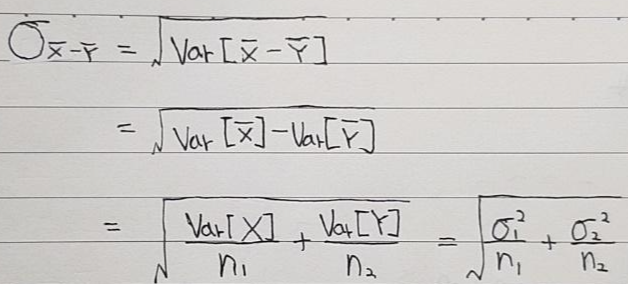이번 글에서는두 집단의 평균 차이를 검정(test)하는 세 가지 가설검정 방식중 하나인 이(2)표본 Z검정에 대해 알아보도록 하겠습니다.
Independent Samples Z-Test is also called the Two-Sample Z-Test or Z-Test for Independent Samples.
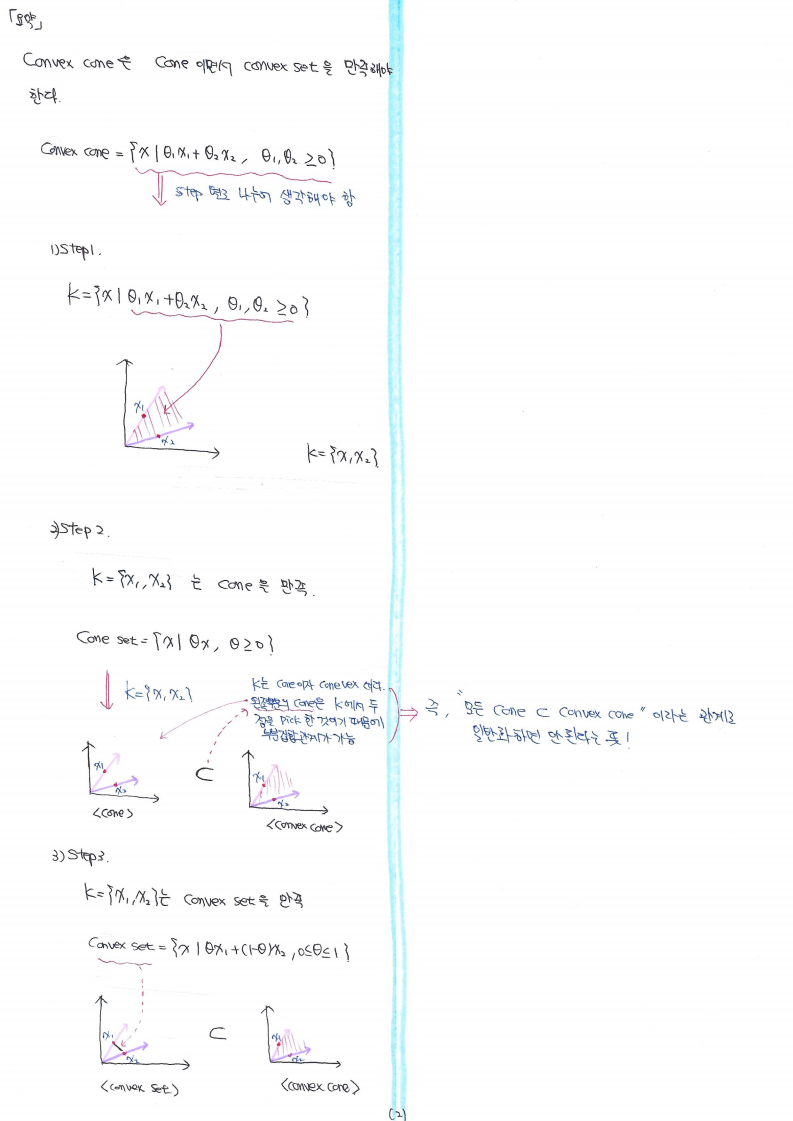
이(2)표본 Z 검정 (Two-sample Z test) = 독립표본 Z검정 (Independent Z test)
독립표본 T 검정 (Independent Sample T test)
대응표본 T 검정 (Paired Sample T test)
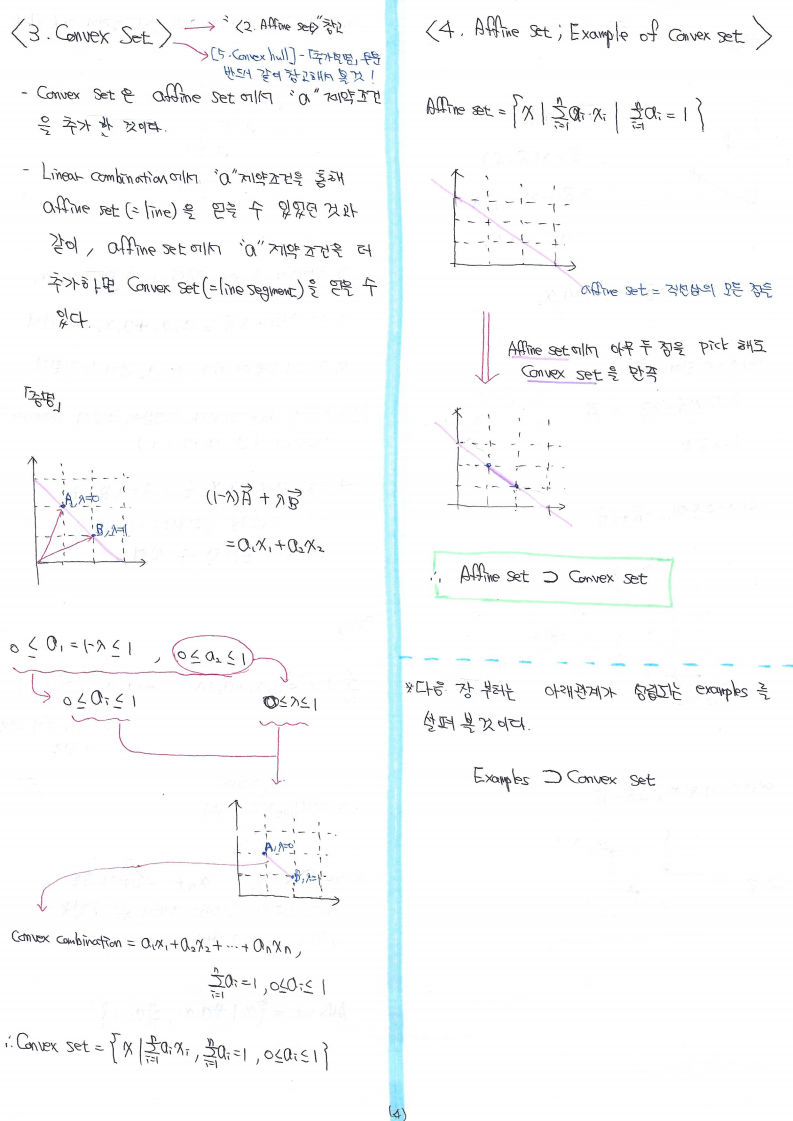
[가설검정의 종류]
'차이'와 관련된 검정
'평균'의 차이를 검정 하고 싶을 때
1-1. 비교하는 집단이 하나일 때
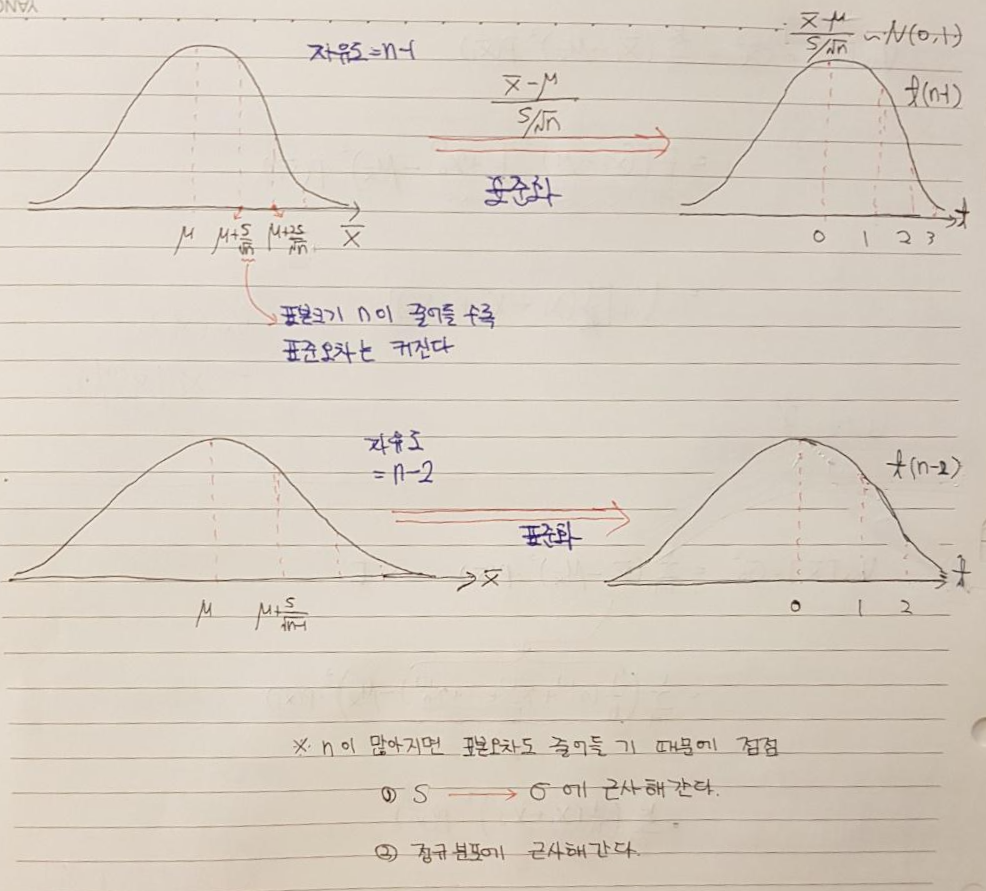
1-1-1. 모분산을 알고 있는 경우
일(1)표본 Z 검정 (One-sample Z test) → ex) 귀무가설(\(H_{0}\)): 한국의 평균은 K이다.
1-1-2. 모분산을 모르는 경우
일(1) 표본 T 검정 (One-sample T test) → ex) 귀무가설(\(H_{0}\)): 한국의 평균은 K이다.
1-2. 비교하는 집단이 둘일 때
1-2-1. 모분산을 알고 있는 경우
이(2)표본 Z검정 (Two-sample Z test) → ex) 귀무가설(\(H_{0}\)): 남, 녀간의 평균에 차이가 없다.
1-2-2. 모분산을 모르는 경우 & 표본이 작을 때
1-2-2-1. 독립표본 T 검정 (Independent Sample T test) → ex) 귀무가설(\(H_{0}\)): 남, 녀간의 평균에 차이가 없다.
1-2-2-2. 대응표본 T 검정 (Paired Sample T test) → ex) 귀무가설(\(H_{0}\)): 남, 녀간의 평균에 차이가 없다 & 해당 차이를 반복해서 검증 (한 달간 간격을 두고 측정: 1개윌 뒤, 2개윌 뒤, 3개윌 뒤, ....)
1-3. 비교하는 집단이 셋 이상일 때
1-3-1. ANOVA (분산분석)
1-3-1-1. 일원 분산분석 (One-way ANOVA) → ex) 귀무가설(\(H_{0}\)): 한국, 미국, 독일의 평균에 차이가 없다
1-3-1-2. 반복측정 분산분석 (Repeated Measures ANOVA) → ex) 귀무가설(\(H_{0}\)): 한국, 미국, 독일의 평균에 차이가 없다 & 해당 차이를 반복해서 검증 (한 달간 간격을 두고 측정: 1개윌 뒤, 2개윌 뒤, 3개윌 뒤, ....)
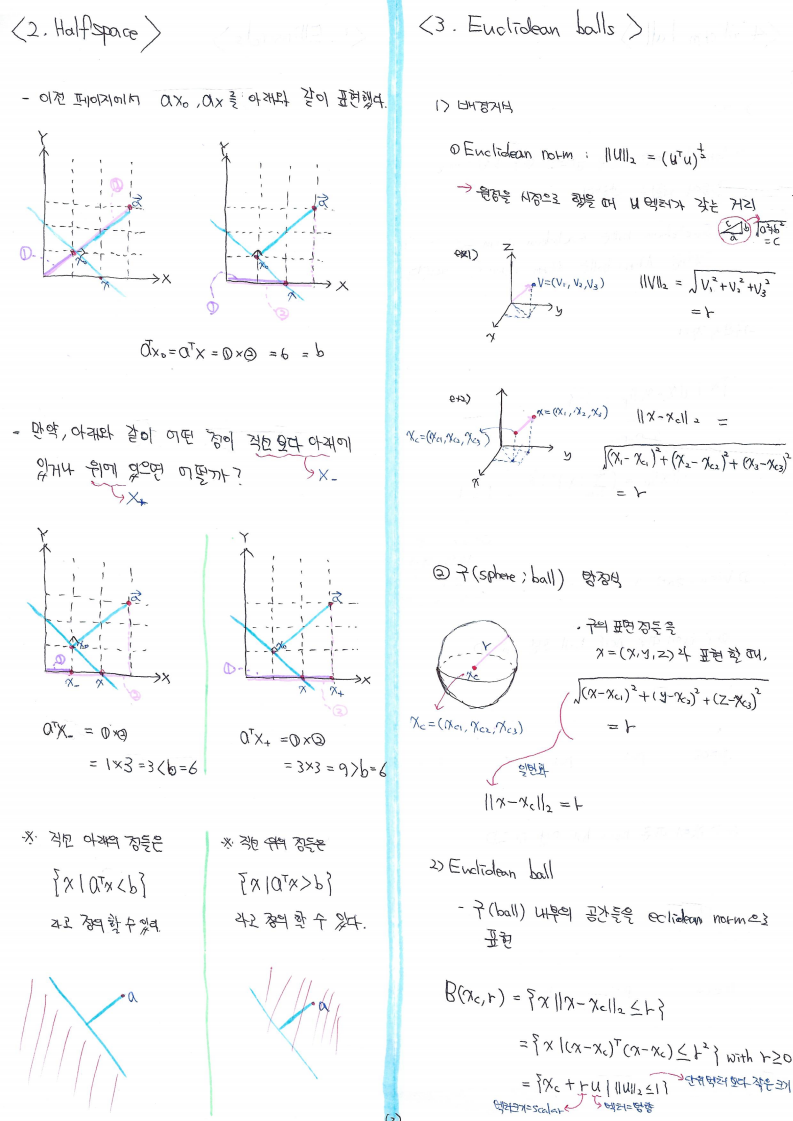
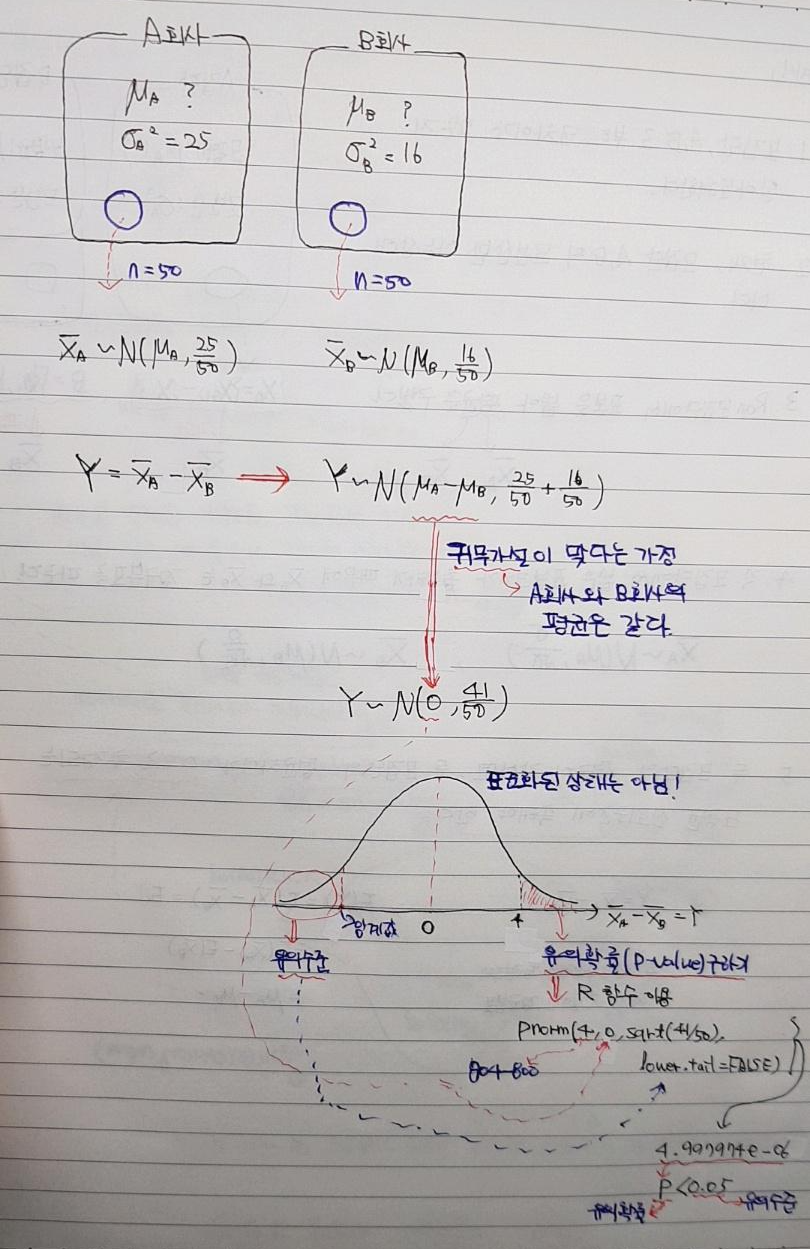
먼저, 일표본 Z검정과 다른 점은, 두 모집단의 평균은 추정하지 못한상태(=두 모집단의 평균은 모르는 상태)이고, 각 두 모집단의 모분산만 알고 있는 경우입니다.
이러한 제약조건에서 어떻게 두 집단의 평균이 같은지 다른지를 판단하는지 아래 가설검정 방식을 통해 알아보도록 합시다.
(위의 설명에서 언급한 \(\bar{X}_B\)가 아래 그림의 \(\bar{Y}\)라고 생각하시면 됩니다.)
이미지 출처: https://www.youtube.com/watch?v=z6gfv9Aojpk
[예시1] LG 트윈스 팀장인 J씨에게 두 야구배트 업체로부터 자신들의 배트를 사용해달라고 의뢰가 들어왔습니다. 두 업체의 가격은 똑같았지만 평소 B회사와 친분이 있었기 때문에, A회사의 배트 강도와 B회사의 배트 강도가 별 차이가 없다고 판단하면, B회사의 배트를 사용하려고 합니다. 그렇다면, A회사의 배트 강도와 B회사의 배트 강도는 같은지 알아봅시다.
팀장 J씨는 A회사의 배트들의 분산(강도와 관련된 분산)과 B회사의 분산 값을 알고 있습니다.
팀장 J씨는 두 업체를 방문해 각각 50개씩 배트 표본을 추출했습니다.
A,B회사의 모든 배트에 대한 각각의 평균강도는 알 수 없지만, 추출한 표본에서 평균강도를 구할 수는 있습니다.
A회사에서 뽑은 50개 배트(=A회사의 표본)의 강도 평균은 804라고 합시다.
B회사에서 뽑은 50개 배트(=B회사의 표본)의 강도 평균은 800이라고 합시다.
p-value가 유의수준보다 낮기 때문에 귀무가설을 기각하고 대립가설을 채택합니다.
즉, A회사와 B회사의 배트강도는 차이가 있다는 판단을 했습니다.
팀장 J씨는 A회사에서 뽑은 배트(=표본)들의 평균 강도가 더 강하기 때문에 (804>800), A회사의 배트를 사용하기로 결정합니다.
일(1)표본 Z 검정 (One-sample Z test) → ex) 귀무가설(\(H_{0}\)): 한국의 평균은 K이다.
1-1-2. 모분산을 모르는 경우
일(1) 표본 T 검정 (One-sample T test) → ex) 귀무가설(\(H_{0}\)): 한국의 평균은 K이다.
1-2. 비교하는 집단이 둘일 때
1-2-1. 모분산을 알고 있는 경우 & 표본이 클 때
이(2)표본 Z 검정 (Two-sample Z test) → ex) 귀무가설(\(H_{0}\)): 남, 녀간의 평균에 차이가 없다.
1-2-2. 모분산을 모르는 경우 & 표본이 작을 때
1-2-2-1. 독립표본 T 검정 (Independent Sample T test) → ex) 귀무가설(\(H_{0}\)): 남, 녀간의 평균에 차이가 없다.
1-2-2-2. 대응표본 T 검정 (Paired Sample T test) → ex) 귀무가설(\(H_{0}\)): 남, 녀간의 평균에 차이가 없다 & 해당 차이를 반복해서 검증 (한 달간 간격을 두고 측정: 1개윌 뒤, 2개윌 뒤, 3개윌 뒤, ....)
1-3. 비교하는 집단이 셋 이상일 때
1-3-1. ANOVA (분산분석)
1-3-1-1. 일원 분산분석 (One-way ANOVA) → ex) 귀무가설(\(H_{0}\)): 한국, 미국, 독일의 평균에 차이가 없다
1-3-1-2. 반복측정 분산분석 (Repeated Measures ANOVA) → ex) 귀무가설(\(H_{0}\)): 한국, 미국, 독일의 평균에 차이가 없다 & 해당 차이를 반복해서 검증 (한 달간 간격을 두고 측정: 1개윌 뒤, 2개윌 뒤, 3개윌 뒤, ....)
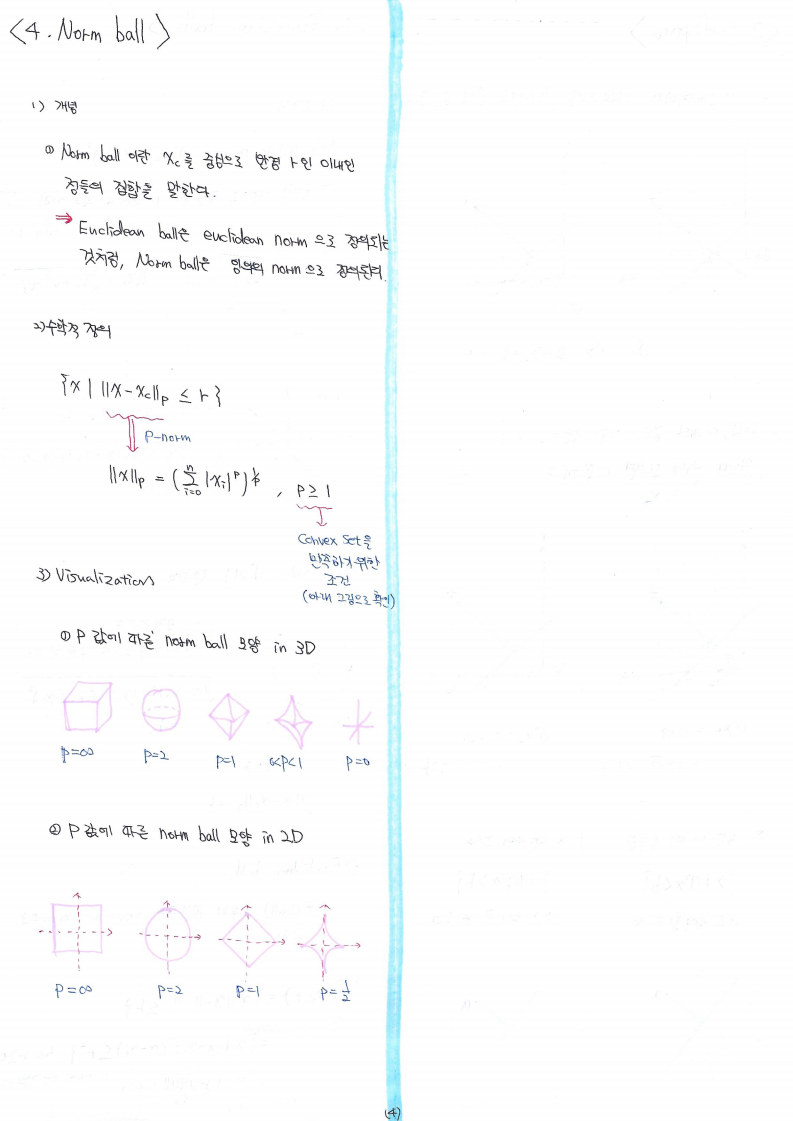
이번 글에서는 한 집단의 평균을 검정(test)하는 두 가지 가설검정 방식중 하나인 일(1)표본(=단일표본) Z검정에 대해 알아보도록 하겠습니다.
일(1)표본(=단일표본) Z검정 (One-sample Z test)
일(1)표본 T검정(=단일표본) (One-sample T test)
[가설검정의 종류]
'차이'와 관련된 검정
'평균'의 차이를 검정 하고 싶을 때
1-1. 비교하는 집단이 하나일 때
1-1-1. 모분산을 알고 있는 경우 & 표본이 클 때
일(1)표본 Z 검정 (One-sample Z test) → ex) 귀무가설(\(H_{0}\)): 한국의 평균은 K이다.
1-1-2. 모분산을 모르는 경우 & 표본이 작을 때
일(1) 표본 T 검정 (One-sample T test) → ex) 귀무가설(\(H_{0}\)): 한국의 평균은 K이다.
1-2. 비교하는 집단이 둘일 때
1-2-1. 모분산을 알고 있는 경우 & 표본이 클 때
이(2)표본 Z 검정 (Two-sample Z test) → ex) 귀무가설(\(H_{0}\)): 남, 녀간의 평균에 차이가 없다.
1-2-2. 모분산을 모르는 경우 & 표본이 작을 때
1-2-2-1. 독립표본 T 검정 (Independent Sample T test) → ex) 귀무가설(\(H_{0}\)): 남, 녀간의 평균에 차이가 없다.
1-2-2-2. 대응표본 T 검정 (Paired Sample T test) → ex) 귀무가설(\(H_{0}\)): 남, 녀간의 평균에 차이가 없다 & 해당 차이를 반복해서 검증 (한 달간 간격을 두고 측정: 1개윌 뒤, 2개윌 뒤, 3개윌 뒤, ....)
1-3. 비교하는 집단이 셋 이상일 때
1-3-1. ANOVA (분산분석)
1-3-1-1. 일원 분산분석 (One-way ANOVA) → ex) 귀무가설(\(H_{0}\)): 한국, 미국, 독일의 평균에 차이가 없다
1-3-1-2. 반복측정 분산분석 (Repeated Measures ANOVA) → ex) 귀무가설(\(H_{0}\)): 한국, 미국, 독일의 평균에 차이가 없다 & 해당 차이를 반복해서 검증 (한 달간 간격을 두고 측정: 1개윌 뒤, 2개윌 뒤, 3개윌 뒤, ....)
다만, 표준화된 표본평균분포 기준으로 유의수준 5%가 오른쪽에 모두 할당되거나, 왼쪽에 모두 할당되는 것이 양측검정과의 차이라고 볼 수 있습니다.
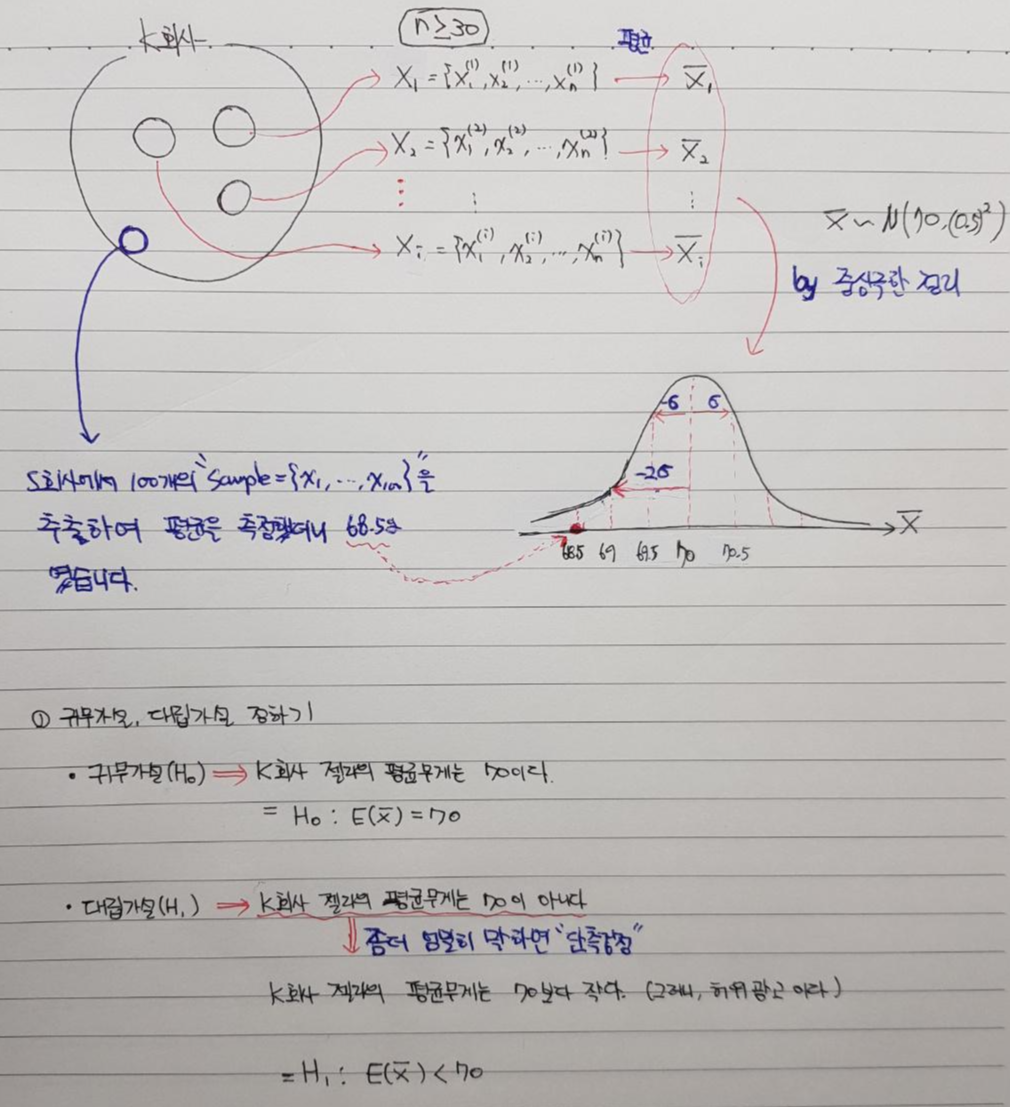
[예시] K제과 회사는 자신들이 생산하는 젤리의 표본을 무수히 많이 추출한 결과 (표본크기≥30이상, 표본개수=多), (중심극한정리에 의해) 무게는 평균60g 이고 5g정도의 표준편차를 갖는 정규분포를 형성한다고 발표했습니다. 하지만, K회사의 경쟁회사인 S회사는 K회사에서 제시한 평균이 잘 못 됐다고 생각하여 허위과장이 아닌지 의심하고 있습니다. S회사는 어떻게 K회사가 제시한 평균을 어떻게 검정할 수 있을까요?
※ 두 집단의 평균이 같은지 다른지 검정할 때는 양측검정 한쪽이 다른쪽보다 큰지 아닌지 검정할 때는 단측검정
[생각해보기]
딥러닝을 이용한 행동인지 프로그램을 개발했다. 해당 프로그램은 치매환자의 행동패턴을 분석하고, 특정패턴이 발견되면 치매환자라고 분류한다. 이러한 특정패턴은 특정 수치값 이상이면 치매와 관련된 패턴이라고 인식되는데, 실제 치매환자들 기준으로 측정한 결과 치매환자로 분류하는 특정 수치 값은 평균50, 분산1 인 정규분포 범위를 갖는다고 한다. 이때, 다른 연구자들이 이 수치 값이 맞는지 100개의 sample을 추출해 Z검정을 실시하고, 해당 프로그램이 통계적으로 참인지 아닌지 구분할 수 있다.