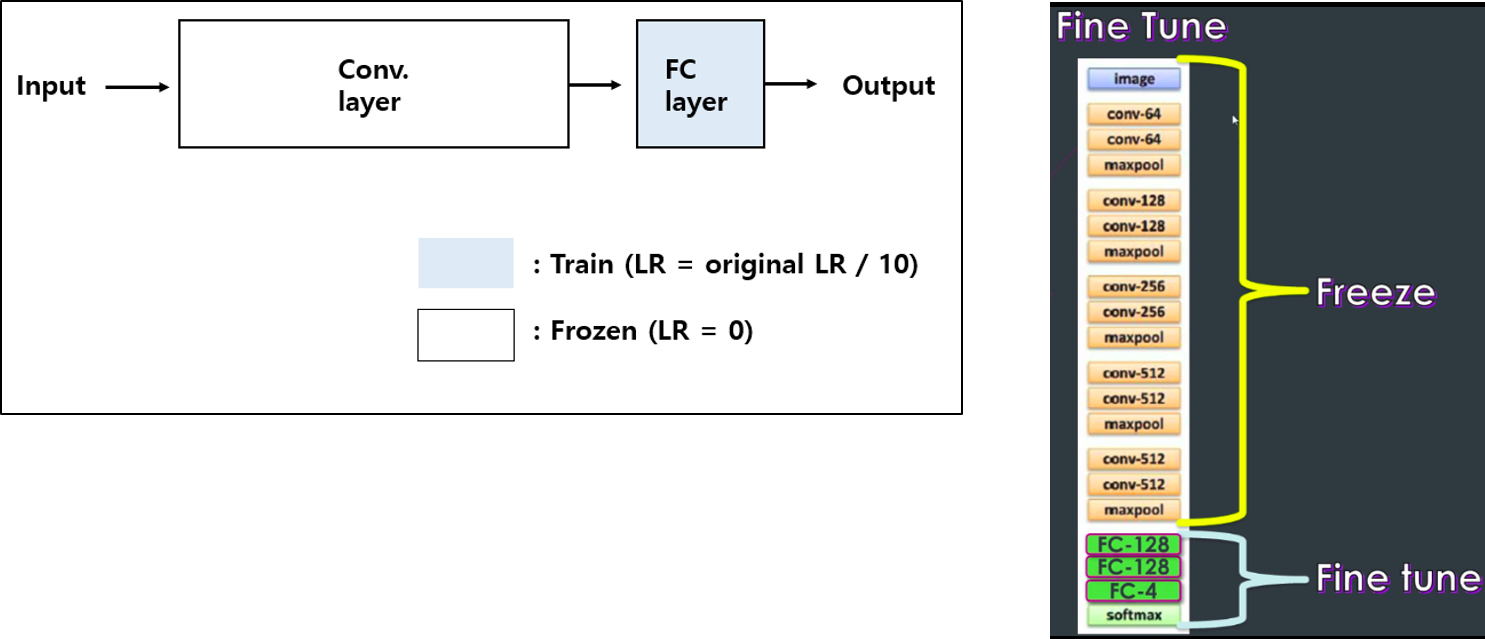
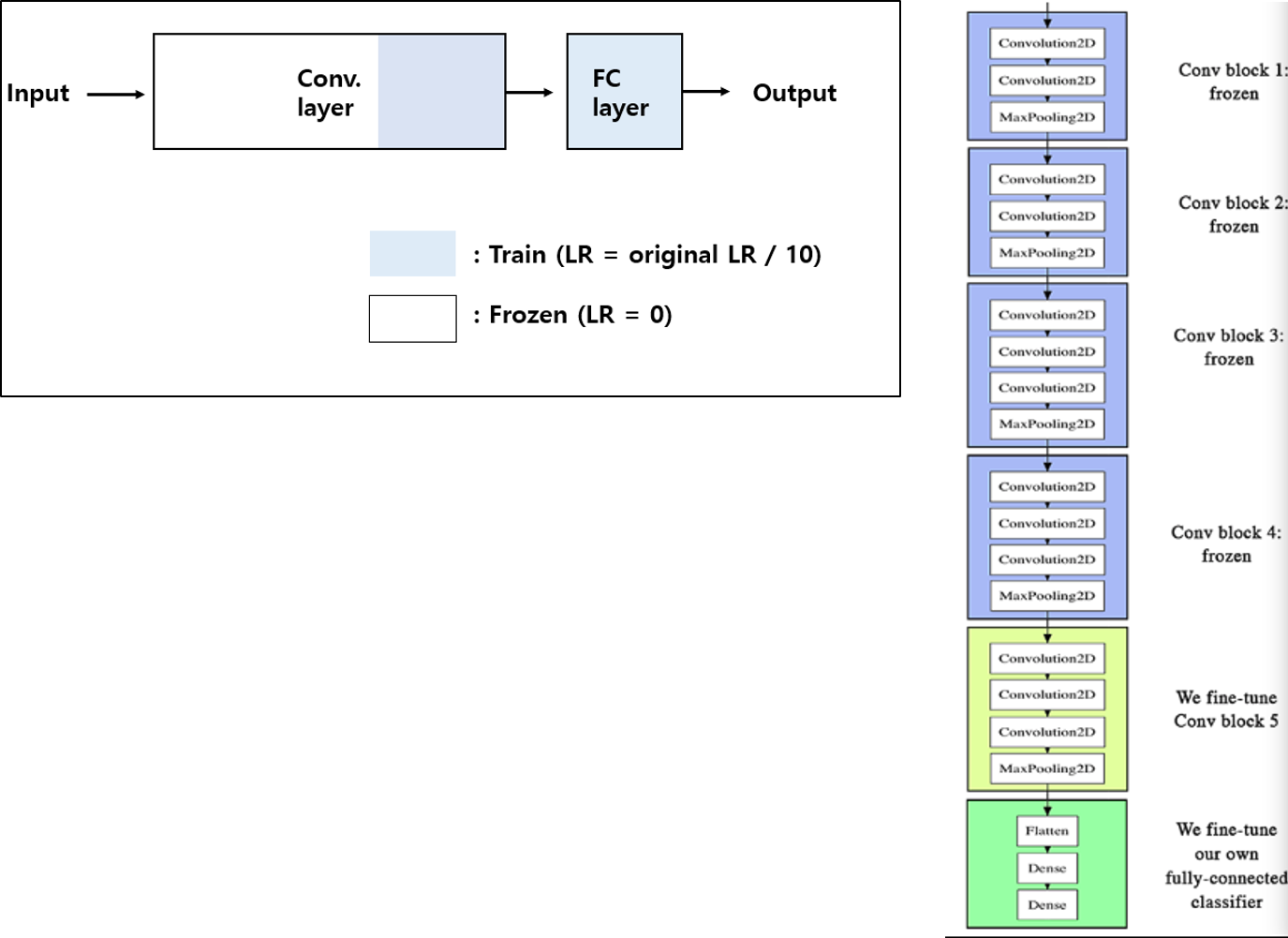
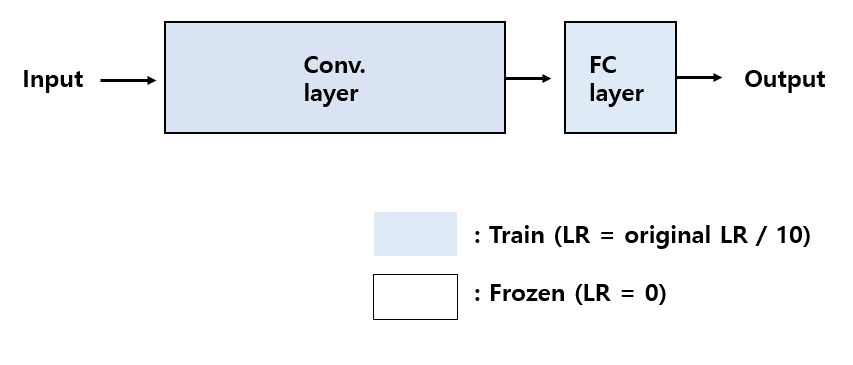
안녕하세요~
이번시간에는 아나콘다를 통해 2개의 가상환경을 만들고 각각의 가상환경에서 pytorch, tensorflow를 설치하는법을 배워볼거에요~
Pytorch: Python 3.7버전/ CUDA 10.1 버전/ Pytorch=1.4버전
Tensorflow: Python 3.6버전/ CUDA 9.0 버전/ cuDNN 7.6버전/ Tesorflow GPU=1.8 버전
<1. Pytorch 가상환경>
1) Pytorch 가상환경 생성 (Python=3.7 버전)

2) 가상환경에 conda 패키지 설치 (이 작업을 하지 않으면 나중에 CUDA 설치할때 에러가 나더라구요)

3) CUDA=10.1, Pytorch=1.4 버전 설치
conda install pytorch==1.4 torchvision cudatoolkit=10.1 -c pytorch
(예전 버전 설치하려면 아래 페이지참고)
https://pytorch.org/get-started/previous-versions/

위의 명령어를 입력하면 아래와 같이 pytorch를 위한 패키지들이 설치될거에요.

4) 그외 추가적으로 아나콘다 패키지들을 설치해줍니다. 딥러닝을 할때 Pytorch에서 제공해주는 패키지 말고도 아나콘다에서 제공하는 패키지들을 쓰는 경우가 많기 때문에 '아나콘다 패키지'를 설치해주는거에요.

아래 데이터 사이언스에서 자주 쓰이는 pandas라는 패키지가 추가로 설치되는게 보이네요.

5) Pytorch 실행
- Pytorch 가 제대로 설치되어 있는지 확인 --> import torch
- 그외 cuda, cudnn 설치가 제대로 됐는지 확인 (pytorch 설치할때 cudnn을 따로 설치하지 않아도 cuda 버전에 맞는 cudnn이 자동적으로 설치되는거 같아요. 자세한건 아니지만요;; ㅎㅎ)

##############################################################################
<2. Pytorch 가상환경과 Pycharm 연동>
일반적으로 IDE 툴(ex: Pycharm)을 이용해서 개발을 많이 하시죠?
그런데 pytorch 가상환경 공간에서 pycharm과 같은 툴을 이용하려면 interpreter를 setting해주어야해요 (interpreter에 대한 설명은 따로 하지 않을게요~ )
1) 먼저 project 파일 만들어주기

2) File -> Setting

3) Project:CNN -> Project Interpreter -> 톱니바퀴 아이콘 클릭!

4) 톱니바퀴 모양 아이콘 클릭하고, show all 클릭!

5) '+' 아이콘 클릭

6) 자신의 가상환경 경로가 어디있는지 확인후 아래와 같이 설정해주고 'ok'버튼 클릭

(참고로 제 가상환경 경로는 아래와 같이 숨긴 폴더에 있었어요~)

7) 생성된 pytorch 가상환경 interpreter 선택및 ok 버튼 클릭

8) 아래 네모박스 부분이 현재 setting 중이라는 의미이며, 없어질때까지 기다렸다가

다 없어지면 'Apply' -> 'Ok' 순으로 클릭

9) 아래 네모박스 부분은 progress bar를 의미하며 현재 pytorch 가상환경의 interpreter가 setting 중이라는 의미이기 때문에 없어질때까지 대기

10) python 파일 생성 후, pytorch 기본 코드 작성
아래와 같이 정상적으로 출력이 된다면 끝!

##############################################################################
<3. Tensorflow 설치하기>
1) Tensorflow gpu 버전을 아래와 같이 설치해주셔도되고 "conda install tensorflow-gpu"라고 해주시면 최신버전이 설치됩니다. 이때 설치되는 패키지 목록을 보시면 CUDA, cuDNN 모두 설치되기 때문에 따로 CUDA, cuDNN을 설치해줄 필요가 없어요!!!
[Note]
참고로 "conda install tensorflow" 처럼 gpu 버전이 아닌 tensorflow를 미리 설치하셨거나 추후에 설치되어 있으면 "conda uninstall tensorflow" 해주시고, tensorflow-gpu 버전을 따로 설치하세요. 왜냐하면 종종 tensorflow 패키지가 tensorflow-gpu 패키지를 override하여 tensorflow-gpu 패키지를 이용못하게 하는경우가 생기기 때문이에요!!!

2) CUDA 9.0 버전 설치
Note: 만약 CUDA 버전을 manually 설정해주고 싶은경우 아래와 같이 패키지를 설치해주시면되요!
conda install -c anaconda cudatoolkit=9.0

3) cuDNN 7.6 버전 설치
Note: 만약 CUDA 버전을 manually 설정해주고 싶은경우 아래와 같이 패키지를 설치해주시면되요!
conda install -c anaconda cudnn=7.6

4) Tensorflow 설치 되었는지 python을 통해 확인

5) Tensorflow GPU 확인 및 경고메시지 해결
Tensorflow GPU가 제대로 설치되어있는지 보려면 아래 그림과 같은 코드를 넣어주면되요.
import tensorflow as tf
s = tf.constant("hello")
sess=tf.Session()
그럼 GPU 정보들이 출력될거에요 (출력된 메시지에 device:GPU:0 이라고 되어있는데, GPU가 없다는 뜻이 아니라 0번째 GPU에 할당되어 있다는 뜻이에요. 컴퓨터에 GPU를 여러개 설치해서 쓰시는 경우가 있으신데 이때 GPU 순서가 0, 1, 2 순서로 진행되요)
가끔 패키지가 여러개 깔리다 보면 최신버전의 패키지들이 설치되는 경우가 많아요. 그래서 아래와 같은 경고창이 뜨기도 합니다.
conda\envs\tensorflow\lib\site-packages\tensorflow\python\framework\dtypes.py:519: FutureWarning: Passing (type, 1)
위와 같은 메시지는 자세히 보면 numpy 버전이 현재 tensorflow 1.8버전이 요구하는것 보다 더 높다고 경고메시지를 띄우고 있어요. 그래서 자신들이 높은 버전의 numpy 패키지를 낮은 버전의 numpy 패키지로 중간중간 코드를 변경하겠다는 메시지를 띄운거에요. 사실 경고메시지로 굳이 따로 신경쓰실 필요는 없는데 그래도 거슬린다고 하신다면

아래와 같이 numpy 버전을 낮춰주시고

다시 아래와 같이 같은 코드를 입력해주시면 문제없이 출력되는걸 알 수 있어요.

8) 아나콘다 가상환경에서 tensorflow version upgrade하기
기존에 1.8 버전이 설치되어 있으다면

아래와 같이 2.0 버전으로 upgrade할 수 있습니다.


<4. VS code IDE를 아나콘다와 연동하기>
step1. VS code IDE 다운받기

step2. VS code IDE 설치해주기

Step3. VS code IDE 실행하기

Step4. Python 플러그인 Extension(확장)하기
이 플러그인을 통해, python interpreter, jupyter notebook, ipynb(주피터 확장자)와 py(파이썬 확장자)간의 자동코드변환 등을 할 수 있게됨

Step5. VS code IDE와 아나콘다 연동해주기
①ctrl+shift+p

②"python: select Interpreter" 클릭

③아나콘다에서 자신이 사용하는 tensorflow2 패키지 경로 확인후 (위에서 설치한 가상환경은 tensorflow 가상환경이지만, 저는 tensorflow2라는 가상환경을 하나 더 만들어준 후 VS code IDE 예제에 적용시켰습니다. 혼동하지마세요!)

④해당되는 경로 클릭

Step5. 작업공간 만들어주기
①바탕화면에 DL_project 폴더 생성해주기

②Open Folder 클릭 후, DL_project 경로 선택


Step7. 'test.ipynb' 파일 생성해주기
:ipynb 파일로 만드는 이유는 jupyter notebook 환경으로 코드를 작성하기 위함

파일 생성시, 아래 밑줄친 파일 클릭해야 주피터 실행화면이 생성됨

Step8-1. ipykernel 설치 (첫 번째 방법)
아래와 같이 'import tensorflow as tf'를 입력하고 실행('shift+enter')시키면 아래메시지 ("Data Science library ipykernel is not installed, install?")가 생성됨 --> yes 클릭


아래 코드가 실행되면 정상적으로 환경이 setting된 것!
(혹시 에러가 나는경우에는 조금 기다리시거나, VS code IDE를 재실행 해보시길 권장드립니다)

Step8-2. ipykernel 설치 (두 번째 방법)
"Step8-1. ipykernel 설치 (첫 번째 방법)"에서 설치 후, 코드가 정상적으로 동작하면 "Step8-2"는 무시해주세요!!
①anaconda prompot에서 해당 가상환경을 activate해준 후, ipykernel 설치해주기

②설치 완료 후, VS code "재실행" 해주고 아래 코드 실행하기
지금까지 가상환경을 설치하고 IDE 툴과 연동하는 방법들에 대해서 알아보았습니다!
[참고 사이트]
https://zereight.tistory.com/224
https://discuss.pytorch.org/t/cudatoolkit-9-2-unavailable/60488
https://gldmg.tistory.com/73