyTorch data loading utility is the torch.utils.data.DataLoaderclass.
딥러닝에서 이미지를 load 하기 위해서는 batchsize, num_workers 등의 사전 정보들을 정의해야합니다. (※torch.utils.data.DataLoader가 이미지를 GPU에 업로드 시켜주는 코드가 아니라, 사전 정보들을 정의하는 역할만 한다는 것을 알아두세요!)
image_datasets[x]: 예를 들어, image_datasets['train']인 경우 train 폴더에 해당하는 클래스들의 이미지 경로를 설정해줍니다.
batch_size: 학습을 위한 batch size 크기를 설정해줍니다.
shuffle: 이미지 데이터를 불러들일 때, shuffle을 적용 여부를 설정해줍니다.
num_workers: 바로 아래에서 따로 설명
아래 코드 역시 dataloaders라는 dictionary 형태의 변수를 for 문으로 생성하는 코드 입니다.
그림13
[num_workers]
학습 이미지를 GPU에 할당시켜 주기 위해서는 CPU의 조력이 필요합니다. 즉, CPU가 학습 이미지를 GPU에 올려주는 역할을 하는 것이죠.
좀 더 구체적으로 말하자면, CPU에서 process 생성해 학습 이미지를 GPU에 업로드 시켜주는 방식입니다.
num_workers는 CPU가 GPU에 이미지를 업로드 할 때, 얼마나 많은 subprocess를 이용할지를 결정하는 인자(argument)라고 생각하시면 됩니다.
howmanysubprocessesto use for data loading. 0 means that the data will be loaded in the main process. (default: 0)
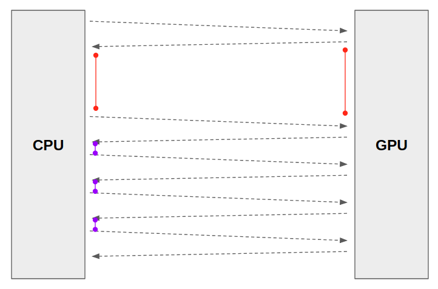
num_workers를 0으로 설정했을 때 (=a main process), CPU가 하나의 이미지를 GPU에 업로드 하는 시간을 1초라고 가정해보겠습니다.
이 때, 업로드된 이미지를 GPU에서 처리 (for CNN training) 를 하는 것이 0.1초라고 가정한다면, 다음 이미지를 업로드 할 때 까지 0.9초 동안 GPU는 놀게(idle)됩니다. (아래 "그림14"에서 빨간색 간격 → CPU에서 GPU로 이미지 데이터를 넘기기 위해 수행되는 전처리 과정)
결국 CPU에서 GPU로 이미지를 넘겨주는 작업을 빠르게 증가시키기 위해서는 여러 subprocess를 이용해 이미지들을 GPU에 업로드 시켜주어야 합니다. 다시 말해, 다수의 process를 이용해서 CPU에서 GPU로 이미지 데이터를 넘기기 위한 전처리 시간을 축소시켜주는 것이죠.
이렇게 num_workers를 증가하여 GPU에 이미지를 업로드 시키는 속도가 빨라지면, GPU가 놀지 않고 열심히 일하게 될 것입니다. → GPU 사용량(이용률)이 증가하게 된다고도 할 수 있습니다.
More num_workers would consume more memory usage but is helpful to speed up the I/O process.
그림14. 이미지 출처: https://jybaek.tistory.com/799
하지만, CPU가 GPU에 이미지를 업로드 시켜주는 역할은 수 많은 CPU의 역할 중 하나입니다.
즉, num_workers를 너무 많이 설정해주어 CPU코어들을 모두 dataload에 사용하게 되면, CPU가 다른 중요한 일들을 못하게 되는 상황이 발생되는 것이죠.
보통 코어 개수의 절반 정도로 num_workers를 설정하는 경우도 있지만, 보통 batch size를 어떻게 설정해주냐에 따라서 num_workers를 결정해주는 경우가 많습니다.
경험적으로 batch_size가 클 때, num_workers 부분도 크게 잡아주면 out of memory 에러가 종종 발생해서, num_workers 부분을 줄이거나, batch_size 부분을 줄였던 것 같습니다. (이 부분은 차후에 다시 정리해보도록 하겠습니다.)
torch.utils.data.Dataloader를 통해 생성한 dataloaders 정보들을 출력하면 아래와 같습니다.
그림15
4. GPU에 업로드 될 이미지 확인하기
앞서 "torch.utils.data.DataLoader"를 통해 이미지를 GPU에 올릴 준비를 끝냈으니, 어떤 이미지들의 GPU에 올라갈 지 확인해보겠습니다.
그림16
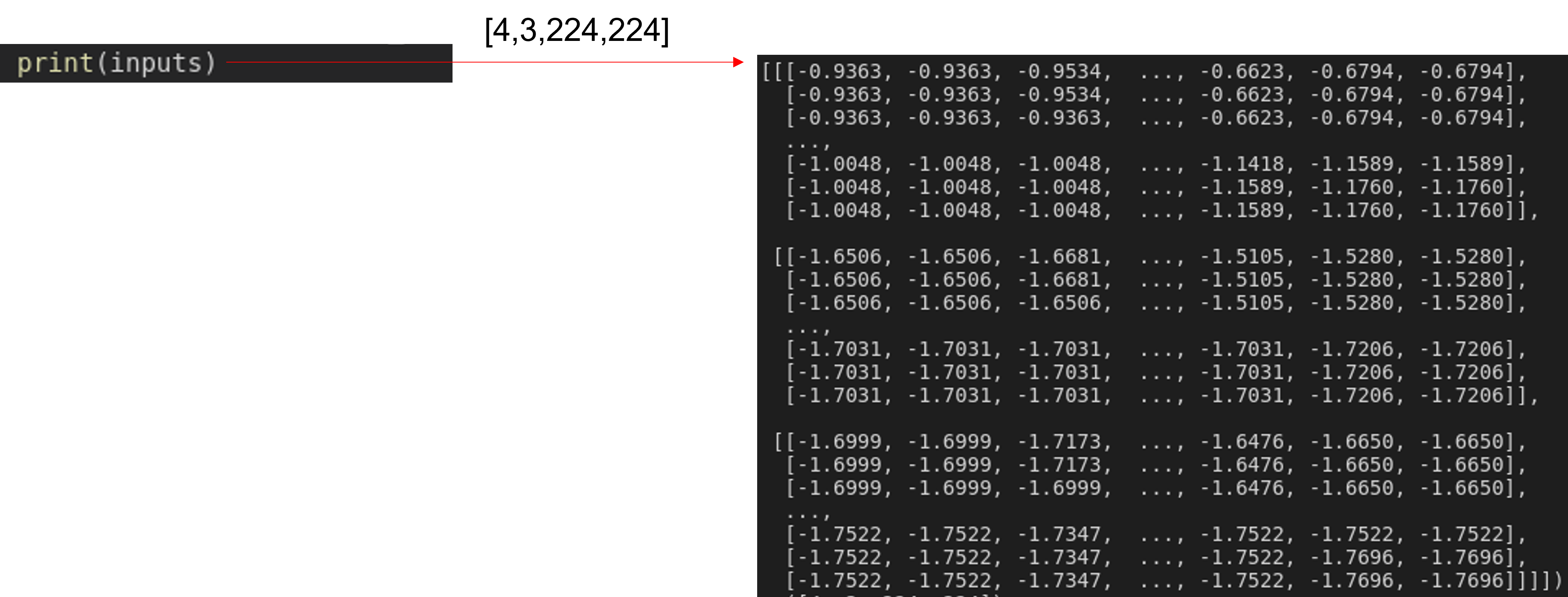
inputs에 어떤 정보들이 저장되어 있는지 알아보도록 하겠습니다.
그림17
그림18
그림19
inputs 데이터에는 batch 단위로 이미지들이 저장되어 있는 것을 확인할 수 있습니다.
그림20
앞서 dataset_sizes['train'] 에서 확인 했듯이, train 원본 이미지 개수는 ‘2683’개 입니다.
transformer.compose()를 통해 생성된 train 이미지 개수도 ‘2683’개 이다.
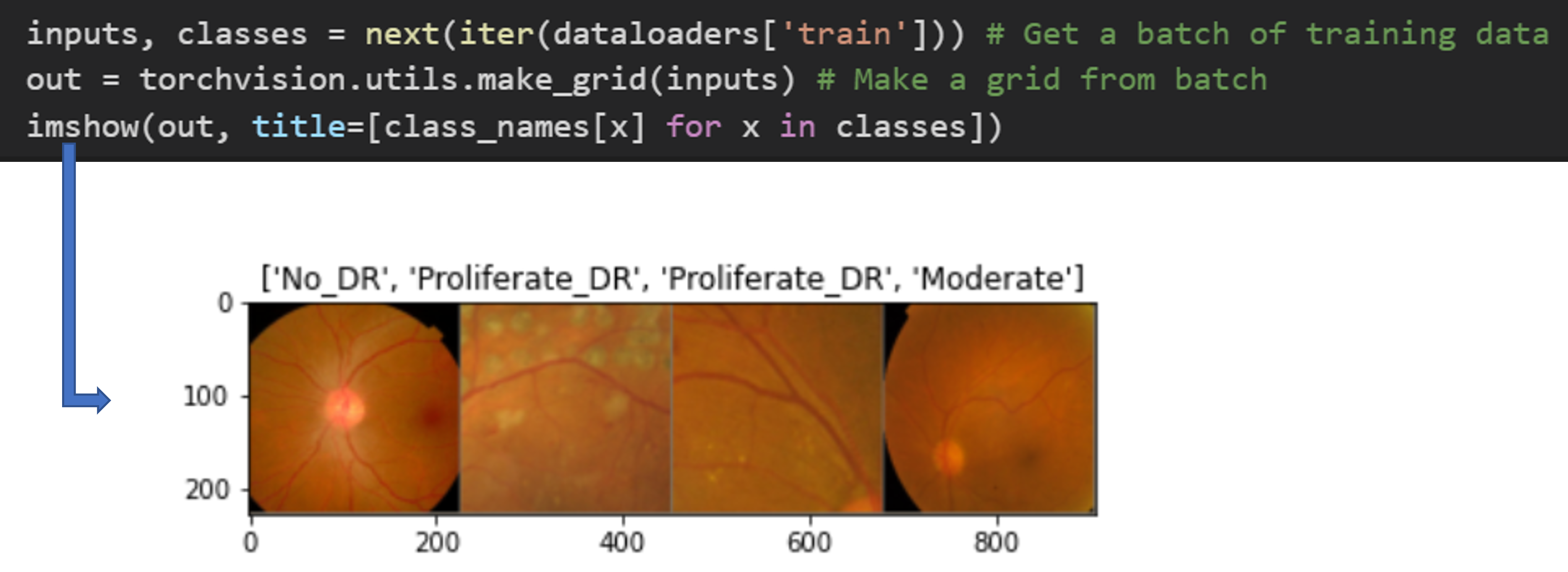
imshow를 통해 생성된 이미지를 봤을 때, data augmentation에 의해 데이터 수가늘어난게아니라, 본래 2683개의 데이터 자체내에서 augmentation이 적용된 것 같습니다. 다시 말해, training dataset의 (절대)개수는 data augmentation을 적용했다고 해서 늘어나는 것이 아닙니다. (imshow 함수는 이 글 제일 아래 있습니다)
결국, (inputs, classes) 가 CNN 입장에서 (학습 이미지 데이터, 라벨) 정보를 담고 있다고 볼 수 있겠네요.
그림21
하지만, 딥러닝 입장에서 중복된 데이터는 학습을 위해 큰 의미가 없을 가능성이 높습니다. 그래서 이미지A 5장이 있는것과, 이미지 A에 5가지 augmentation 적용된 것을 학습한다고 했을 때, 딥러닝 입장에서는 후자의 경우 더 많은 데이터가 있다고 볼 수 있습니다.
그래서 위와 같이 첫 번째 epoch의 첫 번째 iteration에서 잡힌 4개(batch) 이미지에 적용된 augmentation과, 두 번째 iteration에서 잡힌 4개(batch) 이미지에 적용된 augmentation과 다르기 때문에 결국 epoch을 여러 번 진행해주게되면, 다양한 조합으로 data augmentation이 적용되기 때문에 데이터수가 늘어났다고 볼 수 있게 됩니다.
그래서 이와 같은 방식에서 data augmentation을 적용해 (딥러닝 관점에서 봤을 때) 데이터 개수를 늘리려면 epoch을 늘려줘야합니다. (왜냐하면 앞서 transforms.compose에서 봤듯이 augmetnation이 적용될 때 augmetnation의 정도가 random or 확률적으로 적용되기 때문입니다.)
5. Upload to GPU (Feat. torch.cuda)
앞서 "torch.utils.data.DataLoader"를 통해 이미지를 GPU에 올릴 준비를 끝냈으니, 이번에는 실제로 GPU에 이미지를 올리는 코드를 소개하겠습니다.
Pytorch는 torch.cuda 패키지를 제공하여 pytorch와 CUDA를 연동시켜 GPU를 이용할 수 있게 도와줍니다.
CUDA가 정상적으로 pytorch와 연동이 되어 있는지 확인하기 위해서는 아래 코드로 확인해봐야 합니다.
그림22
torch.cuda: "torch.cuda" is used to set up and run CUDA operations.
It keeps track of the currently selected GPU, and all CUDA tensors you allocate will by default be created on that device. ← 아래 그림(코드)에서 설명
torch.cuda.is_avialable(): CUDA 사용이 가능 하다면 true값을 반환해 줍니다.
메인보드에는 GPU slot이 있습니다. 만약 slot이 4개가 있으면 4개의 GPU를 사용할 수 있게 됩니다. 해당 slot의 번호는 0,1,2,3 인데, 어느 slot에 GPU를 설치하느냐에 따라 GPU 넘버가 정해집니다. (ex: GPU 0 → 0번째 slot에 설치된 GPU)
cuda:0 이 의미하는 바는 0번째 slot에 설치된 GPU를 뜻합니다.
if 문에 의해 CUDA 사용이 가능하다면 torch.device("cuda:0")으로 세팅됩니다.
torch.device: "torch.device" contains a device type ('cpu' or 'cuda') and optional device ordinal for the device type.
torch.device("cuda:0") 을 실행하면 0번째 slot에 있는 GPU를 사용하겠다고 선언하게 됩니다.
device
train 함수에 있는 일부 코드를 통해 미리 device의 쓰임새를 말씀드리겠습니다.
앞서 "inputs"이라는 변수에 (batch_size, 3, 224, 224) 정보가 있다는 걸 확인할 수 있었습니다.
inputs 변수를 GPU에 올리기 위해 아래와 같은 "to(device)" 함수를 이용하면 됩니다. (한 가지 더 이야기 하자면 학습을 위해 딥러닝 모델도 GPU에 올려야 하는데, 이때도 "to(device)" 함수를 이용합니다. 이 부분은 나중에 model 부분에서 설명하도록 하겠습니다)
그림23. 이미지 출처: https://jeongwookie.github.io/2020/03/24/200324-pytorch-cuda-gpu-allocate/
torch.cuda.device_count(): 현재 메인보드에서 이용가능한 GPU 개수
torch.cuda.current_device(): 현재 사용중인 GPU 정보
Current cuda device:2 → 3번째 slot에 있는 GPU 사용중
torch.cuda.get_device_name(device): 현재 사용하고 있는 GPU 모델명
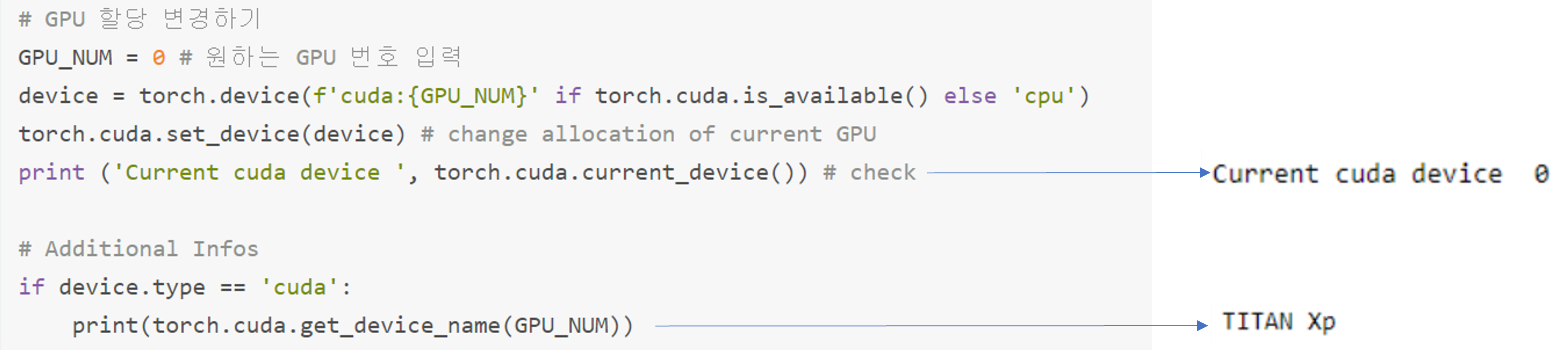
3) 사용할 GPU 변경하기 (or 사용한 GPU 수동 설정하기)
그림24. 이미지 출처: https://jeongwookie.github.io/2020/03/24/200324-pytorch-cuda-gpu-allocate/
torch.cuda.set_device(device): 사용할 GPU 세팅
"그림23"과 비교하면, 사용중인 GPU index가 0번으로 변경된 것을 확인 할 수 있습니다 ← 첫 번째 slot에 있는 GPU 사용
지금까지 설명한 내용이 pytorch에서 이미지 데이터를 로드할 때 필요한 내용들이었습니다.
최종코드는 아래와 같습니다.
# Data augmentation and normalization for training
# Just normalization for validation
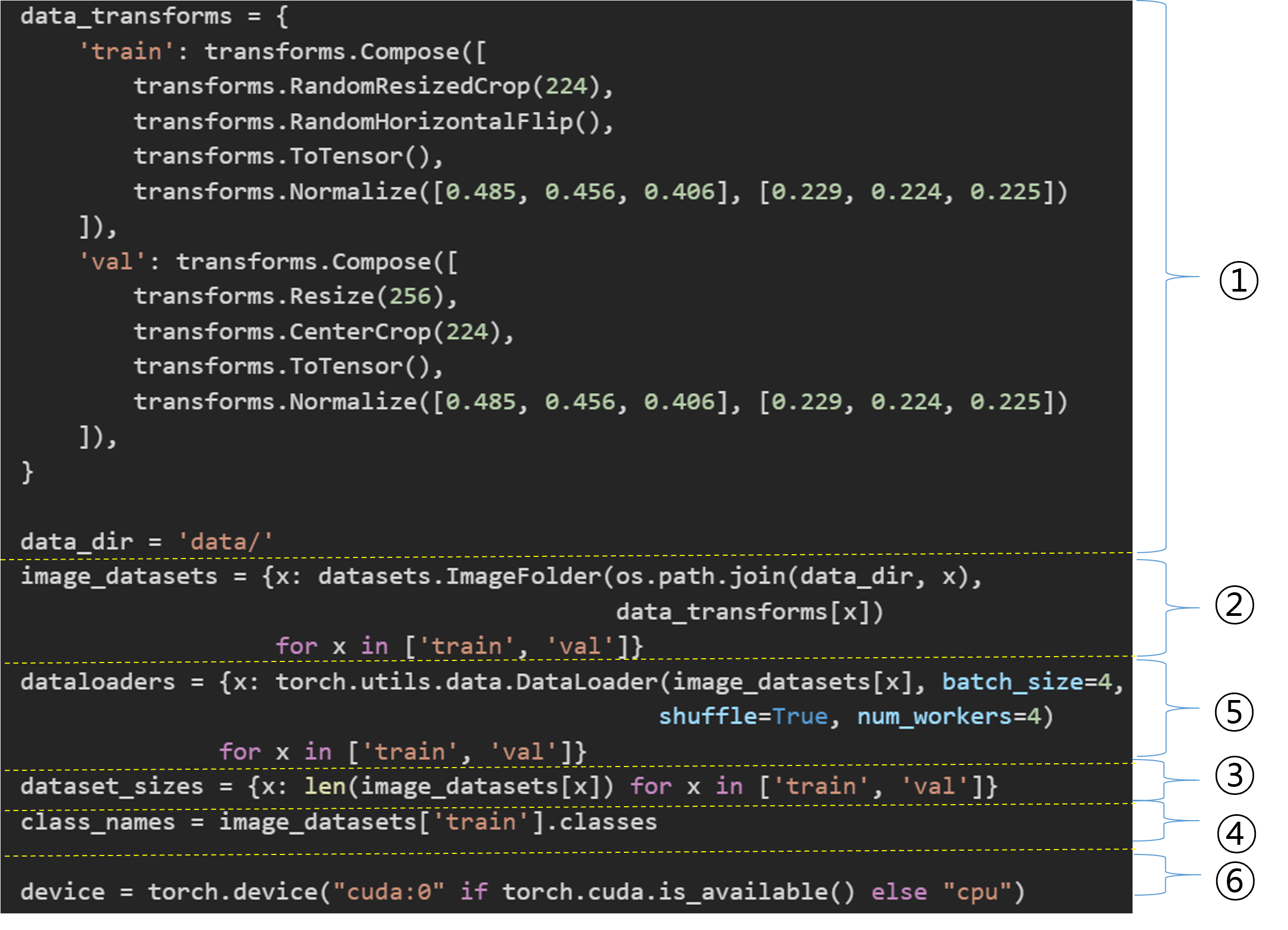
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = 'data/hymenoptera_data'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# Get a batch of training data
inputs, classes = next(iter(dataloaders['train']))
# Make a grid from batch
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])
실제로 많은 의료분야에서 UNet을 베이스 모델로 하여 병변들을 segmentation 하고 있습니다.
그러므로 의료분야에서 딥러닝 기반 segmentation 모델을 이용해보려는 분들은 UNet 구조를 이해하고 UNet논문에서 언급하고 있는 여러 용어들에 친숙해 질 필요가 있습니다.
그럼 지금부터 UNet 논문을 리뷰해보도록 하겠습니다.
0. Abstract
UNet에서 강조하고 있는 부분 중 하나는 강력한 data augmentation을 이용했다는 점입니다.
"contracting path to capture context and a symmetric expanding path"라는 문장은 아래와 "그림1"을 그대로 설명한 문장입니다. 아래 "그림1"을 보면 contracting path를 통해 context 정보(=features from almost last layers)를 구하고, contracting path 부분과 symmetric 한 expanding path를 통해 다시 원본 이미지 크기에 맞도록 (upsampling 후) segmentation (for precise localization) 을 진행하는 작업이 수행됩니다 (사실 이 부분은 FCN과 거의 다른 부분이 없습니다.)
FCN과 UNet의 차별점은 아래 "그림1"에서 같은 층(ex: contracting path 568×568×64 & expanding path 392×392×128)끼리 이어붙여주는 연산의 유무입니다. (좀 더 자세한 설명은 UNet 구조를 설명하는 부분에서 자세히 다루도록 하겠습니다.
"segmentation of neuronal structures in electron microscopic stacks" → "segmentation for stacks of serial images generated by EM (Electron Microscopy(=전자 현미경)).
그림1
UNet 모델은 ISBI cell tracking challenge 2015에 참가하여 주목을 받은 모델이기 때문에 해당 challenge 대회에서 사용한 데이터 셋을 사용했습니다. 해당 데이터 셋의 간단한 정보는 아래와 같습니다 (ISBI challenge에 대해서는 FCN 관련 글에서도 설명해놨으니 참고해주세요!)
Training time: 10 hours → "5. Conclusion"에서 알 수 있는 정보
GPU: NVidia Titan (6 GB) → "5. Conclusion"에서 알 수 있는 정보
1. Introduction
기존 CNN에 대해서 짧게 설명하고 있습니다.
AlexNet 소개
VGGNet 소개
2015년 당시에 CNN 최신 모델은 VGGNet 또는 GoogLeNet이었습니다.
기존 CNN은 보통 single classification task에 사용되었습니다.
하지만 biomedical image processing 분야에서는 한 이미지 내에 모든 pixel을 classification을 하는 segmentation task가 중요하게 사용되기도 합니다. (예를 들어, 암의 위치 또는 크기를 segmentation 할 필요가 있겠죠?)
ImageNet에 비해 (biomedical tasks을 위한) biomedical image 수가 충분하지 않다는 문제가 있습니다.
by reach = 손이 닿지 않는 곳에 = "가능성이 없는" 늬앙스
이러한 데이터 수 문제를 해결하기위해 (UNet 이전에) patch 기반의 학습 기법("Ciresan et al"="Sliding-window setup")을 이용해 data 수를 늘리려는 시도를 했습니다.
Sliding-window setup 방식은 FCN 글에서 설명해 놨으니 참고해주세요.
Sliding window 기반 딥러닝 segmentation 모델이 EM (Electron Microscopy: 전자현미경) segmentation 종류인 ISBI 2012 challenge 우승했습니다.
"Ciresan et al"="Sliding-window setup" 방식은 2가지의 문제점이 있는데, 이 부분도 FCN 글을 참조해주시길 바랍니다!
이 문단은 FCN에 대한 설명이므로 FCN 글을 참조해주세요!
successive layers = deconv layers
"그림1"에서 볼 수 있듯이 expanding path(=upsampling part) 를 보면 기존 FCN 보다 더 많은 conv filter channel들이 사용되었다는걸 확인 할 수 있습니다. 이를 통해 저자는 "propagate context information to higher resolutioin layer" 가 가능하다고 주장하고 있네요.
그림1
"segmentation map only contain ~ in the input image"→ segmentation map (=아래 "그림1"을 보면 최종 output결과를 segmentation map이라고 부름) 에는 입력 영상에서 전체 context를 "available"할 수 있는 pixel만 포함(=segmentation)된다고 합니다. → 이 부분은 그냥 segmentation map 결과가 context (의미 or 객체) 단위로 표현된다는 것으로 이해했습니다. 예를 들어, 아래 그림처럼 입력 이미지는 고양이의 질감이나 다양한 정보들을 확인 할 수 있는데 반해, segmentation map에서는 오로지 context 정보만 확인할 수 있습니다.
Valid part에 대한 정확한 의미는 잘 모르겠네요. Valid part만 보면 segmentation map을 의미하는거 같다가도, "valid part of each convolution"을 보면 convolution과 연관지어 해석해야 할 것 같기도합니다. Segmentation map에 적용되는 각각의 convolution이라고 해석해야하는건지.....
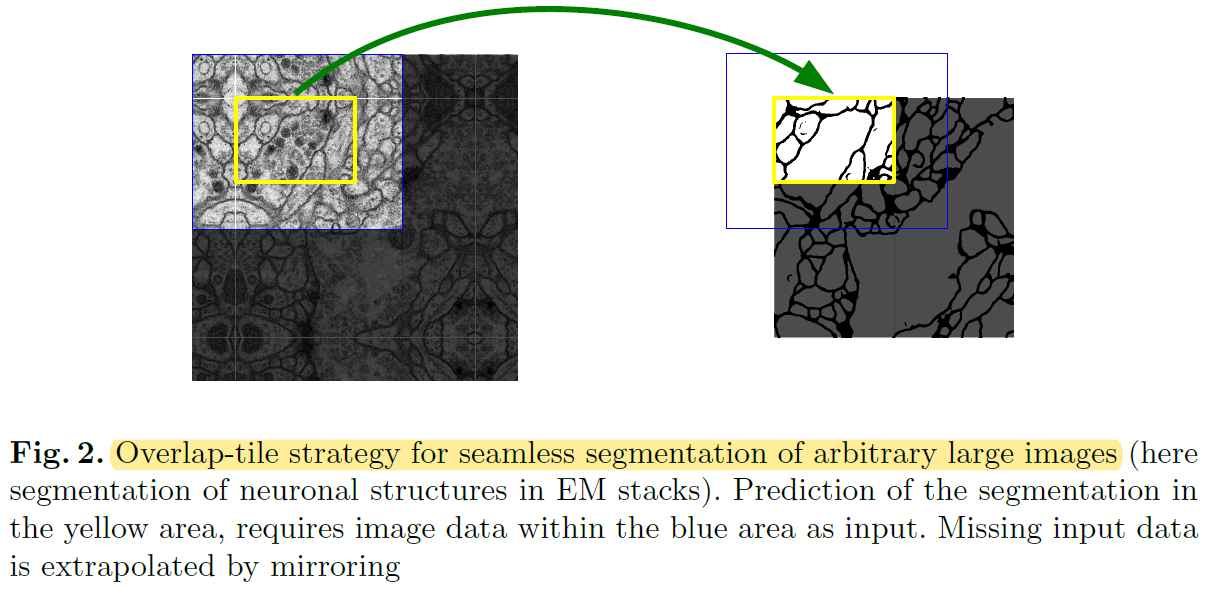
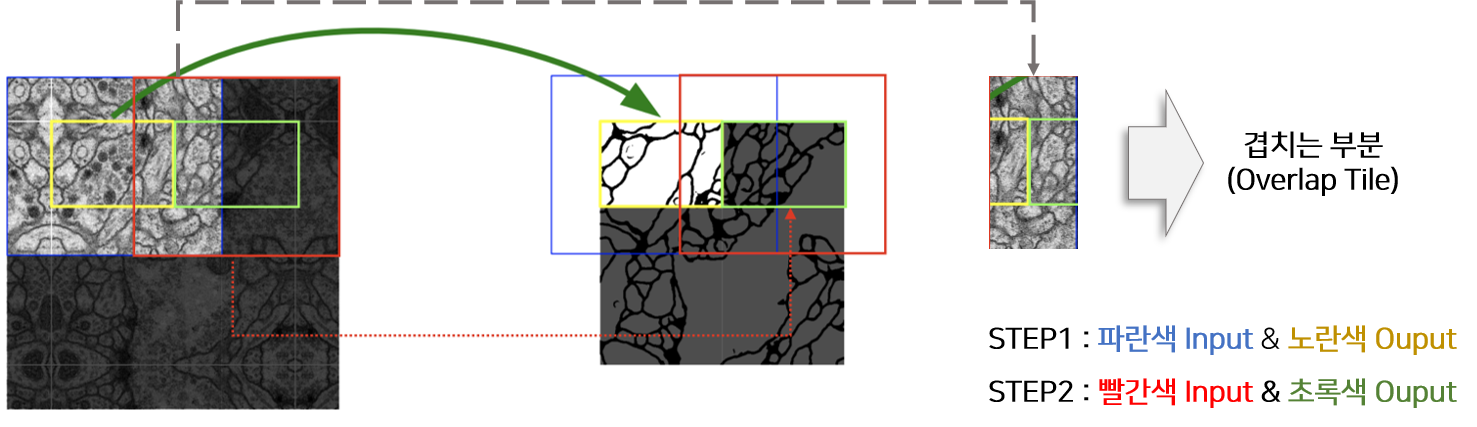
This strategy(=not using FC layer)는 입력 이미지 크기에 제한 받지 않고 (=arbitrarily large images) segmentation이 가능하게 만들었는데, over-tile strategy를 이용해 좀 더 seamless(=매끄러운) segmentation이 가능하게 만들었습니다.
지금부터 아래 "그림2(=over-tile strategy)"에 대해서 좀 더 자세히 설명 해보도록 하겠습니다.
그림2
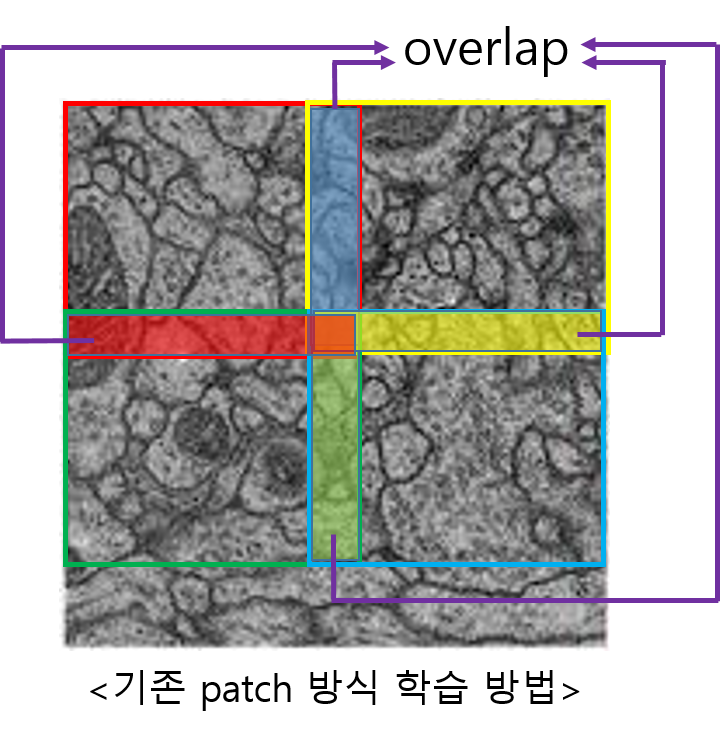
아래 "그림3"과 같이 기존의 patch 방식으로 학습하면overlapping되는 부분이 많이 생깁니다.
이러한 문제는computation의 redundancy를 증가시키기도 합니다.
Unet에서는 이러한 문제를 해결하기 위해 overlap-tile strategy를 적용시켰습니다.
그림3. 이미지 출처: http://brainiac2.mit.edu/isbi_challenge/home
Over-tile strategy를 설명하기에 앞서 “그림1”의 Unet구조를 보면 input size와 output size가 다릅니다.
다시 말해, 실제 segmentation 되는 부분은 input image의 일부분이라는 말과 같습니다. (→ 아래 "그림6"의 오른쪽 이미지 참고)
그림6
Overlap-tile strategy 을 이용하면 실제 segmentation 되는 부분은 overlapping이 안 되는 것을 알 수 있습니다. (이 부분 때문에 “seamless segmentation”이라는 표현을 쓴 건지....)
그림7
To predict the pixels in the border region of the image, the missing context is extrapolated by mirroring the input image.
the pixels in the border region of the image → input image의 주황색bounding box(=the border region)내부(in) pixel들
실제 segmentation되는 부분(=오른쪽 그림에서 “원본 이미지“)이 ground truth의 크기이기 때문에, input으로 들어가는 이미지에 추가 작업을 진행해줘야 합니다.
이 논문에서는 input size에 해당하는 빨간색 bounding box와 실제 segmentation size에 해당하는 주황색 bounding box를 뺀 나머지 부분을 “missing context”라 언급하고, mirroring 기법을 이용해 missing context 부분을 extrapolation(=추론) 하여 input image를 만들어 준다고 합니다.
그림8
이러한 over-tile strategy를 이용해서 input image resolution에 제한받지 않고 segmentation 학습이 가능해졌다고 말하고 있습니다.
그림9. 이미지출처: https://kuklife.tistory.com/119
Segmentation 학습을 위해 제한적인 training dataset을 갖고 있었기 때문에 excessive data augmentation을 진행해 학습 데이터 수를 증가시켰다고 합니다.
여기에서는 elastic deformation augmentation 방식을 설명했지만 "3.1. Data augmentation" 파트에서 실제로 학습에 적용된 다양한 augmentation 방식들을 소개하고 있기 때문에 추가적인 설명은 "3.1. Data augmentation" 파트에서 하도록 하겠습니다.
최근에는 "As for our tasks ~ the available training images"라는 말이 상식적이라 최근 논문에는 굳이 사용하지 않지만, 이 당시 (2015) 까지만 하더라도 data augmentation에 대한 언급을 한 문단으로 따로 해줬나보네요.
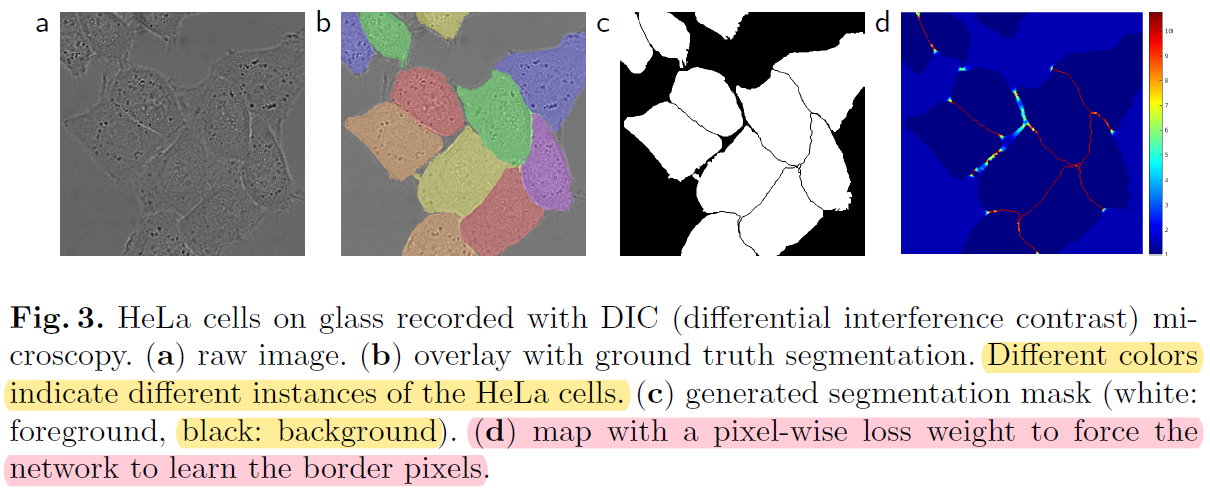
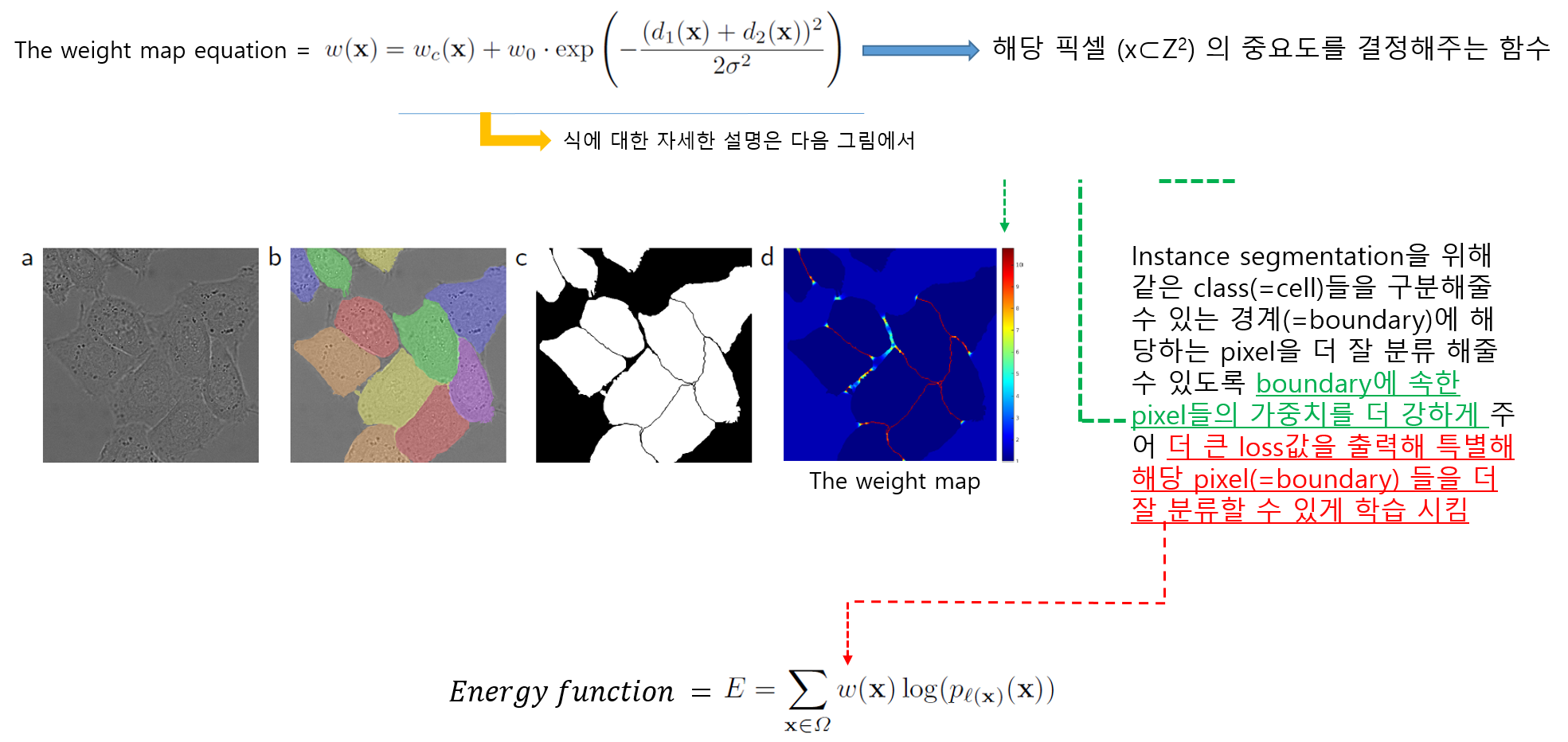
biomedical image segmentation (ex: cell segmentation) 같은 경우는 인접한 세포들간을 분리하는 segmentation을 적용하는 것이 쉽지 않습니다. (→ Instance segmentation)
(↓↓↓ Instance segmentation VS Semantic segmentation↓↓↓)
이 논문에서는 인접한 cell들 사이에 경계가 될 수 있는 background (=the separting background labels) 를 잘 segmentation 해줄 수 있도록 별도의 loss function을 사용했다고 합니다 (해당 부분은 "3.Training" 파트에서 자세히 설명하도록 하겠습니다)
UNet은 2D transmitted light datasets을 기반으로하는 (대표적인) 두 challenging 대회에서 기존 모델들과 큰 격차(=by a large margin)로 우승을 했다고 합니다. (Transmitted light microscopy = 투과 광선 현미경검사)
A 대회: Segmentation of neuronal structures in EM (Electron Microscopy: 전자현미경) stacks at ISBI 2012
B 대회: Light microscopy (=광선 현미경검사) images from the ISBI cell tracking challenge 2015
2. Network Architecture
UNet 구조는 앞에서 추상적으로 설명했기 때문에 이 부분에서는 좀 더 구체적으로 설명하도록 하겠습니다.
Contracting path
Two 3×3 Conv filter (stride=1) with zero padding of input feature map → feature map size-reduction → 2×2 max-pooling → feature map size-reduction (to Half)
이 과정을 반복해서 적용
Expansive path (Expansive path는 크게 세 단계로 나눌 수 있습니다.)
2x2 De-Conv filter that halves the number of feature channels. (아래 "그림10"에서 보라색 점선 화살표를 보면 input channel (=512)을 256으로 줄여주는걸 확인할 수 있습니다.)
Copy and Crop a → "concatenation with the correspondingly cropped feature map from the contracting path"
정확한건 아니지만 이 과정에서 앞서 언급한 mirroring이 적용된 부분이 제거 되는 것으로 추론됩니다. (어떻게 crop하는지 코드를 살펴봐야겠네요)
Copy and Concatentation: Contracting path에서 crop된 (104×104)×256 feature map을 Copy → 아래 "그림10" 기준으로 같은 층에 존재하는 expansive path의 (104×104)×256 feature map에 concatenation → Concatenation 결과: (104×104)×512 feature map 생성
Final layer: 388×388×64 feature map을 output segmentation map으로 만들어주기 위해, 1×1 conv filter를 이용해 388×388×2 feature map으로 만들어줌 (=mapping)
아래 "그림10"을 기준으로 보면 2는 classification해야 할 class 개수인 것 (binary classification: cell인지 아닌지(=background)) 같은데 아니라면 댓글 달아주시면 감사하겠습니다!
2×2 max-pooling을 적용하기 위해서 conv layer에 입력으로 들어오는 feature map size가 x, y축 모두 짝수가 되도록 고려해서, input title size를 설정해줘야 over-tile strategy가 잘 적용될 수 있다는 것을 언급하는 듯 합니다.
3. Training
Optimizer
Stochastic Gradient Descent (SGD)
Momentum: 0.99
Deep learning framework: Caffe
Batch: A single image
1) Loss function
UNet은 아래와 같은 loss function을 사용하고 있습니다.
논문에서 글로 설명하는 내용들을 그림으로 대체해서 설명해보도록 하겠습니다.
1-1) SoftMax
그림11. 이미지 출처: https://medium.com/hyunjulie/1%ED%8E%B8-semantic-segmentation-%EC%B2%AB%EA%B1%B8%EC%9D%8C-4180367ec9cb
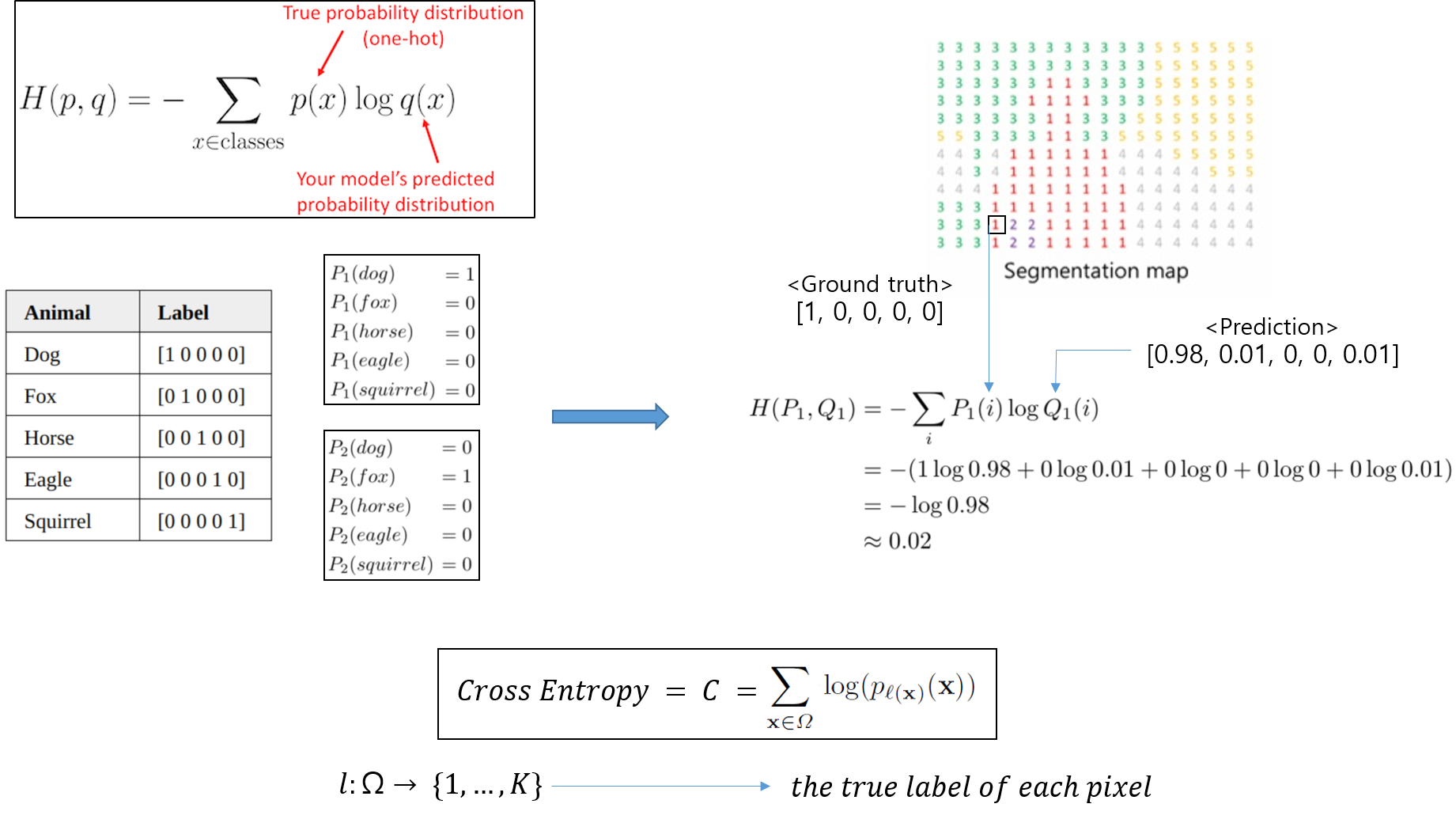
1-2) Cross-Entropy
그림12. 이미지 출처: https://naokishibuya.medium.com/demystifying-cross-entropy-e80e3ad54a8
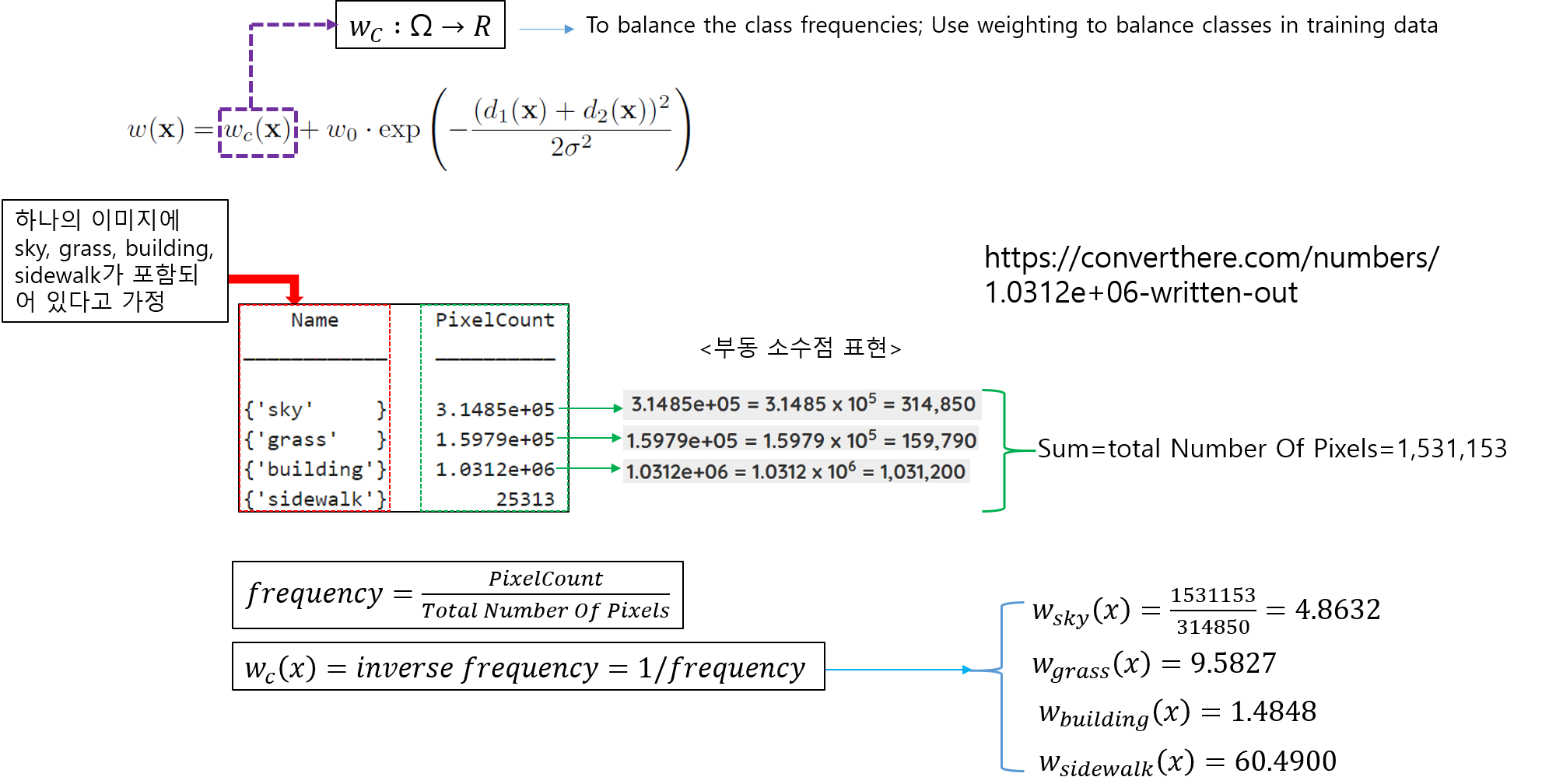
1-3) Weight Map
먼저 weight map equation 식 자체에 대한 concept 부터 이해하도록 하겠습니다.
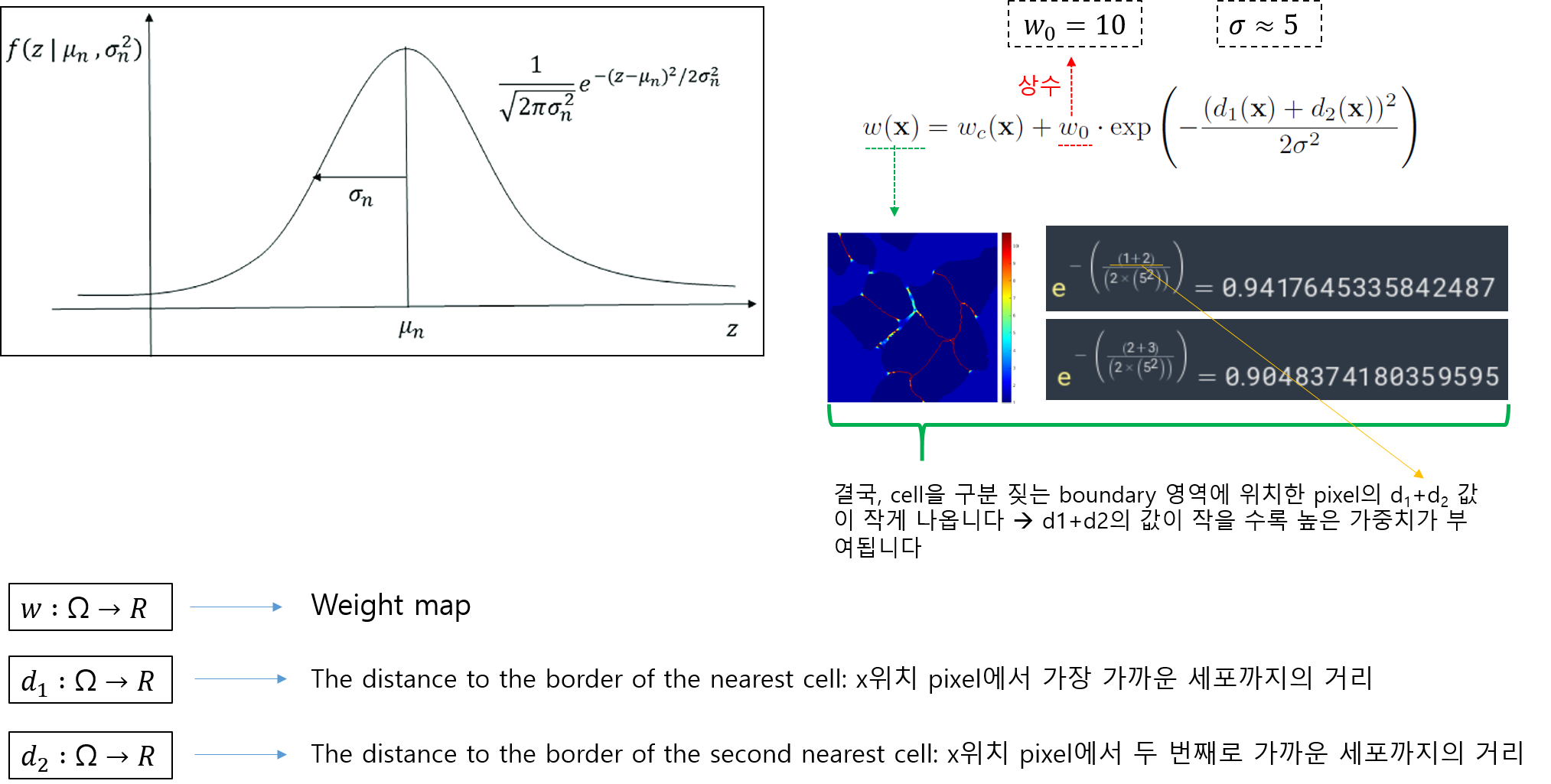
weight map equation 수식의 오른쪽 수식은 guassian distribution과 유사합니다.
개인적으로 gaussian function 수식과 weight map equation 수식의 오른쪽 수식이 어떤 관계가 있을 거라 생각 하는데, 그 이유는 이 논문에서는 σ 개념을 도입했기 때문입니다. 하지만, 좀 더 구체적인 설명은 하지 않고 있어서 해당 exp 수식이 정말 guassian function 개념을 기반으로 설명 될 수 있는지 잘 모르겠네요... (exp 수식을 왜 사용했는지 좀 더 알고 싶은데.... 시간이... 혹시 아시는 분 있으면 답글 달아주세요!)
그림15
2) Weight initialization
Gaussian distribution initialization (=standard deviation distribution)
Standard deviation: \(\sqrt{\frac{2}{N}}\)
N = conv filter size × conv filter channel
3.1 Data Augmentation
이 논문에서 언급하고 있는 data augmentation 방식은 총 가지 입니다.
Shift
Rotation
Gray value
Random elastic deformation
Random elasstic deformation에 대해서 다양하게 설명하고 있는데, 해당 설명은 아래 그림으로 대체하도록 하겠습니다.
이미지 출처: https://www.researchgate.net/figure/Training-data-augmentation-through-random-smooth-elastic-deformation-a-Upper-left-Raw_fig5_329716031
4. Experiments
이 부분에서는 UNet을 적용한 세 가지 task (3가지 dataset 종류)에 대해서 소개합니다. 세 가지 task에 대한 설명은 그냥 논문에 있던 글들을 요약해서 정리해 놓았습니다. 대신에 성능평가를 위해 사용한 evaluation 종류에 대해 자세히 설명하도록 해보겠습니다.
이 논문에서 UNet 모델을 이용해 3가지 segmentation task에 적용해봤다고 합니다.
First task: The segmentation of neuronal structures in electron microscopic (EM) recordings
Dataset: the EM segmentation challenge (at ISBI 2012)
20 training images "512×512" (from serial section transmission electron microscopy of the Drosophila first instar larva ventral nerve cord (VNC))
Drosophila: 초파리
Instar larval: 어린 유충
Ventral nerve cord: 복부 신경 코드
Other tasks: A cell segmentation task in light microscopic images (=A part of the ISBI cell tracking challenge 2014 and 2015)
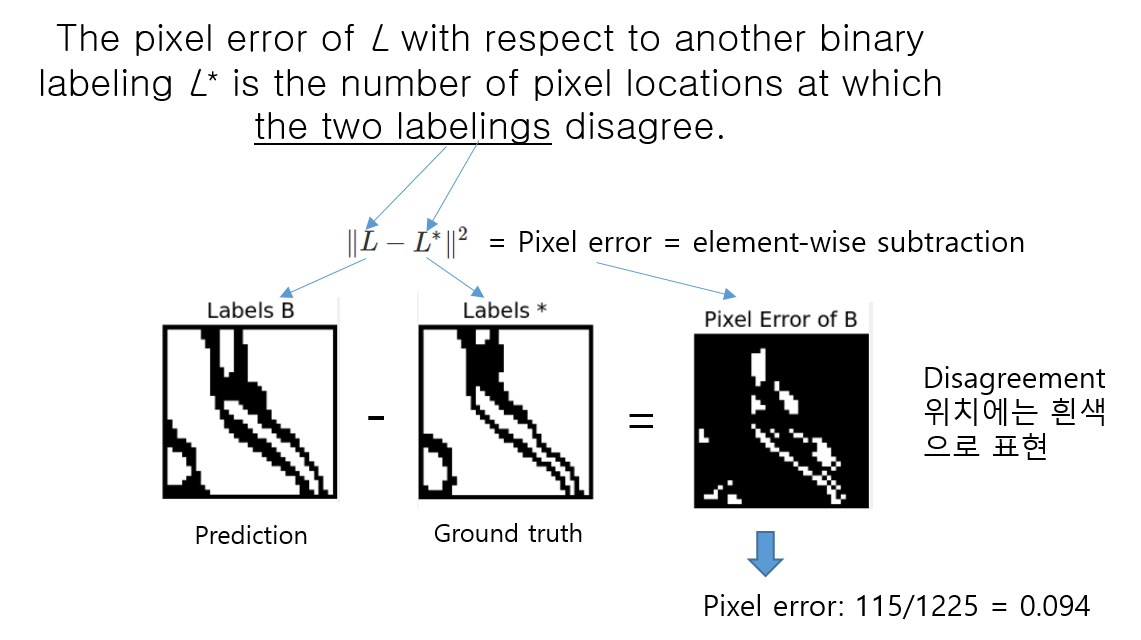
Pixel error는 prediction과 ground truth에 pixel마다 할당된 class들끼리 불일치하는 pixel들의 개수가 전체 pixel들을 기준으로 어느정도 비율이 되는지 알려주는 metric입니다.
이미지 출처: https://imagej.net/plugins/tws/topology-preserving-warping-error
Warping error와 Rand error는 digital topology error과 관련이 있는듯 합니다. 이 부분은 topology(위상수학)에 대한 이해를 기반으로 해석해야 하는데, 시간상 해당 부분을 살펴보지 못했습니다. 좀 더 디테일한 설명을 원하신다면 아래 reference를 참고해주시고, 추후에 시간이나면 설명해 놓도록 하겠습니다!