대학원 박사과정을 시작하기 전까지는 블로그 글을 많이 올렸던 것 같은데, 박사과정이 시작되고는 글 올리는게 쉽지 않네요 ㅜ
요즘에는 블로그 보다는 Notion을 이용하여 글을 작성하고 있는데, 많은 분들께 공유가 안된다는 점이 조금 아쉽네요ㅜ . .
그래서, 이번 글에서는 간단하게 한 해 동안 무엇을 했는지 정리하고, 남은 기간에 무엇을 할지에 대해서 말씀드리려고합니다! (물론 궁금하진 않으시겠지만..ㅎㅎ)
[2022년 경험한 것들]
1. MRI, CT 데이터 공부!
올해는 MRI, CT 관련 딥러닝 연구를 진행했습니다!
처음 다루는 데이터다 보니 데이터의 배경지식 및 여러 전처리 방식들을 정리할 수 있어서 좋았어요ㅎ
예를 들면, 딥러닝 학습을 위해 (brain) MRI nifti 파일을 어떻게 전처리 하면 좋은지, CT DICOM 파일에서 특정 병변을 더 잘 보이게 하기 위해 어떤 작업이 선행돼야하는지, 2D DICOM 데이터를 3D nifti 데이터로 변환시킬 때 어떤 부분을 주의해야하는지 등을 정리할 수 있었습니다!
의료 영상 이미지는 일반 이미지와는 달리 여러 특성들이 meta 정보로 주어지기 때문에 이를 이용해 적절한 전처리 작업을 거쳐야 해요. 그래야, 딥러닝이 학습하기 좋은 데이터셋이 됩니다!
이렇게 잘 정리한 자료를 토대로 내년 부터는 본격적인 의료 딥러닝 리서치 및 연구를 진행할 예정이에요!! (물론, 전처리 관련 자료는 지속적으로 피드백 받으면서 업데이트 해나갈 예정입니다 ㅎ)
2. 대회는 또 달라!
올해부터는 처음으로 의료 인공지능 대회를 참가하기 시작했어요.
대회를 참가하면서 좋았던 것은 실제 의료 현장에서 시급하게 다루어지는 문제들을 쉽게 접해 볼 수 있었어요.
또한, 검증받은 public dataset으로 MRI, CT, 3D, 2D, segmentation, object detection, classification 과 같이 다양한 딥러닝 task를 빠른 시간내에 배우고 습득할 수 있었다는 점입니다.
제 경우에는 대회 참가 시 팀을 구성하는데, 이번에 팀 단위의 작업을 하면서 어떠한 협업 시스템이 마련되면 좋은지를 느낄 수 있었습니다.
그래서, 관련 협업 개발도구를 사용할 수 있어서 개발능력도 향상 됐던것 같아요ㅎ
팀 단위의 협업 시스템을 통해 짧은 시간안에 다양한 실험을 할 수 있었고, 운 좋게도 MICCAI라는 국제 학회의 ISLES라는 challenge에서 2등을 수상할 수 있었습니다!!
해외학회에 참석하여 대회에 참석했던 많은 경쟁자들과 서로의 방법에 대해 논의 할 수 있었고, 새로운 동기부여들도 얻을 수 있어 좋았습니다. (해당 대회는 따로 글을 작성하도록 하겠습니다 ^^)
3. 자료화와 협업은 필수!
대학원에서 성과를 내지 못하고 있을 때, "연구 능력이 없는것 같다", "이런 기초지식도 없으면서 뭘 하겠다는건지" 와 같은 생각을 하면 굉장히 힘들거에요 ㅜ
하지만, 자신이 처한 문제를 오로지 개인의 탓으로 돌리는건 효과적인 문제 해결방식은 아닌것 같습니다.
현재 겪고 있는 문제가 개인의 문제가 아닌 시스템의 문제일 수 도 있기 때문이죠.
물론 개인의 노력이 문제를 해결하는 근본적인 방법이겠지만, 좋은 시스템이 갖춰져 있다면 문제 해결은 좀 더 빨라질거라 생각합니다!
제가 축구를 좋아해서 가끔씩 생각 했던 부분이기도 한데, 예전에만해도 잘 나가는 팀의 기준은 얼마나 좋은 스타플레이어들을 보유하고 있느냐였던 것 같아요.
하지만, 현대 축구로 넘어오면서 얼마나 좋은 감독을 보유하고 있는지가 중요해지기 시작했는데, 그 이유는 그 감독이 팀에 좋은 시스템을 심어 놓기 때문이라고 생각해요.
저는 제가 연구하는 곳이 개인에 의존하기 보다는, 누가 들어와도 잘 성장할 수 있는 좋은 시스템을 보유한 곳이었으면 좋겠어요.
그래서, 올해 저 또한 좋은 시스템을 구축하기 위해서 모두가 이해할 수 있는 자료를 만들고 협업을 위한 다양한 시도를 한 것 같습니다!
내년에는 좀 더 갖춰진 시스템으로 연구성과에 속도를 가해볼까해요ㅎ
[11월, 12월 계획]
이제 올해도 2달 정도가 남은 것 같습니다.
11월, 12월 계획은 지금까지 진행했던 의료 영상 관련 자료를 업데이트 하며, 의료 영상 전처리를 위한 모듈을 정리하려고 해요.
앞서 언급했던대로 내부 github을 만들어 의료 영상 처리의 기본 전처리 모듈을 만들 예정입니다.
또한 대회에 참가했던 methodology를 논문화시키려고 하고 있습니다!
추가적으로 이 분야를 모르지만 관심있는 분들을 초대해 정리한 내용들의 퀄리티 체크를 진행할 예정이에요. 이해가 잘 안되는 부분들은 보완하여 교육자료의 질을 향상시킬 예정입니다.
[개인적인 홍보]
내년에도 역시 연구와 병행하면서 큰 국제 대회를 2개정도 나가려고 합니다!
그 대회를 수행하려면 어느정도 의료 인공지능 연구 경험이 있어야 해요ㅜ
저는 지금까지 팀원 구성을 특정 소속인원들만으로 구성해본적이 없습니다.
그래서 지금도 서울, 포항, 울산 등에서 대학원 및 스타트업 소속인원들과 작업을 하고 있습니다ㅎ (물론 의료 도메인을 전혀 모르시는 분들도 많으셨구요!)
내년 대회 또는 앞으로 의료 인공지능 연구 또한 다양한 인원들과 스터디하여 진행하려고 합니다!
그래서 의료 인공지능을 위한 스터디원(팀원)을 모집하려고 해요!
개인적으로는 협업할 수 있는 자세를 갖고, 지속적으로 시간을 투자해 같이 공부할 수 있는 분들이 지원해주셨으면 좋겠어요ㅜ
사실 고등학생이나 대학교 학부생 분들이 지원하셔도 크게 상관없습니다. 제가 팀을 구성하려는 기준은 다양성이라서요!
[앞으로의 바램]
물론 많은 시간이 소요되는 작업들이지만, 이것이 모두를 성장 시킬 수 있는 가장 빠른 방법이고 시간이 지날 수록 연구속도를 가속화 시키고 좋은 성과를 뱉어내는데 필수적인 역할을 할 것으로 기대하고 있어요.
스타트업이나 회사에서만 배울 수 있는것이 많은게 아니라, 대학원에서도 배울 수 있는게 많았으면 좋겠다는 마음가짐으로 스터디원을 꾸려나갈 생각입니다!
이러한 협업 연구시스템을 구성하는게 또 하나의 좋은 연구 방법이다라는 생각이 들겠금 많은 연구성과로 보여줄 수 있도록 노력하겠습니다!
[공지]
그리고 앞으로는 이 블로그에서 기술관련 내용 보다는 이렇게 개인적인 소식을 전달해 드리는 글을 작성할 것 같습니다!
[하고 싶은 말]
공부를 잘 하고 좋은 성과를 내는 것도 중요하지만, 연구하는 그 과정이 즐거웠으면 좋겠어요.
모른다고 해서 무시받을게 걱정되는게 아니라, 모른다고 말할 수 있는 연구 문화가 됐으면 좋겠어요.
개인의 성장은 누군가의 도움으로 이루어진 것이라고 생각했으면 좋겠어요.
그리고 이러한 이야기들이 듣기 좋은 이상적인 이야기가 아니라 현실적으로 공감하는 이야기가 됐으면 좋겠어요.
단순히 어떠한 큰 포부를 갖고 있거나 신념이 있어서 하는 말이 아니라 그냥 그랬으면 좋겠어요.
P.S. 같이 의료 인공지능관련하여 연구하고 스터디 하시고 싶으신 분이 있으시면 아래 메일로 연락주세요!
지난 글에서는 representation learning에 대해서 알아보았다면, 이번 글에서는 unsupervised learning으로 학습시킨 representation model을 어떻게 pretraining model로써 사용했는지 알아보도록 하겠습니다.
우리는 보통 supervised learning 기반의 Deep Neural Network (DNN) 모델을 deep supervised network라고 합니다. 이러한 deep supervised network는 이미지 분야, 시계열 분야 등 다양한 task 도메인에 따라 CNN, RNN 같은 모델로 확장되어 왔죠. (기존 DNN이 naive한 모델이라고 한다면, CNN과 RNN 같은 모델은 convolution, recurrence 와 같은 DNN에 비해 architecturalspecializations 한 모델이라고 일컫습니다)
하지만, 이러한 CNN, RNN이 아닌 오로지 fully connected layer로 구성된 DNN 방식으로 supervised task에 잘 동작하게 만든 학습 방법이 등장합니다.
"이 학습방법은 unsupervised learning 방식으로 pretraining 모델을 만들고, 해당 pretraining model을 supervised task에 적용하는 것이었습니다."
위에서 설명한 학습 방법론들은 현재 굉장히 많은 분야에서 연구되고 있는데, 이번 글에서는 그 중 최초의 방식인 'Greedy Layer-Wise Unsupervised Pretrainig'에 대해서 알아보려고 합니다.
※Greedy Layer-wise unsupervised training 관련 논문은 아래 논문을 참고해주세요!
Yoshua Bengio, Pascal Lamblin, Dan Popovici, and Hugo Larochelle. Greedy layer-wise training of deep networks. In Bernhard Sch¨olkopf, John Platt, and Thomas Hoffman, editors, Advances in Neural Information Processing Systems 19 (NIPS'06), pages 153–160. MIT Press, 2007.
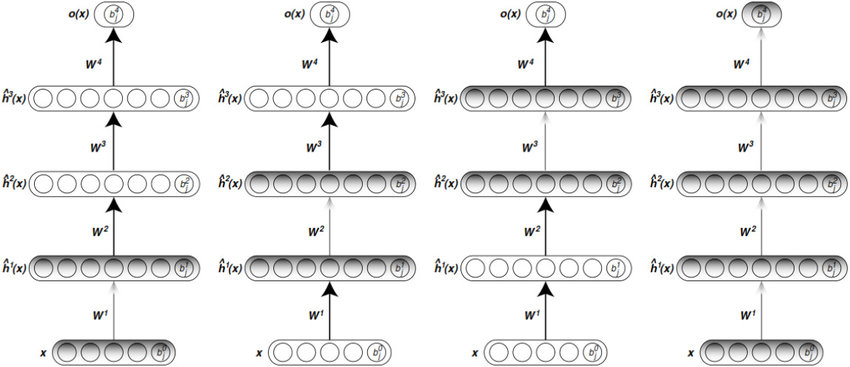
1. Greedy Layer-Wise Unsupervised Pretraining
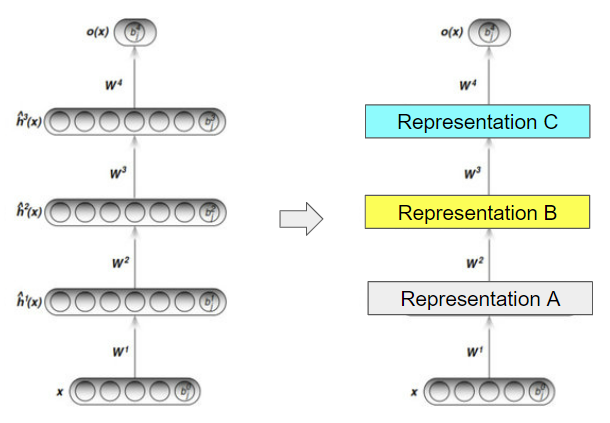
Greedy Layer-Wise Unsupervised Pretraining 방식은 각 layer를 순차적으로 unsupervised learning 시키는 학습 방법론이라고 볼 수 있습니다. 어떤 특정 layer를 B layer라고 했을 때, B layer의 이전 layer output 값을 취하여 B layer가 new representation (or feature)를 출력할 수 있도록 도와주는 방식입니다.
그림 출처: https://www.researchgate.net/figure/Unsupervised-greedy-layer-wise-training-procedure_fig4_308818792
예를 들어, 20×20 이미지 data (=400차원)가 최초의 정보(information)로 주어졌다고 가정해보겠습니다. 그리고, 첫 번째 layer를 거쳐서 나오는 neuron(=indepent vector)이 300개(=300차원)라고 해보겠습니다. 최초의 정보인 400차원 데이터는 첫 번째 layer를 거쳐 가공된 300차원 feature(or representation)가 됩니다. 그리고, 첫 번째 layer를 거친 300차원 feature는 두 번째 layer 입장에서 보면 가공해야 할 또 다른 정보(=information)가 되는 것이죠. 어찌됐든, 첫 번째 layer의 최초의 정보(=400차원)와 두 번째 layer의 정보(=300차원)는 성격이 다르기 때문에, 이들을 가공해서 얻게 되는 output인 feature(or representation)도 layer 마다 성격이 다르다고 할 수 있습니다. 이러한 방식을 통해 각 layer 마다 고유의 representation을 갖게 되는 것이죠.
Greedy Layer-Wise Unsupervised Pretraining 알고리즘은 아래와 같습니다.
L: Unsupervised learning algorithm → for 문에서 k가 하나씩 증가할 때, L 알고리즘을 통해 만들어진 \(f^{(k)}\)은 학습이 완료되었음을 가정 → L을 통해 학습한 각 layer는 고유의 representation을 갖고 있음
참고로 이 책에서는 unsupervised learning algorithm에 대한 구체적인 description은 없고, 여러 논문들을 reference 해놓기만 했습니다.
Identity function: f(x) = x → 입력값=출력값
Function composition: \(g\)∘\(f\) = \(g(f(x))\) → \(f^{(k)}\)∘\(f\) = \(f^{(k)}(f(x))\)
Y: target(labeled) data
X: input data
※ f: fine-tuning if문에서의 f는 이전 for문에 의해 \(f^{k=m}(f(f....(f^{1}(X))....))\)를 의미한다.
앞서 이야기 했듯, 이전에는 FC layer 기반 (=jointly)의 DNN 모델을 처음부터 supervised task에 적용하는 것이 매우 힘들었지만, 위와 같은 학습 방법론 (=Greedy layer-wise Unsuperivsed pretraining)을 통해 DNN 모델을 supervised task에 적용할 수 있게 됐습니다.
Greedy layer-wise training procedures based on unsupervised criteria have long been used to sidestep the difficulty of jointly training the layers of a deep neural net for a supervised task.
1-1. "Greedy layer-wise unsupervised"
위의 알고리즘을 greedy layer-wise라고 부르는 이유를 간단히 설명해보겠습니다.
우리는 어떤 문제(=task)를 해결하기 위해 알고리즘(=solution)을 고안합니다. 그런데, 세상에는 완벽한 해결책이라는게 존재하지 않죠. 그렇기 때문에 어떤 경우에는 굉장히 복잡한 task를 작은 문제들로 나누고, 이러한 작은 문제들을 해결해 나가면서 최종 task의 해를 구하기도 합니다. 보통 이러한 알고리즘 해결법을 Dynamic programming이라고 하죠. 반면, 복잡한 task를 작은 문제들로 나누지 못하는 경우에는 그때 그때 직면한 문제를 해결함으로써 최종 task의 해를 구해나가는데, 이 경우를 greedy algorithm이라고 합니다.
즉, Greedy algorithm은 각각에 직면 하는 단계들에서 solution을 구하는 (=each piece of the solution independently) 방법론이라고 할 수 있습니다. 'Greedy layer-wise unsupervised pretrining' 관점에서 보면 indepent pieces를 각각의 layer라고 볼 수 있겠네요. 여기서 indepent라고 표현한 이유는 두 번째 layer를 unsupervised 방식시켜도, 첫 번째 layer가 학습되지 않기 때문에 '학습의 관점'에서는 layer들이 indepent하다고 할 수 있습니다.
학습 시킬 때는 첫 번째 layer가 별로(=layer-wise) unsupervised learning 방식으로 학습을 시킵니다. 입력 값이 마주하는 layer 마다 독립적으로 unsupervised task를 진행합니다. 즉, 각 layer 마다의 독립적인 solution을 구하는 것인데, 바꿔말하면 각 layer에 해당하는 최소 loss값을 구할 수 있도록 학습시키는 것이 목적입니다.
그림 출처: https://www.researchgate.net/figure/Unsupervised-greedy-layer-wise-training-procedure_fig4_308818792
1-2. "Pretraining"
앞서 학습했던 "Greedy layer-wise Unsupervised" 방식으로 학습한 DNN은 결국 supervised task에 (fine-tuning 되어) 사용됩니다. 이러한 관점으로 봤을 때, 이전 Unsupervised 방식으로 학습된 DNN은 pretraining model이라고 볼 수 있죠.
즉, "Greedy layer-wise unsupervised pretraining model"은 supervised task 관점에서 보면, weight initialization 또는 regularizer (to prevent overfitting) 역할을 하게 되는 겁니다.
2. Greedy Layer-Wise Unsupervised Pretraining for Unsupervised learning
앞선 글에서는 "Greedy layer-wise unsupervised pretraining 모델"이 supervised task에 fine-tuning하기 위해 사용된다고 언급했지만, 사실 unsupervised task를 해결하기 위한 pretraining 모델로써도 사용이 됩니다. 정확히 어떻게 사용했는지는 아래 세 논문을 살펴보는 것을 추천합니다. 참고로 아래 세 가지 모델에 대한 자세한 설명은 Deeplearning book "Chapter 20. Deep Generative model"에서 다루는데,추후에 Chapter20에 대한 내용도 포스팅 하도록 하겠습니다.
Reducing the Dimensionality of Data with Neural Networks → deep autoencoder(by G. E. HINTON AND R. R. SALAKHUTDINOV; 2006)
A Fast Learning Algorithm For Deep Belief Nets → deep belief nets (by G. E. HINTON; 2006)
Deep Boltzmann Machines (by SalakhutdinovandHinton, 2009a)
지금까지 Unsupervised learning 방식으로 pretraining 모델을 만드는 최초의 학습 방법론에 대해서 설명해보았습니다.
그럼 다음 글에서는 "Unsupervised learning 방식의 pretraining 모델을 언제 써야 하는지?"에 대한 내용을 다루어보도록 하겠습니다.
이번글에서는 representation learning이라는 개념에 대해서 설명하려고 합니다.
개인적으로 2021년 동안 논문을 살펴보면서 가장 눈에 많이 띄었던 용어가 representation learning 이었습니다. 예를들어, GAN, self-supervised learning, transfer learning, domain adaptation 관련 논문들에서 자주 봤던 것 같네요.
이렇듯, 최근 deep learning 모델들을 representation learning 관점에서 설명하고 해석하려는 경향이 많은 것 같아 이번글에서 representation learning과 deep learning 간의 관계를 살펴보려고 합니다.
그림 출처: https://dmitry.ai/t/topic/175>
1. Representation Learning이란?
※Representation learning에 대한 개념을 사전적으로 정의하기 전에 우선 몇 가지 예시들을 통해 representation에 대한 개념을 직관적으로 이해해보도록 해보겠습니다.
1-1. 일반적인 관점에서의 representation
먼저, representation이란 개념을 일반적인 관점에서 살펴보겠습니다.
"잠시 아래 이미지를 보고 5초 동안 생각해보세요!"
여러분은 위의 이미지를 보고 다음과 같은 생각을 하셨을 겁니다.
"음.. 나누기가 있네? "나누기"하란 뜻이구나!"
그런데, 여기서 문제가 발생합니다. '나누기'를 하려고 하는데 로마(숫)자 표기가 되어있죠. 로마자를 이용하여 나누기를 하는건 생각보다 어려운 문제입니다. 그래서 여러분은 무의식적으로 위의 로마자를 "0, 1, 2, ..., 9"와 같은 아라비아 숫자로 바꾸어 나누기를 하려고 할 것 입니다.
"즉, 나누기를 하기 위해서는 아리비아 숫자로 표기하는 것이 좀 더 수월한 것이죠."
그럼, 지금까지 이야기 한 내용을 좀 더 자세히 설명해보겠습니다.
우리는 보통 어떤 task를 해결하기 위해서 task와 관련된 정보들을 이용합니다. 예를 들어, 나누기(=task)를 하려고 하면 "수(=numeric)"라는 정보를 이용하죠. 하지만, 이러한 "수(=numeric)"라는 정보들은 다양하게 표현(=representation)될 수 있습니다. 수를 표현하는 방법에는 '로마숫자표기(=Roman numerical representation)', '아라비아숫자표기(Arabic numerial representation)' 등이 있죠.
보통 task들의 난이도는 정보들을 어떻게 표현(=representation)해주느냐에 따라서 결정이 됩니다. 즉, 정보들을 특정 task에 맞게 잘 표현(=representation)해주면 해당 task를 풀 수 있는 확률이 높아지는 것이죠.
예를들어, 우리가 수를 나눈다고 가정해보겠습니다. 이 때, 수(=numeric)라는 정보를 로마숫자(=Roman numerical representation)로 표현하면 어떻게 될까요? 다시 말해, "CCX÷VI"라는 문제(=task)가 주어주면 풀기가(=해결하기가) 매우 힘들 것 입니다. 하지만, 나누기라는 task를 "210÷6"과 같이 아라비아 숫자(=Arabic numerial representation)로 표현하면 금방 해결하실 수 있으실 겁니다. 왜냐하면 아라비아 숫자를 이용하면 'place-value system'을 이용할 수 있기 때문입니다.
“The Roman numeral system (I, II, III, IV,...) lacks an efficient way to represent place, and it makes simple arithmetic functions (<- ex: division) very difficult to perform for most people. So, we need a place-value system. A place-value system assigns a certain value to the spatial location of a number in a series.”
이미지 출처:https://www.splashlearn.com/math-vocabulary/place-value/place-value
(위에서 한 이야기를 아래와 같이 정리해볼 수 있겠네요!)
이렇듯, 우리가 나누기를 할 때, 수(=numeric)라는 정보를 보통 아라비아 숫자로 가공(=processing)하여 표현(=representation)하게 됩니다.
또 다른 예시로는 알고리즘이 있습니다. (이 부분은 자료구조의 개념이 필요하기 때문에 구체적으로 이해가 안되시는 분들은"linked list, binary tree search, 시간복잡도"와 관련된 개념들을 찾아 보시길 권유합니다. 시간이나면 이 개념들에 대한 글을 따로 리포팅 하도록 하겠습니다.)
우리에게 어떤 수들이 주어져있고, 이 수들은 이미 오름차순으로 정렬이 되어 있다고 가정해보겠습니다. 이 때, 우리에게 새로운 수 하나가 주어졌다고 했을 때, 그 수를 올바른 위치에 삽입하는데 필요한 시간 복잡도가 어떻게 될까요? 이에 대한 답은 아래와 같습니다.
"정렬된 수 들을 어떻게 표현(=representation)해주느냐에 따라 다릅니다!"
자료구조에서는 정렬된 수 들을 아래와 같이 두 가지 형태 (=linked list, binary tree) 형태로 표현할 수 있습니다.
(참고로 교재에서 설명하는 red-black tree는 binary search tree의 일종인 self-balancing binary search tree라고 하는데, 이에 대한 자세한 설명은 생략하고 red-black tree를 binary search tree로만 표현하여 설명하도록 하겠습니다.)
결국 우리에게 주어진 수를 어떠한 자료구조 형태 (ex: linked list or binary search tree) 로 표현(=representation)하느냐에 따라서 "정렬된 수에 특정 수를 삽입(=insert)"하는 task의 시간복잡도(=난이도)가 결정됩니다.
이미지 출처:https://callmedevmomo.medium.com/%EC%9B%B9-%EA%B0%9C%EB%B0%9C%EC%9E%90%EB%A5%BC-%EC%9C%84%ED%95%9C-%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0%EC%99%80-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98-01-%EB%B9%85%EC%98%A4-%ED%91%9C%EA%B8%B0%EB%B2%95-ff369f0efc1d
지금까지 이야기한 내용들을 함축적으로 정리하면 아래와 같습니다.
"결국 우리는 어떤 task를 해결할 때, 정보(=information)를 어떻게 가공(processing)하여 표현(=representation)해줄지에 따라서 task의 난이도가 결정이 된다."
(↓↓↓ Deep learning book 본문 내용↓↓↓)
"Many information processing tasks can be very easy or very difficult depending on how the information is represented."
그렇다면 어떻게딥러닝 모델에서 representation이란 개념은 어떻게 이해해야 할까요?
여기서의 task는 linear classifier를 이용한 classification task입니다. 그리고, 최초의 정보(information)라고 할 수 있는 DNN의 input 값들(=다양한 독립변수들: x1, x2, ..., xn)을 neural network로 가공(=processing)하여 'learned h space'로 표현(=representation)해 줍니다.
즉", 최초의 input 값들을 linear classifier가 올바르게 classification 할 수 있도록 'learned h space'로 표현(=representation)해준 것이죠."
2-2.What is representation in supervised training of feedforward networks?
이미지를 CNN으로 분류하는 문제도 동일하게 생각해 볼 수 있습니다. Supervised learning 기반의 이미지 분류에서도 흔히 softmax (linear classifier)를 이용해 최종 분류를 하게 됩니다. (Softmax가 왜 linear classifier인지는 뒤에서 설명하도록 하겠습니다)
"즉, 이미지를 linear classifier로 classification 하려는 task인 셈이죠."
그런데, 일반적으로 DNN(=Deep Neural Network) 구조는 이미지 분류 성능이 좋지 않다고 알려져 있습니다 (자세한 설명은 아래 글을 참고해주세요!)
앞서 "DNN 구조는 이미지 분류 성능이 좋지 않다"고 언급한 부분은 아래와 같이 다르게 해석해 볼 수 있습니다.
"DNN 구조는 (linear classifier를 이용한) 이미지 분류 task를 하기 위해 최초의 정보들을 부적절하게 표현(=representation) 해준다"
그래서, DNN과 다르게 visual feature들을 잘 뽑아(or 표현해) 낼 수 있는 Convolutional Neural Network (CNN)가 도입이 되게 됩니다. CNN은 convolutional filter를 이용한 feature extractor를 갖는데, 이러한 feature extractor 덕분에 softmax linear classifier가 이미지를 잘 classification 해줄 수 있도록 최초 정보(=input 이미지)를 가공(=processing)하여 표현(=representation) 해주게 되는 것이죠.
"CNN achieves good representation for image classification using softmax linear classifier"
Input feature(=원본 이미지)가 CNN에 입력되면 다양한 conv layer에 의해 hierarchical feature map들이 얻어집니다. Task에 따라 feature extractor를 거쳐 얻은 최종 feature(=feature classifier에 입력되기 직전)의 표현(=representation)들이 달라질 것입니다. 예를 들어, classification task이면 classification에 맞는 최종 feature가 representation 될 것이고, segmentation task이면 segmentation에 맞는 최종 feature가 representation이 될 것 입니다.
책에서는 subsequent learning task라고 언급하는 부분이 있는데, 이것이 최종 task의 종류들(=ex: classification task, segmentation task, linear clasifier task, etc...) 을 의미하는 듯 합니다.
"Generally speaking, a good representation is one that makes a subsequent learning task easier. The choice of representation will usually depend on the choice of the subsequent learning task."
결국 DNN, CNN 모두 최종 task의 유형에 따라 'new representation'에 해당하는 new feature(<--> input feature)를 출력하게 됩니다. 이러한 'new representation'을 뽑게 학습하는 것을 representation learning이라고 부르는 것이죠.
이미지 출처:https://srdas.github.io/DLBook/NNDeepLearning.html
좀 더 구체적인 예시를 들어보겠습니다.
먼저, 우리가 24×24 이미지를 갖고 네 가지 클래스를 분류한다고 해보겠습니다.
Blue Square
Blue Circle
Red Square
Red Circle
이 때, 576(=24×24)개의 입력 feature로 부터 뽑을 수 있는 가장 이상적인 (hidden) feature vector (=indepent vectors)를 뽑으라고 한다면, 아래와 같이 'color', 'shape' 2차원 (hidden) feature vector가 될 것 입니다. 그리고 이러한 feature vector를 'new representation'으로 볼 수 있겠네요.
"하지만, 'new representation'을 추출하는 network(=모델)가 무엇이냐에 따라서 달라집니다."
아래 왼쪽 이미지에서 'entangled space'를 DNN을 이용하여 얻은 (hidden) feature vector들이라고 가정한다면, DNN으로는 'blue circles'를 linear classifier로 구분하기 힘듭니다. 반대로, 오른쪽 'disentangled space'를 CNN을 통해 얻은 (hiddent) feature vector들이라고 한다면, 4가지 클래스 모두 linear classifier로 충분히 분류할 수 있게 됩니다.
이미지 출처:&amp;amp;amp;amp;amp;amp;amp;amp;nbsp;https://arxiv.org/abs/2007.06356
"즉, CNN은 이미지를 linear clasifier로 잘 분류할 수 있도록 (hidden) feature vector를 잘 representation 해주는 것이죠."
지금까지 설명한 내용을 종합하자면 결국 아래와 같이 정리해 볼 수 있겠네요.
결국 딥러닝 모델 성능은 "특정 task에 해당하는 최종 feature(=원본 데이터(=information)에서 가공된 데이터)들을 얼마나 잘 representation 해주느냐"에 따라 달려있다.
보통, feature learning, feature representation learning, representation learning 이라는 단어들이 자주 혼용되서 사용되는데, 위에서 언급한 바를 생각해보시면 어떠한 이유로 해당 용어를 혼용해서 사용했는지 조금은 파악하실 수 있으실 거라 생각됩니다.
[Q. Softmax가 왜 linear classifier인가요?]
위의 질문에 답을 하기전에 먼저 아래의 질문에 답을 해보도록 하겠습니다.
'Q. logistic regression'이 어떻게 linear classifier가 될 수 있는가?'
우리는 logistic regression을 아래 그림으로 나타낼 수 있습니다.
우리에게 X라는 input 데이터가 주어 졌을 때, Y가 0 또는 1을 구분 짓는 binary classification을 한다고 가정해보겠습니다. X가 주어졌을 때 Y가 0이 될 확률을 "P(Y=0|X)"와 같이 표현할 수 있고, 이것을 sigmoid function을 이용해 구체적인 (확률) 값으로 표현한다면 아래 이미지의 수식을 이용하게 됩니다. 또한, 'binary clasfication'이기 때문에 P(Y=1|X)인 경우의 확률 값을 "1-P(Y=0|X)"라고 표현 할 수 있게 되죠.
Binary classification 문제는 P(Y=1|X), P(Y=0|X) 둘 중 어느 확률이 더 큰지에 따라서 최종 output 값(=Y)을 1로 classification 할 것인지, 0으로 classification 할 것인지 결정합니다. 그리고 이것을 아래와 같이 정리해볼 수 있죠.
위의 수식을 통해 우리는 아래와 같이 정리해볼 수 있습니다.
"logistic regression이 linear method라고 불리는 이유는 linear한 계산을 통해 풀 수 있는 문제여서가 아니라, logistic regression을 결정짓는 decision boundary가 여전히 linear하기 때문인 것이다."
(↓↓↓ logistic classifier가 linear classfier라는 설명을 참고한 링크 ↓↓↓)
3. Unsupervised learning 관점에서 representation (learning) 이란?
앞서 설명한 supervised learning 기반의 representation (learning)에 대한 연구도 이루어지고 있지만, 오늘날 주로 연구되는 분야는 unsupervied learning 방식으로 하는 representation learning입니다. Deeplearning book의 " Chapter 15. Representation Learning" 역시 대부분 unsupervised learning 방식의 representation learning에 대해서 이야기하고 있습니다. 이에 대한 자세한 설명은 다음 포스팅에서 하도록 하겠고, 여기에서는 추상적인 이유에 대해서만 말씀드리도록 하겠습니다.
앞서 supervised learning 관점에서 representation을 해석해 봤다면, 이번에는 unsupervised learning 관점에서 representation이 (supervised learning 관점에서의 representation과) 어떻게 다르게 설명될 수 있는지 살펴보겠습니다.
Unsupervised learning은 쉽게 말해 unlabelded dataset을 이용한 학습 방식입니다. 물론, unsupervised learning도 objective(=loss) function이 있기 때문에 그 나름대로의 representation을 학습하게 됩니다.
이미지 출처:https://srdas.github.io/DLBook/NNDeepLearning.html
Unsupervised learning에서도 new representation에 해당하는 hidden feature vector를 구할 수 있습니다. 그런데, 우리는 이러한 representation을 명시적(explicit)으로 설정(=design)할 수 있습니다. 즉, hidden feature vector들이 어떠한 density function(→ 뒤에서 더 자세히 설명)을 따를거라고 명시적으로 표현(=representation)해 줄 수 있죠 (물론 이론이 아닌 '현실세계'에서는 굉장히 어려운 문제이지만요!).
예를 들어, VAE (=Variational Auto-Encoder) 같은 경우에도 hidden feature vector (= latent vector)가 normal distribution을 따를 것이라고 명시적으로 가정합니다. 이러한 내용을 Deeplearning book에서는 일반화하여 아래와 같이 표현합니다.
"Other kinds of representation learning algorithms are often explicitly designed to shape the representation in some particular way. (->VAE같은 representation learning 알고리즘은 representation에 해당하는 feature vector가 명시적(=explicit)으로 normal distribution을 따르겠금(=shape) 고안된다)"
이미지 출처:&amp;amp;amp;amp;amp;nbsp;https://learnopencv.com/variational-autoencoder-in-tensorflow/
앞서 설명한 개념들 중에 density estimation과 explicit 이란 단어를 좀 더 설명해보도록 하겠습니다.
위와 같이 다양한 현상들을 확률적으로 표현해주는 probability distribution이 존재합니다.
이미지 출처:&amp;amp;amp;amp;nbsp;https://destrudo.tistory.com/16
앞에 설명한 내용을 다시 정리해보겠습니다.
관측 데이터가 한달, 두 달, 1년 넘게 쌓이게 되면 우리는 '일일 교통량'이란 변수가 어떤 (확률분포) 특성을 갖는지 좀더 정확히 파악할 수 있게 됩니다.
우리는 여기서 '변수'와 '데이터(=관측 값)'에 대한 관계를 정의해볼 수 있습니다.
어떤 변수가 가질 수 있는 다양한 가능성 중의 하나가 현실 세계에 구체화된값을 데이터라고 부릅니다. 즉, 데이터는 변수의 일면에 불과한 것이죠.
“우리는 이렇게 관측된 데이터들을 통해 그 변수(random variable)가 가지고 있는 본질적인 특성을 probability density distribution으로 설명 또는 추정(estimate)하려고 하는데, 이를 'density estimation (밀도추정)' 이라고 합니다”
CS231 수업에서도 generative model을 아래와 같이 구분하고 있는데, VAE와 같은 모델을 explicit density estimation으로 보고 있고, 이것을 통해 'parametric=explicit' 관계로 해석했습니다 (이와 같은 해석은 저의 주관적 해석이니 다른 의견이 있으신 분들은 댓글 달아주시면 감사하겠습니다!).
Deeplearning book에서는 "Supervised training of feedforward networks does not involve explicitly imposing any condition on the learned intermediate features."와 같은 표현을 합니다. 이 문장을 개인적으로 해석하면 아래와 같다고 생각합니다.
does not involve explicitly imposing any condition on the learned intermediate features. ← Supervised learning으로 이미 학습된 feature들은 어떤 PDF를 따를거라고 명시적(=explicit)으로 지정되지 않음
앞서 언급한 latent vector들이 (dependent vector들을 포함하기 보다) independent vector들을 더 많이 포함할 수 록 좀 더 고차원 데이터를 쉽게 표현해 줄 수 있습니다. 예를 들어, 사람 얼굴을 4개의 latent vector들로 표현한다고 했을 때, "x1=얼굴색, x2=인종, x3=머리색, x4=수염" 이렇게 표현하면 x1과 x2는 어느 정도 종속관계 (dependent) 이기 때문에 (상대적으로) 표현력이 떨어지게 되지만, 반대로 "x1=인종, x2=수염, x3=머리색, x4=안경여부" 이렇게 표현한다면 더 많은 사람들의 얼굴을 잘 표현할 수 있을 것입니다.
이미지 출처:&amp;amp;amp;amp;nbsp;https://www.jeremyjordan.me/variational-autoencoders/
"그래서, latent vector들이 최대한 independent 하도록 objective(=loss) function을 설계하는 것이 핵심 포인트가 됩니다."
4. Multi-task learning 그리고 shared internal representation
우리에게 굉장히 적은 데이터들이 주어졌을 때, supervised learning을 적용한다면 흔히 overfitting 문제가 발생할 것입니다. 예를 들어, 우리에게 아래와 같은 Chest X-Ray 폐렴 데이터만 갖고 있다고 해보겠습니다.
이미지 출처:https://www.openaccessjournals.com/articles/advanced-neural-network-solution-for-detection-of-lung-pathology-and-foreign-body-on-chest-plain-radiographs-13104.html그림 출처:https://www.openaccessjournals.com/articles/advanced-neural-network-solution-for-detection-of-lung-pathology-and-foreign-body-on-chest-plain-radiographs-13104.html
의사들이 보는 폐렴 증상은 분명 폐주위의 섬유화에 주목하겠지만, 딥러닝의 경우는 CAM(=Class Activation Map)을 통해 살펴보면 엉뚱한데를 주목하는 경향이 있습니다. 아래와 같이 엉뚱한 곳을 보는 이유는 폐렴 관련 데이터는 저런 부분들만 살펴봐도 분류가 가능했기 때문일 수 있습니다. 즉, 정답의 이유는 상관없이 "학습 데이터의 정답만 맞추면 된다"는 식인 것이죠.
하지만, 저런 artifacts와 같은 요소들이 없는 폐렴 데이터가 들어오면 곧 바로 틀려버립니다. 즉, supervsied learning 방식을 사용한 CNN이 적은 수 의 폐렴 데이터로 학습하게 되면, 폐렴 CXR 이미지를 제대로 representation 해줄 수 없게 된다고 이야기 할 수 있습니다.
또 다른 예시로는 한 병원의 의료 이미지 데이터만 사용하여 학습시킨 딥러닝 모델을 다른 병원의 의료 이미지 데이터로 테스트 하려고 하면 잘 안되는 경우가 있습니다. 여기서 생각해 볼 수 있는 부분은 해당 딥러닝이 특정 병원에서 생산되는 기기의 noise를 학습해버렸다거나, 기기의 contrast를 고유하게 학습했을 경우 다른 병원의 noise, contrast가 들어오면 기존 예측방식에 큰 혼란을 줄 수 있겠죠 (물론 data augmentation을 이용하여 이러한 문제를 조금 해결할 수 있겠으나, 우리가 모르는 해당 병원의 고유의 변수들을 모두 커버할 순 없겠죠).
결과적으로, 적은 수의 데이터를 이용하여 supervised learning을 적용하면 unseen data (=training data에 포함되지 않은 데이터) 를 잘 예측하지 못하게 됩니다. 이를 보통 sensitive 하게 반응한다고 하죠. 그렇다면, 우리는 unseen data에도 robust하게 작동할 수 있는 딥러닝 모델을 만들어야 합니다.
만약 우리가 방대한 unlabeled data를 이용하여 이미지를 잘 representation 해 줄 수 있는 딥러닝 모델을 만든다면, 이러한 딥러닝 모델을 pretrained model로써 활용할 수 있을 겁니다. 즉, 최종 supervised task에 unlabeled data으로 학습시킨 pretrained model을 적용해도 좋은 '일반화 성능'을 얻을 수 있게 되는 것이죠.
"Training with supervised learning techniques on the labeled subset often results in severe overfitting. Semi-supervised learning offers the chance to resolve this overfitting problem by also learning from the unlabeled data. Specifically, we can learn good representations for the unlabeled data, and then use these representations to solve the supervised learning task."
또한 우리는 unlabeled data를 이용한 unsupervised learning 방식과 supervised learning 방식을 섞은 semi-supervised learning 방식을 이용할 수도 있습니다.
"즉, unsupervised learning 방식의 internal representation와 supervised learning 방식의 internal representation을 공유(share)할 수도 있는 것이죠."