Q. 왜 단층 Perceptron 모델에서 Layer를 추가하게 되었나요?
Q. Universal Approximation Theorem은 뭔가요?
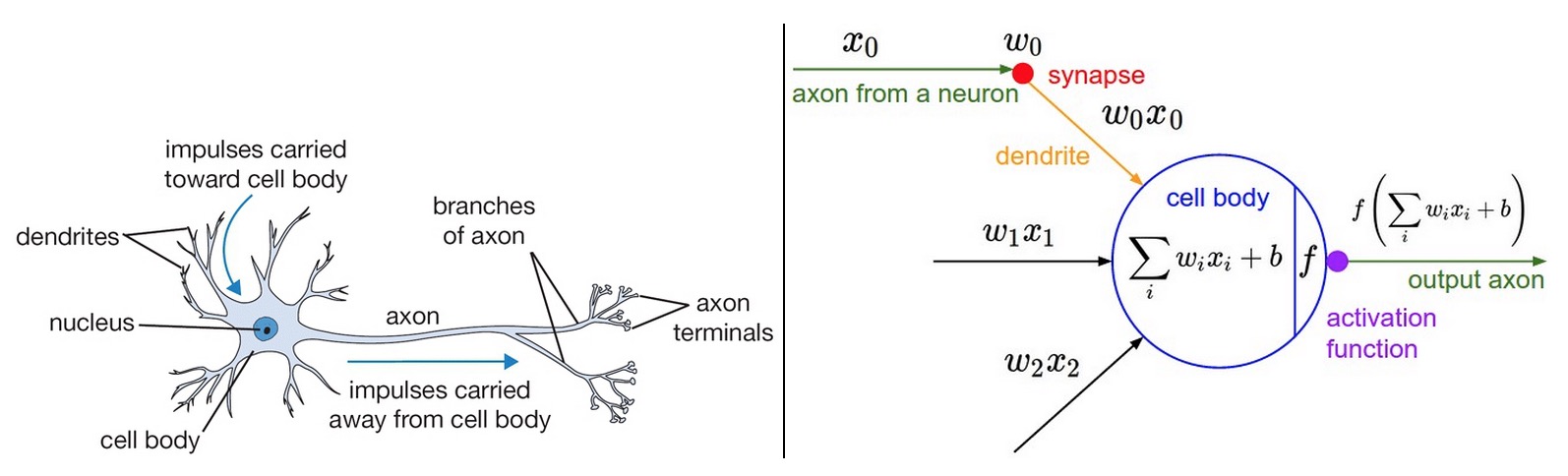
2~4장까지 배웠던 부분을 아래와 같이 하나의 그림으로 요약을 할 수 있습니다.
1.입력값들이 가중치를 곱합니다(=aj) 결과가 aj로 표현되고
2. aj는 activation function 'f'를 통과하고 자신들이 예측한 값 yj을 도출합니다.
3. 실제 정답 값 tj의 오차값을 (문제정의에) 알맞은 cost function을 통해 도출(=ej=(tj-yj)^2/2)합니다.
4. 오차값(ej)을 기반으로 backprogation을 통해 가중치 w를 업데이트 함으로써 학습진행하게 됩니다.

<사진1>
이러한 Perceptron은 많은 문제를 해결해 줄 것으로 기대했어요. 예를들어 두 개의 입력값 x1, x2 ∈ {0,1} 중 하나만 1이라는 입력이 들어오면 1이라는 결과를 도출하는 OR 문제같은 경우나, 두 개의 입력값이 모두 1이어야만 1이라는 결과를 도출하는 AND 문제와 같은 경우는 쉽게 해결이 가능했어요.
x1을 X로, x2를 Y라고 하고 Y를 C라는 임의의 상수라고 표현하면 activation function을 거치기 직전인 w1X+w2Y=C 라는 식이 만들어 지겠네요. 그런데 왼쪽 식을 Y=(-w1X+C)w2 라고 바꿔주면 직선의 방정식 (linear) 이 되는 것을 볼 수 있죠?
충분히 두 개의 입력으로 구성된 perceptron으로 문제 해결이 가능해졌어요.


<사진2>
하지만 XOR 문제를 푼다라고 가정해봅시다. 두 개의 독립변수 x1, x2 ∈ {0,1} 가 입력으로 받아들여지고 이 두 개의 입력중 오직 하나의 입력만이 1인 경우에만 1이라는 결과를 출력할 수 있는 문제입니다. 이를 간단히 표현하면 아래와 같이 표현할 수 있겠네요.
그런데 우리가 정의한 문제공간(Original x space = 사진2 '가운데 그림')은 직선으로는 구분하게 힘들어 보여요. 물론 w1x1+w2x2=c 라는 식이 non-linear한 성격인 activation function을 거치면 어떤 곡선을 나타내는 식이 만들어져 XOR 문제를 해결할 수 있겠지만 현재 우리가 알고 있는 activation function으로는 힘들다고 해요. (제 생각으로는 activation function이 직선형태(linear)라고 할 수는 없지만, ReLU, Leaky ReLU 와 같은 함수들은 영역에 따라 상당히 linear(직선)한 성격을 갖고 있어요. 그래서 아래와 같은 문제를 해결할 수 없는거 같아요)

<사진2>
이렇게 간단한 문제조차도 해결하지 못했기 때문에, 신경망 연구는 더이상 지속되기 힘들다고 했지만 단순히 Layer를 추가 함으로써 위와 같은 문제를 쉽게 해결할 수 있게 되었어요.
우선 기존의 perceptron 모델은 input layer 하나만 있었다면, 우리는 hidden layer라는 층을 추가해서 layer를 2개 이상으로 만들거에요 (=Multi-Layer Perceptron). 그리고 W, w, c는 이미 학습을 완료했다고 가정하고 그림으로 요약하면 아래와 같아요.

<사진3>
처음에 "WX+c --> activation function"과정은 perceptron에서도 봤던 과정이에요. 그런데, 이렇게 한번 거치고 나면 "Original x space->Learned h space"로 문제공간이 변경된 것을 볼 수 있을거에요. 이렇게 변형된 "Learned h space"를 보면 직선(linear)하게 문제를 해결할 수 있게됩니다.

<사진4>
위와같이 문제공간을 변형시키는 트릭을 Kernel trick이라고도 부르는데요. 보통은 문제공간의 차원을 변형시켜서 푸는 방법을 의미합니다. 알아두시면 좋아요!

<사진5. Kernel trick>
Hidden layer를 하나 추가함으로써 non-linear한 문제를 아래와 같이 풀 수 있게 되었어요!

<사진6>
결과적으로 이야기하자면 layer를 하나 더 추가(hidden layer)함으로써 non-linear problem을 linear problem으로 변경해주게 되는데요. 이렇게 layer를 추가해준다는 개념은 linear한 성격만 지닌 perceptron에 non-linear한 성격을 마구 부과해주는 역할로 이해될 수 있어요. (아래의 그림을 보면 더욱 직관적으로 이해하실거에요!)


<사진7>
이전장에서 activation function에 대한 큰 의미가 non-linear한 성격을 지니는 것이라고 언급한바 있죠? 이제는 이해가 되시나요? activation function이 없다면 아무리 layer를 추가한들 "f(x)=ax+b, h(x)=cx à y(x)=h(h(h(x)))=c×c×c×x=(c^3)x --> a=c^3 or "a and c are constant" 라고 한다면 결국 같은 linear 한 성격만 갖게 됩니다. 즉, 아무리 hidden layer를 추가한들, activation function이 없다면 MLP 또한 linear한 문제밖에 풀지 못할거에요! (예를들어 위에 사진5 수식에서 ReLU안에 인자들이 ReLU를 거치지 않고 모두 더해진다고 생각해보세요. 결국 또 직선의 방정식이 나올거에요!)
지금까지 설명한 것을 요약하자면, "activation function을 포함한 다수의 layer를 갖고 있는 MLP는 non-linear한 문제를 풀 수 있다"정도가 되겠습니다. 그리고, 이러한 설명을 하나의 이론으로 설명하고 있는것이 있는데 그것이 바로 'Universal approximation theorem'입니다.
아래글은 위키백과에 나온 universal approximation theorem을 인용한 것 입니다.
"In the mathematical theory of artificial neural networks, the universal approximation theorem states[1] that a feed-forward network with a single hidden layer containing a finite number of neurons can approximate continuous functions on compact subsets of Rn, under mild assumptions on the activation function. The theorem thus states that simple neural networks can represent a wide variety of interesting functions when given appropriate parameters."
"activation function영향 아래에서 추가된 hidden layer는 연속함수를 근사화할 수 있고, 이에 따라 적절한 가중치가 주어진다면, 다양한 함수들(with non-linear function)을 표현할 수 있다"
그럼 지금부터 요약을 해볼께요. 우선 지금까지 배운 MLP를 아래와 같은 그림으로 나타낼 수 있겠어요!

<사진8>

<사진9>
앞에선 하나의 hidden layer만 추가했지만, layer가 더 깊이 쌓여지면 쌓여질수록 deep한 neural network(신경망)이 많들어질거에요. 그리고 우리는 이를 deep neural network (DNN)이라고 부르고, 오늘날 딥러닝이라는 학문의 핵심적인 모델이됩니다.

<사진10>
현재 딥러닝에서 언급하고 있는 Artificial Neural Network (ANN)은 Multi-Layer Perceptron (MLP) 또는 Deep Neural Network (DNN)이라는 용어와 동일하게 사용되고 있어요.
그런데, 무조건 layer를 추가한다고 좋을까요? 계속 추가하게 되면 가중치도 많아지고 뭔가 복잡해질것같지 않나요? 시스템이 복잡해지면 학습이 잘 될까요?
위와같은 질문때문에 DNN에서 어떻게 하면 학습을 더 잘시킬 수 있을지에 대해 많은 방법론이 나오고 있어요. 그리고 다음장에서는 이러한 방법론중 가장 대표적인 '정규화(Regularization)'에 대해서 알아보도록 할거에요!
#Multi-Layer Perceptron #Universal Theorem #Activation function #Non-linearity #Kernel Trick
[사진 래퍼런스]
사진1
https://blog.yani.io/backpropagation/
사진2
http://www.birc.co.kr/2018/01/22/xor-%EB%AC%B8%EC%A0%9C%EC%99%80-neural-network/
사진5
http://solarisailab.com/archives/2552
사진6
https://towardsdatascience.com/the-magic-behind-the-perceptron-network-eaa461088367
사진7
https://towardsdatascience.com/can-neural-networks-really-learn-any-function-65e106617fc6
사진8
딥러닝 제대로 시작하기
사진9
사진10
http://neuralnetworksanddeeplearning.com/chap6.html
'딥러닝 이론 > Deep Neural Network (DNN)' 카테고리의 다른 글
| 7. Curse of Dimension, Reduction of input dimension (차원의저주) (2) | 2020.01.05 |
|---|---|
| 6. 학습을 잘 시킨다는 것은 무엇을 의미하나요? (Regularization, Generalization(일반화)) (1) | 2020.01.02 |
| 4. Activation Function은 왜 만들었나요? (4) | 2019.12.31 |
| 3. 학습을 하는 목적에 따라 cost function이 달라진다구(최대우도법, Cross Entropy)? (0) | 2019.12.30 |
| 2. 기계가 학습(Learning)이 가능하다고? (L1, L2 loss (MSE)) (0) | 2019.12.16 |

 6. Backpropagation (2).pdf
6. Backpropagation (2).pdf



























{kind=link}