안녕하세요.
이번 글에서는 아래 논문을 리뷰해보려고 합니다. (아직 2차 검토를 하지 않은 상태라 설명이 비약적이거나 문장이 어색할 수 있습니다.)
※ 덧붙여 제가 medical imaging에 적용한 다른 전처리(or data augmentation) 방식들을 같이 공유하도록 하겠습니다.
ImageNet-Trained CNNs are Biased Towards Texture; Increasing Shape Bias Improves Accuracy And Robustness
Conference: 2019 ICLR
Authors: 영국의 Edinburgh 대학, IMPRS-IS (International Max Planck Research School for Intelligent Systems), 독일의 Tubingen 대학 간의 협동연구

0. Abstract

[요약]
1. Question (노란색 부분)
- 물체를 인식할 때 어떤 특징을 기반으로 해당 물체를 판별하나? → 즉, "갓난 아이 or 딥러닝 모델"이 해당 물체를 인식하기 위해 어떤 특징을 우선순위로 두고 학습을 하나?
- 일반적으로 물체를 인식하기 위해 CNN 모델들은 물체의 shape을 기반으로 학습한다고 한다.
- 하지만 몇몇 연구에서는 image textures를 기반으로 학습한다고 한다.
- 위와 같은 주장 중에 무엇이 맞는지 판단하기 위해, texture-shape cue conflict 이미지를 기반으로 사람과 CNN 모델들을 정성적으로 평가했습니다.
- "texture-shape cue conflict"라는 용어는 abstract 부분만 보면 무엇인지 파악하기 힘듭니다. (abstract만 읽었을 때는 무슨 말인지 몰랐는데, 바로 아래 figure1을 보니까 바로 알겠더군요!)
- 예를 들어, 아래 그림과 같이 "코끼리 texture로만 이루어져있는 (a) 이미지"에서는 ResNet-50가 코끼리라고 올바르게 분류했고, "texture and shape"이 혼합된 (b) 이미지"에서는 고양이라고 옳게 분류했습니다. 그런데, "texture-shape cue conflict" (c) 이미지 (→ 객체에 특정 texture를 입힌 경우) 에서는 코끼리라고 분류했습니다.
- 그렇다면, (c) 이미지에서 ResNet-50 모델은 올바르게 분류한 것일까요?
- 올바르게 분류했다고 하시는 분들은 texture를 근거로 삼았을 것이고, 잘 못 분류했다고 하시는 분들은 shape을 근거로 삼았을 것입니다.

2. 실험방법 (파란색 부분)
- 위와 같은 질문에 답하기 위해 아래와 같이 실험 세팅을 했습니다.
- 실험을 위한 CNN 모델로 ResNet-50을 사용했습니다.
- Stylized-ImageNet 이미지를 이용해 CNN을 학습시킵니다.
- Figure1에서 (c)를 보면 CNN은 texture를 기반으로 분류한다는 사실을 파악할 수 있습니다.
- ImageNet에 Style Transfer 기술을 이용하면 실제 객체들의 shape은 유지된 채로 texture만 변경됩니다. (Style Transfer 기술을 뒷 부분에서 더 자세히 설명하도록 하겠습니다)
- 예를 들어, CNN이 다양한 texture가 적용된 고양이 이미지들 (← 해당 이미지들은 고양이라고 labeling 되어있음) 을 학습하게 되면, texture에 민감하게 반응하지 않을 거라고 추측해볼 수 있습니다. 즉, shape을 중요 특징으로 삼고 classification 할 수 도 있을거라고 추론할 수 있게 되는 것이죠.
- 사람은 어떤 특징(texture or shape)으로 물체를 판단하는지 알아내기 위해 psychophysical lab에서 96명의 사람들(observers)을 대상으로 psychophysical trail을 했다고 합니다.
3. Result (분홍색 부분)
- 실험결과 아래와 같은 해석을 내놓았습니다.
- Classifcaiton할 때, CNN은 texture를 기반으로 학습하고, 사람들은 shape을 기반으로 학습한다
- 추가적으로 shape 기반으로 학습을 진행하면 CNN을 기반으로 하고 있는 object detection의 성능이 올라간다고 합니다.
- 그 이유는 distorted image (왜곡된 이미지들) 또는 shape-based representation image(shape의 특징이 강하게 묻어나는 이미지들) 에 robust(→민감하지 않게)하게 작동하기 때문이라고 합니다. → 즉, 이 부분이 실험을 통해 주장한 또 하나의 해석(analysis)입니다.
1. Introduction
1-1) 첫 번째 문단
→ 기존 연구들에서는 CNN이 shape 특징을 기반으로 하고 있는 가설 소개

- Introduction의 시작은 "어떻게 CNN이 object recognition, semantic segmentation에 좋은 성능을 보일 수 있었을까?"라는 질문으로 시작됩니다.
- 윗 질문에 대한 가장 보편적인 답으로 "CNN은 low-level features (edge=simple shape)에서 좀 더 복잡한 shape으로 결합해 나가기 때문이라고 합니다.
- CNN 구조를 보면 첫 번째 layer에 있는 CNN filter들이 edge 정보를, 마지막 layer에 위치한 CNN filter들은 좀 더 abstract한 정보를 추출한다는 뜻으로 이해해도 좋을 것 같습니다.)
(↓↓↓이해가 어려우신 분들은 아래 글을 참고해주세요↓↓↓)
https://89douner.tistory.com/57?category=873854
3. CNN(Convolution Neural Network)는 어떤 구조인가요?
안녕하세요~ 이번글에서는 Convolution Neural Network(CNN)의 기본구조에 대해서 알아보도록 할거에요. CNN은 기본적으로 Convolution layer-Pooling layer-FC layer 순서로 진행이 되기 때문에 이에 대해서 차..
89douner.tistory.com
- High-level units은 CNN의 마지막 layer에 있는 CNN filter들을 이야기 하고 있고, 이러한 high-level units들은 이미지들의 shape을 학습할 것이라고 언급하고 있습니다 (이전에 언급한 complex shape을 shape과 동의어로 쓴 듯 합니다. 굳이 구분하자면 edge=simple shape, shape=complex shape)
- 첫 번째 문단을 정리하자면 아래와 같습니다.
"기존의 연구들은 CNN이 shape을 기반해서 classification을 하고 있었다"
1-2) 두 번째 문단
→ 첫 번째 문단에서 주장한 가설의 근거가 되는 논문들 나열

- 앞서 언급한 "기존 연구들은 CNN이 shape을 기반해서 classification 하고 있다"라는 주장의 근거를 뒷 받침해주는 논문들을 소개하고 있습니다 (related work 느낌이네요).
1-3) 세 번째 문단
→ 첫 번째, 두 번째 문단에서 주장한 shape 기반의 classification을 반박하는 texture 기반의 classification 가설 소개

- 세 번째 문단에서는 앞서 주장한 내용들을 반박하는 근거들이 나옵니다. 즉, CNN 모델이 shape이 아닌 texture를 기반해 classification 한다는 주장입니다.
- Gatys (2017) 논문에서는 shape 특징이 거의 없는 객체들도 잘 인식할 수 있다고 언급했습니다 (Thanks to texturised features.
- Ballester (2016) 논문에서는 CNN 모델이 sketch한 객체들을 인지하는데 좋지 않은 성능을 보여주고 있다고 언급하고 있습니다. (예를 들어, 아래와 같은 이미지는 스케치로만 그려졌기 때문에 texture 정보가 없다고 할 수 있죠)

- Gatys (2015) 논문에서는 texture와 같은 local 정보(=객체기준에서는 texture는 local 정보에 해당합니다) 만 가지고도 충분히 ImageNet 객체를 인식할 수 있다고 주장합니다. → texture representation, gram matrix와 같은 설명을 위해서는 "Texture synthesis using convolutional neural networks" 논문을 전반적으로 이해 해야합니다. 해당 논문은 style-transfer 분야에 중추적인 역할을 하는 논문인기 때문에 style-transfer 카테고리를 따로 만들어 올릴 때 자세히 설명하도록 하겠습니다 (정리된 내용은 있는데 다른 논문들 먼저 정리하고 빠르게 올리도록 할게요!)

- Brendel (2019) 논문에서는 receptive field sizes에 제약을 걸어도 좋은 성능을 보인다고 합니다. 해당논문(아래 그림)을 보니 여기서 말하는 receptive fields size란 입력 이미지 크기를 의미하는 듯 했습니다. → 즉, texture 정보만 이용해도 높은 accuracy를 보여준다는 것을 말하고자 한듯 합니다.

- 결국, 세 번째 문단을 요약하자면 아래와 같습니다.
"기존에 주장한 것(두 번째 문단: shape기반의 CNN 분류)과 달리, CNN은 texture 기반으로 classification 한다. 그리고 이것을 texture hypothesis라 하겠다"
1-4) 네번째 문단
→ 앞서 주장한 대립되는 두 가설중에 어떤것이 맞는지 실험 and 해당 실험 결과가 주는 contribution

- 앞서 언급한 두 가지 가설 (Shape-base VS Texture base) 중에 어떤 가설이 맞는지 입증하는 건 딥러닝, human vision, neuroscience 분야에서 모두 중요한 일입니다.
- 이것을 입증하기 위해 사람과 CNN 모델들이 shape biase한지, texture biase 한지 psychophysical 실험을 통해 정성적으로 평가했습니다.
- 이러한 실험을 위해 style transfer 기술을 사용했습니다.
- style transfer를 이용해 texture-shape cue conflict 이미지들을 생성하고, 해당 이미지를 이용해 정성적인 평가에 이용했습니다 (→자세한건 실험 부분에서 설명이 되겠죠?)
- 이러한 실험은 두 가지 main contribution이 있습니다.
- changing biases: 하나는 texture bias의 CNN 모델들을 shape bias로 변경해준 것
- discovering emrgent benefits of chanaged biases
- shape bias가 가미된 CNN은 왜곡된 이미지들에 더 robust하게 작동된다는 것
- classification과 object recognition tasks에 더 뛰어난 성능을 보여줬다는 점
"실험을 통해 shape bias하게 CNN을 training 시킬 수 있었으며, shape bias가 가미된 CNN 모델은 classification, object recognition 성능에 긍정적인 영향을 미쳤다"
2. Method
→ Method에서 앞서 언급한 실험들에 대해 ouline을 잡아 줄 예정 + Extensive details들은 Appendix를 참고 할 것 + 데이터, 코드들은 아래 github 사이트 참고

https://github.com/rgeirhos/texture-vs-shape
rgeirhos/texture-vs-shape
Pre-trained models, data, code & materials from the paper "ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness" (ICLR 2019 Oral) -...
github.com
2-1) Psychophysical experiments
→ Psychophysical experiments 설명

- 사람이 shape기반으로 판단하는지, texture 위주로 판단하는지 알아보기 위해서는 사람들을 대상으로 실험해야 합니다.
- 첫 번째 문단은 사람을 대상을 어떻게 실험을 진행했는지 설명해줍니다.
- 간단하게 설명하자면 사람과 AlexNet, GoogLeNet, VGG-16, ResNet-50 에게 다양한 사진들을 보여주고, 해당 사진이 무엇인지 classification하는 실험입니다. (→"2-2. dataset" 부분을 보면 더 자세히 이해하실 수 있습니다)
- 해당 문단만 읽으면 실험이 어떻게 진행 됐는지 모르고, "appendix A.1~A.4" 부분을 보시면 어떻게 Psychophysical experiments 가 진행됐는지 알 수 있습니다. → Appendix 내용까지 다 설명하면 너무 길어질 듯하여 생략했습니다.
2-2) Dataset sets
2-2-1) 첫 번째 문단
→ 이 실험이 6개의 실험으로 구성되어 있는데, 각각의 실험들은 개별적인 dataset을 기반으로 진행

- texture bias인지 shape bias인지 테스트 하기 위해 6개의 main 실험들을 진행했습니다.
- 그 중 5개의 실험은 아래와 같습니다.
- 앞서 2-1에서 설명한 것처럼 AlexNet, GoogLeNet, VGG-16, ResNet-50, 사람에게 아래 다섯 종류(=5개의 실험)의 이미지들을 보여주고, 어떤 이미지인지 맞추도록 합니다.
- 그 중 5개의 실험은 아래와 같습니다.
2-2-2) 두 번째 문단
→ "shape VS texture"를 입증 할 6번째 실험 소개

- 6번째 실험을 진행하기 위한 데이터 셋을 생성해야 했습니다.
- 우선, 4개의 CNN 모델 (AlexNet, GoogLeNet, VGG, ResNet-50) 이 모두 올바르게 분류한 이미지들을 수집했습니다.
- 16개의 카테고리 마다 80개의 이미지를 선별해 총 1280개 데이터 셋을 구축했습니다.
- 그리고, 해당 이미지들(=1280개)에 cue conflict를 적용시키기 위해 style transfer를 적용했습니다.
- 만약, CNN 모델들이 cue conflict가 적용된 이미지들을 잘 못 분류한다면 "shape VS texture" 중에 어느 특징을 기반으로 학습하는지 알려줄 수 있게 됩니다. → 왜냐하면, cue conflict가 적용되기 이전 4개의 CNN 모델에서는 모두 올바르게 분류했기 때문
2-2-3) 세 번째 문단
→ 이 논문에서 주장하는 shape의 정의와 texture의 정의

- "2-2-1"을 보면 silhouette 기반의 데이터를 볼 수 있습니다.
- 이 논문에서는 silhouette을 bounding contour라고 정의했는데 이것이 shape과는 조금 다르다고 합니다.
- silhouette보다는 객체의 broader 부분을 shape으로 봐야한다고 언급하고 있습니다.
- 또한, 어떤 이미지가 texture 기반이라고 말할 때에는 'spatially stationary statistics' 특성을 갖고 있어야 한다고 주장합니다. → "Texture and art with deep neural networks"라는 논문에서 좀 더 수학적으로 texture에 대한 정의를 설명하고 있습니다.
- All images with equal Nth-order joint pixel histograms are preattentively indistinguishable for human observers and therefore samples from the same texture.
- A joint histogram is a multidimensional histogram created from a set of local pixel features.
- 즉, 아래 그림처럼 pixel histogram이 유사하게 나온다면 texture가 같다고 정의합니다.

- 그런데 이 논문에서는 아래 그림처럼 여러 bottle(병)을 기반으로 texture를 변경했습니다. 아래 그림에서 두 번째 이미지를 보면 very local level은 local shape이 될 수 있기 때문에 non-stationary 특성을 갖는다고 할 수 있습니다.
- 예를 들어, 아래 두 번째 이미지에서 개별 bottle만 비교하면, 서로 texture가 다를 것입니다. 하지만, 여러 bottle을 기준으로 봤을 때는 서로 texture가 비슷할 수 있습니다.


2-3) Dataset sets

- 앞서 언급한 cue conflict 이미지를 만들기 위해 imageNet에 style transfer 기술을 적용시켜 SIN (Stylized-ImageNet) 데이터 셋을 구축했습니다.
- 이 논문에서는 style transfer 기술을 적용시키기 위해, AdaIN style transfer 모델을 사용했고, AdaIN을 학습시키기 위해 Kaggle에 있는 "painter by numers"라는 데이터 셋을 활용했습니다.
https://www.kaggle.com/c/painter-by-numbers
Painter by Numbers
Does every painter leave a fingerprint?
www.kaggle.com
- AdaIN Fast style transfer 모델을 사용한 이유는 두 가지가 있습니다.
- Training은 SIN 데이터 (made by AdaIN)로 하고, test는 cue conflict 데이터(maybe, made by existing iterative stylization)에서 함으로써, 특정 stylization 기법에 의해 결과가 바뀌지 않는 다는 것을 보여주기 위함
- ImageNet에 기존 iterative stylization 기법을 적용하면 너무 오랜 시간이 걸리기 때문
https://github.com/rgeirhos/Stylized-ImageNet
rgeirhos/Stylized-ImageNet
Code to create Stylized-ImageNet, a stylized version of standard ImageNet (ICLR 2019 Oral) - rgeirhos/Stylized-ImageNet
github.com
- 생성된 이미지는 아래와 같습니다.

- 위의 데이터들을 pre-trained 시킨 CNN 모델은 아래 github 주세에서 제공되고 있습니다.
https://github.com/rgeirhos/texture-vs-shape
rgeirhos/texture-vs-shape
Pre-trained models, data, code & materials from the paper "ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness" (ICLR 2019 Oral) -...
github.com
3. Result
3-1. Texture VS Shape bias in humans and ImageNet-Trained CNNs
→ Figure2, Figure4 기반으로 CNN과 사람이 shape 기반으로 classification 하는지, texture 기반으로 classifcation 하는지 보여줌
3-3-1) 첫 번째 문단
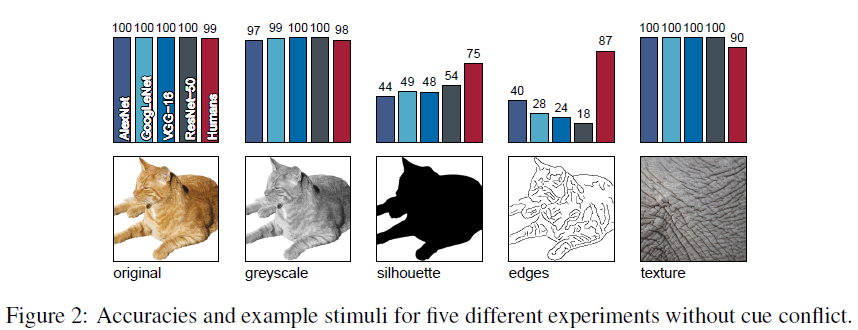
→ Figure2의 결과: Original, Greyscale, Silhouette, Edge 이미지 분류 결과 (CNN VS 사람)

- Graysacle은 shape과 texture의 특징을 모두 갖고 있다고 주장합니다.
- silhouette에서는 CNN이 사람보다 accuracy가 떨어집니다.
- edge에서는 그 차이(=CNN이 사람보다 accuracy가 떨어지는 정도)가 더 심합니다.
- 이러한 결과는 사람이 texture 정보가 없는 이미지에 더 잘 대응(=잘 classification)하는 것을 보여줍니다.
- 특히 CNN은 domain shift에 취약한 것으로 드러났습니다.
- CNN 입장에서는 학습한 데이터가 natural images입니다.
- Texture가 없는 sketch 이미지는 training 때 사용되지 않은 이미지입니다.
- 즉, sketch 이미지를 inference 할 때는 완전히 다른 domain을 inference한다고 볼 수 있습니다.
3-3-1) 두 번째 문단
→ Figure4의 결과: Texture, Cue conflict 이미지 분류 결과 (CNN VS 사람)

- Fig 2를 보면 Texture 베이스의 그림이 있습니다.
- 사람은 texture 베이스의 이미지만 보고서는 정확히 분류하지 못하고, CNN은 cue conflict (Shape 기반) 이미지를 잘 분류하지 못하는 것을 볼 수 있습니다.
- 수직라인들은 CNN 모델들과 사람의 16개 모든 카테고리 classification 평균 결과입니다.
- 좌측에 위치할 수록 shape을 기반으로 classification하고, 우측에 위치할수록 texture에 기반해서 classification 한다고 해석하고 있습니다.

""3-1" 실험 결과를 통해 CNN은 texture bias 하다고 할 수 있습니다"
3-2. Overcoming the texture bias of CNNs
→ Style transfer를 적용시킨 data를 기반으로 학습 시켰을 때, texture 기반의 CNN 모델을 shape 기반의 CNN 모델로 변경할 수 있는지를 보여주는 결과들
3-2-1) 첫 번째 문단

- 앞선 실험에서 CNN 모델은 texture bias하다고 했습니다.
- 그래서, 이 논문에서는 CNN이 많은 local texture features을 기반으로 classification 한다고 추론하고 있습니다.
- "3.2" 실험에서는 texture bias 성향을 갖은 CNN 모델을 uninformative style( shape base인 듯 합니다) 성향으로 바꾸려는 시도를 했습니다.
- 이를 위해, ResNet-50을 베이스로 하고, SIN (Stylized-ImageNet) data set을 사용했습니다.
3-2-2) 두 번째 문단
→ Table 1에서 첫 번째 행에 해당하는 결과들 설명

- SIN 데이터만으로 training, evaluation한 결과 top-5 79% accuracy를 달성했습니다.
- IN 데이터만으로 training, evaluation한 결과 top-5 92.9% accuracy를 달성했습니다.
- 이러한 차이는 SIN 데이터로 학습된 CNN은 더이상 texture 정보가 predictive하지 않기 때문에 SIN으로만 학습하고 evaluation 하는 것이 더 어려운 task임을 보여줍니다.
- You use predictive to describe something such as a test, science, or theory that is concerned with determining what will happen in the future.
- SIN feature(including only shape feature)으로 학습된 CNN들은 ImageNet feature (texture feature + other features(=shape feature + etc..) 에도 잘 대응(부합)하지만, ImageNet features들로 학습된 CNN 모델들은 SIN feautre에 부합하지 않은 것으로 보입니다.
- 결과론적으로 해석하자면 ImageNet features들로 학습한 CNN 모델들은 texture bias하다고 할 수 있습니다.

3-2-3) 세 번째 문단
→ Table 1에서 2,3,4 번째 행에 해당하는 결과들 설명

- BagNets을 이용해 local texture features (Fig1에서 (c)이미지) 만 training하고 evaluation 해봤습니다.
- "1-3) 세 번째 문단"에서 receptive field에 대해 소개했습니다.
- 즉, local path image를 receptive field로 갖는 ResNet-50은 학습 시 전체 이미지에서 제한적인 부분만 학습하는 것과 같기 때문에 long-range spatial relationships를 고려하지 않은채 학습하게 됩니다.
- 이러한 네트워크(BagNet)는 ImageNet에는 높은 성능을 보이지만, SIN데이터에는 좋지 못한 성능을 보입니다.
- 쉽게 말해 아래 테이블의 결과를 다음과 같이 정리 할 수 있습니다.
- IN→SIN (ResNet-50보다 BagNet에서 성능이 더 떨어지는 이유)
- ImageNet으로 학습한 CNN 모델은 texture 정보외에 spatial relationship 같은 정보들도 학습하게 됩니다.
- SIN 데이터에는 texture 정보가 없는데, 여기에 receptive field크기에 제약까지 걸어버리면 spatial relationship 같은 정보도 잃어버리기 때문에 성능이 더 안 좋아집니다.
- 결국, SIN data를 만든다는 건 local texture feature 정보도 없앤다는 것과 같기 때문에, local texture feature들이 중요한 요소가 되는 기존 CNN (on ImageNet) 모델들의 성능이 현저히 떨어지게 되는 것입니다.
- IN→SIN (ResNet-50보다 BagNet에서 성능이 더 떨어지는 이유)

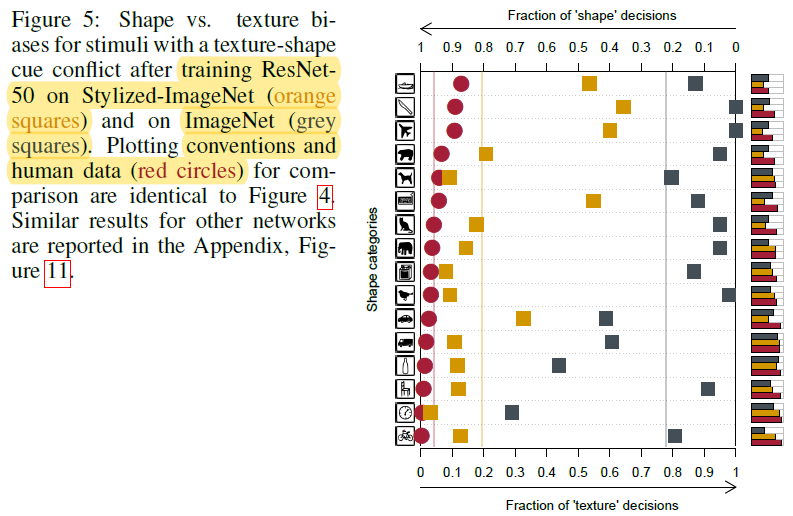
3-2-4) 네 번째 문단
→ Figure 5 설명하는 문단

- Figure 5를 보면, SIN data로 학습된 ResNet-50은 Figure 4와 비교했을 때, 좀 더 shape bias하게 변한 것을 확인할 수 있습니다.
3-3. Robustness and accuracy of shape-based representations
- "3-3"에서는 3가지 실험을 진행 했습니다.
- 이 실험에서 중요한 부분은 SIN, IN data를 다 같이 학습시킨 모델의 성능이 더 좋아질 수 있는지 입니다.

- 첫 번째 실험은 Classification performance 관점입니다.
- SIN+IN을 동시에 학습시킨 후, IN을 다시 fine-tuning 시킨 결과가 기존 IN으로만 학습시간 ResNet(=vanilla ResNet) 모델보다 좋습니다.
- 두 번째 실험은 Transfer Learning 관점입니다.
- CNN 모델은 Object detection 모델의 backbone 역할을 하는데, SIN+IN으로 학습시킨 CNN을 Object detection의 backbone으로 사용하면 object detection 성능이 5%나 향상되는 것을 볼 수 있습니다.
- 그 이유는 object detection의 성능 지표인 mAP에는 bounding box가 얼마나 fit하게 잡히는지도 포함되는데, 보통 bounding box가 fit하게 잡으려면 객체의 윤곽(=shape) 부분을 잘 포착해야합니다.
- 그래서, shape feature도 잘 학습한 shape-ResNet 모델을 backbone으로 사용하면 object detection 성능이 큰 폭으로 향상되는 것이라고 주장합니다.

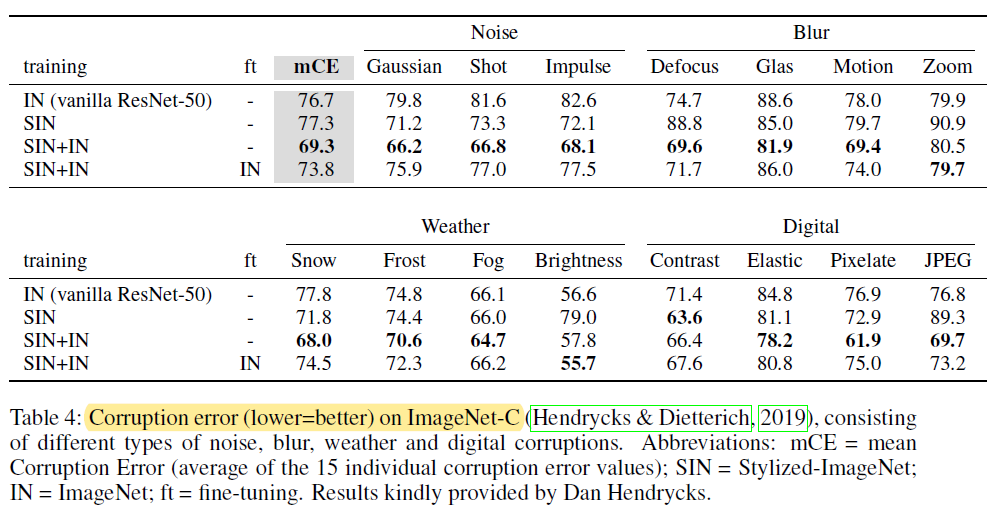
- 세 번째 실험은 Robustness against distortions 관점입니다.
- 사람들은 왜곡된 이미지를 classification 할 때 accuracy 결과에 편차가 있습니다. (by box plot)
- CNN 모델들은 일정한 accuracy 결과를 보여주는데 (← 아마 모든 seed값을 동일하게 고정했다고 가정한 것이 아닌가 싶습니다), 특히 SIN 데이터로 학습한 CNN 모델은 다양한 noise or distortion에 robust하게 동작하는 것을 확인할 수 있습니다.



- ImageNet-C 데이터들은 기존 ImageNet에 다양한 nosie를 섞어서 만든 dataset입니다.
- SIN 데이터와 IN 데이터를 동시에 학습시킨 경우 ImageNet-C 데이터셋에서 더 좋은 성능을 보여줍니다. → 즉, noise에 더 robust하다고 할 수 있죠.
- 결국 SIN 데이터를 함께 학습시킨다는 건, CNN 입장에서 다양한 augmentation이 적용된 데이터들을 학습시키는 것이라고도 볼 수 있습니다.

- 아래 테이블을 봤을 때 주목할 부분은 SIN+IN을 학습시킨 후 IN 데이터로 fine-tuning 한 것보다, SIN+IN으로만 학습시킨 CNN 모델이 훨씬 더 noise에 robust하다는 것을 확인할 수 있습니다.
4. Conclusion
"Shape-based Representation can be beneficial for recognition tasks."
"Shape-based CNN is the better backbone for Object detection"
"Shape-based training is robust to distortion(noises)"
5. 개인적인 경험 및 생각
아무래도 의료 이미지를 CNN에 적용시킨적이 많아서 아래와 같은 경험 및 생각을 하게 됐습니다.
- Super Resolution (SR) 을 전처리 작업으로 사용할 경우
- SR을 이용하면 저화질을 고화질로 만들 수 있다.
- 그럼 texture가 좋아질 수 있고, SR을 통해 생성된 이미지들은 좀 더 textue feature를 갖고 있을 수 있다.
- SR이 적용된 이미지를 사용한다면 texture가 정말 중요한 feature로 여겨지는 domain에서는 유용할 수 있다.
- 하지만, SR이 적용되기 전의 이미지 크기가 CNN의 크기인 224x224를 넘는다면 사용하는것이 무의미하다.
- 왜냐하면, SR을 적용해 224x224를 448x448로 만들어 준다고 해도, 다시 입력 이미지 크기에 맞게 224x224로 줄여줘야 하기 때문이다. → 즉, texture 변화가 없을 수 있다는 뜻이다.
- 하지만, 마지막 layer에 GAP (global Average Pooling)을 적절하게 이용해준다면 입력 이미지 크기를 굳이 축소시킬 필요가 없으므로, SR을 전처리 or data augmentation 기법으로 이용해볼 수 있다.
- Medical imaging에 적용시킬 경우
- 의료 이미지에서 texture가 중요한 feature일 수 도 있기 때문에 함부로 SIN+IN 적용된 모델을 사용하는건 위험할 수 있습니다.
- 하지만, medical imaging에서도 noise 문제가 존재하기 때문에, SIN+IN (without fine-tuning IN data) 데이터로 학습시킨 모델을 이용해 transfer learning을 적용한다면 noise에 robust한 모델을 만들 수 도 있을거라 생각합니다.
이상으로 논문리뷰를 마치겠습니다!
아래 영상은 style-transfer 공부하다가 만든 영상입니다.
무성영화에 Fast style transfer를 적용시킨 후, 노래영상을 입혔습니다.
즐겁게 봐주세요^^~
(Stylized soundless video +"12:45" song)
원본영상
https://www.youtube.com/watch?v=PoAJ1KoBcEk
원본노래
https://www.youtube.com/watch?v=OyTIMOlY1ag
'딥러닝 응용 > CNN 학습기법관련 논문들' 카테고리의 다른 글
| 2. Bag of Tricks for Image Classification with Convolutional Neural Networks (0) | 2021.06.06 |
|---|---|
| 이 글을 쓰는 이유 (0) | 2021.06.04 |