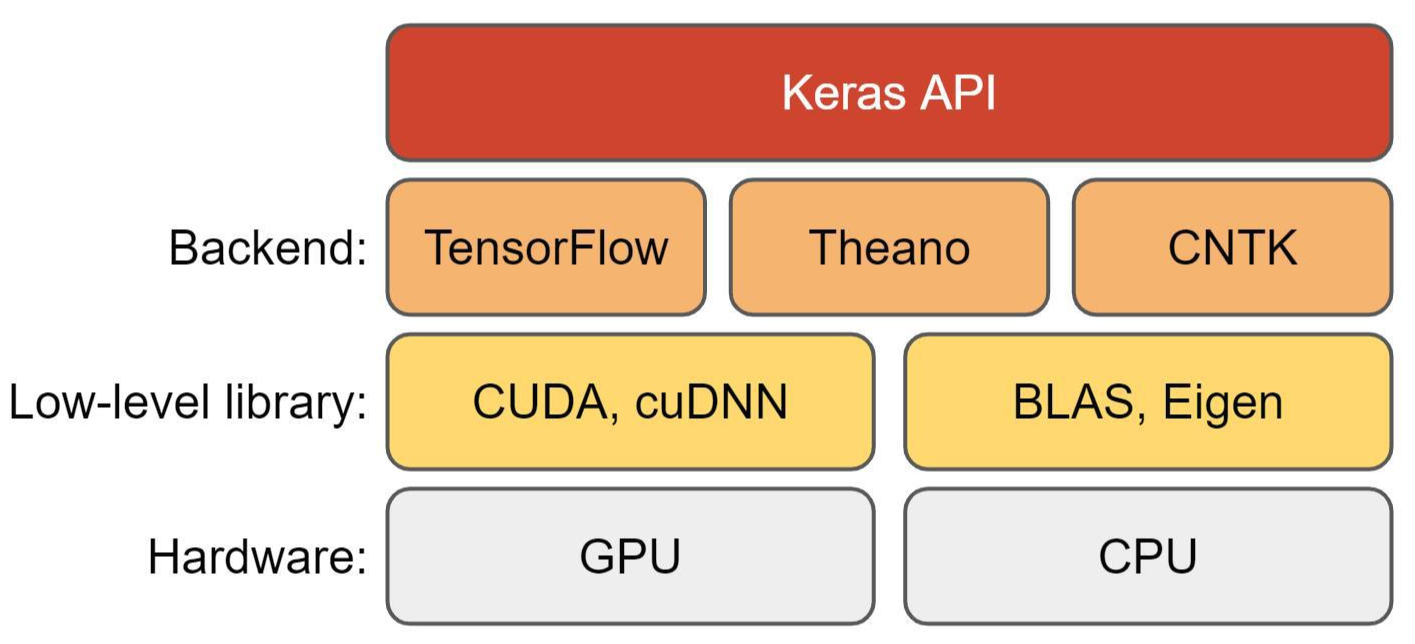
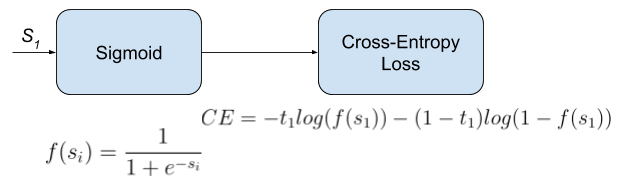Keras는 기본적으로 high level API 입니다. 아래 링크에서 언급하고 있듯이 딥러닝의 아주 기본적인 연산들(ex: tensor들의 연산 or 미분)이나 CPU, GPU, TPU 같은 hardware를 동작시키는 같은 작업(ex: CUDA)들은 Keras에서 구현하지 않습니다.
하지만, Keras가 딥러닝 학습을 하려면 앞서 언급한 딥러닝의 기본적인 연산을 해야하는데, 이를 어떻게 사용할 수 있을까요?
Keras는 backend engine에서 제공하는 특화된 tensor library를 사용함으로써 딥러닝의 기본적인 연산을 수행합니다. 예를 들어, tensorflow, theano, CNTK 라는 딥러닝 프레임워크를 backend로 사용합니다. 다양한 backend (tensorflow, theano, CNTK) 를 사용한다고 하여 아래와 같이 표현하기도 합니다.
"Kerass는 multi-backend(멀티 백엔드)를 지원합니다"
Theano: developed by LISA Lab at Université de Montréal → http://deeplearning.net/software/theano
Tensorflow: developed by Google→ https://www.tensorflow.org
CNTKL: developed by Microsoft→ http://github.com/Microsoft/CNTK
이미지 출처: https://www.digikey.de/en/maker/projects/getting-started-with-machine-learning-using-tensorflow-and-keras/0746640deea84313998f5f95c8206e5b
2. Tensorflow와 Keras의 관계 (Tensorflow 2.5 & Keras 2.4)
예전에는 기존 케라스 사용자들이 Keras API를 사용하면서 backend로 종종 tensorflow를 사용했습니다.
하지만, 2020.06.18에 케라스가 2.4 버전을 release 하면서 아래와 같은 말을 했습니다. (현재(2021.06.30)까지도 keras 최신 버전은 2.4입니다)
"We have discontinued multi-backend Keras to refocus exclusively on the TensorFlow implementation of Keras."
"In the future, we will develop the TensorFlow implementation of Keras in the present repo, atkeras-team/keras. For the time being, it is being developed intensorflow/tensorflowand distributed astensorflow.keras. In this future, thekeraspackage on PyPI will be the same astf.keras."
결국 multi-backend를 더 이상 지원하지 않고 오로지 tensorflow backend만을 지원할 것이라고 선언했습니다. 기존에는 Keras-team/keras라는 repo에서 다양한 backend를 지원하는 keras API를 업데이트하고 있었는데, 이제는 tf.keras에서 keras 관련 기능들을 업데이트 할거라고 명시했습니다.
다시 말해,keras-team/keras 저장소는 오로지 tensorflow만을 위한 tensorflow 백엔드 전용 Keras 되고 tf.keras가 keras-team/keras를 사용할 것으로 예상되었습니다.
3. Keras separate from Tensorflow 2.6 (2021.06.30)
아래 박혜선님의 글을 인용하면 올해(2021) 초부터 keras-team/keras 저장소의 코드가 다시 채워지고 있었다고 합니다. 당시에는 tf.keras 코드를 기반으로 keras-team/keras에 코드를 그대로 복사 붙여넣기 하여 싱크를 맞추는 작업(복붙)이 대부분이였다고 하네요. 그래서 tensorflow 2.5를 설치하면 keras-nightly 패키지(←복사붙여넣기된 keras-team/keras)도 같이 설치가되어 별도의 패키지로써 제공했다고 합니다.
그리고, 2021.06.30일에 Tensorflow 2.6 버전이 release 되면서, tensorflow 진영에서 아래와 같은 선언을 하게 됩니다.
Keras has been split into a separate PIP package (keras), and its code has been moved to the GitHub repository keras-team/keras. → Tensorflow 2.6 버전부터 keras는 tensorflow 패키지에서 분리가 됩니다. 앞으로 tensorflow 2.6 이후 부터 업데이트되는 Keras 관련 코드들은 다시 keras-team/keras로 옮겨진다고 하니 앞으로 "import keras"를 다시 사용해야 할 것 같습니다.
The API endpoints fortf.kerasstay unchanged, but are now backed by thekerasPIP package. All Keras-related PRs and issues should now be directed to the GitHub repository keras-team/keras.
두 번째 방식. loss instance 생성 후, compile 함수에 있는 loss 속성에 앞서 생성한 loss instance를 기재
loss = CategoricalCrossentropy()
model.compile(loss=loss, optimizer='adam', metrics=["accuracy"])
Q. tf.keras.losses 부분 보면 bianry_crossentropy는 function이고, BinaryCrossentropy는 class로 되어 있는데, 이 두 가지가 어떤 차이가 있는지 모르겠네요. 어느 사이트 보면 function으로 선언한 경우 accuracy가 더 떨어져서 나온다는 말도 있는데, 정확히 어떤 차이가 있는건지...
1-2. 세 가지 기본 Loss function 소개
앞서 tensorflow에서 제공한 기본 loss 함수 중에, 딥러닝 분류 목적으로 사용하는 대표적인 loss function은 3가지 입니다.
1) Binary Crossentropy
Tensorflow에서 제공하는 BinaryCrossentropy는 2가지의 클래스를 구분하는 task에 적용할 수 있는 함수입니다.
이미지 출처: https://gombru.github.io/2018/05/23/cross_entropy_loss/
2) Categorical Crossentropy
3개 이상의 클래스를 classification 할 경우 우리는 이를 multiclassification이라고 합니다.
이 경우에는 tensorflow에서 제공하는 CategoricalCrossentropy를 적용해주어야 합니다.
이미지 출처: https://gombru.github.io/2018/05/23/cross_entropy_loss/
3) SparseCategorical Crossentropy
10개의 클래스를 분류한다고 한다는 가정하에 아래 그림에 있는 기호를 간단히 표현하면 다음과 같습니다.
t → label=answer → [0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
y → probability = predict → [0.1, 0.05, 0.05, 0.1, 0.1, 0.3, 0.1, 0.05, 0.05, 0.1]
아래의 CategoricalCrossentropy 수식을 보면 사실 6번째 해당하는 class를 제외하면 모든 t는 0이기 때문에 loss function에 아무런 영향도 미치지 않습니다. 사실상 6번째에 해당하는 t, y 값만 고려해주고 나머지는 무시해줘도 되는 것이죠.
예를 들어, if 문을 이용하여 정답에 해당하는 label에 대해서만 "loss=-t×log(y)" 를 적용해주면 속도도 더 빨라지게 되는데, 이러한 방식의 loss function을 SparseCategoricalCrossentropy 라고 합니다. (실제로 DNN을 hardcoding 했을 때, CategoricalCrossentropy와 SparseCategoricalCrossentropy 학습 결과에는 변함이 없었습니다. 또한, 실제로 돌려보면 SparseCategoricalCrossentropy 방식으로 hardcoding 했을 때 좀 더 학습 속도가 빨랐습니다)
1-3. Label smoothing
Tensorflow 기본 loss API에서는 label smoothing을 쉽게 적용할 있게 구현해 놨습니다.
loss = CategoricalCrossentropy(label_smoothing=0.1)
model.compile(loss=loss, optimizer='adam', metrics=["accuracy"])
For example, if 0.1, use (0.1 / num_classes) for non-target labels and (0.9 + (0.1 / num_classes)) for target labels. (참고로 non-target labels의 확률값은 uniform distribution을 따릅니다)
이미지 출처: https://towardsdatascience.com/label-smoothing-make-your-model-less-over-confident-b12ea6f81a9a
참고로 앞서 설명한 SparseCategoricalCrossentropy의 기본전제는 hard label이기 때문에, label smoothing 속성이 왜 없는지 쉽게 파악할 수 있습니다.
hard label: 실제 정답외에 모든 label 값은 0으로 설정하는 방식
1-4. Extra loss functions by Tensorflow addons
Tensorflow 기본 loss API외에 SIG라는 곳에서 추가적인 loss function 들을 구현해 tensorflow에 contribution하고 있습니다. 예를 들어, 최근에 contrastive loss 도 주목을 받고 있는데, 이러한 loss를 Tensorflow Addons (by SIG) 에서 제공하는 API를 이용해 사용할 수 있습니다.
우리가 사용할 loss function이 앞서 소개된 기본 loss function에 없다면 우리가 스스로 만들어야 합니다.
대부분 정해진 task에 의해 기본적인 loss function을 쓰는 것이 보편적이지만, 종종 자신만의 loss function을 만들어 사용하는 경우도 있습니다. 예를 들어, Semi-supervised loss function, focal loss function과 같은 경우는 tensorflow에서 기본적으로 제공되는 loss function이 아니기 때문에 사용자가 직접 함수를 만들어 사용해야 합니다.
예를 들어, hubber loss라는 것을 만들어 사용하려면 아래와 같이 작성해주면 됩니다.
※Learning rate warm-up도 굉장히 자주쓰이는 트릭인데, tensorflow에서 기본적으로 제공해주는 방식은 없는 듯합니다. Github에서 다운받거나 아래 사이트를 참고하여 직접구현해주면서 사용해야 할 듯 합니다 (Pytorch는 굉장히 쉽게 사용할 수 있게 되어 있는데, tensorflow로 쓰려니 참...)
(↓↓↓아래 사이트에서 learning rate warm up 코드 부분을 참고해주세요!↓↓↓)