안녕하세요.
이번 글에서는 아래 논문을 리뷰해보도록 하겠습니다.(아직 2차 검토를 하지 않은 상태라 설명이 비약적이거나 문장이 어색할 수 있습니다.)
※덧 분여 제가 medical image에서 tranasfer learning을 적용했을 때 유효했던 방법론들도 공유하도록 하겠습니다.
"Bag of Tricks for Image Classification with Convolutional Neural Networks"
Conference: 2019 CVPR
Authors: Amazon Web Servies

0. Abstract

- Data augmentation과 optimization 같은 training procedure refinements (학습 절차 개선)은 image classification 성능 향상에 큰 기여를 했습니다.
- training procedure refinements라는 말이 모호하긴 한데, 이 논문에서는 CNN 구조(모델링) 관점에서 CNN 성능을 향상시키는 방법이 아니라, CNN을 학습시킬 때 어떠한 방법 (= training procedure) 을 사용해야 CNN 성능을 개선 (refinments) 시킬 수 있는지에 대한 방법론들을 의미하는 용어로 이해했습니다.
- 지금까지 언급된 training procedure refinements 방법론들은 간략하게 detail한 정도로 언급되거나, source 코드를 들여다 봐야 알 수 있는 경우가 있었습니다.
- 이 논문에서는 지금까지 언급된 training procedure refinements 방법들을 모두 모아 empirically (경험적으로) 실험하고 accuracy를 평가했습니다.
- 그 결과, ResNet-50 모델에 training procedure refinements 방법론들을 적용시켰을 때, top-1 accuracy는 75.3%에서 79.29% 까지 향상됐습니다.
- 이렇게 향상된 CNN 모델은 transfer learning, object detection, semantic segmentation의 성능을 향상시키는데 좋은 영향을 미쳤습니다.
- Transfer learning, object detection, semantic segmentation 모두 CNN을 backbone으로 사용하고 있습니다.
- 즉, abstract 내용을 아래와 같이 요약정리 할 수 있습니다.
"우리 논문에서는 training precedure refinements를 위한 방법론들을 모두 적용시켜 CNN 성능을 향상시켰어!"
1. Introduction
1-1. 첫 번째 문단
→ CNN 모델 구조들의 간략한 history

- AlexNet이라는 CNN 모델이 처음 등장한 후 VGG, Inception, ResNet, DenseNet, NasNet과 같은 여러 CNN 모델이 출현했습니다.
- 이러한 CNN 모델은 image classification 분야에서 top-1 accuracy를 62.5%에서 82.7%까지 향상시켰습니다.
(↓↓↓CNN 관련 내용 정리한 카테고리↓↓↓)
'Deep Learning for Computer Vision/Convolution Neural Network (CNN)' 카테고리의 글 목록
#Interest: World History (The past) #Work: Deep Learning (The future) #Hobby: Music, Sports
89douner.tistory.com
1-2. 두 번째 문단
→ 모델링 위주의 CNN 연구도 중요하지만, CNN 학습 방법론들도 중요하다고 언급

- 앞서 언급한 Top-1 accuracy의 향상은 대부분 CNN 구조를 모델링하는 연구에서 기인했습니다.
- CNN 모델링을 하는 것 외에, training procedure refinements (ex: loss function, data preprocessing, optimization) 방법론들도 굉장히 중요하지만, 덜 주목을 받고 있습니다.
1-3. 세 번째 문단
→ "CNN 학습방법론들 적용 + 약간의 모델링 수정"을 통해 CNN 성능의 변화를 테스트

- 이 논문에서는 아래 두 가지 방법을 기준으로 CNN 모델 성능 향상을 꾀했습니다.
- Training procedure refinements
- stride size, learning rate schedule 과 같은 요소들을 적절하게 변경해주는 방법 → 이 논문에서는 이러한 방법들을 trick이라고 표현 함 → "bag of = plenty of" 이므로, 다양한 tricks(=training procedure refinements)을 사용한다고 해서, 논문 제목을 "Bag of Tricks for Image Classification with Convolutional Neural Networks"라고 명명했습니다.
- Model architecture refinements
- Training procedure refinements
- 객관적인 evaluation을 위해 다양한 CNN 아키텍쳐와 다양한 dataset을 기반으로 실험을 진행했습니다.
- 예를 들어, 특정 dataset이나 특정 모델에서만 "Bag of tricks"가 적용되는건 의미가 없기 때문입니다.
1-4. 네 번째 문단
→ "CNN 학습방법론들 적용 + 약간의 모델링 수정"을 통해 CNN 성능의 변화를 테스트

- 여러 trick들을 결합시키면 accurcy를 크게 향상시킬 수 있습니다.
- ResNet-50을 기준으로 top-1 accuracy가 75.3에서 79.29까지 향상된 것을 확인 할 수 있습니다.
- 이러한 training procedure refinements를 적용시켰을 때, 새로운 CNN 모델링 연구를 통해 개발된 SE-ResNeXt-50 모델보다 더 accuracy 성능이 좋은 것으로 나타났습니다. → 그러므로, CNN 모델링 연구 뿐만 아니라 training procedure refinements관련 연구도 중요하다는 것을 입증했습니다.
- 이러한 training procedure refinements 방법론들은 ResNet-50 모델의 성능만 향상시킨 것이 아니라, 다른 CNN 모델들의 성능도 향상시켰으므로, 이 논문에서 제시한 "training procedure refinements" 방법론들이 특정 CNN 모델에 국한되지 않았다는 것을 보여줍니다.
- 추가적으로, 이렇게 향상된 CNN 모델은 transfer learning, object detection, semantic segmentation 의 성능도 향상시켰습니다.
- 왜냐하면 CNN이 backbone network 역할을 하기 때문입니다.
(↓↓↓CNN과 object detection 관계가 궁금하시다면↓↓↓)
https://89douner.tistory.com/81?category=878735
3. Object Detection과 CNN의 관계
안녕하세요~ 이번글에서는 Object Detection과 CNN의 관계에 대해서 알아보도록 할거에요. CNN분야가 발전하면서 classification 영역에 엄청난 영향을 미친것처럼 동시에 Object detection 영역에도 굉장한 영
89douner.tistory.com
1-5. 다섯 번째 문단
→ 이 논문에서 앞으로 어떤 순서로 내용을 전개할지 언급

- 이 논문은 다른 논문들 처럼 related work, method, experiment, result 순서를 따르지 않고 있습니다.
- Section 2에서는 실험을 위한 기본적인 세팅들을 설명합니다. → 대조군(control group) 역할을 하는 모델을 설명한다고 볼 수 있겠네요.
- 이 논문에서는 크게 세 가지 방향(목적)을 갖는 개별 실험들 (Section3, 4, 5) 이 존재합니다.
- Section 3: 몇몇 tricks들이 hardware 관점에서 효과적인 것을 보여주기 위한 실험들
- Section 4: ResNet 모델의 구조를 약간 수정하면서 성능 효과를 꾀한 실험들
- Section 5: 4가지 training procedure refinements를 적용해 성능 효과를 꾀한 실험들
- 마지막 Section 6에서는 앞서 적용한 기술들로 성능 향상이 된 CNN이 transfer learning, object detection, segmentation에서 얼마만큼 좋은 영향을 끼쳤는지 볼 수 있습니다.
https://github.com/dmlc/gluon-cv
dmlc/gluon-cv
Gluon CV Toolkit. Contribute to dmlc/gluon-cv development by creating an account on GitHub.
github.com
2. Training Procedures
→ 여러 학습 방법론을 적용시키기 위한 baseline 모델이 있어야 한다. 여기서는 이러한 baseline 모델을 어떻게 training시키고, validation 했는지 설명한다.

- 이 논문에서는 아래와 같은 Batch 전략을 따르기로 했습니다.
- Mini Batch 전략
- b개수 만큼의 이미지를 하나의 batch로 설정 → 이 때, 뽑히는 이미지들은 uniformly distribution에 기반한 확률로 선별됩니다. (비복원 추출로 선별되는 듯 합니다)
- K번의 epoch을 거치고 나면 학습을 종료합니다.


(↓↓↓ Mini-Batch 관련 설명 ↓↓↓)
https://89douner.tistory.com/43?category=868069
9. Mini-Batch (데이터가 많은 경우에는 학습을 어떻게 시키나요?)
Q. 굉장히 많은 데이터를 학습시키려고 한다면 어떻게 학습시켜야 하나요? 데이터 하나하나 단계적으로 학습시켜야 하나요? 안녕하세요~ 이번시간에도 DNN(Deep Neural Network) 모델을 좀 더 효율적
89douner.tistory.com
2-1. Baseline Training Procedure

- 실험을 위해 ResNet을 baseline CNN 모델로 선정했습니다.
- training을 위한 이미 전처리 or data augmentation 전략은 아래와 같이 설정했습니다.
- 해당 전략들을 순차적으로 설명하도록 하겠습니다.

- Step1: 이 부분은 Section 3에서 "3.2 Low-precision Training" 부분을 통해 더 자세히 설명 하도록 하겠습니다.

- Step2: ImageNet의 원본 이미지 size는 굉장히 큰데, 이 크기에서 8%~100% 비율에 맞게 랜덤하게 crop 합니다. 이 때, 가로 세로의 비율은 3:4 or 4:3으로 설정합니다. 이렇게 crop된 이미지는 ResNet 입력 사이즈인 224x224로 resize됩니다.
- Step3: 50%의 확률로 horizontal flip augmentation 기법을 적용합니다.
- Step4: Scale hue, saturation, brightness의 정도(강도)를 결정하는 coefficients 를 [0.6~1.4] 범위로 설정해 줍니다.

- Step5: PCA augmentation은 AlexNet에서 사용된 data augmentation 기법입니다.
- PCA noise의 정도(강도)를 결정하는 인자 값은 normal distribution (확률분포) 를 기반으로 선별합니다.
(↓↓↓PCA augmentation에 대한 설명은 아래 글을 참고하세요!↓↓↓)
https://89douner.tistory.com/60?category=873854
6. AlexNet
안녕하세요~ 이제부터는 CNN이 발전해왔던 과정을 여러 모델을 통해 알려드릴까해요. 그래서 이번장에서는 그 첫 번째 모델이라 할 수 있는 AlexNet에 대해서 소개시켜드릴려고 합니다! AlexNet의 논
89douner.tistory.com
https://github.com/koshian2/PCAColorAugmentation
koshian2/PCAColorAugmentation
PCA Color Augmentation in TensorFlow/Keras. Contribute to koshian2/PCAColorAugmentation development by creating an account on GitHub.
github.com

Step6: 이 부분은 normalization 전처리 기법인데, 해당 기법에 대한 자세한 설명은 아래 글을 참고해주세요!
https://89douner.tistory.com/42?category=868069
8. 데이터 전처리 (Data Preprocessing and Normalization)
Q. DNN을 학습시키기 전에 왜 데이터를 전처리해주어야 하나요? 안녕하세요~ 이번시간에는 DNN 모델이 학습을 효율적으로 하기위해 필요한 정규(Noramlization; 정규화) 대해서 알아보도록 할거에요~
89douner.tistory.com
※ 여기서는 실제 논문에서 기재된 문단 순서를 조금 변경했습니다 (개인적으로 training 관련 내용들을 다 적어주고, validation을 언급해주는게 좋다고 봐서....)

- 가중치 초기화: Xavier → [-a, a] 범위에서 uniform sampling
- Batch norm layer의 hyper-parameter인 값들을 다음과 같이 설정 (gamma=1, beta=0)
- 이 부분은 "3.1 Large-bath training"에서 "Zero \(\gamma\)를 설명할 때 더 자세히 말씀드리겠습니다.
- Optimizer: Nesterove Accelerated Gradient (NAG) descent
- Epoch: 120
- batch size: 256
- Learning rate: 0.1
- 30, 60, 90번째 epoch에 도달할 때마다 10을 나눠줌
- epoch=30→0.01, epoch=60→0.001, epoch=90→0.0001
- 30, 60, 90번째 epoch에 도달할 때마다 10을 나눠줌
- GPU: 8 NVIDIA V100 GPUs
(↓↓↓Volta가 궁금하시다면↓↓↓)
https://89douner.tistory.com/159?category=913897
4.NVIDIA GPU 아키텍처(feat.FLOPS)
안녕하세요~ 이번글에서는 NVIDIA에서 출시했던 GPU 아키텍처들에 대해 알아볼거에요. 가장 먼저 출시됐던 Tesla 아키텍처를 살펴보면서 기본적인 NVIDIA GPU 구조에 대해서 알아보고, 해당 GPU의 스펙
89douner.tistory.com

- Validation 할 때는 아래와 같은 방식으로 진행합니다.
- ImageNet 원본 이미지에서 가로, 세로 중 길이가 짧은 쪽을 기준으로 256 pixel(길이)로 만듭니다. 이때, 더 긴쪽의 길이 또한 aspect ratio (가로, 세로 비율)을 유지해주면서 변경해 줍니다.
- 이렇게 변경된 이미지에서 224x224 만큼 크기로 center crop 해주고, normalization 전처리 작업을 해줍니다.
- 최종적으로 전처리가 된 이미지를 기반으로 validation을 진행합니다.
2-2. Experiment Results

- 위에서 baseline으로 설정한 값들을 기준으로 ResNet-50, Inception V3, MobileNet 을 학습시키고 validation 했습니다.
- Dataset은 ISLVRC2012 challenge에 사용된 데이터를 이용했습니다.
- Inceptoin V3는 본래 입력 사이즈가 299x299이기 때문에, 앞서 언급한 224x224 resize 방식을 299x299 resize 방식으로 변경해 적용했습니다.
- 아래 테이블은 실제 paper(←reference)에서 제시한 결과들과 자신들이 적용한 baseline을 토대로 얻은 결과값을 비교한 것입니다.
- 이 후부터 적용할 여러 학습방법론들은 reference가 아닌 baseline과 비교해가면서 성능변화를 살펴볼 예정입니다. (당연히 자신들이 실험하는 환경의 baseline(=대조군)을 기반으로 여러 학습방법론들을 적용해야 유의미한 실험군이 되므로, 대조군과 실험군간에 비교가 유의미해집니다)

3. Efficient Training
→ Accuracy 성능을 떨어뜨리지 않으면서 빠르고 효과적으로 training 시키는 방법을 소개

- 보통 하드웨어에서 말하는 trade-off는 speed와 accurcay의 관계를 의미합니다.
- speed를 키우기 위해서 하는 행위들이 accuracy를 낮추는 행위가 되기도 하기 때문에 서로 trade-off 관계가 성립이 됩니다.
- 그래서 speed와 accuracy를 모두 취할 수 있는 적절한 지점 (optimal choices) 을 잘 찾아야 하죠.
- 이 논문에서는 lower numerical precision과 larger batch sizes를 이용하여 model의 accuracy가 떨어지지 않으면서도 좀 더 빠르고 효율적으로 CNN을 training 시키는 방법을 제안하고 있습니다.
3-1. Large batch training

- 이 글에서는 이미지 하나를 batch size로 잡기보단, 여러 이미지를 batch size로 잡는 mini-batch 전략을 세울 때 얻을 수 있는 장점과 단점을 이야기 하고 있습니다. → 즉, batch size를 키워줄 때 발생하는 장점과 단점을 설명하고 있습니다.
- 먼저, 장점에 대해서 알아보고 단점을 알아보도록 하겠습니다.
[장점] Large Batch size → Increase parallelism and decrease communication costs
- Parallelism과 communication costs에 대한 이해를 위해서는 CNN이 weight를 업데이트할 때 GPU내에서 어떻게 동작하는지 알고 있어야 합니다.
- Parallelism과 Multi-GPU
- Step1. 각각의 GPU에 딥러닝 모델을 복사해서 올린다. → 예를 들어, 3개의 GPU가 있고 각각 9GB라고 가정하고, 3G 크기의 딥러닝 모델이 복사되어 각각의 GPU에 업로드 된다고 하면, 현재 각각의 GPU (A, B, C)의 용량은 6GB의 여유 용량이 있다.
- Step2. 자신이 잡은 batch size (mini-batch)가 99라고 한다면, 각각의 A, B, C GPU에 33개씩 이미지 데이터를 VRAM(비디오 메모리)에 할당한다. → 만약, 33개의 이미지 용량의 6GB를 넘는다면 GPU memory 에러가 발생한다.
- Step3. 각각의 GPU는 자신들이 할당 받은 (해당 GPU 고유의) 33개의 error 값에 대한 (평균) loss 값을 계산한다.
- Step4. 각각의 GPU에서 얻은 loss값을 다시 합산하여 GPU 개수 (여기에서는 3개) 만큼 나누면 mini-bath size 만큼의 데이터에 대한 loss 값이 계산이 된다.
- Step5. Mini-batch size loss 값을 각각의 GPU에 전달하면 mini-batch size 이미지들에 대한 gradient 값을 갖을 수 있게 된다.
- Step6. 이후 같은 gradient 값으로 각각의 GPU에 있는 모델 parameter가 업데이트 되게 된다.
- 결국, mini-bath size를 크게 잡을 수록 다수의 GPU를 (동시에) 최대한 활용하게 되며, 이를 통해 parallelism을 증가시킨다고 볼 수 있다.

- Parallelism과 Single-GPU
- Batch size 만큼의 데이터가 GPU에 올라갑니다.
- GPU를 활용한다는 것은 그만큼 병렬처리를 잘하기 위함인데, GPU 당 이미지 데이터를 하나만 cover하는 것 보다, 2개의 이미지 데이터를 cover하는 것이 GPU를 더 잘 활용한다고 할 수 있죠.
- 즉, batch size를 크게 잡아줄 수록 그만큼 병렬성(parallelism)을 증대시킨 것이라고 할 수 있습니다.
(↓↓↓GPU 내부동작 살펴보기↓↓↓)
https://89douner.tistory.com/157?category=913897
2.내장그래픽과 외장그래픽 그리고 GPU 병목현상(feat. Multi-GPU)
안녕하세요~ 이번글에서는 내장그래픽과 외장그래픽에 대해서 알아보면서 그래픽카드의 내부구조 동작 방식에 대해 간단히 알아보도록 할거에요. 그리고 딥러닝을 돌리시다보면 CUDA memory alloca
89douner.tistory.com
- Communication cost와 GPU
- Multi-GPU 측면에서 보면, 만약 각각의 GPU에 하나의 이미지만 할당된다고 하면 나중에 각각의 GPU에서 발생한 loss 값들 (=3개의 loss 값들) 을 최종 합산 해야 하는 빈도가 많아집니다. → 또한, 각 GPU에 평균으로 계산된 loss 값들이 전달이 되겠죠.
- 각 GPU에 평균 loss 값을 전달하는 거리와, 33개의 데이터를 하나의 GPU 안에서 병렬처리 했을 때, 서로의 물리적 거리를 고려한다면 당연히 후자의 경우 communication cost가 적다고 할 수 있습니다.
- Single-GPU 측면에서 봤을 때도, update 횟수가 잦아질 수록 communication cost가 커지겠죠. (딥러닝 모델이 GPU에 업로드 되어있다는 것을 상상해보세요! 업데이트가 잦을 수록 gradient 값들이 GPU 내에서 이동하는 횟수도 증가하겠죠?)
[단점] Large batch size → Slow down training progress + convergence rate decrease + degraded validation accuracy
- Batch size를 키운다는 것은 speed 면에서 좋을 수 있지만, accuracy 면에서는 좋지 못할 수 있습니다.
- "slow down training progress"라는 말은 global minimum loss에 도달하기까지 걸리는 training epoch의 횟수가 크다는 것을 말합니다.
- 즉, GPU에서 학습하는 물리적인 속도를 의미하는 것이 아니고, optimization 측면에서 봤을 때의 학습속도를 의미합니다.
- 예를 들어, batch size=1 인경우에는 training epoch=20 이라고 했을 때, batch size=20 으로 늘려주면 training epoch=40 이 되는 개념입니다. (→관련링크)
- 이러한 근거로 convex problem이라는 용어를 사용했는데, convex problem 관점에서 봤을 때, batch size를 키워주면 convergence rate 이 좋지 않아지는데, 이것이 validation accuracy를 악화시키는 요인이 된다고 합니다.
- 이 부분은 convex optimization 관점에서 SGD를 이해하고 있어야 하는데, 추후에 convex optimization 정리가 다끝나면 해당 링크를 추가하도록 하겠습니다.
- 이미 개념을 알고 있으시다면, "DON’T DECAY THE LEARNING RATE, INCREASE THE BATCH SIZE" 논문의 section 2를 참고하시면 될 것 같습니다.
(↓↓↓현재까지 정리되어 있는 convex optimization 내용들 ↓↓↓)
'딥러닝수학/Convex Optimization' 카테고리의 글 목록
#Interest: World History (The past) #Work: Deep Learning (The future) #Hobby: Music, Sports
89douner.tistory.com
[Four heuristic methods]
- 이 논문에서는 앞서 언급한 단점을 커버하는 4가지 heuristic한 방법들을 제시합니다.
- Linear scaling learning rate
- Learning rate warm-up
- Zero gamma
- No bias decay
- 즉, batch size를 키우면서도 accuracy를 악화시키지 않고, training 효율성은 증가시키는 방식들을 제안합니다.
3-1-1. Linear scaling learning rate
→ batch size를 키워줄 때, learning rate을 어떻게 변화시켜주면 좋을지 설명하는 내용

- (아래 그림과 같이 봐주시면 좋을 것 같습니다)
- Mini-batch 방식으로 학습하면, Mini-batch 당 parameter를 updating 하게 되는데, 첫 번째 mini-batch에서 업데이트해서 조정된 parameter(weight)값들은 첫 번째 mini-batch에 특화되어 있을 가능성이 큽니다.
- 예를 들어, 아래 그림에서 첫 번째 미니배치 업데이트 수식을 보면 해당 미니배치에 할당된 이미지들을 classification한 error값을 평균 냅니다. 즉, 해당 미니배치에서 구성되어 있는 이미지들이 problem space가 되었을 것이고, 해당 problem space에서 SGD 방식이 진행되었을 것입니다.
- 하지만, 두 번째 미니배치는 또 다른 이미지들의 집합이기 때문에 해당 이미지들을 평균적으로 잘 classification하기 위해 학습 할 것입니다. 즉, SGD 방식은 같으나 첫 번째 미니배치에서의 problem space와는 다른 problem space에서 SGD 방식이 진행될 것 입니다.
- 만약, mini-batch size가 커진다면 즉, 극단적으로 모든 이미지를 하나의 mini-bath size로 잡는다면 epoch당 학습하는 problem space는 매번 동일할 것입니다. → 배치 size가 커지면 커질 수록 mini-batch간의 error 값들이 서로 차이가 많이 안날 것이고 이에 따라 우측과 같은 표현을 할 수 있게 됩니다 → "Increasing batch size does not change the expectation of the SGD but reduces its variance"
- 다른 관점에서 보면, batch size가 커질 수록 많은 데이터를 sampling 하기 때문에 결국 데이터 평균에 수렴한다는 중심극한정리 관점에서도 해석해 볼 수 있을 듯 합니다.

- 일반적으로 batch size가 커질 수록 안전하게 학습이 됩니다. 안전하다는 말을 수학적으로 풀어 설명하려면 위에서 언급한 것처럼 convex optimization 관점에서 설명해야 하는데, 너무 길어질 듯하여 생략하도록 하겠습니다.
- 개인적으로는 batch size를 크게 잡아주면 problem space(loss landscape)가 좀 더 global minimum을 찾기 쉽게 smooth해지는게 아닌가 싶습니다. (← 주관적인 해석이라 그냥 넘어가셔도 좋을 듯 합니다)

- 결국 안정화된 problem space 에서는 learning rate을 크게 잡아줘도 올바른 방향으로 학습을 할거라 생각합니다. (←이 부분도 주관적인 해석이니 넘어가셔도 좋습니다)
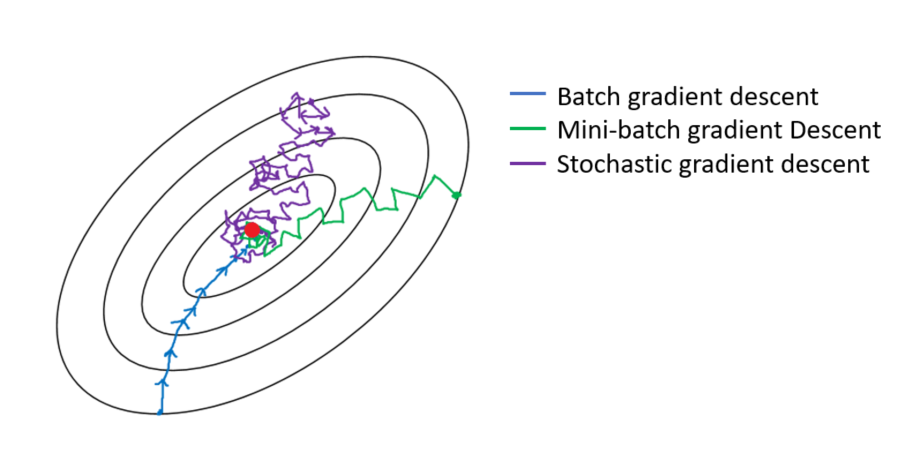
- "Accurate, large minibatch SGD: training imagenet in 1 hour." 논문에서는 경험적으로 batch size가 증가하면, linear하게 learning rate도 증가시켜주는게 좋다고 합니다.
- "Deep residual learning for image recognition" 논문에서는 batch size 256 일 때, learning rate 값을 0.1로 설정했고, 256 batch size 보다 크면 learning rate를 0.1보다 증가시켜주고, 256 batch size보다 작으면 learning rate를 0.1보다 감소시켜주는것이 좋다고 합니다.

- 결과적으로 이야기하면, batch size를 키워주면 GPU를 최대한 활용할 수 있어 speed는 빨라집니다. 하지만, accuracy 성능이 크게 떨어질 수 있는데, learning rate을 linear하게 키워준다면 그나마 accuracy 성능이 감소하는 것을 상쇄해줄 수 있다는 것이 이 논문에서 주장하는 바 입니다.
3-1-2. Learning rate warmup

- 초기에는 layer의 가중치 값들이 굉장히 불안정하기 때문에 너무 큰 learning rate를 적용하면 loss값이 지나치게 커저 gradient exploding 할 수 있습니다.
- 그래서 학습 초기에는 learning rate를 낮게 설정해주고, 특정한 학습 단계에 도달할때 까지는 천천히 learning rate을 증가시켜주는것이 좋다고 합니다.
- 이 논문에서는 아래와 같이 5 epoch에 해당하는 "m"개의 batch까지는 learning rate을 서서히 증가시켜줍니다.

(↓↓↓Warm-up 관련 github code↓↓↓)
https://github.com/ildoonet/pytorch-gradual-warmup-lr
ildoonet/pytorch-gradual-warmup-lr
Gradually-Warmup Learning Rate Scheduler for PyTorch - ildoonet/pytorch-gradual-warmup-lr
github.com
3-1-3. Zero gamma
→ Residual block에 위치한 Batch Normalization layer의 zero gamma 값을 0으로 초기화 시켜주면 초기학습 단계에서 더 적은 layer로 효과적으롤 학습할 수 있음 → Speed도 증가시키면서, accuracy 성능도 악화시키지 않음

- 위에서 설명한 "All BN layers that sit at the end of a residual block"의 위치는 아래와 같습니다.

- 첫 training에서는 gamma와 beta 부분이 0으로 설정되어 있기 때문에, block(x)값은 0이 됩니다.
- 즉, 첫 training 시에는 학습에 관여하지 않게 된다는 말과 같습니다.
- 결과적으로, 초기에는 "identity ResNet block" 부분이 관여를 하지 않기 때문에 layer 수를 급격히 줄인 상태에서 학습시키는 것과 같은 방식이 됩니다.
- 개인적으로 봤을 때 layer들도 단계별로 warm-up 시켜 학습시킨게 아닌가 싶습니다.
- 아무리 residual block으로 vanishing gradient 문제를 개선시켰다고 하더라도 그 문제를 완전히 해결 한 것이 아닙니다. 즉, vanishing gradient로 인해 초기 layer 부분에서 학습이 잘 안된 상태에서 뒷 쪽 layer 위주로 학습이 됐을 가능성도 있습니다.
- 그래서, 초기에는 적은 수의 layer로 학습시켜 해당하는 8개의 layer를 안정화 시켰던 것 같습니다.
- Gamma 값은 아래와 같이 업데이트 됩니다.

- Batch Normalization 관련 설명도 제 블로그에 다루었으나, 최근에 나오는 paper들이 기존 BN 이론을 반박하는 내용들이 많아, 이 부분은 batch normalization 파트를 따로 개설해 정리하도록 하겠습니다.
3-1-4. No bias decay
→ bias, bath normalization's gamma and beta 에는 regularization을 적용하지 않는 것이 좋다

- “Highly Scalable Deep Learning Training System with Mixed-Precision(Training ImageNet in Four Minutes)”논문에서 사용된 regularization 방식을 사용했습니다.
- Weight에만 regularization을 적용하고, bias나 batch layer에서는 regularization을 적용하지 않았다고 합니다.
- bias에도 regularization을 적용하면 모든 파라미터들의 값들이 0으로 수렴한다고 하는데, 이 부분에 대해서는 아직 명확한 이유를 모르겠어서 추후에 더 공부한 후 설명을 하려고 합니다 (뭔가.. 되게 기초적인 내용 같은데;;)
- 위와 같은 이유 외에 bias에 regularziation을 적용하지 않는 다른 이유를 설명해보겠습니다.
- Y=WX+B
- Regularization is based on the idea that overfitting on Y is caused by W being "overly specific", so to speak, which usually manifests itself by large values of X's elements.
- B merely offsets the relationship and its scale therefore is far less important to this problem. Moreover, in case a large offset is needed for whatever reason, regularizing it will prevent finding the correct relationship.
Why is the bias term not regularized in ridge regression?
In most of classifications (e.g. logistic / linear regression) the bias term is ignored while regularizing. Will we get better classification if we don't regularize the bias term?
stackoverflow.com
- 결론적으로 말하자면, bias와 batch normalization의 gamma, beta는 overfitting에 기여도가 낮습니다.
- 오히려, 이 부분에 regularization을 주면, underfitting이 일어날 확률이 더 커질 수 있다고 하니 regularization을 적용 할거면 weight에 대해서만 적용하는 것이 바람직하다고 설명하고 있습니다 (Ian goodfellow 저서인 Deep Learning 책을 보시면 설명이 나온다고 하니 참고하시면 좋을 것 같습니다).
3-1-5. Low-precision training

- Votal 관련한 FP16 설명은 아래 글을 참고해주세요.
(↓↓↓FP에 대한 개념과 Volta 아키텍처에서의 Mixed precision 설명 ↓↓↓)
https://89douner.tistory.com/159?category=913897
4.NVIDIA GPU 아키텍처(feat.FLOPS)
안녕하세요~ 이번글에서는 NVIDIA에서 출시했던 GPU 아키텍처들에 대해 알아볼거에요. 가장 먼저 출시됐던 Tesla 아키텍처를 살펴보면서 기본적인 NVIDIA GPU 구조에 대해서 알아보고, 해당 GPU의 스펙
89douner.tistory.com

- 위의 설명은 아래 그림으로 도식화 할 수 있습니다. (FWD: ForWarD, BWD: BackWarD)
- 간단히 설명하면 연산과정에서 forwarding하는 것과, gradient값을 구하는 과정에는 곱셈연산이 다수 포함되기 때문에 이러한 부분들은 FP16으로 처리하고, updating 시에는 이전 weight에 gradient값을 단순히 더해주기만 하면 되기 때문에 이 때만 FP32를 적용해 low-precision의 단점을 커버했습니다.

- "Multiplying a scalar to the loss" 관련 내용은 loss scaling을 말하는 것으로써 자세하 설명하자면 아래와 같습니다.
- Weight를 FP16으로 변환시켰을 때, 소수의 weight gradeint 값만 FP16으로 표현이 불가능하여 0값으로 설정된다고 합니다.
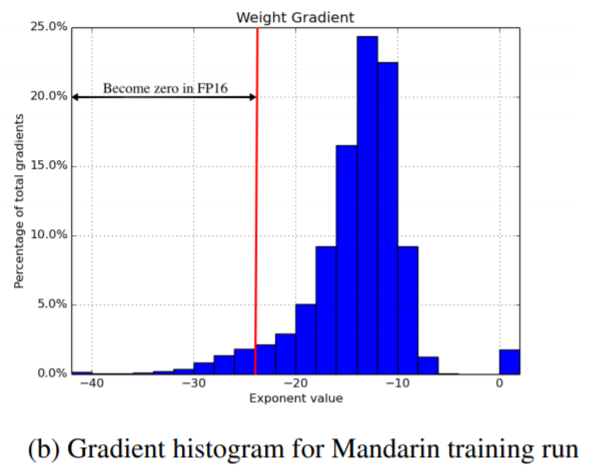
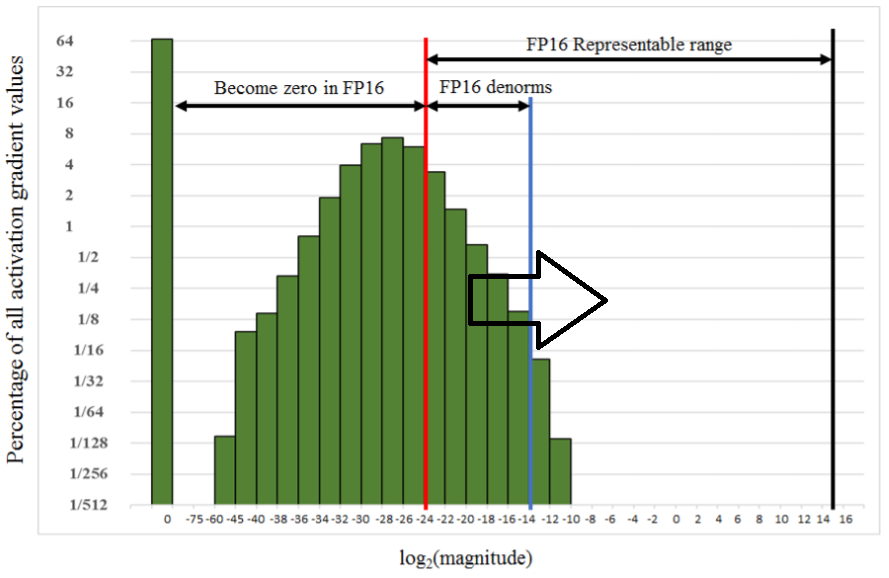
- 하지만, activation gradient값들은 FP16으로 표현될 시 대부분 표현불가능해 진다고 합니다. 즉, activation gradeint 값들이 대부분 0이 되는 것이죠. (아래 Become zero in FP16으로 표현되어 있는 부분이 FP16으로 표현했을 때 activation gradeint 값들 대부분이 0됩니다.)

- 이 때, loss값을 scalar만큼 곱해주면 당연히 gradient값도 커지게 되집니다.
- 즉, loss scaling(=multiplying scalar to loss) 을 통해, activation gradeint 값을 조금씩 증가시켜주면
- ex) activation gradient = 0.00000000000000000000000000000001 FP16 표현 불가 → by loss scaling, activation gradient = 0.000000000000001 FP16으로 표현 가능
(↓↓↓loss sacling 참고할만한 사이트↓↓↓)
https://hoya012.github.io/blog/Mixed-Precision-Training/
Mixed-Precision Training of Deep Neural Networks
NVIDIA Developer Blog 글을 바탕으로 Deep Neural Network를 Mixed-Precision으로 학습시키는 과정을 글로 작성하였습니다.
hoya012.github.io
(↓↓↓Mixed precision and loss scaling 참고할만한 사이트↓↓↓)
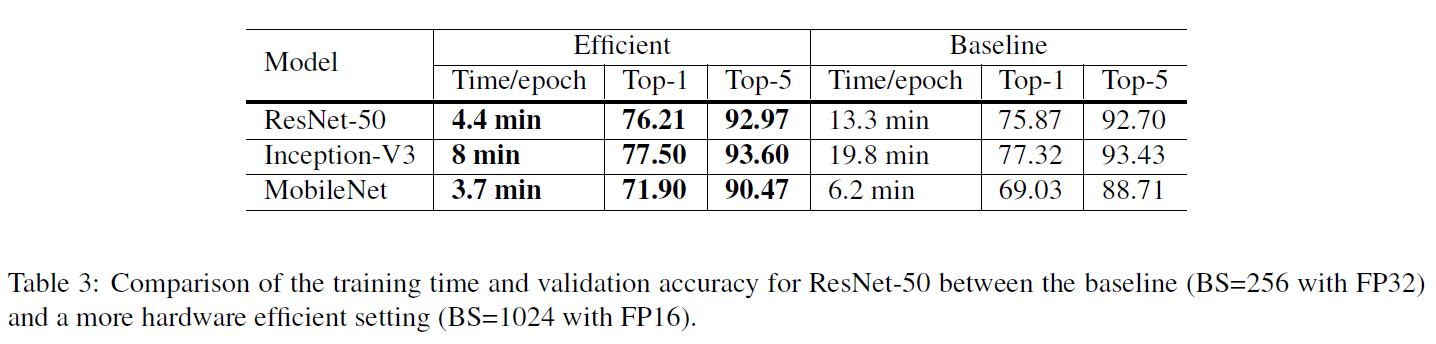
- Batch size를 크게 키우면서 low-precision을 적용시킨 결과입니다. 학습은 빠르게 되면서 accuracy 또한 감소되지 않은 것을 볼 수 있습니다.
- 특히 이러한 결과는 특정모델에 국한된 결과가 아니라 다양한 CNN 모델에서 발견됐기 때문에, 굉장히 유의미한 결과라고 볼 수 있습니다.
3-3. Experiment Results
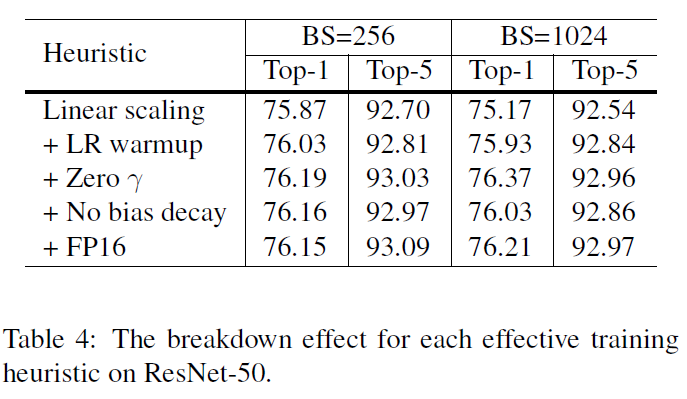
- 앞서 batch size를 키워줄 때 적용시켜줄 4가지 heuristic methods(="3-1"에서 언급)와 "3-2"에서 언급한 low-precision을 적용시켰을 때, accurcay의 변화에 대한 결과 입니다.
- 논문에서는 이 결과에 대해 해석을 내놓고 있기는 한데, 개인적으로는 위와 같은 결과는 큰 의미가 없어보입니다.
- 통계적으로 이러한 변화를 보려면 random seed 값을 다르게 해준 후, 적어도 30개의 결과 sample을 통해 비교해줘야 통계적 해석이 가능합니다.
- 여기서는 seed 값을 어떻게 설정해줬는지 설명도 안나와 있는데, 만약 하나의 seed 값만 활용했던거라면, 다른 seed 값을 적용했을 0.xx% 의 차이는 충분히 바뀔 수 있습니다. (random seed에 따라 batch에 포함되는 이미지 순서도 바뀔 수 있으니.... → 참고로 학습하는 이미지 순서도 validation accuracy 결과에 굉장한 영향을 미칠 수 있습니다)
- 뒤에서 더 이야기 하겠지만, 개인적으로 Zero gamma와 FP16 부분이 흥미로웠는데, FP16은 Volta GPU 아니라 적용 못 시켜봤고, zero gamma 부분은 transfer learning에 맞게 변경시켜 적용시키니 유의미한 결과를 얻기도 했습니다. (→ 맨 뒤에서 간단히 추가 설명하도록 하겠습니다)
4. Model Tweaks
- Model tweaks 부분은 단순히 ResNet의 일부 구조를 변경시킨 것이라 특별히 설명할 부분이 없어서, 아래 사이트 링크를 걸어두었습니다.
- 아래 사이트를 참고하셔도 되고, 충분히 논문의 그림만 보셔도 이해가 수월 하실거라 생각합니다.
CNN 꿀팁 모음 (Bag of Tricks for Image Classification with Convolutional Neural Networks) 논문 리뷰
논문 제목 : Bag of Tricks for Image Classification with Convolutional Neural Networks 오늘은 Bag of Tricks for Image Classification with Convolutional Neural Networks에 대해 리뷰를 해볼까..
phil-baek.tistory.com
- 만약, 해당 논문에 제시된 모델 중에 사용해보고 싶으신 모델이 있으시다면 아래 사이트에서 ResNet 부분을 참고하시고, pre-trained model을 이용하면 될 것 같습니다 (MXNET 기반입니다. Pytorch 버전은 추후에 추가할거라고 하네요)

https://cv.gluon.ai/model_zoo/classification.html#id239
Classification — gluoncv 0.11.0 documentation
cv.gluon.ai
5. Training Refinements

- 앞서 배운내용을 잠시 정리하면 다음과 같습니다.
- Section3: batch size를 키워주어 학습을 빠르게 진행하되 accuracy를 악화시키지 않는 방법들 소개
- Section4: ResNet의 모델을 조금씩 바꿔주면서 accuracy를 향상
- 이번 section5에서는 4가지 학습 방법론 (training refinements) 을 소개하면서 accuracy를 향상시키는 방법에 대해서 설명해보겠습니다.
5-1. Cosine Learning Rate Decay

- 앞서 특정 batch 까지는 learning rate warm-up 적용시킨다고 언급했습니다.
- learning rate warm-up 이후에는 learning rate decay를 하게 됩니다.
- 아래 그리처럼 epoch 마다 특정 learning rate 값을 설정해주면 step decay가 되고, batch마다 꾸준히 cosine annealing function을 이용해 learning rate 값을 줄여주면 cosine decay가 됩니다.
- 이 논문에서는 처음 warm-up 단계에서의 batch 동안에는 이 함수가 적용되지 않기 때문에 실제 t값은 아래의 범위를 갖습니다.
- t > total_number_of_batches_for_warm_up

(↓↓↓ Cosine learning rate 관련 github코드↓↓↓)
https://github.com/katsura-jp/pytorch-cosine-annealing-with-warmup
katsura-jp/pytorch-cosine-annealing-with-warmup
Contribute to katsura-jp/pytorch-cosine-annealing-with-warmup development by creating an account on GitHub.
github.com
(↓↓↓ Cosine learning rate 관련 pytorch코드↓↓↓)
https://pytorch.org/docs/stable/optim.html
torch.optim — PyTorch 1.8.1 documentation
torch.optim torch.optim is a package implementing various optimization algorithms. Most commonly used methods are already supported, and the interface is general enough, so that more sophisticated ones can be also easily integrated in the future. How to us
pytorch.org
- 개인적으로 Medical imaging transfer learning을 위해 cosine annealing 기법을 적용시켜 봤을때, 큰 효과는 없었습니다. (Warm-up은 약간의 성능향상을 가져오긴 했습니다)
5-2. Labeling smoothing
- 해당 논문에서 언급하는 label smoothing에 대한 직관적인 개념은 아래와 같습니다.
- 보통 one-hot encoding labeling을 사용하게 되면 [0, 0, 0, 1, 0, 0, 0] 이런 식으로 실제 정답에 1을 부여하는 식으로 q분포를 설정해줍니다. 그리고, 딥러닝이 예측하는 p분포와 cross entropy 수식을 통해 점점 p분포와 q분포의 gap을 줄여주게 되죠.
- 하지만 이러한 one-hot encoding 방식에는 직관적으로 봤을 때 여러 문제가 있습니다.
- 예를 들어, 우리가 아래 이미지 대해서 정답 labeling을 한다고 해보겠습니다.
- 여러분은 아래 이미지가 고양이다라고 100% 확신할 수 있으신가요?
- 아래 이미지에는 안경, 책 같은 물체들도 포함되어 있는데 아래 이미지의 제목을 100% 고양이라고 붙이긴 힘들거라고 생각합니다.
- 결과적으로, 딥러닝 모델에게 "이러한 이미지가 100% 고양이다"라고 하는 것 자체가 잘 못된 학습을 시켜주는게 될 수 도 있습니다. (실제로 "From ImageNet to Image classification" 이라는 논문에서는 ImageNet labeling에 대한 문제점도 제기하고 있죠)
- 그 외에 다른 측면에서보면, 특정 label에 100%의 확률을 할당하는 건 딥러닝 모델이 해당 label 이미지에 overfitting하게 학습시킬 우려가 있습니다.
- 위와 같은 이유로 [0, 0, 0, 1, 0, 0] → [0.1, 0.1, 0.1, 0.5, 0.1, 0.1] 와 같이 label smoothing을 적용시켜주어 위와 같은 문제를 피하려고 하고 있습니다.

- 논문에 있는 labeling smoothing을 적용시키는 q부분은 이해하기 어렵지 않습니다.
- 하지만, 개인적으로 logPy에서 log와 exponential 함수가 합성함수 형태로 되어 있는 부분과, z에 대한 optimal solution 부분이 이해가 잘 안되어 이 부분에 대한 설명은 추후로 미뤄야 할 것 같습니다. (P분포와 Q분포의 차이를 줄여주는 관점을 또 다른 식으로 표현한 거 같긴한데, KL divergence 관점에서의 수식도 아닌거 같고.. 기본 지식에 대한 이해가 안되어 있는건지, 논문에서 설명이 부족한건지.. ;;)
- 어떻게 적용하는지는 수식만 따라하면 하겠지만, 해당 수식에 대한 직관적인 이해가 잘 안되고 있어서 나중에 알게 되면 다시 수정하도록 하겠습니다.
- 하지만, 논문에서 언급한 Labeling smoothing 적용 방법은 어렵지 않으니 논문을 보시면 쉽게 적용하실 수 있으실 겁니다.
5-3. Knowledge distillation
- Knowledge Distillation에 대한 부분은 아래 카테고리에서 여러 Knowledge distillation 모델을 다룬 논문들을 게재하고 있으니 참고해주시면 감사하겠습니다.
- 본래 Knowledge distllation은 Network compression에서 자주 사용되던 개념이었지만, 최근에는 KD를 학습방법론에 이용하기도 하고, 앙상블 관점에서도 응용해서 적용시키기도 하기 때문에 배워두시면 여러 방면에서 도움이 될거라 생각합니다.
https://89douner.tistory.com/category/Network%20Compression%20for%20AI/Knowledge%20Distillation
'Network Compression for AI/Knowledge Distillation' 카테고리의 글 목록
#Interest: World History (The past) #Work: Deep Learning (The future) #Hobby: Music, Sports
89douner.tistory.com
5-4. Mix-up training
- Mix-up에 관한 설명은 "MixMatch; A Holistic Approach to Semi-Supervised Learning" 논문을 리뷰한 곳에서 자세히 설명되어 있으니, 아래 링크를 참고해주시면 감사하겠습니다.
(↓↓↓MixMatch 논문에서 Mix-up 개념 설명↓↓↓)
https://89douner.tistory.com/249
1.MixMatch; A Holistic Approach to Semi-Supervised Learning
현재 다른 페이지에 작성하고 있습니다. 6월 11일 안으로 작성이 완료되는대로 글을 옮겨적도록 하겠습니다.
89douner.tistory.com

- 지금까지의 언급한 내용을 다양한 CNN 모델에 적용한 결과가 Table 6입니다.
- ImageNet이 아닌 다른 dataset(=MIT Places 365)으로 test한 결과는 Table7 입니다.
- 개인적으로 1%이상 차이가 나지 않는 결과들에 대해서는 회의적으로 보는 경향이 있습니다.
- Seed를 어떻게 설정해주느냐에 따라서도 결과가 바뀔 수 도 있고, 가끔씩 자신들에게 유리한 실험결과들만 올리는 듯한 느낌을 받기도 하기 때문입니다.
- 하지만, 실제로 다른 도메인에 trasnfer learning 관점에 맞춰 적절하게 방법을 변경하거나, object detection, segmentation 모델에 적용해보면 큰 achievement를 달성하는 경우도 있기 때문에, 해당 방법론들을 경우에 따라 잘 적용하려는 노력과 연구가 필요하다고 생각합니다.
6. Transfer Learning (for Object detection, Segmentation)

- Table8은 bag of tricks를 CNN에 적용한 후, Faster RCNN(object detection model)의 backbone으로 사용했을 때 결과들을 보여주고 있습니다. 최대 대략 4%까지 성능이 향상되는 것을 보면 꾀 유의미한 결과라고 볼 수 있을 듯 합니다.
- Table9는 FCN (segmentation model)에 해당 trick들을 적용한 결과입니다. 그래도 1% 이상의 성능향상을 이끄는 것을 보면 유의미한 결과라고 볼 수 있을 듯 합니다.
[개인적인 경험 글]
- 위에서 언급 한 방법론 들을 medical 연구를 진행할 시 적용시켜 보았습니다 (KD, Mix-up, low precision을 제외).
- 해당 방법론들 중에서 warm-up 부분과 batch normalization zero gamma 방법들이 성능향상에 기여했습니다.
- 개인적인 경험에서는 batch normalizatioin에 zero gamma 부분을 적절하게 세팅해주는게 유용할 때가 많았습니다.
- 예를 들어, X-ray 이미지 domain에 transfer learning을 적용할 시, 이 논문에서 제시된 모든 BN layer에 zero gamma를 적용해주는 것 보다, 뒷 쪽에 conv layer에 위치한 BN layer 중 적절한 위치에 zero gamma 또는 one gamma로 세팅해주는게 유의미한 결과를 가져올 때가 많았습니다 (현재 해당 방법을 COVID-19 X-ray데이터 적용한 논문이 under review 중이라 결과가 나오면 따로 논문을 review하도록 하겠습니다)
- Mix-up은 Medical data에 적용시키기가 조심스러운 부분이 있을거라 판단해서 적용하지 않았습니다.
- KD 관련 방법론은 올해 GAN과 CNN을 융합할 때 같이 적용해보려고 하고 있습니다.
- Low precision or Mixed precision 방법은 GCP 기반으로 volta GPU를 세팅한 후, GCP 베이스로 학습을 시킬 때 적용해보려고 하고 있습니다.
(↓↓↓Bag of Tricks for Image Classification with ~ 관련 Tensorflow 2 코드↓↓↓)
Bag of Tricks for Image Classification with Convolutional Neural Networks in Keras | DLology
Posted by: Chengwei 2 years, 6 months ago (Comments) This tutorial shows you how to implement some tricks for image classification task in Keras API as illustrated in paper https://arxiv.org/abs/1812.01187v2. Those tricks work on various CNN models like
www.dlology.com
지금까지 읽어주셔서 감사합니다!
'딥러닝 응용 > CNN 학습기법관련 논문들' 카테고리의 다른 글
| 1. ImageNet-Trained CNNs are Biased Towards Texture; Increasing Shape Bias Improves Accuracy And Robustness (2) | 2021.06.05 |
|---|---|
| 이 글을 쓰는 이유 (0) | 2021.06.04 |