안녕하세요.
이번 글에서는 Albumentations라는 패키지를 이용하여 데이터를 로드하는 방법에 대해서 설명하도록 하겠습니다.
https://github.com/albumentations-team/albumentations
GitHub - albumentations-team/albumentations: Fast image augmentation library and an easy-to-use wrapper around other libraries.
Fast image augmentation library and an easy-to-use wrapper around other libraries. Documentation: https://albumentations.ai/docs/ Paper about the library: https://www.mdpi.com/2078-2489/11/2/125 -...
github.com
Albumentations
Albumentations: fast and flexible image augmentations
albumentations.ai
앞선 글에서는 pytorch에서 제공하는 torchvision.transforms를 이용하여 데이터 로드 하는 방식을 설명했습니다.
하지만, 이러한 방식으로 데이터 로드를 할 때, 두 가지 부분에서 불편한 부분이 생깁니다.
- input과 label 이미지에 동일한(일치한) augmentation이 적용되야하기 때문에 torch.manual_seed() 함수를 이용해 난수를 고정시켜주어야 합니다.
- torchvision.transforms에서 제공해주는 augmentation 종류는 한정적입니다.
위와 같은 문제를 해결하기 위해 많은 분들이 albumentations 패키지를 사용하고 있습니다.
그럼 지금부터 albumentations 패키지를 사용하여 데이터를 로드하는 방식에 대해서 설명해보도록 하겠습니다.
필자는 현재 Visual Studio Code IDE (=VS Code)를 이용해 코딩을 하고 있는데, VS Code의 interpreter가 아나콘다(anaconda) 가상환경에 연동되어 있기 때문에, Albumentations 패키지를 설치하기 위해서 anaconda 명령어를 이용하도록 하겠습니다.
(↓↓↓아나콘다 가상환경 설명↓↓↓)
https://89douner.tistory.com/73?category=878197
4. 아나콘다 가상환경 구축하기
안녕하세요~ 제가 이전글에서 했던 질문을 다시 가져와 볼게요. "여러분이 진행하는 프로젝트에서 딥러닝과 관련된 프로그램을 3개(A,B,C) 정도 사용한다고 했을때 여러분의 PC는 하나라고 가정
89douner.tistory.com
(↓↓↓아나콘다 가상환경과 VS code interpreter 연동방법↓↓↓)
https://89douner.tistory.com/74
5. 아나콘다 가상환경으로 tensorflow, pytorch 설치하기 (with VS code IDE, pycharm 연동)
안녕하세요~ 이번시간에는 아나콘다를 통해 2개의 가상환경을 만들고 각각의 가상환경에서 pytorch, tensorflow를 설치하는법을 배워볼거에요~ Pytorch: Python 3.7버전/ CUDA 10.1 버전/ Pytorch=1.4버전 Tensorf..
89douner.tistory.com
1. Albumentations 패키지 설치하기
앞서 필자는 VS code interpereter에 아나콘다 가상환경을 연동해서 사용하기 때문에, anaconda 명령어를 통해 albumentations 패키지를 설치할 것이라고 언급했습니다.
Anaconda 명령어를 이용해 albumentations 패키지를 설치하는 방식은 아래사이트에서 확인할 수 있습니다.
https://anaconda.org/conda-forge/albumentations
Albumentations :: Anaconda.org
Fast image augmentation library and easy to use wrapper around other libraries
anaconda.org
(↓↓↓ albumentations 설치 명령어 ↓↓↓)
conda install -c conda-forge albumentations
anaconda prompt를 열고 위와 같이 설치 명령어를 입력한 후 설치를 진행해줍니다.
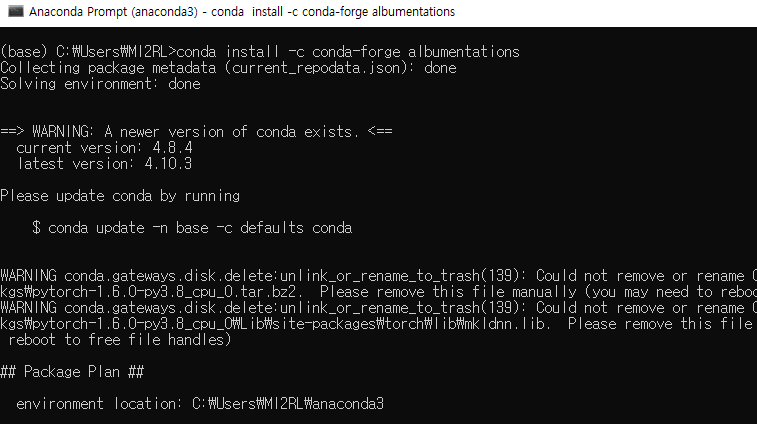
설치가 완료되면 아래와 같이 자신이 코드를 작성하고 있는 디렉토리에서 albumentations 모듈을 import해 관련 attribute or function들을 사용하면 됩니다. 그럼 지금부터 albumentations 모듈을 사용하여 데이터 로드 하는 방식을 설명해보도록 하겠습니다.
2. Albumentation 데이터 로드 코드
지금부터 설명하는 내용은 대부분 이전글 ("1-1. Data Load (Feat. torchvision transform) 을 기반으로 달라진 부분들에 대해서만 설명하도록 하겠습니다. 다시 말해, albumentation 을 이용하여 데이터 로드를 할 때 torchvision transform 기반으로 데이터 로드를 하는 코드들 중 어느 부분을 수정하면 되는지 말씀드리겠습니다. (그러므로 이전 글을 읽어보시는걸 추천합니다)
(↓↓↓ 이전 글: torchvision.transform 기반 데이터 로드 방식↓↓↓)
https://89douner.tistory.com/299?category=1001221
1-1. Data Load (Feat. torchvision transform)
안녕하세요. 이번 글에서는 "UNet (딥러닝 segmentation모델)" 학습을 위해 해당 모델에 입력으로 들어갈 데이터들이 어떤 과정을 통해 load 되는지 알아보도록 하겠습니다. 코드는 아래 사이트를 기반
89douner.tistory.com
먼저, 필자는 "alb_data_load.py, alb_train2.py"와 같이 파이썬 파일을 만들었습니다.
이 파일의 코드는 이전 글에서 설명한 코드들을 복사 붙여넣기 하여, albumentation을 적용하기 위해 수정된 최종 코드입니다.
[alb_data_laod.py]
import os
import numpy as np
import glob
import torch
import torch.nn as nn
## 데이터 로더를 구현하기
class Dataset(torch.utils.data.Dataset):
def __init__(self, data_dir, transform=None):
self.data_dir = data_dir
self.transform = transform
self.data_dir_input = self.data_dir + '/input'
self.data_dir_label = self.data_dir + '/label'
lst_data_input = os.listdir(self.data_dir_input)
lst_data_label = os.listdir(self.data_dir_label)
self.lst_label = lst_data_label
self.lst_input = lst_data_input
def __len__(self):
return len(self.lst_label)
def __getitem__(self, index):
label = np.load(os.path.join(self.data_dir_label, self.lst_label[index]))
input = np.load(os.path.join(self.data_dir_input, self.lst_input[index]))
if label.ndim == 2:
label = label[:, :, np.newaxis]
if input.ndim == 2:
input = input[:, :, np.newaxis]
#data = {'input': input, 'label': label}
if self.transform:
data = self.transform(image=input, mask=label)
data_img = data["image"]
data_lab = data["mask"]
data = {'input': data_img, 'label': data_lab}
return data
[alb_train2.py]
import os
from albumentations.pytorch import transforms
import numpy as np
import torch
from torch._C import dtype
import torch.nn as nn
from torch.utils.data import DataLoader
from model import UNet
from alb_data_load import Dataset
import time
#from torchvision import transforms
import albumentations as A
import copy
from torchvision.utils import save_image
data_dir = 'data'
batch_size= 2
transform_train = A.Compose([
A.HorizontalFlip(),
A.VerticalFlip(),
A.Normalize(mean=0.5, std=0.5),
transforms.ToTensorV2(transpose_mask=True)
])
transform_val = A.Compose([
A.HorizontalFlip(),
A.Normalize(mean=0.5, std=0.5),
transforms.ToTensorV2(transpose_mask=True)
])
dataset_train = Dataset(data_dir=os.path.join(data_dir, 'train'), transform=transform_train)
loader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=False, num_workers=0)
dataset_val = Dataset(data_dir=os.path.join(data_dir, 'val'), transform=transform_val)
loader_val = DataLoader(dataset_val, batch_size=batch_size, shuffle=False, num_workers=0)
# 그밖에 부수적인 variables 설정하기
num_data_train = len(dataset_train)
num_data_val = len(dataset_val)
num_batch_train = np.ceil(num_data_train / batch_size)
num_batch_val = np.ceil(num_data_val / batch_size)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
## 네트워크 생성하기
net = UNet().to(device)
## 손실함수 정의하기
fn_loss = nn.BCEWithLogitsLoss().to(device)
## Optimizer 설정하기
optim = torch.optim.Adam(net.parameters(), lr=1e-3)
## 네트워크 학습시키기
st_epoch = 0
num_epoch = 30
# TRAIN MODE
def train_model(net, fn_loss, optim, num_epoch):
since = time.time()
best_model_wts = copy.deepcopy(net.state_dict())
best_loss = 100
for epoch in range(st_epoch + 1, num_epoch + 1):
net.train()
loss_arr = []
for batch, data in enumerate(loader_train, 1):
data['label'] = data['label']/255.0
input = data['input']
label = data['label']
# forward pass
label = data['label'].to(device)
input = data['input'].to(device)
output = net(input)
# backward pass
optim.zero_grad()
loss = fn_loss(output, label)
loss.backward()
optim.step()
# 손실함수 계산
loss_arr += [loss.item()]
print("TRAIN: EPOCH %04d / %04d | BATCH %04d / %04d | LOSS %.4f" %
(epoch, num_epoch, batch, num_batch_train, np.mean(loss_arr)))
with torch.no_grad():
net.eval()
loss_arr = []
for batch, data in enumerate(loader_val, 1):
data['label'] = data['label']/255.0
# forward pass
label = data['label'].to(device, dtype=torch.float32)
input = data['input'].to(device, dtype=torch.float32)
output = net(input)
# 손실함수 계산하기
loss = fn_loss(output, label)
loss_arr += [loss.item()]
print("VALID: EPOCH %04d / %04d | BATCH %04d / %04d | LOSS %.4f" %
(epoch, num_epoch, batch, num_batch_val, np.mean(loss_arr)))
epoch_loss = np.mean(loss_arr)
# deep copy the model
if epoch_loss < best_loss:
best_loss = epoch_loss
best_model_wts = copy.deepcopy(net.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val loss: {:4f}'.format(best_loss))
# load best model weights
net.load_state_dict(best_model_wts)
return net
model_ft = train_model(net, fn_loss, optim, num_epoch)
torch.save(model_ft.state_dict(), './model_log/model_weights.pth')
그럼 위의 코드와 이전 글의 코드를 비교하면서 설명을 해보도록 하겠습니다.
3. Import
먼저 이전 글에서 추가할 import 부분에 대해서 설명하겠습니다.
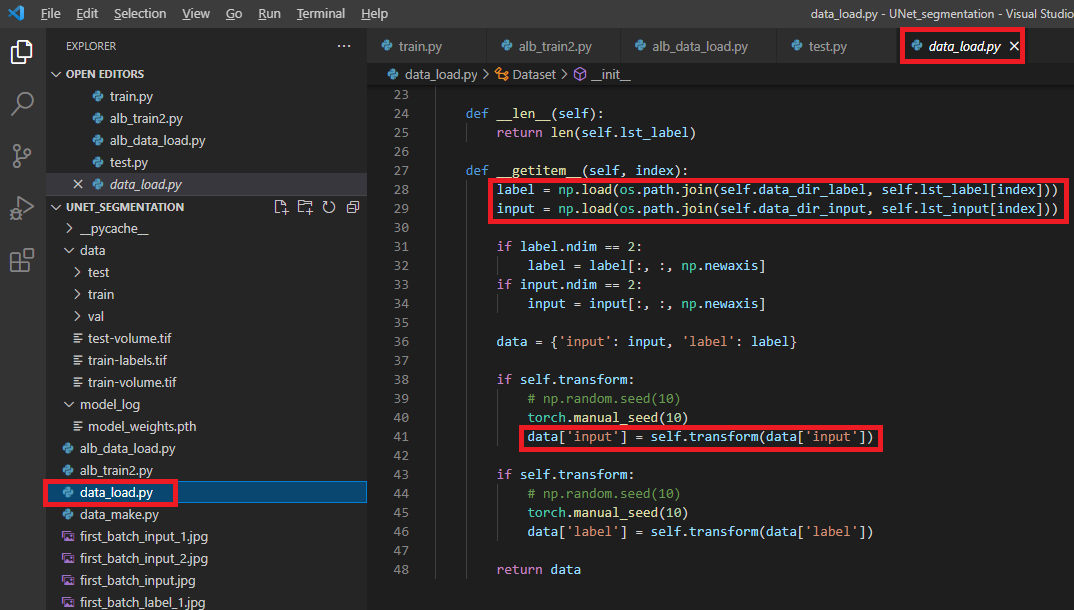
- alb_data_load.py 라는 새로운 데이터 로드 파일을 만들어 주었으므로 alb_data_load의 Dataset을 import 합니다.
- from alb_data_load import Dataset
- 설치한 albumentaion 관련 모듈을 import 해줍니다.
- import albumentations as A
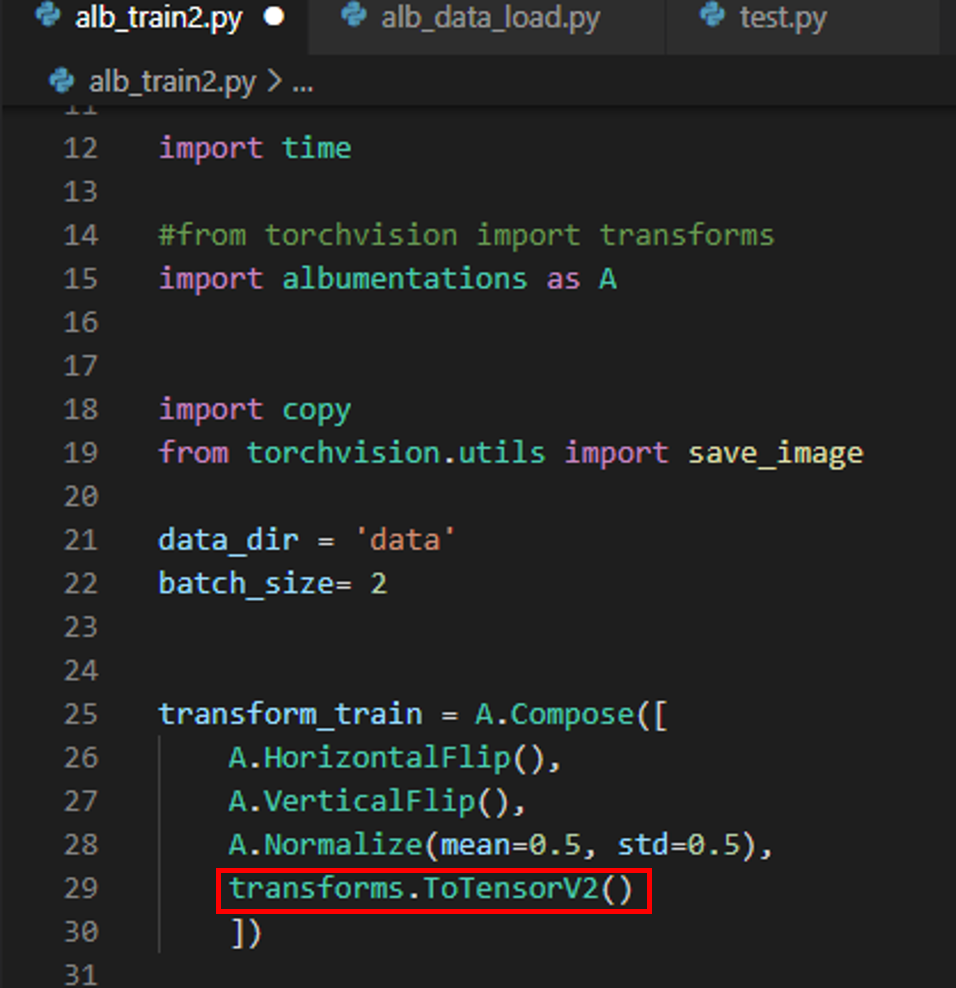
- from albumentations.pytorch import transfroms → 아래 "그림3"에서 transfor_train 부분을 보면 마지막에 ToTensorV2가 구현된 것을 볼 수 있습니다. ToTensorV2만 "albumentations.pytorch"로부터 import 한다는 걸 인지하세요!
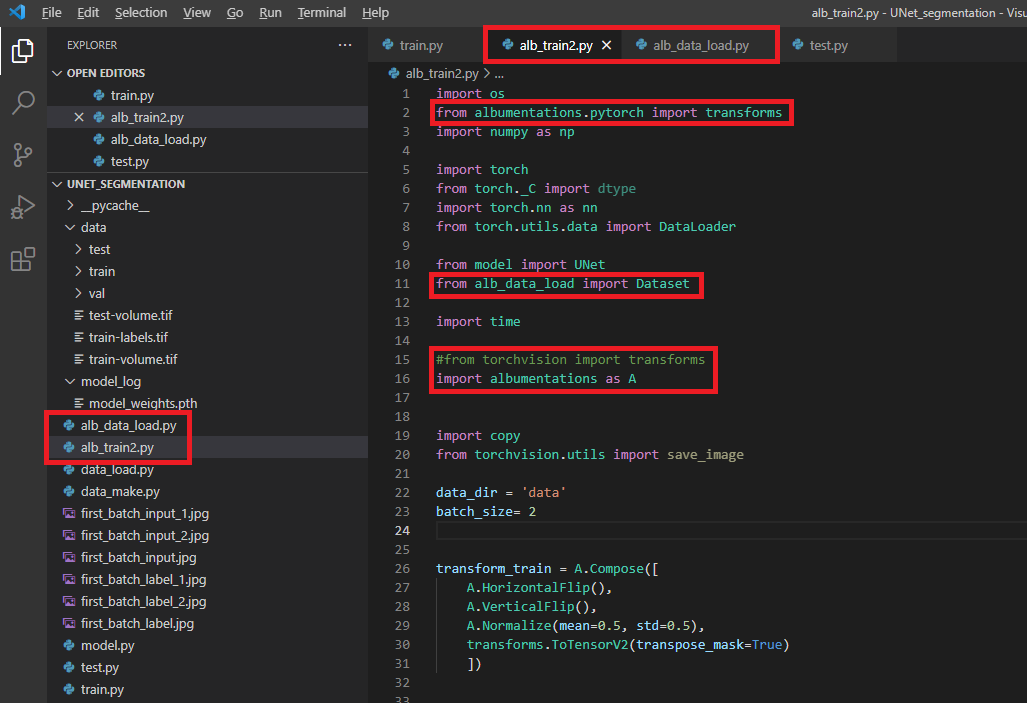
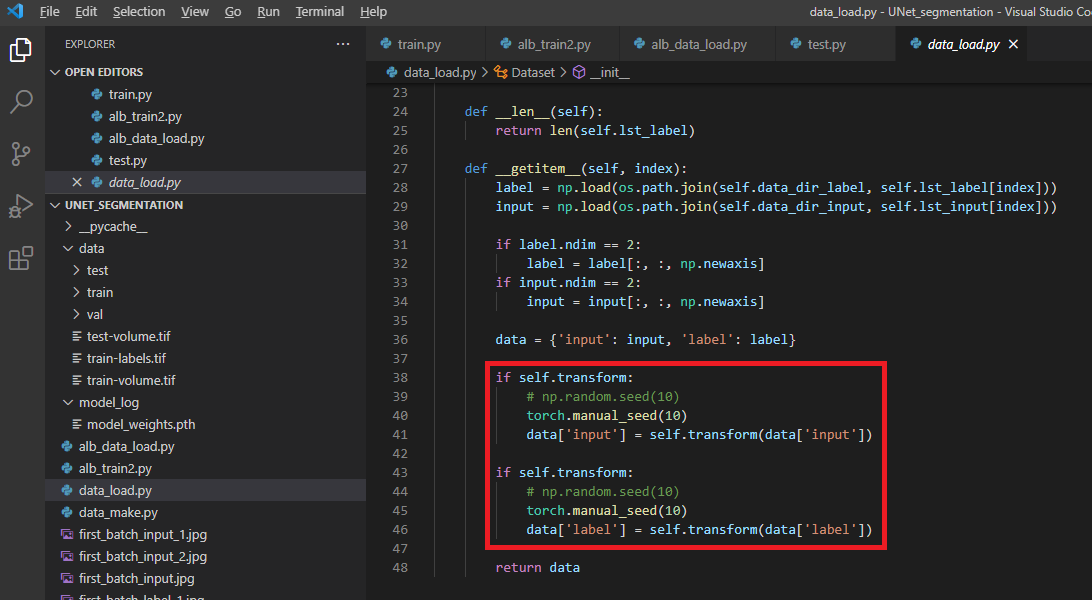
4. alb_data_load.py 변경
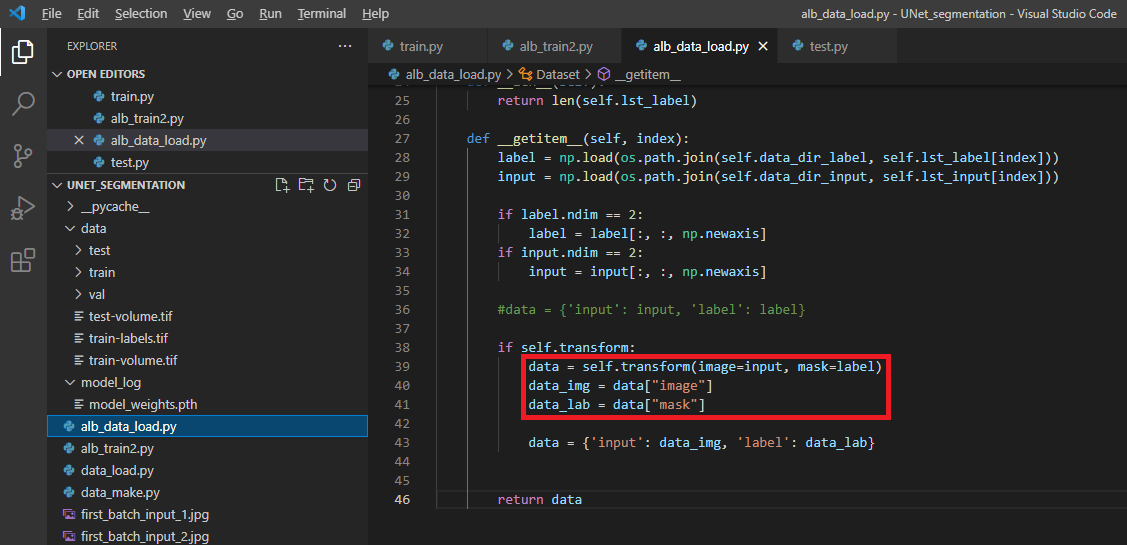
4-1. albumentation.transform(image, mask)
먼저, 이전 글에서 설명한 torchvision.transform의 인자형태를 보도록 하겠습니다. (아래 "4그림")
transform(data['input']), transform(data['label']) 이렇게 transform에는 하나의 리스트 인자(argument)만 받을 수 있게 되어 있습니다 (이러한 부분 때문에 torch.manual_seed()를 사용했죠 ← 자세한 설명은 이전 글 참고!)
그렇다면, albumentation에서 제공해주는 transform을 이용하면 위의 부분(="그림4"의 빨간색 박스)이 어떻게 바뀔 수 있을까요?
albumentation에서 제공해주는 transform은 두 개의 리스트 인자를 받을 수 있게 되어 있습니다. (아래 "그림5")
그래서 training image, training label을 동시에 넘겨줄 수 있기 때문에 따로 seed를 고정시켜줄 필요가 없습니다. (실제로 data_img, data_lab 데이터를 10번 정도 이미지화해서 살펴봐도 augmentation이 동일하게(일치하게) 적용되는 것을 확인할 수 있었습니다)
5. alb_train2.py 변경
5-1. transform.Compose → A.Compose
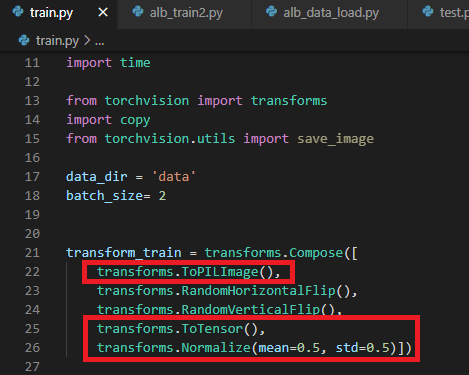
(이전 글에서 봤듯이) transform.Compose에 구현된 augmentation을 적용하기 위해 입력되는 데이터 형식은 numpy입니다.
먼저, 이전 글에서 사용했던 torchvision.transform.Compose에 구현된 순서를 살펴보겠습니다. (아래 "그림8")
torchvision.transform.Compose에서 제공하는 augmentation (ex: RandomHorizontalFlip(), etc..) 을 적용하기 위해서는 PIL 타입의 데이터가 입력되어야 합니다. 그래서 아래와 같이 "transforms.ToPILImage()" 를 먼저 수행시켜주어야 합니다. 그리고, PIL 타입을 torch tensor 타입으로 변경시켜준 후 (by "ToTensor()"), Normalize() 작업을 진행해줍니다.
그렇다면, albumentation.transform.Compose에서는 어떤 순서로 구성되는지 알아볼까요? (아래 "그림9")
우선 numpy 형식으로 입력되는 데이터를 PIL 형식으로 변경해줄 필요가 없기 때문에 "ToPILImage()"를 사용할 필요가 없습니다. 그리고, torch tensor 형태로 변경하기 전에 먼저 Normalize를 적용해주네요. 그리고, ToTensorV2를 적용해줍니다.

여기서 좀 더 보충해서 설명해야할 부분이 Normalize(), ToTensorV2() 입니다.
5-2. Normalize()
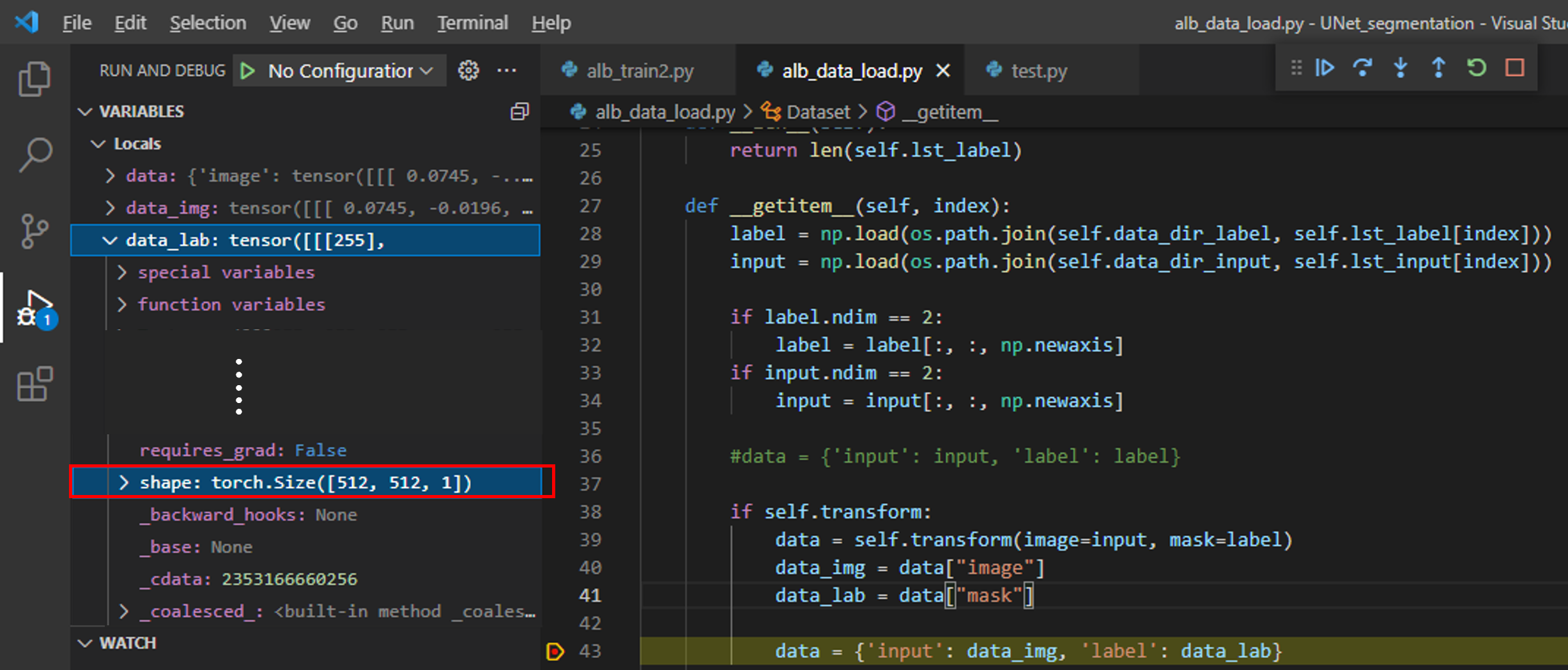
먼저, 아래 "그림10"처럼 breakpoint를 걸어주고 "alb_train2.py"를 실행시켜봅시다.
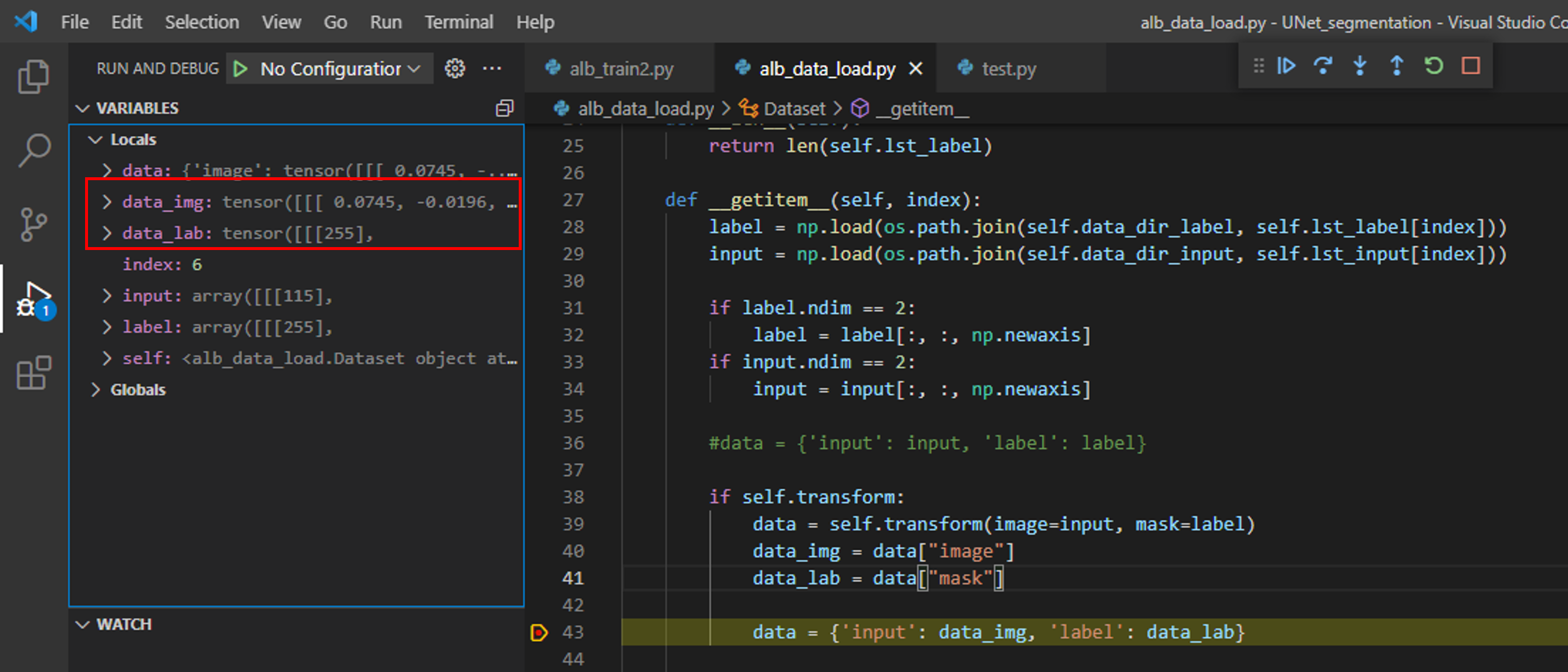
위 "그림10"처럼 디버깅을 하면 data_img, data_lab 값을 살펴볼 수 있습니다.
그런데, data_img에는 Normalize가 적용이 안되어 있습니다.
이러한 사실로 볼때 albumentation.transform.Compose에 적용되는 augmentation 중에 Normalize()는 label(=mask)에 적용되지 않는 듯합니다.
5-3. ToTensorV2()
이전 글에서 torchvision.transform.ToTensor()는 아래와 같은 기능을 한다고 했습니다.
- Converts a PIL Image or numpy.ndarray (H x W x C) in the range [0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0] if the PIL Image belongs to one of the modes (L, LA, P, I, F, RGB, YCbCr, RGBA, CMYK, 1) or if the numpy.ndarray has dtype = np.uint8
그런데, albumentation.transform.ToTensorV2() 결과 label의 타입이 numpy (=H x W x C) 에서 torch tensor 타입 (=C x H x W)으로 바뀌었지만, range는 그대로 0~255인 것을 확인할 수 있습니다. (아래 "그림11")
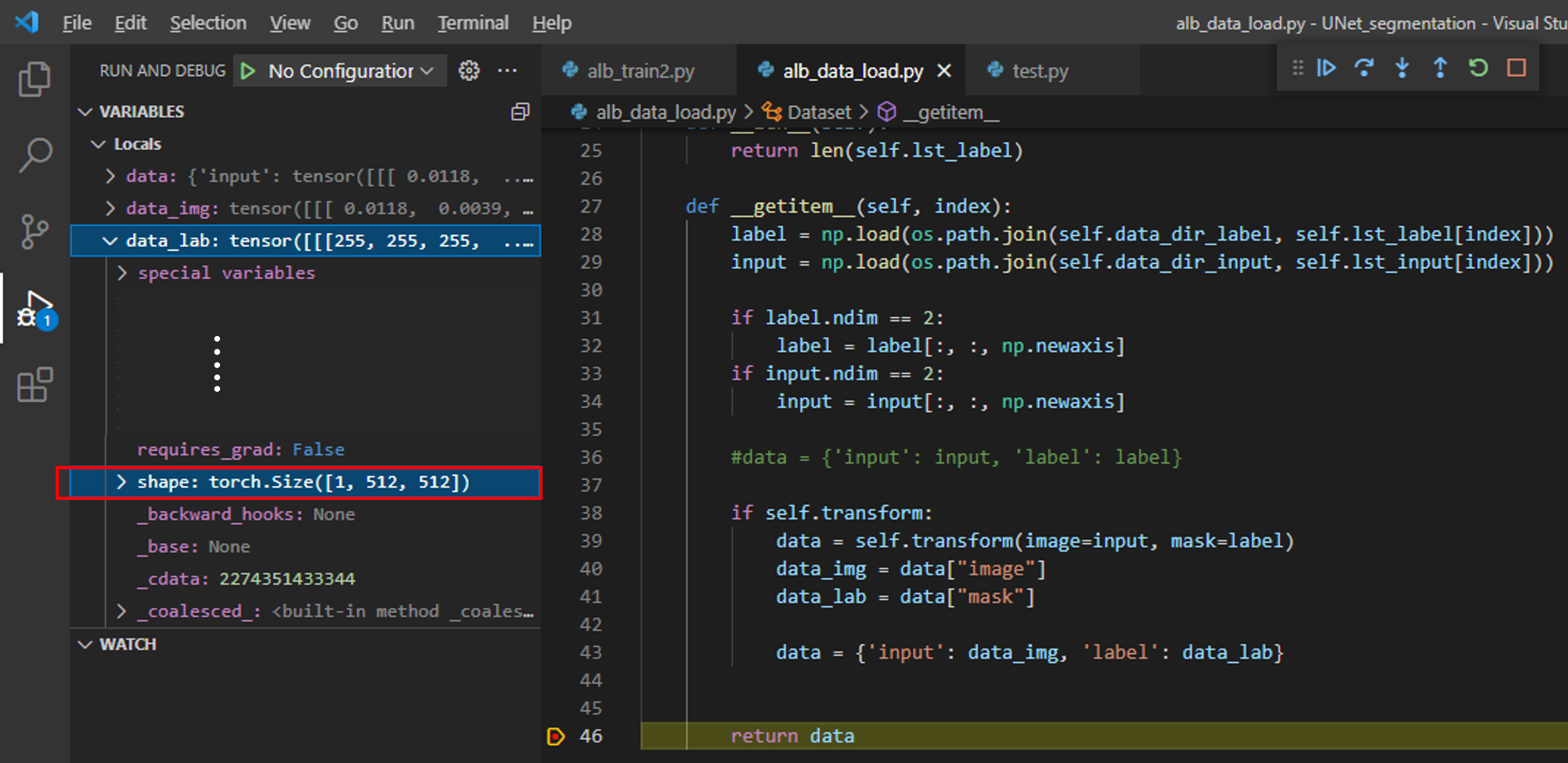
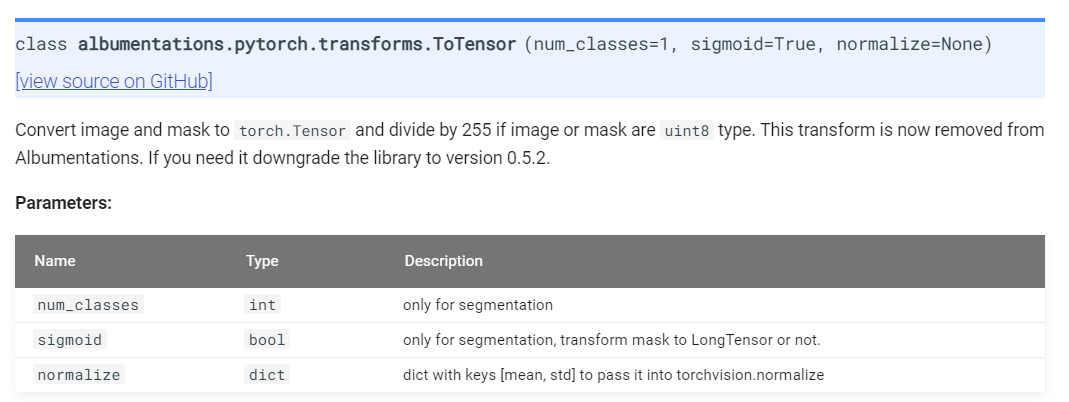
그 이유를 아래 "albumentations.pytorch.transforms.ToTensorV2()" API를 살펴본 후 알 수 있었습니다.
https://albumentations.ai/docs/api_reference/pytorch/transforms/
Albumentations Documentation - Transforms (pytorch.transforms)
Albumentations: fast and flexible image augmentations
albumentations.ai
쉽게 말해 albumentation 패키지 version 0.5.2 이후 부터는 255로 나누어주어 range를 0~1로 변경해주는 기능이 제거된다. 이러한 사실통해 살펴 볼때, 앞서 "data_img" 값들이 0~1로 범위가 변경된 이유는 Normalize()에 해당 기능(← 값의 범위를 0~1로 변경해주는 기능)이 들어있기 때문인듯 합니다. (앞서 albumentation.transforms.Normalize()는 label이 아닌 image에만 적용된다고 언급했습니다)
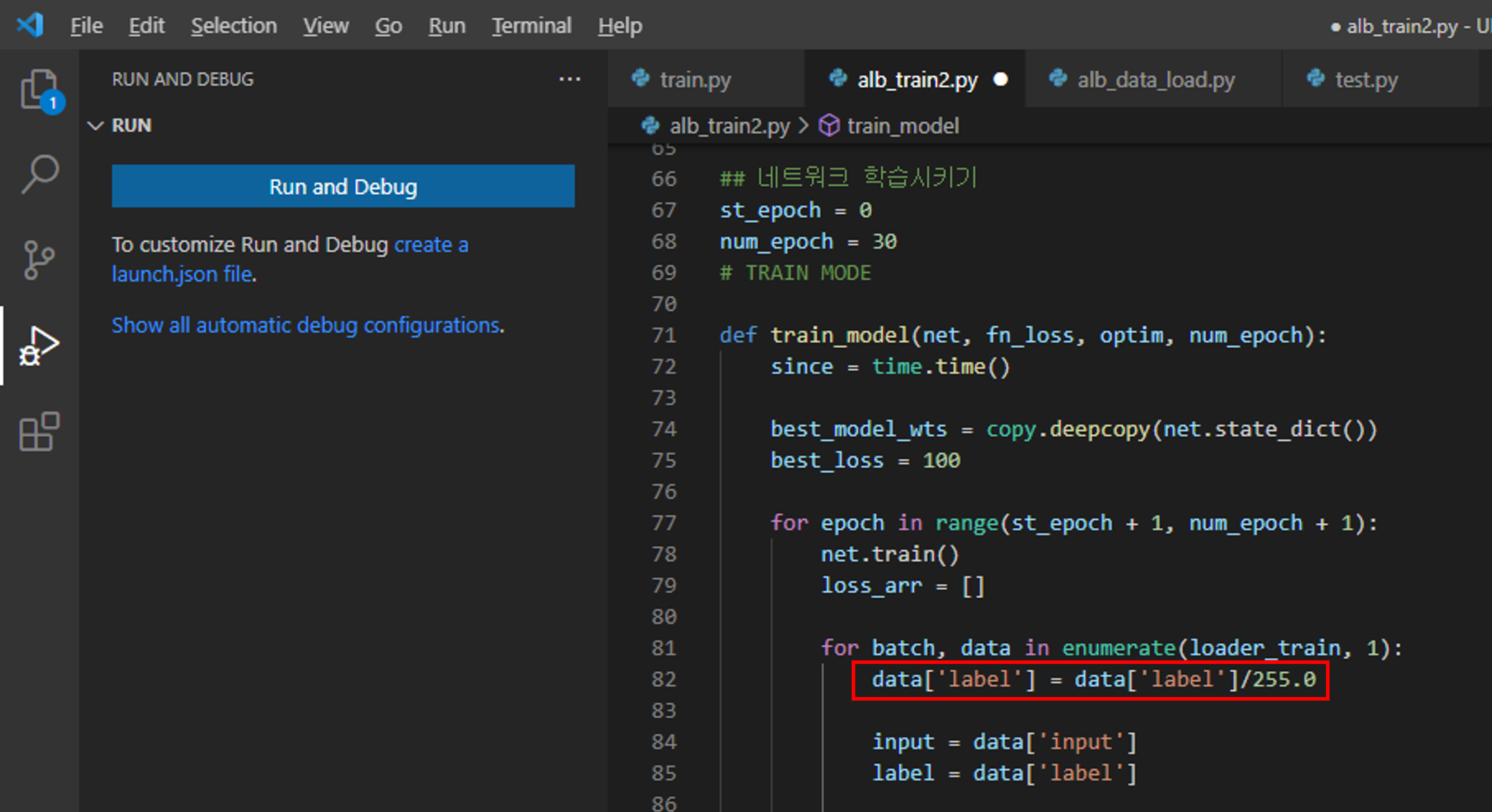
하지만, label(=mask)에 해당하는 값이 loss function(=crossentropy)의 인자 값으로 들어가기 위해서는 label이 0 or 1의 값을 갖아야 합니다. 즉, label 데이터 값의 255를 1로 변경해주어야 하는 것이죠 (or labeling smoothing을 적용하려면 label의 값의 범위가 0~1 사이로 변경되어야겠죠?)
이 부분은 간단하게 구현해줄 수 있습니다.
그냥 "alb_train2.py"에서 아래와 같이 data['label']을 255로 나누어주면 됩니다.
[주의사항]
아래와 같이 "ToTensorV2()"에 transpose_mask 부분을 명시해주지 않으면 False 값이 default가 됩니다.
위와 같이 코드를 실행 시키면 torch tensor 형식(=C x H x W)이 아닌 (H x W x C) 형식인걸 알 수 있습니다.
물론 (H x W x C) 구조를 permute()을 이용해 쉽게 (C x H x W) 구조로 변경 가능하지만, 그냥 ToTensorV2(transpose_mask=True)를 해주면 자동으로 구조변경이 된다는 점을 알아두시면 좋을 듯 합니다.
(↓↓↓permute() 사용법 ↓↓↓)
https://devbruce.github.io/machinelearning/ml-05-np_torch_summary/
[ML] Numpy & PyTorch Summary
devbruce.github.io
6. albumentation 응용
albumentation.transform.Compose 내부에 적용되는 augmetation 조합은 굉장히 다양하게 가져갈 수 있습니다.
방법은 아래 사이트의 "albumentations 응용 사례" 부분을 참고해주세요!
https://hoya012.github.io/blog/albumentation_tutorial/
albumentations - fast image augmentation library 소개 및 사용법 Tutorial
image augmentation library인 albumentations에 대한 소개와 사용 방법을 Tutorial로 정리해보았습니다.
hoya012.github.io
지금까지 albumentations 패키지를 이용한 segmentation 데이터 로드 코드를 알아보았습니다.
감사합니다.
'Pytorch > 3.Segmentation' 카테고리의 다른 글
| 3-1. Training 과정 Visualization (Feat. WandB) (1) | 2021.08.05 |
|---|---|
| 2. Segmentation 모델 구현 (feat. UNet) (0) | 2021.08.05 |
| 1-1. Data Load (Feat. torchvision transform) (0) | 2021.08.04 |
| 0.DataSet 마련하기 (Feat. ISBI 2012 EM segmentation) (0) | 2021.08.04 |
| 코드 참고 사이트 (0) | 2021.08.04 |