현재 다른 페이지에 작성하고 있습니다.
6월 11일 안으로 작성이 완료되는대로 글을 옮겨적도록 하겠습니다.
'딥러닝 응용 > Semi-Supervised Learning' 카테고리의 다른 글
| 0. 딥러닝에서 unlabeled data를 활용하는게 필요한 이유 (0) | 2021.05.21 |
|---|
현재 다른 페이지에 작성하고 있습니다.
6월 11일 안으로 작성이 완료되는대로 글을 옮겨적도록 하겠습니다.
| 0. 딥러닝에서 unlabeled data를 활용하는게 필요한 이유 (0) | 2021.05.21 |
|---|
안녕하세요.
이번 글에서는 아래 논문을 리뷰해보도록 하겠습니다.(아직 2차 검토를 하지 않은 상태라 설명이 비약적이거나 문장이 어색할 수 있습니다.)
※덧 분여 제가 medical image에서 tranasfer learning을 적용했을 때 유효했던 방법론들도 공유하도록 하겠습니다.
"Bag of Tricks for Image Classification with Convolutional Neural Networks"
Conference: 2019 CVPR
Authors: Amazon Web Servies


"우리 논문에서는 training precedure refinements를 위한 방법론들을 모두 적용시켜 CNN 성능을 향상시켰어!"
→ CNN 모델 구조들의 간략한 history

(↓↓↓CNN 관련 내용 정리한 카테고리↓↓↓)
'Deep Learning for Computer Vision/Convolution Neural Network (CNN)' 카테고리의 글 목록
#Interest: World History (The past) #Work: Deep Learning (The future) #Hobby: Music, Sports
89douner.tistory.com
→ 모델링 위주의 CNN 연구도 중요하지만, CNN 학습 방법론들도 중요하다고 언급

→ "CNN 학습방법론들 적용 + 약간의 모델링 수정"을 통해 CNN 성능의 변화를 테스트

→ "CNN 학습방법론들 적용 + 약간의 모델링 수정"을 통해 CNN 성능의 변화를 테스트

(↓↓↓CNN과 object detection 관계가 궁금하시다면↓↓↓)
https://89douner.tistory.com/81?category=878735
3. Object Detection과 CNN의 관계
안녕하세요~ 이번글에서는 Object Detection과 CNN의 관계에 대해서 알아보도록 할거에요. CNN분야가 발전하면서 classification 영역에 엄청난 영향을 미친것처럼 동시에 Object detection 영역에도 굉장한 영
89douner.tistory.com
→ 이 논문에서 앞으로 어떤 순서로 내용을 전개할지 언급

https://github.com/dmlc/gluon-cv
dmlc/gluon-cv
Gluon CV Toolkit. Contribute to dmlc/gluon-cv development by creating an account on GitHub.
github.com
→ 여러 학습 방법론을 적용시키기 위한 baseline 모델이 있어야 한다. 여기서는 이러한 baseline 모델을 어떻게 training시키고, validation 했는지 설명한다.



(↓↓↓ Mini-Batch 관련 설명 ↓↓↓)
https://89douner.tistory.com/43?category=868069
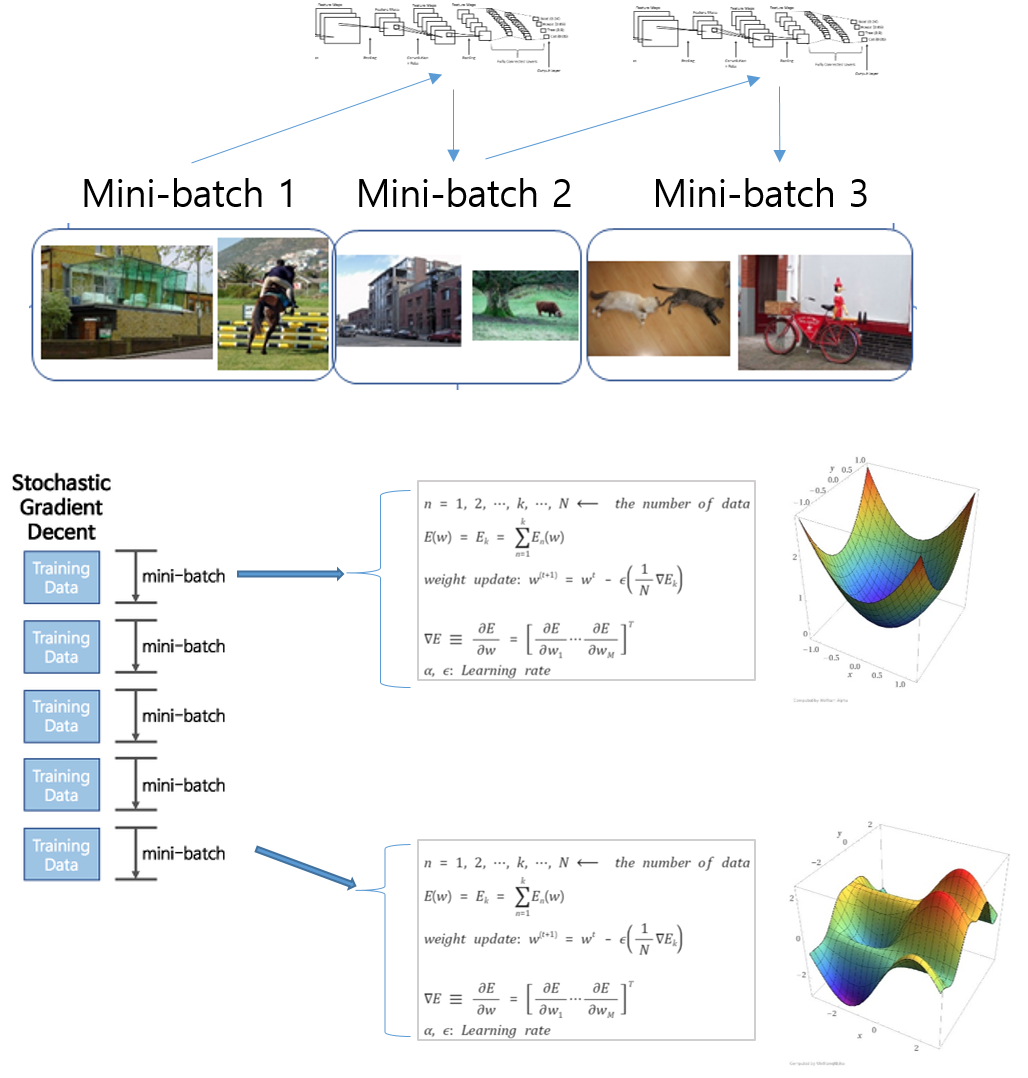
9. Mini-Batch (데이터가 많은 경우에는 학습을 어떻게 시키나요?)
Q. 굉장히 많은 데이터를 학습시키려고 한다면 어떻게 학습시켜야 하나요? 데이터 하나하나 단계적으로 학습시켜야 하나요? 안녕하세요~ 이번시간에도 DNN(Deep Neural Network) 모델을 좀 더 효율적
89douner.tistory.com




(↓↓↓PCA augmentation에 대한 설명은 아래 글을 참고하세요!↓↓↓)
https://89douner.tistory.com/60?category=873854
6. AlexNet
안녕하세요~ 이제부터는 CNN이 발전해왔던 과정을 여러 모델을 통해 알려드릴까해요. 그래서 이번장에서는 그 첫 번째 모델이라 할 수 있는 AlexNet에 대해서 소개시켜드릴려고 합니다! AlexNet의 논
89douner.tistory.com
https://github.com/koshian2/PCAColorAugmentation
koshian2/PCAColorAugmentation
PCA Color Augmentation in TensorFlow/Keras. Contribute to koshian2/PCAColorAugmentation development by creating an account on GitHub.
github.com

Step6: 이 부분은 normalization 전처리 기법인데, 해당 기법에 대한 자세한 설명은 아래 글을 참고해주세요!
https://89douner.tistory.com/42?category=868069
8. 데이터 전처리 (Data Preprocessing and Normalization)
Q. DNN을 학습시키기 전에 왜 데이터를 전처리해주어야 하나요? 안녕하세요~ 이번시간에는 DNN 모델이 학습을 효율적으로 하기위해 필요한 정규(Noramlization; 정규화) 대해서 알아보도록 할거에요~
89douner.tistory.com
※ 여기서는 실제 논문에서 기재된 문단 순서를 조금 변경했습니다 (개인적으로 training 관련 내용들을 다 적어주고, validation을 언급해주는게 좋다고 봐서....)

(↓↓↓Volta가 궁금하시다면↓↓↓)
https://89douner.tistory.com/159?category=913897
4.NVIDIA GPU 아키텍처(feat.FLOPS)
안녕하세요~ 이번글에서는 NVIDIA에서 출시했던 GPU 아키텍처들에 대해 알아볼거에요. 가장 먼저 출시됐던 Tesla 아키텍처를 살펴보면서 기본적인 NVIDIA GPU 구조에 대해서 알아보고, 해당 GPU의 스펙
89douner.tistory.com


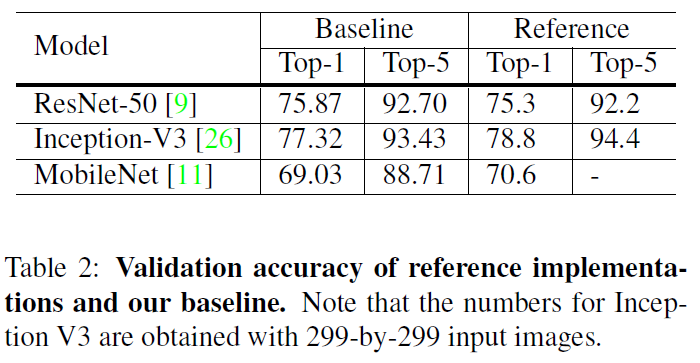
→ Accuracy 성능을 떨어뜨리지 않으면서 빠르고 효과적으로 training 시키는 방법을 소개


[장점] Large Batch size → Increase parallelism and decrease communication costs

(↓↓↓GPU 내부동작 살펴보기↓↓↓)
https://89douner.tistory.com/157?category=913897
2.내장그래픽과 외장그래픽 그리고 GPU 병목현상(feat. Multi-GPU)
안녕하세요~ 이번글에서는 내장그래픽과 외장그래픽에 대해서 알아보면서 그래픽카드의 내부구조 동작 방식에 대해 간단히 알아보도록 할거에요. 그리고 딥러닝을 돌리시다보면 CUDA memory alloca
89douner.tistory.com
[단점] Large batch size → Slow down training progress + convergence rate decrease + degraded validation accuracy
(↓↓↓현재까지 정리되어 있는 convex optimization 내용들 ↓↓↓)
'딥러닝수학/Convex Optimization' 카테고리의 글 목록
#Interest: World History (The past) #Work: Deep Learning (The future) #Hobby: Music, Sports
89douner.tistory.com
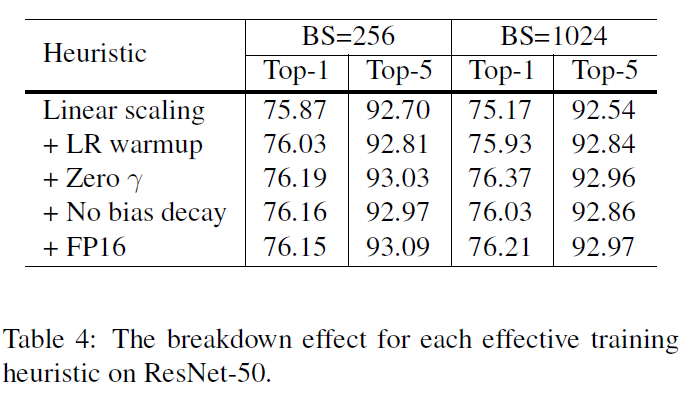
[Four heuristic methods]
→ batch size를 키워줄 때, learning rate을 어떻게 변화시켜주면 좋을지 설명하는 내용






(↓↓↓Warm-up 관련 github code↓↓↓)
https://github.com/ildoonet/pytorch-gradual-warmup-lr
ildoonet/pytorch-gradual-warmup-lr
Gradually-Warmup Learning Rate Scheduler for PyTorch - ildoonet/pytorch-gradual-warmup-lr
github.com
→ Residual block에 위치한 Batch Normalization layer의 zero gamma 값을 0으로 초기화 시켜주면 초기학습 단계에서 더 적은 layer로 효과적으롤 학습할 수 있음 → Speed도 증가시키면서, accuracy 성능도 악화시키지 않음


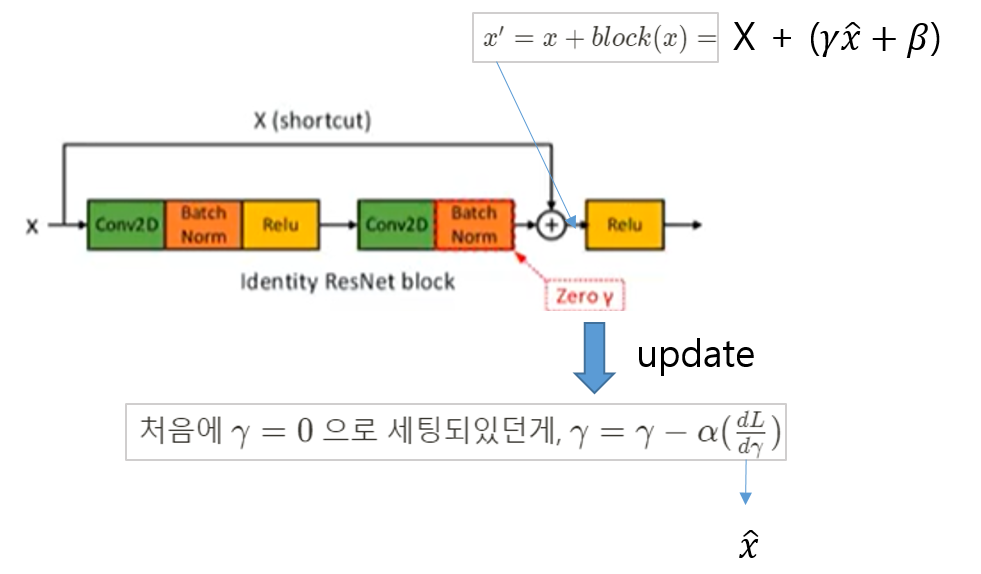
→ bias, bath normalization's gamma and beta 에는 regularization을 적용하지 않는 것이 좋다

Why is the bias term not regularized in ridge regression?
In most of classifications (e.g. logistic / linear regression) the bias term is ignored while regularizing. Will we get better classification if we don't regularize the bias term?
stackoverflow.com

(↓↓↓FP에 대한 개념과 Volta 아키텍처에서의 Mixed precision 설명 ↓↓↓)
https://89douner.tistory.com/159?category=913897
4.NVIDIA GPU 아키텍처(feat.FLOPS)
안녕하세요~ 이번글에서는 NVIDIA에서 출시했던 GPU 아키텍처들에 대해 알아볼거에요. 가장 먼저 출시됐던 Tesla 아키텍처를 살펴보면서 기본적인 NVIDIA GPU 구조에 대해서 알아보고, 해당 GPU의 스펙
89douner.tistory.com

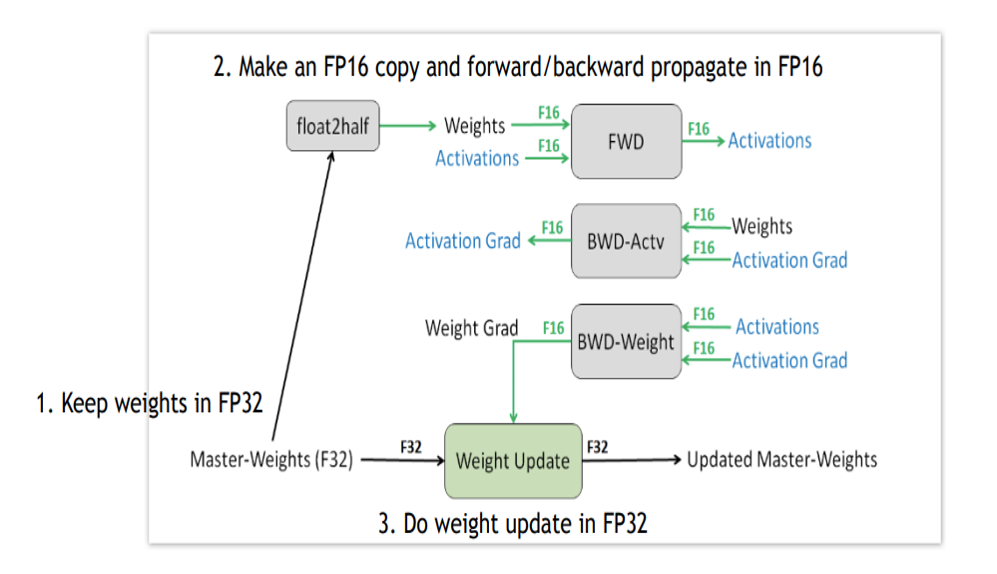
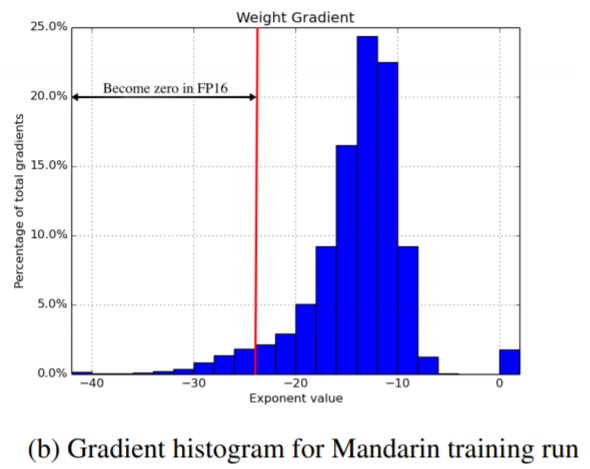


(↓↓↓loss sacling 참고할만한 사이트↓↓↓)
https://hoya012.github.io/blog/Mixed-Precision-Training/
Mixed-Precision Training of Deep Neural Networks
NVIDIA Developer Blog 글을 바탕으로 Deep Neural Network를 Mixed-Precision으로 학습시키는 과정을 글로 작성하였습니다.
hoya012.github.io
(↓↓↓Mixed precision and loss scaling 참고할만한 사이트↓↓↓)

CNN 꿀팁 모음 (Bag of Tricks for Image Classification with Convolutional Neural Networks) 논문 리뷰
논문 제목 : Bag of Tricks for Image Classification with Convolutional Neural Networks 오늘은 Bag of Tricks for Image Classification with Convolutional Neural Networks에 대해 리뷰를 해볼까..
phil-baek.tistory.com
https://cv.gluon.ai/model_zoo/classification.html#id239
Classification — gluoncv 0.11.0 documentation
cv.gluon.ai

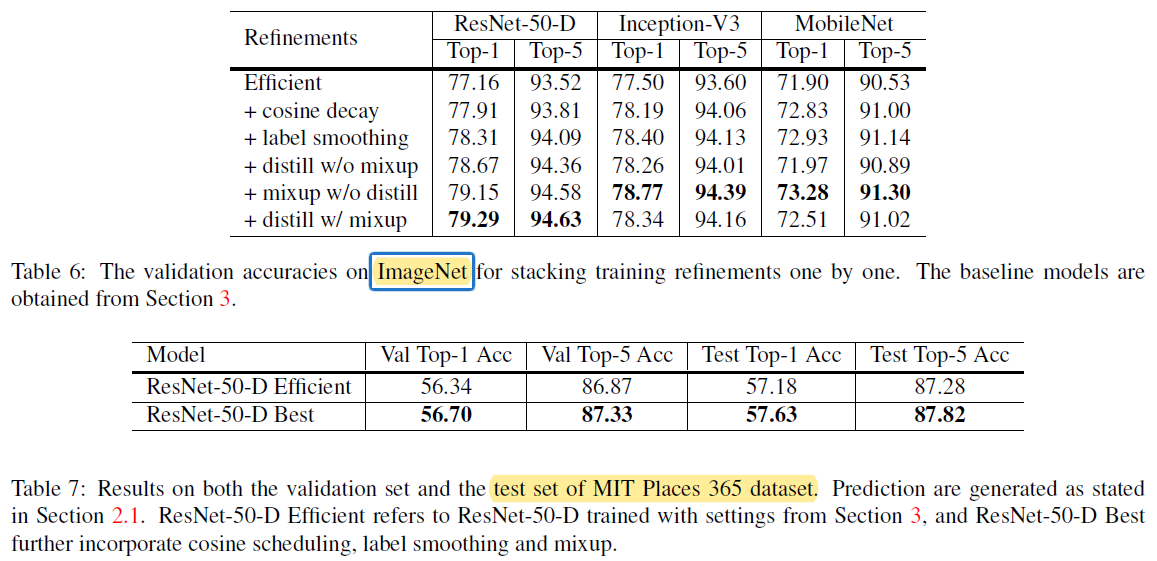
5-1. Cosine Learning Rate Decay


(↓↓↓ Cosine learning rate 관련 github코드↓↓↓)
https://github.com/katsura-jp/pytorch-cosine-annealing-with-warmup
katsura-jp/pytorch-cosine-annealing-with-warmup
Contribute to katsura-jp/pytorch-cosine-annealing-with-warmup development by creating an account on GitHub.
github.com
(↓↓↓ Cosine learning rate 관련 pytorch코드↓↓↓)
https://pytorch.org/docs/stable/optim.html
torch.optim — PyTorch 1.8.1 documentation
torch.optim torch.optim is a package implementing various optimization algorithms. Most commonly used methods are already supported, and the interface is general enough, so that more sophisticated ones can be also easily integrated in the future. How to us
pytorch.org

https://89douner.tistory.com/category/Network%20Compression%20for%20AI/Knowledge%20Distillation
'Network Compression for AI/Knowledge Distillation' 카테고리의 글 목록
#Interest: World History (The past) #Work: Deep Learning (The future) #Hobby: Music, Sports
89douner.tistory.com
(↓↓↓MixMatch 논문에서 Mix-up 개념 설명↓↓↓)
https://89douner.tistory.com/249
1.MixMatch; A Holistic Approach to Semi-Supervised Learning
현재 다른 페이지에 작성하고 있습니다. 6월 11일 안으로 작성이 완료되는대로 글을 옮겨적도록 하겠습니다.
89douner.tistory.com
[개인적인 경험 글]
(↓↓↓Bag of Tricks for Image Classification with ~ 관련 Tensorflow 2 코드↓↓↓)
Bag of Tricks for Image Classification with Convolutional Neural Networks in Keras | DLology
Posted by: Chengwei 2 years, 6 months ago (Comments) This tutorial shows you how to implement some tricks for image classification task in Keras API as illustrated in paper https://arxiv.org/abs/1812.01187v2. Those tricks work on various CNN models like
www.dlology.com
지금까지 읽어주셔서 감사합니다!
| 1. ImageNet-Trained CNNs are Biased Towards Texture; Increasing Shape Bias Improves Accuracy And Robustness (2) | 2021.06.05 |
|---|---|
| 이 글을 쓰는 이유 (0) | 2021.06.04 |
안녕하세요.
이번 글에서는 아래 논문을 리뷰해보려고 합니다. (아직 2차 검토를 하지 않은 상태라 설명이 비약적이거나 문장이 어색할 수 있습니다.)
※ 덧붙여 제가 medical imaging에 적용한 다른 전처리(or data augmentation) 방식들을 같이 공유하도록 하겠습니다.
ImageNet-Trained CNNs are Biased Towards Texture; Increasing Shape Bias Improves Accuracy And Robustness
Conference: 2019 ICLR
Authors: 영국의 Edinburgh 대학, IMPRS-IS (International Max Planck Research School for Intelligent Systems), 독일의 Tubingen 대학 간의 협동연구


[요약]
1. Question (노란색 부분)

2. 실험방법 (파란색 부분)
3. Result (분홍색 부분)

(↓↓↓이해가 어려우신 분들은 아래 글을 참고해주세요↓↓↓)
https://89douner.tistory.com/57?category=873854
3. CNN(Convolution Neural Network)는 어떤 구조인가요?
안녕하세요~ 이번글에서는 Convolution Neural Network(CNN)의 기본구조에 대해서 알아보도록 할거에요. CNN은 기본적으로 Convolution layer-Pooling layer-FC layer 순서로 진행이 되기 때문에 이에 대해서 차..
89douner.tistory.com
"기존의 연구들은 CNN이 shape을 기반해서 classification을 하고 있었다"





"기존에 주장한 것(두 번째 문단: shape기반의 CNN 분류)과 달리, CNN은 texture 기반으로 classification 한다. 그리고 이것을 texture hypothesis라 하겠다"

"실험을 통해 shape bias하게 CNN을 training 시킬 수 있었으며, shape bias가 가미된 CNN 모델은 classification, object recognition 성능에 긍정적인 영향을 미쳤다"
→ Method에서 앞서 언급한 실험들에 대해 ouline을 잡아 줄 예정 + Extensive details들은 Appendix를 참고 할 것 + 데이터, 코드들은 아래 github 사이트 참고

https://github.com/rgeirhos/texture-vs-shape
rgeirhos/texture-vs-shape
Pre-trained models, data, code & materials from the paper "ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness" (ICLR 2019 Oral) -...
github.com

→ 이 실험이 6개의 실험으로 구성되어 있는데, 각각의 실험들은 개별적인 dataset을 기반으로 진행







https://www.kaggle.com/c/painter-by-numbers
Painter by Numbers
Does every painter leave a fingerprint?
www.kaggle.com
https://github.com/rgeirhos/Stylized-ImageNet
rgeirhos/Stylized-ImageNet
Code to create Stylized-ImageNet, a stylized version of standard ImageNet (ICLR 2019 Oral) - rgeirhos/Stylized-ImageNet
github.com

https://github.com/rgeirhos/texture-vs-shape
rgeirhos/texture-vs-shape
Pre-trained models, data, code & materials from the paper "ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness" (ICLR 2019 Oral) -...
github.com
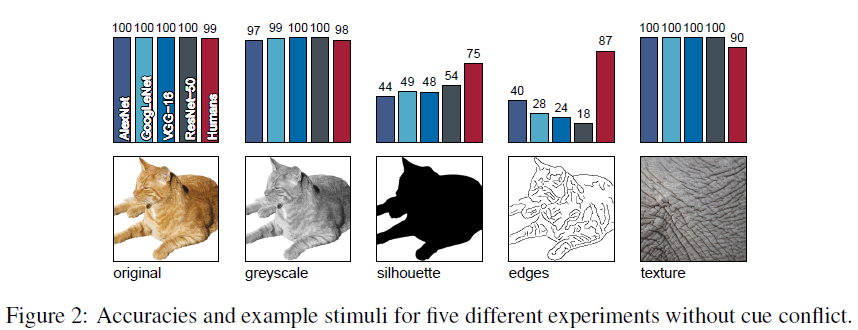
→ Figure2의 결과: Original, Greyscale, Silhouette, Edge 이미지 분류 결과 (CNN VS 사람)

→ Figure4의 결과: Texture, Cue conflict 이미지 분류 결과 (CNN VS 사람)


""3-1" 실험 결과를 통해 CNN은 texture bias 하다고 할 수 있습니다"

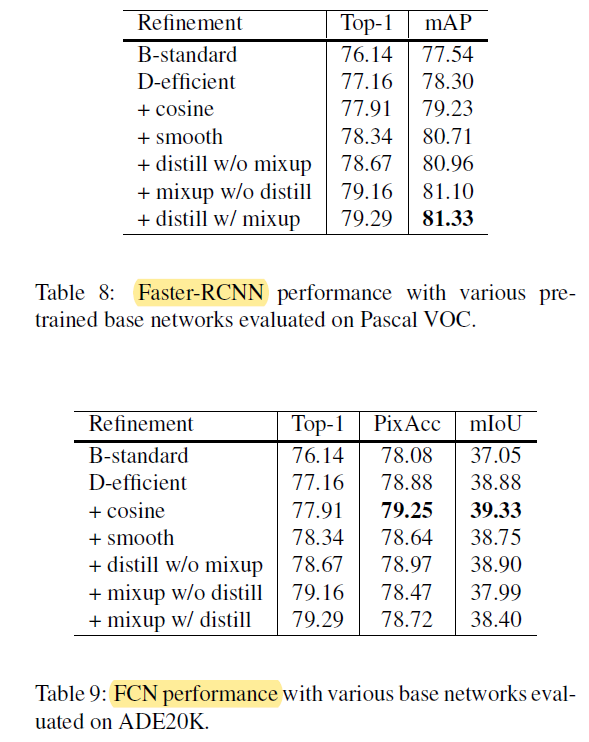
→ Table 1에서 첫 번째 행에 해당하는 결과들 설명


→ Table 1에서 2,3,4 번째 행에 해당하는 결과들 설명


→ Figure 5 설명하는 문단

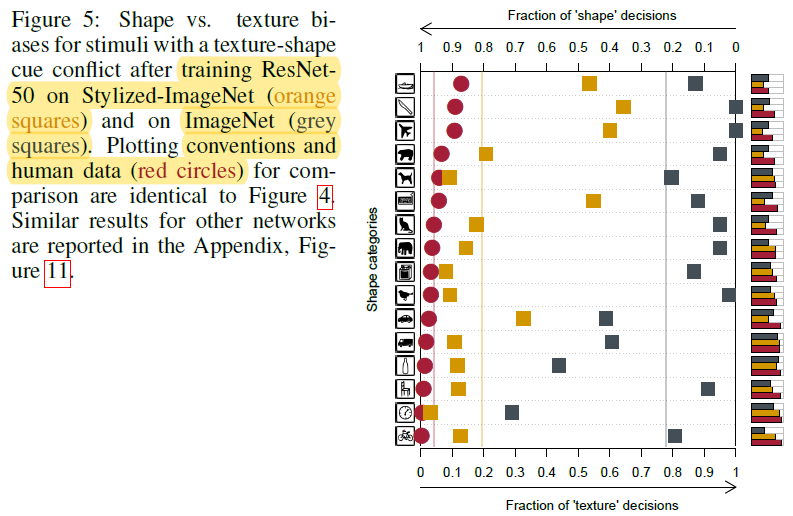






"Shape-based Representation can be beneficial for recognition tasks."
"Shape-based CNN is the better backbone for Object detection"
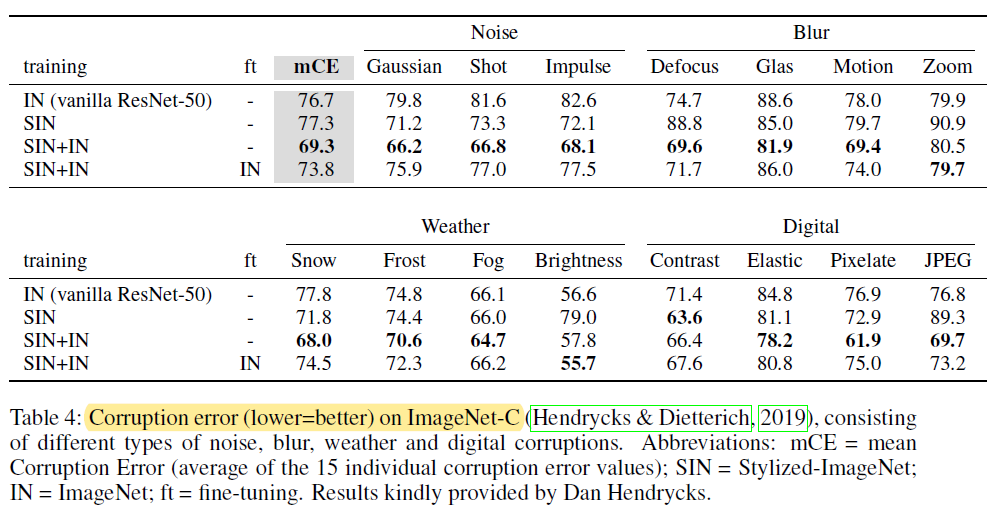
"Shape-based training is robust to distortion(noises)"
아무래도 의료 이미지를 CNN에 적용시킨적이 많아서 아래와 같은 경험 및 생각을 하게 됐습니다.
이상으로 논문리뷰를 마치겠습니다!
아래 영상은 style-transfer 공부하다가 만든 영상입니다.
무성영화에 Fast style transfer를 적용시킨 후, 노래영상을 입혔습니다.
즐겁게 봐주세요^^~
(Stylized soundless video +"12:45" song)
원본영상
https://www.youtube.com/watch?v=PoAJ1KoBcEk
원본노래
https://www.youtube.com/watch?v=OyTIMOlY1ag
| 2. Bag of Tricks for Image Classification with Convolutional Neural Networks (0) | 2021.06.06 |
|---|---|
| 이 글을 쓰는 이유 (0) | 2021.06.04 |
안녕하세요.
이번 글에서는 왜 CNN 학습 방법론에 대해 관심을 갖게 됐는지에 대해 설명해보도록 하겠습니다.
CNN을 연구한다고 했을 때, 대부분 CNN 구조를 모델링하는 것을 연상할 것입니다.
(↓↓↓CNN 아키텍처들↓↓↓)
https://89douner.tistory.com/category/Deep%20Learning%20for%20Computer%20Vision
'Deep Learning for Computer Vision' 카테고리의 글 목록
#Interest: World History (The past) #Work: Deep Learning (The future) #Hobby: Music, Sports
89douner.tistory.com
모델링을 한다는 것은 정말 멋지고 대단한 일이지만, 지나친 CNN 모델링 연구 또한 문제가 될거라고 생각합니다.
CNN을 모델링 하는 것은 오랜 시간을 요구합니다.
즉, 다양한 모델들을 섭렵하기도 해야하고, 자신만의 창의적인 방법을 적용시키면서 독특한 모델을 만들어야 하기 때문이죠.
이러한 독창적인 CNN 모델을 만들었다고 끝이 아닙니다. 왜냐하면 방대한 ImageNet을 통해 해당 CNN 모델을 학습시키는 것도 오랜 시간이 걸리기 때문이죠.

추가적으로, 최적의 Hyper-parameter를 찾는 것도 고려해야 한다면, 모델링 연구는 개인이 하기에 시간/비용적으로 너무 부담이 되는 것도 사실입니다.
아카데믹(학계)에서는 이러한 연구를 할 수 있는 시간이 충분히 주어지겠지만, 산업현장 같은 곳에서는 빠르게 비지니스 모델을 출시해야 하므로 무작정 모델링 연구를 기다려 주는 것도 어렵습니다.
2012년 AlexNet의 등장이후 이미지 classifiction, segmentation, detection과 같은 분야에서 대부분 CNN 기반 모델들이 적용되어 왔습니다.
학습 방법론에 대해 관심을 갖게 된것은 2019년부터인데, 그 이유는 ResNet이후 다양하게 나온 CNN 모델들을 사용해도 별반 차이가 나지 않았기 때문입니다. 해당 논문들에서는 ResNet 보다 훨씬 뛰어난 performance를 보여줬으나 실제로 transfer learning을 통해 다른 domain에 적용해봤을 때는 생각만큼 뛰어나 보이지 않았기 때문입니다 (물론 좋은 성능을 보인 모델도 있었으나 평균적으로 ResNet 모델과 차이가 나지 않은 경우가 많았습니다)
하지만 2020년 Transformer의 등장과, 2021년 MLP로만 구성된 모델이 기존 CNN 기반의 모델들의 성능을 뛰어넘는 모습을 보면서 학습 방법론에 관심갖길 잘했다는 생각을 했습니다.
또한, AutoML과 같은 기술이 도입되면서 우리가 적용시키려는 domain에 맞는 모델을 자동적으로 만들어주려는 연구가 진행되는 것을 보면서, 아래와 같은 생각을 했습니다.
"CNN 모델을 이해하는 것은 필수적이지만, 모델링을 연구하는건 연구자로써 수명이 그리 길지 않을 수도 있겠구나"
"차라리 모델에 치우친 연구를 하기보다는 여러 모델에 적용시켜볼 수 있는 학습 방법론에 대해서 연구하는것이 더 실용적이겠다"
위와 같은 문제를 않고 여러 딥러닝 학회 논문을 살펴봤습니다.
정말 다양한 학습방법론을 다룬 내용들이 많았습니다.
대충 내용을 정리하면 아래와 같습니다.
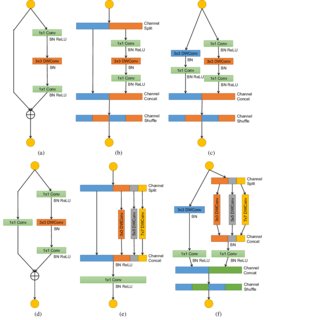
(b) Partial fine-tuning of pre-trained CNN. (c) Complete fine-tuning of pre-trained CNN

사실 위에서 CNN이라고 적시했지만 해당 방법론들은 MLP, Transformer 같은 모델에서도 충분히 적용 가능한 insight를 줄거라고 생각합니다.
과거 딥러닝 모델을 개발하는 것에만 몰두했다면, 최근에는 여러 기술들을 접목해 딥러닝 모델을 효과적으로 학습시키려는 노력을 더 많이 하는듯 보입니다. (물론 딥러닝 모델 개발을 게을리 해서도 안되겠죠)
그럼 다음 글에서부터는 다양한 학습 방법론들을 소개시켜 드리도록 하겠습니다.
안녕하세요.
이번 글에서는 semi-supervised learning에 대한 간략한 개념과 왜 이러한 기술이 필요한지 설명해보도록 하겠습니다.


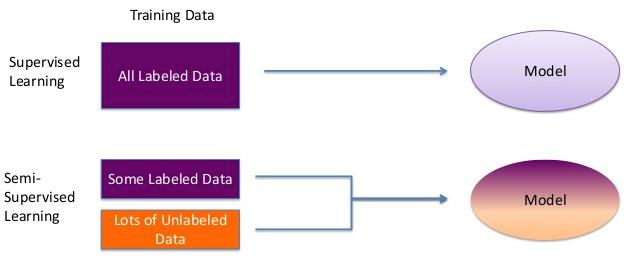
https://sites.google.com/view/berkeley-cs294-158-sp20/home
CS294-158-SP20 Deep Unsupervised Learning Spring 2020
About: This course will cover two areas of deep learning in which labeled data is not required: Deep Generative Models and Self-supervised Learning. Recent advances in generative models have made it possible to realistically model high-dimensional raw data
sites.google.com

| 1.MixMatch; A Holistic Approach to Semi-Supervised Learning (0) | 2021.06.08 |
|---|
안녕하세요.
이번 글에서는 Adversarial Attack이 무엇인지 간단히 설명하고 왜 이러한 분야들을 알고 있어야 하는지 설명해보겠습니다.


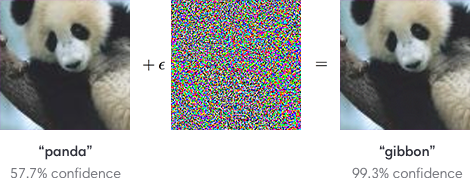
아래 논문을 바탕으로 딥러닝 모델이 adversarial attack에 얼마나 취약한지 살펴 보도록 하겠습니다.
https://arxiv.org/abs/1804.05296
Adversarial Attacks Against Medical Deep Learning Systems
The discovery of adversarial examples has raised concerns about the practical deployment of deep learning systems. In this paper, we demonstrate that adversarial examples are capable of manipulating deep learning systems across three clinical domains. For
arxiv.org


의료산업에서 딥러닝 모델을 사용한다고 했을 때, adversarial attack은 산업전반에 치명적인 타격을 줄 수 있습니다. 아래 두 논문을 기반으로 발생할 수 있는 문제들에 대해서 알아보도록 하겠습니다.
https://arxiv.org/abs/1804.05296
Adversarial Attacks Against Medical Deep Learning Systems
The discovery of adversarial examples has raised concerns about the practical deployment of deep learning systems. In this paper, we demonstrate that adversarial examples are capable of manipulating deep learning systems across three clinical domains. For
arxiv.org
https://ir.ymlib.yonsei.ac.kr/handle/22282913/173346
YUHSpace: 딥러닝 기반 의료 영상 인공지능 모델의 취약성: 적대적 공격
딥러닝 기반 의료 영상 인공지능 모델의 취약성: 적대적 공격
ir.ymlib.yonsei.ac.kr
https://89douner.tistory.com/195
1. 미국의 Healthcare환경 및 의료시스템
안녕하세요. 이번 글에서는 미국의 healthcare환경 및 의료 시스템에 대해서 알아보도록 하겠습니다. 사실, 각 나라마다 의료환경이 다릅니다. 예를 들어, 유럽의 의료환경, 한국의 의료환경, 미국
89douner.tistory.com
(↓↓↓적대적 환자 개념 제시 논문↓↓↓)
https://link.springer.com/chapter/10.1007/978-3-030-10925-7_3
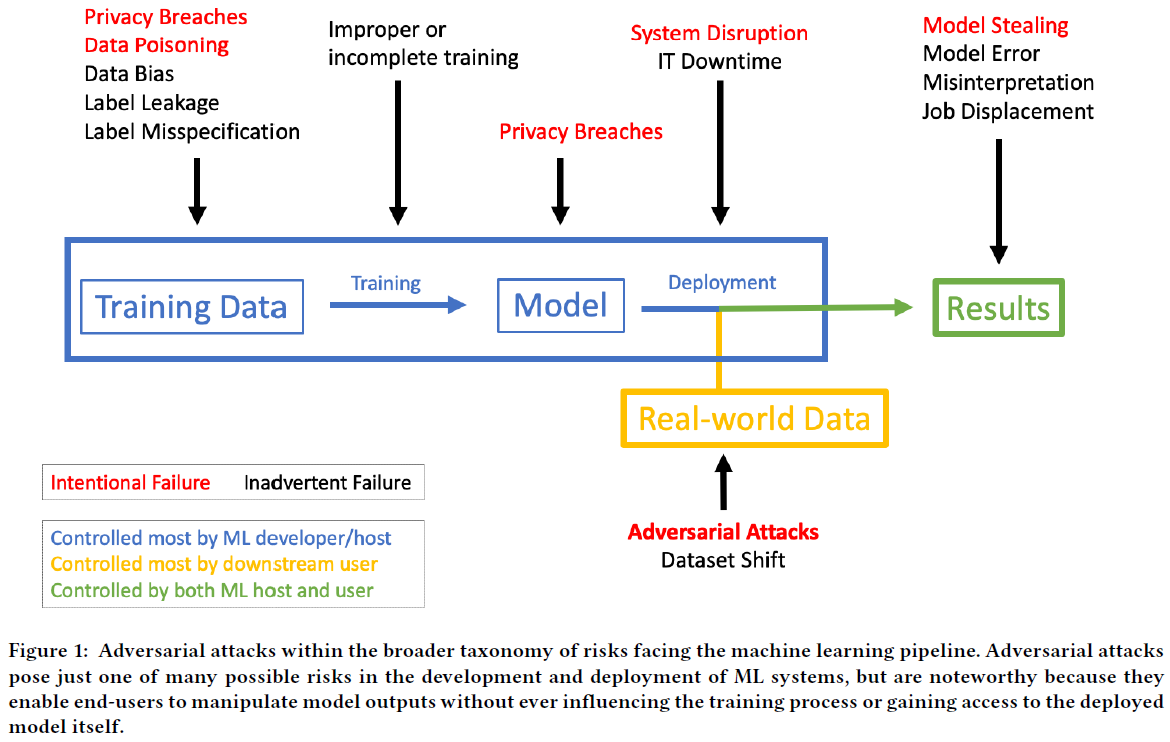
앞서 언급한 adversarial attack은 딥러닝 모델을 상용화 시키는데 큰 걸림돌이 될 수 있습니다. 그러므로, adversarial attack에 robust한 딥러닝 모델을 만들기 위한 노력도 수반되어야 합니다.
앞으로, 해당 카테고리에서는 adversarial attack과 관련된 연구들이 뭐가 있는지 알아볼 예정입니다.
읽어주셔서 감사합니다.
안녕하세요~
이번엔 딥러닝 응용이라는 chapter를 개설하게 되었어요~
딥러닝에 대한 기본 지식을 넘어서 실제 현실에 맞게 이용하거나 좀 더 효율적으로 학습시키기 위한 방법론들에 대한 개념들을 다루어보려고해요.
저는 최근에 Edge device 같은 곳에 딥러닝 모델을 올려보기 위해 딥러닝 모델을 compression하는데 관심을 갖게 되었는데, 이를 위해 사용될 수 있는 응용개념들을 다루어 보려고 합니다!