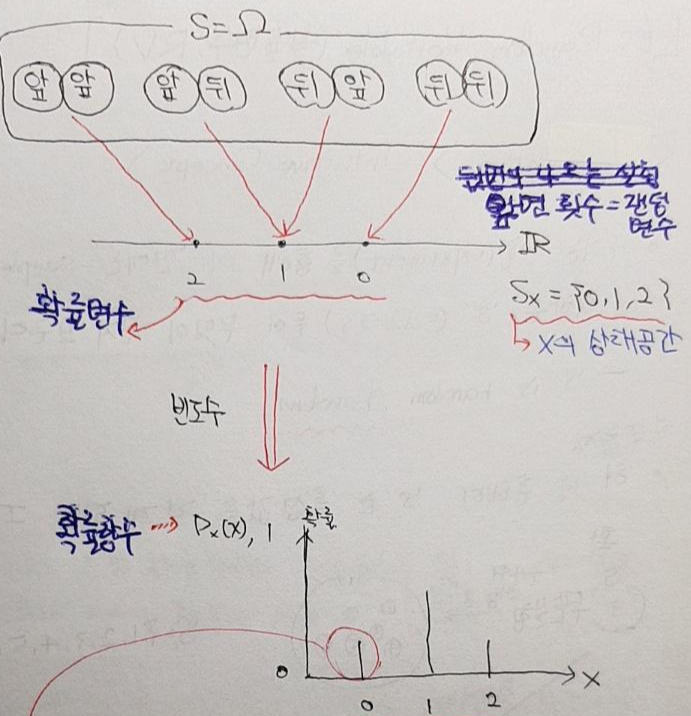
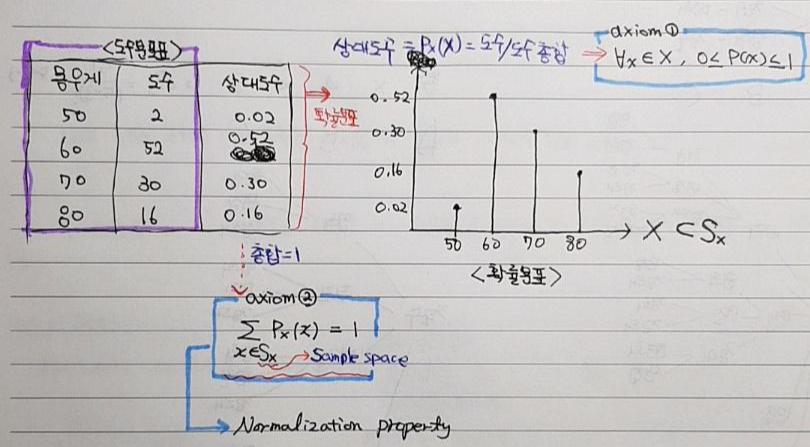
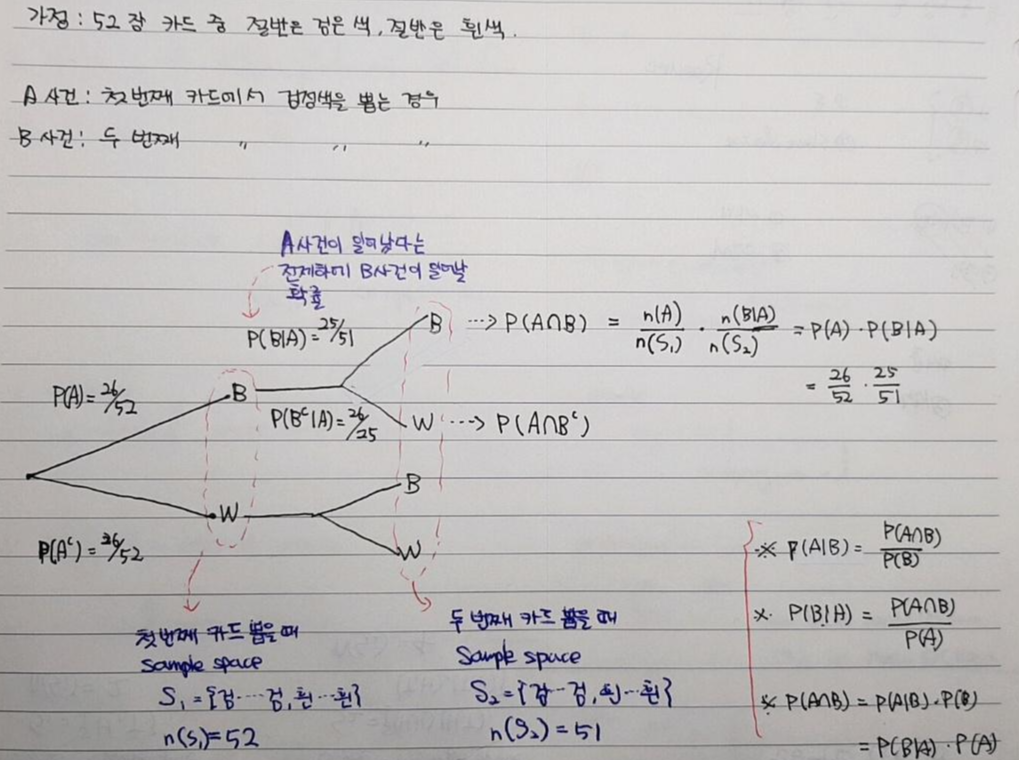
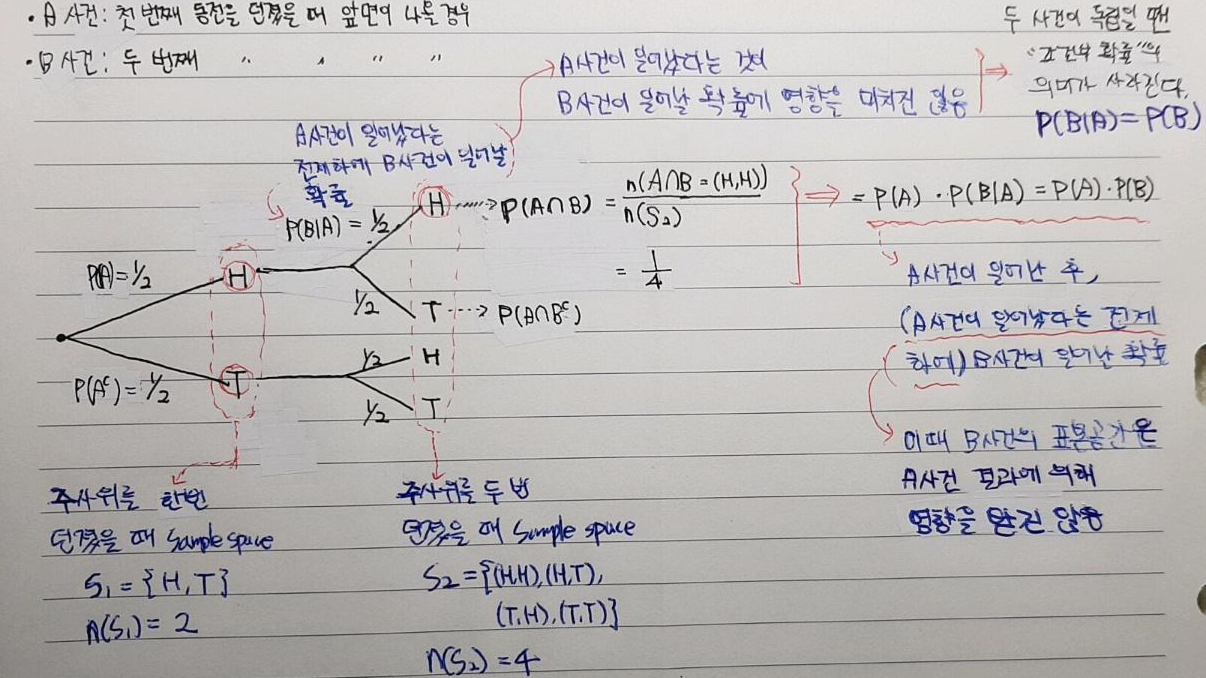
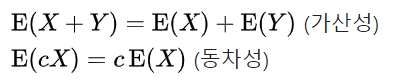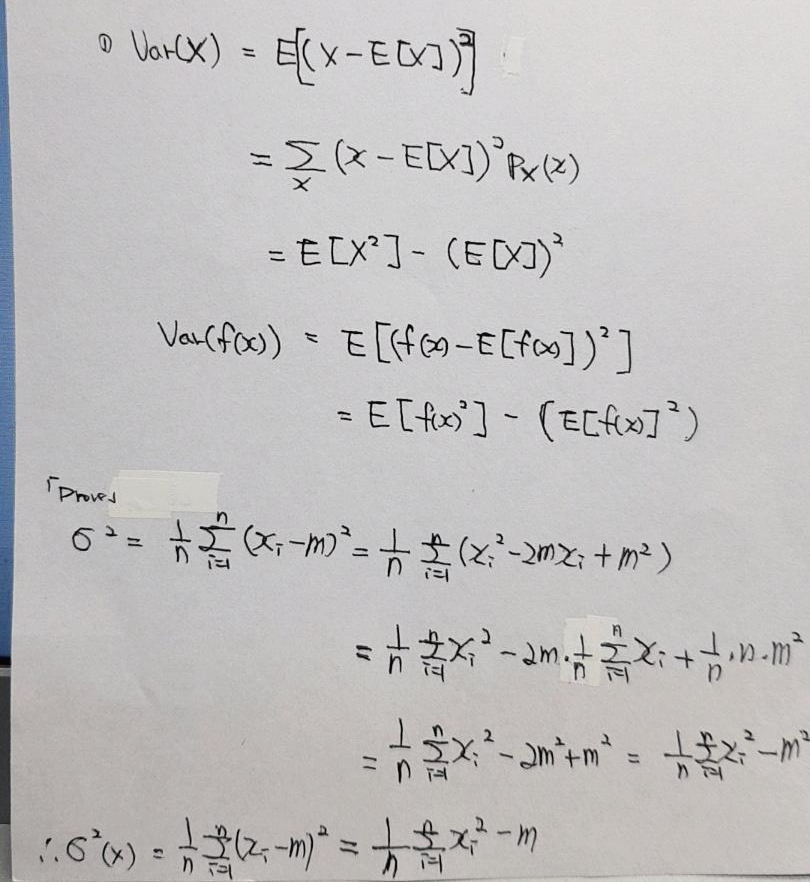[이번 장에서의 목표]
- 이번장에서는 이산확률변수를 기반으로 한 다양한 확률분포들에 대해서 알아보도록 하겠습니다.
- 앞서 확률분포와 평균, 분산을 구하는 방법에 대해서 알아보았으니, 이번장에서는 각각의 확률분포가 어느 경우에 사용되는 건지, 해당 확률분포의 평균과 분산은 어떻게 되는건지 알아보도록 하겠습니다.
1. Cumulative Distribution (누적확률분포)
- 누적확률분포는 말 그대로 특정 확률변수까지 누적된 확률 값을 알아내기 위해 사용됩니다.
- 예를들어, 확률변수 3이전의 경우(1,2,3)가 나올 확률에 대해서 알아보는 것과 같습니다.
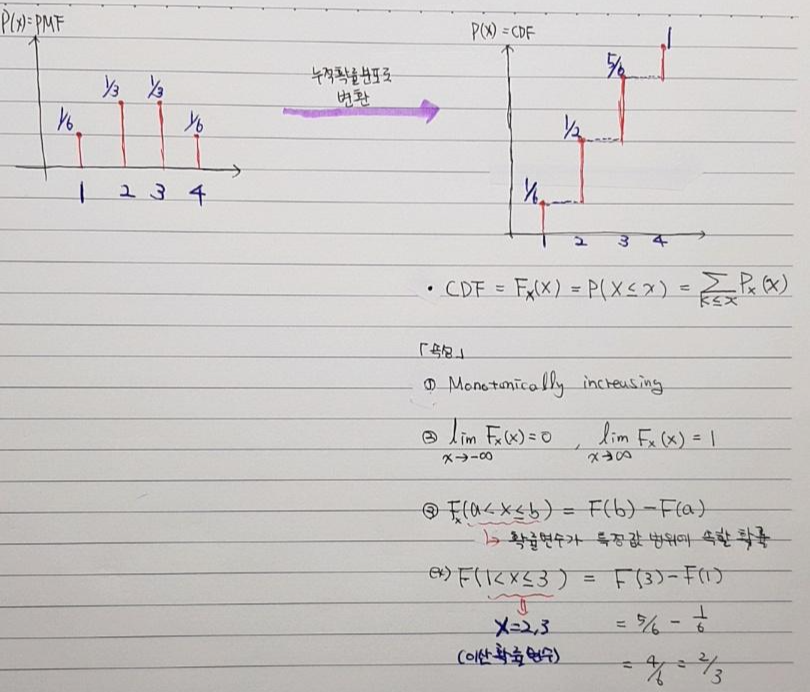
- 모든 확률분포는 PMF 또는 CDF로 표현 가능합니다.

2. Bernoulli Distribution (베르누이 확률분포)
2-1. 베르누이 확률함수
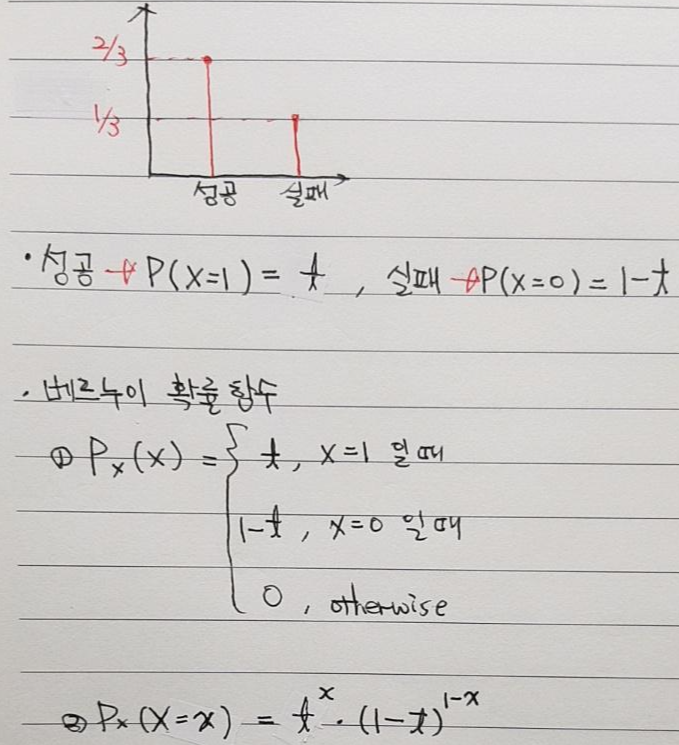
- 베르누이 분포는 성공과 실패 또는 이분법적인 상황에 대한 확률 값을 나타내고자 하는 확률분포입니다.
- 즉, 베르누이 분포에서 확률 변수는 2가지 만 존재하고, 이 두 가지의 확률값은 p, 1-p 입니다.
2-2. 베르누이 확률분포의 평균식 증명

2-2. 베르누이 확률분포의 분산식 증명

3. Binomial Distribution (이항확률분포)
3-1. 이항확률 함수
- 이항확률함수는 n번 실행했을 때 x번 성공할 경우에 대한 확률 값을 도출합니다. 이 때, x번 성공하는 횟수가 이항확률함수의 (Binomial) random variable이 됩니다. 예를 들어, 100번 동전을 던졌을 때 앞면이 50번 나올 확률을 구할 때 사용되는 함수입니다.
- Binomial random variable is Independent Identically Distribution (I.I.D) Bernoulli. (독립시행 링크)
- 시행(trial)이 연속적일 때, 이전 시행의 결과가 다음 시행에서 일어날 확률에 아무런 영향을 미치지 않습니다. (Independent)
- 시행할 때마다 항상 성공과 확률이 같은 bernoulli distribution을 따릅니다 (Identically Distribution)
- Binomial distribution은 독립시행 확률을 따르는 I.I.D라고 할 수 있습니다.
- 종합하자면, Bernoulli random variable을 따르는 bernoulli experment를 n번 실행하여 성공횟수를 binomial random variable로 삼는 확률분포를 binomial distribution이라 합니다.
- 이항분포는 아래와 같은 확률함수를 갖는다. (해당 확률함수의 증명은 아래 예시를 보면 직관적으로 파악할 수 있습니다)

(조합 관련 개념 또는 아래의 예시에 대한 자세항 설명은 다음 링크에서 독립시행 확률 part을 참조해주세요)

2-2. 베르누이 확률분포의 평균식 증명

2-3. 베르누이 확률분포의 분산식 증명

4. Geometric Distribution (기하분포, 연속확률변수에서는 지수분포가 됨)
4-1. 기하분포 확률함수
- Geometric distribution의 random variable은 성공할 때 까지 시행한 횟수를 의미합니다.

(↓↓↓위에 무한 등비급수합 수식증명↓↓↓)
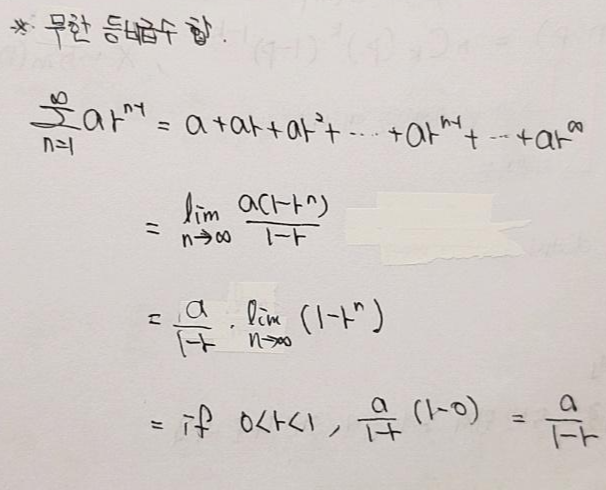
4-2. 기하분포 확률분포의 평균식 증명

- 왜 해당 시그마 공식이 1/p^2 를 도출하는지 증명하겠습니다.
- 먼저 등비수열 공식에 따라 아래와 같이 정의할 수 있습니다.
- 해당 등비수열 공식을 양쪽으로 미분해보겠습니다.

- 이로써 평균 수식의 증명이 완료되었습니다.
4-3. 기하분포 확률분포의 분산식 증명
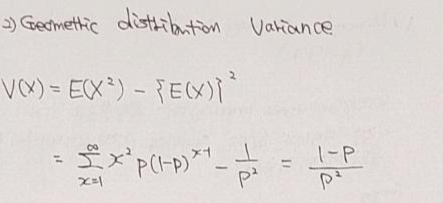
- 기하확률분포의 분산식 증명은 아래와 같습니다.

4-3. Memoryless property in Geometric distribution (무기억성 성질)

- 위의 식에 대한 이해을 위해 몇 가지 예시를 들어보겠습니다.
- [첫 번째 예시]
- P(X>t)라는 뜻은 t번 시도한 후에 3점 슛을 성공할 확률을 의미합니다.
- 농구를 좋아하는 학생이 3점 슛을 성공하기 위해 s번의 실패(시도)를 했다고 합시다. 그리고 t번의 실패(시도)를 더 한 끝에 슛을 성공했습니다. 그리고 s+t번 이후에는 계속해서 슛을 성공시킵니다. 이를 조건부 확률로 표현하자면 P(X≥s+t | X≥s) 입니다.
- 사실 위에서 설명한 개념들을 P(X≥s+t)만으로도 설명 가능한거라고 볼 수 도 있는데, 조건부 개념을 도입한건 무기억성이라는 특성을 설명하기 위해서 인듯합니다 (즉, 위의 수식을 만족하기 위해 도입한 개념). 그럼, 계속해서 알아보도록 하겠습니다.
- P(X≥s+t | X≥s) = P(X≥t) 수식을 보면 s번의 시도를 한 후에 t번 더 시도해서 성공할 확률과, t번 시도해서 성공할 확률과 같다는 뜻이됩니다.
- 즉, s+t번의 시도를 한 것 과, t번의 시도를 한 것을 동일하게 보는 것인데, 예를 들어,s=5, t=2라고 했을 때 단순히 5+2(=s+t)번의 시도와 2(=t)번의 시도가 같다고 보는게 아니라, 5번의 시도를 어떻게 바라볼 것인가가 포인트가 될 수 있다고 생각합니다. 어떻게 보면 s번 시도 한것은 농구를 좋아하는 학생이 집중을 못했기 때문에 아무 의미가 없었다는 결론을 내릴 수도 있을 것 같습니다.
- 결과적으로, s번의 실패(시도)가 아무 의미 없어진 것과 같습니다. 즉, s번의 실패(시도)에 대한 기억을 잃어버리게 되는 것이죠.
- [두 번째 예시 - 링크] (해당 예시는 좌측 링크 사이트에서 인용했습니다)
- 어떤 기계가 처음 만들어져서 사용되기 시작한 뒤 t시간 이내에 고장날 확률과, 그 기계가 s시간 까지 계속 사용되다가 t시간 이내에 고장날 확률이 동일하다는 말과 같습니다.
- 기계가 이전 s시간 동안 사용되었다는 것을 기억하지 못하는 것과 같습니다 (무기억).
- 위의 예시를 통해 봤듯이, 무기억성이란 특정분포가 과거의 이력을 잊어버리는 성질을 의미합니다. 이력을 잃어 버리더라도 특정 분포를 여전히 따릅니다.
- 그렇다면 무기억성의 수식을 증명해보도록 하겠습니다.


4-4. 기하분포 어원
- 기하확률분포의 확률함수는 등비수열이라고 할 수 있는데, 왜 등비수열에 geometric이라는 표현을 사용했을까요?

5 Negative Binomial Distribution (음이항분포 or Pascal distribution)
5-1. 음이항분포 확률함수
- r번의 성공횟수를 기록할 때 까지 x번 실패 할 횟수를 random variable로 갖는 확률분포입니다. 즉, r번 성공할 때 까지 x번 실패 하는 경우에 대한 확률값을 알고자 할 때 사용하는 확률함수가 음이항분포 확률함수입니다.
- 여기서 중요한 부분은 r은 고정 값이고, x는 random variable이기 때문에 변할 수 있는 변수이고, n=x+r이기 때문에 x에 따라 n(시행) 값이 변합니다.
- 먼저 예를 통해 설명해보도록 하겠습니다.
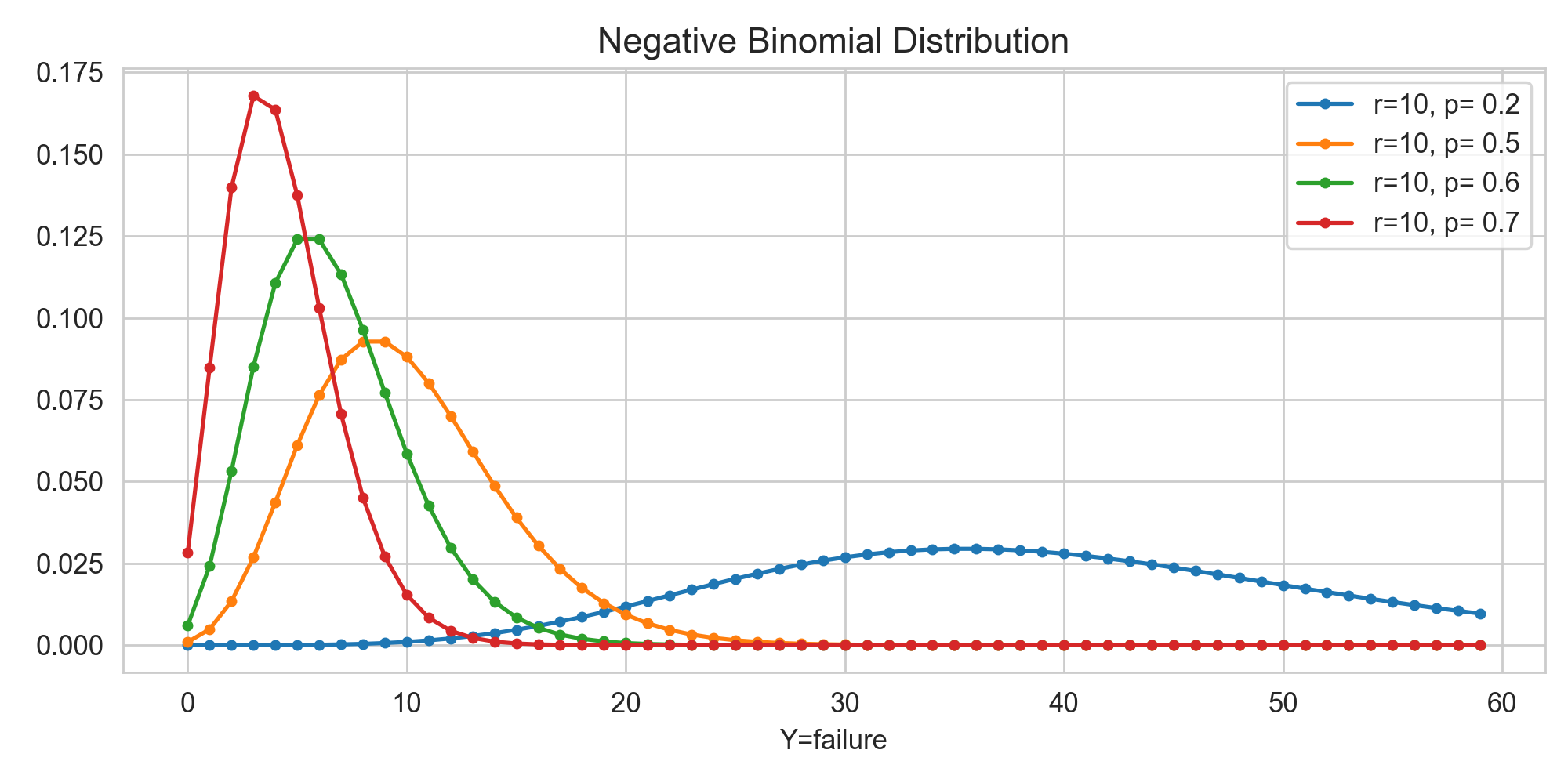
- 아래 예를 보면, 3번 성공하는 동안 실패하는 횟수에 따라 확률값을 알고자 합니다. 먼저, 3번 성공할 때까지 1번 실패할 확률을 구하는 과정은 아래와 같습니다. (음이항확률함수=P(X))먼저, 음이항분포를 표현하기 위해서는 성공횟수(r)가 고정되어 있어야 합니다. 실패횟수(x)가 random variable이기 때문에 시행횟수 (n=r+x)도 실패횟수에 따라 변경됩니다.

- 예를 들어, 아래 표에서 성공횟수는 10으로 고정되어 있고, 시행횟수는 보이지 않지만 implicit (암묵적)으로 실패횟수에 따라 변한다고 보시면 됩니다. 만약 아래 실패횟수(random variable)가 60이 최대치라면, 전체 시행횟수(n=x+r)는 70이 됩니다.)

5-2. 음이항분포의 평균식 증명
- 평균수식을 알아보기 전에 음이항분포에서의 모든 확률 값의 총합이 1임을 확인해보겠습니다.

- 지금부터 평균 식을 증명해보겠습니다.

5-3. 음이항분포의 분산식 증명


5-4. 음이항분포와 기하분포의 관계
- 음이항분포를 자세히 보면 r=1일 때 기하분포와 동일하다는 것을 확인할 수 있습니다. 즉, 성공횟수가 1이 나올 때 까지 시행한 횟수를 확률 변수를 삼는다는 것은 성공할 때까지 시행한 횟수를 확률변수로 삼는다는 것과 같습니다. 즉, 기하분포의 정의인 "성공할 때까지 시행한 횟수를 random variable로 삼는다"와 동일한 경우라고 볼 수 있습니다. 그러므로, 기하분포는 음이항분포의 특이한 케이스라고 보시면 될 것 같습니다.
- 식으로 증명하면 아래와 같습니다.
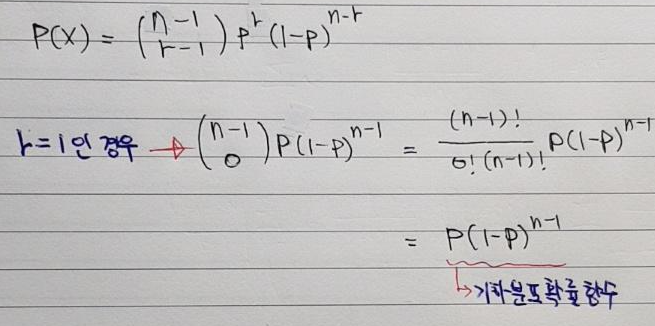
6. Hypergeometric Distribution (초기하 확률분포)
6-1. 초기하분포 확률함수
- 초기하분포 역시 이항분포와 마찬가지로 '성공', '실패' 2가지 상황만 나오는 실험에서 사용됩니다.
- 하지만, 이항분포와 복원추출인 반면에 초기하분포는 비복원추출을 전제로 합니다.
- 결국, 현재 진행하는 실험의 sample space(표본공간)가 이전 실험의 sample space보다 작기 때문에 이전실험이 현재실험의 확률값에 영향을 미치게 됩니다. 그러므로, 초기하분포는 다음과 같은 의미를 내포합니다 → "Non-independent Bernoulli trials"
- 아래 수식은 초기하분포 확률함수 수식입니다. 이에 대해서 설명해보도록 하겠습니다.
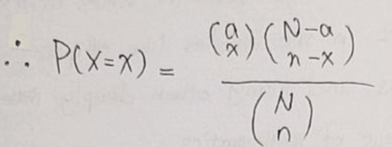
- 초기하분포의 수식은 모집단과 표본에 대한 개념을 베이스로 두고 있습니다. 두 측면에서 초기하분포를 설명해보도록 하겠습니다.
- [첫 번째 설명]
- 모집단의 크기를 N이라고 하고, 모집단 안에는 우리가 원하는 원소가 a개 있다고 하겠습니다.
- 모집단에서 크기가 n인 표본을 뽑습니다.
- 해당 표본안에서 우리가 원하는 원소가 x개 있을 확률분포를 초기하확률분포라고 합니다.
- 즉, 표본안에서 우리가 원하는 원소가 뽑히는 갯수 (x)가 random variable이 됩니다.
- [두 번째 설명]→ 두 번째 설명은 우측 사이트를 참고했습니다 링크
- N개의 구성원의 모집단이 있습니다.
- 이 모집단이 두 그룹으로 나누어진다고 가정하겠습니다.
- 첫 번째 그룹에는 a개의 구성원이 있다고 하면, 두 번째 그룹에는 N-a개의 구성원이 존재합니다.
- 이때 초기하 확률변수 x는 전체 모집단에서 n개의 샘플을 비복원으로 뽑을 때, n개 샘플 중에서 첫 번째 그룹(=a)에 해당하는 샘플 수를 의미합니다.
- [예시]
- 하나의 상자에 6개의 빨간색 공과, 14개의 노란색공이 있습니다.
- 비복원으로 5개의 공을 추출합니다.
- 이때 5개의 공 중 4개의 공이 빨간색일 확률은 얼마입니까?
- [첫 번째 설명]

6-2. 음이항분포의 평균식 증명

6-3. 음이항분포의 분산식 증명


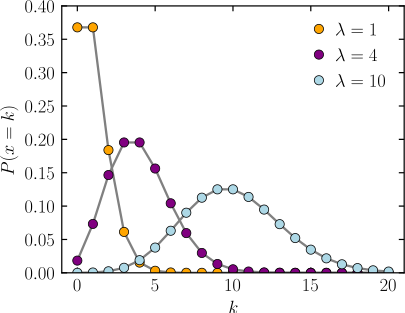
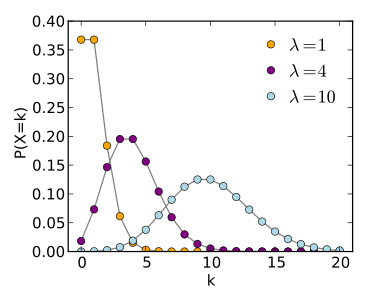
7. Poisson Distribution
- 포아송 분포는 '단위시간(or공간)안에 어떤 사건이 몇 번 발생할 것인지를 표현하는 이산 확률 분포입니다.
- 한 달 동안 발생하는 교통사고의 횟수
- 책 한 페이지 당 오타의 횟수 → 예시 인용 사이트 링크
- 어느 전공 책 5페이지를 검사했는데, 10개의 오타가 발생했다. 이 책에서 어느 한 페이지를 검사했을 때, 오타가 3개 나올 확률은?
- 포아송 분포에서의 발생하는 사건의 횟수가 random variable이 되고, 발생하는 평균 횟수가 고정값(=\(\lambda\))이 됩니다. 발생하는 평균횟수는 "전체 시행횟수×사건이 발생할 확률"입니다. (위의 예시를 기준으로 값을 설정해보겠습니다)
- 사건이 발생하는 횟수=k→ 3
- 전체 시행횟수=n→ 5
- 사건이 발생할 확률=p=\lambda/n → (10/5)/5
- 특정 시행횟수에서 사건이 발생할 수 있는 평균 횟수= \(\lambda\)=n×p
- 위의 전공 책 관련 예시를 보면, 3건의 사건이 발생할 횟수 (오타가 나올 횟수=3) 가 random variable이 되고, 이러한 경우 (random variable=3)의 확률을 알아보기 위해, 한 페이지 당 오타가 발생할 평균 횟수 \(\lambda\)=10/5 을 알고 있어야 합니다. (여기에서는 성공할 확률을 딱히 몰라도 \(\lambda\)=2 이라는 건 알 수 있습니다.
- 우리는 "어느 전공 책 5페이지를 검사했는데, 10개의 오타가 발생했다."에 대한 정보를 기반으로, "어느 한 페이지를 검사했을 때, 오타가 3개 나올 확률은?"에 대한 답을 해야합니다.
- 어느 한 페이지라는 것은 단위공간이라고 볼 수 있고, 이것을 전체 시행 횟수(=n)로 볼 수 있습니다.
- 결국 이는 한 페이지에 n이라는 글자가 있다면, 거기서 k개의 오타가 나올 확률을 의미하고, 이를 다른 측면에서보면 n번 동전을 던졌을 때 k번 앞면이 나올 확률과 동일한 문제가 됩니다. 즉, 이항확률분포(Binomial distribution)의 확률 함수와 동일 한 것이죠.
- 포아송 분포에서 중요한 전제조건은 n이 굉장히 크다는 상황을 가정하고 있다는 것입니다. 즉, 이항확률분포에서 n이 엄청크다면 포아송 분포로 근사할 수 있다는 의미입니다. 이러한 방식을 사용했던 이유는, 과거에 계산기가 없었을 때 n이 엄청 크다면 이항확률분포를 계산하는게 엄청 힘들었기 때문에 n이 무한대라는 극한의 개념을 도입해 포아송 확률함수를 만들었다고 합니다. 즉, 이항확률분포에서 n이 굉장히 큰 경우 포아송 분포식으로 계산할 수 있게 되는 것이죠 (근래에는 컴퓨터의 발달로 이항확률분포 n이 충분히 커도 쉽게 계산 가능하다고 하지만, n>50, or \(\lambda\)=np<5 이면 컴퓨터에서 비트의 제한으로 수치에러가 날 경우가 있다고 합니다.)
- 그럼 지금부터 n이 무한대일 때 이항분포 확률함수가 어떠한 확률 함수를 갖는지 살펴보도록 하겠습니다.


①식 풀이
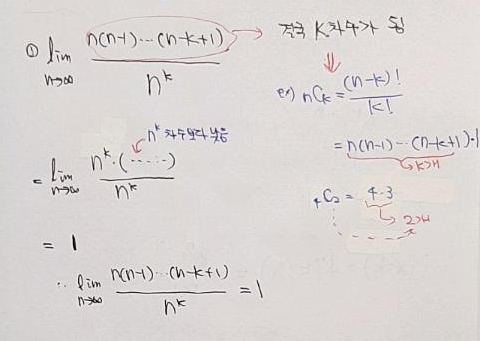
②번식 풀이 (해당 식을 풀이하기 위해서는 자연상수에 대한 개념을 이해할 필요가 있어서 자연상수 내용을 다루었습니다. (하...정말 글씨가....))

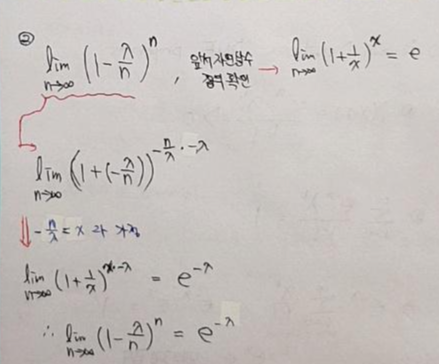
③번식 풀이

최종풀이

- 결국 위와 같은 식을 통해, 특정 시행횟수에 사건이 발생할 수 있는 평균 횟수 "\(\lambda\)"의 정보만을 갖고 random variable(=k)에 속한 확률 값을 알아낼 수 있고, 이를 위해 포아송 확률 함수라 합니다 (포아송 확률 함수를 적용하려고 할 때에는 n이 엄청 커야 한다는 전제를 항상 염두해두시면 좋을 것 같습니다).
- 람다가 고정값이기 때문에 시행횟수와 사건이 발생할 확률이 암묵적(implicit)으로 고정값으로 정해져 있습니다.
- 포아송 확률함수의 총합이 1임을 증명해보겠습니다.

7-1. 포아송분포의 평균식 증명

7-2. 포아송분포의 분산식 증명
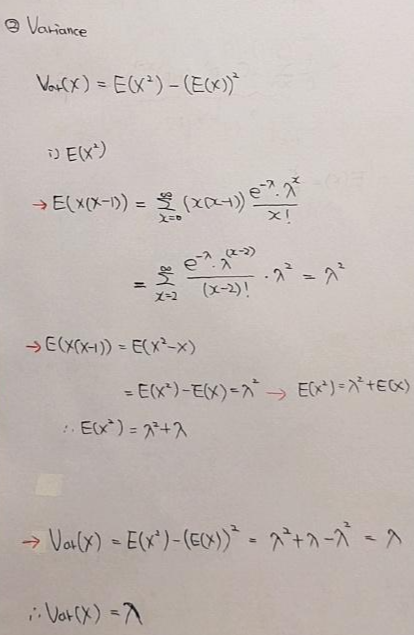
지금까지 이산확률분포의 여러 종류들과, 해당 확률분포의 평균 및 분산식에 대해서 알아보았습니다. 다음 글에서는 연속확률변수 및 연속확률분포에 대한 기본적인 개념들에 대해서 알아보도록 하겠습니다.