안녕하세요~ 지난 시간에는 DNN의 일반화성능을 높이기 위해 Regularization 기법에 대해서 알아보았어요. 또한 L1 regularization 기법이 낮은 가중치를 0으로 만드는 경향이 있어 입력차원을 줄여주는 효과를 얻을 수 있다고 했었던거 기억하세요?
이번장에서는 입력차원을 줄여주는것이 왜 효과적인지, 이것이 딥러닝 성능을 어떻게 높여준다는것인지 알아볼거에요.
위키백과에서 내린 차원의저주 정의는 아래와 같아요. 쉽게 말하자면 데이터의 차원이 증가하면 이것을 표현하기 위한 데이터양이 기하급수적으로 올라간다는 뜻이에요.
"The common theme of these problems is that when the dimensionality increases, the volumeof the space increases so fast that the available data become sparse. This sparsity is problematic for any method that requires statistical significance"
먼저, 아주 간략하게 설명을 해보도록 해볼게요.
우리에게 4개의 데이터가 있다고 가정해볼게요. 그리고 모든 축의 길이가 2인 2차원공간과 3차원공간에 4개의 데이터를 집어넣을거에요. 왼쪽그림에서는 면적당 데이터가 차지하는 밀도는 1이겠네요. 우측그림에서는 면적당 데이터가 차지하는 밀도가 1/2일거에요. 그렇다면 공간의 차원이 높아질 수록 같은 데이터량이라고 할지라도 (데이터가 공간을) 차지하는 비율이 낮아진다고 할 수 있겠죠?
우리가 30개의 데이터를 갖고 있는다고 했을때보다 1000개의 데이터를 갖고 있을때 overfitting이 일어날 확률이 더 적을거에요 (이에 대한이유는 앞선글의 가위 예시를 통해 이해해주시면 좋을것 같아요). 결국엔 같은 공간차원이라고 해도 데이터가 더 적을수록 overfitting이 일어나게되고, 이것을 일반화해서 설명하면 "데이터가 공간상에서 차지하는 비율이 적을 수록 상대적으로 overfitting이 일어날 확률이 높다"라고 할 수 있어요.
.
.
.
.
.
.
이제부터는 위에서 언급한 내용들을 조금 더 자세히 풀어 설명해보도록 할께요.
먼저 어떤 사람에 정보에 관한 데이터를 갖고 있다고 가정해볼께요. 그리고 사람정보(X)에는 나이(=x1), 키(=x2), 몸무게(=x3)가 들어가 있다고 합시다. 그렇다면 사람정보 데이터 X는 아래와 같이 3차원 공간상에서 표현이 가능하겠네요? 그리고 다음과 같이 표현 할 수 있을 겁니다 --> X=(x1,x2,x3)
우리는 앞으로 데이터 X를 이루는 3가지 조건인 x1,x2,x3의 총 갯수를 데이터 건수라고 명명할거에요. 그러니까 여기 3차원 데이터에서 데이터 건수=3이 되겠네요.
<사진1>
이때, 1명의 사람에 대한 데이터를 수집했다고 해볼께요. X데이터는 3개로 나누어지니 각각의 공간은 33%의 비율을 갖고있을 겁니다. 만일 데이터건수가 2라고 한다면 각각의 공간은 50%의 비율을 차지하고 있겠네요.
<사진2> <사진3>
만약 어떤 데이터가 27차원으로 이루어져있다고 해봅시다. 만약으로가 어떤 서로다른 특성을 갖는 데이터 I=(I1,I2,I3), J=(J1,J2,J3), K=(K1,K2,K3)를 조합하여 입력데이터를 사용한다고하면 아래와 같이 구성이 가능해 질 겁니다.
<사진4>
이때는 하나의 데이터건수가 갖고 있는 공간비율이 1/27 = 0.037 이 되겠어요.
예를들어, 우리가 6명의 사람에 대한 데이터를 수집한다고 해볼께요. 먼저 데이터가 3차원으로 구성된다고 하면 3가지 데이터조건에 6명을 채우는게 됨으로 실제 3차원 공간에서 6/3=200% 공간을 채울 수 있게되요. 이 말을 바꿔말하자면 6명의 데이터는 3차원 공간을 200% 채울 수 있다는 뜻으로 풀이할 수 있습니다.
그런데, 27차원인 경우에는 어떻게 될까요? 6/27=0.22=22%의 공간밖에 채우질 못하네요.
이처럼 수집된 데이터 건수는 동일하더라도 입력데이터 차원이 증가하면, 데이터 공간을 채우는 비율이 줄어들기 때문에 분석에 요구되는 데이터 수도 증가하게되요.
만약 1가지 데이터 건수에 최소 30건의 데이터가 있어야 분석이 용이하다고 했을 때, 3차원의 입력데이터는 3*30=90 개의 데이터 (건수)가 필요하고, 27차원 입력은 27*30=810건의 데이터 (건수)가 필요하게 됩니다.
언뜻보면 데이터건수가 많아지면 데이터를 표현하는 정보가 많아져 분석에 더 유리할 것 같이 보이시나요?
그런데 자세히 보시면 입력 데이터의 차원이 커지게 되면 데이터 건수가 많아지므로 하나의 데이터건수가 갖는 공간비율도 점점 줄어들게 되고, 분석에 필요한 데이터 건수도 기하급수적으로 늘어나게 됩니다.
딥러닝 관점에서 해석을 다시 해볼께요. 우리가 어떤 Deep Neural Network모델을 학습시키고 분류하는 성능을 테스트 해본다고 가정해봅시다. 먼저 1차원 입력데이터 30개를 Deep Neural Network로 학습을 시킨 후, 학습데이터가 아닌 데이터로 검증을 했다고 해봤을 때 문제없이 동작을 합니다. 그런데, 27차원으로 표현되는 입력데이터 30개를 학습시킨 후 테스트를 해보면, 학습된 30개의 데이터에 대해서는 무리없이 잘 분류하는데 다른 학습데이터로 검증을 한다고 하면 잘 분류를 하지 못하는 현상이 벌어지곤 합니다. 다시말하자면, 입력 데이터의 차원이 증가했는데 데이터 수가 부족하니 학습데이터만 잘 구분하도록 모델이 학습데이터에 편중 되었네요. 이 역시 Overfitting입니다.
아래 사진을 보면 입력데이터가 일정한 차원 수를 넘어가게되면 분류성능이 급격하게 떨어지는 것을 볼 수 있어요.
<사진5>
이전장에서 L1 regularization이 낮은 가중치를 0으로 만드는 경향이 있다고 했죠? 사실 낮은 가중치는 딥러닝 모델에서 큰 부분을 차지하지 않아요. 예를들어, 가중치가 0.00000000000001이라고 한다면 아무리큰 입력값이 곱해져도 그 결과가 0에 수렴할거니까요. 만일 가중치가 0이 된다면 결국 입력차원이 줄어들게 되고, 분석에 필요한 데이터량이 줄어들 수도 있겠네요.
또는 복잡한 딥러닝 모델을 좀 더 simple하게 만드는 효과도 불러일으킬 수 있겠네요.
<사진6>
이렇게 딥러닝에서 데이터의 차원이나 딥러닝 모델의 파라미터를 줄여주려는 노력은 계속되고 있어요. 일반화성능을 위해서도 줄여주려고 하는 것도 있지만, 딥러닝 모델의 속도를 향상시키거나, 제한적인 데이터량을 극복하려고 하는 등의 여러 이점이 있기 때문에 이와같은 노력이 지속되고 있어요.
이제 이번장에 기술했던 글을 요약해볼께요~
1. 주어진 데이터 샘플에 대한 세밀하고 밀도 있는 데이터 (=고차원 데이터)는 많은 정보를 담고 있지만, 딥러닝 모델 관점에서 고차원 입력데이터는 부작용을 일으킬 가능성이 더 높아요.
2. 즉, 고차원 입력데이터일수록 훨씬 더 많은 데이터량이 필요하게 되는데, 이것을 차원의 저주라고해요.
3. 하지만 현실적으로 방대한량의 데이터를 모으는데 힘든 부분이 많아요.
4. 또한 입력차원의 데이터가 고차원이어도 실제분석에서는 저차원으로 구성된 데이터가 더 분류성능을 높일 수 있어요. 왜냐하면 가끔씩 우리가 품질좋은 세밀하고 밀도 있는 데이터를 구성했다고 하지만, 그건 언제나 우리관점에서에요. 그러니까, 없어도 되는 변수들을 데이터에 추가했을 가능성도 있어요 (오히려 분류에 방해되는 변수를 넣을 가능성도...).
5. 이러한 이유들 때문에 어떻게든 입력데이터의 차원을 줄여주는 노력들을 하고 있어요.
-Feature extraction: PCA
-Feature selection: Correlation Analysis, VIF(Variance Inflation Factor), Random Forest
(위에 있는 개념들은 사실 선형대수나 Machine Learning에서 주로 다루는 개념이에요. 그래서 이 부분은 나정에 관련 챕터를 개설하게 되면 그때 설명하도록하고 지금은 이러한 기법들이 사용되고 있구나 정도만 알고있으면 될 것 같아요)
이번장에서는 Curse of Dimension에 대해서 알아보았어요. 다음장에서는 지금까지 배운내용을 전체적으로 요약정리하면서 디테일한 수식들을 사용해보도록 할게요!
이전글에서 대만이 일본의 식민지하에 있었으면서 일본을 긍정적으로 생각을 했는지에 대해서 설명하고 이와 관련된 재미있는 이야기들을 하려고 합니다~
이전에 대만의 역사에 대해서 다시 리마인드 해볼께요~
원주민들이 서식 -> 스페인과 네덜란드의 침략으로 못살게 굼 -> 명나라의 침략으로 못살게 굼 -> 청나라의 침략으로 못살게 굼
ㅎㅎ
매우 간단히 요약했죠?
사실 대만이라는 곳은 본래 원주민들의 나라에요. 그런데 여기저기서 침략해오고 자신들의 문화도 무시하고점령하니 기분이 좋진 않았겠죠??
그런데 1895 청일전쟁 이후 일본에게 패한 대만이 시모노세키 조약에 의해 대만을 할양받게 됩니다.
대만도 1895년 타이완 민주국 수립 선포, 1915년 티파니 사건과 같은 역사적 사건을 통해 항일운동을 벌이곤 했습니다.
조선도 처음에는 강압적으로 무단통치를 하다가 문화통치와 같은 유화정책을 펼쳤죠? 대만에서도 같은 일이 벌어지게 되는데요. 1922년 일본은 대만에 일본과 같은 법제도를 적용하면서 동화정책을 펼치게 됩니다.
이 과정에서 대만사람들은 지난 스페인, 네덜란드, 명나라, 청나라에게 받은 핍박에 비해 자신들에게 잘해주는 일본이 밉진 않았던거 같아요~ 아래 영상을 보면 좀 더 쉽게 이해하실 수 있으실 거에요!!
이번 대만 여행에서 방문했던 스펀폭포에 있는 철도와 진과스에 있는 일본식 가옥들을 보면서 일본의 흔적들을 많이 살펴볼 수 있었어요.
또 재미난 사실은 대만의 유명한 망고빙수도 일본 식민지 시절의 흔적이라고 하더라구요. 일본은 청일전쟁 승리로 열대과일과 설탕을 대량으로 들어왔는데 이때부터 일본에서는 열대과일을 첨가한 '가키고오리'라는 빙수가 대중적인 간식으로 자리잡았다고해요~
그리고 아래사진은 지우펀이라는 곳인데, 일본의 애니메이션 '센과치히로의 행방불명'의 배경이 됐던 장소에요. (사람이 너무 많아서 큰일날뻔 했어요 ㅜㅜㅜㅜ) 지우펀에 대한 여러 설명들이 있는데 이러한 설명들은 유튜브를 참고하시는게 더 좋을 듯 해요! (여긴 역사관점에서 주로 다루는 블로그라 ㅜㅜ)
당시 일본은 한국과 대만을 다른 태도로 식민지배를 했어요 (물론 대만도 무단통치-문화통치-민족말살정책 과정을 거쳤지만요).
"그 이유는 경제적인 관점에서 일본과 조선은 대치관계에 있었고, 대만은
일본과 대체관계에 있었기 때문에 조선에 대해서는 좀 더 강경한 정책을 대만에 대해서는 좀 더 유한 정책을 펼쳤다는 이야기가 있어요. 일본이 조선에 자립할 만한 산업으로 홍삼, 금광 정도가 있었는데
원하는 만큼 수익을 기대하긴 힘들었는데,그나마 수익을 기대할 만한 사업이 초기에는 쌀농사, 중후기에는 중공업등이 있었다고 해요. 이것은 일본 산업과 경쟁관계에 놓인 산업이었죠.
하지만, 대만의 경우는 막대한 설탕, 아편 그리고
각종 상품성 작물 등의 재배가 주요 산업이었는데 이것들은 일본 본토와 경쟁 관계게 놓여있지 않고 대체관계에 놓여있었다고해요. 덕분에 대만에 있는 대만 (일본)
총독부는 10년만에 자립을 할 수 있게 되었다고합니다 (인구수도
대만이 더 적어 일본 입장에서는 먹여살릴 부담도 적었다고 해요).
추가적으로 일제강점기 시대의 한국과 대만이 갖고 있던 일본에 대한 인식을 잘보여주는 재미있는
사례가 있는데 그것이 한국의 최고의 대학 서울대학교, 대만의 최고의 대학 국립타이완대학이에요. 일본은 제국주의를 강화하기 위해 교육에 열을 올리고 있었는데 그것이 제국대학령이었어요. 일본에 7개 대학 (7개의
대학을 ‘칠제대’라고 한다.
일본의 아이비리그) ‘도쿄제국대학(1886; 현
도쿄대학)’, ‘교토제국대학(1897; 현 교토대학)’, ‘도호쿠제국대학(1907; 현 도호쿠대학)’, ‘규슈제국대학(1911; 현 규슈대학)’, ‘훗카이도제국대학(1918; 현 훗카이도대학)’, ‘오사카제국대학(1931; 현 오사카대학)’, ‘나고야제국대학(1939; 현 나고야대학)’와 식민지 2곳에 각각 하나의 대학을 설립했는데,그 중 하나가 경성제국대학 (1924), 다이호쿠제국대학 (1928) 이다. 이 두 대학은 오늘날 서울대학교와 국립타이완대학이라고
불리고 있는데, 서울대학은 경성제국대학을 자신들의 전신이라고 인정하지 않는데 반해 국립타이완대학은 다이호쿠제국대학을
자신들의 전신으로 인정하고 있는 차이를 보인다고 합니다." --> https://namu.wiki/w/%EB%8C%80%EB%A7%8C-%EC%9D%BC%EB%B3%B8%20%EA%B4%80%EA%B3%84
이번여행을 하면서는 '왜 우리는 아직도 그 시절의 잔재에 대해 저항을 하고있고, 대만은 아직도 일본을 그리워하는지'에 대한 생각에 잠겼던것 같아요.
이러한 태도들이 오늘날 한국과 대만의 경제격차를 불러일으킨거라고 연결짓기는 힘들지만, 그래도 계속 여러 생각을하게 만들더라구요. 민족성을 지키려는 의지에서 차이가 있었던건지, 아니면 단지 우연이었던건지..
당시에 여행을 마치고 숙소에 들어와 이런 질문들을 하고 복잡한 생각을 하고 있을때 우연히 암살 영상을 보게됐는데, 그냥 그때 생각나서 링크 걸어놨어요ㅎㅎ
안녕하세요~ 이번장에서는 다클래스분류에서 쓰이는 Cross Entropy가 지니는 본질적인 의미에 대해서 설명해 볼거에요. 사실 Cross Entropy는 정보이론(Information Theory)분야 뿐만아니라 열역학 분야에서도 쓰여요. 하지만 이번장에서는 딥러닝과 관련이 깊은 정보이론분야의 Cross entropy 개념에 대해서 알아볼거에요.
먼저 정보이론에 대한 기초개념을 간단히 살펴본후, Entropy라는 개념을 살피고, Cross Entropy에 대해서 설명해보도록 할께요!
<1.Information Theory; 섀넌의 정보이론>
처음으로 소개해드릴 개념은 '정보량'이라는 개념이에요. 두 개의 메시지를 받았을 때, 어떤 메시지가 정보량이 더 많다고 할 수 있을까요? 아래의 예시를 통해 알아보도록 할께요.
우리가 예(1), 아니오(0)로만 대답할 수 있는 스무고개를 한다고 해봅시다. A커튼 뒤에는 강아지가 있고, B커튼에는 알파카가 있다고 할께요. A커튼 뒤에 있는 강아지는 4번만에 맞췄고, B커튼 뒤에있는 질문은 16번만에 맞췄습니다. 우리가 강아지를 알아내기 위해서는 4비트의 정보가 필요해요. 왜냐하면 예, 아니오라는 질문을 한 번 할때마다 1bit(={0,1})가 필요하다고 보면되니까요. 그렇다면, 알파카를 알기 위해서는 16개의 비트가 필요하겠죠? 이때, 알파카의 정보량이 더 많다고 할 수 있겠어요.
그런데, 이것을 좀 더 다른관점에서 보도록 해볼게요. 질문이 많다는건 다른말로 표현하면 상대적으로 불확실성이 높다는 말로 표현할 수 있어요. 커튼뒤에 강아지가 있을 때보다 알파카가 있을때 답을 맞출 확실성이 떨어져요(=불확실성이 높아져요).
섀넌은 이러한 관계성을 통해서 '정보량=불확실성'이라는 개념을 소개하게 되요. 즉, 불확실성이 높을 수록 또 불확실성이 높아진다는 이야기에요.
일반적으로 정보량을 메시지의 정보량에 빗대어 설명해요. 예를 들어, 전체 메시지 중에서 "했"일아는 단어가 나오면 "습니다"라는 단어가 나온다는 것을 쉽게 알 수 있어요. 그러므로, '했' 다음에 오는 '습니다'라는 부분이 메시지에서 지워졌다고 해도 전체 메시지 내용을 파악하는데 큰 어려움은 없을거에요.
다른 관점에서보면 전체 메시지에서 명사와 동사만 알고 있어도 전체 메시지 내용을 파악하는데 어려움이 없다는 결론을 도출할 수 있게 됩니다. 왜냐하면 우리는 명사, 동사 뒤에 어떤 '조사'가 나오는지 쉽게 알 수 있기 때문이죠. 그리고 이렇게 판단하는 이유는 명사, 동사 뒤에 오는 '조사'가 빈번하게 우리눈에 목격됐기 때문이에요. 우리는 이런경우 '조사'를 redundant한 정보라고 불러요.
즉, 전체 메시지에서 잦은 단어는 정보량이 적고, 드문 단어는 정보량이 많다는 관계를 만들어 낼 수 있어요. 그리고, 이전에 설명했던 불확실성과 연결지으면 아래와 같은 관계를 성립시킬 수 있겠네요.
정보량↑ = 빈번하지 않은 정보 = 불확실성 ↑
그렇다면 정보량은 수식으로 어떻게 표현할까요? 먼저 이전에 설명했던 강아지와 알파카의 예를 들어 봅시다. 우리가 강아지를 맞추기 위해서 총 4번의 질문을 했어요. 그런데 사실 4번의 질문으로 얻을 수 있는 대답의 경우의수는 N=2^4 이에요. 그럼 아래사진과 같이 그림을 그려볼 수 있고, log2N=k bit 라는 수식을 만들 수 있어요. (질문의 수=k, 질문을 통해 얻을 수 있는 대답의 경우의 수=N)
<사진1>
위의 그림을 보면 강아지를 맞출 확률은 'p(x)=1/16'이겠네요. 그럼, -log2p(x) 라고 표현하면 4라는 수가 나오겠죠? 그래서 정보량의 수식을 아래와 같이 표현해요.
<2. Entropy>
정보량에 대한 개념을 알아보았으니 Entropy라는 개념에 대해서 알아보도록 할께요. 결론부터 이야기하자면 엔트로피는 정보량의 기대값(평균)을 의미해요.
섀넌이은 이러한 Entropy를 통해 distribution을 표현했는데요. 섀넌 엔트로피 distribution은 아래와 같이 설명될 수 있겠어요.
"사건의 분포가 결정적(사건에 대한 확률이 어느 한쪽으로 치우친 정도->ex: 동전 4번 던졌을 때, 앞이3번 나오면 다음에도 앞이 나올 확률이 크기 때문에 치우친 정도가 큼)이라면 해당 확률분포의 불확실성 정도 (정보량)을 나타내는 엔트로피는 낮아진다. 반대로 사건의 분포가 균등적(ex: 동전 4번 던졌을 때 앞2번, 뒤2번으로 확률이 어느 한쪽으로 취우쳐지지 않음)일 수록 엔트로피는 높아진다"
<사진2>
정리하는 차원에서 하나의 예시로 연결지어 설명해볼께요. 아래 '사진3', '사진4'가 있습니다. '사진3'에서는 다음날 해가 뜨거나 비가 올 확률을 동일하게 봤네요. '사진4'에서는 해가 뜰 확률을 더 높게 봤습니다. 그렇다면, 여기에서는 사건이 비가오거나 해가오는 경우인데, 각각의 사건에 대한 확률이 '사진3'과 '사진4'처럼 설정되면 엔트로피는 어떻게 될까요? 당연히 각 사건에 대한 불확실성이 높은 '사진3'의 경우가 불확실성의 평균(기댓값)도 높게 나오겠죠? 이 말을 다르게 말하자면 '사진3'의 경우가 엔트로피가 더 높을거라는 말과 같네요. 그럼 한번 정말 그런지 살펴볼까요?
수식을 대입해보면 '사진3'의 기댓값은 1bit, '사진4'의 기댓값은 0.81bit가 나와요. 요약하자면, '사진4'의 경우가 정보량이 적다는 말인데, 그 이유는 당연히 다음날 해가뜰 확률이 더 높아져서 정보의 불확실성이 낮아졌기 때문이라고 할 수 있겠네요.
<사진3> <사진4>
<3. Cross Entropy>
엔트로피에 대한 개념을 이해했으니 이제는 Cross Entropy에 대한 개념을 살펴볼께요. Cross Entropy에 대한 개념은 아래영상으로 대체하려고해요. 정말 설명을 잘 해 놓으셨더라구요~
중간에 구체적으로 이해가 안되시는 부분이 있으실 수 있는데, 한번 영상을 끝까지 보시면 그래도 Cross Entropy에 대한 개념을 명확히 잡으실 수 있으실 거에요.
아래영상을 요약하자면 아래와 같습니다.
"Cross Entropy는 Estimated value (from Deep Learning Model)와 실제 정답이 되는 값 (딥러닝관점에서 학습데이터가 되겠네요) 이 서로 얼마나 근사한지를 보는것!"
나중에는 Cross Entropy를 KL-Divergence라는 개념과 비교하여 설명하긴 하는데, 추후에 KL-Divergence를 다루게 되면 그때 비교해서 설명해드릴께요!
지금까지 설명한 내용들은 아래영상을 차례대로 보시면 더 자세히 이해하실 수 있으실거에요. 그럼 이번장은 여기서 마칠게요~!
영어가 수월하신 분들은 아래 영상을 보시는걸 추천드려요. (영어를 잘 못하시더라도 자막보고 번역해가면 충분히 이해하실 수 있으 실 거에요!)
Feature selection을 하는데에도 PCA라는 개념이 설명되기도 하는데 PCA를 설명하려다보면 Covariance라는 개념도 설명해야되고 이러다 보면 선형대수에 대한 전반적인 이해도 필요하게돼요 ㅜㅜ 뿐만아니라, 다클래스 분류에 쓰이는 cost function에서는 정보이론에서 쓰이는 Cross Entropy라는 개념이 쓰이기도해요.
입력변수가 많아지면 다변수함수라는 개념이 쓰이기도 하고, 최적화된 학습을 하기위해서는 수치해석이나 다른 최적화이론들이 쓰이기도해요.
그럴때마다 이러한 수학적 개념을 딥러닝 이론을 설명하면서 함께 다루기에는 내용이 너무 방대해지기 때문에 따로 챕터를 마련하게 되었어요. 그래서 이 챕터는 순서는 따로 없어서, 필요한 개념만 그때그때 골라서 읽으시면 될거 같아요!
안녕하세요~ 이번에는 Deep Neural Network (DNN)을 학습 시키기 위해서 사용되는 regularization(규제화) 기법에 대해서 알아볼께요.
위키백과에서는 Regularization에 대한 개념정의를 아래와 같이 해놓았어요.
"Regularization is the process of adding information in order to solve an ill-posed problem or to prevent overfitting."
위의 정의를 알아보기 위해서 overfitting이라는 개념부터 알아보도록 할께요.
아래 두 그림 처럼 O,X를 구분하는 DNN을 학습시킨다고 해볼께요. 두 그림 중 어느 DNN 모델이 더 학습을 잘 한것 같나요? 물론 대다수 분들이 오른쪽이라고 할 거에요. 왜냐하면 완벽히 O,X를 구분했으니까요. 그런데 딥러닝에서는 일반적으로 왼쪽 그림과 같은 경우가 학습이 잘 됐다고 하는 경우가 많아요. 왜일까요?
<사진1>
위와같이 왼쪽 그림이 더 학습이 잘됐다고 판단을 하는 이유는 크게 두 가지에요.
첫 번째는 "우리가 학습하는 데이터에는 잘 못된 학습데이터들도 있을 것이다"라는 점이에요. 만약에 outlier 또는 noise(or 불순물)가 섞인 데이터가 포함되어 있다고 생각해봅시다. 위 그림을 예를들어보면 O에 깊숙히 침투해 있는 두 개의 X는 사실 불순물이 섞였을 가능성도 있는거에요. 이런 좋지 않은 데이터로 학습하면 학습결과가 좋지는 않겠죠?
두 번째는 "DNN 모델이 학습데이터에만 지나치게 편중하여 학습시키는 것이 좋지 않을 것이다"라는 점이에요. 예를 들어, 가위를 구별하려는 DNN 모델을 만든다고 가정해볼께요. 아래 가위를 학습데이터로 이용한다고 합시다. 아래 가위의 특징은 톱니모양, 검은색 및 동그란 손잡이 등등이 있겠네요.
<사진2>
자 이제 학습된 DNN 모델로 아래 사진들의 가위들이 가위인지 아닌지 구별해보려고 합니다. 자! 그럼 실행시켜볼께요~ 엥? 위에 학습된 DNN 모델이 아래 그림들에 있는 사물들이 가위가 아니라고 결론을 지었네요.. 왜일까요?
<사진3>
사람들은 대부분 위의 사물들이 가위라고 결론을 내리지만 학습된 DNN은 그렇지 않았어요. 그 이유는 학습된 DNN 모델이 지나치게 "사진2"에 있는 가위의 특징을 학습했기 때문이에요. 그러니까 "사진3"에 있는 사진들은 톱니모양도 없고, 손잡이도 검은색이 아닌경우도 있기 때문에 "가위"가 아니라고 결론을 내린거에요. 즉, '사진2'라는 데이터에 DNN 모델이 너무 편중되게 학습을 한 것인데 이러한 현상을 우리는 DNN모델이 학습 데이터에 overfitting 되었다라고 표현해요.
DNN 입장에서 엄밀히 말하자면 "내가 학습했던 이미지에서의 가위랑은 달라!"가 되겠네요. 그래서 우리는 DNN이 학습시 주어지는 학습데이터에만 너무 치중(specific)하지 않도록 하여 일반적(general)으로 판단할 수 있게 해주는 "일반화(Generalization)"성능을 향상 시키는것이 학습시 더 중요하다고 판단을 내린거에요. 즉, overfitting을 피한다는 것은 DNN의 일반화성능을 높인다는 말과 일맥상통해요.
그렇다면 이러한 일반화 성능을 향상시키는 방법에는 무엇이 있을까요?
다시 아래그림을 살펴볼께요. 오른쪽 그림은 학습데이터에 지나치게 편중된 모델이에요. 지나치게 편중되었다는 것은 DNN 입장에서 가중치값들이 지나치게 학습데이터에 편중되어 있다는 뜻과 같은 말이에요. 왜냐하면 DNN에서는 입력(학습데이터)는 항상 고정값이고 (이미지를 학습한다고 생각해보세요. 입력이미지값은 변하지 않아요!), 가중치를 업데이트해서 무엇가를 분류하기 때문이에요.
<사진4>
그렇다면 가중치가 업데이트 될 때, 학습데이터에 편중되지 않도록 해주면 되지 않을까요?
이러한 물음에서나온 방법이 Regularization이에요! 좀더 풀이하자면 업데이트되는 가중치에 규제를 가해야 한다는 뜻이에요. 그럼 지금부터 Regularization의 종류들에 대해서 알아보도록 할께요
Regularization의 대표적인 종류는 L1, L2 regularization입니다. 우선 L1, L2를 나누는 이유는 regularization을 적용할 때 쓰이는 norm 때문이에요. 우선 L1 norm과 L2 norm에 대해서 짧게 설명드릴께요.
<1.Norm>
Norm이란 벡터의 크기를 의미해요. 벡터의 정의와 크기를 구하는 공식은 아래의 영상을 보시면 될거에요. (첫번째 영상은 벡터의 정의를 다루었고, 두 번째 강의에서 크기가 언급될거에요)
요약하자면 하나의 벡터가 2차원이면 x=(x1, x2)라고 표현되고, 3차원이면 x=(x1,x2,x3)라고 표현될거에요. 그리고 영상에서 소개한 크기 공식을 일반화하면아래와 같이 표현할 수 있을거에요.
또한 norm과 관련된 식은 아래와 같이 나타나요. (L1 norm은 p=1만 대입해주면 L1 norm 식이되요)
그렇다면 본격적으로 L1, L2 regularization에 대해서 알아볼까요? 우선 L2 norm에 대해서 알아보고 L1 norm과 L2 norm을 비교하는 방향으로 알아볼거에요.
<2. L2 regularization (Ridge regression)>
아래수식은 2장에서 설명드린 가중치를 업데이트 하는 수식이에요.
우리는 가중치가 크게 업데이트가 될 경우 이를 규제(억제)시키려고 해요. 그렇다면 위의 수식을 어떻게 변경시켜주면 될까요? 먼저 아래식들을 볼께요.
1번 수식은 MSE cost function이에요. 1/2이 MSE 수식앞에 붙은건 미분을 거친 후 계산을 편하기 하기 위해서에요 (미분을하면 제곱이 1/2과 곱해져서 1이 되겠죠?). 그리고 2번 수식을 잘 살펴볼 필요가 있어요. Regularization을 위해서 새로운 cost function을 만들어줬는데 식을 자세히 보내 (λ/2)||w||^2 를 더해주었네요? 더해진 식이 의미하는 바가 무었일까요?
더해진식을 자세히 보면 λ X L2 norm이라는 것을 볼 수 있어요. (1/2)이 곱해진 이유는 gradient descent로 학습시 적용되는 미분계산 이후의 과정을 편하게 하기 위함이고, 람다(λ)가 곱해진 이유는 regularization의 정도를 결정하기 위함이에요(보통0~1사이로 조절한다고해요). 중요한건 왜 L2 norm이 적용됐냐는 부분이에요.
큰 가중치값이 overfitting에 영향을 미치기 때문에, 그 벌(페널티)로써 큰 가중치 값이 업데이트 될 때에는 업데이트를 더 급격하게해주려는 의도에요. 예를 들어, 가중치값이 0.1 인 경우(w=0.1)와 3인 경우 (w=3)에는 w=3일 때 더 큰 값이 이전 가중치 값인 w(t)에 더 큰 변화를 줄 거에요 (즉, w(t+1)값과 w(t)값의 변화가 클거라는 말이에요). 다시말하자면, L2 norm이 적용돼었다는건 큰 가중치값을 가질수록 학습시 더 큰 페널티를 주겠다는거에요.
그런데 왜 큰 가중치값이 overfitting에 영향을 미친다고 판단한걸까요? 우선 L2 norm에서는 항상 결과값이 음이아닌 정수이기 때문에 0에 가까운 값이 작은 값이 되고, 0에서 멀어질 수록 큰 값이됩니다. 이러한 개념이 weight에 적용되기 때문에 가중치값이 작다는 말은 바꿔말해 0에 수렴하는 것이라고 말할 수 있겠네요.
앞서 신경망이 계산되는 원리를 설명드렸죠? Wx->activation->Wx-> .... ->Wx
결국 DNN 모델은 거대한 Wx 함수의 연속이라고 추상화시킬 수 있는데요. 만약에 Wx^2+Wx+1 이런식으로 표현된다고 했을 때, coefficient 값에 해당하는 W값이 커지게되면 그래프모양이 굉장히 sharp하게 그려질거에요 (sharp하다는 표현이 조금 애매하긴한데, noise가 섞인 데이터조차 표현하다보면 그래프가 완만해지기 보다는 sharp해지는 경우가 흔하기 때문에 이렇게 표현했어요).
<사진5>
또 다른 측면에서 보면 입력값에 해당하는 X의 차원이 높으면 높을 수록 overfitting이 일어나는 경우가 있어요. 그래서 X입력값과 결합되는 가중치 W의 값이 0에 가까울 수록 X입력값의 차원이 줄어드는 것 처럼 보일 수도 있겠네요. (이부분은 이해가 안되시면 넘어가도 좋아요. 추후에 Curse of Dimension (차원의 저주) 라는 개념에 대해서 다시 설명하도록할께요)
아무튼 결론적으로 요약하자면 가중치 값이 크면 overfitting을 일으킬 확률이 크다고 보기 때문에, 큰 가중치에 대해서는 L2 norm이라는 식을 적용하여 가중치 업데이트시 페널티를 주고 있어요. 그리고 이러한 행위를 Weight decay (regularization) 라고 부르기도 해요.
하지만 필자는 이런의문이 들어요. "정말 큰 가중치가 overfitting을 일으킬까? 학습데이터에 따라서 큰 가중치값이 더 좋을 수 있지 않을까? 오히려 overfitting을 일어나다는 것은 오차값(E=d-y(x;w))이 적다는 뜻이므로 오차값을 크게 만드는데 관여하는 w에 대해서 페널티를 주는식을 만드는것이 더 효율적이진 않을까?"
물론 딥러닝이라는것이 기계학습의 일부로 확률적 모델을 기반으로 하기 때문에 어떤 개념을 명확하게 설명하는게 힘들긴 하겠지만, 위와 같은 질문을 통해 regularization을 적용할 시 L2 norm이 아닌 다른 방식을 써보는건 어떨까라는 생각을 해봤어요.
<3. L1, L2 regularization 비교>
L1 regularization (Lasso regression)은 따로 설명을 하진 않았지만 L2 regularization을 보셨다면 쉽게 이해 되실거에요. 앞선 "<1.Norm> 파트에 언급된 수식에 p=1만 집어 넣고, L2 regularization 수식에 적용된 L2 norm 부분은 L1 norm으로 바꿔주기만 하면되요.
L1 reguralization은 L1 norm을 적용하기 때문에 가중치 크기에 상관없이 일정한 상수값으로 매번 페널티를 부여받아요. 가중치의 부호에 따라 +λ or -λ 의 상수값이 되겠네요.
그렇다면 이렇게 가중치와 상관없이 '일정한 상수값'이 페널티로 부여되면 어떤일이 발생할까요?
VS
결과론적으로 말씀드리자면 상수값 때문에 L2보다는 L1에서 낮은 가중치값에 해당하는 coefficient가 0이 될 확률이 높다고 설명해놨습니다. 사실 이부분이 이해가 잘 안되서 외국분들에게 질문했는데요. 답변해주신 내용을 통해 아래와 같은 해석을 할 수 있었습니다.
가중치 값이 낮은 경우 L1 norm이 더 0으로 빠르게 수렴하게 영향을 미치는지 살펴볼께요. 먼저, 낮은 가중치(0~0.01)가 있다고 가정해봅시다. L1 norm, L2 norm 둘다 가중치를 업데이트하는데 영향을 미칠거에요. 그러다보면 값이 0.01 값보다 점점 더 작아질거에요 (물론 람다(0~1)의 부호에 따라서 설명이 달라지겠지만 여기서는 가중치가 양의 값을 갖는 0~1사이에 값이라고 가정할께요. 이에 따라 업데이트 되는 가중치의 변화는 0.1->... ->0.001 이런흐름으로 작아질거에요. 하지만 지속적으로 업데이트 하다보면 가중치 w는 0에 가까운 값을 갖게되고 그렇게 되면 L2 regularization에서 사용되는 미분된 L2 norm은 아래수식과 같이 0에 수렴하게될거에요.
요약하자면, L2 regularization에서는 학습을 하다 결국 w가 0에 가까운 값을 갖게되는 시점부터는 가중치 업데이트할때 E(x)만 관여하게 되는거에요 (위의 수식참고). 결국 어느 순간부터는 수식이 아래와 같이 바뀌겠네요. 이렇게 보면 L1이 regularization에 좀더 공격적이라고 표현할 수 있겠어요. (그런데 이 설명이 완벽하진 않아요. 왜냐하면 작은 가중치에 대한 εΔE(w) 값이 가지는 범위에 따라서 해석이 달라질 수 있거든요. 그래서 가끔 느끼는거지만 딥러닝을 설명하는데 있어서 명확하게 설명되는 부분이 종종 있다고 느껴져요. 그냥 확률적으로 그렇다고 설명하고 넘어가는 부분들이 종종있어서..)
VS
아무튼 중요한 점은 가중치값이 작아질 수록 0에 수렴하게 하는 regularization 기법에는 L1이 더 적극적일 확률이 높다는거에요!
먼저, 아래식을 먼저 볼께요. 위에서 설명한대로라면 x2, x4, x5 앞에 붙은 가중치 값들이 0이 될 확률이 높아요! 그렇게 된다면, x1, x3, x6 만으로도 충분히 Deep Neural Network를 나타내는 식을 만들어 낼 수 있어요. 즉, 입력차원을 줄일 수 있어서 모델의 complexity를 줄여준다는 건데, 이렇게 입력차원을 낮아주게 만들어 나타나는 효과는 다음장 curse of dimension에서 다룰거에요.
다시설명하자면, 가중치값이 굉장히 낮은 부분은 0에 수렴한다고 보기 때문에 오히려 없애주어 얻는 효과가 DNN 성능향상에 미치는 영향이 크다고 보는 거에요.
아래 그림은 실제 regularization식을 적용해보고 학습을 시켜본 결과입니다. 329번 학습을 시켰을 때, 학습이전 낮은 값을 갖고 있던 가중치값들이 중 몇몇이 L2보다 L1 regularization에서 더 많은 zero값을 갖게 된 것을 볼 수 있죠?
<사진6>
또하나 주의할 점은 L1 regularization에 적용되는 L1 norm은 절대값이 포함되어있기 때문에 미분이 안되는지점이 발생할 수 있다는 점입니다.
<사진7>
(간혹 딥러닝 공부하시다보면 smooth L1 norm이라는 개념이 튀어나오는데, 이 개념은 보통 loss function에서 많이 다루어요. 추후에 Convolutional Neural Network (CNN)이라는 개념을 다룰 건데 여기서 smooth L1 loss를 사용해요~ 물론 다른곳에서도 많이 사용하겠지만요;;ㅎㅎ 한가지 힌트를 드리자면 당연히 n1 norm의 단점이라고 할 수 있는 학습 시 미분불가능한 부분을 개선했겠죠?? )
지금까지 내용을 요약하자면 아래와 같아요.
1. 가중치가 큰 값은 overfitting을 일으킬 요인이 크기 때문에 학습시 페널티를 주어야한다는 관점에서 나온것이 weight decay regularization이에요.
3. 가중치가 큰 정도를 판단하기 위해 가중치를 하나의 벡터라고 가정했고, 그 벡터의 크기를 가중치의 크기로 보고자 L1-norm, L2-norm이라는 개념을 도입해 L1-regularization, L2-regularization을 고안해냈습니다.
4. L1-regularization은 L2-regularization 보다 낮은 가중치 값을 0으로 만들어줘 입력차원을 줄여주는 경향이 있고, 이것은 입력차원을 낮춰주는 효과가 있어요.
5. 보통은 weight decay regularization에서는 L2-regularization이 사용되고 있어요.
이번장에서는 overfitting을 이유로 들어 왜 regularization이 DNN을 학습시킬 때 필요한지 알아보았어요. 하지만 조금 깔끔하지 못했던 것이 중간에 'curse of dimension', '입력차원'이라는 용어를 설명없이 기술해놓았기 때문이에요. 그래서 다음장에는 curse of dimension이라는 개념을 설명해보려고합니다!
오늘은 과거 대만사람들이 반한감정을 가진 이유에 대해서 설명해보도록 할께요! 이번장에는 대한민국과 대만의 관계를 시기별로 나누어 설명하려고 해요~
1) 초기
본래
중국과 북한이 공산주의 연합이었고, 한국과 대만이 민주주의 연합이어서 전우애 같은 것이 있었습니다. 우리는 대만을 자유중국 (중화민국) 이라고
불렀고, 중국을 중공(중화인민공화국)이라고 불렀었다. 그래서 일반적으로 ‘중국’이라고
하면 ‘중화민국’ 즉 대만을 일걷는 말이었다고 하네요.
단교 직전인 1990년 기준으로,
서울에는 미국, 소련, 프랑스, 서독, 영국, 일본, 이탈리아 등 이른바 세계 열강의 대사급 외교관이 상주하여, 중화민국
외교관이 대사 자격으로, 강대국 대사들과 대등하게 접촉하는 유일한 공간이 대한민국 이었기 때문에 한국과 대만의 관계는 상당히 끈끈했다고 하네요.
2) 대만 UN 탈퇴
1945년부터 한때 대만은 UN 안전보장이사회의
상임이사국 중 하나였지만, 1971년 10월 25일 중화인민공화국이 UN에 공식 가입하게 되면서 UN 총회의 투표 결과에 따라 결국에는 중화인민공화국에게 상임이사국 자리를 내줘야 했고 UN에서도 자의 반, 타의 반으로 탈퇴하게 되었습니다.
당시 UN 총회에는 중화민국 축출과 중화인민공화국의 상임이사국 지위
획득을 지지하는 알바니아의 결의안과 그것을 반대하는 미국의 안이 동시 상정되었는데, 서방 국가들(캐나다, 프랑스, 이탈리아
등)도 다수가 알바니아의 결의안에 찬성표를 던져 미국에 충격을 주기도 했습니다.
이때는 아직 중국의 저력이 핵무기 정도에 국한되어 있었지만, 어느
정도 예견되기도 한 결과인것이,프랑스는 이미 1960년대에
중국과 수교했다. 당시 미국은 중국을 대표하는 권리는 포기하되 대만(Taiwan)
지역의 주권국가로서의 회원국 지위는 유지하는대만 공화국? 타협안을 제시하기도 했으나 대부분의 나라들이 반대하고 중화민국도 거부하여 무산되었고, 표결 직후 UN 총회에서 중화인민공화국의 합법적 권리 회복을 골자로 하는 '제2758호 결의'가 찬성 76, 반대 35, 기권 17로 통과되고, 그
직전에 중화민국이 스스로 UN 탈퇴 선언을 함으로서 UN 상임이사국
지위는 물론 회원국 지위를 완전히 상실하게 되었습니다.
즉, 서방국가들
또는 UN 가입국들이 중국의 영향력 (중국에 자신들의 기업들을
투자 유치 등) 을 우선으로 하여 대만을 버린 것이라 할 수 있는데요.사실, UN에서는 중공의 UN 가입을 반대하다가 중소결렬 (공산주의의 해석차이 + 한국전쟁에 소련이 중국을 제대로 돕지 않음 (소련은 남한 침략에
회의적이었음)) 이후에 미국을 위시한 서방국가들이 소련 견제를 위해서 중국과 손 잡는 것이 유리하다는
판단을 내리면서 정책변화가 일어난 것입니다.
이러한 국제 정세의 변화는 대만을 중국의
정통 정부로 인정하고 국교를 맺어온 한국에게도 커다란 충격으로 다가왔다. 특히 한국전쟁의 일방 당사자
가운데 하나였던 중국이 UN에 가입하고, 그것도 상임이사국이
됨으로서 한국전쟁 휴전 협정이 무효화될지도 모른다는 불안감이 한국 사회에 밀어닥치기도 했다. 그걸 빌미로
유신헌법이 만들어져 제4공화국이 출범하기도 했습니다.
3) 한중 수교
대한민국과 중화민국은 이토록 친밀했지만 1971년, 중화민국이 안보리 상임이사국 자리와 전 중국의 대표자격을 빼앗기며 UN에서
추방당할 때(대만 축출)는 도움을 주지 못했는데요. 그 이유는당시 한국은 공산권의 반대로 참관국이었을 뿐, 가맹국이 아니라 반대표를 던질 수 없었기 때문입니다.
그러다가 1988년에 출범한 노태우 정부가 공산권과 외교 관계 개선에
적극 나서면서 한국-중국 및 한국-대만 관계에 변화의 기류가
나타나기 시작합니다. 소위 북방정책으로 표현되는 이러한 외교 노선에 따라 한국은 헝가리, 폴란드, 체코슬로바키아, 유고슬라비아, 불가리아, 루마니아 등 동구권 국가들과 수교한 데 이어 1990년 10월에는 공산주의의 종주국 소련과 수교함으로써 북방정책의
정점을 찍게 되는데요. 특히 중국은 한국과 수교할 경우 이에 반발한 북한이 친소로 기울어질 것을 염려하여
한중 수교에 미온적이었는데, 1991년 8월 쿠데타 이후
소련이 급속히 와해되면서 상황이 급변하게 됐다고합니다.
한국은 노태우 정부의 사실상 임기 마지막 해인 1992년 안에 중국과 수교함으로써 북방정책의 대미를 장식하고 싶어했고, 중국
역시 한국과 수교함으로써 대만을 아시아에서 완전히 고립시키게 되었습니다. 물론 한중 수교가 가시화되면 북한과
대만이 견제에 나설 게 불 보듯 뻔한지라 한중 외교 당국자들은 북한과 대만을 설득하여 양해를 구하는 절차를 생략하고 비공개로 직접 수교 교섭을
벌여야 했습니다.
4) 단교
1992년에 대한민국이 중화인민공화국과 수교 교섭을 할 때 중국 측은
여느 때와 마찬가지로 하나의 중국원칙을 들이대며 대만과의 단교를 조건으로 내걸었습니다. 그리고 이것은 중국의
외교에서 최우선 원칙으로 대한민국에만 요구한 것은 아니였으며,당장 미국도 1979년 중국과 수교하면서 중화민국(대만)과는 단교하였습니다.
대한민국은 당시 중화민국에 있어 최후의 대국이었는데요.중화민국 외교관이 외교부장(외무부 장관)으로 가는 엘리트 코스의 마지막 관문이 바로 주한대사였다고도 합니다.
그렇지만
한중수교는 한국의 입장에서는 북한에 대해, 중국의 입장에서는 대만에 대해 외교적 판정승을 상징한다는
점에서 양국의 이해가 맞아떨어지는 부분도 있었기에 언젠가는 이루어질 수밖에 없었다고 합니다.
하지만, 결정적으로 한국과 대만의 관계가 틀어진 것은 단교가 되고
나서부터이다. 마침내 중국과의 수교가 정식으로 맺어지기 일주일 전인
1992년 8월 15일. 결국 한국 외무부는 중화민국 대사를 소환해 비공식적으로 중국과의 수교, 중화민국과의
단교 계획을 밝힙니다. 한편 첸푸외교부장은 주한 대사관으로부터 한중수교 합의를 통보받은 후 8월 19일 입법원 대표들을 외교부로 불러 한국이 중국과 수교하고 대만과 단교한다는 사실을 통지하고 이에 동요하지
말 것을 당부합니다.
하지만 입법원 의원들은 외교부장의 당부에도 불구하고 이를 즉각 언론에 누설하였고, 대만 내 여론은 격분했다. 한국 정부는 대만 소식통을 통해 한중수교
뉴스가 전해지자 처음에는 즉각 부인했다가 결국 하룻만에 이를 번복하여 한중수교 사실을 시인했는데,이
때 대만에 유학중이던 한국외대 중국어과 학생이 대만인들에게 폭행을 당하는 사건도 있었습니다.
그리고 8월 21일 공식적으로 중화민국에게 단교 문서를 전달하려고 했는데,중화민국측에서 선수를 쳐
대한민국과의 단교를 선언했습니다. 그리고 중국과 수교를 맺은 24일, 중화민국 대사관에 72시간 내에 국기와 현판을 내리고 철수해줄 것을
요구했고, 이후 중화민국 대사관은 6시간 만에 국기 하강식을
갖고 한국을 떠났습니다. 실제로 당시 중화민국 국적의 화교들이 눈물로 진 대사를 배웅했으며, 일부는 울분을 참지 못하고 거리에 나가 한국 정부를 규탄하는 시위를 벌였다고 합니다.
5) 중국
중화인민공화국을 국가승인하지 않았던 한국이 1988년 한국이 중화인민공화국에
대한 호칭을 중공에서 중국으로 변경했을 때, 중화민국 측은 항의했습니다. 중화민국이 중국 대륙의 정통 국가라는 원칙을 훼손하기 때문입니다. 여러
번 강조되지만, 여타 소국들과 달리 한국은 차례 차례 단절되어 가는 중화민국 외교에서 최후의 대국이었기에
그러한 조치가 중화민국 입장에서는 중대하게 받아들여질 수밖에 없었는데요. 아래와 같은 연설은 당시의 대만의 입장을 잘 보여주는 대목입니다.
한·중 외교관계 수립으로 대만은 이번에 세 번째 타격을 받았다고 말합니다. 첫 번째는 1971년 유엔에서 쫓겨난 것이고, 두 번째가 미중 수교, 세 번째가 한중 수교라는 것입니다. - 첸지천 중화인민공화국
외교부장의 국제정세 문제에 관한 연설(’92. 09. 05.)
6) 그외의 반한감정 요소들
다음장에서 일본과 대만과의 관계를 설명할텐데요. 결론적으로 말하자면 대만은 일본에게 굉장히 긍정적인 감정을 가지고 있었다고 합니다. 이러한 부분이 반한감정을 부추기는 또하나의 요소라고도 하는데 더욱 중요한 요소는 대한민국의 성장이라고 보는 것이 일반적입니다.
사실 대만은 우리나라보다 경제적으로 굉장히 앞선 나라였는데요 (한국전쟁이후에는 모든 나라가 대한민국보다 잘 사는 나라였죠;;). 대한민국이 눈부신 경제발전을 이룩하자 상대적으로 대만이 뒤쳐지는 모습에 반한감정이 생겼났다고해요. 물론 대만과의 수교를 단절한 것이 큰 요소였겠지만, 앞서 언급했던 여러요소들이 결합하여 반한감정을 부추기는 역할을 했다고해요
7) 현재
하지만 요즘 세대들은 반한감정이 있었나 할정도로 대만과 한국의 관계는 우호적으로 변했습니다. 특히 요즘에는 Kpop의 영향으로 요즘 세대들은 서로에 대한 호감도가 점차 올라가는 중이라고해요~ 2018년에는 더욱더 교류를 활발하게 하기위해서 한국인들은 입국시 혜택을 주는제도도 생겼다고하는데요. 여행했을 당시에도 반한감정같은게 뭔가할 정도로 사람들이 친절했고 아무튼 너무 좋았습니다~
지난시간에 본성인, 외성인 등을 설명하면서 청나라가 대만이라는 섬을 실효지배했다고 배웠어요. 이번장에서는 대만의 초대 총통인 장제스라는 인물이 어떻게 등장했는지 알아보려고해요.
사실 청나라가 멸망하고 오늘날의 중국으로 넘어가기까지 굉장히 많은 사건이 있었는데요, 그 과정은 홍콩편 '쑨원은 누구인가?'에서 언급하려고합니다. 그러니 여기에서는 시간적 흐름만 설명만 하도록 할께요!
'1894 청일전쟁' -> 청나라 패 -> 청나라 학생 중 하나인 쑨원이 국가의 무능함에 분개 -> 황제가 아닌 백성을 위한 나라를 만들고자 함 -> 삼민주의(민족, 민권, 민생)를 앞세워 혁명을 일으킴 -> 1912년 신해혁명을 통해 청나라 몰락시키고 '중화민국(대만)'을 수립 -> 국민당 창당 -> 쑨원은 소련의 도움을 받은 공산당 세력 (모택동)을 포섭 -> 1925년 쑨원 사망 -> 장제스가 국민당 대표가 됨'
장제스에 대한 좋은 영상이 있어서 유튜브링크를 걸어 놓을께요. 한 번 보시면 좋을 듯 합니다~
요약하자면 아래와 같아요!
당시 청나라가 몰락하고 쑨원이 곧바로 모든 청나라의 영토를 지배한 것은 아니었어요. 군벌세력들이라고 해서 여러 세력들이 존재했는데 장제스는 모택동과 함께 1차 국공합작을 통해 이러한 세력들을 진압해 나갔어요.
하지만 진압하는 과정에서 모택동의 공산당원들이 희생을 당하자 더이상 합작을 진행하지 않았는데요. 장제스는 민주주의 이념에 반하는 공산당을 처벌해야 한다고 주장하면서 1927.4.12 상하이에서 공산당을 진압하기 시작했어요. 이것이 바로 국공내전이에요.
하지만 일본의 제국주의가 거세지기 시작하면서 다시 제2차 국공합작이 이루어지기 시작해요. 1943년 미국(루즈벨트), 영국(처칠), 중화민국(장제스)은 이집트 수도 카이로에 모여 5일간 회담을 갖게 되는데요. 여기서 한반도의 독립이 비공식적으로 논의 되었다고 해요. 비공식회담이라 공식적인 문서는 존재하지 않지만 장제스는 한반도의 독립을 주장했다고 해요 (그 이유에 대해서는 여러 논란이 있지만요). 아무튼 장제스가 윤봉길 의사에게 감동받아 상해임시정부를 도와주었던 점도 있었고 대한민국에게는 많은 도움을 주려했던것 같아요. 이와 관련한 자세한 부분은 상해 여행에서 다룰께요~
1945년 미국의 히로시마 원폭으로 일제가 항복하자 1946~1949년 제2차 국공내전이 발생하게되요. 처음에는 장제스의 중화민국이 절대적으로 유리한 상황이었지만 점점 모택동의 중국 공산당에게 밀려나게 되고 지금의 대만섬으로 피신했다고 해요.
장제스가 일본에게 대항할 때, 당시 자신들의 역사가 담긴 신석기
때부터 청나라까지의 문화재들을 지키기 위해 가장 귀중한 69만 여점을 선별해 각종 지역에 숨겨두었는데, 국공내전에서 마오쩌둥에게 밀리면서 대만으로 이주할때 모든 문화재들과 군인 200만을
데리고 갔다고 해요.
이때 옮겨진 문화재들이 현재 타이페이 부근의 고궁박물관에 위치하고 있으며, 이 박물관은 동양의 역사와 문화재를 대표한다는 측면에서 세계 4대
박물관 중 하나로 뽑히고 있는데,사실 신석기때부터 청나라때까지 가장 유명한 문화재를 보려면 현재 북경이
아닌 대만의 타이페이로 가야한 다고 합니다!
중화민국은 섬으로 피신하고 중국공산당이 모든 영토를 지배하게 되자, 결국 중국공산당이 중화인민공화국(오늘날 중국)으로 바뀌게 되고, 1970년대 UN에서도 중화인민공화국의 압력에 밀려나게되요. 상임이사국 자격을 박탈당하죠. 그 이후로는 여러나라들이 중화인민공화국의 압력에 못이겨 단교를 하는 상황이 벌어지게 되요. 결국 1992년 대한민국과도 단교를 하게됩니다.
이번장에서는 장제스에 대해서 알아봤는데요. 그 과정에서 언급된 "고궁박물관"과 장제스를 기념하는 "중정기념관"을 방문했기에 관련 후기를 쓰려고해요~
<1.고궁박물관>
아래가 고궁박물관이에요. 박물관안에는 굉장히 많은 유물이 있는데, 실제로는 모든 문화재를 전시를 하지 않는다고 해요 (워낙 수가 많으니까요;;ㅎㅎ). 고궁박물관 뒤에 있는 3000M 넘는 고봉 200개에 보물을 숨겨놓고 3개월마다 교체하는데, 모든 유물을 다 보려면 30년이 걸린다고 하고, 주요 전시물들을 제외한 것들은 3~6개월 마다 교체한다고 해요!
사진촬영이 허용된 문화재중에 대표적인 '취옥백채'만 사진으로 남겼었어요. 취옥백체의 정보는 아래와 같아요.
사용용도: 청나라 11대 광서제의 왕비인 서비의 혼수품
줄기의 하얀색 부분: 순결을 의미
초록 잎: 미와 젊음을 의미
한쌍의 메뚜기: 다산의 의미
공식적으로 확인 된 바 없으나 중국이 대만의 UN 가입 조건으로 비밀리에 제안한 것이 바로 ‘취옥백채’를 들려주는 것이었다고 해요. "만약" 사실이라면 이 제안을 대만은 일언지하에 거절하였으니 이 옥배추가 지닌 무한한 예술적 가치를 가늠해 볼 수 있을 것 같아요~
그외 여러 문화재들을 감상할 수 있어요. 그리고 정말 오래된 문화재이지만 정말 독특하고 세련된것들이 많았어요. 오늘날에는 모든 것을 기계로 만들지만 저 당시에는 저런것들을 모두 손으로 많들었던것을 생각해보면 과거의 사람들이 현대인보다 손재주는 훨씬 뛰어났을것 같다는 생각을했어요.
<2.중정기념관>
1975년 장제스 사망을 기리기 위해중화민국 행정원이 기념당의 건설을 결정하였고해요.
본당 건물의 높이가 70m. 본관으로 이어지는 계단은 모두 89개인데, 이는장제스가 사망한 나이 89세를 의미한다고 해요. 제가 방문했을 때는 보수공사중이었어요.
해당 부지는 본래 육군본부 및 헌병사령부로 쓰였던 곳이고,미국의 링컨 기념관을 본따 만들어졌다고해요.
중정기념당의
경비병들은 모두 현역 군 의장대로 구성되는데, 10시~17시 사이에 매시 정각마다 교대를 한다고해요. 건물이 바라보고 있는 방향이 서북쪽 방향인데 이것이 중국본토 방향이라고해요. (본토의 수복의지를 표현한걸까요?) 당시 방문했을 때 교대식을 영상으로찍었는데 용량크기 때문에 편집을해야할 것 같네요 ㅎㅎ 시간있을 때 금방해서 올릴께요!
중국의 전통적 건축양식의 하나로, 패방(엄밀하게는 패루)이라는 문이 있는데중국에서는
지금도 사적지 (역사적으로 중요한 사건이나 시설의 자취가 남아 있는 곳)를 조성할 때 패방을 세운다고해요.
그런데 문구를 바꾸는것만으로도 엄청난 세금이 투입된다고해요. 그래서 더이상 문구를 바꾸지 않고 그냥 두었다고합니다.
현재 대만에는 국민당과 민진당이 주요 정당인데, 아이러니하게 국민당은 중국과 우호적일 것을 주장하고 있고, 민진당은 대만의 강력한 독립을 주장하고 있어요. 차이잉원 현 총통은 이러한 기념당이 권위주의 숭배라며 기념품 판매를 금지시키고, 매년 2.28일 폐관을 시키고 있다고 합니다. 대만 국민은 대만의 독립을 강력하게 지지하지만, 랜드마크가 되어버린 중정기념관을 비판하는 민진당에 대한 입장에 대해서는 부정적인 시각이 지배적이라고 해요.
중국분들이 이 글을 보면 싫어하실 수 있겠지만, 대한민국 사람입장에서는 임시정부를 도와주었던 장제스가 무력이 아닌 다른 방식으로 공산당을 흡수했으면 어땠을까라는 생각을해요. 장제스가 쑨원만큼 했다면, 장제스가 오늘날 중국을 통일했다면, 오늘날 중국이 민주주의 국가였다면 우리나라가 분단되는 일이 있었을까요?
2. aj는 activation function 'f'를 통과하고 자신들이 예측한 값 yj을 도출합니다.
3. 실제 정답 값 tj의 오차값을 (문제정의에) 알맞은 cost function을 통해 도출(=ej=(tj-yj)^2/2)합니다.
4. 오차값(ej)을 기반으로 backprogation을 통해 가중치 w를 업데이트 함으로써 학습진행하게 됩니다.
<사진1>
이러한 Perceptron은 많은 문제를 해결해 줄 것으로 기대했어요. 예를들어 두 개의 입력값 x1, x2 ∈ {0,1} 중 하나만 1이라는 입력이 들어오면 1이라는 결과를 도출하는 OR 문제같은 경우나, 두 개의 입력값이 모두 1이어야만 1이라는 결과를 도출하는 AND 문제와 같은 경우는 쉽게 해결이 가능했어요.
x1을 X로, x2를 Y라고 하고 Y를 C라는 임의의 상수라고 표현하면 activation function을 거치기 직전인 w1X+w2Y=C 라는 식이 만들어 지겠네요. 그런데 왼쪽 식을 Y=(-w1X+C)w2 라고 바꿔주면 직선의 방정식 (linear) 이 되는 것을 볼 수 있죠?
충분히 두 개의 입력으로 구성된 perceptron으로 문제 해결이 가능해졌어요.
<사진2>
하지만 XOR 문제를 푼다라고 가정해봅시다. 두 개의 독립변수 x1, x2 ∈ {0,1} 가 입력으로 받아들여지고 이 두 개의 입력중 오직 하나의 입력만이 1인 경우에만 1이라는 결과를 출력할 수 있는 문제입니다. 이를 간단히 표현하면 아래와 같이 표현할 수 있겠네요.
그런데 우리가 정의한 문제공간(Original x space = 사진2 '가운데 그림')은 직선으로는 구분하게 힘들어 보여요. 물론 w1x1+w2x2=c 라는 식이 non-linear한 성격인 activation function을 거치면 어떤 곡선을 나타내는 식이 만들어져 XOR 문제를 해결할 수 있겠지만 현재 우리가 알고 있는 activation function으로는 힘들다고 해요. (제 생각으로는 activation function이 직선형태(linear)라고 할 수는 없지만, ReLU, Leaky ReLU 와 같은 함수들은 영역에 따라 상당히 linear(직선)한 성격을 갖고 있어요. 그래서 아래와 같은 문제를 해결할 수 없는거 같아요)
<사진2>
이렇게 간단한 문제조차도 해결하지 못했기 때문에, 신경망 연구는 더이상 지속되기 힘들다고 했지만 단순히 Layer를 추가 함으로써 위와 같은 문제를 쉽게 해결할 수 있게 되었어요.
우선 기존의 perceptron 모델은 input layer 하나만 있었다면, 우리는 hidden layer라는 층을 추가해서 layer를 2개 이상으로 만들거에요 (=Multi-Layer Perceptron). 그리고 W, w, c는 이미 학습을 완료했다고 가정하고 그림으로 요약하면 아래와 같아요.
<사진3>
처음에 "WX+c --> activation function"과정은 perceptron에서도 봤던 과정이에요. 그런데, 이렇게 한번 거치고 나면 "Original x space->Learned h space"로 문제공간이 변경된 것을 볼 수 있을거에요. 이렇게 변형된 "Learned h space"를 보면 직선(linear)하게 문제를 해결할 수 있게됩니다.
<사진4>
위와같이 문제공간을 변형시키는 트릭을 Kernel trick이라고도 부르는데요. 보통은 문제공간의 차원을 변형시켜서 푸는 방법을 의미합니다. 알아두시면 좋아요!
<사진5. Kernel trick>
Hidden layer를 하나 추가함으로써 non-linear한 문제를 아래와 같이 풀 수 있게 되었어요!
<사진6>
결과적으로 이야기하자면 layer를 하나 더 추가(hidden layer)함으로써 non-linear problem을 linear problem으로 변경해주게 되는데요. 이렇게 layer를 추가해준다는 개념은 linear한 성격만 지닌 perceptron에 non-linear한 성격을 마구 부과해주는 역할로 이해될 수 있어요. (아래의 그림을 보면 더욱 직관적으로 이해하실거에요!)
<사진7>
이전장에서 activation function에 대한 큰 의미가 non-linear한 성격을 지니는 것이라고 언급한바 있죠? 이제는 이해가 되시나요? activation function이 없다면 아무리 layer를 추가한들 "f(x)=ax+b, h(x)=cxày(x)=h(h(h(x)))=c×c×c×x=(c^3)x --> a=c^3or "a and c are constant"라고 한다면 결국 같은 linear 한 성격만 갖게 됩니다. 즉, 아무리 hidden layer를 추가한들, activation function이 없다면 MLP 또한 linear한 문제밖에 풀지 못할거에요! (예를들어 위에 사진5 수식에서 ReLU안에 인자들이 ReLU를 거치지 않고 모두 더해진다고 생각해보세요. 결국 또 직선의 방정식이 나올거에요!)
지금까지 설명한 것을 요약하자면, "activation function을 포함한 다수의 layer를 갖고 있는 MLP는 non-linear한 문제를 풀 수 있다"정도가 되겠습니다. 그리고, 이러한 설명을 하나의 이론으로 설명하고 있는것이 있는데 그것이 바로 'Universal approximation theorem'입니다.
아래글은 위키백과에 나온 universal approximation theorem을 인용한 것 입니다.
"In the mathematical theory of artificial neural networks, the universal approximation theorem states[1] that a feed-forward network with a single hidden layer containing a finite number of neurons can approximate continuous functions on compact subsets of Rn, under mild assumptions on the activation function. The theorem thus states that simple neural networks can represent a wide variety of interesting functions when given appropriate parameters."
"activation function영향 아래에서 추가된 hidden layer는 연속함수를 근사화할 수 있고, 이에 따라 적절한 가중치가 주어진다면, 다양한 함수들(with non-linear function)을 표현할 수 있다"
그럼 지금부터 요약을 해볼께요. 우선 지금까지 배운 MLP를 아래와 같은 그림으로 나타낼 수 있겠어요!
<사진8>
<사진9>
앞에선 하나의 hidden layer만 추가했지만, layer가 더 깊이 쌓여지면 쌓여질수록 deep한 neural network(신경망)이 많들어질거에요. 그리고 우리는 이를 deep neural network (DNN)이라고 부르고, 오늘날 딥러닝이라는 학문의 핵심적인 모델이됩니다.
<사진10>
현재 딥러닝에서 언급하고 있는 Artificial Neural Network (ANN)은 Multi-Layer Perceptron (MLP) 또는 Deep Neural Network (DNN)이라는 용어와 동일하게 사용되고 있어요.
그런데, 무조건 layer를 추가한다고 좋을까요? 계속 추가하게 되면 가중치도 많아지고 뭔가 복잡해질것같지 않나요? 시스템이 복잡해지면 학습이 잘 될까요?
위와같은 질문때문에 DNN에서 어떻게 하면 학습을 더 잘시킬 수 있을지에 대해 많은 방법론이 나오고 있어요. 그리고 다음장에서는 이러한 방법론중 가장 대표적인 '정규화(Regularization)'에 대해서 알아보도록 할거에요!
#Multi-Layer Perceptron #Universal Theorem #Activation function #Non-linearity #Kernel Trick
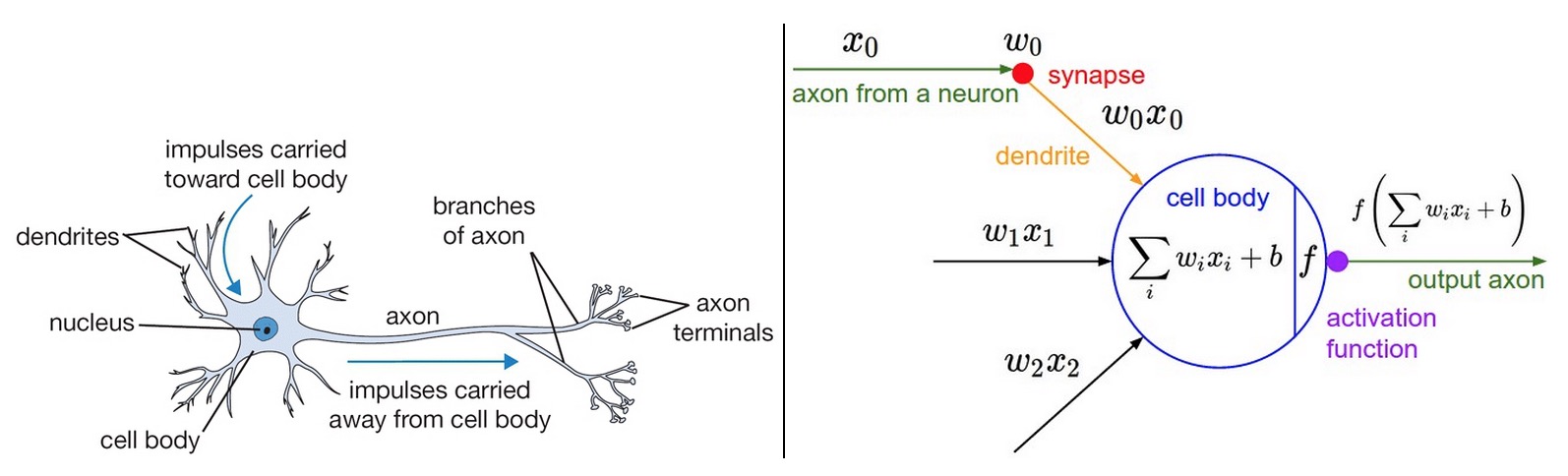
앞서 Neural Network에 대해서 배워보았습니다. 다시 Neural Network를 살펴볼까요? 아래그림중에 f라고 표시된 activation function이 담당하고 있는 역할이 뭘까요?
<사진1>
본래 뉴런은 여러 경로를 통해 들어온 전기신호의 합이 일정치 이상이 되면 다음 뉴런으로 신호를 전달하게 됩니다. 앞서 언급한 "일정치 이상이 되는 기준"이 Activation function이 되는 것입니다. 예를 들어, 일정 값 이상이 되면 1을 출력하여 다음 뉴런에 값을 전달해 주고, 일정 값 이하가 되면 0을 출력하여 다음 뉴런에 값을 전달해주지 않게 합니다.
사실 굳이 출력 값을 activation function을 통해 0 or 1 값으로 범위를 한정하는 것이 얼마나 큰 의미를 갖고 있는지는 모르겠습니다. 그냥 가중치에 입력값을 곱한 것을 그대로 다음 신경망에 넘겨줘도 되지 않을까요? (물론 값이 굉장히 커지거나 굉장히 작아지는 것 이외에도 우리가 모르는 문제가 생기긴 하겠습니다만 명확하게 그렇게 하면 안되는 이유를 찾긴 힘들어보입니다)
하지만 분명한 사실은 non-linear한 성격을 가진 activation function의 역할이 Multi-Layer Perceptron (MLP)에서 두드러지게 되는데요. 결론부터 이야기하지면 Deep Neural Network에서 layer가 깊어질수록 Wx라는 linear function만으로는 non-linear한 모델을 표현할 수 없기 때문에 문제가 발생하게 됩니다(이 부분은 이해가 안되는게 당연해요! 자세한 내용은 5장 Multi-Layer Perceptron에서 설명하겠습니다)
그래서 Activation function의 존재이유를 5장으로 미루고 이번장에서는 간단히 activation function의 변천과정을 살펴보도록 할께요!
1)Step function
초기에는 뉴런의 특성을 그대로 적용하여 step function을 activation function으로 삼았습니다. 단지 다음 뉴런으로 전기신호를 보내줄지 말지를 결정하는 모델을 본따서 만든 것 같습니다. 그런데, step function이 가지는 가장 큰 단점은 미분이 불가능 하기 때문에 backpropagation을 통한 학습이 불가능해진다는 것 입니다. (Backpropagation 설명은 아래 사이트를 참고해주세요! 아니면 "밑바닥부터 시작하는 딥러닝"이라는 책의 backpropagation 부분을 참고하셔도 됩니다! 좀 더 압축된 내용은 제가 따로 정리한 pdf파일을 올려놓을께요. 그런데 글씨가.. ㅜㅜ)
Backpropagation을 통한 학습이 가능하게 하기 위해서, 미분이 불가능한 step function을 sigmoid function 으로 대체하게 됩니다. 함수가 연속성을 갖고 있기 때문에 모든 구간에서 미분이 가능하게 되죠!
<사진3>
하지만 sigmoid function에도 문제가 생기게 되는데요. Backpropagation으로 가중치가 업데이트되는 원리를 알고 계신다면 sigmoid function의 치명적인 단점을 볼 수 있게 됩니다. 예를 들어, sigmoid function은 0~1 사이의 값을 도출하게 되는데 sigmoid 그래프를 보면 알 수 있듯이 입력 값들이 점점 위의 그래프 가운데서 멀어지게 되면 미분시 굉장히 작은 값을 도출하게 됩니다.
제가 업로드한 PDF파일을 보시면 알겠지만, backprogation으로 학습하는 방식은 chain rule을 이용하게 되는데, 만약 Wx 값이 아주 크게나오거나 아주 작게 나오게 되는 경우 제일 마지막에 연결된 뉴런에 해당하는 가중치 업데이트가 아래와 같이 이루어지게 됩니다.
∇W = 0.1x0.4x.0.3x.0.60=0.0072
결과적으로, 제일 뒤에 연결된 뉴런들은 가중치 업데이트를 못하는 상황이 발생하게 되는데요. 이를 Vanishing Gradient 문제라고 합니다.
<사진4>
3) ReLU (Rectifier Liner Unit = ramp function)
Vanishing Gradient 문제를 해결하기 위해서는 어떻게 하면 좋을까요? 시그모이드 함수에서 미분값이 문제가 되었으니 이를 해결해주면 되지 않을까요?
이러한 문제를 해결해주고자 ReLU라는 activation function이 나오게 됩니다.
위의 수식을 보시면 알겠지만 Activation function을 통해 나온 값을 굳이 0~1 사이로 제한하지 않았네요!
<사진5>
0이상이면 미분이 항상 일정한 기울기 값이 나오기 때문에, Backpropagation을 통해 학습을 하더라도 맨 뒤에 있는 뉴런까지 학습이 잘 되겠네요! (결과론적이지만 아래 cost function이 최저로 수렴하는 속도를 보더라도 ReLU가 학습이 빠른시간내에 된다는것을 알 수 있습니다!)
<사진6>
그런데 한가지 의아한 부분이 있습니다. x<0 인경우에 그냥 미분값이 0으로 설정되게 했는데, 그렇다면 Wx 값이 0이하에 관련된 weight parameter들은 backpropagation을 통해 업데이트가 이루지지 않게 됩니다. Wx 값이 음수가 나오더라도 음수값이 지니는 의미가 있을테니 이를 잘 활용하여 가중치들을 업데이트 시키면 좋지 않을까요?
4) 기타 사용되는 activation function
위에서 던진 질문을 해결하고자 나온 activation function들은 아래와 같습니다.
제시된 activation function을 보면 모두 음수값을 어떻게든 활용하려는게 보이시죠?
<사진7>
2015년에 나온 논문에는 ELU(Exponential Linear Unit) activation function을 사용했다고 하네요?
<사진8>
다양한 activation function이 나오고 있지만 결과적으로 ReLU와 큰 차이를 보이진 않는다고 해요. Activation function은 x<0 이하의 값들을 어떻게 출력해줄지, 또는 현재 x>=0 인 경우를 어떻게 출력해줄지에 따라서 굉장히 다양한 조합으로 activation function을 만들어 줄 수 있어요 (물론 현재는 x>=0인 경우는 그대로 x를 출력해주는게 보편화 되었지만요).
"하지만 개인적인 생각으로는 가중치의 초기값을 어떻게 설정해주는지에 따라, 또는 초기 가중치 값에 따른 Wx 값들이 어떤 분포를 이루는지 따라서 어떤 activation function을 사용하면 좋을지를 판단하는게 좋을 것 같아요. 물론 이 부분에 있어서 많은 경험적or이론적 연구가 많이 진행되어야겠지만요"
5) Softmax activation function
마지막으로 알아볼 것은 softmax activation function이에요. Softmax는 아래와 같은 수식을 나타내요. 결론적으로 말하자면 Softmax는 최종적인 결과를 확률로 알아보기 위해 사용되요. 우선 아래그림을 살펴볼께요.
아래수식이 그림에 표현된 softmax라는 영역에 다 적용이되요. 아직 Deep Neural Network에 대해서 설명한건 아니지만, Neural Network를 아래와 같이 구성할 수 있어요. 만약 아래와 같이 입력뉴런이 다음 뉴런들에 연결이 되고, 그 연결된 뉴런에서 결과값 z를 얻는다고 해볼께요. 임의로 설정된 z는 k개이고, 이 k라는 인자가 softmax에서 중요한 역할을 해요. 우리는 z라는 뉴런들의 결과들을 확률로써 이해하고 싶다고 해볼께요. 그렇다면 z1~zk의 합은 1이되어야 겠죠? 그리고 z1와 z2의 값이 상대적으로 큰 경우 확률로 변환되었을 때에도 상대적인 차이가 유지되어야겠죠?
<사진9>
위에있는 설명을 사진하나로 요약하면 아래와 같습니다. 이젠 Softmax가 어떤목적으로 사용되는지 아시겠죠? 다음장에서 Deep Neural Network를 보시면 더 잘 이해가 되시겠지만 Softmax는 마지막 layer가 되는 부분에서 확률적인 결과값을 얻기 위해종종 사용됩니다. (ReLU, Sigmoid 처럼 매번 쓰이는것과는 다르게 마지막 layer에서 한번 사용되는게 일반적이에요~)
<사진10>
지금까지 Activation function을 살펴봤습니다. 사실 이번장에서는 Activation function이 가지는 큰 의미에 대해서 깊게 살펴보지는 못했어요. 하지만 다음장 Multi-Layer Perceptron (MLP)에서 activation function이 지니는 유용성을 알아볼꺼에요 (힌트는 non-linearity 에요!).
#Activation function #Step function #Sigmoid function #ReLU #Leaky ReLU #PReLU #ELU
앞선 2장에서는 MSE(Mean Square Error)를 cost function으로 사용했습니다. 그런데, 모든 딥러닝에서 Cost function이 MSE로 통일되는건 아니에요. 그래서 이번장에서는 또 다른 cost function에 대해서 알아보려고 해요.
<1. 이진분류에 사용되는 Cost function; Logistic cost function>
상품을 품질 테스트 할때, 테스트의 합격 여부를 구분하려는 문제가 있다고 해볼께요. 어떤 입력 X가 들어왔을 때, d=0 을 '불합격', d=1 을 '합격'이라고 한다면 아래와 같이 표현할 수 있게 됩니다.
1번은 상품의 품질에 영향을 미칠 수 있는 변수들 (ex: x11=색이변한정도, x12=내구성 ...)에 대한 정보를 담고 있습니다. 그리고, 3번 처럼 각 변수들이 가지고 있는 값들이 합격(d=1)인지, 불합격(d=0)인지에 대한 정보를 갖고 있습니다. 1~3번에 대한 정보를 갖고 신경망(가중치)을 학습시킵니다. 우리의 목표는 4번처럼 우리가 갖고 있지 않은 미지의 입력값 x가 들어오더라도 최적화된 가중치 w를 통해 상품이 합격인지 불합격인지 구분해 낼 수 있는 신경망을 얻는 것입니다.
앞에서 간단한 흐름을 언급했으니 이제부터 이진분류에 대한 문제정의를 해볼거에요.
입력값 x가 들어왔을 때, d=1일 확률(=조건부확률)을 수식으로 써보면 아래와 같습니다.
앞서 설명한 neural network의 perceptron(neural network) 모델 기반으로 설명하자면 아래와 같습니다.
① 상품 품질에 영향을 미칠만한 변수들 x11, x12, ... 등을 입력으로 받는다.
② 입력값에 가중치 값을 곱해준다.
③ Activation function을 거친 결과가 50%(0.5) 이상이면 1이라는 값을 출력하여 합격이라는 결과를 주고, 50% 이하면 0이라는 값을 출력하여 불합격이라는 결과를 주게 된다. (Activation function에 대한 자세한 설명은 바로 다음장에서 이어지니 우선은 이런 과정이 있구나 정도로 이해해주시면 될거같아요!)
<사진1>
지금까지 설명한 내용을 수식으로 정리하면 아래와 같습니다. "x를 입력으로 받았을 때, w값이 곱해진 결과가 d=1 or d=0일 확률"이라는 문장을 아래 수식하나로 표현할 수 있게 됐네요. (아래의 확률값이 activation function을 거쳐 최종 output 값(0 or 1)을 갖게 됩니다)
다시 종합해서 정리해 보겠습니다. 우리에게는 상품품질에 영향을 미치는 변수정보 x1={x11, x12, ...} 가 있고, 그 상품이 합격인지 불합격인지에 대한 정보도 가지고 있습니다. 이미 우리가 갖고있는 입력값에 대한 합격 또는 불합격 정보를 통해 최적의 가중치 값 w를 찾을 예정입니다.
그런데, 최적의 가중치 값 w를 어떻게 찾는지 궁금하지 않으신가요? 이를 이해하기 위해서는 최대우도법(maximum likelihood estimation)이라는 개념을 알아둘 필요가 있습니다.
먼저 아래 영상을 통해 maximum likelihood estimation에 대한 의미를 알아보도록 할께요.
위의 강의에서 log가 쓰인 이유를 간단히 정리하자면 아래와 같습니다.
①
log함수는 concave(오목)이기 때문에, 미분 시 maximum 값을 고를 수 있게 된다.
②
log 함수는 미분이 쉽다.
③
log 함수는 곱하기 부분을 덧셈으로 나눌 수 있기 때문에, 전체 식을 미분하기 쉽다.
그리고 두번째로 기하적인 관점에서 Maximum likelihood estimation이 어떻게 동작하는지 살펴볼께요. (영어설명이긴 한데, 자막과 같이 보면 이해하는데 크게 어렵진 않으실거에요!)
강의는 잘 보셨나요? 그렇다면 제가 다시 정리해서 설명드려 볼께요.
먼저 아래 그림을 살펴볼께요.
<사진2>
우리에게는 X라는 입력데이터가 있습니다. 위의 사진에서 보면 X축에 있는 빨간점들이 되겠네요. 위의 확률분포는 Normal distribution 입니다. 가운데에 있는 입력변수들은 합격과 관련된 입력변수들입니다. 그런데, 위에 있는 Normal distribution 위치는 조금 이상하죠? 합격으로 부터 멀리떨어진 불합격과 관련된 입력변수의 확률값이 굉장히 높게 나오네요. 왜 이렇게 나온건지 지금부터 천천히 살펴 보겠습니다.
우리가 세운 모델(=위의 수식)에서는 X입력값 말고도 확률값에 영향을 미치는것이 있었습니다. 그것이 w(가중치)입니다.
다시 사진2를 보게 되면 초기에는 가중치값이 랜덤하게 설정되어 있다보니, 합격이 아닌 입력데이터X가 들어오더라도 최적화되지 않은 가중치 w의 영향으로 합격일 확률이 굉장히 높게 나왔어요.
하지만, 가중치들이 학습을 거치게되면 아래와 같이 입력데이터들에 따른 합격, 불합격 정보를 잘 나타나게 해줍니다.
<사진3> <사진4>
이제는 MLE(최대우도추정법)에 대한 정의를 이해하실 수 있으실 겁니다.
"우도(likelihood = L(Θ;w|x) 란 이미 주어진 표본데이터(X)들에 비추어 봤을 때 모집단의 parameter인 가중치(w)에 대한 추정이 그럴듯한 정도를 가리키며, 미지의 가중치(=parameter)값인 확률분포에서 뽑은 X값들을 바탕으로 우도를 가장 크게 해주는 추정방식을 Maximum Likelihood Estimation 이라고 한다"
자! 그렇다면 이제 수식을 살펴볼까요?
우리는 처음에 이진분류의 문제정의를 아래와 같이 만들었습니다.
그렇다면 위의 수식모델을 기반으로 입력데이터 X에 영향을 미치는 w에 대한 우도(Likelihood)를 아래처럼 구할 수 있게 됩니다. (첫번째 영상강의를 보시면 아래 수식의 의미를 정확히 이해하실수 있으실거에요!)
마지막으로 첫 번째 강의에서 언급해주신 대로 위의 수식을 log화 해주면 아래와 같은 수식이 완성되고, 우리의 최종 오차함수가 됩니다. (식 앞에 마이너스를 해준 이유는 신경망의 cost 함수에서는 미분시 최소값을 찾아야 하기 때문이에요!)
지금까지 이진분류에 따른 오차함수를 설정하는 방법에 대해서 알아보았어요.
오차함수를 정하는 방법을 아래처럼 요약할 수 있겠네요!
1. 문제정의에 따라 신경망이 출력하는 예상값과 실제 정답지에 대한 오차를 어떻게 설정할지 결정한다.
2. 오차함수를 결정할 때에는 미분이 쉽게 되는지, 기하적으로 미분시에 cost(오차)값을 최소한으로 만들어 줄 수 있는지를 살펴보아야 합니다.
<2. 다 클래스 분류에 사용되는 Cost function; Cross Entropy function>
다음장에서는 이진클래스 분류가 아닌 여러 클래스 분류에 대해서 알아보도록 할거에요. 핵심적인 설명은 이진분류에서 설명을 다했기 때문에 여기서는 수식만 설명을 하겠습니다.
이진 분류의 수식을 이해했으면 다 클래스에 대한 수식도 금방 이해할 수 있어요. 몇 가지 다른 점들만 설명할께요!
1. 분류하려고 하는 클래스를 아래와 같이 정의 한다.
2. 앞선 이진분류에서 언급한 (x,d) training data들에서 d의 표현식을 아래와 같이 정의한다. (dn의 각 성분은 대응하는 클래스가 정답 클래스일 때 1이 된다) 예를 들어, 우리가 0~9 숫자를 분류한다고 했을때, 우리가 갖고 있는 이미지 데이터 x가 2라고 하면 d는 d=[0 1 0 0 0 0 0 0 0 0] 가 됩니다.
그럼 이진분류의 기본개념을 생각해보면 다 클래스 분류의 cost function을 만들어 볼까요?
1. 먼저 사후확률 분포를 만들어 줍니다 ('사후확률분포'라는 용어 대해 깊게 생각 하실 필요는 없습니다!)
2. 위의 표기식에 우도를 구하면 아래와 같다
3. 위의 우도식을 log 취하여 부호를 반전한 것을 오차함수로 삼고, 이 함수를 cross entropy(or negative log likelihood)라고 한다.
사실 cross entropy라는 개념은 정보이론에서 KL divergence와 연계되서 설명이 많이 되는 개념이에요. 정보이론에서 사용되는 cross entropy 개념은 여기를 참고해주세요!
지금까지 딥러닝에서 쓰이는 대표적인 오차함수들에 대해서 알아보았습니다.
실제로는 딥러닝에서 쓰이는 cost function 종류가 많지는 않다고 해요. 하지만, 오차함수라는 개념이 왜 나왔는지에 대한 맥을 잡고 있다면, 자신이 새로이 문제정의를 하고 새로운 cost function을 만들어 좀 더 딥러닝 모델의 효율을 높일 수 있겠죠??
혹시, 글 초반부분에 Activation function에 대해서 언급하고 추후에 설명하겠다고 했던말 기억하시나요? 다음 장에서 Activation function에 대해 설명할 예정이니 많이 기대해주세요!
#Cost function #오차함수 #Maximum Likelihood Estimation (MLE) #Cross Entropy
#Logistic cost function
P.S 2장에서와 같이 책을 하나 더 추천해 주고 싶은데요. 수식에 대한 이해를 좀 더 깊게 하시고 싶으신 분이 계신다면 아래 책을 추천해드려요! 이번장에서 설명한 내용 대부분은 아래 책을 참고했으니 관심있으신 분은 한 번 읽어보시길 바랍니다!






























 VS
VS 




























 6. Backpropagation (2).pdf
6. Backpropagation (2).pdf



























{kind=link}