안녕하세요.
이번 글에서는 semi-supervised learning에 대한 간략한 개념과 왜 이러한 기술이 필요한지 설명해보도록 하겠습니다.
1. 기존 딥러닝 학습 방식 (Supervised-learning)
- 기존 딥러닝에서는 supervised learning 방식을 통해 분류작업(classification)을 수행합니다.
- 학습과정에서 딥러닝이 예측하는 값이 실제 정답(label 정보)에 가까워 지도록 학습을 유도하는 방식이 supervised learning 방식입니다.
- 즉, supervised learning 방식으로 학습을 시키기 위해서는 training data에 labeled data 정보를 포함하고 있어야 하죠.


2. 의료 분야에서 supervised learning 학습의 한계
- 앞서 언급했듯이, supervised learning의 성능을 극대화 시키기 위해서는 방대한 양의 label 데이터를 필요로 합니다.
- 하지만, 의료 분야에서 이러한 방대한 양의 labeled data를 획득하는 것이 쉽지만은 않습니다.
- 예를 들어, 의료 영상에서 어떤 label 데이터를 얻기 위해서는 다수의 수준급 전문의들이 모여서 각자 소견을 내고 진단을 위한 토론과정을 거쳐야 하는데, 이러한 과정은 굉장한 시간과 비용을 요구합니다.
3. Unlabeled data에 대한 Needs
- 상대적으로 labeled data를 얻는 것 보다 unlabeled data를 얻는 것이 더 수월합니다.
- 현재는 이러한 데이터들이 활용이 되지 않고 있습니다만, 최근 딥러닝에서는 이러한 데이터를 이용해 딥러닝 분류 정확도를 높이는 시도를 하고 있습니다.
- 특히, COVID-19 같은 신종바이러스 발병 초기에는 해당 바이러스의 데이터가 부족하기 때문에 unlabeled data를 잘 활용하는 것이 매우 중요할 수 있습니다.
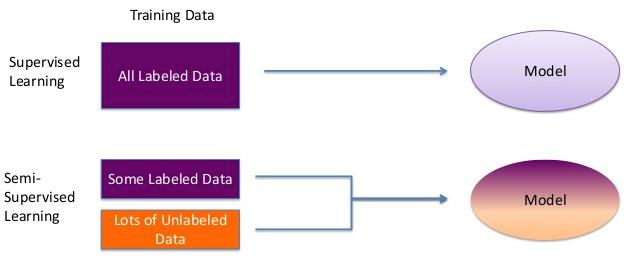
- Semi-supervised learning에서는 기존 labeled data와 unlabeled data를 모두 활용하여 학습시키는 방식이기 때문에, unlabeled data에 대한 활용도가 높아질 것으로 기대하고 있습니다.
4. Future Work
- 해당 카테고리에서는 앞으로 semi-supervised learning 방식을 도입한 모델들을 소개할 예정입니다.
- 관심이 더 있으신 분들은 아래 uc berkeley unsupervised learning 강의에서 아홉번째 lecture를 참고하시면 도움이 될거라 생각합니다.
https://sites.google.com/view/berkeley-cs294-158-sp20/home
CS294-158-SP20 Deep Unsupervised Learning Spring 2020
About: This course will cover two areas of deep learning in which labeled data is not required: Deep Generative Models and Self-supervised Learning. Recent advances in generative models have made it possible to realistically model high-dimensional raw data
sites.google.com

'딥러닝 응용 > Semi-Supervised Learning' 카테고리의 다른 글
| 1.MixMatch; A Holistic Approach to Semi-Supervised Learning (0) | 2021.06.08 |
|---|