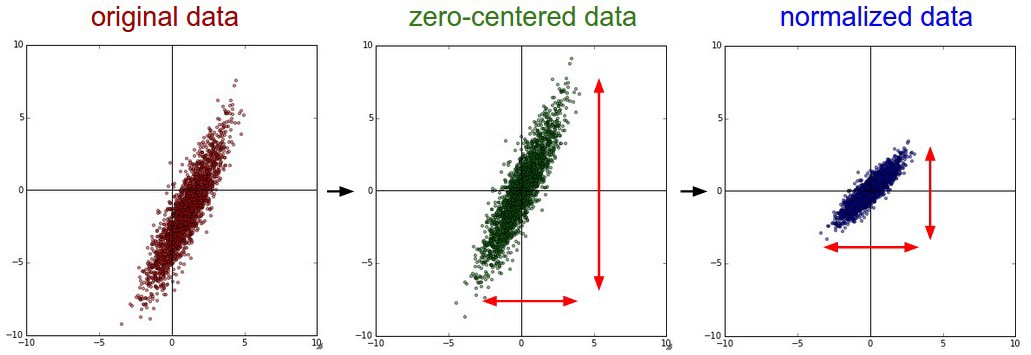
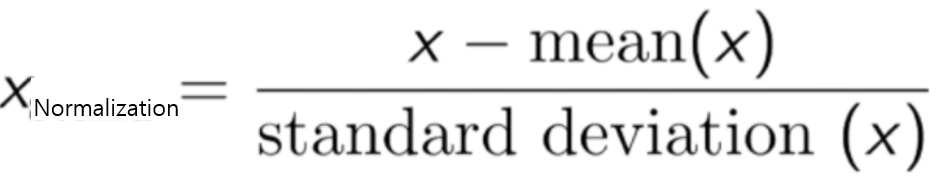안녕하세요.
이번 장에서는 지난시간에 배운 내용들을 토대로 코드를 작성해보도록 하겠습니다.
첫 번째에는 아예 새로운 CNN 모델을 구축(by Functional API)하여 학습시키는 방식을 구현하고, 두 번째에는 pre-trained model을 다운받아 transfer learning과 fine-tuning을 적용시킨 방식을 구현해보도록 하겠습니다.
1. New model 구축 버전
import os
from tensorflow import keras
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import layers
from tensorflow import keras
import matplotlib.pyplot as plt
import math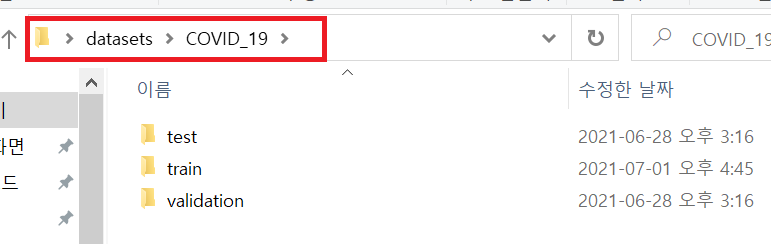
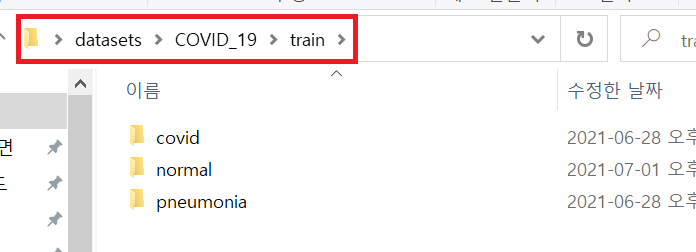
base_dir = './datasets/COVID_19/'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
train_datagen = ImageDataGenerator(
featurewise_center=True,
featurewise_std_normalization=True,
rescale=1./255,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
validation_split=0.2)
validation_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 타깃 디렉터리
train_dir,
# 모든 이미지를 150 × 150 크기로 바꿉니다
target_size=(150, 150),
batch_size=32,
# categorical_crossentropy 손실을 사용
class_mode='categorical') #COVID_19는 3개의 클래스로 구성됨
validation_generator = validation_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='categorical')
input_shape = (150,150,3)
img_input = layers.Input(shape=input_shape)
output1 = layers.Conv2D(kernel_size=(3,3), filters=32, activation='relu')(img_input)
output2 = layers.MaxPooling2D((2,2))(output1)
output3 = layers.Conv2D(kernel_size=(3,3), filters=64, activation='relu')(output2)
output4 = layers.MaxPooling2D((2,2))(output3)
output5 = layers.Conv2D(kernel_size=(3,3), filters=128, activation='relu')(output4)
output6 = layers.MaxPooling2D((2,2))(output5)
output7 = layers.Conv2D(kernel_size=(3,3), filters=128, activation='relu')(output4)
output8 = layers.MaxPooling2D((2,2))(output7)
output9 = layers.Flatten()(output8)
output10 = layers.Dropout(0.5)(output9)
output11 = layers.Dense(512, activation='relu')(output10)
predictions = layers.Dense(2, activation='softmax')(output11)
model = keras.Model(inputs=img_input, outputs=predictions)
model.summary()opt = SGD(lr=INIT_LR, momentum=0.9)
loss = CategoricalCrossentropy(label_smoothing=0.1)
model.compile(loss=loss, optimizer=opt, metrics=["accuracy"])train_step = math.ceil(train_generator.n/32)
valid_step = math.ceil(valid_generator.n/32)
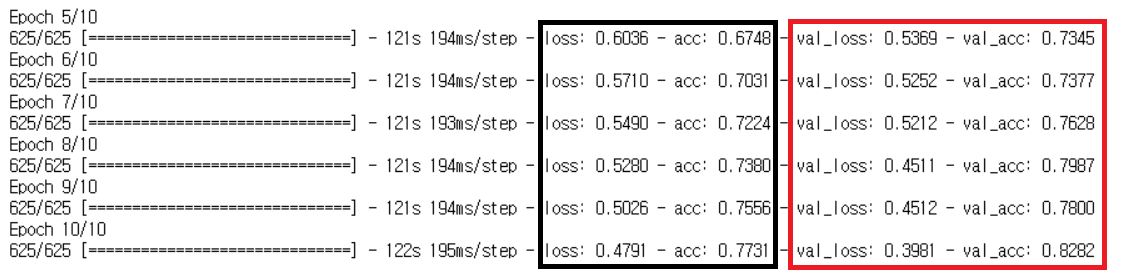
history = model.fit_generator(
train_generator,
steps_per_epoch=train_step,
epochs=30,
validation_data=validation_generator,
validation_steps=valid_step)acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
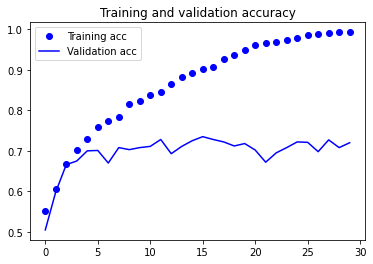
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
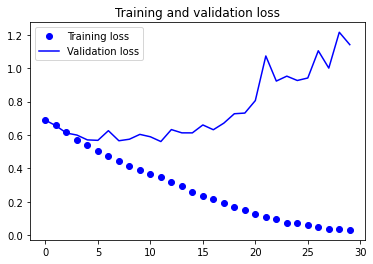
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()model.save('CNN_epoch_20.h5')
test_dir = os.path.join(base_dir, 'test')
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
test_step = math.ceil(test_generator.n/32)
test_loss, test_acc = model.evaluate_generator(test_generator, steps=test_step, workers=4)
print(f'test loss : {test_loss:.4f} / test acc : {test_acc*100:.2f} %')
2. Pre-trained model with transfer learning an fine tuning 구축 버전
import os
from tensorflow import keras
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import layers
from tensorflow import keras
from tensorflow.keras.applications import VGG16
import matplotlib.pyplot as plt
import math
base_dir = './datasets/COVID_19/'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
train_datagen = ImageDataGenerator(
featurewise_center=True,
featurewise_std_normalization=True,
rescale=1./255,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
validation_split=0.2)
validation_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 타깃 디렉터리
train_dir,
# 모든 이미지를 150 × 150 크기로 바꿉니다
target_size=(150, 150),
batch_size=32,
# categorical_crossentropy 손실을 사용
class_mode='categorical') #COVID_19는 3개의 클래스로 구성됨
validation_generator = validation_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='categorical')
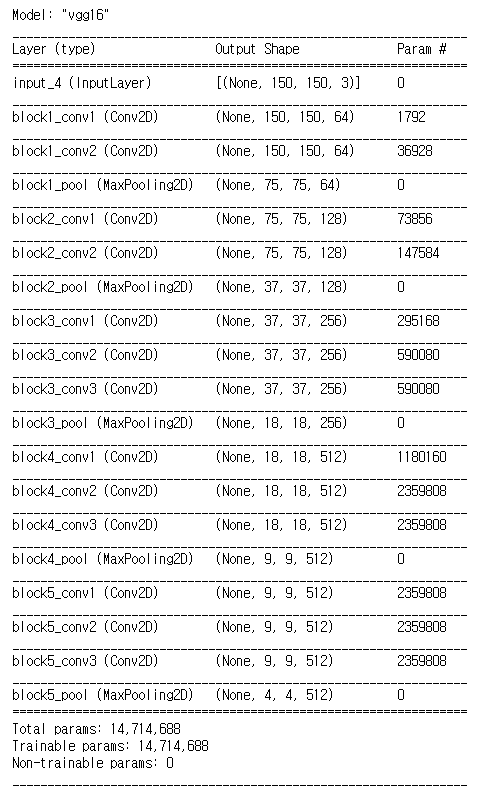
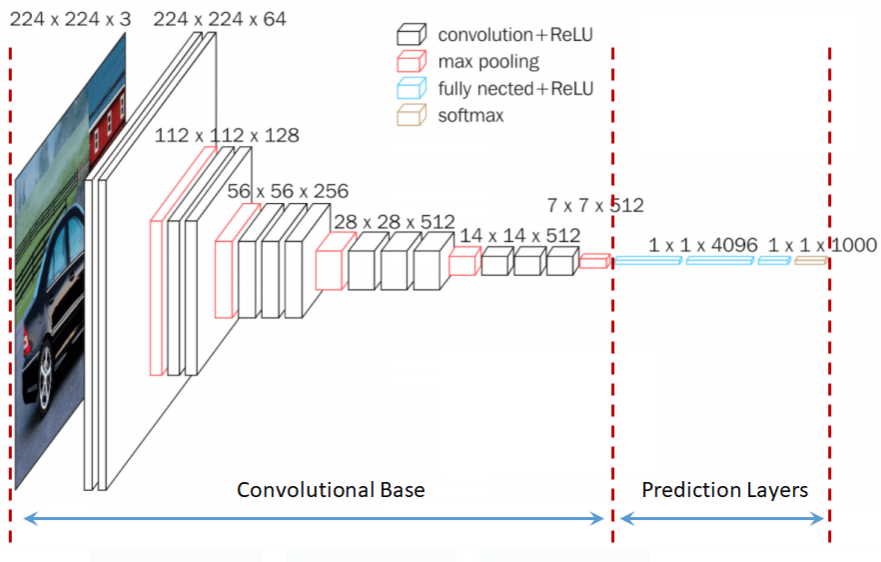
vgg_base = VGG16(weights='imagenet',
include_top=False,
input_shape=(150, 150, 3))vgg_base.summary()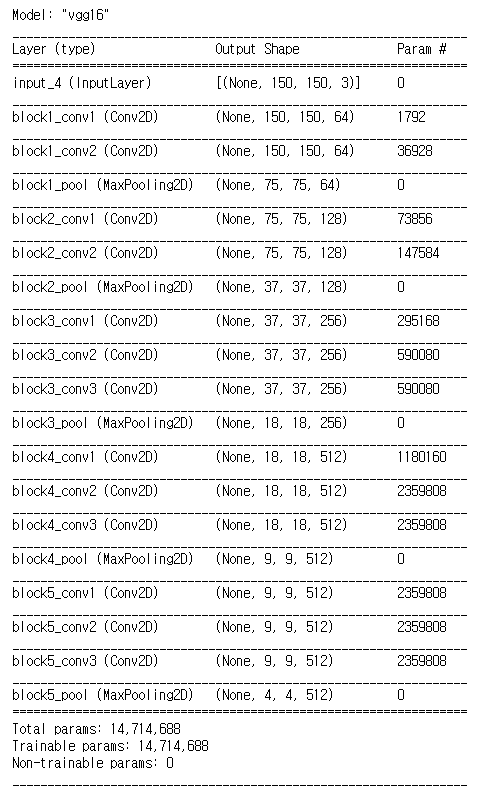
model = models.Sequential()
model.add(vgg_base)
model.add(layers.Flatten())
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(3, activation='softmax'))for layer in vgg_base.layers:
layer.trainable = False
for layer in vgg_base.layers[15:]:
layer.trainable = Trueopt = SGD(lr=INIT_LR, momentum=0.9)
loss = CategoricalCrossentropy(label_smoothing=0.1)
model.compile(loss=loss, optimizer=opt, metrics=["accuracy"])train_step = math.ceil(train_generator.n/32)
valid_step = math.ceil(valid_generator.n/32)
history = model.fit_generator(
train_generator,
steps_per_epoch=train_step,
epochs=30,
validation_data=validation_generator,
validation_steps=valid_step)acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()model.save('CNN_epoch_20.h5')
test_dir = os.path.join(base_dir, 'test')
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
test_step = math.ceil(test_generator.n/32)
test_loss, test_acc = model.evaluate_generator(test_generator, steps=test_step, workers=4)
print(f'test loss : {test_loss:.4f} / test acc : {test_acc*100:.2f} %')
'Tensorflow > 2.CNN' 카테고리의 다른 글
| 5.Pre-trained model 불러오기 (feat. Transfer Learning and .h5 파일) (0) | 2021.06.30 |
|---|---|
| 4. 평가지표(Metrics ) visualization (0) | 2021.06.29 |
| 3.CNN 모델의 loss function 및 optimizer 설정 (0) | 2021.06.29 |
| 2.CNN 모델 구현 (Feat. Sequential or Function API) (0) | 2021.06.29 |
| 1.Data Load 및 Preprocessing (전처리) (0) | 2021.06.28 |