안녕하세요.
이번 장에서는 이산확률분포를 설명하기 위한 여러 개념들에 대해서 살펴보도록 하겠습니다.
1. 확률분포를 사용하는 이유
- 우리는 사회현상, 자연현상을 분석하기 위해 통계적 개념을 이용합니다.
- 예를 들어, 정규(확률)분포는 '일반적인 사회현상을 통계로 나타낼 때, 대부분 평균 주위에 가장 많이 몰려 있고, 그 수치가 평균보다 높거나 낮은 경우는 점점 줄어들게 되는 현상'을 나타내는데, 이러한 현상을 보여주는 확률 분포로써 '정규(확률)분포'를 사용합니다. (정규(확률)분포에 대해서는 연속확률분포를 다룰때 자세히 설명하도록 하겠습니다.)

- 통계학에서는 다양한 확률분포를 사용합니다. 당연히 다양한 자연현상과 사회현상이 있기 때문에, 이러한 현상들을 대표하는 확률분포도 다양하겠죠.
- 그럼 지금부터 확률분포에 대해서 천천히 알아보도록 하겠습니다.

2. 확률분포(Probability Distribution)
- 실험(시행)을 통해 확률변수(random variable) 값이 정해지면, 그 값들의 빈도수를 기반으로한 확률함수를 통해 각각의 변수에 대한 확률 값이 정해집니다.
- 아래 그림에서는 몸무게에 해당하는 정수 값들 (50,60,70,80)이 random variable이며, 상대도수 값이 확률 값입니다.


- 위의 설명을 좀 더 직관적으로 표현하면 아래와 같습니다.
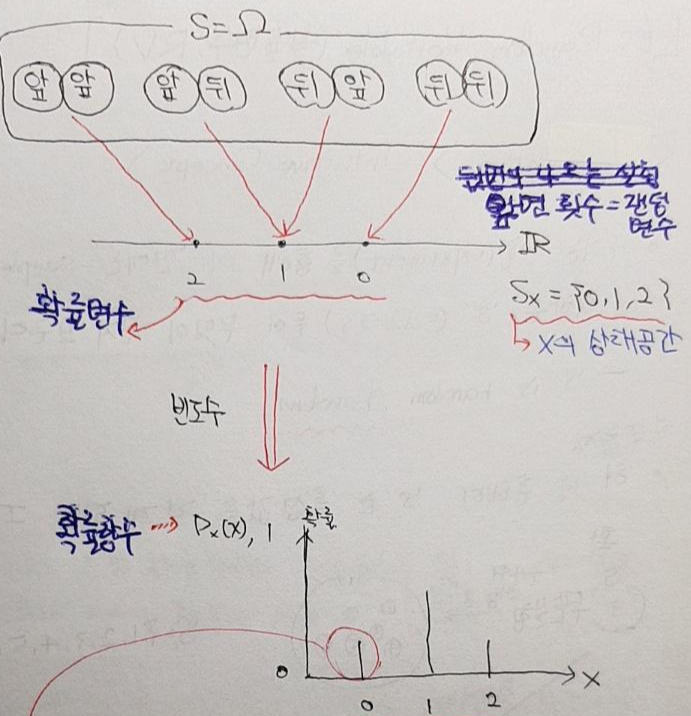
- 실험 데이터들이 많아지면 확률 변수에 따른 확률 값들의 분포를 짐작할 수 있게 됩니다.
- 이러한 실험을 통해서 얻은 확률분포 자체만으로도 굉장히 유용하게 쓰이지만, 해당 확률분포를의 expectation, variance 등의 개념들을 이용하여 유의미한 통계 작업을 하게 됩니다. (expectation, variance 에 대한 설명은 뒷 부분에서 하도록 하겠습니다)
3. Probability Mass Function (PMF)
- 이전 글("2. 확률분포")에서 확률 함수에 대해서 앞서 설명했기 때문에 확률함수에 대한 설명은 생략하도록 하겠습니다. PMF는 간단히 말해 확률 함수가 취하는 정의역이 이산확률변수(discrete probability variable)일 뿐입니다.
- Probability Mass Function describes a probability distribution over discrete variables.
- 밀도라고 이름을 붙인 이유는 사실 연속확률분포와 관련된 PDF (Probability Density Function)를 먼저 살펴봐야 하는데, 먼저 여기에서는 간단히 "정의" 정도만 언급하고 자세한 설명은 연속확률분포 파트에서 설명하도록 하겠습니다.
- 연속확률분포에서 사용되는 PDF는 밀도라는 개념을 이용합니다. '밀도'라는 것은 부피당 차지하는 질량의 정도(=질량/부피)를 말합니다. 연속확률분포에서는 면적이 확률 값이 되는데 아래 그림을 보면 면적에 해당하는 공간(부피)에 무수한 선들이 빽빽하게 채워져있는 것 처럼 보이게 됩니다.
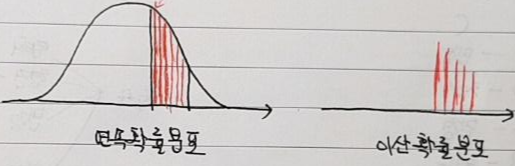
- 이산확률분포에서는 질량에 해당하는 하나의 선 자체가 확률 값이 되기 때문에 해당 질량(확률 값)을 도출하는 확률 함수를 PMF라고 부르게 됩니다.
- PMF는 어떤 discrete random variable에 대한 probability model이라고 할 수 있습니다.
4. 이산확률분포(Discrete Probability Distribution) with PMF axiom
- 우리는 실험을 통해서 확률변수(random variable)을 얻게 됩니다.
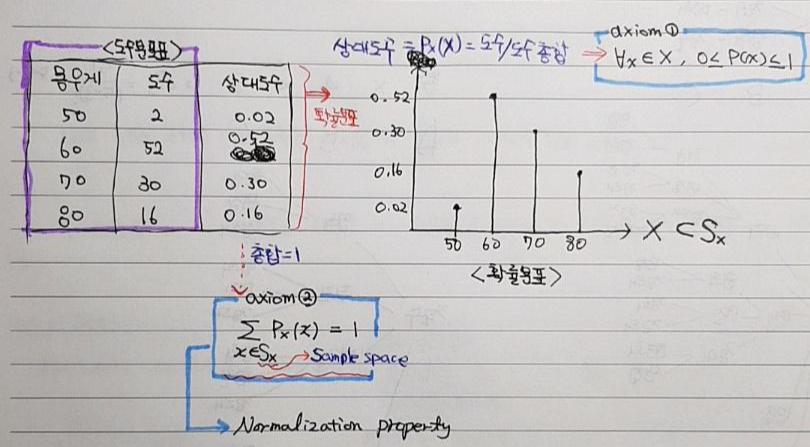
- 보통 확률변수를 변량(variance)라고도 하는데, 예를 들어, 몸무게를 측정하는 실험을 통해 얻은 변량 or 확률변수는 50, 60, 70, 80이 될 수 있습니다.
- 만약, 우리가 100명에 대해서 조사한다고 했을 때, "몸무게 50에 해당하는 사람이 2명, 60에 해당하는 사람이 52명, 70에 해당하는 사람이 30명, 80에 해당하는 사람이 16명"이라고 했을 때, 해당 확률변수(50,60,70,80)의 사람 수는 일종의 (빈)도수(frequency)가 됩니다.
- 이러한 확률변수에 대한 (빈)도수를 표로 정리한 것이 도수분포표입니다.
- 그리고 이러한 도수분포표는 상대도수(=도수/도수총합)를 통해 확률 값으로 변경되는데, 이 때 상대도수를 도출하기 위한 함수를 확률함수(PMF)로 볼 수 있습니다.
- 그리고 이러한 PMF에는 아래 그림에서와 같이 두 가지 공리(axiom①, axiom②)가 존재합니다. 그러므로 다음글에서 소개할 다양한 이산확률분포의 확률함수는 아래 두 가지 공리가 항상 성립해야합니다.
- 특히, 도수에서 상대도수로 바꿀 때, 각각의 도수를 도수총합(=N)으로 나누는데 이를 normalization(정규화)이라고 합니다.
- 앞서 "실험을 통해 얻은 확률분포에서 expectation, variance 등의 개념들이 출현하게 되는데, 이러한 개념들을 이용하여 유의미한 통계 작업을 하게 됩니다."라고 언급했는데, expectation과 variance가 어떻게 쓰이는지 알아보기 전에, expectation과 variance가 무엇인지 먼저 알아보도록 하겠습니다.
5. Expectation (기댓값)
- 기댓값 E(X)를 보통 평균(mean)이라고 합니다.
- 만약 한 반의 시험점수 '평균'이 70점이라고 한다면, 해당 반의 학생 중 아무나 한명을 골랐을 때 시험점수가 70점일거라고 '기대'하기 때문에, '평균'과 '기대값'이라는 용어를 동일시합니다.

5-1. Linearity of expectations
- 선현성에 대한 개념은 나중에 선형대수라는 과목을 다룰 때 더 자세히 설명하도록 하고, 여기에서는 기댓값과 관련된 성질을 알아보는 차원정도로 정리해보도록 하겠습니다.
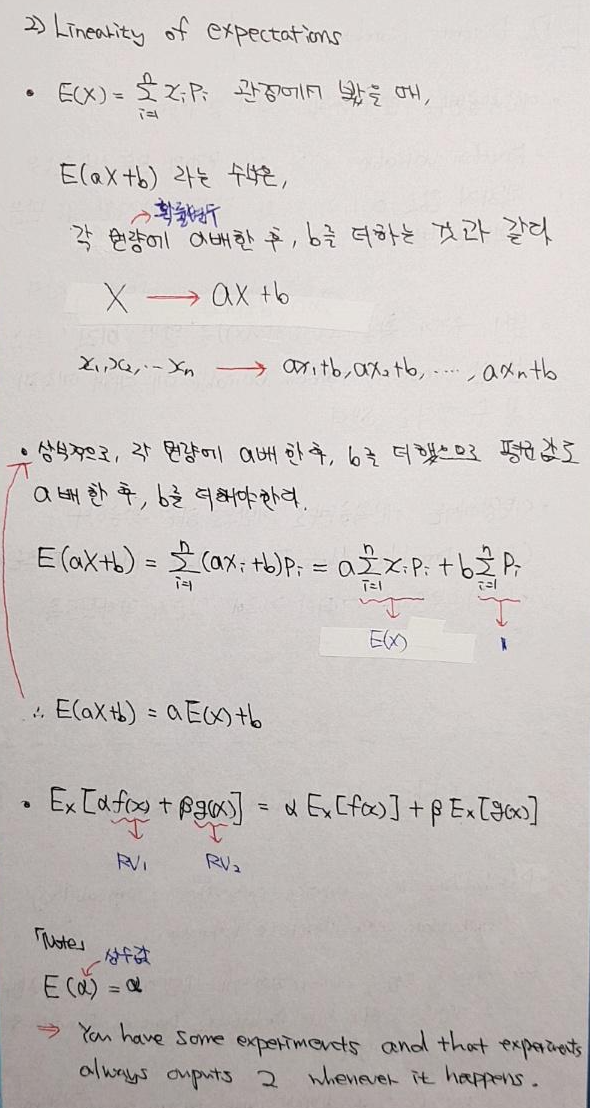
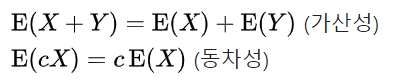
- 평균(기댓값)이 통계적으로 의미가 있는 이유는 데이터들의 분포를 대표할 수 도 있기 때문입니다.
- 예를 들어 아래 그림에서는 평균이 (대략) 175정도 된다고 볼 수 있는데, 아래와 같은 정규(확률)분포표를 따른다고 하면 실험을 통해 수집한 데이터들이 175에 몰려있다는 것을 추론할 수 있게 됩니다.
- 즉, 평균(기댓값)이 데이터들의 분포를 대표할 수 있게 됩니다.

6. 편차(Deviation)와 분산 (Variance)
- 앞서 살펴본 '키'관련 확률분포표에서 평균(기댓값)은 데이터들의 분포를 대표할 수 있다고 설명했습니다.
- 아래와 같은 상황에서 A확률 분포는 평균(기댓값)이 데이터들의 분포를 대표할 수 있다고 말할 수 있겠는데, B확률분포를 상대적으로 봤을 때 평균(기댓값)이 데이터의 분포를 대표한다고까지 할 수 있을지 잘 모르겠습니다.

- B확률 분포와 같은 경우는 평균과 데이터들의 거리가 매우 멀기 때문에, 평균값이 데이터들의 분포를 대표한다고 자신있게 말하기 어렵습니다.
- 그래서 B와 같은 확률 분포를 대표하기 위해서 '평균'과 '평균으로부터 떨어져 있는 데이터들의 거리정도'를 사용해야 B 확률분포를 상징(represent)할 수 있게 됩니다.
- 이때 '평균과 데이터들의 거리'를 '편차'라고 하는데, 해당 확률분포가 평균과의 '편차'가 얼마나 심한지 알기 위해서는 '편차'의 평균을 구하면 됩니다.
- 그런데 아래 그림에서보면 알 수 있듯이 편차가 분명 존재함에도 불구하고 편차들의 평균값이 0이 나올 수 있습니다. (아래 그림에서 변량(확률변수=random variable)은 몸무게에 해당하고, 몸무게의 평균은 70입니다)
- 사실 아래 예시 뿐만아니라 모든 경우에도 편차(변량-평균)의 평균값은 '0'이라는 걸 알 수 있습니다.

- 결국, 편차의 대푯값을 구하기 위해 편차에 존재하는 음수를 양수로 바꾸자는 idea가 나오게 되었고, 음수를 제곱하여 편차의 대푯값을 구하는 '분산'이라는 개념이 나오게 되었습니다.
- 모든 편차에 제곱을 해주면 항상 양수가 나오기 때문에 아래와 같이 계산하는 방식을 분산이라고 정의하게 됩니다.

- 분산(variance) 공식은 아래와 같이 정리할 수 있습니다.
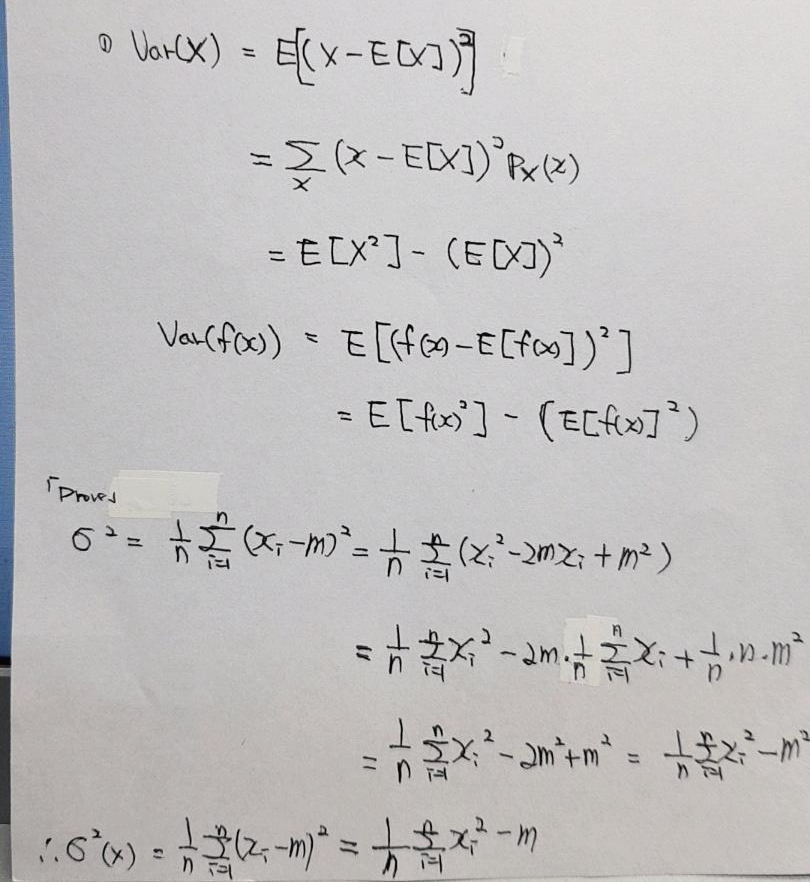
- 분산은 아래와 같은 속성을 지닙니다.

- 통계학에서는 평균(기댓값)과 분산을 통해 유의미한 연구를 진행하게 됩니다.
7. 표준편차 (Standard deviation)
- 분산식을 보면 제곱 성질로 인해 값이 커진다는 것을 알 수 있습니다.
- 그렇기 때문에 분산식에 루트 (√) 를 씌워주어 값의 크기를 줄여주는데, 이것을 표준편차라고 합니다.
- 즉, 평균으로부터 데이터들이 얼마나 떨어져 있는지의 정도를 표준적으로 알려준다는 의미를 지닙니다.
- 표준편차를 구할 때 식을 RMS (Root Mean Square)이라고도 부릅니다.

이번 장에서는 이산확률분포에 대한 개념과, 확률분포에서 사용되는 유의미한 개념들(평균, 분산, 표준편차)에 대해서 알아보았습니다. 그럼 다음 글에서부터는 이산확률분포의 여러 종류들에 대해서 알아보도록 하겠습니다.
'딥러닝수학 > 확률-통계학' 카테고리의 다른 글
| [확률]4-1. 연속확률분포 (feat. Probability Density Function) (feat.평균(기댓값), 분산(variance), 표준편차(Standard deviation)) (1) | 2021.05.17 |
|---|---|
| [확률]3-2. 이산확률 분포 종류들 (feat. 베르누이 분포, 이항분포, 기하분포, 음이항 분포, 초기하 분포, 포아송 분포 (1) | 2021.05.15 |
| [확률]2. 확률분포(Probability distribution) (feat. 확률변수(Random variable), 확률함수) (0) | 2021.05.13 |
| [확률]1.확률이란? (feat. 수학적 확률, 통계적 확률) (0) | 2021.05.11 |
| 통계학에 대한 글을 쓰는 이유 (0) | 2021.05.11 |