안녕하세요.
지난 글에서는 representation learning에 대해서 알아보았다면, 이번 글에서는 unsupervised learning으로 학습시킨 representation model을 어떻게 pretraining model로써 사용했는지 알아보도록 하겠습니다.
우리는 보통 supervised learning 기반의 Deep Neural Network (DNN) 모델을 deep supervised network라고 합니다. 이러한 deep supervised network는 이미지 분야, 시계열 분야 등 다양한 task 도메인에 따라 CNN, RNN 같은 모델로 확장되어 왔죠. (기존 DNN이 naive한 모델이라고 한다면, CNN과 RNN 같은 모델은 convolution, recurrence 와 같은 DNN에 비해 architectural specializations 한 모델이라고 일컫습니다)
하지만, 이러한 CNN, RNN이 아닌 오로지 fully connected layer로 구성된 DNN 방식으로 supervised task에 잘 동작하게 만든 학습 방법이 등장합니다.

"이 학습방법은 unsupervised learning 방식으로 pretraining 모델을 만들고, 해당 pretraining model을 supervised task에 적용하는 것이었습니다."
위에서 설명한 학습 방법론들은 현재 굉장히 많은 분야에서 연구되고 있는데, 이번 글에서는 그 중 최초의 방식인 'Greedy Layer-Wise Unsupervised Pretrainig'에 대해서 알아보려고 합니다.
※Greedy Layer-wise unsupervised training 관련 논문은 아래 논문을 참고해주세요!
Yoshua Bengio, Pascal Lamblin, Dan Popovici, and Hugo Larochelle. Greedy layer-wise training of deep networks. In Bernhard Sch¨olkopf, John Platt, and Thomas Hoffman, editors, Advances in Neural Information Processing Systems 19 (NIPS'06), pages 153–160. MIT Press, 2007.
1. Greedy Layer-Wise Unsupervised Pretraining
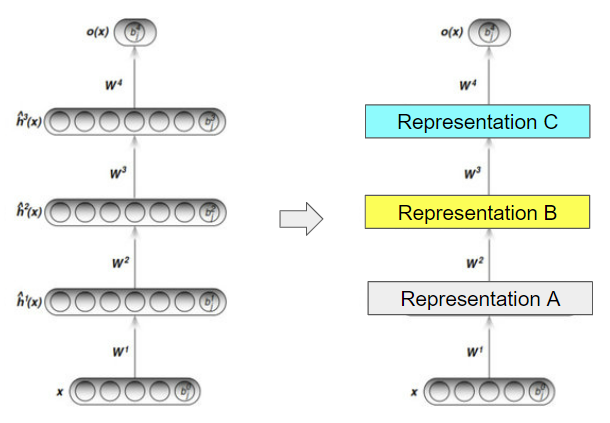
Greedy Layer-Wise Unsupervised Pretraining 방식은 각 layer를 순차적으로 unsupervised learning 시키는 학습 방법론이라고 볼 수 있습니다. 어떤 특정 layer를 B layer라고 했을 때, B layer의 이전 layer output 값을 취하여 B layer가 new representation (or feature)를 출력할 수 있도록 도와주는 방식입니다.
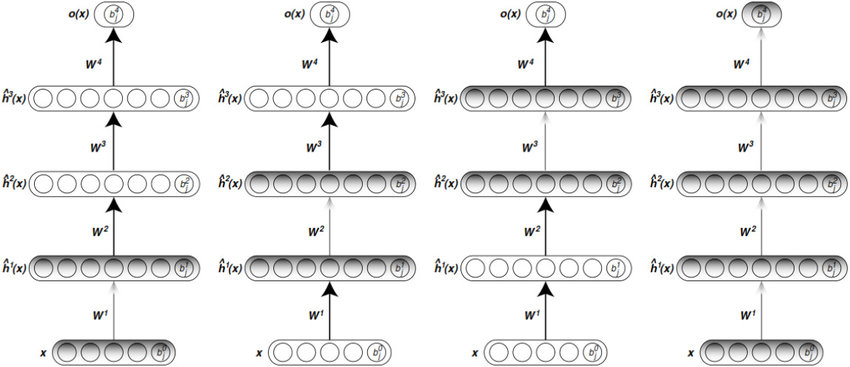
예를 들어, 20×20 이미지 data (=400차원)가 최초의 정보(information)로 주어졌다고 가정해보겠습니다. 그리고, 첫 번째 layer를 거쳐서 나오는 neuron(=indepent vector)이 300개(=300차원)라고 해보겠습니다. 최초의 정보인 400차원 데이터는 첫 번째 layer를 거쳐 가공된 300차원 feature(or representation)가 됩니다. 그리고, 첫 번째 layer를 거친 300차원 feature는 두 번째 layer 입장에서 보면 가공해야 할 또 다른 정보(=information)가 되는 것이죠. 어찌됐든, 첫 번째 layer의 최초의 정보(=400차원)와 두 번째 layer의 정보(=300차원)는 성격이 다르기 때문에, 이들을 가공해서 얻게 되는 output인 feature(or representation)도 layer 마다 성격이 다르다고 할 수 있습니다. 이러한 방식을 통해 각 layer 마다 고유의 representation을 갖게 되는 것이죠.
Greedy Layer-Wise Unsupervised Pretraining 알고리즘은 아래와 같습니다.
- L: Unsupervised learning algorithm → for 문에서 k가 하나씩 증가할 때, L 알고리즘을 통해 만들어진 \(f^{(k)}\)은 학습이 완료되었음을 가정 → L을 통해 학습한 각 layer는 고유의 representation을 갖고 있음
- 참고로 이 책에서는 unsupervised learning algorithm에 대한 구체적인 description은 없고, 여러 논문들을 reference 해놓기만 했습니다.
- Identity function: f(x) = x → 입력값=출력값
- Function composition: \(g\)∘\(f\) = \(g(f(x))\) → \(f^{(k)}\)∘\(f\) = \(f^{(k)}(f(x))\)
- Y: target(labeled) data
- X: input data
※ f: fine-tuning if문에서의 f는 이전 for문에 의해 \(f^{k=m}(f(f....(f^{1}(X))....))\)를 의미한다.

앞서 이야기 했듯, 이전에는 FC layer 기반 (=jointly)의 DNN 모델을 처음부터 supervised task에 적용하는 것이 매우 힘들었지만, 위와 같은 학습 방법론 (=Greedy layer-wise Unsuperivsed pretraining)을 통해 DNN 모델을 supervised task에 적용할 수 있게 됐습니다.
Greedy layer-wise training procedures based on unsupervised criteria have long been used to sidestep the difficulty of jointly training the layers of a deep neural net for a supervised task.
1-1. "Greedy layer-wise unsupervised"
위의 알고리즘을 greedy layer-wise라고 부르는 이유를 간단히 설명해보겠습니다.
우리는 어떤 문제(=task)를 해결하기 위해 알고리즘(=solution)을 고안합니다. 그런데, 세상에는 완벽한 해결책이라는게 존재하지 않죠. 그렇기 때문에 어떤 경우에는 굉장히 복잡한 task를 작은 문제들로 나누고, 이러한 작은 문제들을 해결해 나가면서 최종 task의 해를 구하기도 합니다. 보통 이러한 알고리즘 해결법을 Dynamic programming이라고 하죠. 반면, 복잡한 task를 작은 문제들로 나누지 못하는 경우에는 그때 그때 직면한 문제를 해결함으로써 최종 task의 해를 구해나가는데, 이 경우를 greedy algorithm이라고 합니다.
즉, Greedy algorithm은 각각에 직면 하는 단계들에서 solution을 구하는 (=each piece of the solution independently) 방법론이라고 할 수 있습니다. 'Greedy layer-wise unsupervised pretrining' 관점에서 보면 indepent pieces를 각각의 layer라고 볼 수 있겠네요. 여기서 indepent라고 표현한 이유는 두 번째 layer를 unsupervised 방식시켜도, 첫 번째 layer가 학습되지 않기 때문에 '학습의 관점'에서는 layer들이 indepent하다고 할 수 있습니다.
"The lower layers (which are trained first) are not adapted after the upper layers are introduced."
학습 시킬 때는 첫 번째 layer가 별로(=layer-wise) unsupervised learning 방식으로 학습을 시킵니다. 입력 값이 마주하는 layer 마다 독립적으로 unsupervised task를 진행합니다. 즉, 각 layer 마다의 독립적인 solution을 구하는 것인데, 바꿔말하면 각 layer에 해당하는 최소 loss값을 구할 수 있도록 학습시키는 것이 목적입니다.
1-2. "Pretraining"
앞서 학습했던 "Greedy layer-wise Unsupervised" 방식으로 학습한 DNN은 결국 supervised task에 (fine-tuning 되어) 사용됩니다. 이러한 관점으로 봤을 때, 이전 Unsupervised 방식으로 학습된 DNN은 pretraining model이라고 볼 수 있죠.
즉, "Greedy layer-wise unsupervised pretraining model"은 supervised task 관점에서 보면, weight initialization 또는 regularizer (to prevent overfitting) 역할을 하게 되는 겁니다.
2. Greedy Layer-Wise Unsupervised Pretraining for Unsupervised learning
앞선 글에서는 "Greedy layer-wise unsupervised pretraining 모델"이 supervised task에 fine-tuning하기 위해 사용된다고 언급했지만, 사실 unsupervised task를 해결하기 위한 pretraining 모델로써도 사용이 됩니다. 정확히 어떻게 사용했는지는 아래 세 논문을 살펴보는 것을 추천합니다. 참고로 아래 세 가지 모델에 대한 자세한 설명은 Deeplearning book "Chapter 20. Deep Generative model"에서 다루는데,추후에 Chapter20에 대한 내용도 포스팅 하도록 하겠습니다.
- Reducing the Dimensionality of Data with Neural Networks → deep autoencoder (by G. E. HINTON AND R. R. SALAKHUTDINOV; 2006)
- A Fast Learning Algorithm For Deep Belief Nets → deep belief nets (by G. E. HINTON; 2006)
- Deep Boltzmann Machines (by Salakhutdinov and Hinton, 2009a)
지금까지 Unsupervised learning 방식으로 pretraining 모델을 만드는 최초의 학습 방법론에 대해서 설명해보았습니다.
그럼 다음 글에서는 "Unsupervised learning 방식의 pretraining 모델을 언제 써야 하는지?"에 대한 내용을 다루어보도록 하겠습니다.
'Representation Learning' 카테고리의 다른 글
| 1. Representation Learning 이란? (6) | 2022.01.21 |
|---|