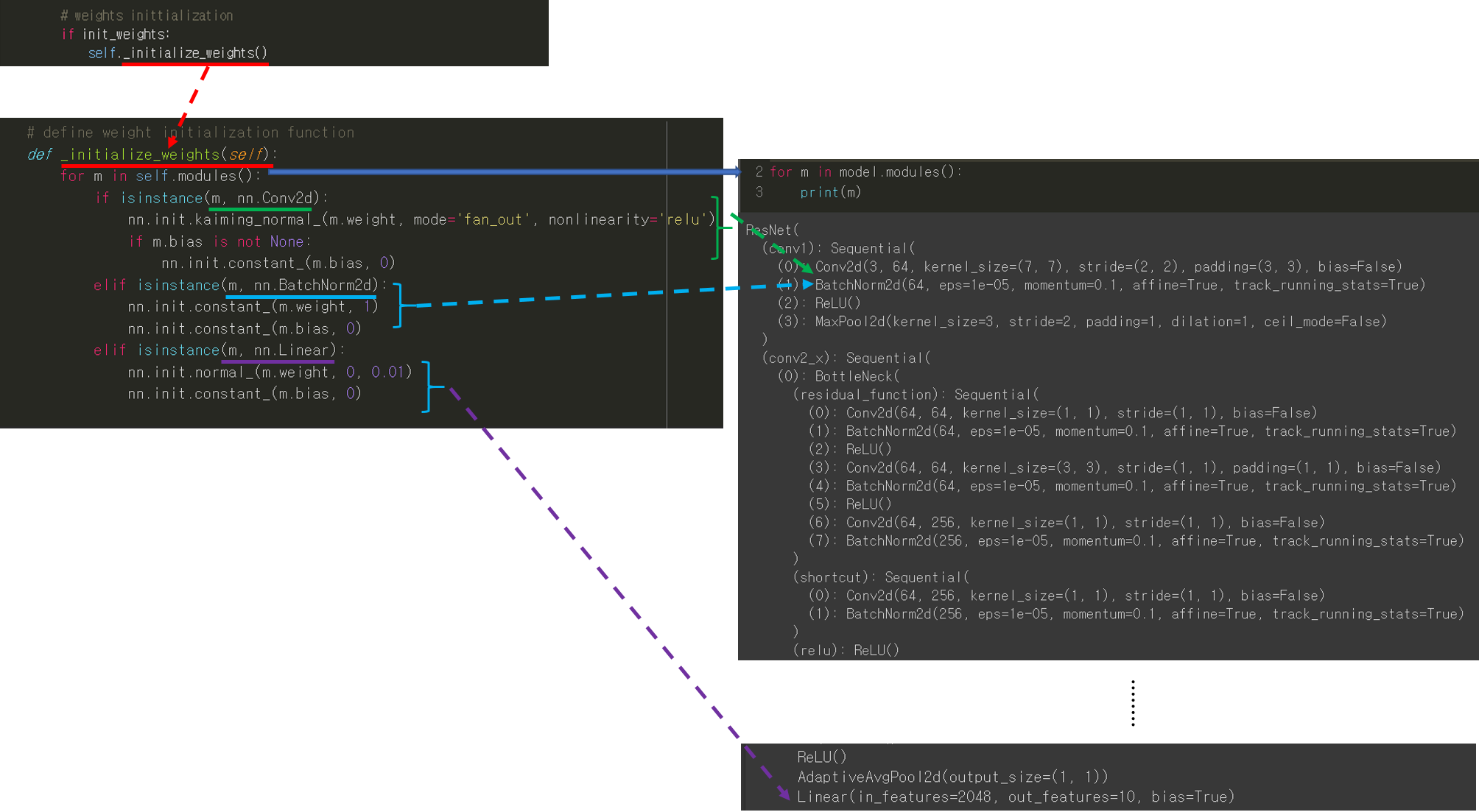
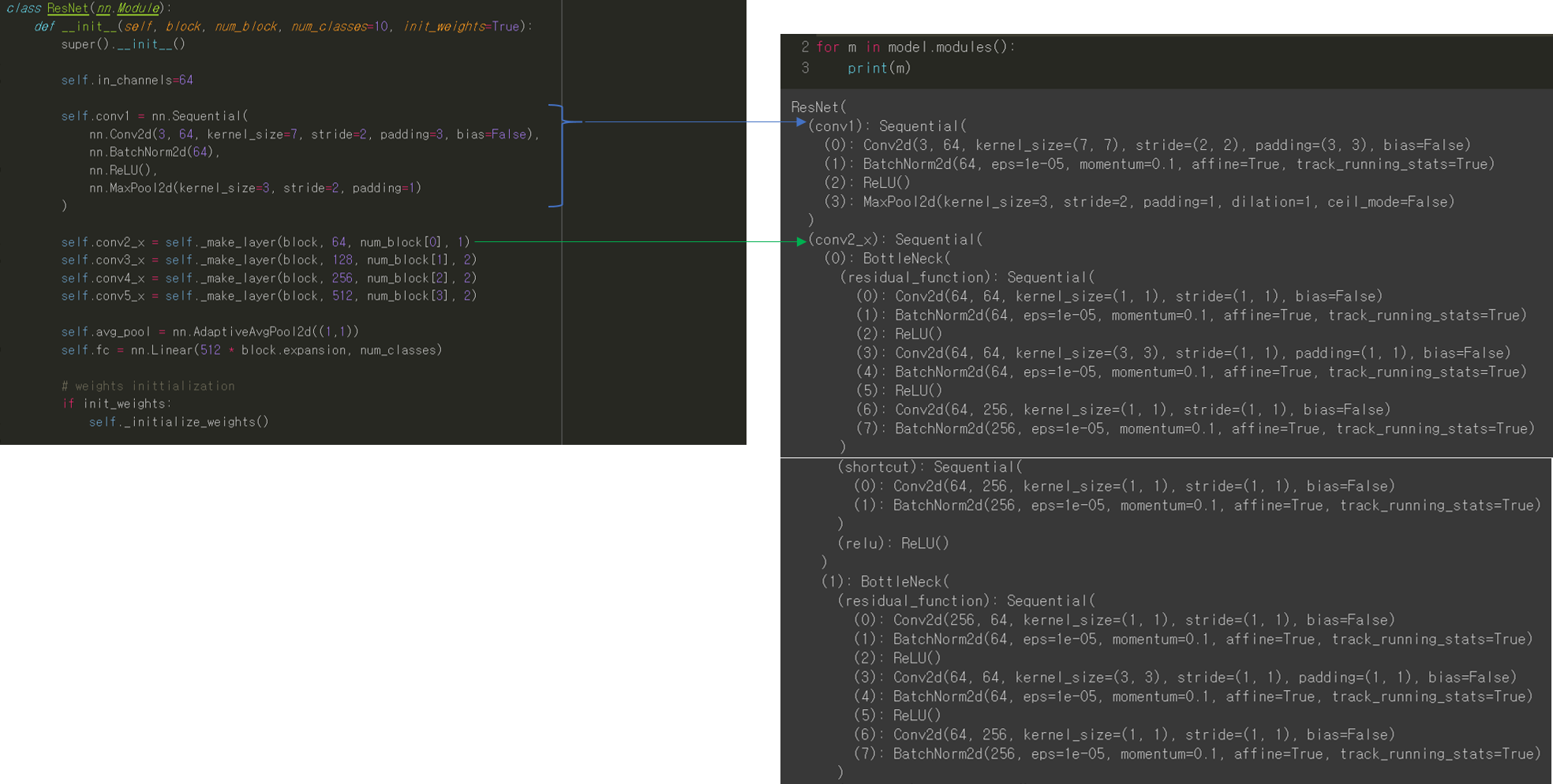
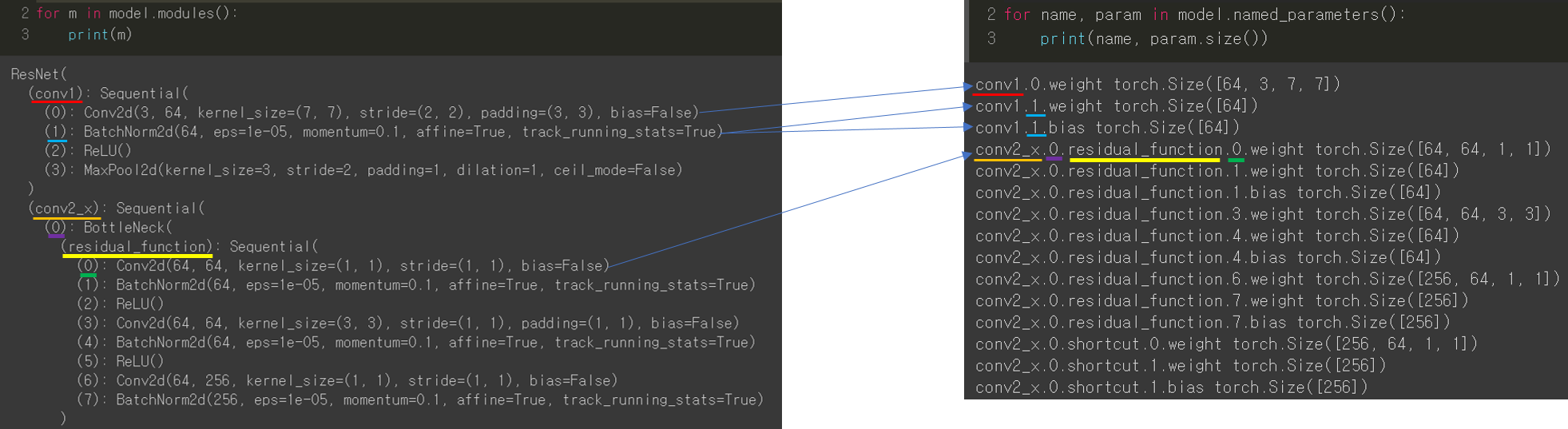
안녕하세요.
이번 글에서는 CNN 모델의 학습할 방향성을 정해주기 위한 loss function, opimizer, learning rate policy를 설정해주는 코드들을 살펴보도록 하겠습니다.
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
1. Loss function 설정
torch.nn 을 살펴보면 다양한 neural network를 제공해주는 것 외에 loss function도 제공해주고 있다는 걸 확인할 수 있습니다.

https://pytorch.org/docs/stable/nn.html
torch.nn — PyTorch 1.9.0 documentation
Shortcuts
pytorch.org
CNN 학습을 위해 torch.nn에서 제공해주는 CrossEntropyLoss를 사용합니다. (다른 loss function도 사용가능 하지만 보통은 crossentropy loss를 사용합니다)
2. optimizer 정의 (Feat. 최신 optimizer 사용방식)
torch.optim 이라는 패키지를 살펴보면 다양한 optimizer를 제공해준다는 것을 알 수 있습니다.
(경험상 optimizer를 무엇으로 사용했는지에 따라 딥러닝 모델 성능에 많은 영향을 끼치는걸 확인할 수 있었기 때문에 어떠한 optimizer를 사용할지 잘 결정하는 것이 중요합니다.)
https://pytorch.org/docs/stable/optim.html
torch.optim — PyTorch 1.9.0 documentation
torch.optim torch.optim is a package implementing various optimization algorithms. Most commonly used methods are already supported, and the interface is general enough, so that more sophisticated ones can be also easily integrated in the future. How to us
pytorch.org
(↓↓↓optimizer 관련 내용 정리한 글↓↓↓)
https://89douner.tistory.com/46
12. Optimizer (결국 딥러닝은 최적화문제를 푸는거에요)
안녕하세요~ 지금까지는 DNN의 일반화성능에 초점을 맞추고 설명했어요. Batch normalization하는 것도 overfitting을 막기 위해서이고, Cross validation, L1,L2 regularization 하는 이유도 모두 overfitting의..
89douner.tistory.com
torch.optim은 가장 기본이 되는 optimizer들을 제공합니다.
하지만 최신 SOTA 성능의 optimizer들은 제공하지 않는 경우가 많죠.
그래서 SOTA 성능의 optimizer를 이용하기 위해서는 다른 방법을 찾아야 합니다.
보통 SOTA optimizer 같은 경우는 논문으로 출판할 때, 해당 optimizer를 이용할 수 있게 github에 업로드합니다. 업로드된 optimizer를 패키지로 다운받아 pytorch, tensorflow와 연동해서 사용하면 됩니다.
예를 들어, adabelief optimizer라는 최신 optimizer가 나왔다고 하면 아래와 같은 순서를 따라 이용하면 됩니다.
1) adabelief optimizer github 사이트 검색
https://github.com/juntang-zhuang/Adabelief-Optimizer
GitHub - juntang-zhuang/Adabelief-Optimizer: Repository for NeurIPS 2020 Spotlight "AdaBelief Optimizer: Adapting stepsizes by
Repository for NeurIPS 2020 Spotlight "AdaBelief Optimizer: Adapting stepsizes by the belief in observed gradients" - GitHub - juntang-zhuang/Adabelief-Optimizer: Repository for NeurIPS ...
github.com
2) 위의 사이트에서 언급한대로 adabelief optimizer 패키지 설치
- 여기에서는 pytorch 버전 설치
- 다른 가상환경을 사용하고 있으면 해당 가상환경에 설치하는데 필요한 명령어로 바꾸어 설치 (ex: anaconda)
pip install adabelief-pytorch==0.2.0
3) 설치한 adabelief optimizer 패키지 설치 후, 해당 optimizer 이용
from adabelief_pytorch import AdaBelief
optimizer_ft = AdaBelief(model.parameters(), lr=1e-3, eps=1e-16, betas=(0.9,0.999), weight_decouple = True, rectify = False)
3. learning rate scheduler (policy) 정의
앞서 optimizer를 정의 했다면, learning rate policy를 정해주어야 합니다.
기본적인 learning rate policy 역시 torch.opim에서 제공해주니 아래 API를 참고하시면 다양한 learning rate policty를 확인하실 수 있습니다.
https://pytorch.org/docs/stable/optim.html
torch.optim — PyTorch 1.9.0 documentation
torch.optim torch.optim is a package implementing various optimization algorithms. Most commonly used methods are already supported, and the interface is general enough, so that more sophisticated ones can be also easily integrated in the future. How to us
pytorch.org
Learning rate policy는 정말 다양하게 있는데 대표적인 경우들에 대해서 소개하도록 하겠습니다.
1) Step policy
학습을 하다보면 loss가 정체되어 있는 경우가 있습니다. 이 경우 early stoping을 하여 학습을 종료시키는 경우도 있지만 아래 "그림10"에서 처럼 정체되는 순간 learning rate을 감소시켜주면 loss가 다시 줄어드는경우도 있습니다.
이와 같이 계단 형식으로 learning rate을 감소(decay) 시켜주는 learning rate policy 방식을 step decay라고 합니다.
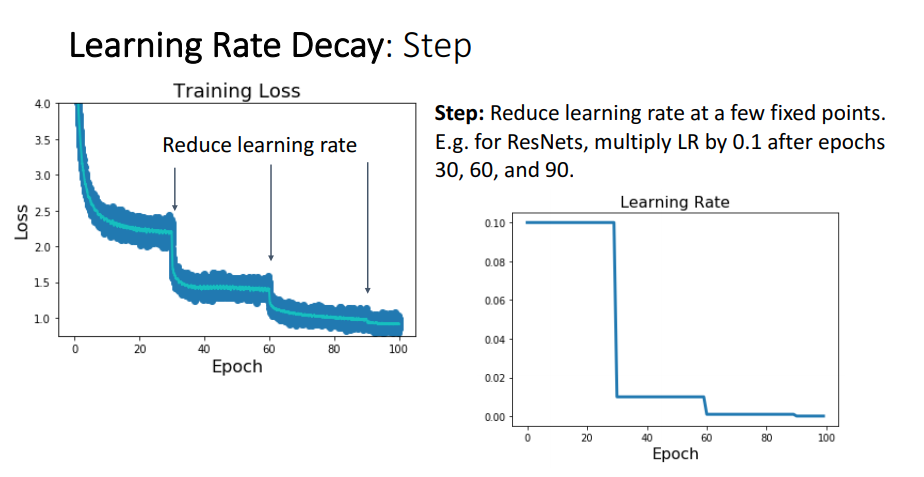
Step decay 방식을 이요하려면 아래와 같이 코드를 작성해주면 됩니다.
아래와 같은 코드를 작성해주면 3번의 epoch 마다 learning rate가 0.1씩 감소하게 됩니다.

(↓↓↓pytorch에서 제공해주는 step learning rate policy API↓↓↓)
StepLR — PyTorch 1.9.0 documentation
Shortcuts
pytorch.org
2) Cosine annealing policy
Pytorch에서는 step learning rate policy외에 cosine annealing policy라는 방식도 제공해줍니다.
보통은 cosine annealing policy를 warm_up과 같이 사용하는데, 이에 대해서는 뒷 부분에서 설명하도록 하겠습니다.


- optimizer – Wrapped optimizer.
- T_max (int) – Maximum number of iterations.
- eta_min (float) – Minimum learning rate. Default: 0.
- last_epoch (int) – The index of last epoch. Default: -1.
(↓↓↓pytorch에서 제공해주는 Cosine Annealing learning rate policy API↓↓↓)
CosineAnnealingLR — PyTorch 1.9.0 documentation
Shortcuts
pytorch.org
3) Warm_up policy
초기에는 layer 값들이 굉장히 불안정하기 때문에 너무 큰 learning rate을 적용하면 loss값이 지나치게 커질 수 있습니다. 그래서 초기의 unstable 상태를 고려해 초기 특정 epoch 까지는 learning rate을 천천히 증가시켜주는 방식이 warm_up 방식입니다.
Warm_up을 통해 특정 epoch 까지 learning rate을 증가시키면, 특정 epoch 이후에는 기존 learning rate policy를 적용시켜주어야 합니다.
아래 그림을 보면 초기 5 epoch 까지는 learning rate을 점진적으로 증가시키고, 5 epoch 이후에는 step policy 또는 cosine annealing policy 확인할 수 있습니다.

Warm_up policy는 pytorch에서 기본 learning rate policy로 제공해주고 있지 않기 때문에 따로 warm_up laerning rate policy 패키지를 설치해야합니다.
3-1) Warm_up policy with step learning rate policy
3-1-1) warm_up step learning rate과 관련된 사이트 검색
https://github.com/ildoonet/pytorch-gradual-warmup-lr
GitHub - ildoonet/pytorch-gradual-warmup-lr: Gradually-Warmup Learning Rate Scheduler for PyTorch
Gradually-Warmup Learning Rate Scheduler for PyTorch - GitHub - ildoonet/pytorch-gradual-warmup-lr: Gradually-Warmup Learning Rate Scheduler for PyTorch
github.com
3-1-2) 패키지 설치
pip install git+https://github.com/ildoonet/pytorch-gradual-warmup-lr.git
3-1-3) 설치된 패키지 이용
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 3 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=3, gamma=0.1)
exp_lr_scheduler = GradualWarmupScheduler(optimizer_ft, multiplier=1, total_epoch=5, after_scheduler=exp_lr_scheduler)

3-2) Warm_up policy with cosine annealing learning rate policy
3-2-1) warm_up consine annealing learning rate과 관련된 사이트 검색
https://github.com/katsura-jp/pytorch-cosine-annealing-with-warmup
GitHub - katsura-jp/pytorch-cosine-annealing-with-warmup
Contribute to katsura-jp/pytorch-cosine-annealing-with-warmup development by creating an account on GitHub.
github.com
3-2-2) 패키지 설치
pip install 'git+https://github.com/katsura-jp/pytorch-cosine-annealing-with-warmup'
3-2-3) 설치된 패키지 이용
from cosine_annealing_warmup import CosineAnnealingWarmupRestarts
criterion = nn.CrossEntropyLoss()
optimizer_ft = optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=1e-5) # lr is min lr
scheduler = CosineAnnealingWarmupRestarts(optimizer, first_cycle_steps=200, cycle_mult=1.0, max_lr=0.1, min_lr=0.001, warmup_steps=50, gamma=1.0)

Cosine annealing with warm_up 과 관련된 hyper parameter들은 아래 그림을 보면 이해하시기 편하실 겁니다. (참고로 gamma부분은 다음 cycle에서 max_lr을 어느 정도 줄여줄지를 결정해주는 hyper parameter 입니다)
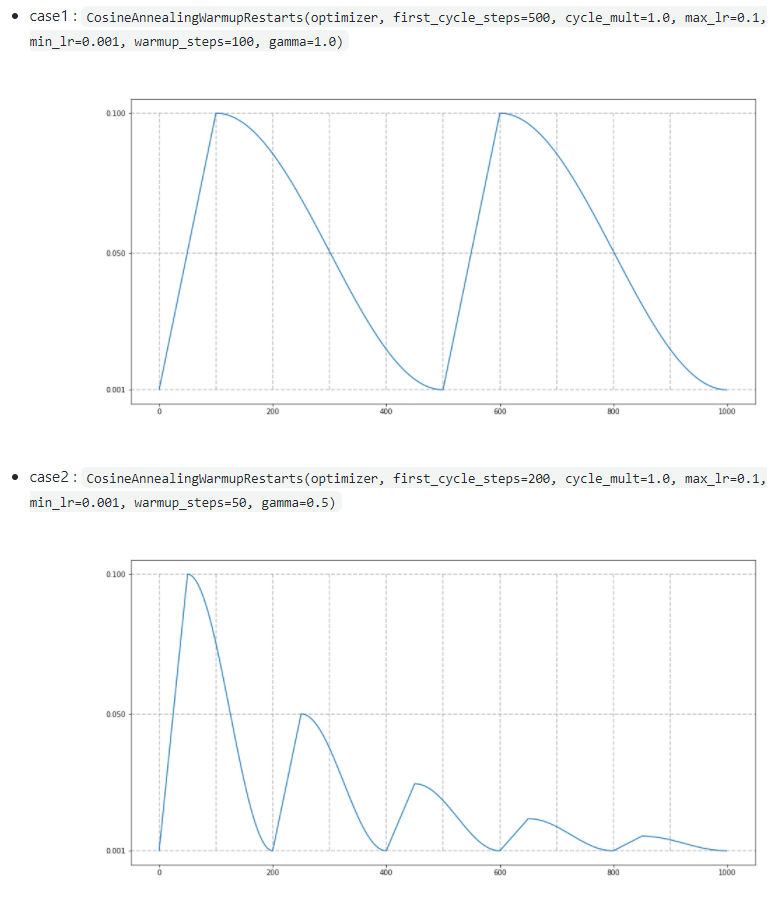
Warm_up을 적용시킬 때 batch size에 따라 initial learning rate(=마지막 warm up 단계에서의 learning rate)를 어떻게 설정해 줄 지 결정해 주기도 합니다. 이 부분은 아래 글에서 learning rate warmup 부분을 참고해주시면 될 것 같습니다.
https://89douner.tistory.com/248
2. Bag of Tricks for Image Classification with Convolutional Neural Networks
안녕하세요. 이번 글에서는 아래 논문을 리뷰해보도록 하겠습니다.(아직 2차 검토를 하지 않은 상태라 설명이 비약적이거나 문장이 어색할 수 있습니다.) ※덧 분여 제가 medical image에서 tranasfer l
89douner.tistory.com
4. 요약
지금까지 배운 내용을 잠시 정리 해보겠습니다.
# License: BSD
# Author: Sasank Chilamkurthy
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
plt.ion() # interactive mode
4-1. Data Load
먼저 아래 글을 통해 CNN 학습을 위하 이미지 데이터들을 어떻게 load 하는지에 대해서 설명했습니다.
https://89douner.tistory.com/287?category=994842
1. Data Load (Feat. CUDA)
안녕하세요. 이번 글에서는 CNN 모델 학습을 위해 학습 데이터들을 로드하는 코드에 대해 설명드리려고 합니다. 아래 사이트의 코드를 기반으로 설명드리도록 하겠습니다. https://pytorch.org/tutorials
89douner.tistory.com
# Data augmentation and normalization for training
# Just normalization for validation
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = 'data/hymenoptera_data'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
추가적으로 batch 단위로 augmentation이 적용된 이미지 데이터들을 아래 함수로 확인해볼 수 있었습니다.
def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# Get a batch of training data
inputs, classes = next(iter(dataloaders['train']))
# Make a grid from batch
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])
4-2. Data Preprocessing
아래 글을 통해 학습 데이터를 전처리하기 위한 다양한 방식들에 대해서 다루어 봤습니다.
(작성중....)
4-3. CNN
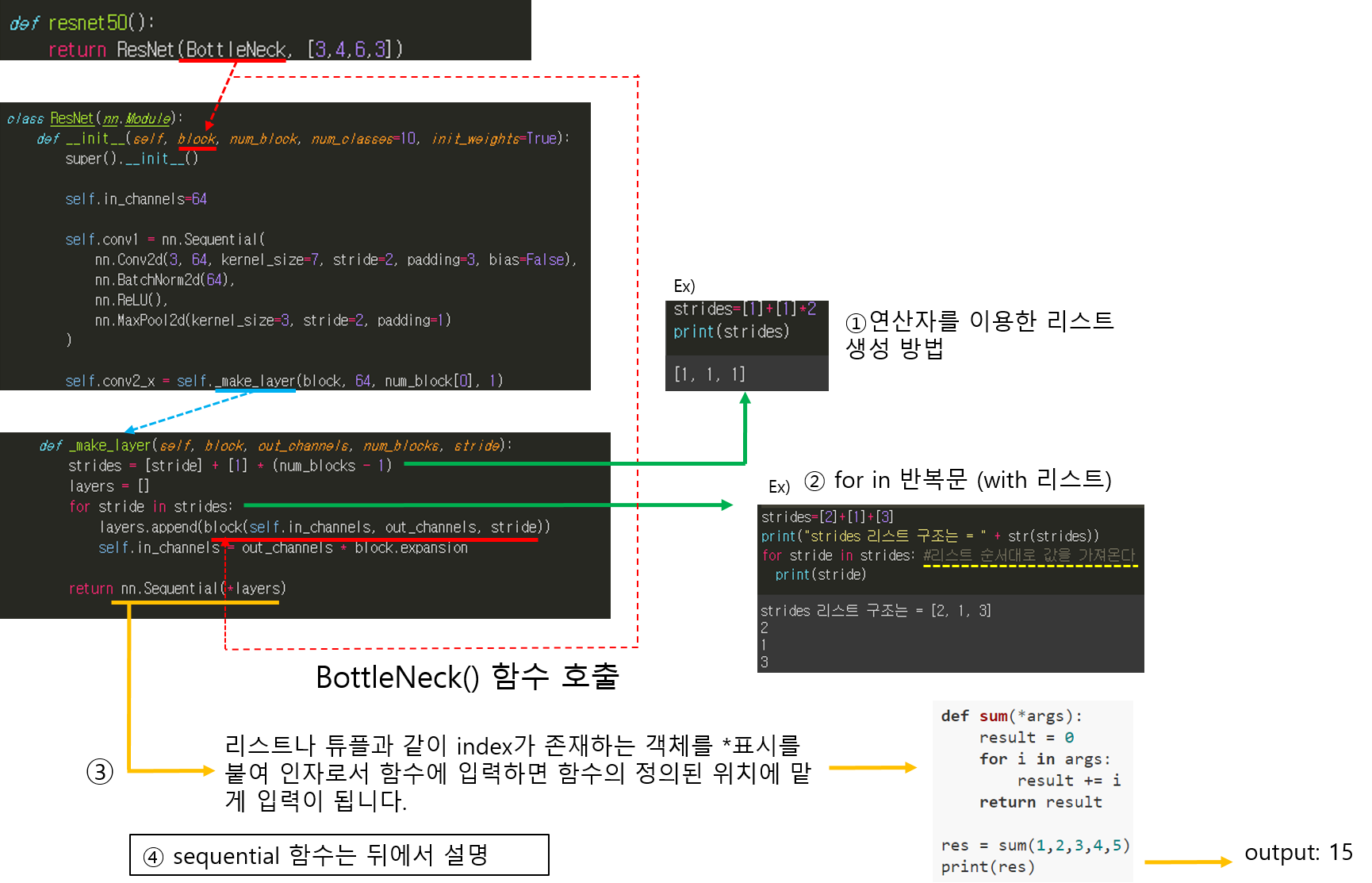
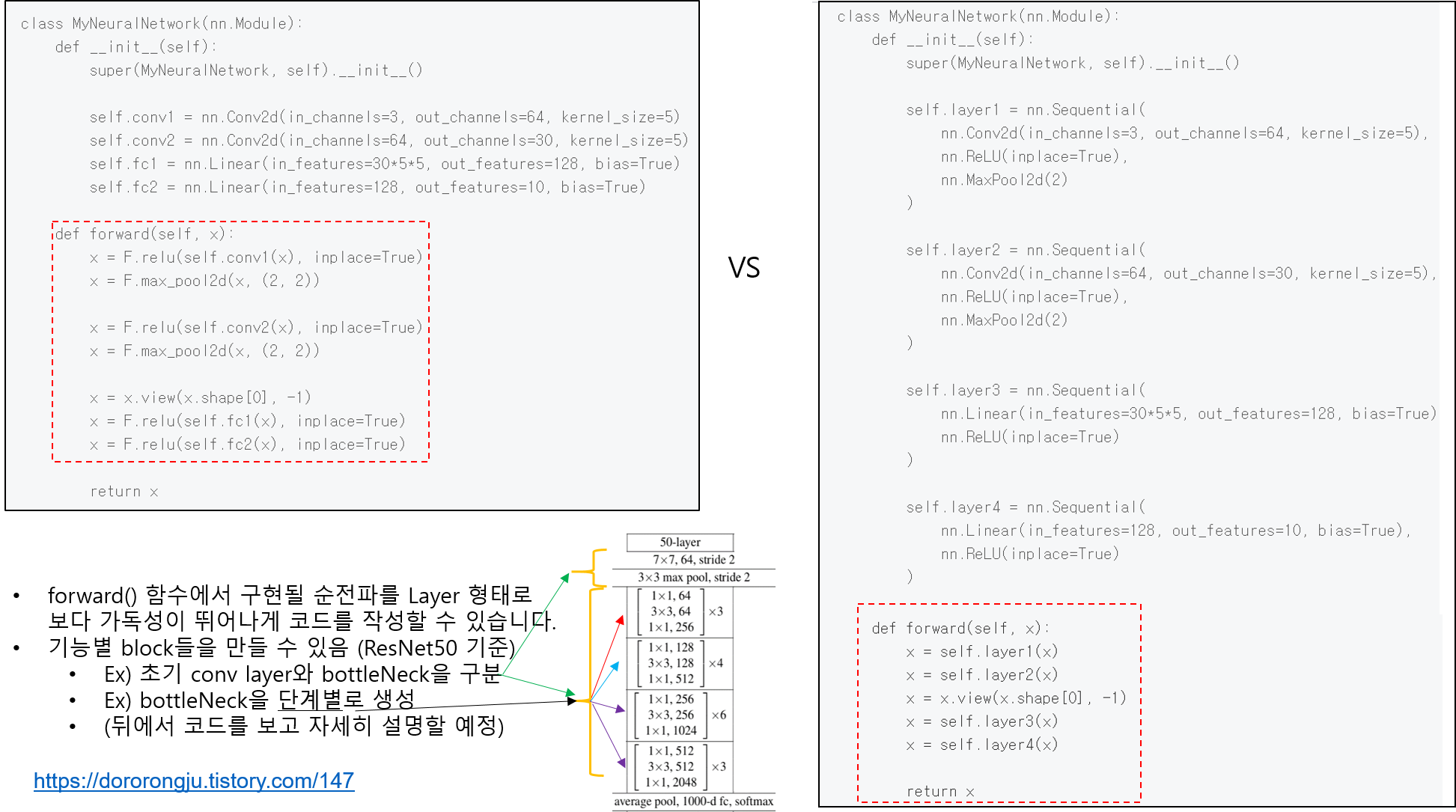
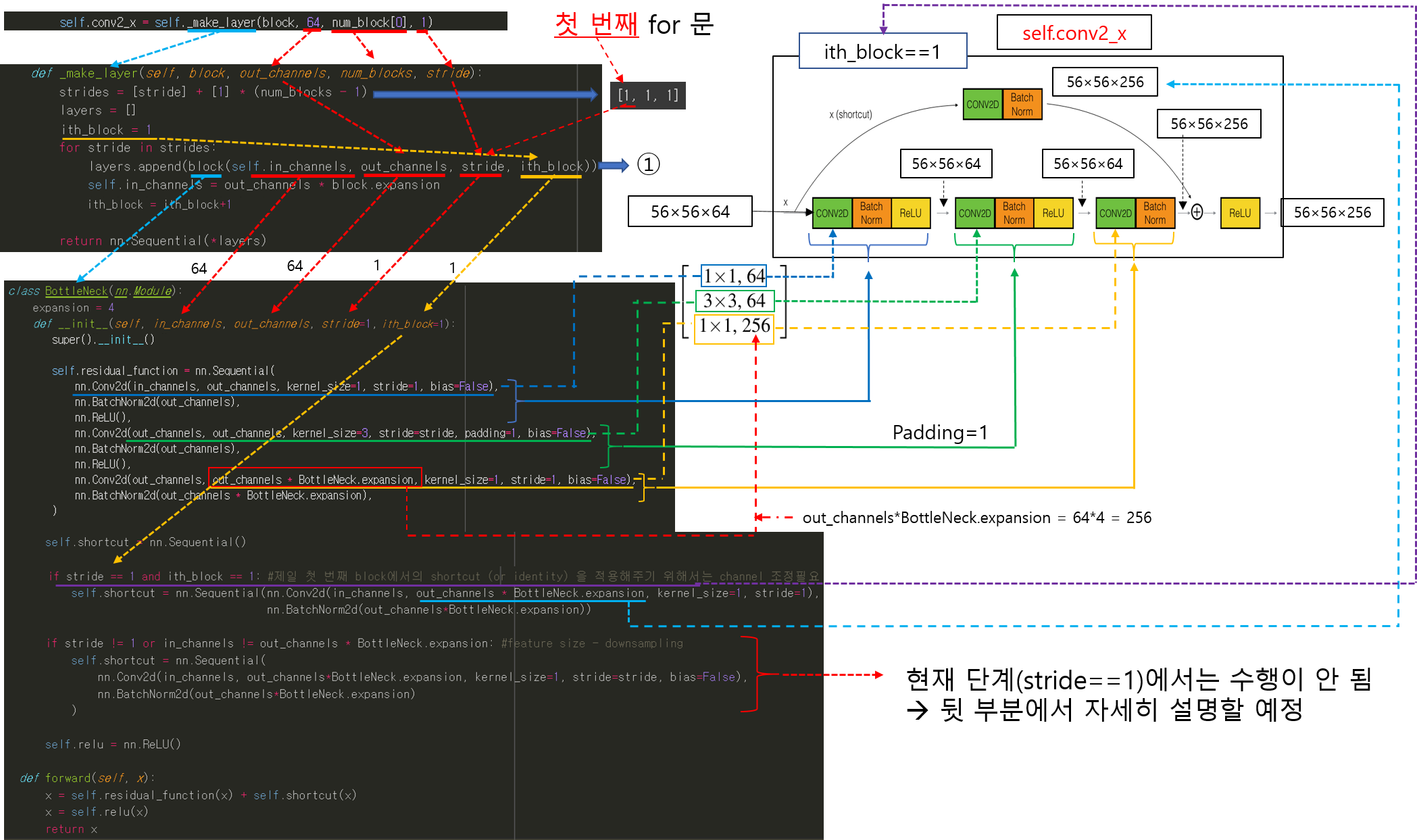
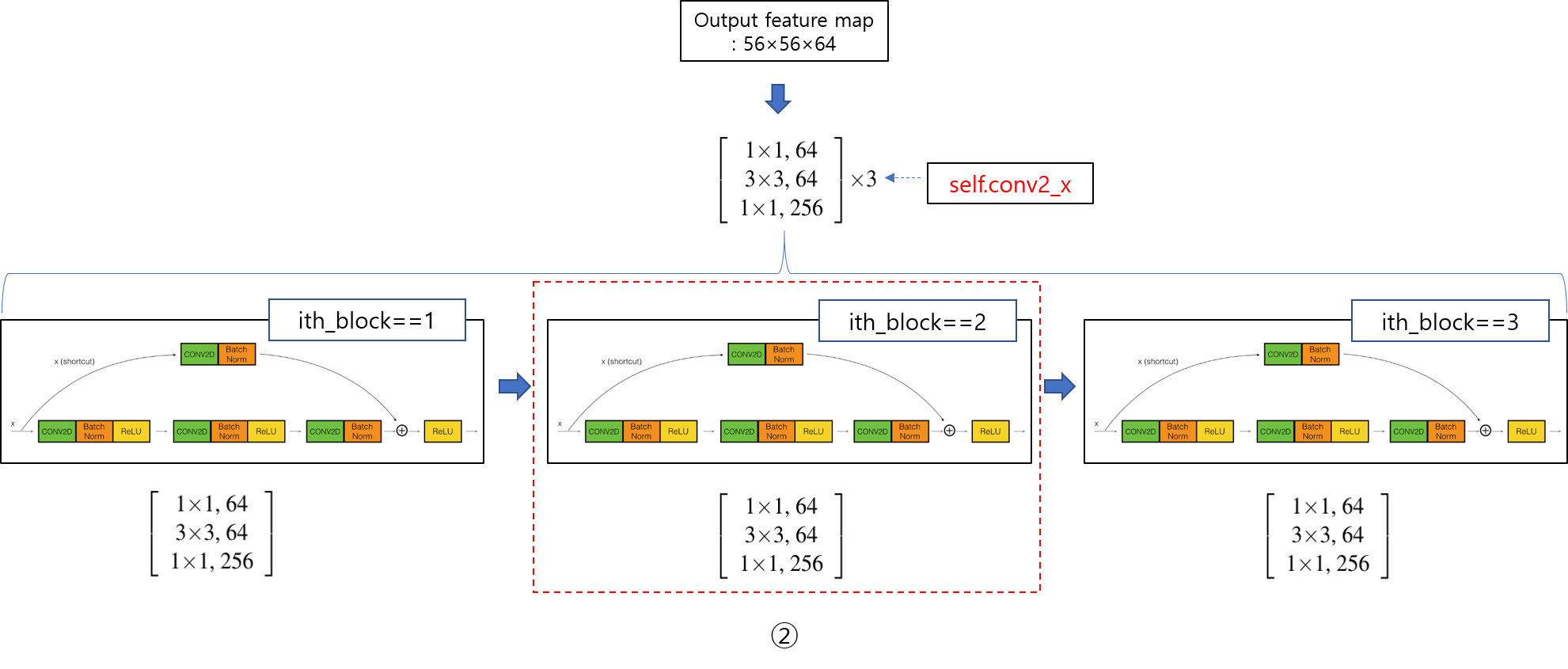
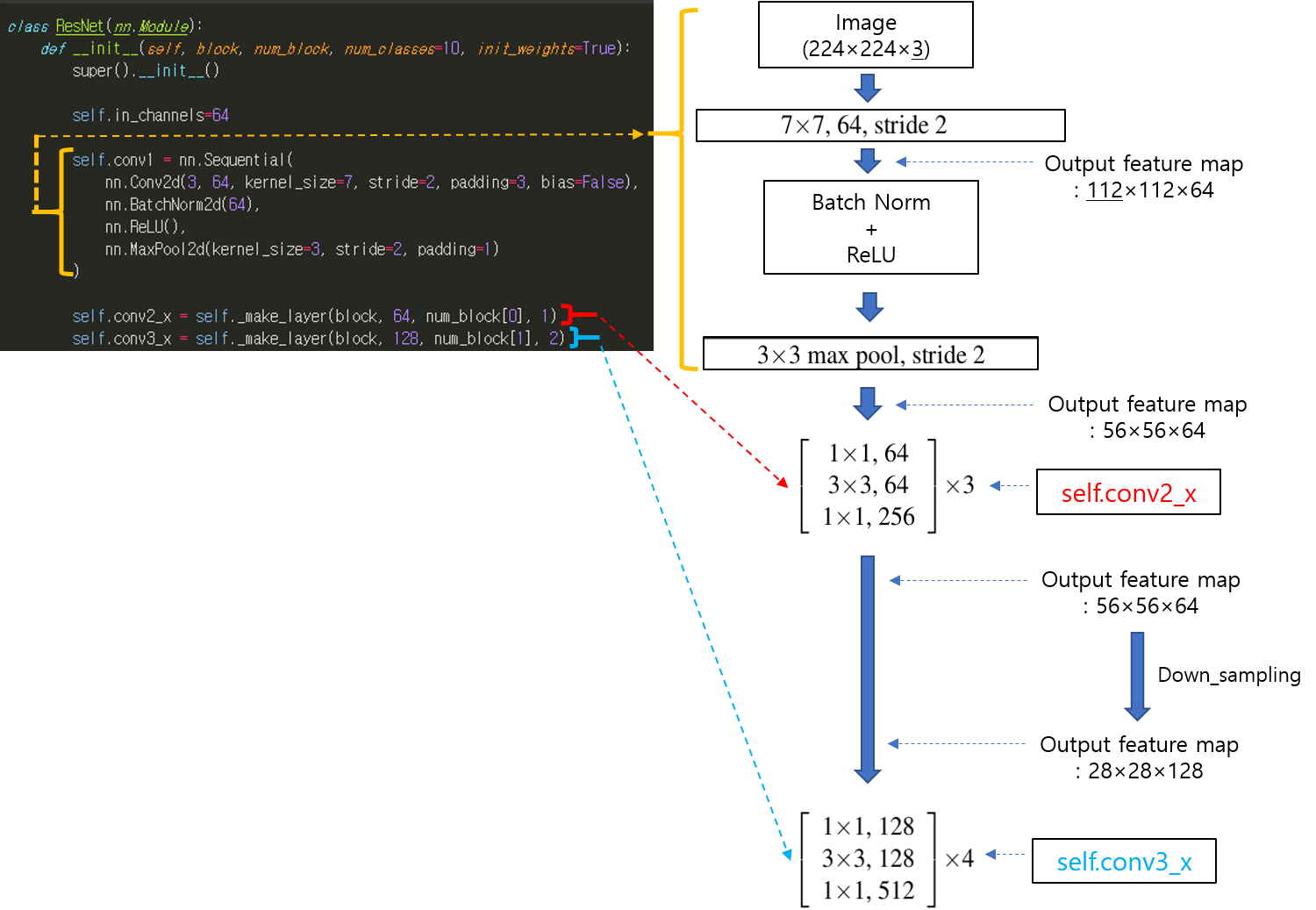
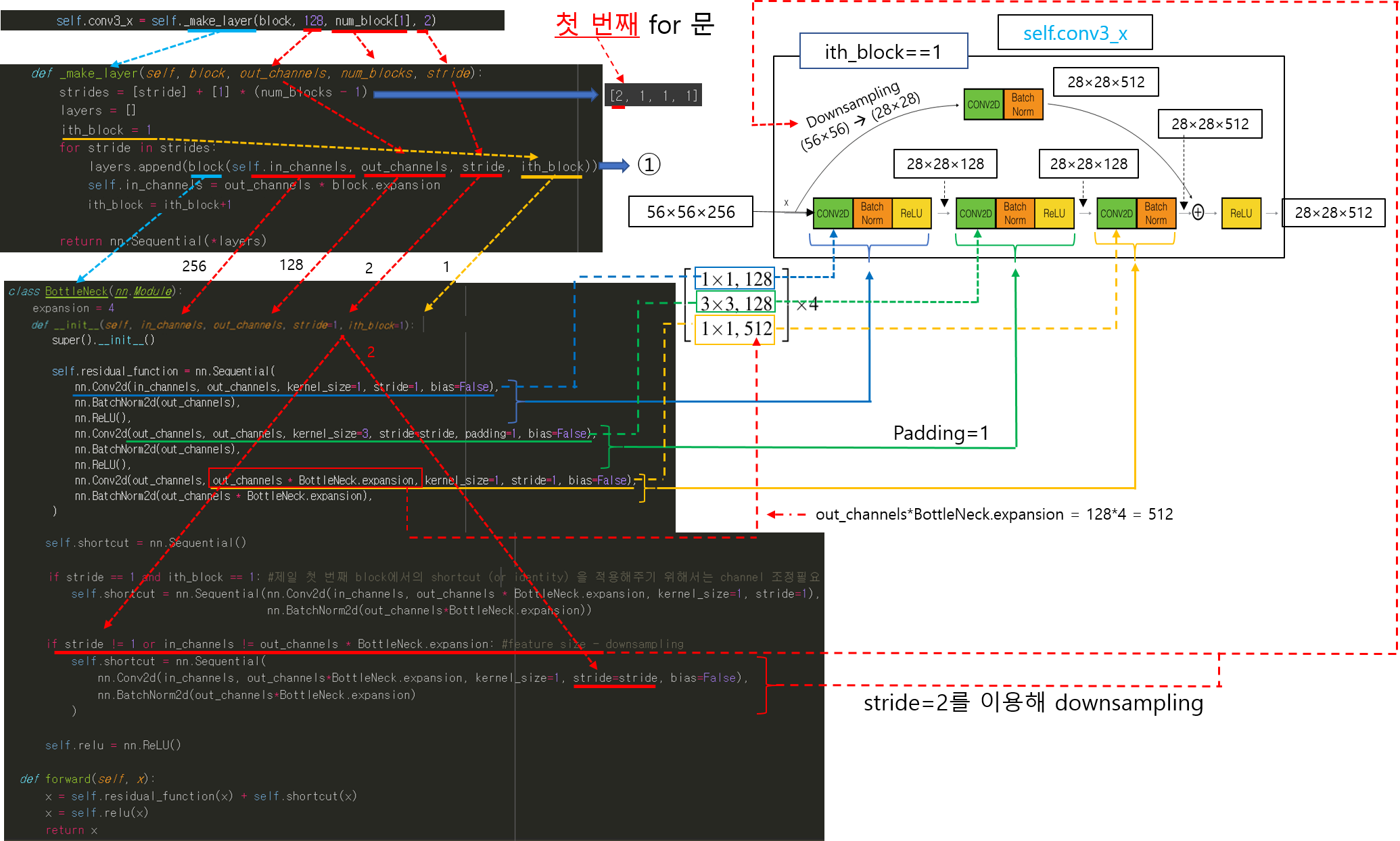
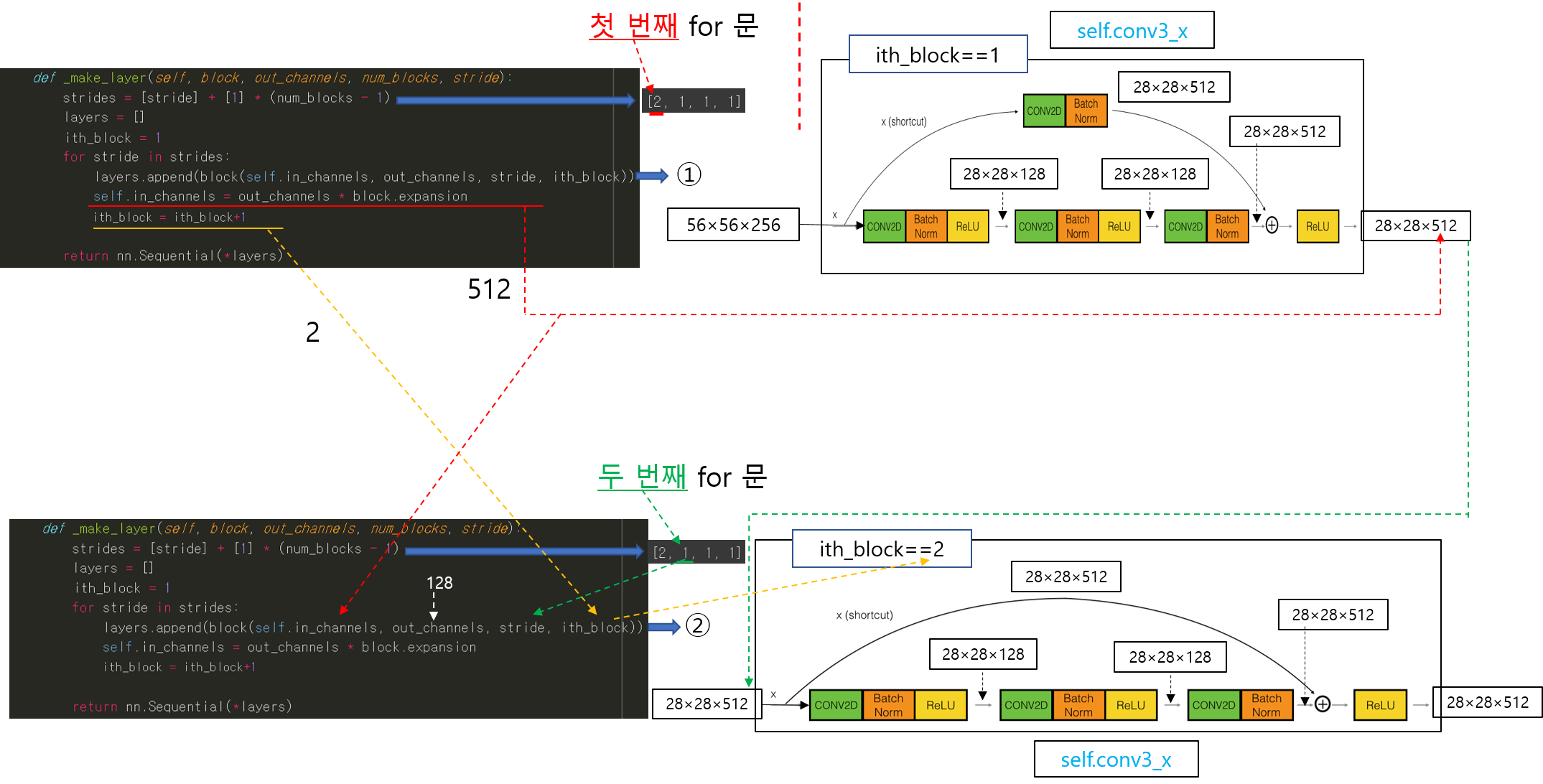
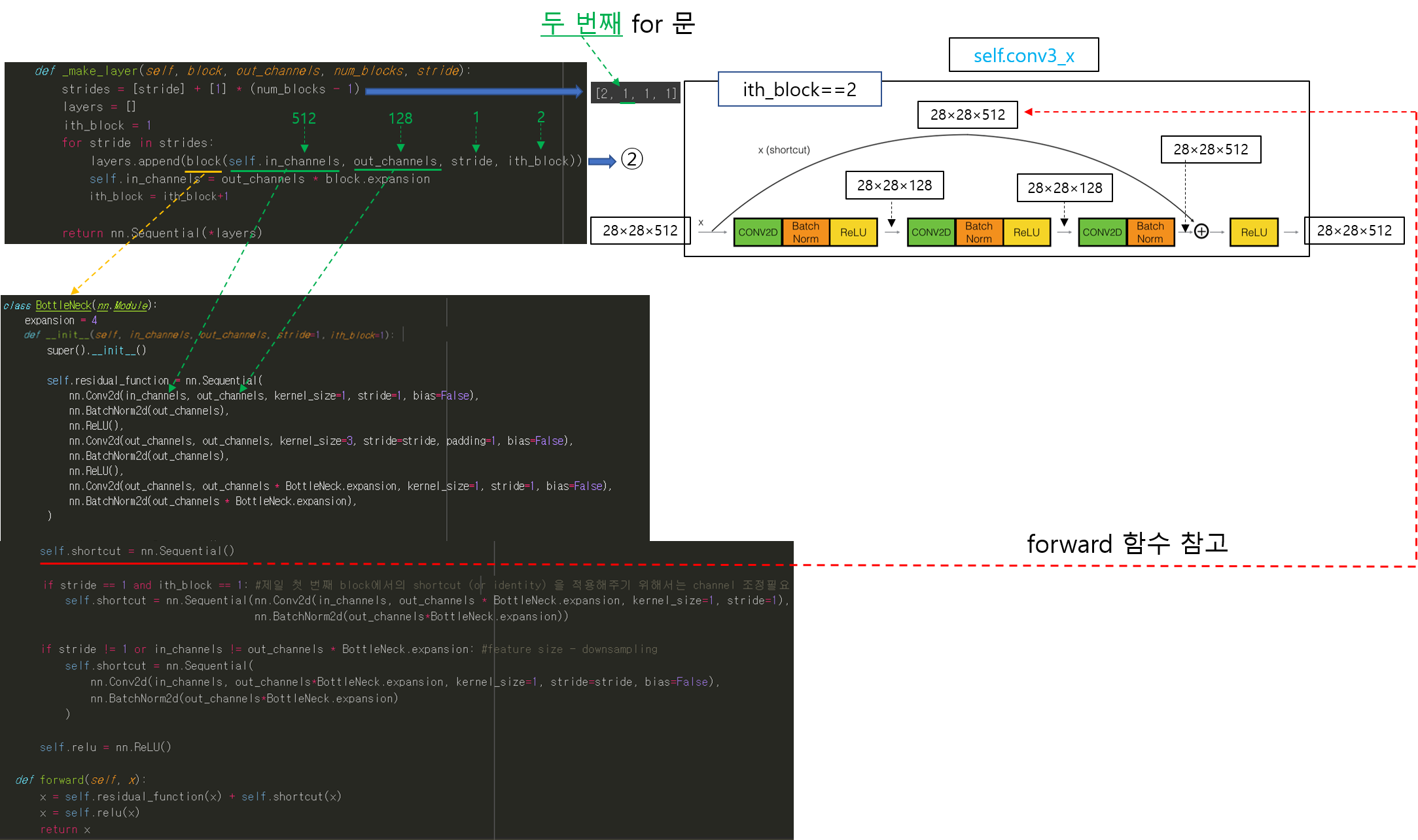
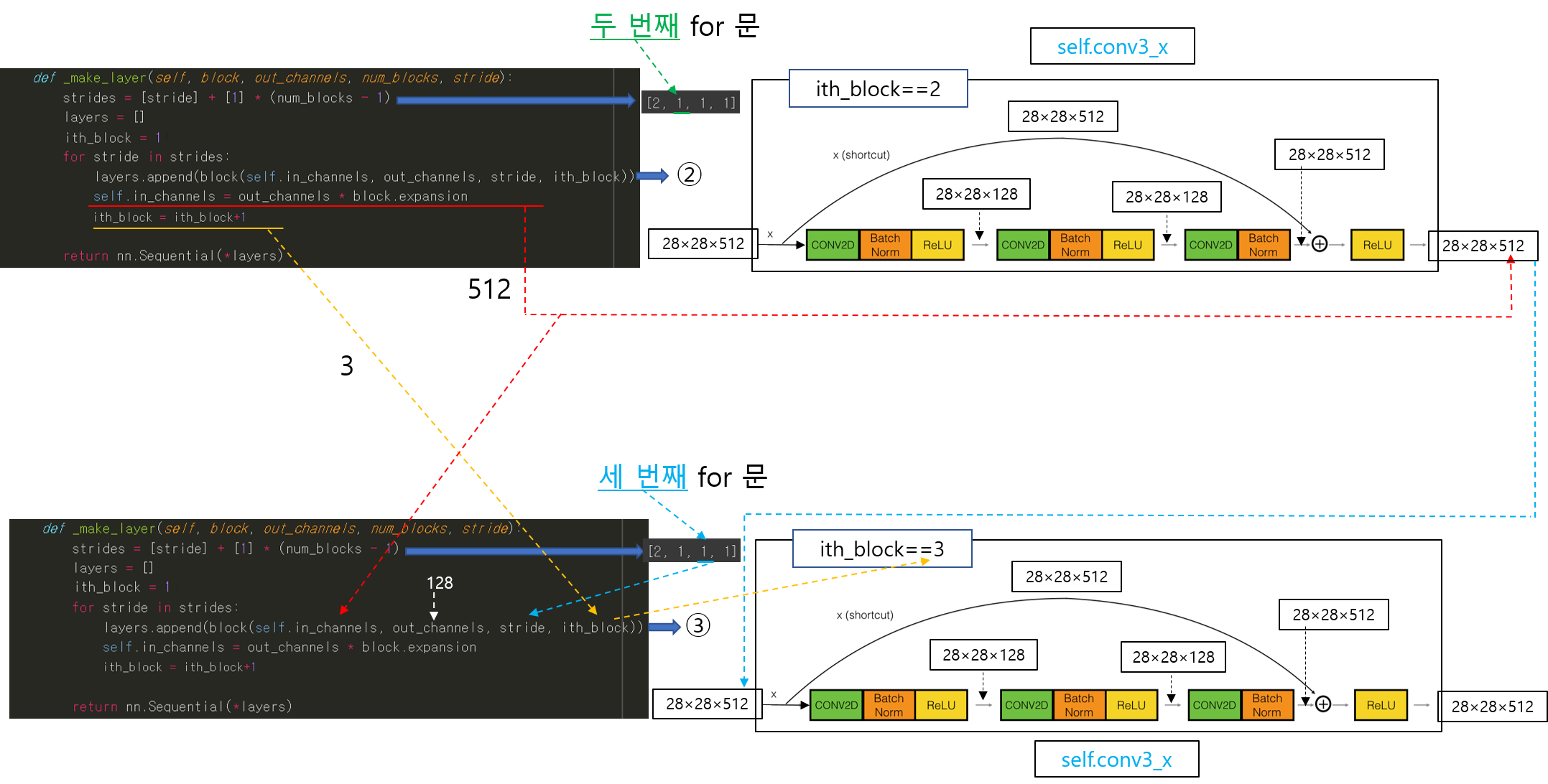
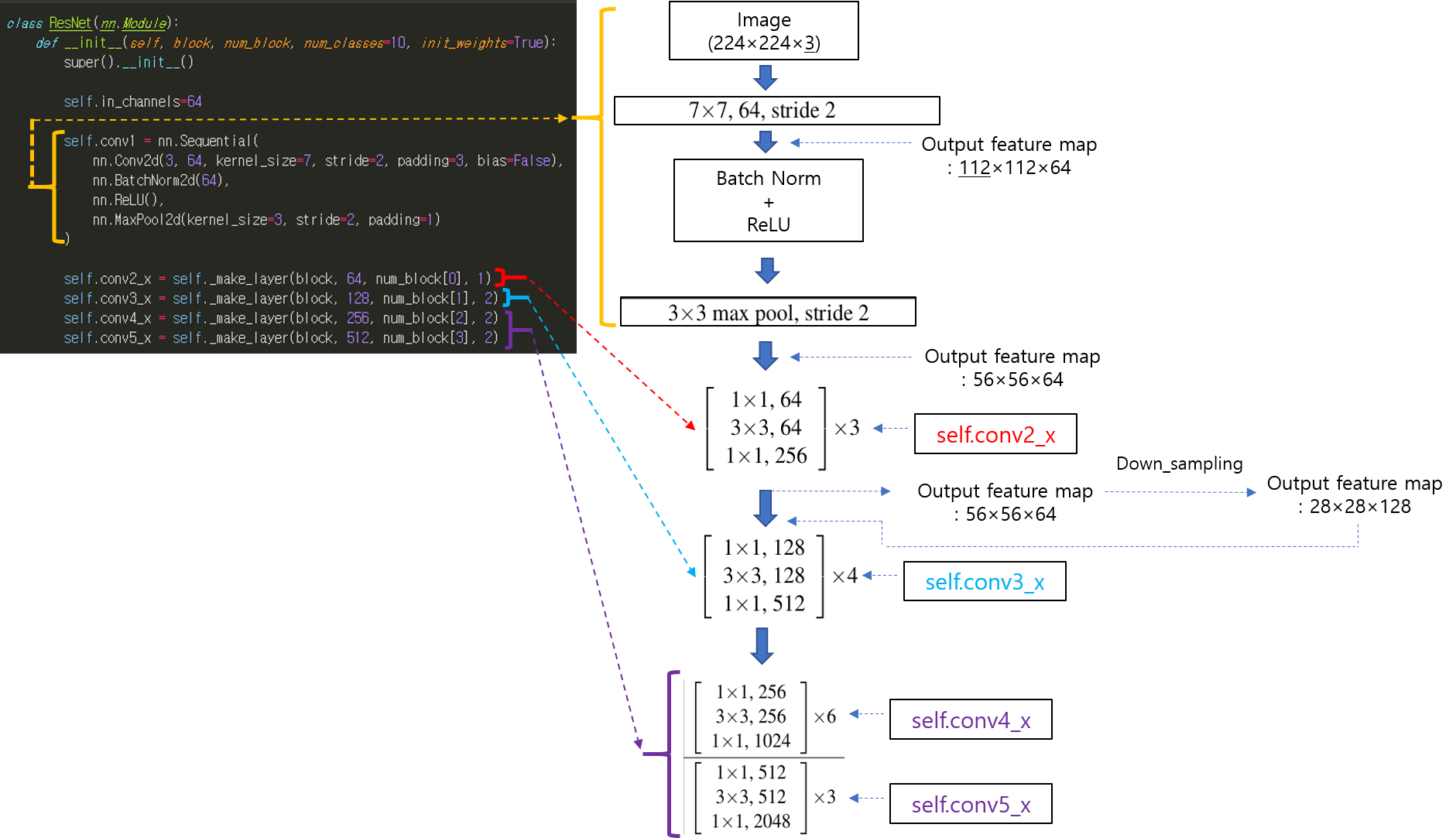
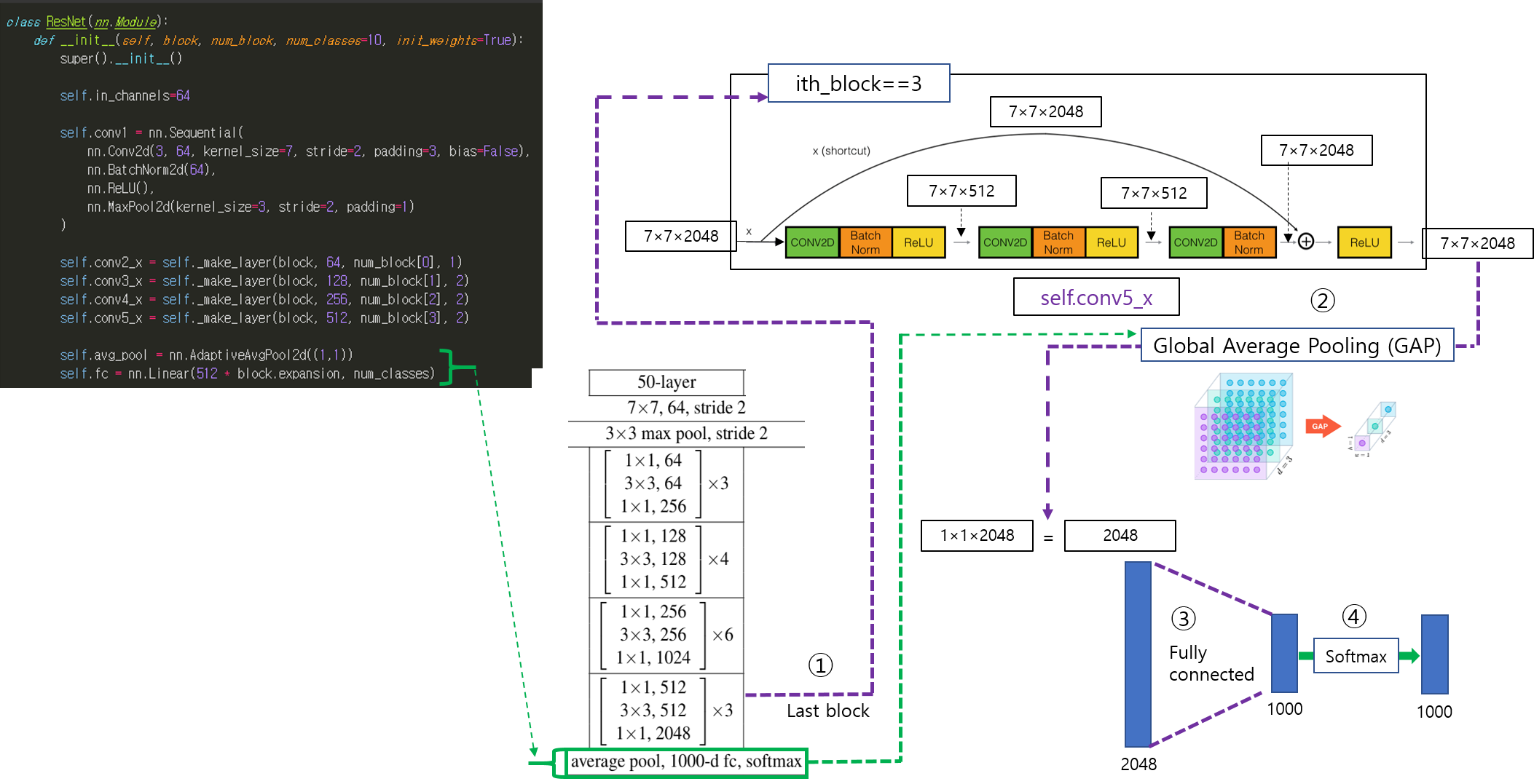
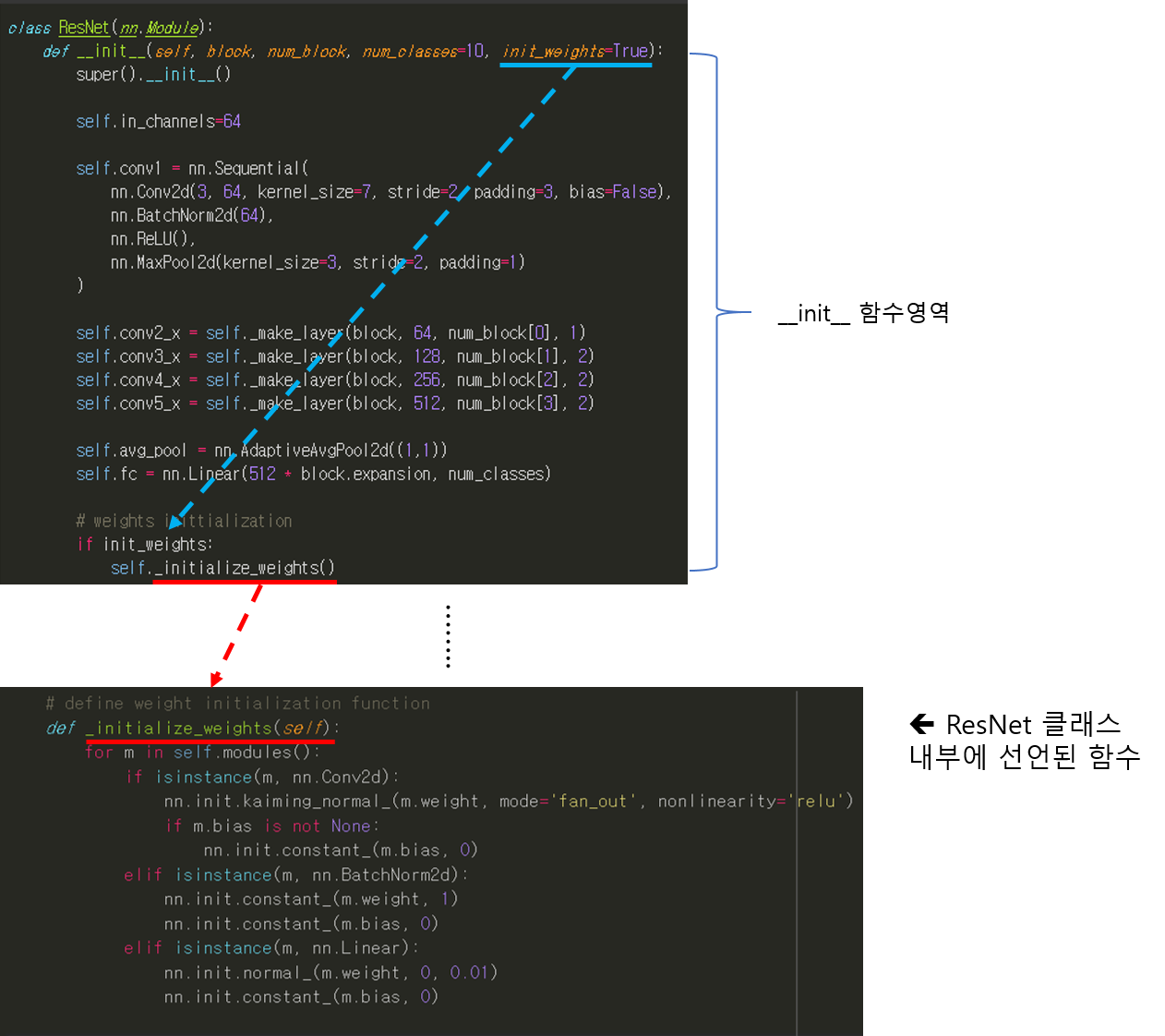
CNN 모델(ResNet)을 처음부터 scratch로 구현해보았습니다.
https://89douner.tistory.com/288?category=994842
3. CNN 구현
안녕하세요. 이번 글에서는 pytorch를 이용해서 대표적인 CNN 모델인 ResNet을 implementation 하는데 필요한 코드를 line by line으로 설명해보려고 합니다. ResNet을 구현할 줄 아시면 전통적인 CNN 모델들
89douner.tistory.com
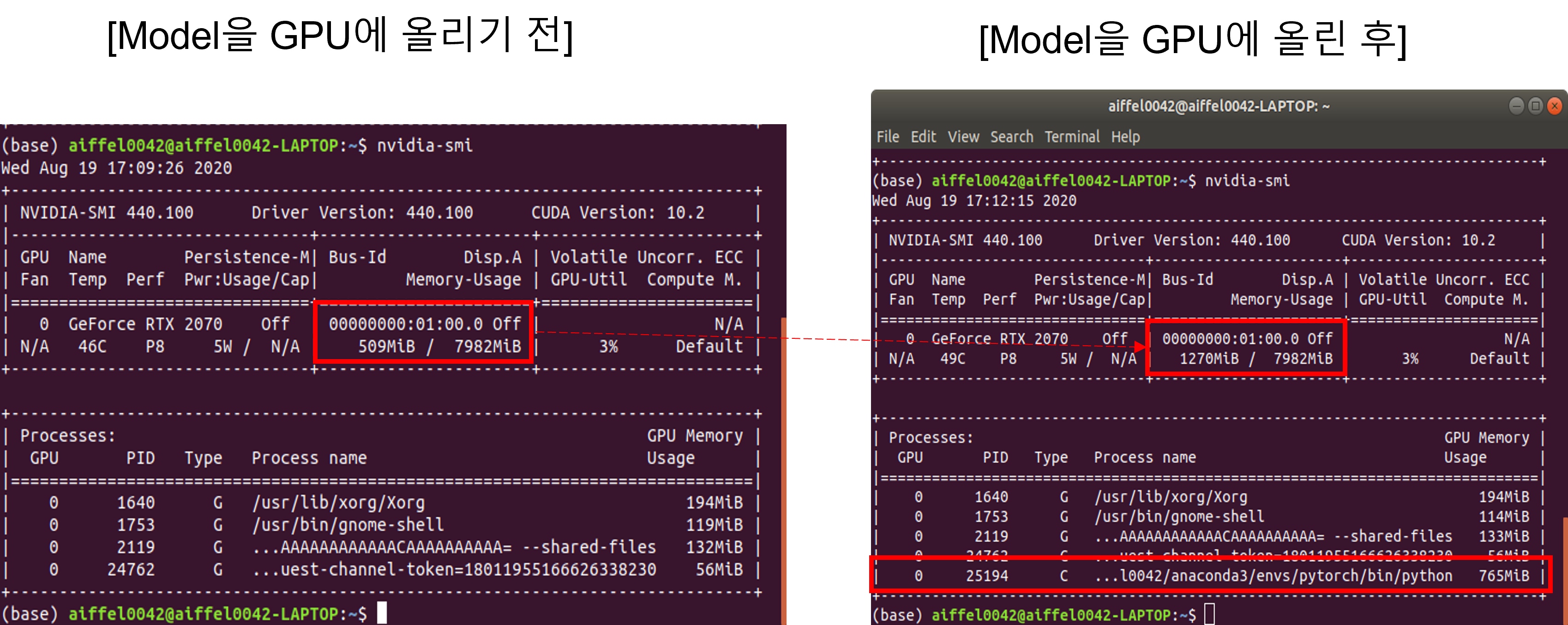
4-4. Transfer Learning (Feat. Pre-trained model, GPU)
pre-trained model을 다운 받아 transfer learning을 적용하는 코드에 대해서 다루었고, 추가적으로 해당 모델을 GPU에 업로드 하는 것 까지 살펴봤습니다.
https://89douner.tistory.com/289?category=994842
4. Transfer Learning (Feat. pre-trained model)
안녕하세요. 이번 글에서는 transfer learning을 pytorch로 적용하는 방법에 대해서 알아보도록 하겠습니다. CNN 모델을 training하는 방식에는 2가지가 있습니다. Scratch training (learning) 자신의 데이터 셋..
89douner.tistory.com
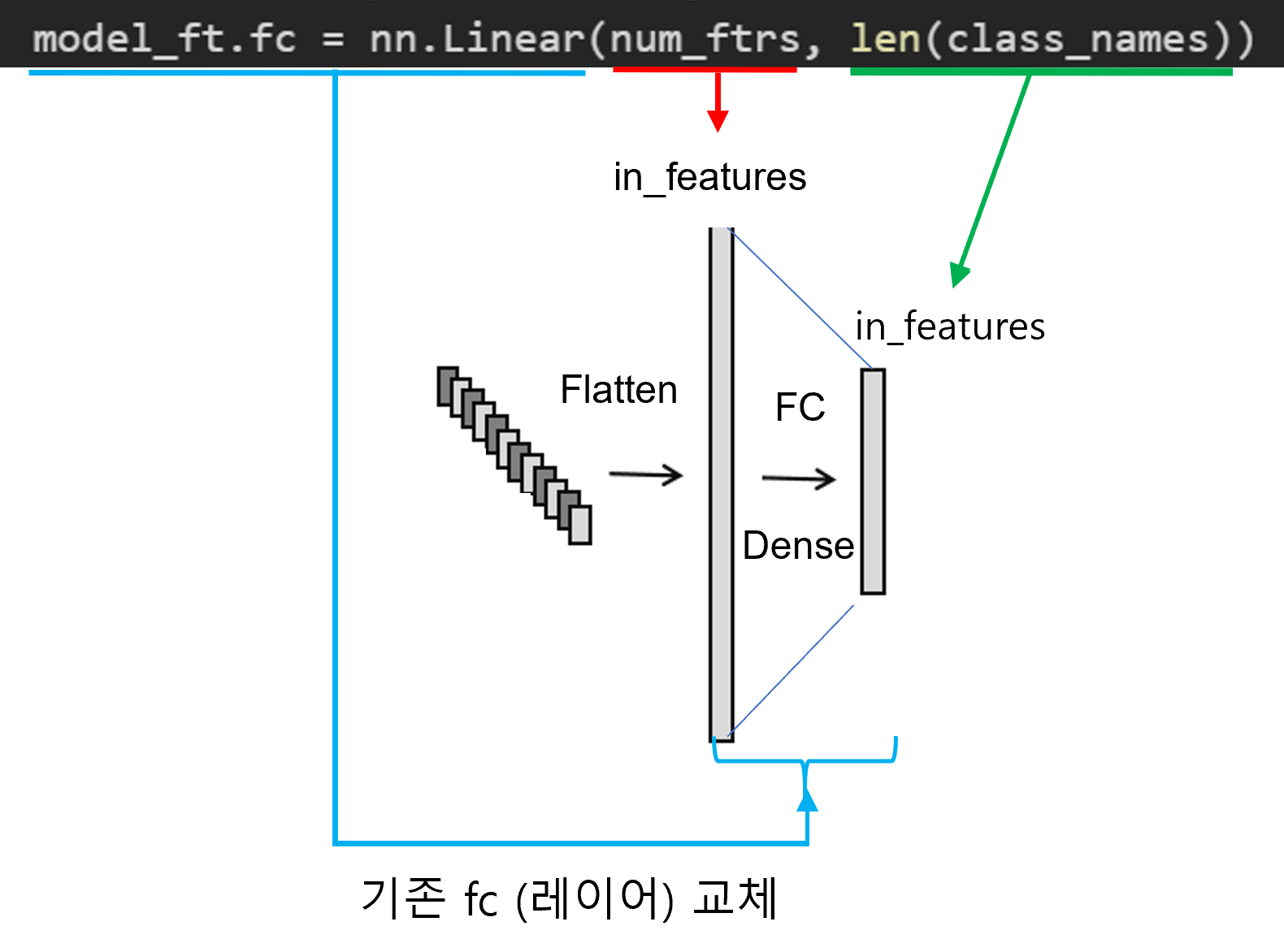
model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
# Here the size of each output sample is set to 2.
# Alternatively, it can be generalized to nn.Linear(num_ftrs, len(class_names)).
model_ft.fc = nn.Linear(num_ftrs, 2)
model_ft = model_ft.to(device)
4-5. Loss function, Optimizer, Learning rate policy (← 현재 글)
이번 글에서는 딥러닝 모델이 학습할 방향성에 대해서 정리했고, 관련 코드는 아래와 같습니다.
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
5. 코드 정리
지금까지 배운 내용을 코드로 정리하면 아래와 같습니다.
# License: BSD
# Author: Sasank Chilamkurthy
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
from warmup_scheduler import GradualWarmupScheduler
plt.ion() # interactive mode# Data augmentation and normalization for training
# Just normalization for validation
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = 'data/hymenoptera_data'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# Get a batch of training data
inputs, classes = next(iter(dataloaders['train']))
# Make a grid from batch
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
# Here the size of each output sample is set to 2.
# Alternatively, it can be generalized to nn.Linear(num_ftrs, len(class_names)).
model_ft.fc = nn.Linear(num_ftrs, 2)
model_ft = model_ft.to(device)criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 3 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=3, gamma=0.1)
exp_lr_scheduler = GradualWarmupScheduler(optimizer_ft, multiplier=1, total_epoch=5, after_scheduler=exp_lr_scheduler)
6. 다음 글에서 배울 내용
지금까지 딥러닝 학습을 위한 모든 준비를 끝냈습니다.
그렇다면 딥러닝이 실제로 어떤 단계(code)를 통해 학습하는지 알아봐야겠죠?
이 부분에 대한 내용은 train_model이라는 함수를 통해 실행이 되는데 이 부분은 다음 글에서 살펴보도록 하겠습니다.
(↓↓↓다음 글에서 배울 코드↓↓↓)
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=20)
'Pytorch > 2.CNN' 카테고리의 다른 글
| 4. Transfer Learning (Feat. pre-trained model) (0) | 2021.07.27 |
|---|---|
| 3. CNN 구현 (2) | 2021.07.27 |
| 2. Data preprocessing (Feat. Augmentation) (0) | 2021.07.27 |
| 1. Data Load (Feat. CUDA) (0) | 2021.07.27 |
| 코드 참고 사이트 (0) | 2021.07.02 |