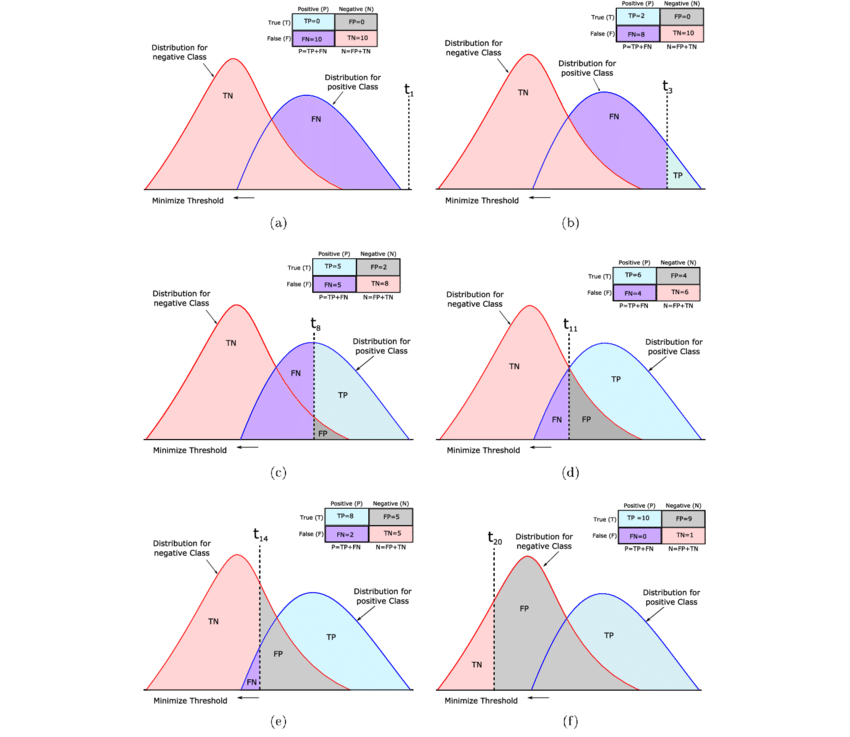
안녕하세요.
이번 글에서는 2D 이미지로 사용되는 대표적인 영상이미지인 X-ray와 CT에 대해서 알아보도록 하겠습니다.
먼저, X-ray, CT에 대해 간단히 알아본 후, 2D 영상 이미지에서 사용되는 전처리 기법에는 어떤 종류들이 있는지 알아보도록 하겠습니다.
아래 영상을 미리 한 번 보시면 글을 읽기 수월 하실 거에요!
(↓↓↓의료 이미지, X-ray, CT, MRI에 대한 간단한 설명↓↓↓)
https://www.youtube.com/watch?v=wbqeIpigxfs
※Medical Imaging이라는 수업에서는 이러한 기기들의 물리적인 작동 방식에 대해서 설명하고 있으나, 여기에서는 단순히 기계의 작동원리나 어떻게 이미지들이 생성되는지만 간단히 알아보도록 하겠습니다.
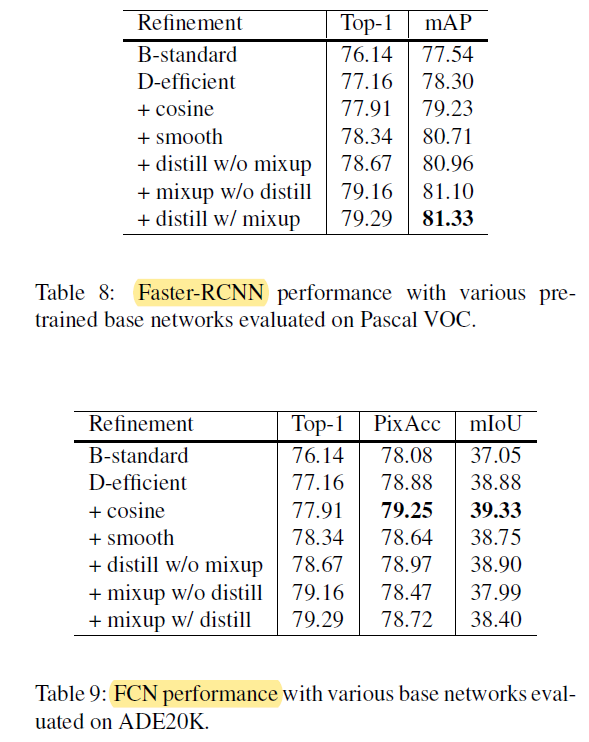
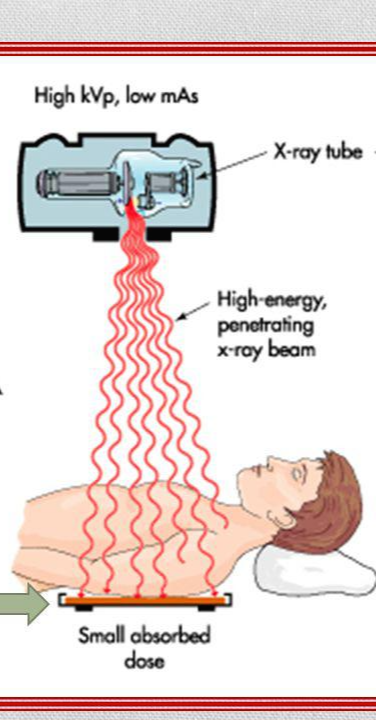
1. X-ray 이미지 (Feat. Digital detector)
X-ray를 이용해 병변을 분류하는 과정은 아래와 같습니다.
1) X-ray generator에서 방사선 발사
2) 발사된 방사선이 Object(사람 또는 다른 객체)에 투과
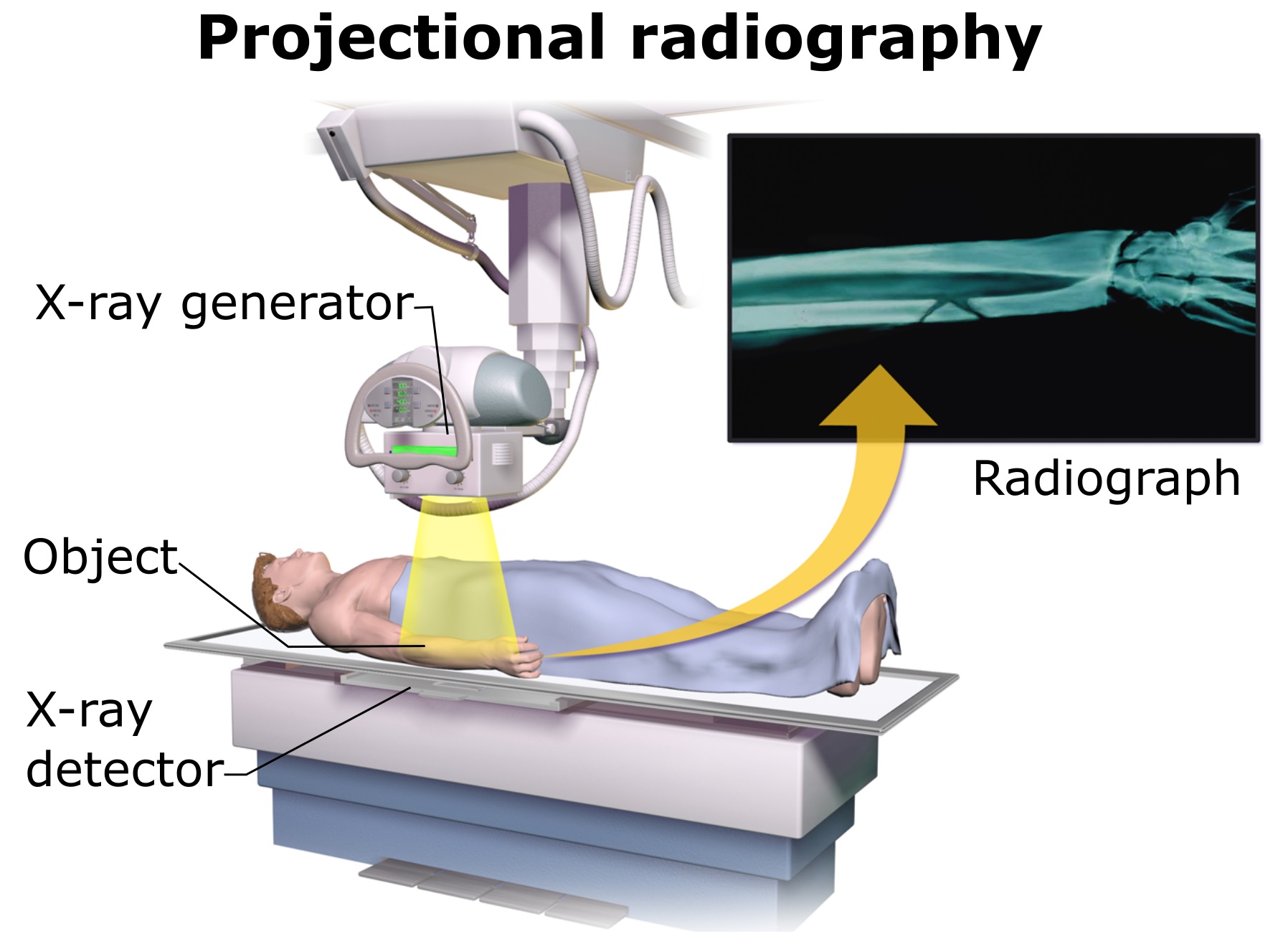
3) 사람 내부 인체 조직에 따라 X-ray detector에 있는 image receptor에 투과되는 방서선 양이 다름
| Symptom | Color |
| Black | Air |
| Dark gray | Fat |
| Light gray | Soft tissues ex) Water |
| White | Calcification ex) bone |
| Whiter | Metal |
4) 투과된 방사선량에 따른 병변 분류
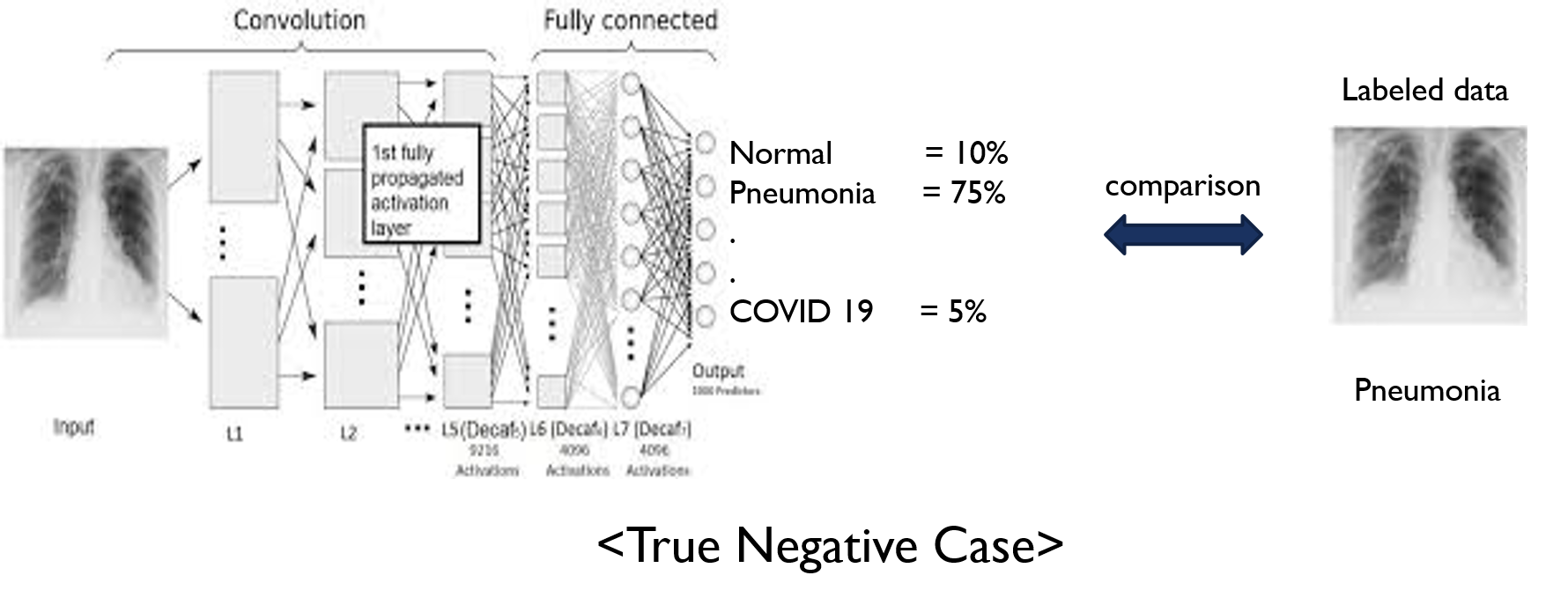
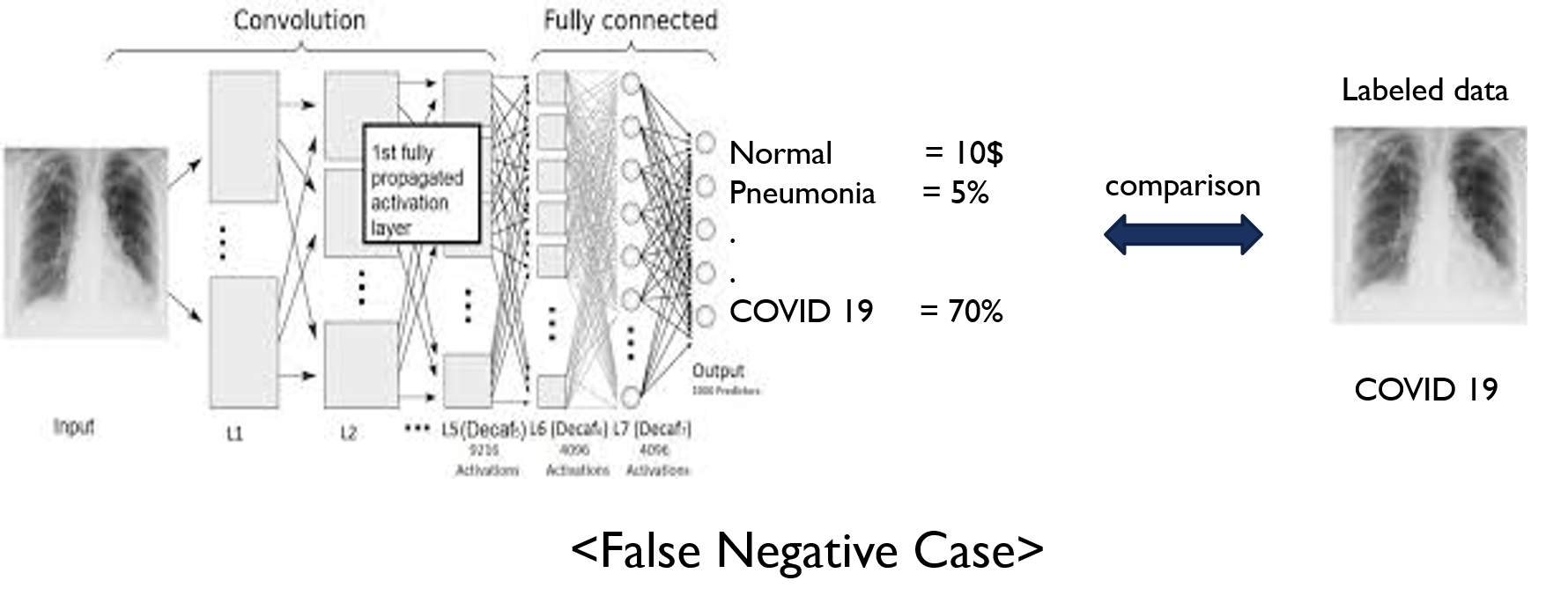
- 예를 들어, X-ray를 기반으로 폐렴(pneumonia)을 분류한다고 해보겠습니다.
- 보통 폐렴같은 경우는 X-ray 장비로도 진단을 합니다.
- 폐렴이 의심되는 환자를 촬영할 땐, image Receptor를 가슴 쪽에 두고 사진을 찍게 되죠. 보통 이러한 사진을 Chest-Xray라고 합니다.
- 폐는 사람의 호흡과 관련된 기관입니다. 폐를 구성하는 것 중하나는 폐포(alveoli)인데, 여기에서 혈액과 가스의 교환이 이루어집니다.
- 폐렴(Pneumonia)은 공기 중에 떠다니는 있는 세균, 곰팡이 및 바이러스가 체내에 흡입되고 폐포(pulmonary alveoli)에 안착한 후 염증을 일으키면서 발생합니다. 이 과정을 통해 다양한 호흡기 질환으로 합병증이 나타나고 폐 전체에 염증을 일으켜 심각한 결과를 초래하게 됩니다.
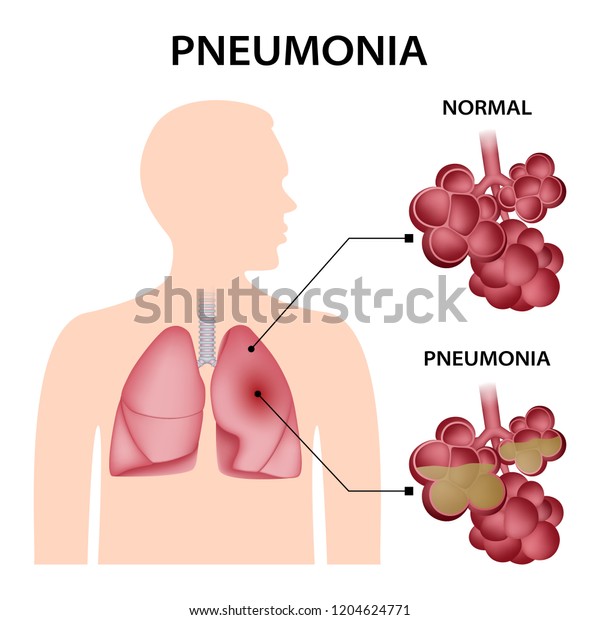
- 정상적인 폐포의 내부는 기체로 이뤄진 상태이지만 폐렴으로 인해 손상된 폐포에는 염증이 있어 액체 물질로 가득 차 있습니다.
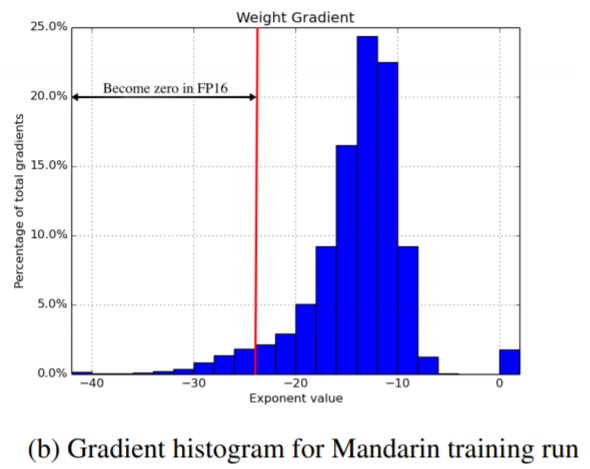
- 본래 폐포는 공기(기체) 상태인데, 폐렴으로 인해 액체가 폐포에 가득해지면 X-ray 촬영 시, 아래와 같이 X-ray 이미지가 나오게 됩니다. (왼쪽 이미지: 정상(normal), 오른쪽 이미지: 폐렴(pneumonia))
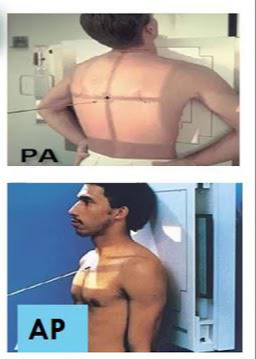
[Q. X-ray 이미지에서 AP, PA는 무엇을 의미하나요?]
Chest X-ray (CXR)를 찍을 때 찍는 방향에 따라 AP(Anterior-Posterior)와 PA(Posterior-Anterior)로 나눌 수 있습니다.
Chest X-ray의 경우 찍는 방향에 따라 나오는 X-ray 이미지 상태가 다릅니다.
보통, AP 방식으로 찍기보다 PA 방식을 찍는데 그 이유는 아래와 같습니다.
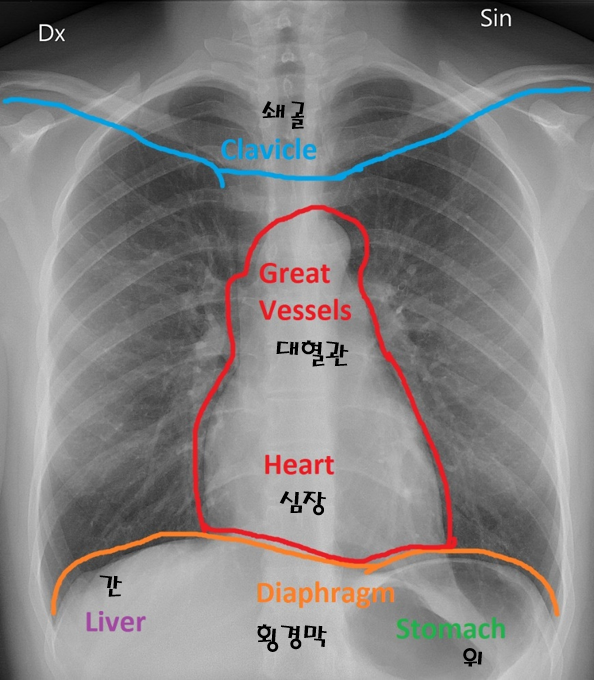
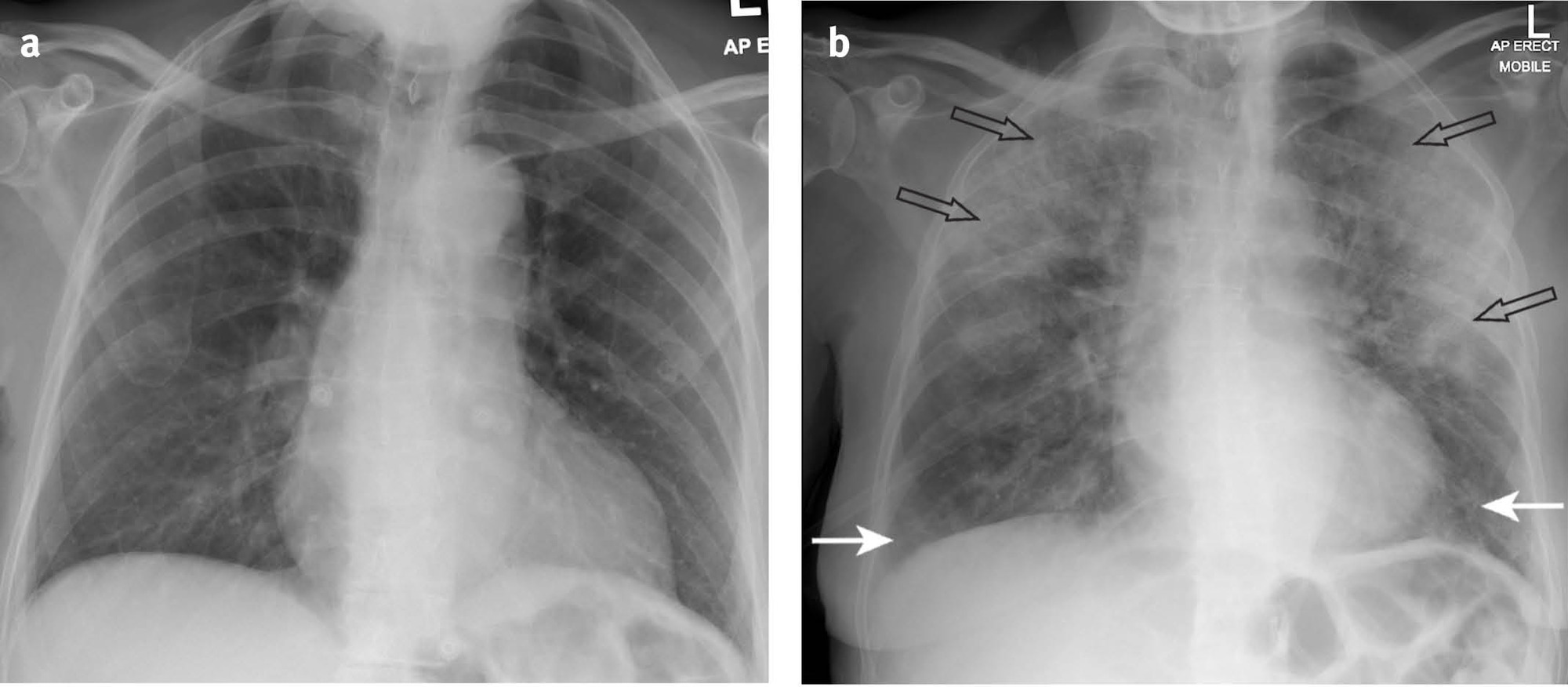
- AP view: 심장이 확대되어 보이며, 견갑골에 의해 폐야가 많이 가려지며, 횡경(Diaphragm)막이 높이 올라가 있어 폐가 좁게 나타남
- 따라서 COVID-19 선별진료소와 같이 Chest AP에서 얻은 CXR 이미지는 폐 병변을 보기에는 사실 썩 좋지 않은 경우가 꽤 있다. (Dataset 수집할 때 이러한 부분도 고려하면 좋을 듯)

- 위의 그림을 보면 같은 환자인데 Chest AP에서는 심장 size도 크고 그리고 견갑골에 의해서 폐야도 많이 가려지는 형태고 그 다음에 diaphragm도 많이 올라와 있기 때문에 PA와 비교했을 때 상당히 폐야가 좁고, 굉장히 내부의 vessel도 굉장히 engorgement(폐에서의 염증성 충혈)되어 보이는 경우가 많습니다.
- 이러한 경우, GGO 병변을 딱히 구분할 수 없거나 잘 안보이는 경우가 생길 수 도 있습니다. → 참고로 GGO는 COVID-19에서 발견되는 주요 소견 중 하나입니다.
- 또한, Chest X-ray는 누워서 찍기보단 서서 찍는 것이 좋습니다.
- 아래의 환자는 effusion이 있던 환자인데, chest AP 를 누워서 찍으니까 effusion이 전부 뒤로 깔려서 폐 병변을 보기가 상당히 어렵게 됐습니다. 가끔 chest X-ray 데이터셋을 보면 저런 경우를 종종 볼 수 있는데 이런 경우 effusion이 있는 환자가 누워서 찍은건 아닌지 고려한 후 데이터셋을 제거하는 것이 필요할 듯 보입니다.

(↓↓↓AP, PA에 대한 자세한 설명은 아래 사이트를 참고해주세요↓↓↓)
https://www.radiologymasterclass.co.uk/tutorials/chest/chest_quality/chest_xray_quality_projection
Chest X-ray Quality - Projection
Key points Posterior-Anterior (PA) is the standard projectionPA projection is not always possibleBoth PA and AP views are viewed as if looking at the patient from the frontPA views are of higher quality and more accurately assess heart size than AP imagesI
www.radiologymasterclass.co.uk
2. CT 이미지
(↓↓↓CT 가 탄생한 이유↓↓↓)
X-ray 이미지는 2D로 볼 수 있는 반면, CT는 X-ray generator(source)가 여러 측면에서 촬영하기 때문에 2D 이미지와, 회전을 통해 얻은 이미지들을 이용 (by interpolation ← 몰라도 될 것 같습니다 ㅎ;;) 해 3D 이미지를 얻기도 합니다.
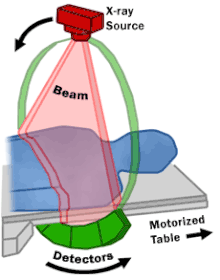
아래 gif 이미지에서 보이는바와 같이 CT를 촬영하게 되면 360도 촬영을 하게 됩니다.

위와 같이 촬영을 하면 아래와 같은 축으로 여러 이미지가 나올 수 있죠.
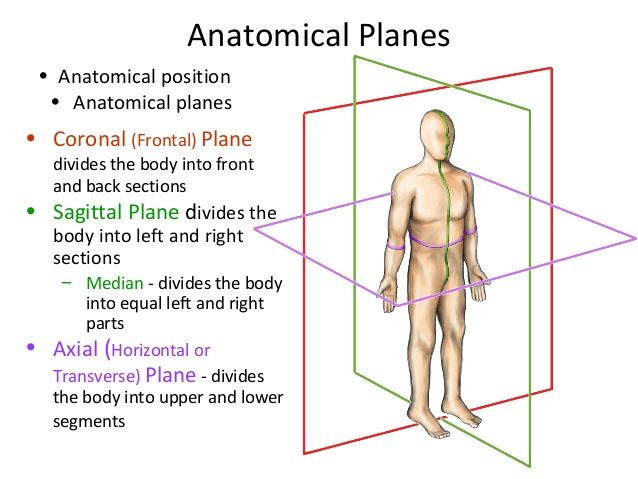
위의 이미지에 해당하는 축(axis) 마다 다른 형태의 CT 이미지를 출력하게 됩니다.
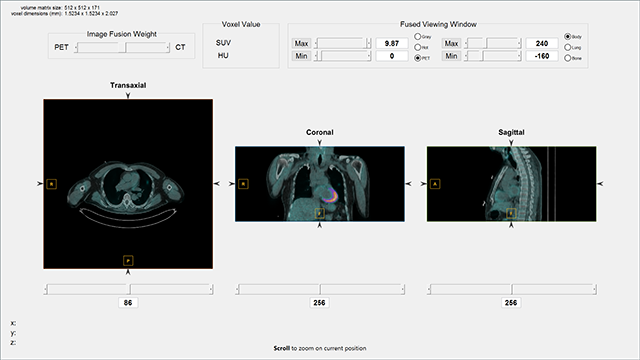
COVID-19 데이터 셋을 보면 대부분 Trans-axial(=Transverse)에 해당 하는 축의 이미지들로 구성되어 있습니다.
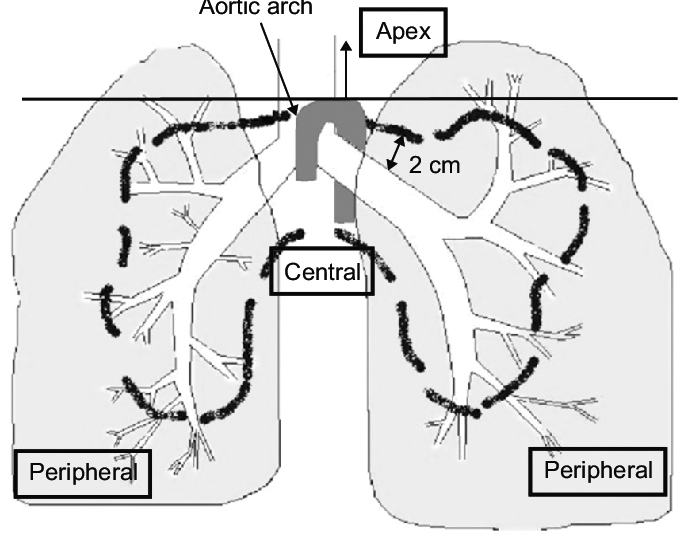
폐 위치 관련한 용어를 잠시 보여드리면 아래와 같습니다.
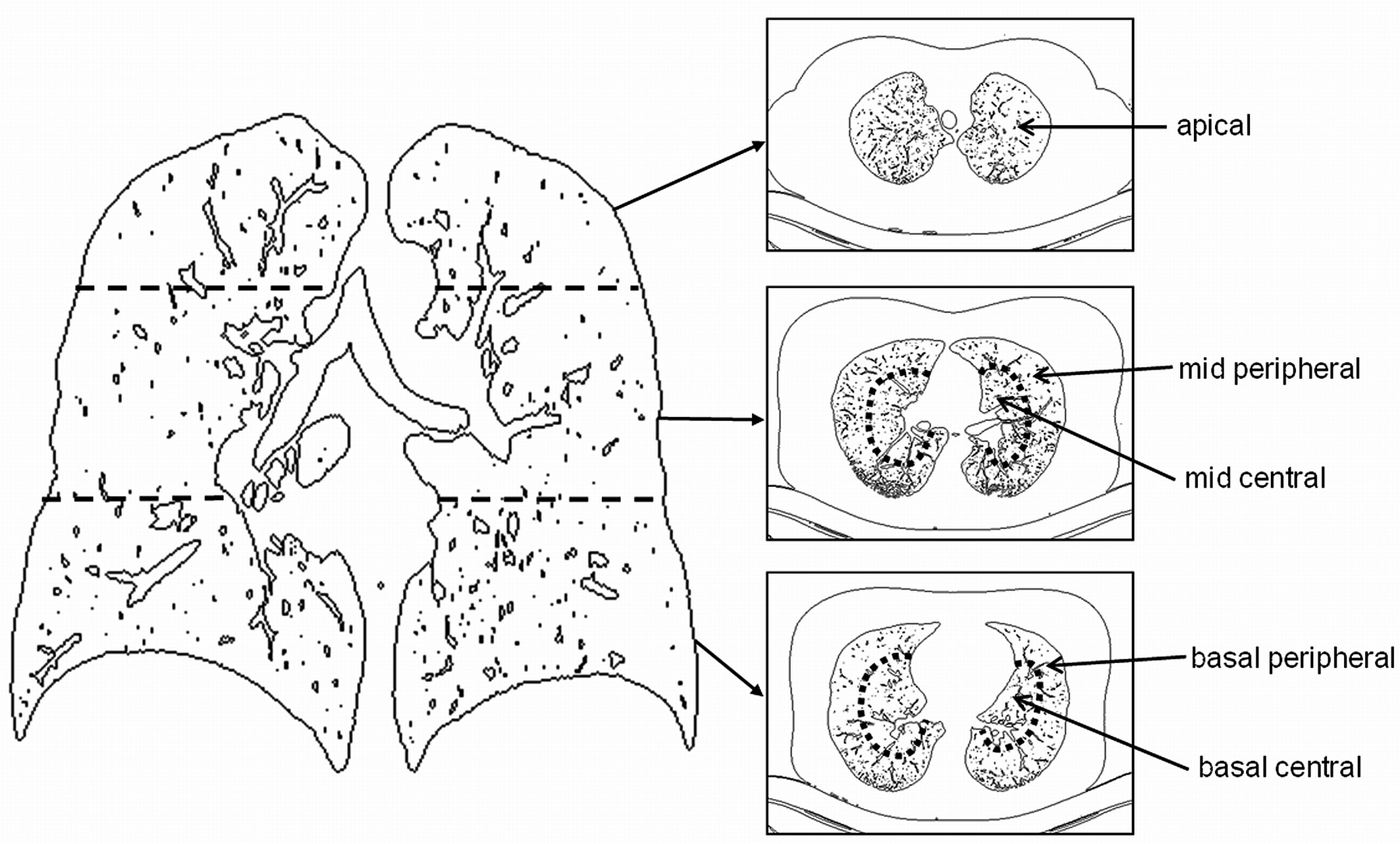
(↓↓↓CT 이미지 읽는 장면 아래 영상에서 3:29~3:38 참고↓↓↓)
https://www.youtube.com/watch?v=P6nweaRTiLs
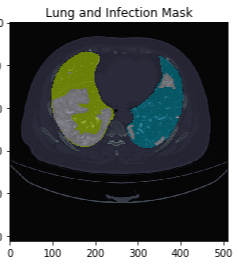
아래 사진을보면 정상인, 폐렴, COVID-19 의 폐 CT 사진입니다.
아래 사진을 기반으로 하면 다음과 같이 해부학적으로 병변을 분류할 수 있겠죠.
- Normal: 깨끗함
- Pneumonia: 광범위하게 GGO(Ground Glass Opacity)가 퍼져있음
- COVID-19: peripheral부분에 GGO가 위치하기도 하며, 진행단계에 따라 GGO 정도가 심해지는 consolidation 현상도 볼 수 있습니다.
※ 물론 이것은 아래 사진만 살펴본 예입니다. 실제로 폐렴(pneumonia)은 그 종류가 다양하기 때문에, CT 상에서 보여지는 특징도 굉장히 다양합니다.

3. X-ray, CT 이미지 전처리하기 (Feat. 히스토그램)
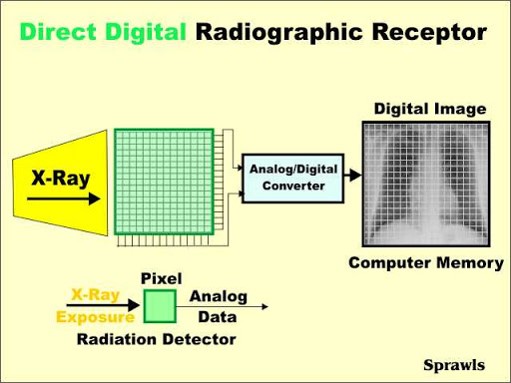
전통적으로 사용되는 X-ray 이미지 같은 경우는 앞서 설명한 것처럼 image receptor에 투과된 방사선 양을 토대로 보여지게 됩니다.
예전에는 이미지를 필름에 찍어내는 방식을 이용한 X-Ray 검사를 많이 진행했지만,
몇년 전부터는 해당 방사선 양을 직접 전송해 영상화하는 Digital Radiography (DR)을 많이 사용하고 있다고 합니다.
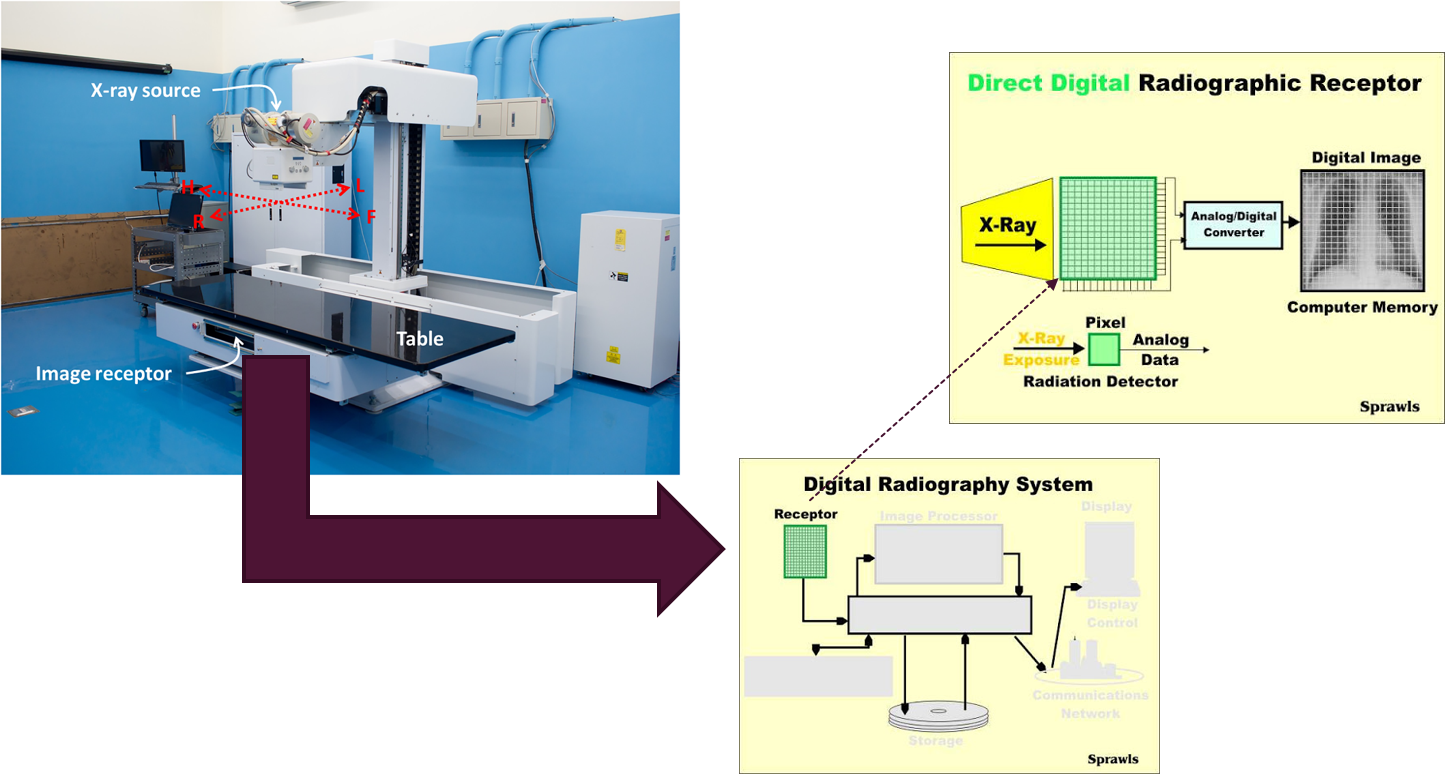
좀 더 구체적으로 설명하자면 아래와 같습니다.
- receptor는 N×N grid 형태로 있습니다.
- 각각의 위치는 하나의 pixel이 됩니다.
- receptor에 exposure된 방사선 양은 analog/digital converter에 의해 픽셀 값을 갖는 digtal image로 변환됩니다.
1) Histogram analysis
히스토그램의 여러 어원 중 하나는
'똑바로 선 것'이라는 뜻을 가진 histos에 '그림'을 뜻하는 gram이 합쳐진 합성어라고 합니다.
풀어설명하면 '똑바로 선 막대 그림'이라는 뜻으로 사용되기도 합니다.
수학에서 히스토그램은 표로 되어 있는 도수 분포표를 정보 그림으로 나타낸 것입니다.
그렇다면 이미지에서 히스토그램은 무엇을 의미할까요?
쉽게 말하자면 이미지 상에 나타난 색상 값들을 도수분포표로 나타낸 것이라고 볼 수 있습니다.
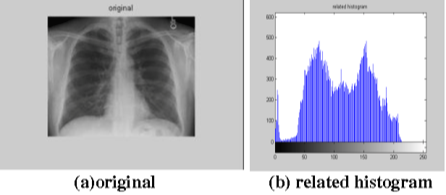
예를 들어, 흑백 이미지에 대한 히스토그램은 아래와 같이 표현 할 수 있습니다.
- (a) 이미지는 흑백 이기 때문에 X축은 pixel 값 범위 "0~255"로 표현할 수 있습니다.
- 해당 픽셀 값들이 얼마나 많은지 도수분포표를 통해 나타내면 그것이 이미지 히스토그램입니다.
2) X-ray 이미지 전처리(preprocessing) 기법들
2-1) HEQ (Histogram EQualization)
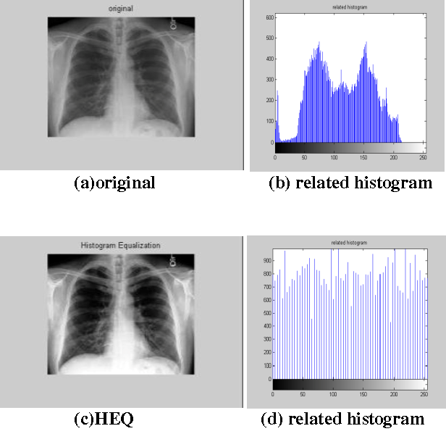
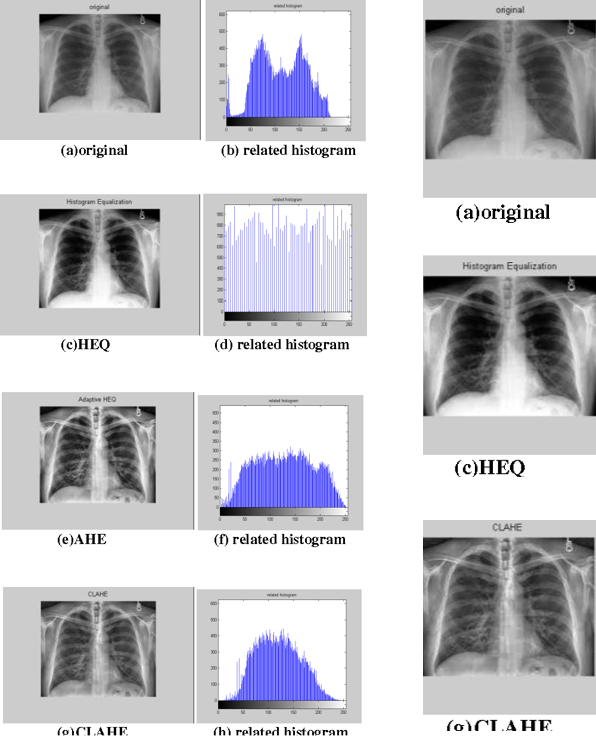
몇몇 “Original(원본)" 이미지는 contrast 가 매우 떨어지는 경우가 있습니다.
즉, 이미지 픽셀이 0~255에 고르게 퍼져있는 게 아니라, 일부분에 몰려있다는 것을 확인할 수 있죠.
아래 그림을 기준으로 설명하면, "Original" 이미지(→(a) 이미지)에 "Histogram Equalization“ 기법을 적용시킬(→(c) 이미지) 때, 이미지의 contrast 가 증가한 것을 확인할 수 있습니다.
"Histogram equalization (HEQ) is a digital image processing technique used for contrast enhancement across a number of modalities in radiology."
HEQ에 대한 수식은 아래와 같습니다.
수식에 대한 직관적인 설명은 여기링크를 참고해주세요!

(↓↓↓HEQ Open CV 함수↓↓↓)
https://docs.opencv.org/3.4/d4/d1b/tutorial_histogram_equalization.html
OpenCV: Histogram Equalization
Prev Tutorial: Affine Transformations Next Tutorial: Histogram Calculation Goal In this tutorial you will learn: What an image histogram is and why it is useful To equalize histograms of images by using the OpenCV function cv::equalizeHist Theory What is a
docs.opencv.org
(↓↓↓HEQ pytorch 함수↓↓↓)
https://pytorch.org/vision/stable/transforms.html
torchvision.transforms — Torchvision master documentation
torchvision.transforms Transforms are common image transformations. They can be chained together using Compose. Additionally, there is the torchvision.transforms.functional module. Functional transforms give fine-grained control over the transformations. T
pytorch.org
2-2) AHE (Adaptive Histogram Equalization)
2-3) N-CLAHE (Contrast Limited Adaptive Histogram Equalization)
AHE와 N-CLAHE에 대한 설명은 아래 블로그를 참고하시는게 도움이 되실 것 같아, 따로 설명은 하지 않고 관련 링크를 걸어두도록 하겠습니다.
https://3months.tistory.com/407
Adaptive Histogram Equalization 이란 무엇인가?
Adaptive Histogram Equalization 이란 무엇인가? Adaptive Histogram Equalization (AHE) 이란 이미지 전처리 기법으로 이미지의 contrast 를 늘리는 방법이다. Histogram Equalization (HE) 방법을 조금 더 개..
3months.tistory.com
(↓↓↓ Open CV에서 N-CLAHE 사용 예제↓↓↓)
https://docs.opencv.org/master/d5/daf/tutorial_py_histogram_equalization.html
OpenCV: Histograms - 2: Histogram Equalization
Goal In this section, We will learn the concepts of histogram equalization and use it to improve the contrast of our images. Theory Consider an image whose pixel values are confined to some specific range of values only. For eg, brighter image will have al
docs.opencv.org
위의 전처리 방식 외에 Contrast, brightness 등 여러 다른 방식들도 같이 사용될 수 있다는 점 알아두세요!
CT 이미지 또한 X-ray 선을 이용한 것이 때문에 X-ray와 비슷한 전처리 기법이 사용된다는 것을 알아두시면 좋을 것 같습니다~
[전처리를 배우고 딥러닝에 적용해본 후기]
위와 같은 전처리 기법을 딥러닝에 적용했을 때, 유의미하게 CNN 성능이 개선되는 것을 확인할 수 있었습니다.
다음 글에서 설명하겠지만, 전처리한 이미지를 segmentation 같은 모델에 적용했을 때 눈에 띄게 향상되는 모습들을 빈번하게 살펴볼 수 있었습니다.
딥러닝 모델 자체에 대한 연구도 중요하지만, 의료 이미지를 다루는 영역에서는 전처리 영역에 대한 테크닉을 적절히 구사할 줄 알아야 한다고 생각했습니다. 즉, 전처리를 적절하게 구사해야 딥러닝 모델의 성능향상을 이끌 수 있을거라 생각합니다.
(↓↓↓아래 글에 제가 적용했던 사례들이 있으니 확인해보셔도 좋을 것 같습니다↓↓↓)
https://89douner.tistory.com/256
지금까지 간단하게 X-ray, CT 이미지들과 관련 전처리 기법들을 알아봤습니다.
다음 글에서는 MRI, PET, 초음파, 내시경에서 얻어지는 medical imaging들을 알아보도록 하겠습니다~