CNN모델을 학습시킬 때, 가장먼저 해야할 것은 train, validation, test dataset을 load하는 것입니다.
이번 장에서는 내가 구축한 (custom) dataset을 load하는 방식에 대해서 알아보도록 하겠습니다.
1. Custom dataset directory 설정
1) 학습데이터는 이미지 파일이므로 파일데이터와 관련된 module를 import합니다.
- OS 모듈은 환경 변수나 디렉터리, 파일 등의 OS 자원을 제어할 수 있게 해주는 모듈
import os
2)학습할 데이터셋을 세팅합니다.
우선 학습할 데이터를 다운받고 아래와 같이 세팅이 되어 있는지 확인해 줍니다.
기본적으로 학습을 위한 데이터(cat_and_dogs)는 아래와 같이 train, validation, test 데이터 셋으로 구성이 되어있습니다.

train, validation, test 데이터셋(폴더)에는 각각 클래스와 관련된 폴더가 있고, 해당 폴더에 실제 이미지 데이터가 위치합니다. cats_and_dogs 분류문제는 개와 고양이 두 클래스를 구분하는 binary classification 문제이므로, 각 폴더에 2개의 클래스(개, 고양이)가 포함되어 있습니다.
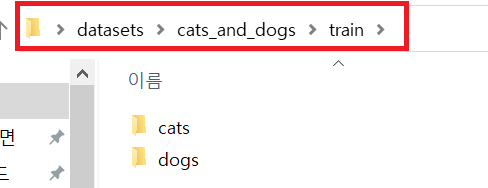
!! 주석부분에 폴더 정보들을 기록해놨으니 꼭 확인해 주세요 !!
#base_dir → 다운받은 원본 데이터셋 경로 = 모든 training, validation, test 데이터셋이 포함되어 있음
#cats_and_dogs에 있는 총 이미지 데이터 개수 = 25,000 ← training:20,000 + validation:4,000 + test:500
base_dir = './datasets/cats_and_dogs/'
#train_dir → 원본 데이터셋의 학습 데이터 경로 = 모든 class(개, 고양이)들의 이미지들이 포함되어 있음
#train_dir에 있는 총 이미지 데이터 개수 = 20,000 ← 강아지=10,000 + 고양이=10,000
train_dir = os.path.join(base_dir, 'train') #train_dir = './datasets/cats_and_dogs/train'
#validation_dir → 원본 데이터셋의 학습 데이터 경로 = 모든 class(개, 고양이)들의 이미지들이 포함되어 있음
#validation_dir에 있는 총 이미지 데이터 개수 = 4,000 ← 강아지=2,000 + 고양이=2,000
validation_dir = os.path.join(base_dir, 'validation') #validation_dir = './datasets/cats_and_dogs/validation'
#test_dir → 원본 데이터셋의 학습 데이터 경로 = 모든 class(개, 고양이)들의 이미지들이 포함되어 있음
#test_dir에 있는 총 이미지 데이터 개수 = 1,000 ← 강아지=500 + 고양이=500
test_dir = os.path.join(base_dir, 'test') #test_dir = './datasets/cats_and_dogs/test'
2. Preprocessing (Normalization)
아래 링크에 걸어둔 글에서 볼 수 있듯이, 보통 효율적인 학습을 위해 딥러닝의 학습데이터들은 전처리의 일환으로 normalization이 적용됩니다
https://89douner.tistory.com/42?category=868069
8. 데이터 전처리 (Data Preprocessing and Normalization)
Q. DNN을 학습시키기 전에 왜 데이터를 전처리해주어야 하나요? 안녕하세요~ 이번시간에는 DNN 모델이 학습을 효율적으로 하기위해 필요한 정규(Noramlization; 정규화) 대해서 알아보도록 할거에요~
89douner.tistory.com
간단하게 말하자면, normalization이 적용된 학습데이터의 problem space가 더 안정적으로 형성될 수 있으므르로 학습이 더 수월하게 된다는 이점이 있습니다.

위와 같은 normalization을 적용해주기 위해서는 아래와 같이 zero center를 맞춰준후, data를 normalization 해주어야 합니다.
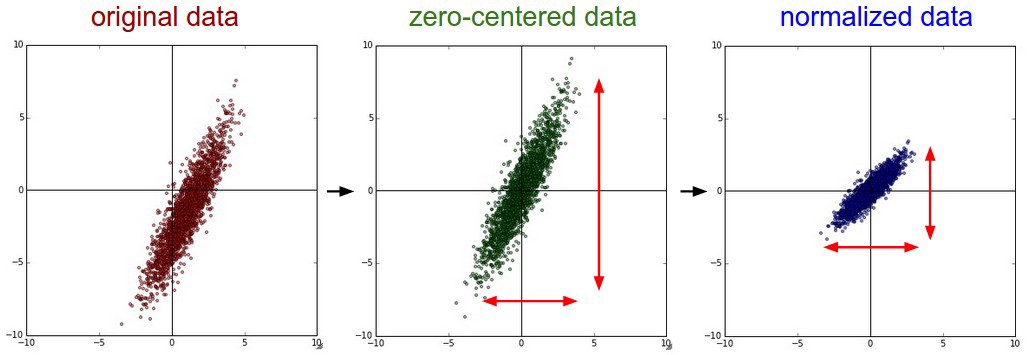
위와 같이 "zero-center→normalization"을 적용시켜주려면 아래와 같은 순서를 따르면 됩니다.
- Zero center: 모든 데이터들의 평균을 구한다 → 모든 데이터들 각각에 해당 평균 값을 빼준다.
- Normalization: 모들 데이터들의 표준편차를 구한다 → 모든 데이터들 각각에 해당 표준편차 값을 나눠준다.
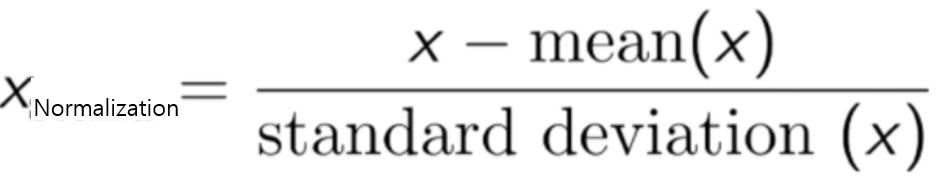
위와 같은 데이터 전처리를 이미지에 적용할 때, 가능한 2가지 경우의 수가 있습니다.
2-1) 하나의 이미지 데이터를 기반으로 normalization 적용하기
예를 들어, 224×224×3 이미지가 있다고 가정해보겠습니다. 하나의 pixel에는 0~255값들이 들어 있는데, 앞에서 언급한 이미지 크기를 기준으로 한다면 150528(=224×224×3) pixel들이 존재하게 됩니다.

즉, 하나의 이미지에 해당하는 고유의 평균 및 표준편차 값을 구할 수 있기 때문에, 하나의 데이터에만 normalization을 적용할 수 있게 됩니다. 예를 들어, 150528(=224×224×3) 개의 pixel값들을 기반으로 평균 및 표준편차 값을 구하고, 모든 pixel에 평균값을 빼준후 표준편차값을 나눠주게 됩니다.
Keras API에서 의 설명을 보면 알 수 있듯이, 하나의 이미지당 normalization을 적용시키려면 samplewise 속성을 이용하면 됩니다.
- samplewise_center: Boolean. Set each sample mean to 0.
- samplewise_std_normalization: Boolean. Divide each input by its std.
tf.keras.preprocessing.image.ImageDataGenerator(
samplewise_center=True,
samplewise_std_normalization=True
)
(↓↓↓Keras Image data Preprocessing API: ex) ImageDataGenerator↓↓↓)
https://keras.io/api/preprocessing/image/
Keras documentation: Image data preprocessing
Image data preprocessing image_dataset_from_directory function tf.keras.preprocessing.image_dataset_from_directory( directory, labels="inferred", label_mode="int", class_names=None, color_mode="rgb", batch_size=32, image_size=(256, 256), shuffle=True, seed
keras.io
2-2) 모든 이미지 데이터를 기반으로 normalization 적용하기
이번에는 하나의 이미지가 아닌 batch 단위로 묶인 이미지들을 기반으로 하여 해당 평균 및 표준편차 값을 구한 뒤, normalization을 적용 시키는 방식입니다. (사실, 전체 학습 이미지에 대한 평균 및 표준편차 값을 구하는건지 아닌지 모르겠으나 해당 API에서 "The data will be looped over (in batches)."라고 기술된 부분을 보고 'batch 단위로 평균 및 표준편차 값이 구해지겠구나'라고 추정했습니다. 혹시 아니면 알려주시면 감사하겠습니다)
예를 들어 batch가 4라고 하면, 224×224×3×4 개의 pixel값들을 기반으로 평균 및 표준편차 값을 구하고, 모든 pixel에 평균값을 빼준후 표준편차값을 나눠주게 됩니다.
Keras API에서 의 설명을 보면 알 수 있듯이, batch 이미지당 normalization을 적용시키려면 featurewise 속성을 이용하면 됩니다.
tf.keras.preprocessing.image.ImageDataGenerator(
featurewise_center=True,
featurewise_std_normalization=True
)- featurewise_center: Boolean. Set input mean to 0 over the dataset, feature-wise.
- featurewise_center: Boolean. Set input mean to 0 over the dataset, feature-wise.
아래 API를 보면 featurewise와 samplewise 관련 속성은 모두 False로 적용되어 있는걸 확인할 수 있다.
(↓↓↓Tensorflow 2 API 에서 ImageDataGenerator ↓↓↓)
https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/image/ImageDataGenerator
tf.keras.preprocessing.image.ImageDataGenerator
Generate batches of tensor image data with real-time data augmentation.
www.tensorflow.org

Q. DNN에서 봤을 때는 이러한 것이 많은 도움이 되는걸 이론적으로 확인할 수 있습니다. 그런데, 개인적으로 pytorch 기반으로 작성하여 CNN에 적용시켰을 때는 적용을 하나 안하나 큰 차이가 없었던 것 같습니다. 다른 분야에서는 어떻게 적용하고 있는지 궁금하네요.
3. Data augmentation
CNN은 굉장히 다양한 data augmentation 기법을 지원합니다.
따라서 분류하려는 대상에 따라 적절한 data augmentation 기법을 적용시키면 됩니다.
예를 들어, Chest X-ray 같은 경우는 90도 rotation 해서 evaluation 하는 경우는 없으니, 90도 rotation은 적용시키지 않아도 되겠죠?
아래 코드에서 rescale은 overfitting을 방지하고자 모든 pixel 값들을 0~1 범위로 normalization 해주는 것인데, 앞서 "2. Preprocessing (Normalization)"에서 언급한 것과 같은 목적으로 적용된 것이라 생각하시면 될 것 같습니다.
tf.keras.preprocessing.image.ImageDataGenerator(
featurewise_center=True,
featurewise_std_normalization=True,
zca_whitening=False,
zca_epsilon=1e-06,
rotation_range=0,
width_shift_range=0.0,
height_shift_range=0.0,
brightness_range=None,
shear_range=0.0,
zoom_range=0.0,
channel_shift_range=0.0,
fill_mode="nearest",
cval=0.0,
horizontal_flip=False,
vertical_flip=False,
rescale=1./255
)
(↓↓↓위에서 언급한 data augmentation 중 몇 가지 예시↓↓↓)
https://theailearner.com/2019/07/06/data-augmentation-with-keras-imagedatagenerator/
Data Augmentation with Keras ImageDataGenerator
One of the methods to prevent overfitting is to have more data. By this, our model will be exposed to more aspects of data and thus will generalize better. To get more data, either you manually col…
theailearner.com
Q. rescaling=./255를 먼저 해주고, feature_wise or sample_wise같은 normalization을 적용을 해주는건지, 아니면 그 반대순서로 적용을 해주는건지 모르겠네요....
4. 총정리: Data Load
지금까지 배운 내용을 토대로 data load 코드를 작성하면 아래와 같습니다.
import os
from tensorflow import keras
from tensorflow.keras.preprocessing.image import ImageDataGenerator
base_dir = './datasets/cats_and_dogs/'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
train_datagen = ImageDataGenerator(
featurewise_center=True,
featurewise_std_normalization=True,
rescale=1./255,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
validation_split=0.2)
validation_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 타깃 디렉터리
train_dir,
# 모든 이미지를 150 × 150 크기로 바꿉니다
target_size=(150, 150),
batch_size=32,
# binary_crossentropy 손실을 사용하기 때문에 이진 레이블이 필요합니다
class_mode='binary') #cats_and_dogs는 2개의 클래스만 있음
validation_generator = validation_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
위와 같이 코드를 세팅해주면 학습을 시켜주기 위한 data loader 과정이 마무리 됩니다.
이후 아래 코드를 실행시켜주면 학습이 진행됩니다.
아래 코드는 다음 글에서 설명하도록 하겠습니다.
from tensorflow.keras import layers
from tensorflow.keras import models
from tensorflow.keras import optimizers
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['accuracy'])
※보통 cifar10, mnist, fashion mnist와 같은 적은 양의 데이터셋은 아래 링크에 기재된 tensorflow.keras.datasets 에서 제공을 해줍니다. 하지만, ImageNet 같은 경우는 데이터양이 워낙 방대하여 직접다운로드 받고 학습을 위한 구조를 세팅해주고 학습시켜야 한다는점 알아두시면 좋을것 같습니다!
https://www.tensorflow.org/api_docs/python/tf/keras/datasets
Module: tf.keras.datasets | TensorFlow Core v2.5.0
Small NumPy datasets for debugging/testing.
www.tensorflow.org
'Tensorflow > 2.CNN' 카테고리의 다른 글
| 5.Pre-trained model 불러오기 (feat. Transfer Learning and .h5 파일) (0) | 2021.06.30 |
|---|---|
| 4. 평가지표(Metrics ) visualization (0) | 2021.06.29 |
| 3.CNN 모델의 loss function 및 optimizer 설정 (0) | 2021.06.29 |
| 2.CNN 모델 구현 (Feat. Sequential or Function API) (0) | 2021.06.29 |
| 코드참고 사이트 (0) | 2021.06.28 |