Q.학습이란 무엇인가요? 신경망이 어떻게 학습을 할 수 있다는 것인가요?
Q. L1 loss function이 뭔가요? L2 loss function이 뭔가요?
우리는 학습이라는 것을 하기 위해 아래와 같은 과정을 거칩니다. 예를 들어, 기계가 탁구치는 것을 학습한다고 가정해볼께요.
① 처음에는 기계가 사람이 넘겨준 공을 칩니다.
② 하지만, 상대방 테이블에 정확히 들어가지 않습니다.
③ 기계는 자신의 행위가 잘 못 되었음 (error)을 인지하고 자세를 바꿉니다.
④ 상대방 테이블에 정확히 들어갈때까지 계속 자세를 바꾸는 과정을 반복합니다.
아주 간단하게 보면 학습이라는 것은 어떤 정답이되는 결론에 도달하기 위해 수 없이 시행착오(trial-error)를 거치는 행위를 의미하게 됩니다.
그렇다면 기계는 시행착오를 통해 어떤 방식으로 학습을 할까요? 기계를 학습시키기 위해 몇몇 학자들이 신경망(Neural Network)이라는 모델을 제시하게 되는데, 그 중 대표적인 모델이 perceptron 입니다. (Rosenblatt이 제시한 perceptron(퍼셉트론)이라는 모델은 딥러닝의 기원이 되는 중요한 모델입니다!)
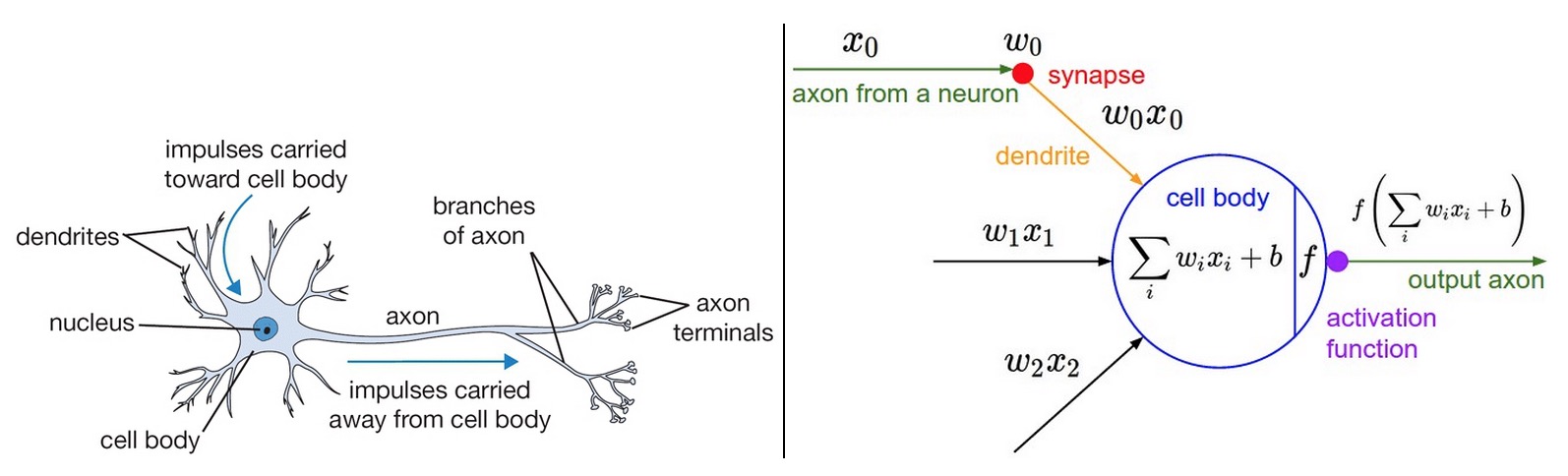
Perceptron은 뉴런(Neuron)의 작동방식을 본 떠서 만들어졌습니다. 수 많은 뉴런들은 서로 연결되어 전기신호를 주고 받습니다.
예를 들어, A,B,C,D 라는 뉴런들이 서로 연결되어 있다면, 공부를 할 때는 A->D->C->B, 운동을 할 때는 A->B->D->C 라는 경로를 통해 신호를 전달하게 됩니다. 이러한 뉴런들은 뇌에서 일어나는 모든 활동들에 관여하면서 사물을 인지하고, 학습하고, 판단함으로써 지능적인 역할을 담당하게 되었습니다.
그렇다면 하나의 인공신경망(뉴런)이 어떻게 학습하는지 김성훈 교수님의 동영상을 보면서 이해해 볼까요?

<사진1>
학습이 되는 과정을 이해하기 위해서는 미분의 기하적인 개념을 이해하면 좋은데요. 아래 강의를 보시면서 미분의 개념은 쉽게 잡으시고 강의를 이어서 보시는걸 추천합니다.
지금까지 설명한 내용들을 수식으로 정리해봤어요. 앞으로 딥러닝을 하시게 되면 아래와 같은 그림과 수식들이 쉽게 눈에 들어와야해요!

강의만 들으셔도 학습이 어떻게 되는지 쉽게 이해되시죠? 그런데 문제는 우리가 학습하는 이유가 단지 무언가를 분류를 하기 위해서만 한다는것이 아니라는 점이에요. 예를들어, 무엇인가를 예측하기 위해서도 학습을 하기는 것처럼, 다양한 목적에 따라 학습을 하기도해요.
1) L2 loss function
유튜부 강의에서 설명한 cost function은 MSE(Mean Square Error)라고해요. MSE는 Least Square Error (LSE) 또는 L2 loss function이라고도 불립니다.

2)L1 loss function
L2 loss function이 있으면, L1 loss function도 있겠죠? L1 loss function의 수식부터 설명하자면 아래와 같아요.

L1 loss function은 Least Absolute deviations (LAD) 또는 Least Absolute Errors (LAE)라고도 불린다고 해요.
3) L2 loss function VS L1 loss function
두 cost function의 공통점은 오차값을 0이상의 양수의 범위로 제한해준다는 점이에요. 제곱과 절대값은 항상 음이 아닌 정수가 나오겠죠?
두 함수의 큰 차이점은 오차값의 크기를 증가시키는 '정도'라고 생각해요. 예를 들어, L2 loss function 같은 경우에는 L1 loss function에 비해 오차값의 크기가 클 수록 더욱 오차의 정도를 배가시키고, 작을 수록 (0<오차값<1) 더욱 감소시키는 경향이 있어요.
간혹 outlier가 되는 값들이 오차값을 크게 일으키고는 하는데, 이러한 outlier에 영향을 덜 받고 싶다면 L1 loss function을 쓰는것도 하나의 방법이겠어요!
그럼 지금까지 배운내용을 종합해볼께요.
1. 신경망을 학습을 시킨다는 것은 가중치(w)를 학습시킨다는 것이다.
2. 가중치를 학습하기 위해서는 아래와 같은 과정을 거친다.
- E(w)는 cost function을 통해 얻은 cost value이다. (E(w)=J(Θ))
- 입실론은 learning rate이며 신경망이 적절하게 학습할 수 있도록 도와준다
('사진4'에서 볼 수 있듯이 만약 learning rate이 너무크면 최적화된 값을 갖지 못하고 오히려 cost value 발산하게 되고, learning rate이 너무작으면 학습하는데 오랜시간이 걸린다)


<사진4>
자! 그럼 마무리 질문을 던져볼께요~
지금까지 설명한 것처럼 모든 학습의 cost function을 L1 or L2 loss function을 사용할까요? 결론부터 말하자면 "아닙니다!"
우리가 학습하기 위한 목적 또는 문제정의를 어떻게 하는지에 따라서 다양한 cost function이 쓰여요. 그래서 다음장 부터 cost function에 대해 좀 더 다루어보려고 합니다!
P.S 홍보는 절대 아니구요. 저같이 수학적 백그라운드가 없던 사람도 아래 책을 보고 신경망이 학습하는 원리를 굉장히 구체적이고 직관적으로 이해할 수 있었어요. 그래서 공부하실 때, 같이 보시면 좋을 것 같아서 소개할께요!

<사진5>
#퍼셉트론 #Perceptron #학습 #신경망 #Artificial Neural Network #Neural Network #Cost function
#L1 loss function #Least Absolute Deviations (LAD) #Least Absolute Errors (LAE)
#L2 loss function #Least Square Error (LSE) #Mean Square Error (MSE)
[사진 래퍼런스]
사진1
http://www.yoonsupchoi.com/wp-content/uploads/2017/08/neuron.jpg
{kind=link}
사진2
http://m.hanbit.co.kr/store/books/book_view.html?p_code=B1910379076
사진4
https://www.jeremyjordan.me/nn-learning-rate/
사진5
한빛미디어
'딥러닝 이론 > Deep Neural Network (DNN)' 카테고리의 다른 글
| 6. 학습을 잘 시킨다는 것은 무엇을 의미하나요? (Regularization, Generalization(일반화)) (1) | 2020.01.02 |
|---|---|
| 5.Multi-Layer Perceptron (MLP), Universal Theorem (2) | 2020.01.02 |
| 4. Activation Function은 왜 만들었나요? (4) | 2019.12.31 |
| 3. 학습을 하는 목적에 따라 cost function이 달라진다구(최대우도법, Cross Entropy)? (0) | 2019.12.30 |
| 1. 생각한다는 것이 무슨 뜻인가요? (딥러닝의 부모님) (2) | 2019.12.16 |