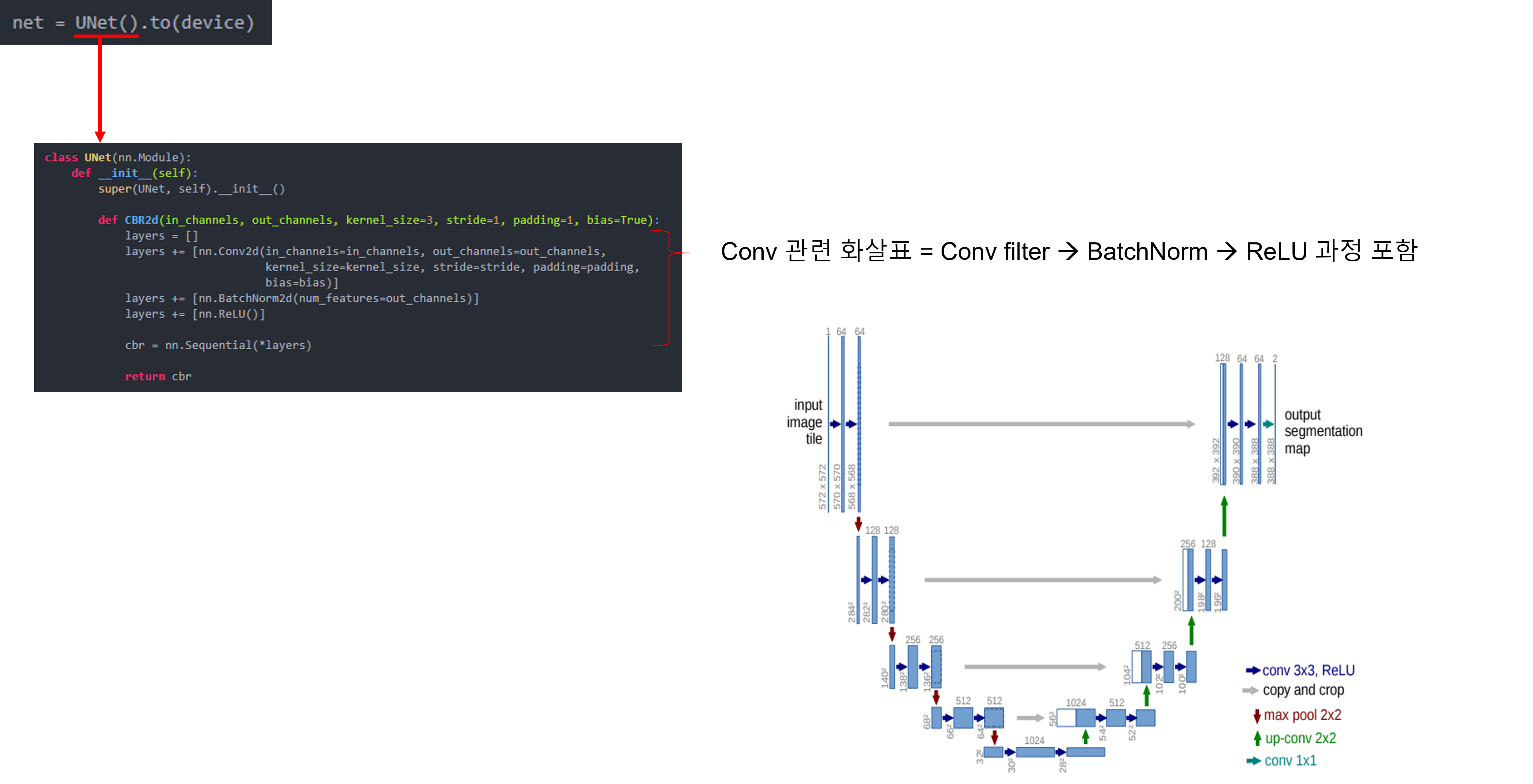
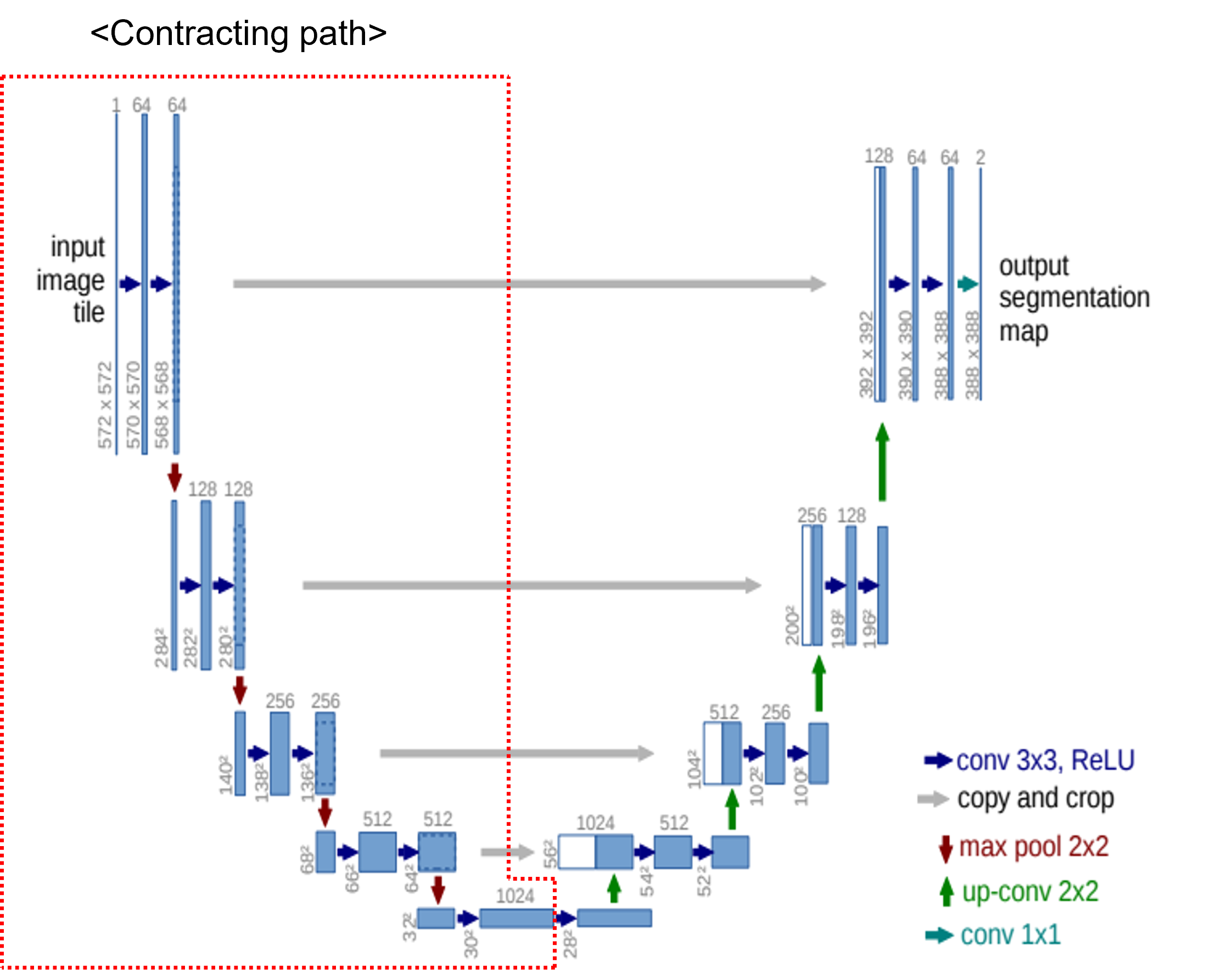
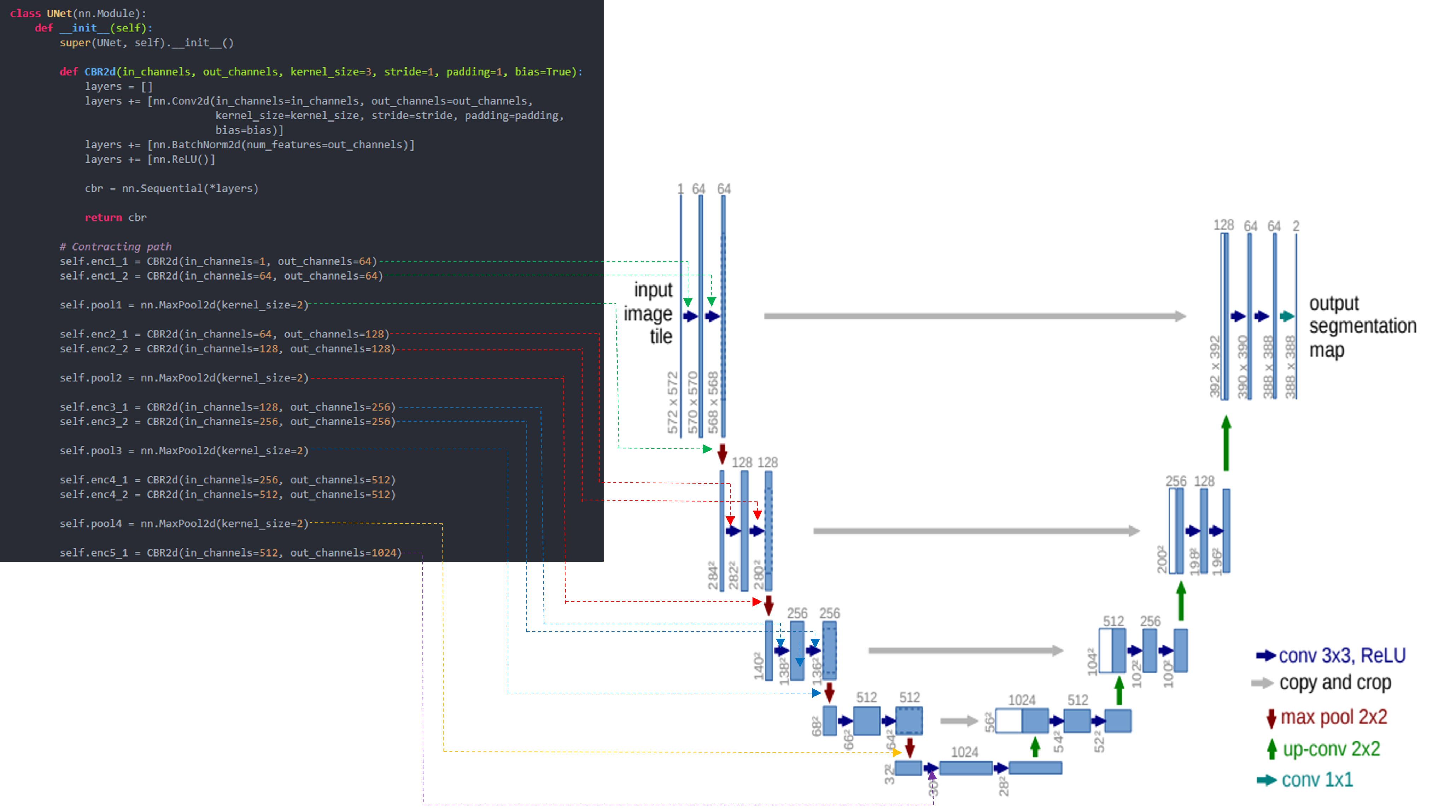
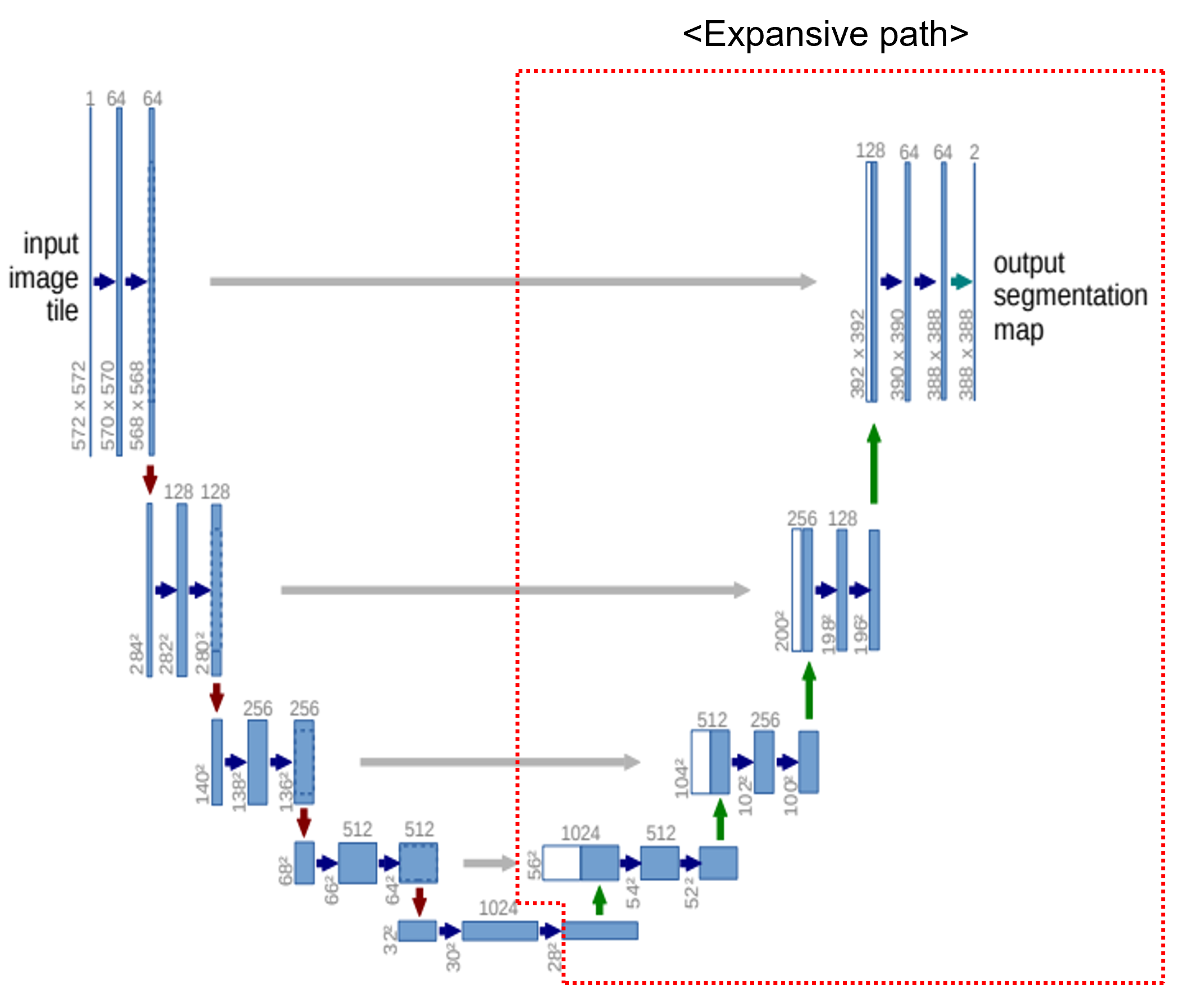
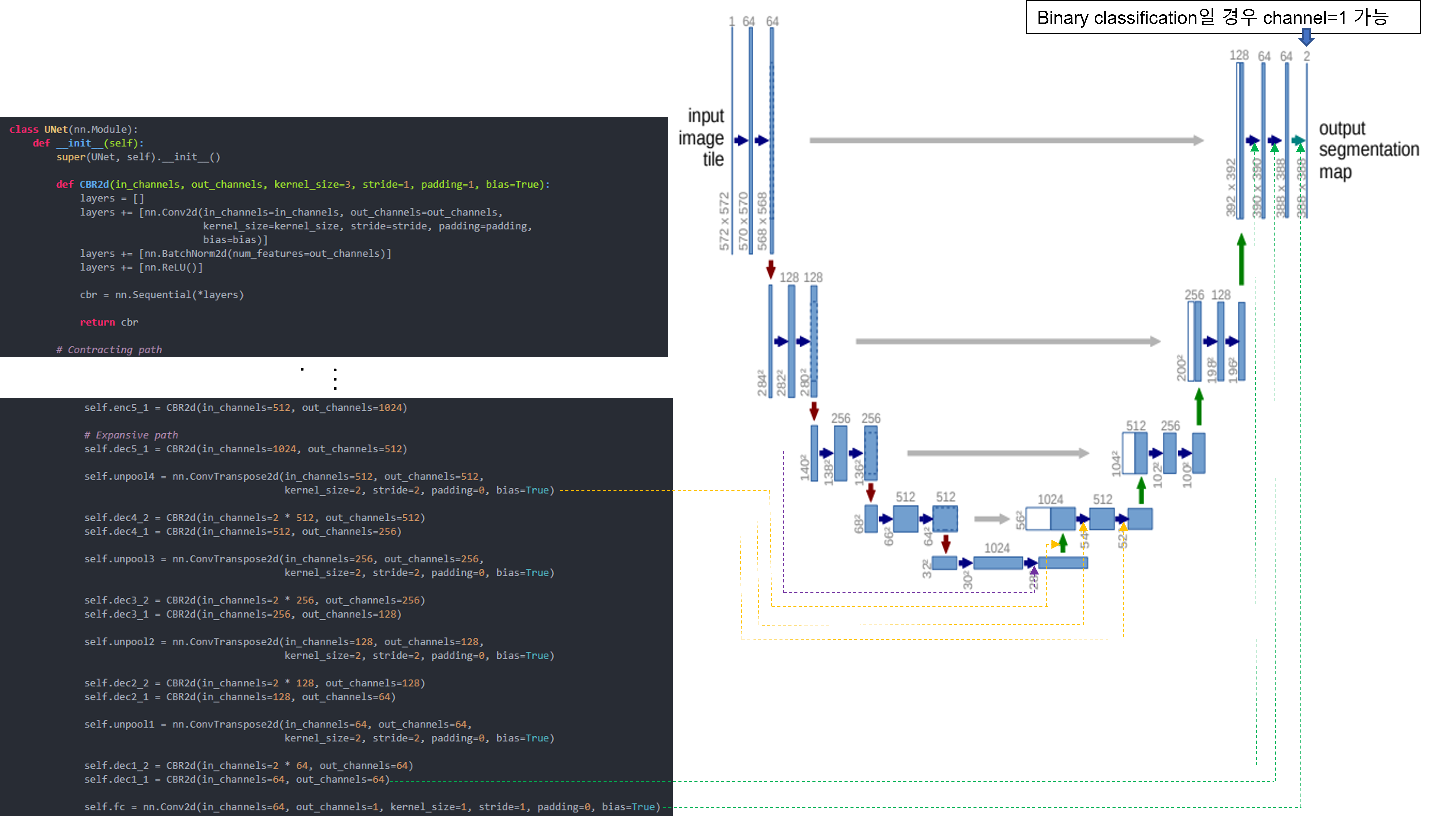
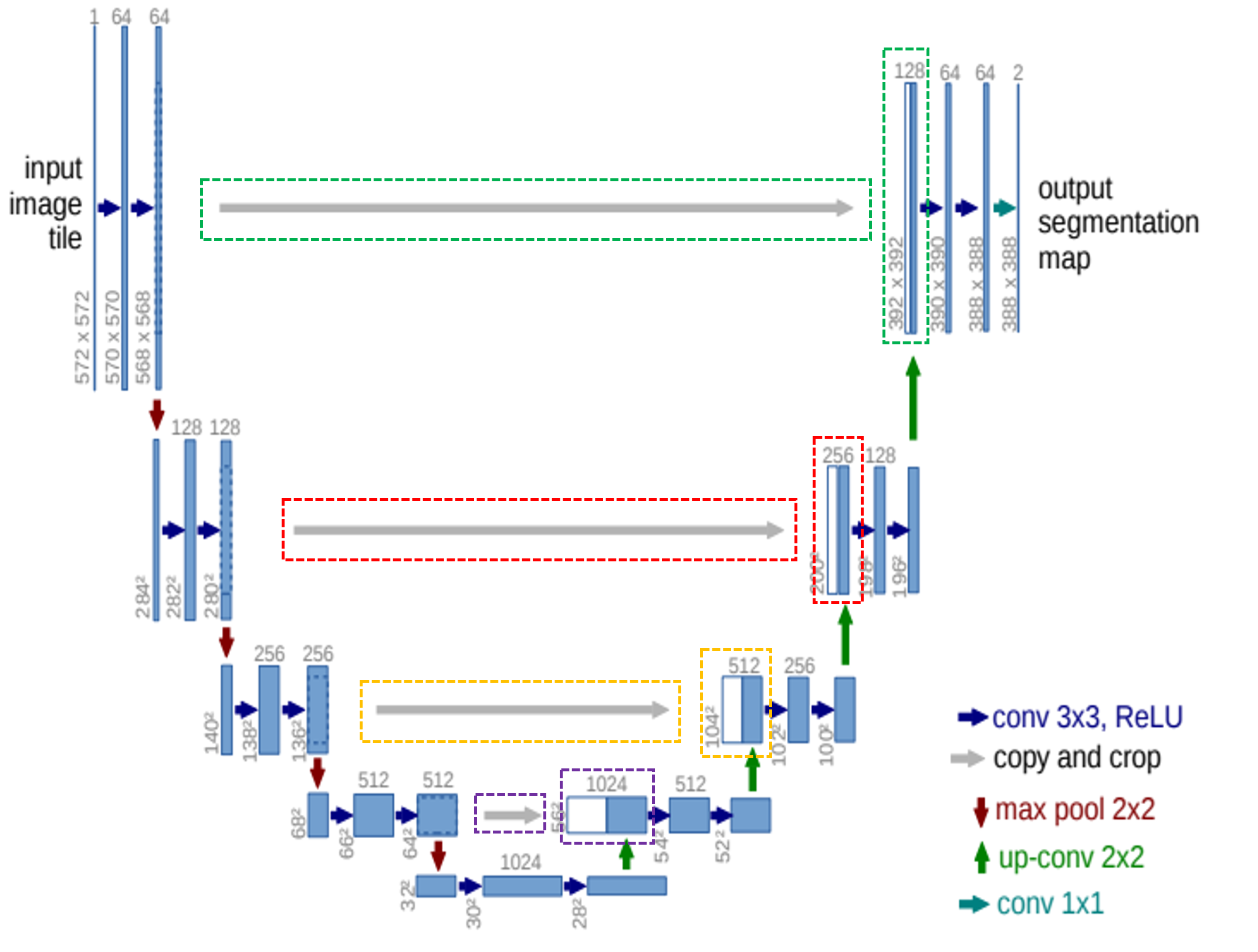
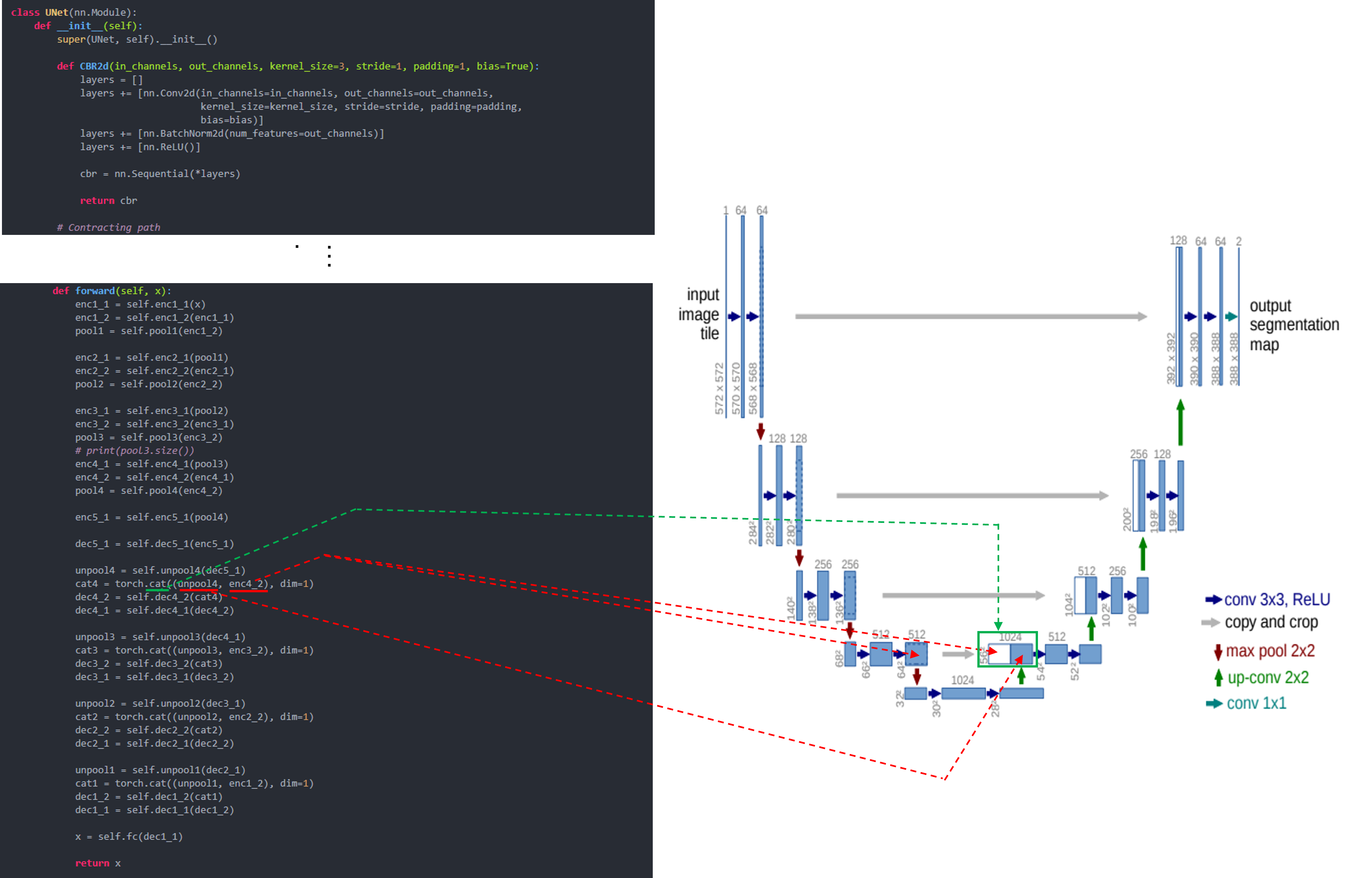
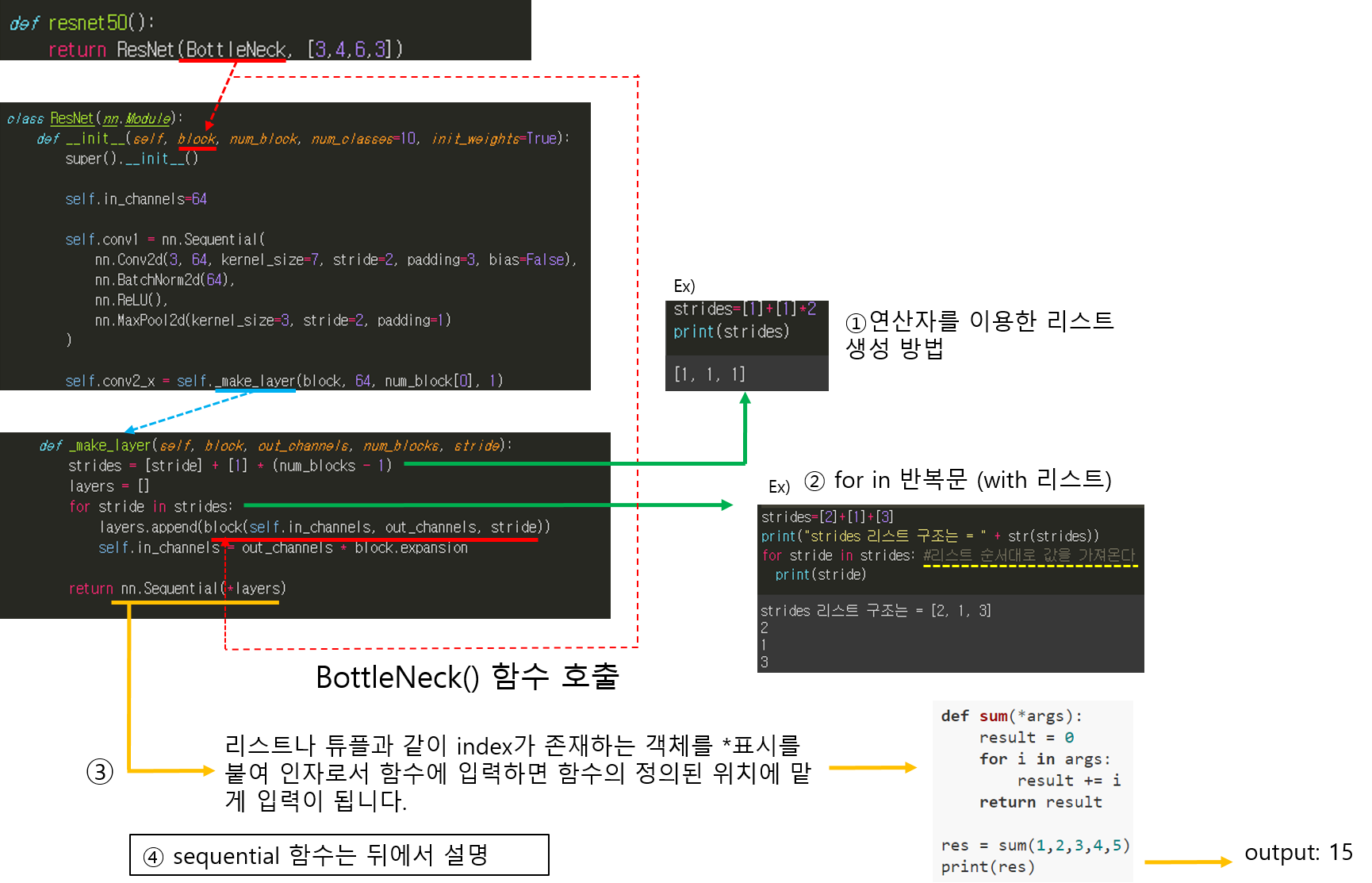
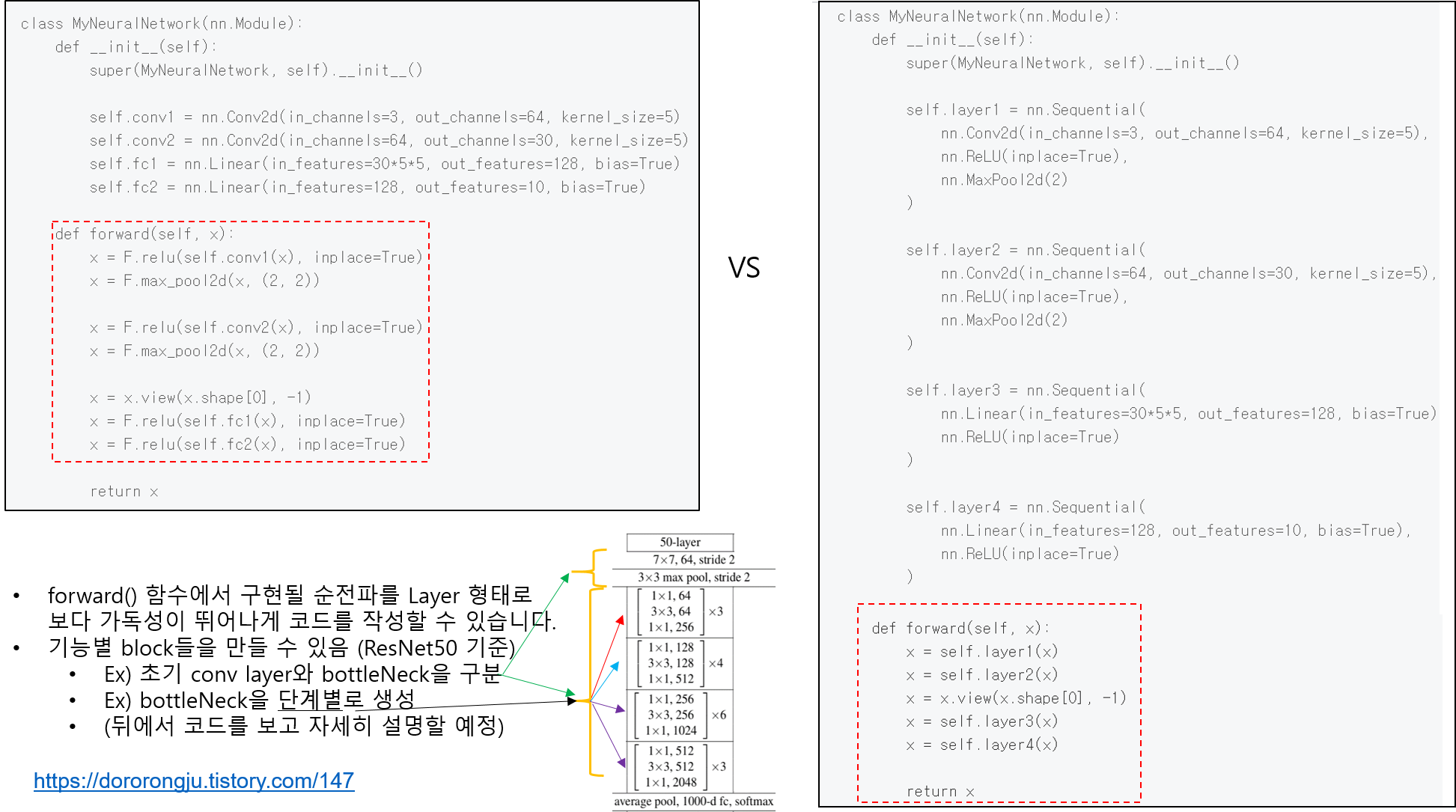
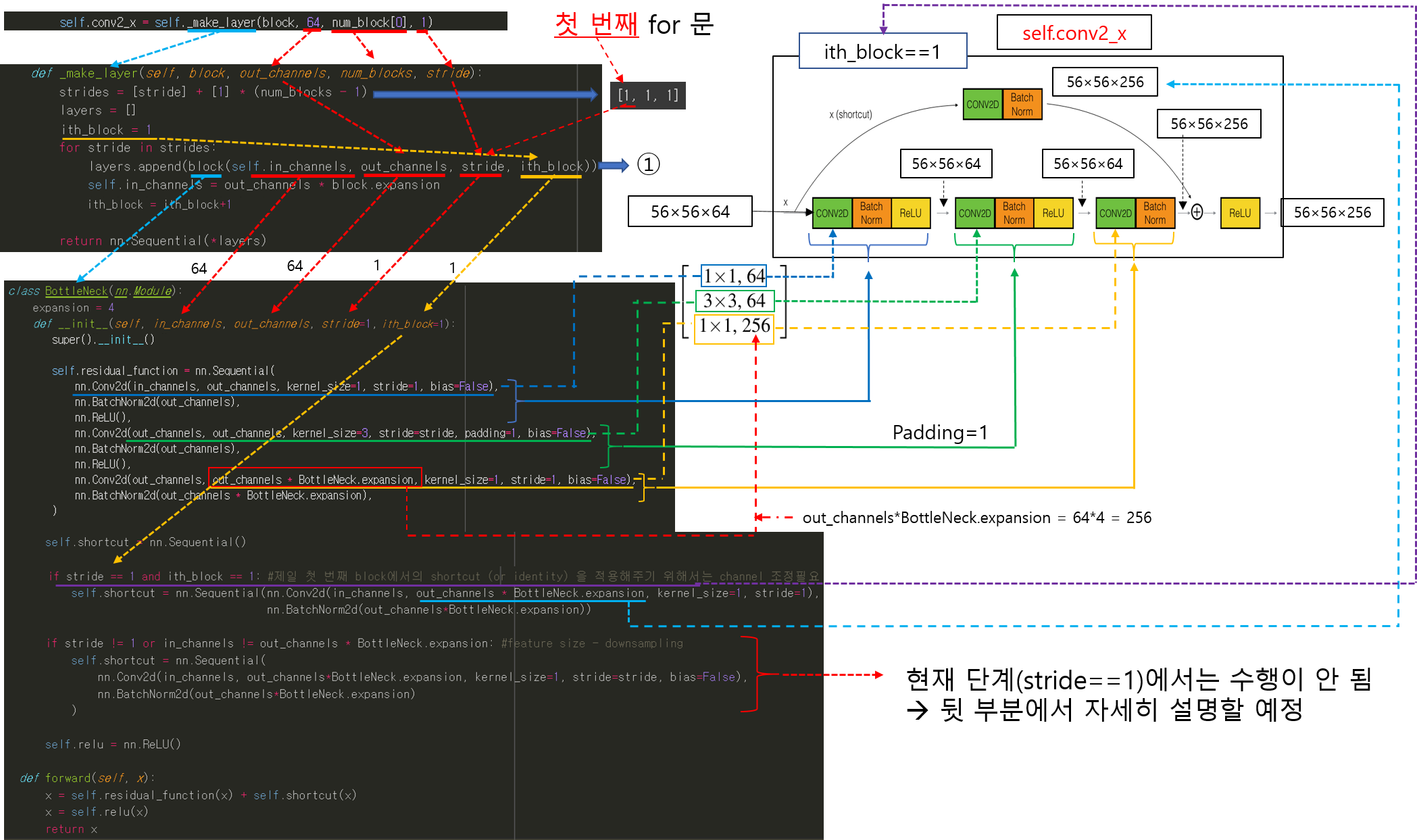
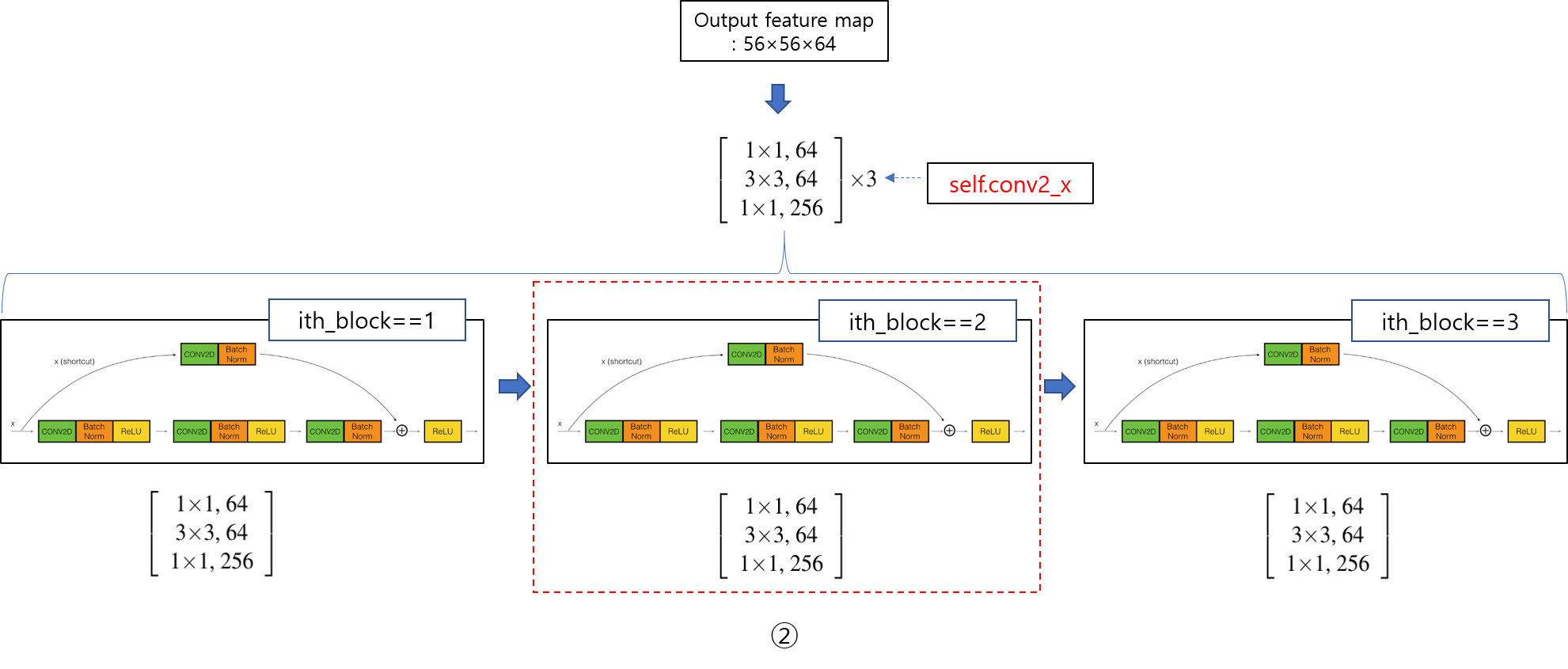
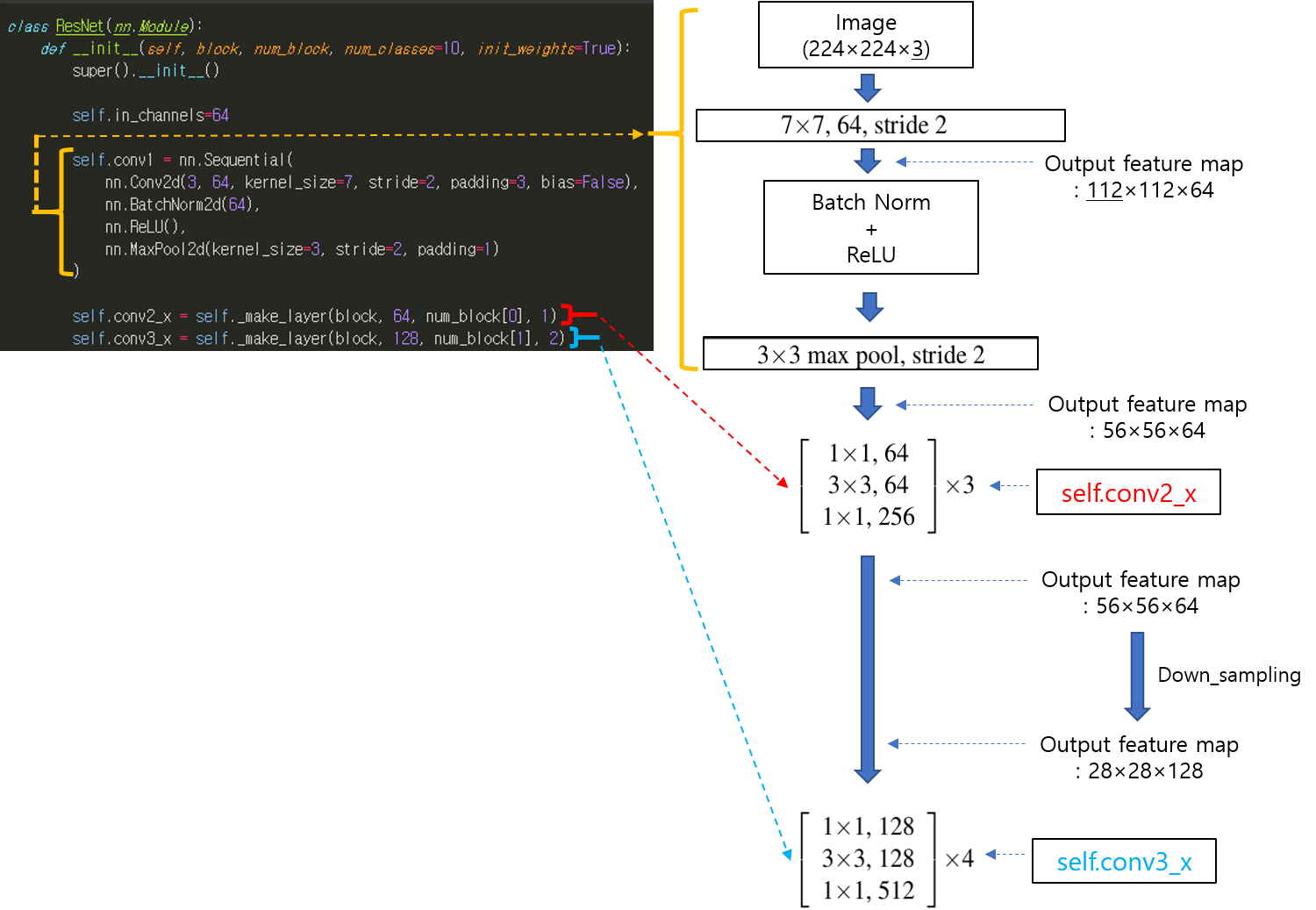
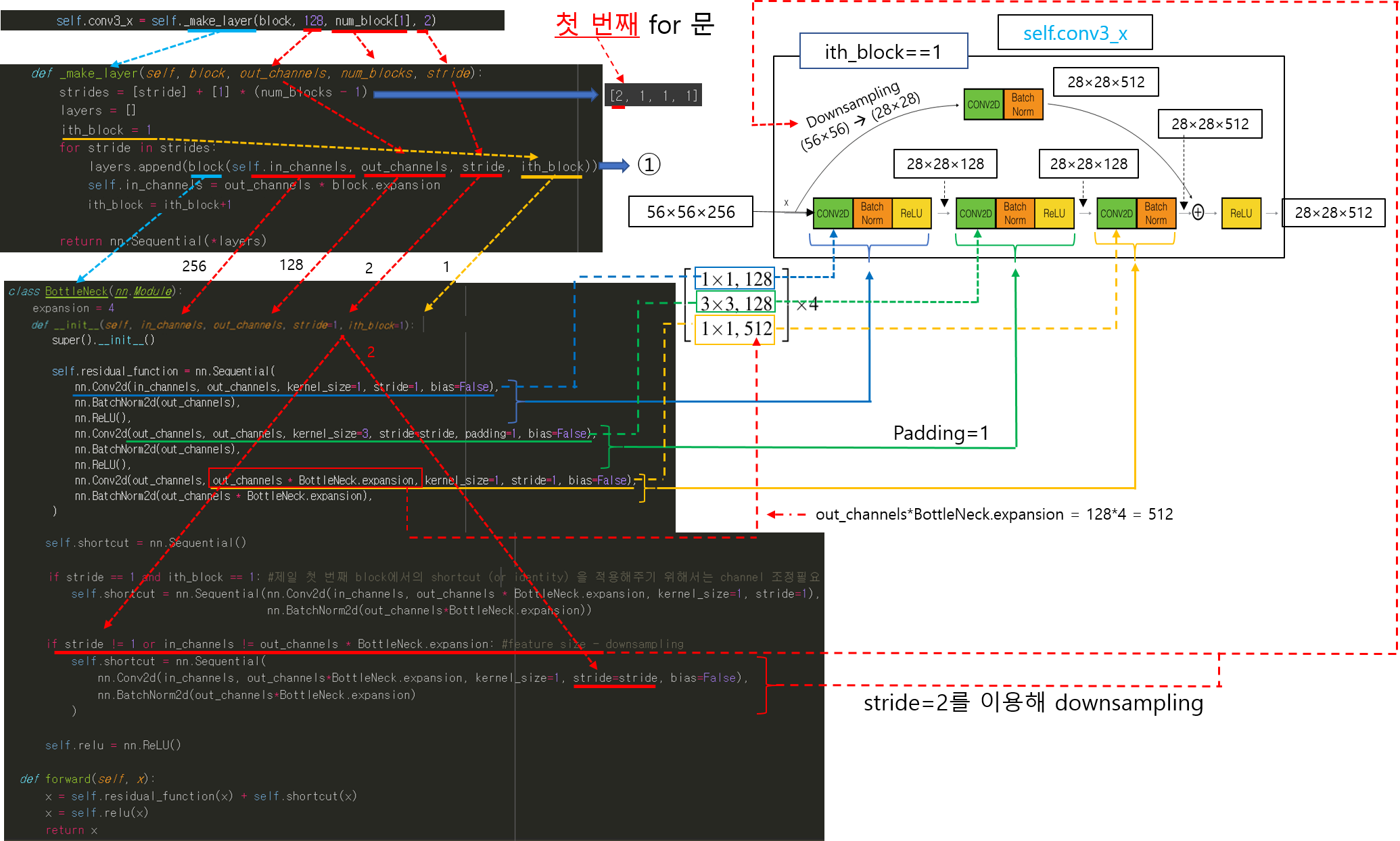
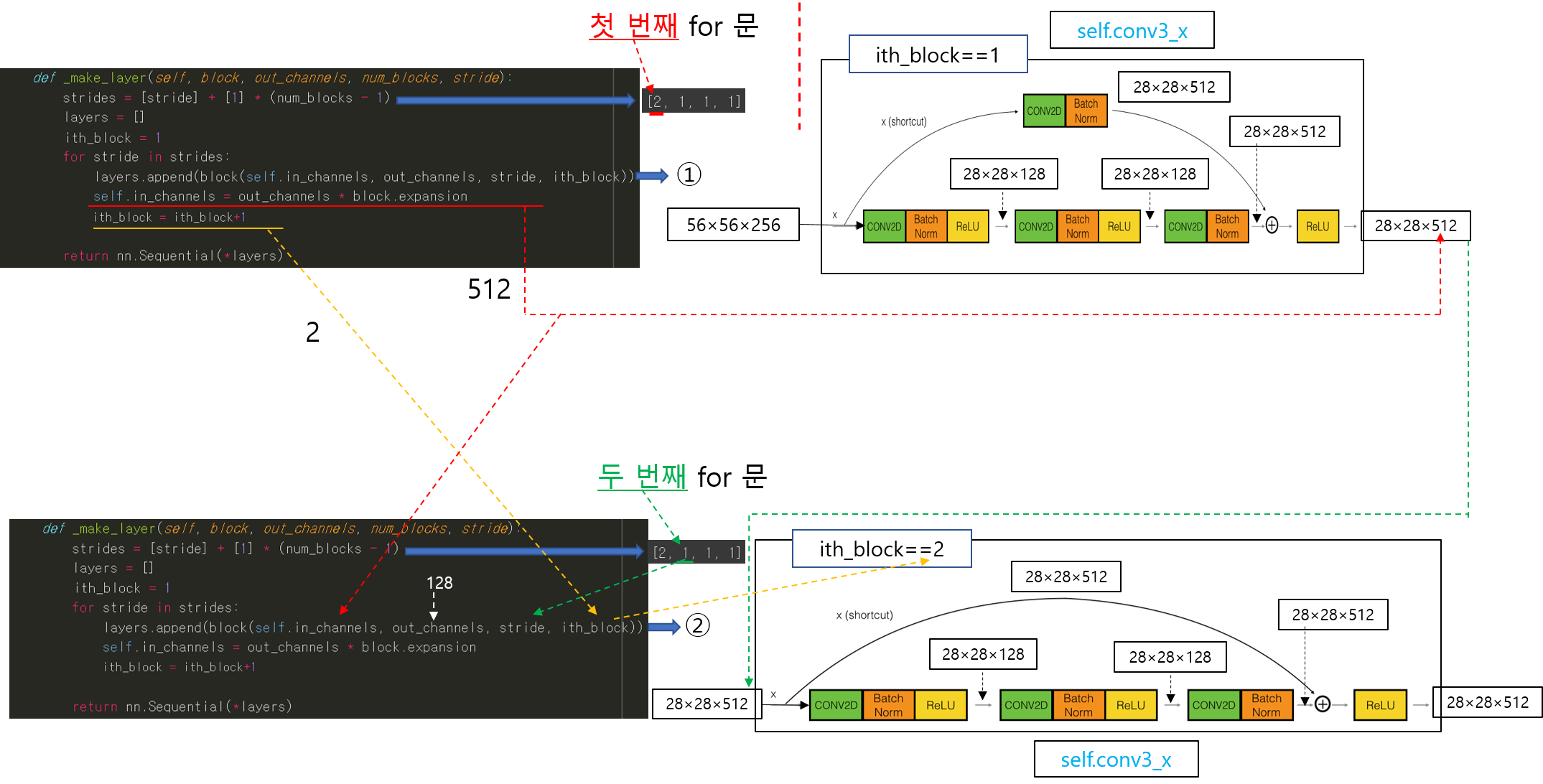
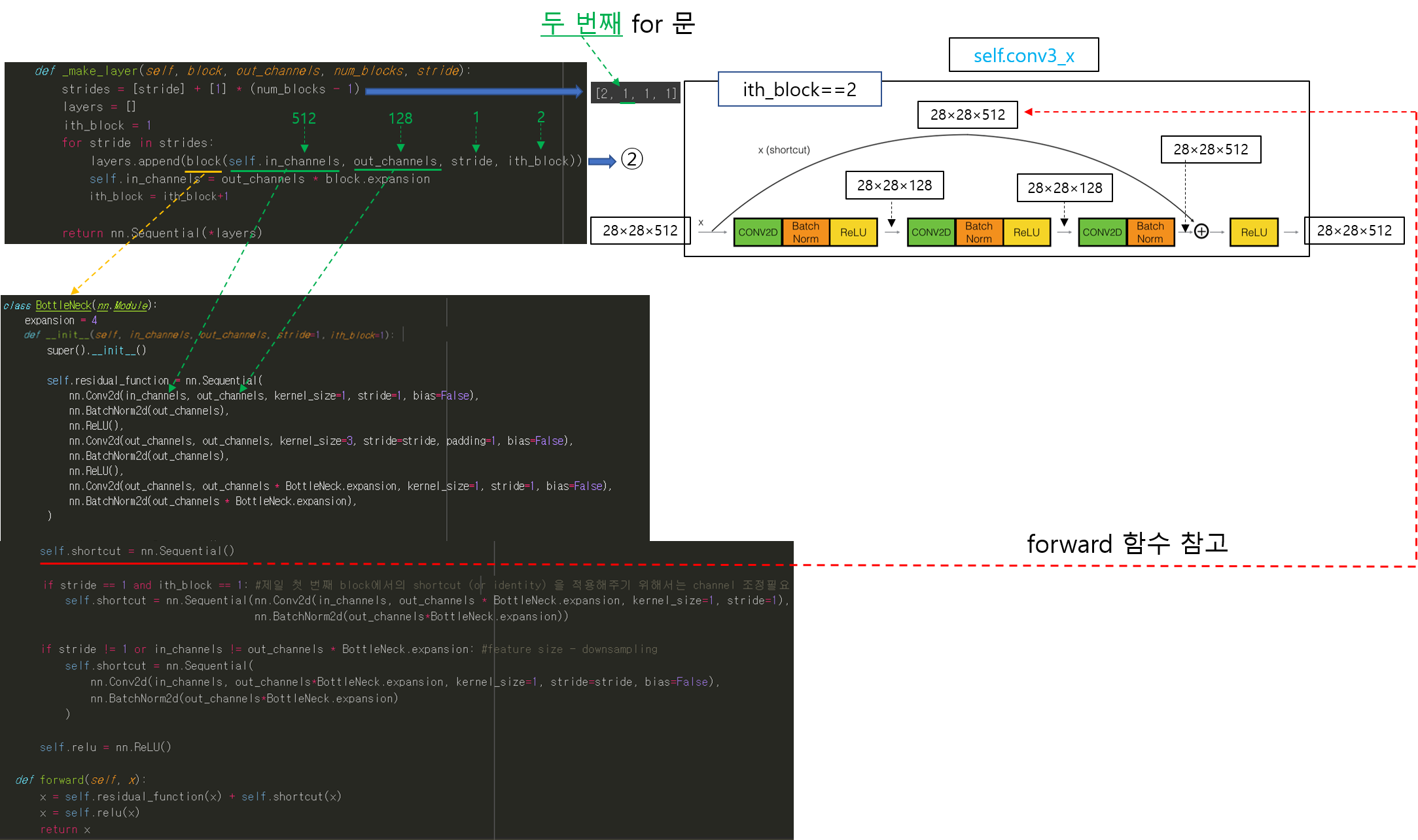
앞선 글에서는 pytorch에서 제공하는 torchvision.transforms를 이용하여 데이터 로드 하는 방식을 설명했습니다.
하지만, 이러한 방식으로 데이터 로드를 할 때, 두 가지 부분에서 불편한 부분이 생깁니다.
input과 label 이미지에 동일한(일치한) augmentation이 적용되야하기 때문에 torch.manual_seed() 함수를 이용해 난수를 고정시켜주어야 합니다.
torchvision.transforms에서 제공해주는 augmentation 종류는 한정적입니다.
위와 같은 문제를 해결하기 위해 많은 분들이 albumentations 패키지를 사용하고 있습니다.
그럼 지금부터 albumentations 패키지를 사용하여 데이터를 로드하는 방식에 대해서 설명해보도록 하겠습니다.
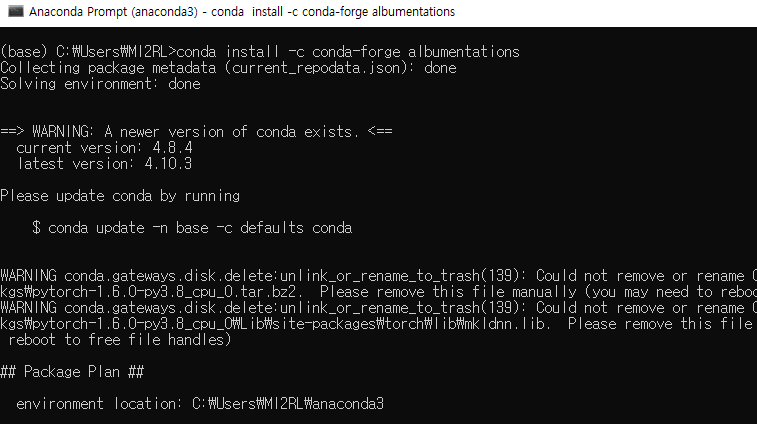
필자는 현재 Visual Studio Code IDE (=VS Code)를 이용해 코딩을 하고 있는데, VS Code의 interpreter가 아나콘다(anaconda) 가상환경에 연동되어 있기 때문에, Albumentations 패키지를 설치하기 위해서 anaconda 명령어를 이용하도록 하겠습니다.
anaconda prompt를 열고 위와 같이 설치명령어를 입력한 후 설치를 진행해줍니다.
그림1
설치가 완료되면 아래와 같이 자신이 코드를 작성하고 있는 디렉토리에서 albumentations 모듈을 import해 관련 attribute or function들을 사용하면 됩니다. 그럼 지금부터 albumentations 모듈을 사용하여 데이터 로드 하는 방식을 설명해보도록 하겠습니다.
그림2
2. Albumentation 데이터 로드 코드
지금부터 설명하는 내용은 대부분 이전글 ("1-1. Data Load (Feat. torchvision transform) 을 기반으로 달라진 부분들에 대해서만 설명하도록 하겠습니다. 다시 말해, albumentation 을 이용하여 데이터 로드를 할 때 torchvisiontransform 기반으로 데이터 로드를 하는 코드들 중 어느 부분을 수정하면 되는지 말씀드리겠습니다. (그러므로 이전 글을 읽어보시는걸 추천합니다)
먼저, 필자는 "alb_data_load.py, alb_train2.py"와 같이 파이썬 파일을 만들었습니다.
이 파일의 코드는 이전 글에서 설명한 코드들을 복사 붙여넣기 하여, albumentation을 적용하기 위해 수정된 최종 코드입니다.
[alb_data_laod.py]
import os
import numpy as np
import glob
import torch
import torch.nn as nn
## 데이터 로더를 구현하기
class Dataset(torch.utils.data.Dataset):
def __init__(self, data_dir, transform=None):
self.data_dir = data_dir
self.transform = transform
self.data_dir_input = self.data_dir + '/input'
self.data_dir_label = self.data_dir + '/label'
lst_data_input = os.listdir(self.data_dir_input)
lst_data_label = os.listdir(self.data_dir_label)
self.lst_label = lst_data_label
self.lst_input = lst_data_input
def __len__(self):
return len(self.lst_label)
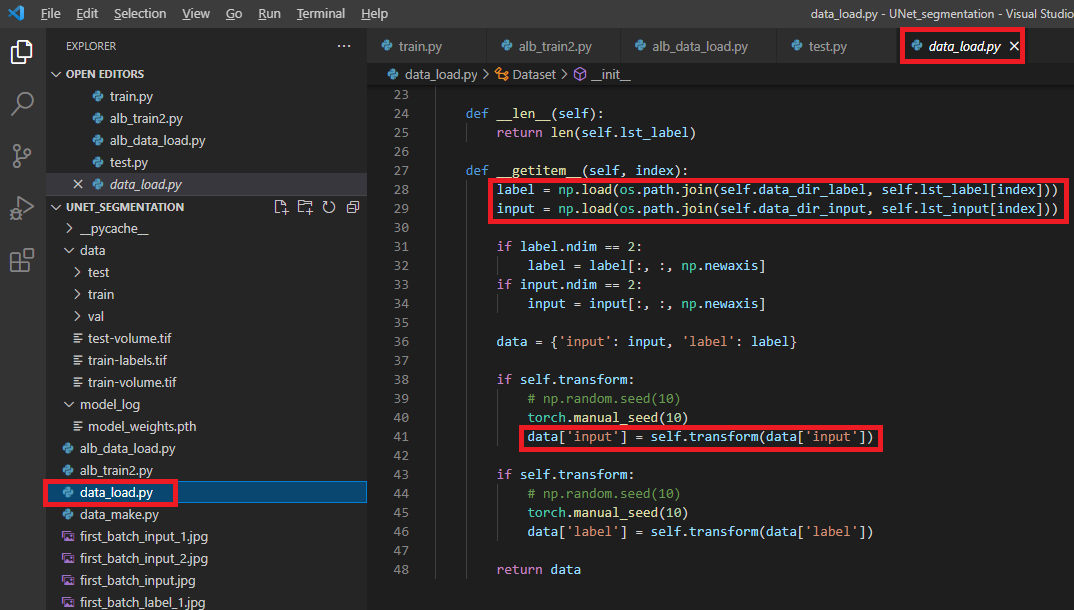
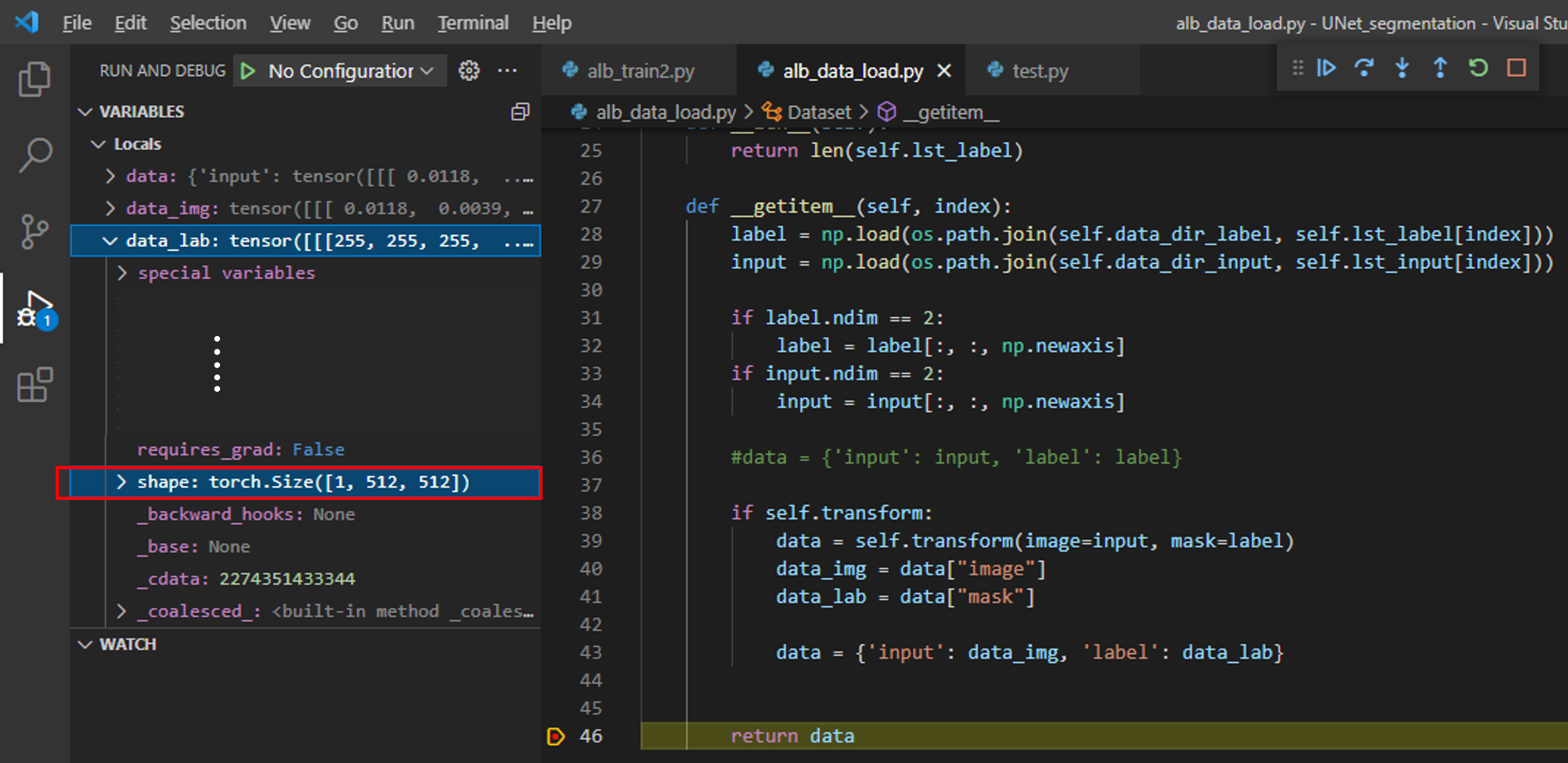
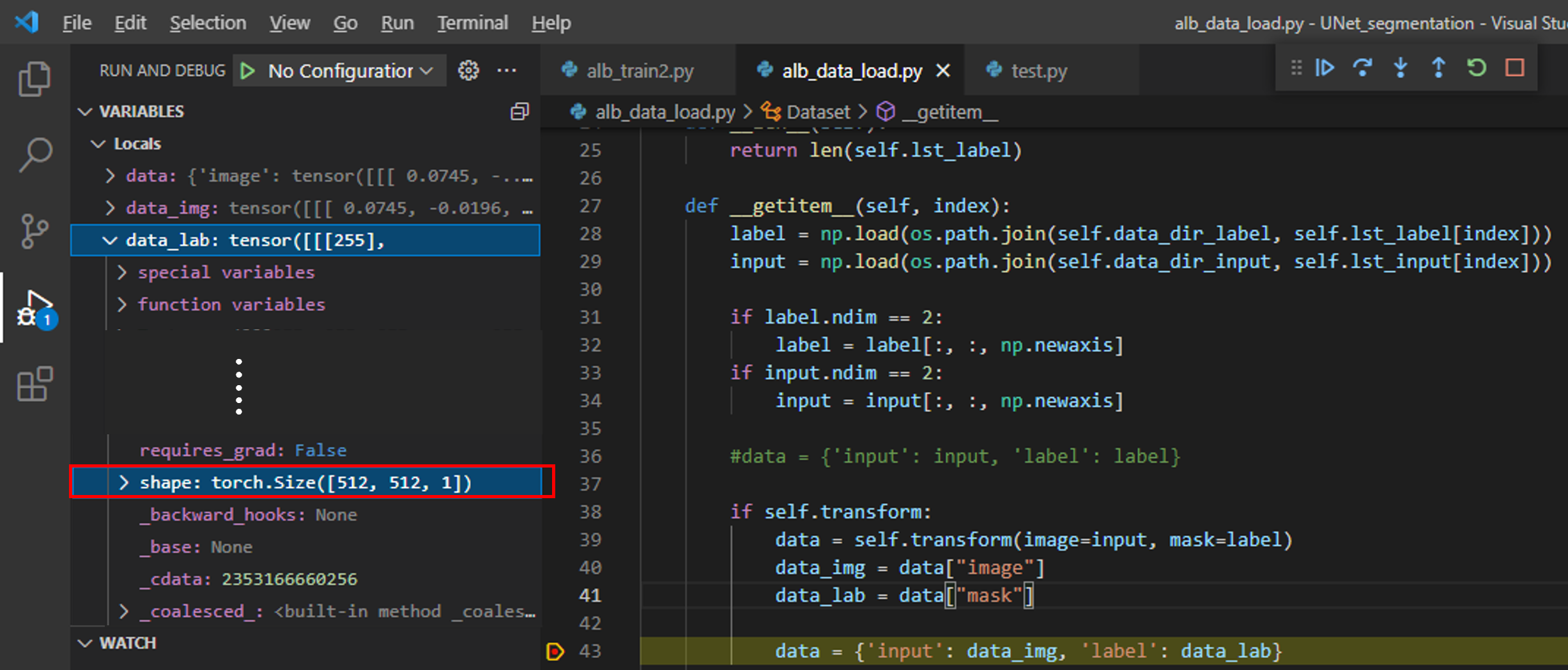
def __getitem__(self, index):
label = np.load(os.path.join(self.data_dir_label, self.lst_label[index]))
input = np.load(os.path.join(self.data_dir_input, self.lst_input[index]))
if label.ndim == 2:
label = label[:, :, np.newaxis]
if input.ndim == 2:
input = input[:, :, np.newaxis]
#data = {'input': input, 'label': label}
if self.transform:
data = self.transform(image=input, mask=label)
data_img = data["image"]
data_lab = data["mask"]
data = {'input': data_img, 'label': data_lab}
return data
[alb_train2.py]
import os
from albumentations.pytorch import transforms
import numpy as np
import torch
from torch._C import dtype
import torch.nn as nn
from torch.utils.data import DataLoader
from model import UNet
from alb_data_load import Dataset
import time
#from torchvision import transforms
import albumentations as A
import copy
from torchvision.utils import save_image
data_dir = 'data'
batch_size= 2
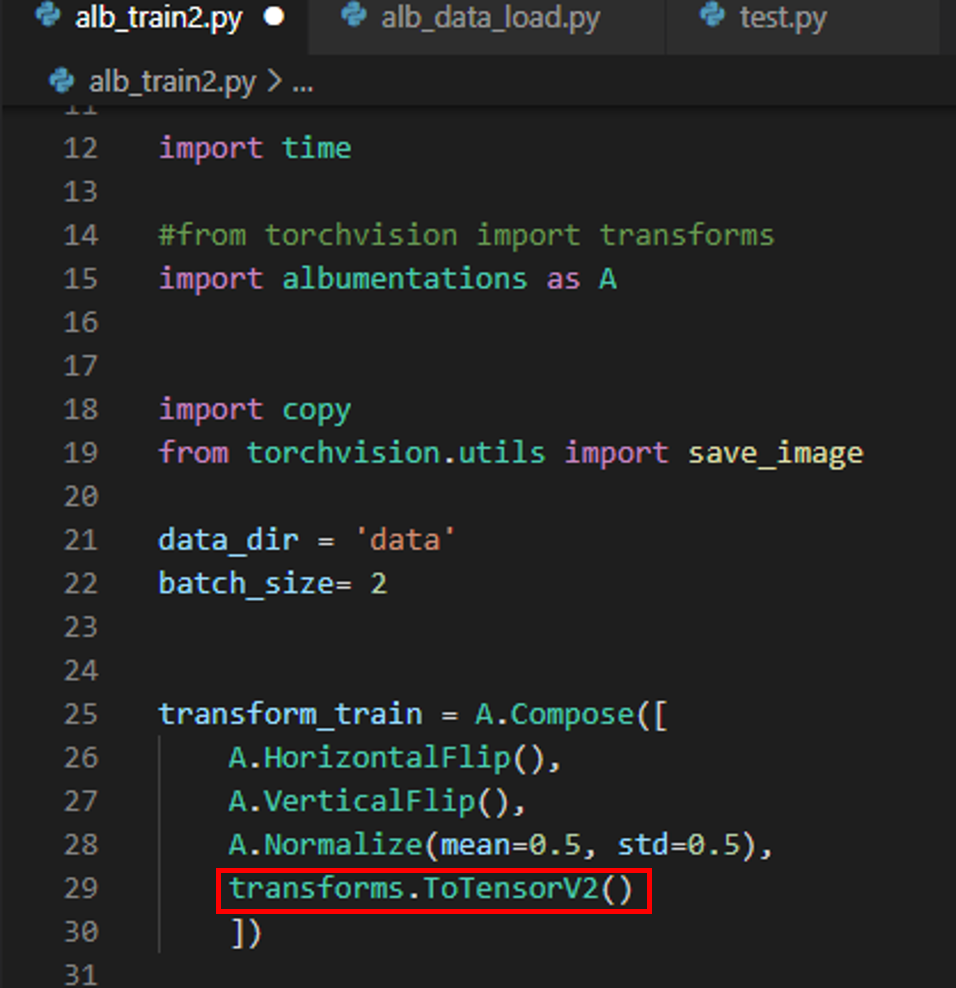
transform_train = A.Compose([
A.HorizontalFlip(),
A.VerticalFlip(),
A.Normalize(mean=0.5, std=0.5),
transforms.ToTensorV2(transpose_mask=True)
])
transform_val = A.Compose([
A.HorizontalFlip(),
A.Normalize(mean=0.5, std=0.5),
transforms.ToTensorV2(transpose_mask=True)
])
dataset_train = Dataset(data_dir=os.path.join(data_dir, 'train'), transform=transform_train)
loader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=False, num_workers=0)
dataset_val = Dataset(data_dir=os.path.join(data_dir, 'val'), transform=transform_val)
loader_val = DataLoader(dataset_val, batch_size=batch_size, shuffle=False, num_workers=0)
# 그밖에 부수적인 variables 설정하기
num_data_train = len(dataset_train)
num_data_val = len(dataset_val)
num_batch_train = np.ceil(num_data_train / batch_size)
num_batch_val = np.ceil(num_data_val / batch_size)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
## 네트워크 생성하기
net = UNet().to(device)
## 손실함수 정의하기
fn_loss = nn.BCEWithLogitsLoss().to(device)
## Optimizer 설정하기
optim = torch.optim.Adam(net.parameters(), lr=1e-3)
## 네트워크 학습시키기
st_epoch = 0
num_epoch = 30
# TRAIN MODE
def train_model(net, fn_loss, optim, num_epoch):
since = time.time()
best_model_wts = copy.deepcopy(net.state_dict())
best_loss = 100
for epoch in range(st_epoch + 1, num_epoch + 1):
net.train()
loss_arr = []
for batch, data in enumerate(loader_train, 1):
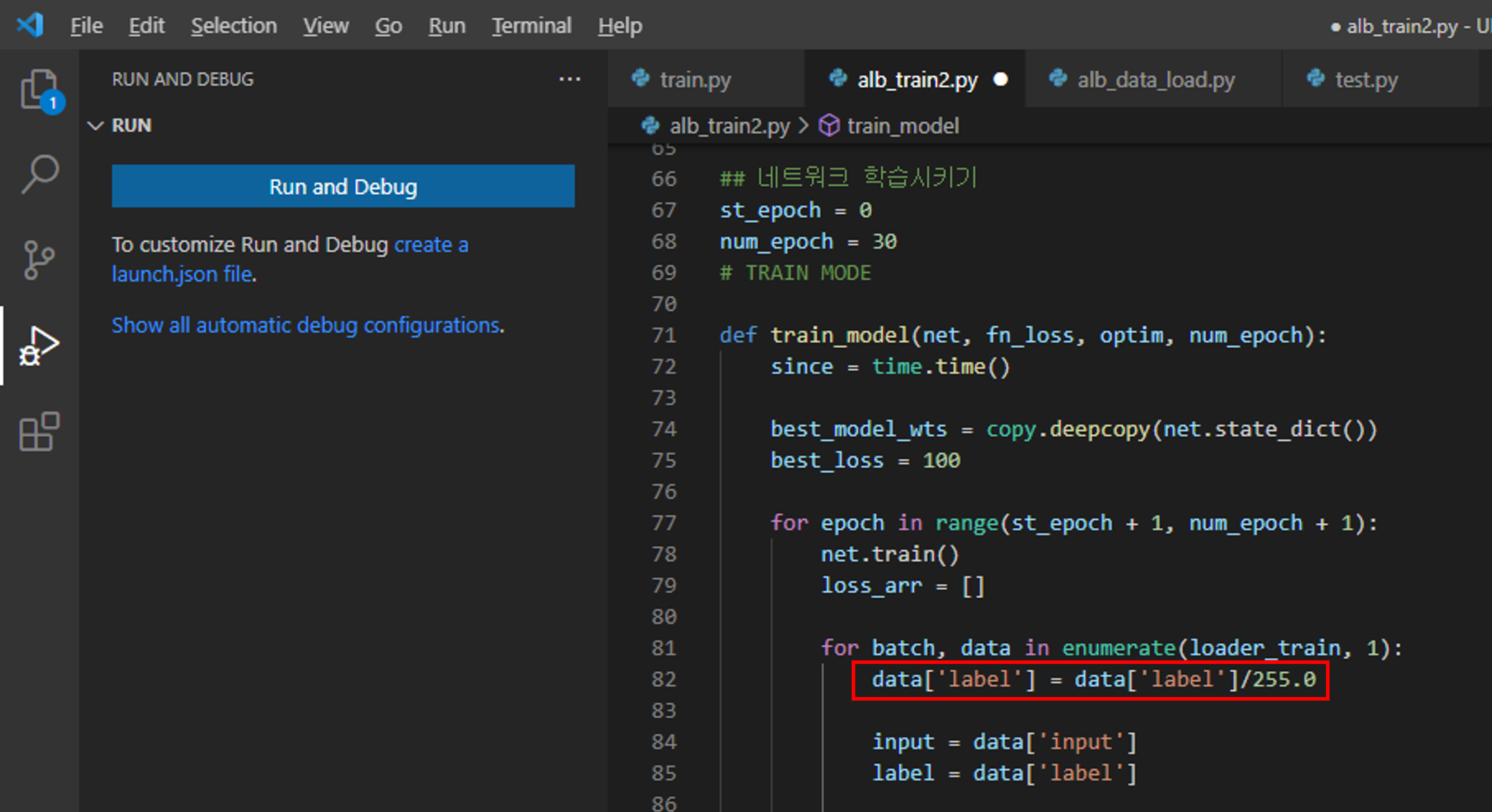
data['label'] = data['label']/255.0
input = data['input']
label = data['label']
# forward pass
label = data['label'].to(device)
input = data['input'].to(device)
output = net(input)
# backward pass
optim.zero_grad()
loss = fn_loss(output, label)
loss.backward()
optim.step()
# 손실함수 계산
loss_arr += [loss.item()]
print("TRAIN: EPOCH %04d / %04d | BATCH %04d / %04d | LOSS %.4f" %
(epoch, num_epoch, batch, num_batch_train, np.mean(loss_arr)))
with torch.no_grad():
net.eval()
loss_arr = []
for batch, data in enumerate(loader_val, 1):
data['label'] = data['label']/255.0
# forward pass
label = data['label'].to(device, dtype=torch.float32)
input = data['input'].to(device, dtype=torch.float32)
output = net(input)
# 손실함수 계산하기
loss = fn_loss(output, label)
loss_arr += [loss.item()]
print("VALID: EPOCH %04d / %04d | BATCH %04d / %04d | LOSS %.4f" %
(epoch, num_epoch, batch, num_batch_val, np.mean(loss_arr)))
epoch_loss = np.mean(loss_arr)
# deep copy the model
if epoch_loss < best_loss:
best_loss = epoch_loss
best_model_wts = copy.deepcopy(net.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val loss: {:4f}'.format(best_loss))
# load best model weights
net.load_state_dict(best_model_wts)
return net
model_ft = train_model(net, fn_loss, optim, num_epoch)
torch.save(model_ft.state_dict(), './model_log/model_weights.pth')
그럼 위의 코드와 이전 글의 코드를 비교하면서 설명을 해보도록 하겠습니다.
3. Import
먼저 이전 글에서 추가할 import 부분에 대해서 설명하겠습니다.
alb_data_load.py 라는 새로운 데이터 로드 파일을 만들어 주었으므로 alb_data_load의 Dataset을 import 합니다.
from alb_data_load import Dataset
설치한 albumentaion 관련 모듈을 import 해줍니다.
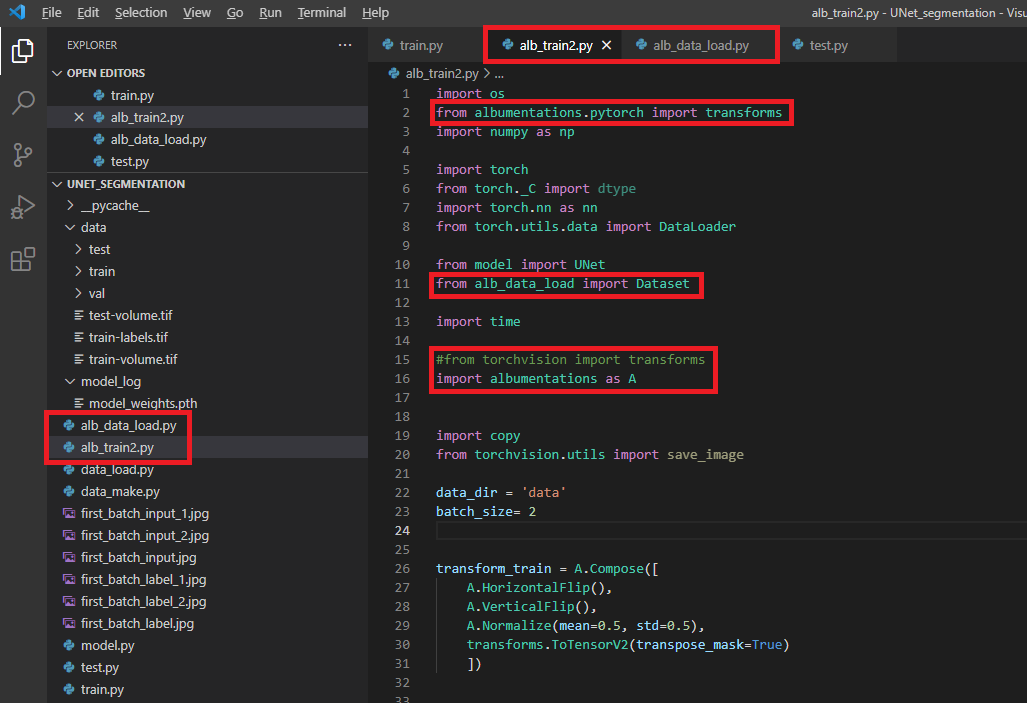
import albumentations as A
from albumentations.pytorch import transfroms → 아래 "그림3"에서 transfor_train 부분을 보면 마지막에 ToTensorV2가 구현된 것을 볼 수 있습니다. ToTensorV2만 "albumentations.pytorch"로부터 import 한다는 걸 인지하세요!
그림3
4. alb_data_load.py 변경
4-1. albumentation.transform(image, mask)
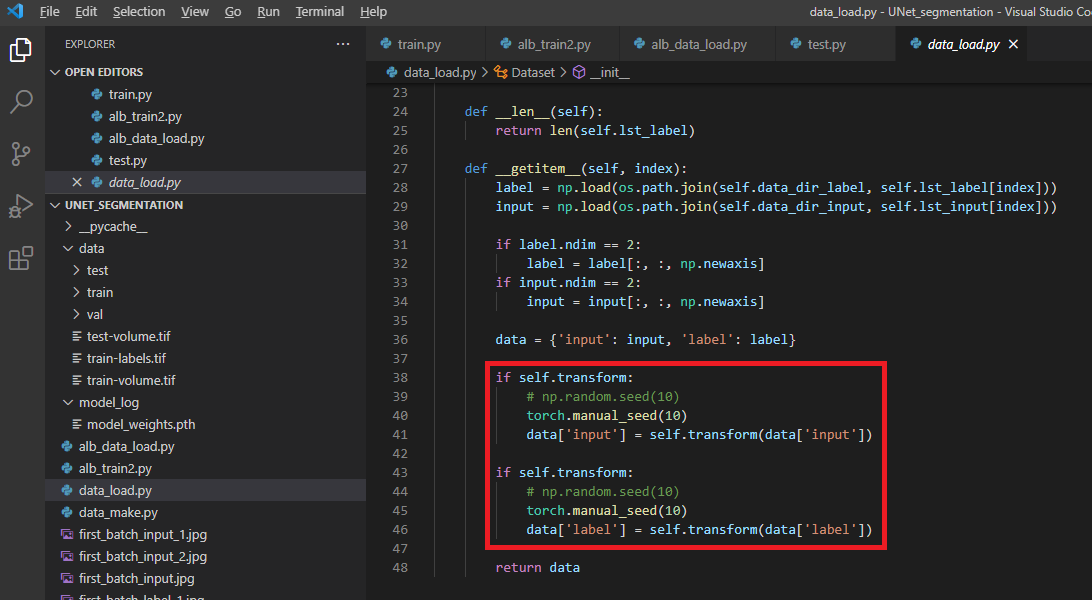
먼저, 이전 글에서 설명한 torchvision.transform의 인자형태를 보도록 하겠습니다. (아래 "4그림")
transform(data['input']), transform(data['label']) 이렇게 transform에는 하나의 리스트 인자(argument)만 받을 수 있게 되어 있습니다 (이러한 부분 때문에 torch.manual_seed()를 사용했죠 ← 자세한 설명은 이전 글 참고!)
그림4
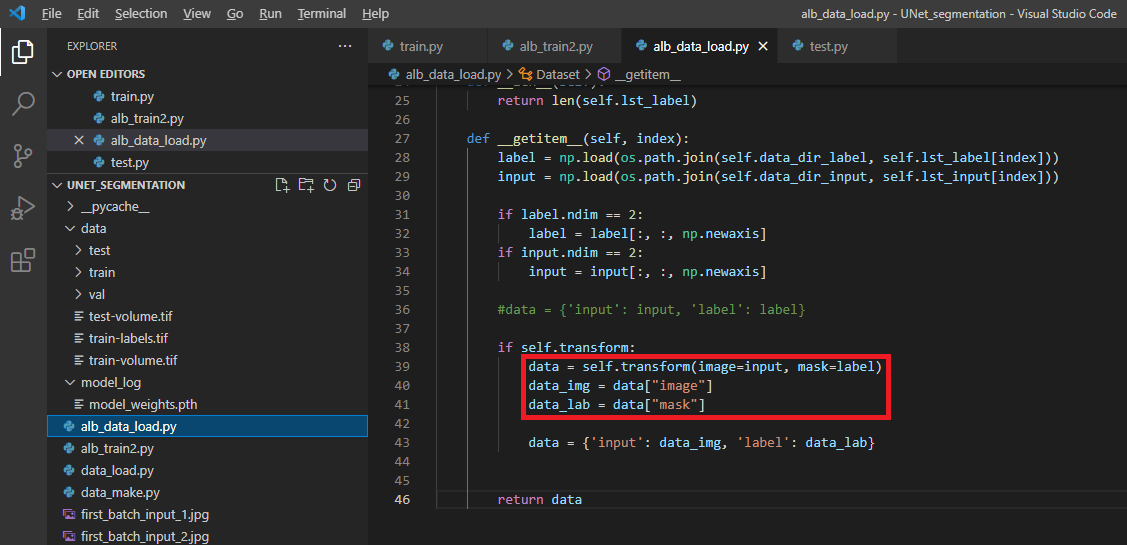
그렇다면, albumentation에서 제공해주는 transform을 이용하면 위의 부분(="그림4"의 빨간색 박스)이 어떻게 바뀔 수 있을까요?
albumentation에서 제공해주는 transform은 두 개의 리스트 인자를 받을 수 있게 되어 있습니다. (아래 "그림5")
그래서 training image, training label을 동시에 넘겨줄 수 있기 때문에 따로 seed를 고정시켜줄 필요가 없습니다. (실제로 data_img, data_lab 데이터를 10번 정도 이미지화해서 살펴봐도 augmentation이 동일하게(일치하게) 적용되는 것을 확인할 수 있었습니다)
그림5
5. alb_train2.py 변경
5-1. transform.Compose → A.Compose
(이전 글에서 봤듯이) transform.Compose에 구현된 augmentation을 적용하기 위해 입력되는 데이터 형식은 numpy입니다.
그림6
그림7
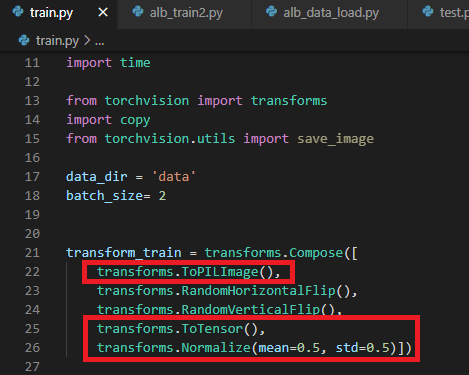
먼저, 이전 글에서 사용했던 torchvision.transform.Compose에 구현된 순서를 살펴보겠습니다. (아래 "그림8")
torchvision.transform.Compose에서 제공하는 augmentation (ex: RandomHorizontalFlip(), etc..) 을 적용하기 위해서는 PIL 타입의 데이터가 입력되어야 합니다. 그래서 아래와 같이 "transforms.ToPILImage()" 를 먼저 수행시켜주어야 합니다. 그리고, PIL 타입을 torch tensor 타입으로 변경시켜준 후 (by "ToTensor()"), Normalize() 작업을 진행해줍니다.
그림8
그렇다면, albumentation.transform.Compose에서는 어떤 순서로 구성되는지 알아볼까요? (아래 "그림9")
우선 numpy 형식으로 입력되는 데이터를 PIL 형식으로 변경해줄 필요가 없기 때문에 "ToPILImage()"를 사용할 필요가 없습니다. 그리고, torch tensor 형태로 변경하기 전에 먼저 Normalize를 적용해주네요. 그리고, ToTensorV2를 적용해줍니다.
그림9
여기서 좀 더 보충해서 설명해야할 부분이 Normalize(), ToTensorV2() 입니다.
5-2. Normalize()
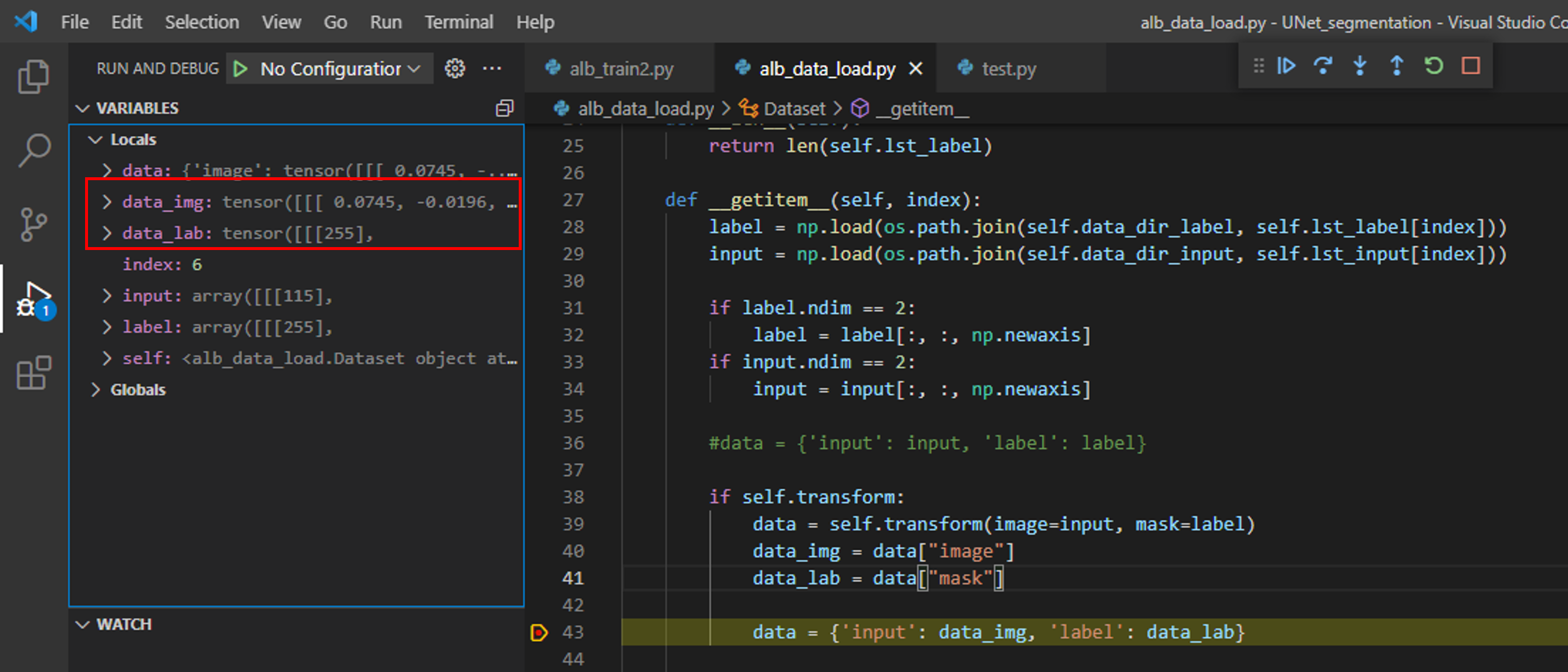
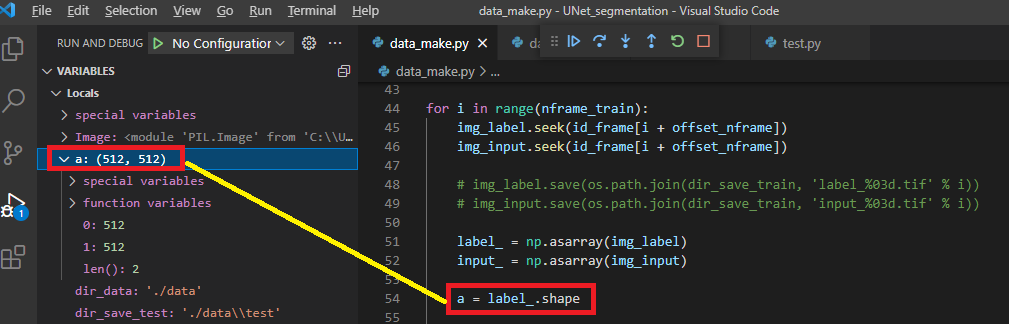
먼저, 아래 "그림10"처럼 breakpoint를 걸어주고 "alb_train2.py"를 실행시켜봅시다.
그림10
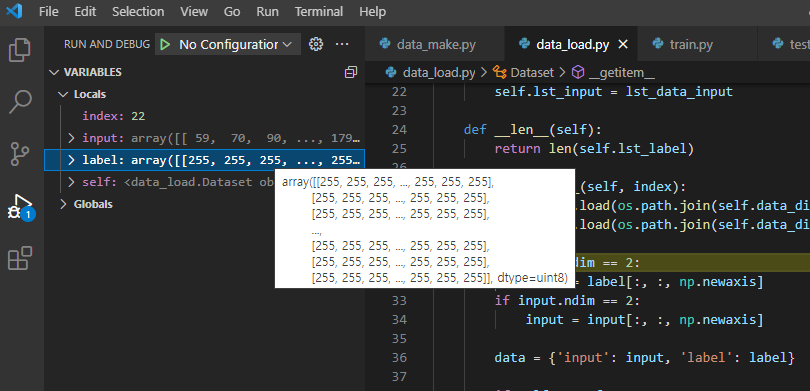
위 "그림10"처럼 디버깅을 하면 data_img, data_lab 값을 살펴볼 수 있습니다.
그런데, data_img에는 Normalize가 적용이 안되어 있습니다.
이러한 사실로 볼때 albumentation.transform.Compose에 적용되는 augmentation 중에 Normalize()는 label(=mask)에 적용되지 않는 듯합니다.
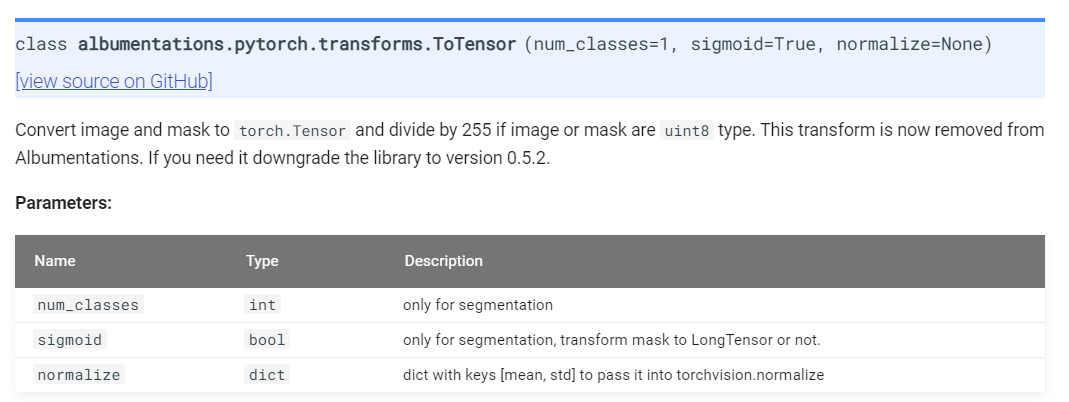
5-3. ToTensorV2()
이전 글에서 torchvision.transform.ToTensor()는 아래와 같은 기능을 한다고 했습니다.
Converts a PIL Image or numpy.ndarray (H x W x C) in the range [0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0] if the PIL Image belongs to one of the modes (L, LA, P, I, F, RGB, YCbCr, RGBA, CMYK, 1) or if the numpy.ndarray has dtype = np.uint8
그런데, albumentation.transform.ToTensorV2() 결과 label의 타입이 numpy (=HxWxC) 에서 torch tensor 타입 (=C x H x W)으로 바뀌었지만, range는 그대로 0~255인 것을 확인할 수 있습니다. (아래 "그림11")
그림11
그 이유를 아래 "albumentations.pytorch.transforms.ToTensorV2()" API를 살펴본 후 알 수 있었습니다.
쉽게 말해 albumentation 패키지 version 0.5.2 이후 부터는 255로 나누어주어 range를 0~1로 변경해주는 기능이 제거된다. 이러한 사실통해 살펴 볼때, 앞서 "data_img" 값들이 0~1로 범위가 변경된 이유는 Normalize()에 해당 기능(← 값의 범위를 0~1로 변경해주는 기능)이 들어있기 때문인듯 합니다. (앞서 albumentation.transforms.Normalize()는 label이 아닌 image에만 적용된다고 언급했습니다)
그림12
하지만, label(=mask)에 해당하는 값이 loss function(=crossentropy)의 인자 값으로 들어가기 위해서는 label이 0 or 1의 값을 갖아야 합니다. 즉, label 데이터 값의 255를 1로 변경해주어야 하는 것이죠 (or labeling smoothing을 적용하려면 label의 값의 범위가 0~1 사이로 변경되어야겠죠?)
이 부분은 간단하게 구현해줄 수 있습니다.
그냥 "alb_train2.py"에서 아래와 같이 data['label']을 255로 나누어주면 됩니다.
그림13
[주의사항]
아래와 같이 "ToTensorV2()"에 transpose_mask 부분을 명시해주지 않으면 False 값이 default가 됩니다.
그림14
위와 같이 코드를 실행 시키면 torch tensor 형식(=C x H x W)이 아닌 (H x W x C) 형식인걸 알 수 있습니다.
그림15
물론 (H x W x C) 구조를 permute()을 이용해 쉽게 (C x H x W) 구조로 변경 가능하지만, 그냥 ToTensorV2(transpose_mask=True)를 해주면 자동으로 구조변경이 된다는 점을 알아두시면 좋을 듯 합니다.
현재 아래코드가 실행되기 직전의 data['input']에 들어 있는 데이터 구조는 3차원(H,W,C) 형태로 변경된numpy 데이터 입니다.
if self.transform:
torch.manual_seed(10)
data['input'] = self.transform(data['input'])
그리고, self.transform(data['input'])이 실행되면 transform.Compose에 적힌 순서대로 데이터의 변화가 일어납니다.
먼저, RandomHorizontalFlip과 같이 torchvision에서 제공해주는 augmentation 기법을 사용하기 위해서는 현재 numpy 형식의 데이터가 PIL 이미지 형식의 데이터가 입력값으로 들어와야 합니다.
그렇기 때문에 transform.Compose 부분에서 제일 처음으로 "transforms.ToPILImage()"를 작성해줍니다.
[주의사항1]
만약, ToPILImage() 부분을 작성하지 않으면 아래와 같은 에러가 발생합니다.
에러 메시지 내용은 아래와 같습니다.
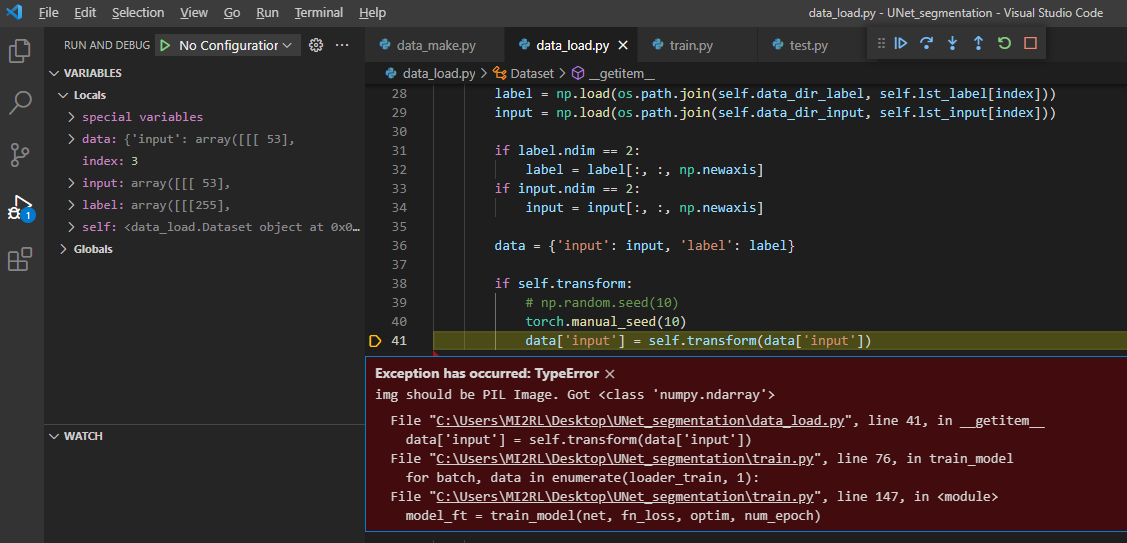
"현재 입력 받은 이미지의 형식은 numpy.ndarray 이니까 (="Got <class 'numpy.ndarray'>), PIL 형태로 바꿔주어야 합니다(="img should be PIL Image")"
그림4
2-2) transforms.ToTensor, transforms.Normalize 위치
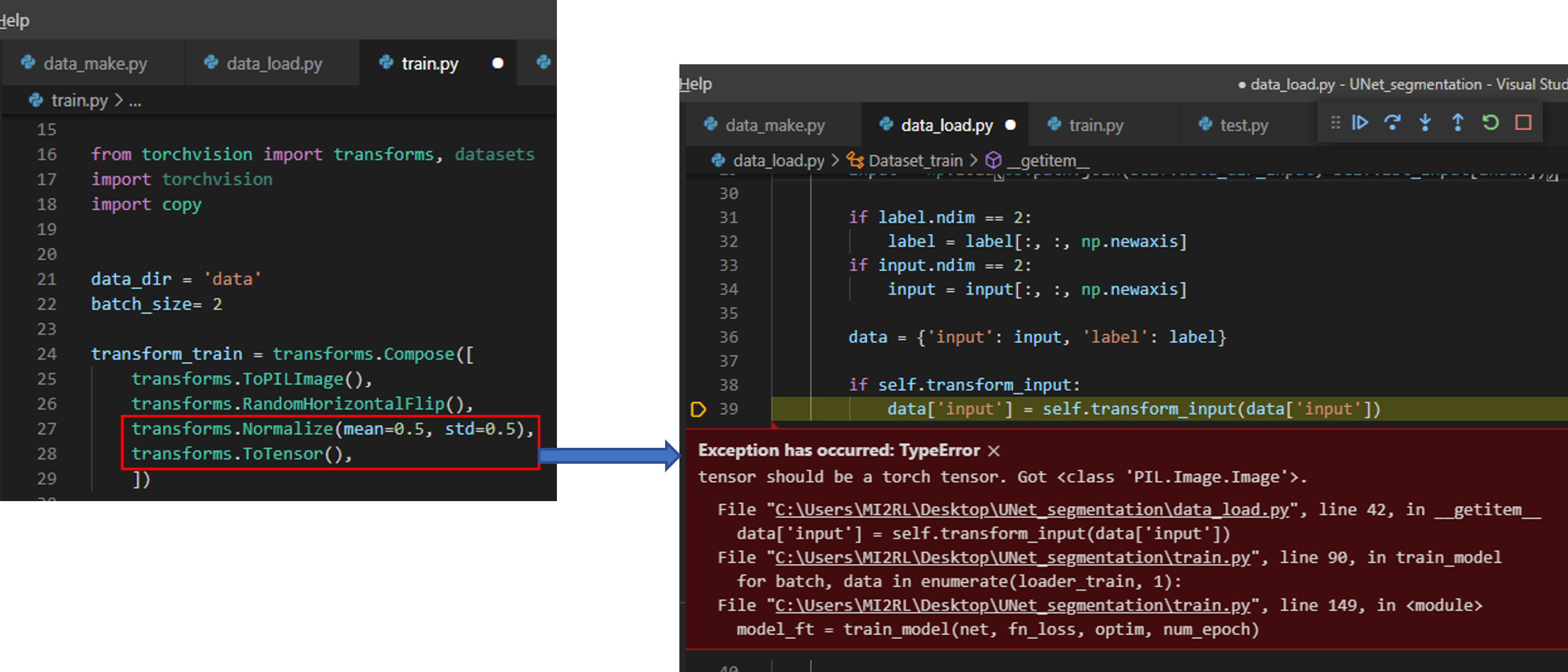
Pytorch에서 제공해주는 transforms.Normalize()를 사용하려면 항상 transforms.ToTensor() 이후에 위치해야 합니다.
이렇게 위치시켜야하는 이유는 Normalize()가 torch tensor 형식을 입력으로 받기 때문입니다.
아래 코드를 기반으로 설명하면, RandomVerticalFlip까지 적용된 데이터 형식은 PIL image 형식 (512x 512x 1)인데, 이것을 Normalize가 적용되려면 (1x 512x 512) 형식으로 변경되어야 합니다 (pixel range도 0~1로 변경되어야 합니다).
ToTensor(): Converts a PIL Image or numpy.ndarray (H x W x C) in the range [0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0]
"현재 입력 받은 이미지의 형식은 PIL기반 tensor이니까 (="Got <class 'PIL.Image.Image'>), PIL 형태로 바꿔주어야 합니다(="tensor should be a torch tensor")"
그림5
2-3. input, label에 적용되는 transform seed 고정해주기
아래 코드를 살펴보면 "torch.manual_seed(10)"이라는 것이 있습니다.
[data_load.py]
if self.transform:
torch.manual_seed(10)
data['input'] = self.transform(data['input'])
if self.transform:
torch.manual_seed(10)
data['label'] = self.transform(data['label'])
"torch.manual_seed(10)" 코드를 추가하는 이유를 설명하기 위해, "torch.manual_seed(10)"가 없을 때 일어나는 일에 대해서 알아보도록 하겠습니다.
우선 "data_load.py" 부분에서 "torch.manual_seed(10)" 코드를 주석 처리해보겠습니다.
if self.transform:
#torch.manual_seed(10)
data['input'] = self.transform(data['input'])
if self.transform:
#torch.manual_seed(10)
data['label'] = self.transform(data['label'])
그리고, "train.py" 부분에서 딥러닝 모델에 입력되기 직전의 이미지 상태를 알아보도록 하겠습니다.
이전 transforms.Compose에서 input, label에 모두 transforms.Normalize가 적용이 됐다는걸 알 수 있습니다.
그런데, 생각해보면 label에는 Normalize가 적용이 돼서는 안되겠죠? (label에는 0 or 1 값만 들어 있어야 되는데 앞서 mean, std를 이용해 normalize를 하면 1 or -1 값을 갖게됩니다. 하지만, CrossEntropy loss function이 받는 label 값들은 0 or 1 이어야 하죠)
그러므로, 가장 먼저 수정해주어야 하는 부분이 normalize가 적용된 label 이미지 데이터들을 다시 denormalize 해주어야 한다는 점입니다. 그래서 아래 "data['label']*0.5+0.5" 부분이 추가가 되었습니다.
[train.py]
for batch, data in enumerate(loader_train, 1):
data['label'] = data['label']*0.5+0.5 #denormalization -> X*std+mean
label = data['label']
input = data['input']
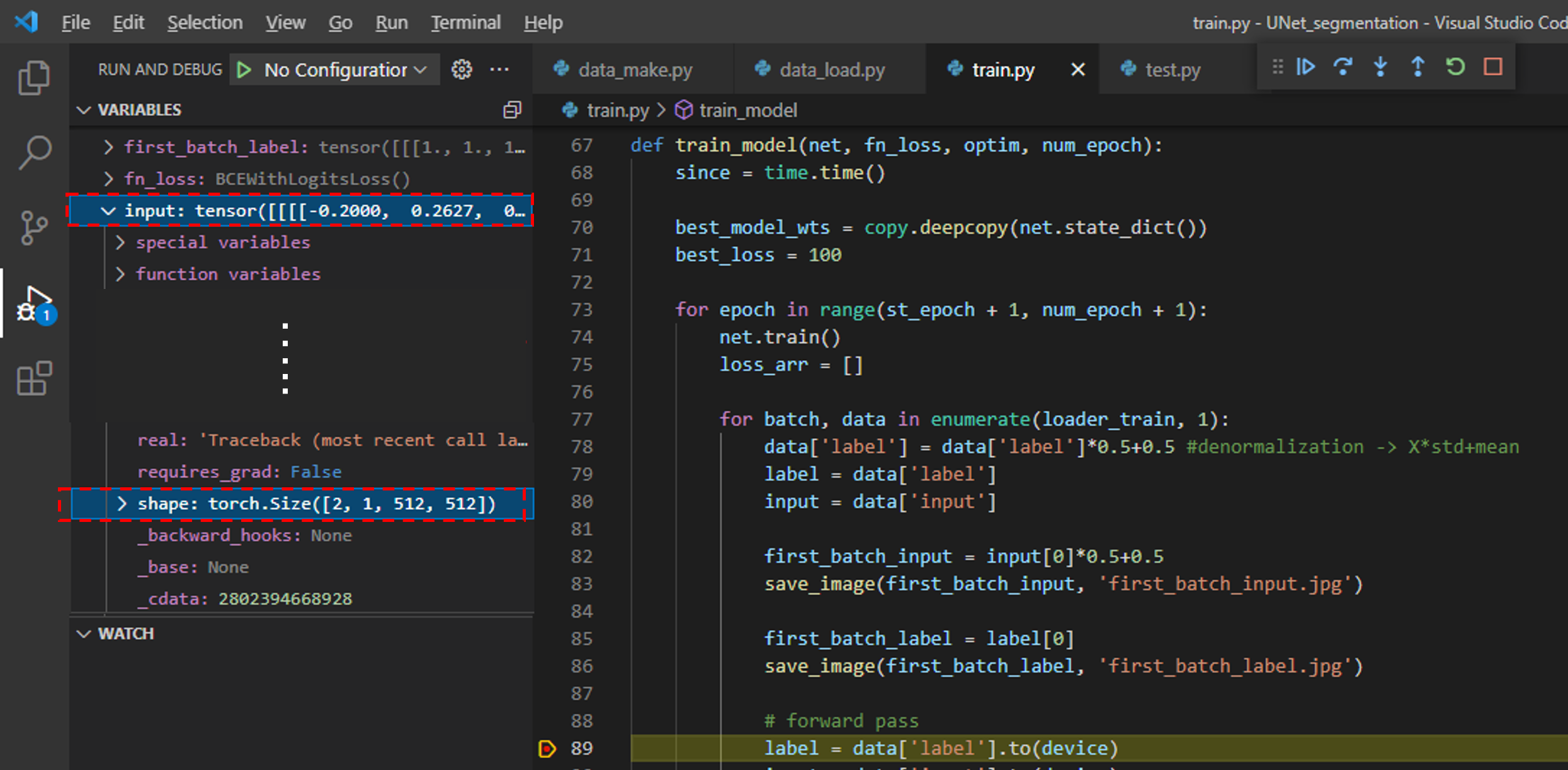
다음으로는 딥러닝 모델에 들어가기 직전의 데이터들을 저장해서 보겠습니다.
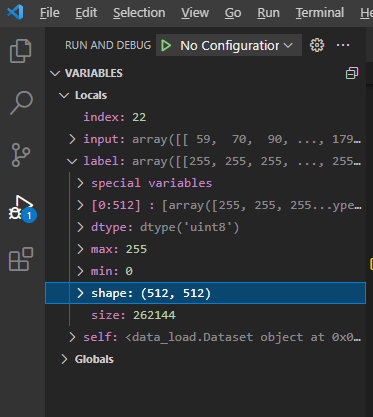
먼저, 아래 부분(89번 line)에 breakpoint를 걸어주어 input 데이터의 shape을 살펴보면, (batch, Channel, Height, Width)와 같은 형태로 구성되어 있는걸 확인하실 수 있습니다.
그림6
그럼 input, label의 각각 첫 번째 batch 이미지를 따로 저장시킬 코드를 추가하겠습니다.
우선 input 데이터에서도 normalize가 적용된 상태이기 때문에 denormalize를 해줍니다. (←"input[0]*0.5+0.5")
그리고 첫 번째 batch 이미지에 해당하는 데이터 값은 "input[0]*0.5+0.5", "label[0]"인데, 현재 데이터 형식은 torch tensor입니다.
torch tensor 형식에서 곧 바로 이미지를 저장하기 위해서는 "torchvision.utils"에서 제공하는 save_image()를 이용하면 됩니다.
for batch, data in enumerate(loader_train, 1):
data['label'] = data['label']*0.5+0.5 #denormalization -> X*std+mean
label = data['label']
input = data['input']
#################코드가 추가된 부분###################
first_batch_input = input[0]*0.5+0.5
save_image(first_batch_input, 'first_batch_input.jpg')
first_batch_label = label[0]
save_image(first_batch_label, 'first_batch_label.jpg')
#######################################################
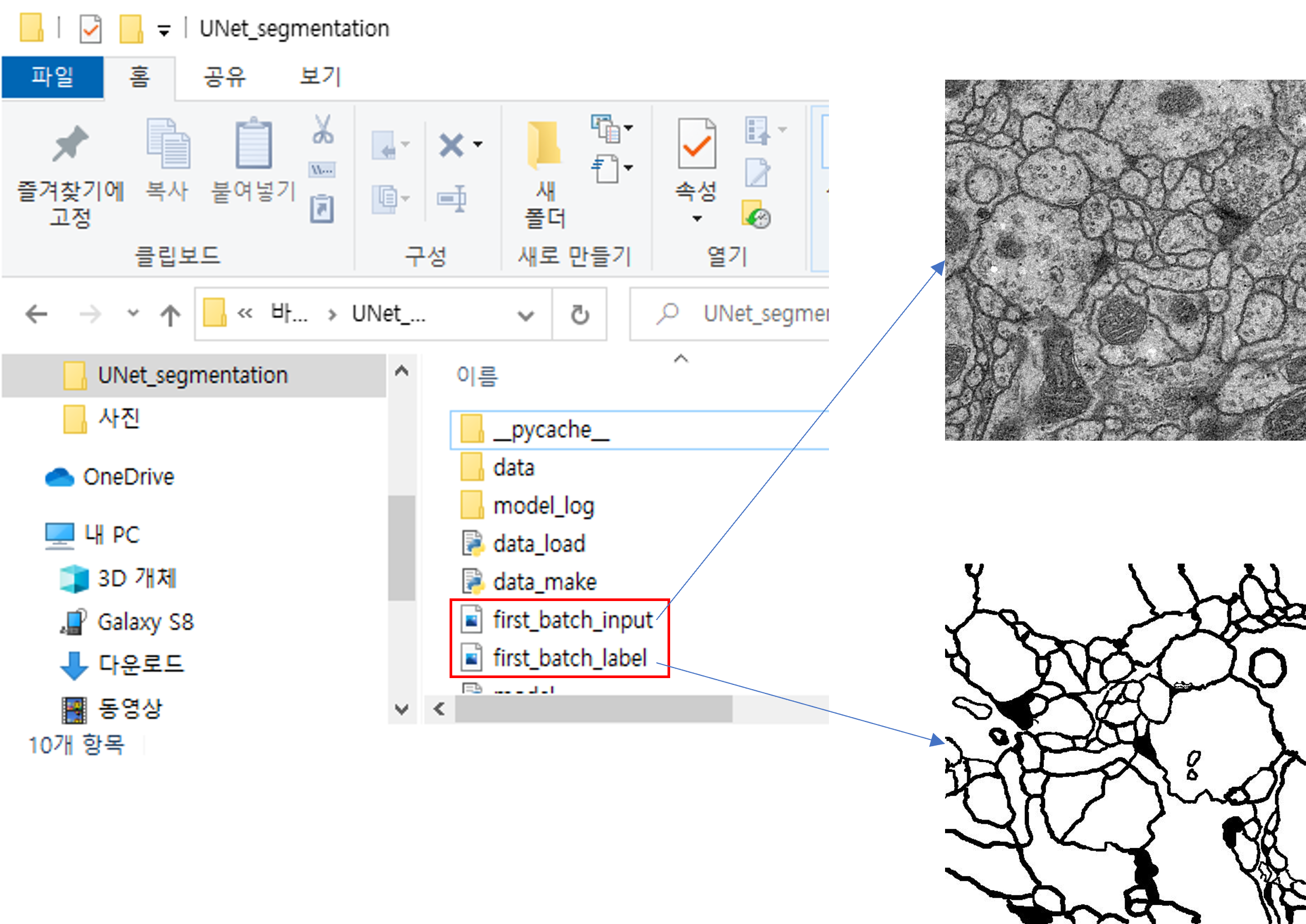
코드를 실행하고 저장된 이미지를 살펴보겠습니다.
input 데이터의 이미지와 label 데이터의 이미지가 일치하지 않는게 보이시나요? 어느 한쪽이 flip이 안 됐다는 정도는 파악할 수 있을겁니다.
그림7
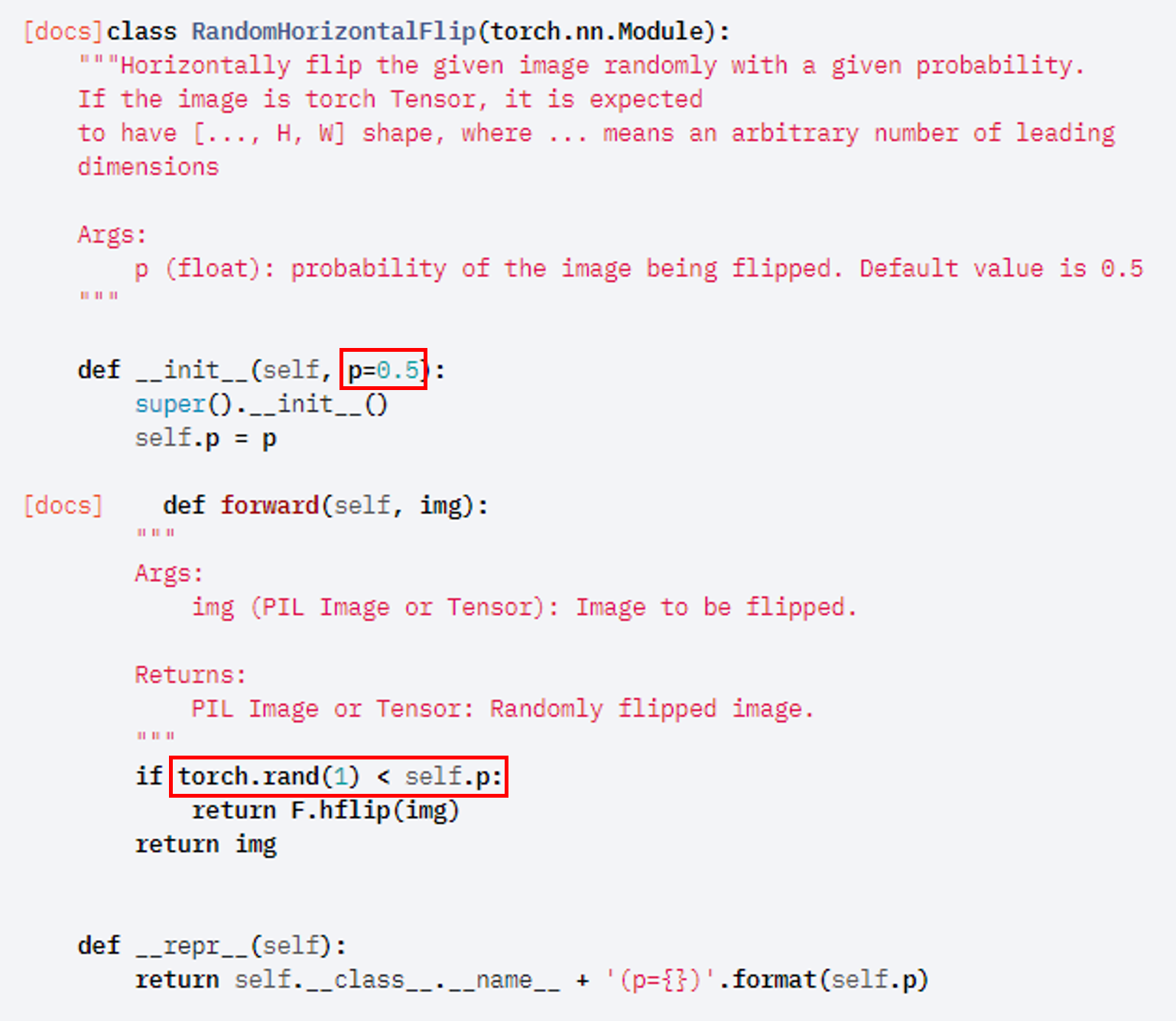
이렇게 나오는 이유를 찾기 위해 transforms.RandomHorizontalFlip 코드를 살펴보았습니다.
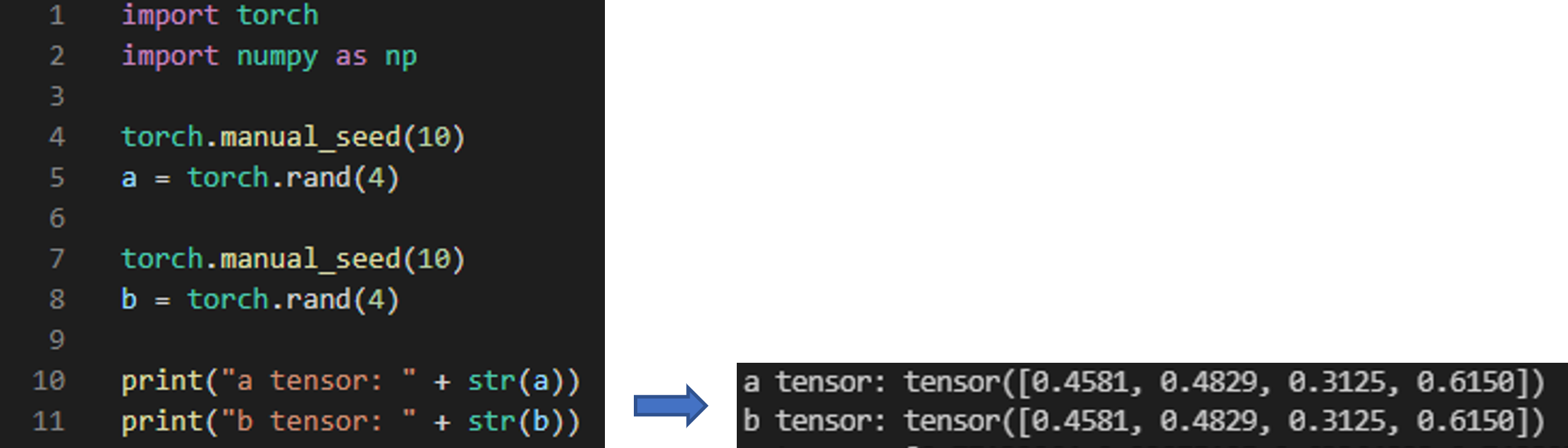
torch.rand(1)은 데이터가 1차원 형태이며 0~1 사이의 값 중 하나를 출력한다는 뜻입니다.
만약, 4차원 형태를 나타내려면 아래와 같이 코딩해주면 됩니다.
그림9
위의 코드를 결과를 살펴보면 torch.rand를 실행시켜 줄 때 마다 난수가 발생하기 때문에 a, b에 들어가는 값들이 전부다른걸 보실 수 있습니다.
위와 같은 사실을 기반으로 "data_load.py"에 구현되어 있는 아래 코드를 살펴보겠습니다.
우선 data['input']에 해당하는 데이터에 transform이 진행되는 과정을 살펴보겠습니다. → self.transform(data['input'])
if self.transform:
#torch.manual_seed(10)
data['input'] = self.transform(data['input'])
앞서 transforms.Compose에 구현된 것 중하나가 RandomHorizontalFlip()인데, 이 부분이 아래와 같은 코드를 기반으로 수행이 될 겁니다. 그런데 보면, torch.rand(1)를 통해 난수가 발생하는 걸 볼 수 있죠? 만약 여기서 0.3이라는 값이 생성되면 "p=0.5" 기준에 의해 RandomHorizontalFlip() 방식의 augmentation이 진행되지 않을 것입니다.
그림8
이때 label 데이터에서도 RandomHorzontalFlip()이 적용이 되는데 (by "self.transform(data['label'])"), torch.rand(1)에서 생성된 값(=난수)가 0.6이면, label에는 RandomHorzontalFlip()이 적용되게 됩니다.
if self.transform:
#torch.manual_seed(10)
data['input'] = self.transform(data['input'])
if self.transform:
#torch.manual_seed(10)
data['label'] = self.transform(data['label'])
그래서 "그림7"과 같은 결과를 보이게 됩니다.
이러한 문제를 해결하기 위해서는 "torch.rand(1)"를 통해 생성되는 난수를 고정시켜주어야 합니다.
난수를 고정시키는 방법은 간단합니다. 아래와 "그림10"처럼 난수가 생성되기 전에 seed 값을 고정시켜주면 됩니다. 그러면, torch.rand()를 통해 생겨나는 난수 값들이 고정됩니다.
그림10
위와 같은 방식을 통해 self.transform(data['input']), self.trasnform(data['label'])에서 augmentation 시, 발생되는 난수 값이 (by "torch.rand()") 동일해집니다. 즉, input, label 모두 동일한(일치한) augmentation을 제공해주게 됩니다.
if self.transform:
torch.manual_seed(10)
data['input'] = self.transform(data['input'])
if self.transform:
torch.manual_seed(10)
data['label'] = self.transform(data['label'])
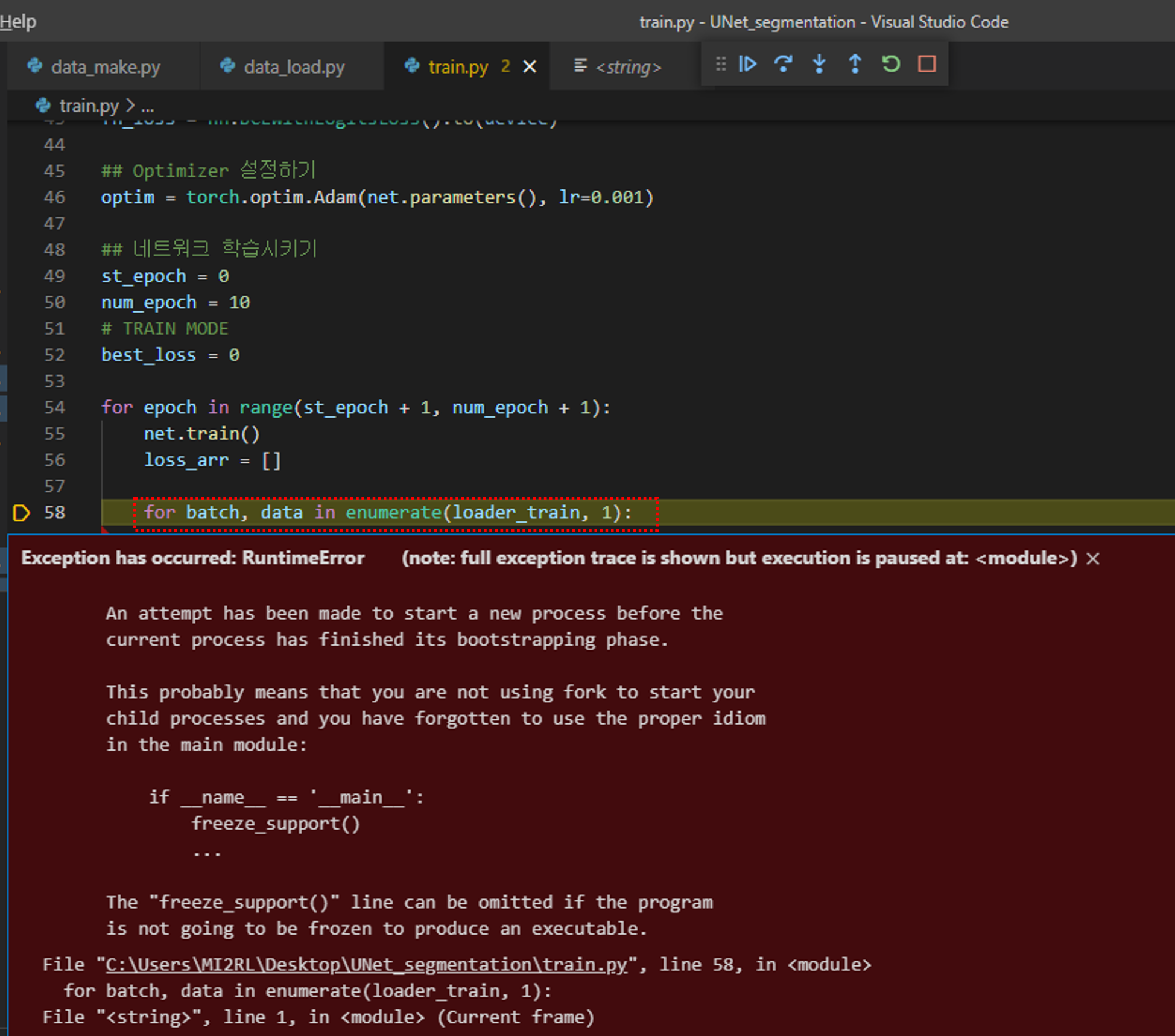
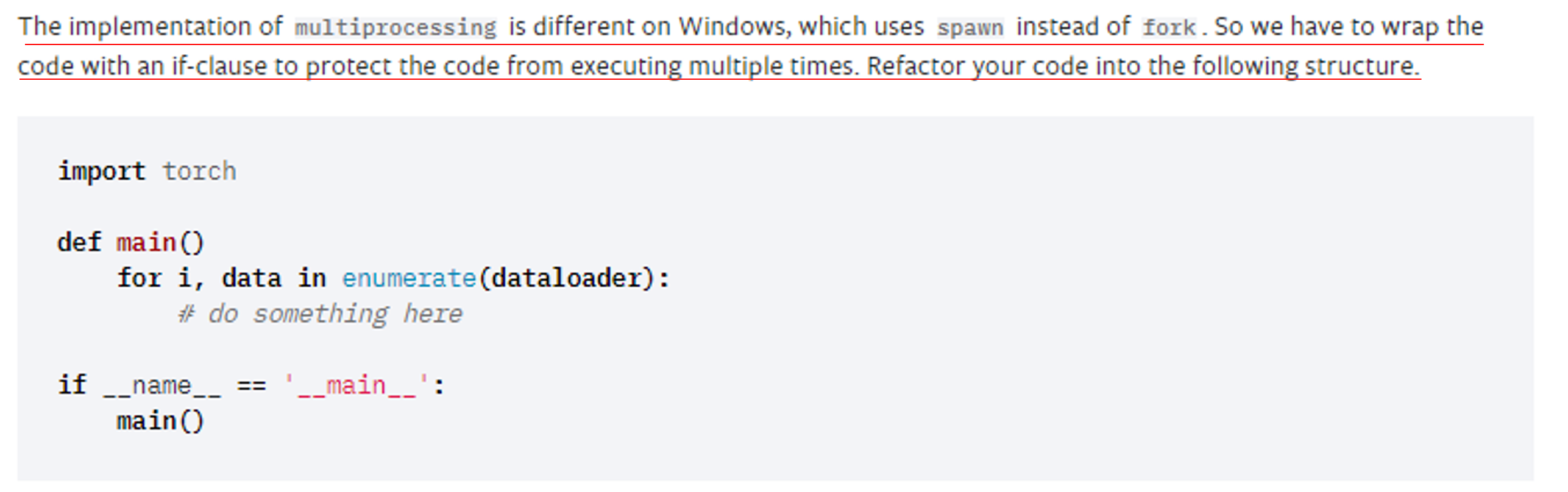
3. freeze_support() 에러
데이터 로드와 관련된 모든 준비가 완료되었습니다.
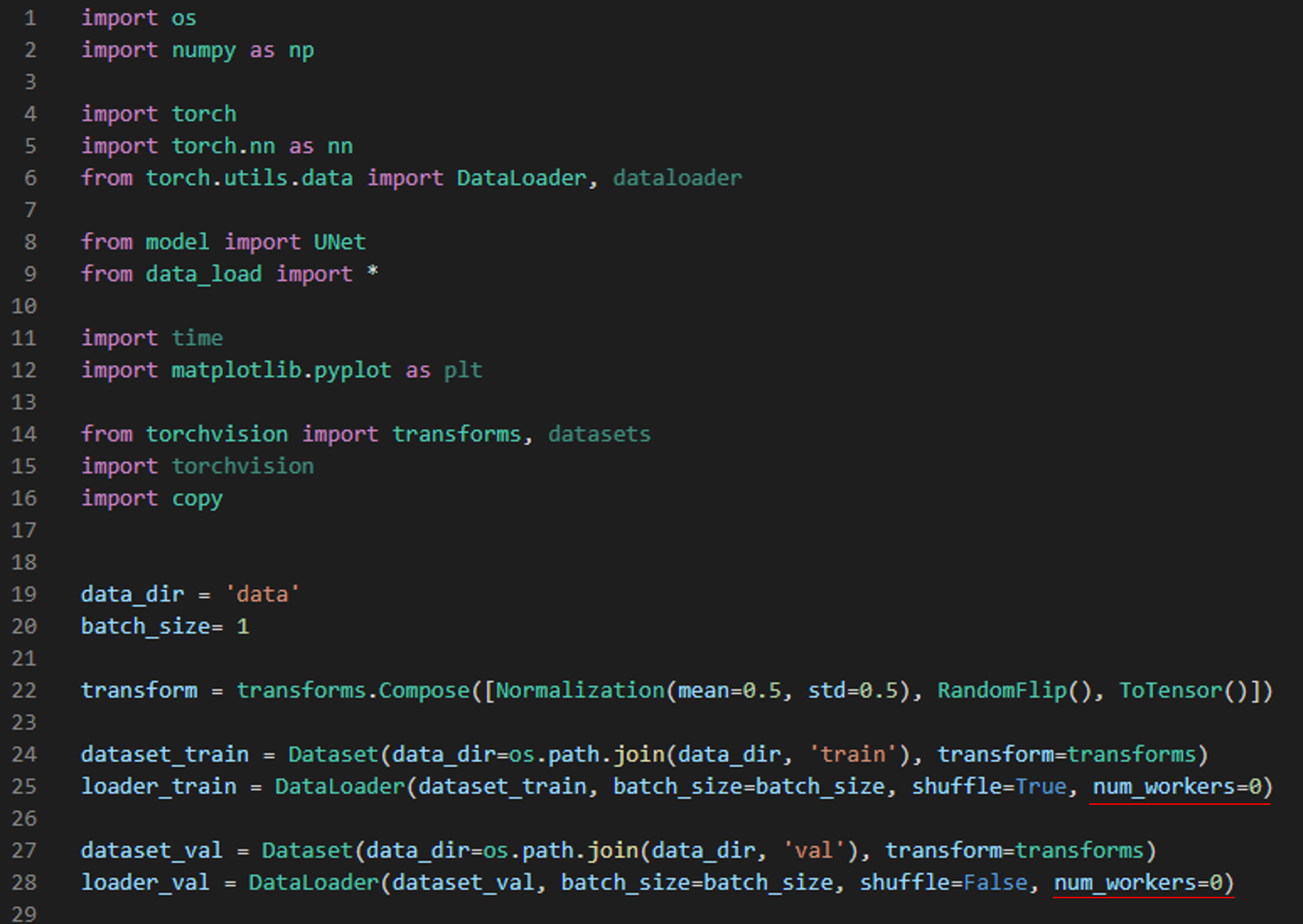
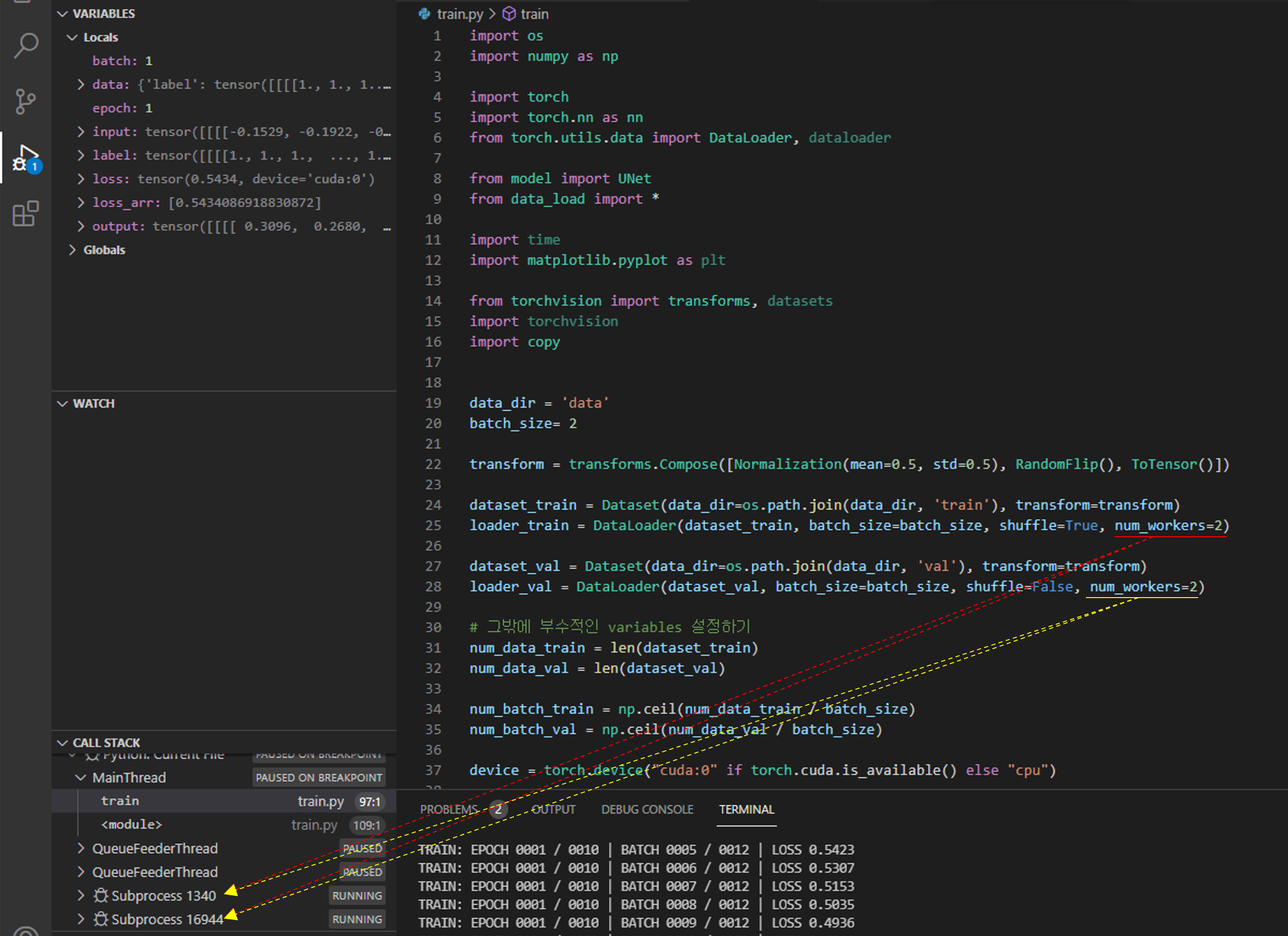
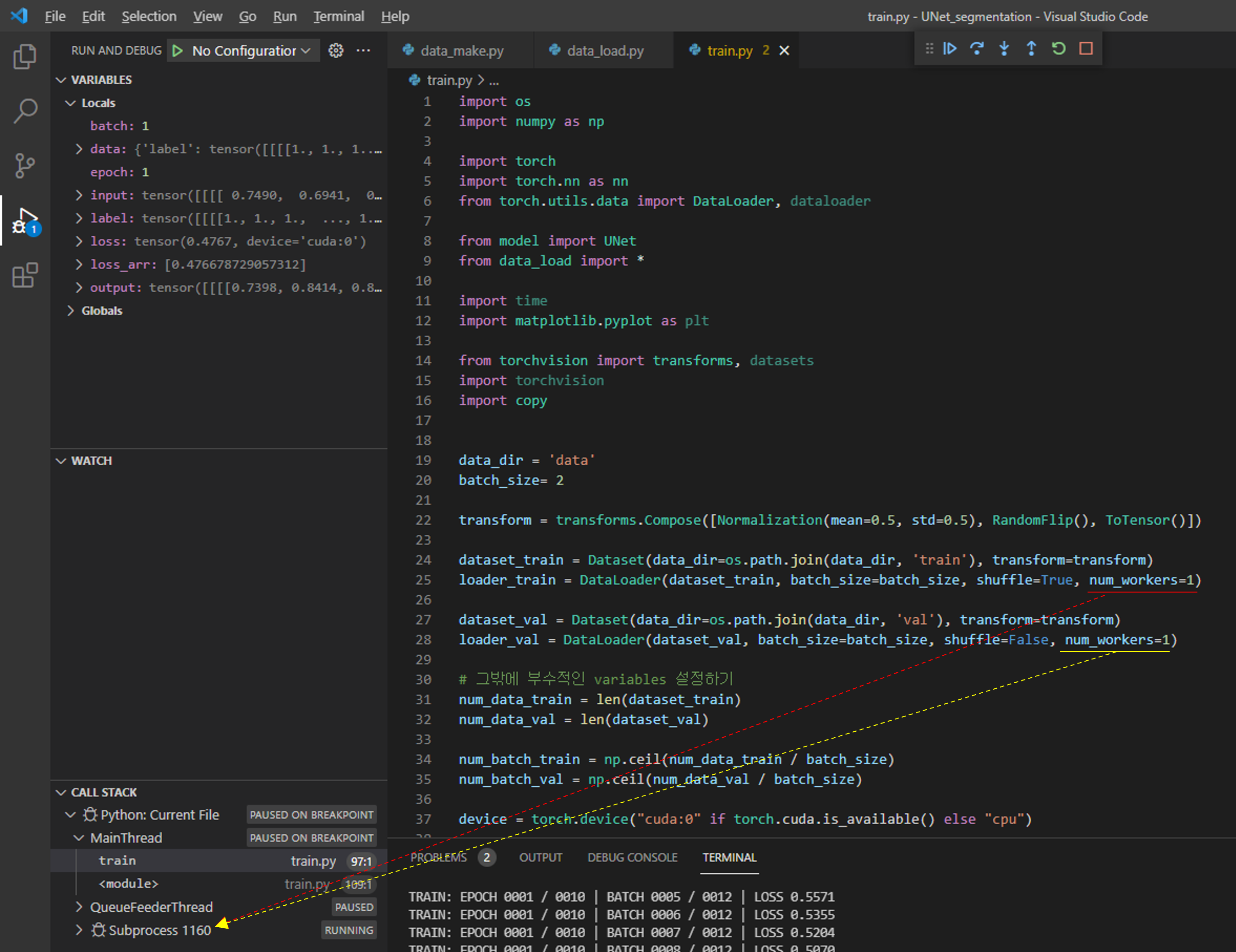
그럼 "train.py" 코드를 실행해보죠.
만약 앞서 제가 설명드린 코드가 아닌 유튜브 강의에서 설명한 코드로 실행했을 때 리눅스에서 실행하셨다면 큰 문제없이 실행됐겠지만, 만약 윈도우에서 실행시키셨다면 아래와 같은 에러 메시지를 만나실 수 있습니다.
num_workers는 GPU에 학습 이미지를 업로드하기 위해서 사용되는 CPU의 process 개수입니다.
쉽게 말해 GPU 학습 이미지를 업로드 하기 위해서는 결국 CPU가 중간 다리 역할을 해줘야 하는데, 이때 num_workers를 크게 설정해주면 GPU에 학습 이미지를 업로드하는데 관여하는 process도 많아지겠죠. 이렇게 되면 결국 학습 이미지 업로드 속도도 빨라질겁니다.
1. 데이터 다운받기 (Feat. ISBI 2012 EM segmentation Challenge)
보통 segmentation을 하기 위한 public 데이터들은 Kaggle, MICCAI 같은 곳에서 열리는 segmentation challenge에서 구할 수 있습니다. 또는 과거에 진행되었거나 현재에 진행되는 다른 segmentation challenge에서도 구할 수 있습니다.
보통 유명한 데이터셋들 중에 크기가 작은 데이터들은 github에 올려놓는 경우도 있습니다.
이번 글에서는 "ISBI 2012 EM segmentation Challenge"에서 사용되었던 membrane 데이터셋을 github에서 다운받아 사용해보려고 합니다.
방법은 간단합니다.
먼저 "ISBI 2012 github", "ISBI 2012 segmentation" 등의 키워드를 구글에 검색하시면 다양한 github 사이트가 노출이 될 겁니다.
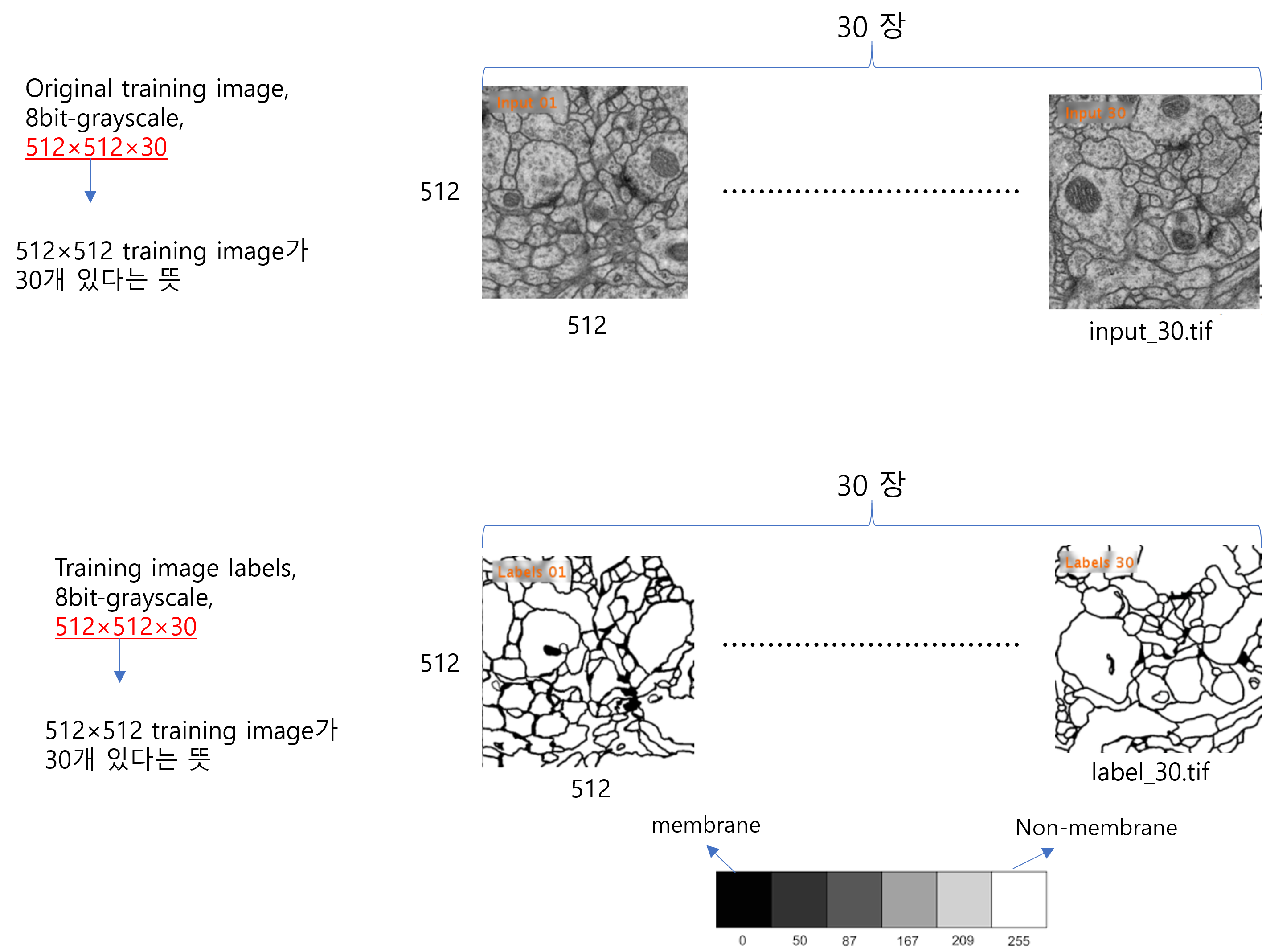
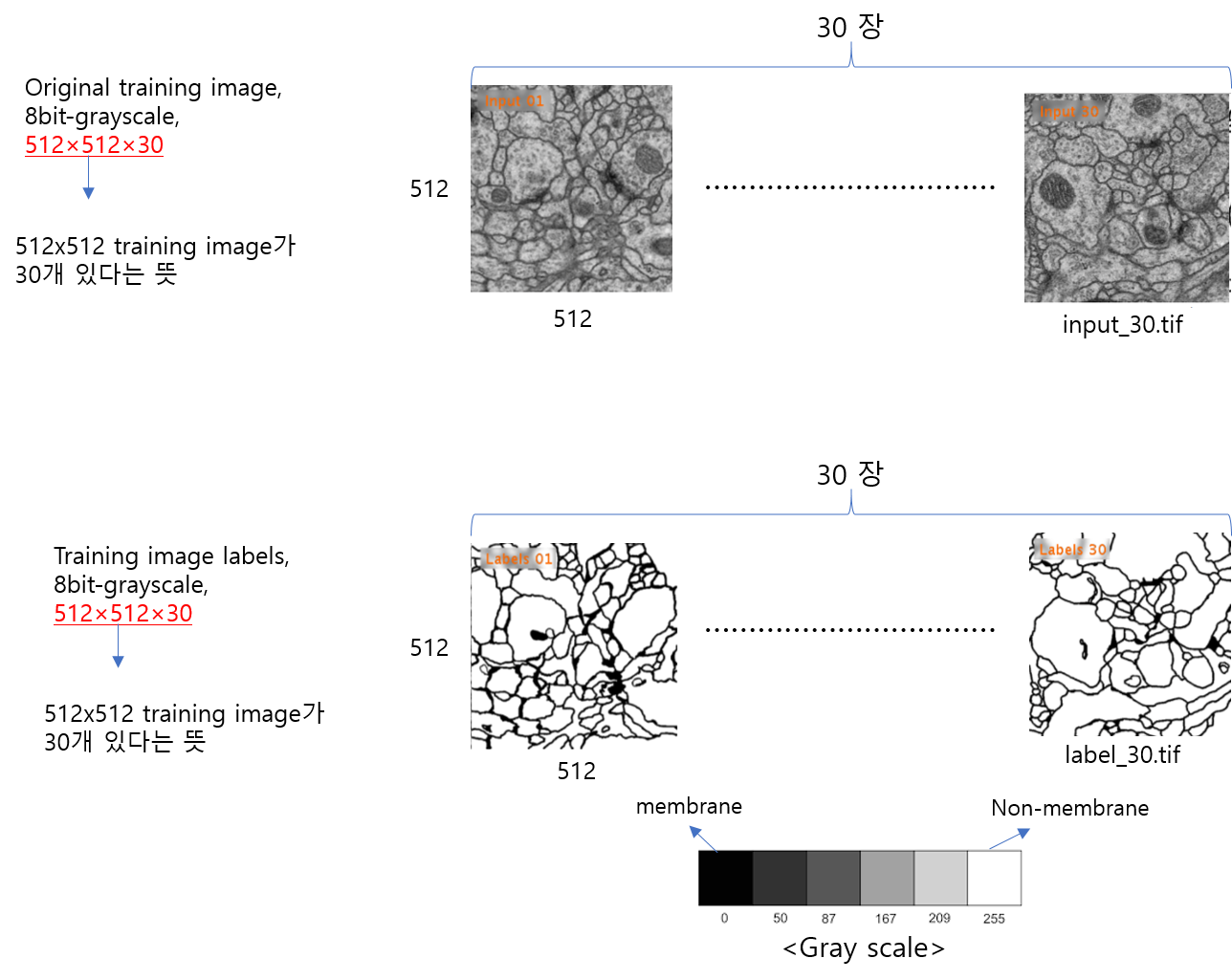
※사실 R,G,B 이미지였다면 (512,512,3) 형태로 저장이 되었을 것이기 때문에, 따로 numpy로 저장할 필요가 없습니다. 하지만, 현재 다루고 있는 이미지가 Gray scale을 따른다면 numpy 형태로 저장할 필요가 있습니다. (사실, gray scale 이미지도 엄격하게 표현하려면 (512,512,1)로 표현되어야 하지만, 이미지에서는 channel에 해당하는 1 부분을 생략하고 (512,512)로 표현하는 경우가 있습니다.)
※이 글에서는 slice형태로 이미지가 묶여서 나오기 때문에 지금과 같이 별개의 이미지로 분리하는 작업을 거쳤지만, 만약 이미지 데이터들이 3차원의 별도의 이미지로 제공이 될 경우는 지금까지 설명했던 코드를 구현할 필요는 없습니다.
※하지만, 의료 영상에서 다루는 CXR, CT, MRI 이미지들은 대부분 Gray scale이 많기 때문에 medical 분야에서 인공지능을 하시는 분들은 위의 코드를 잘 숙지하고 있으시면 많은 도움이 될 거라 생각합니다.
Image 모듈 reference site를 들어가 보면 첫 번째로 보이는 함수가 open()입니다.
아래 설명을 통해 보자면 open()이라는 함수는 어떤 이미지 파일을 단지 identification(확인) 하는 역할을 수행합니다.
즉, 이미지 데이터를 읽어드린 것이 아니라 단지 이미지 파일에 대한 몇 가지 (메타)정보를 확인합니다.
예를 들어, 아래와 같이 Image.open() 함수를 통해 리턴 받은 img_input 값들을 살펴보면 Image 모듈의 기본적인 attribute 값들 (=filename, size, width, height, format) 과 그 외에 현재 이미지와 관련한 다양한 정보들을 포함하고 있다는걸 확인할 수 있습니다.
(↓↓↓ Image 모듈의 다양한 attribute들 ↓↓↓)
image 모듈은 굉장히 다양한 image file format을 지원합니다. 아래 링크에 접속하면 지원가능한 format 형식들이 나옵니다.
"The open() function identifies files from their contents. When an image is opened from a file, only that instance of the image is considered to have the format."
즉, 리턴 받은 값에서 다시 Image 모듈의 function, attribute를 사용할 수 있다는 뜻입니다.
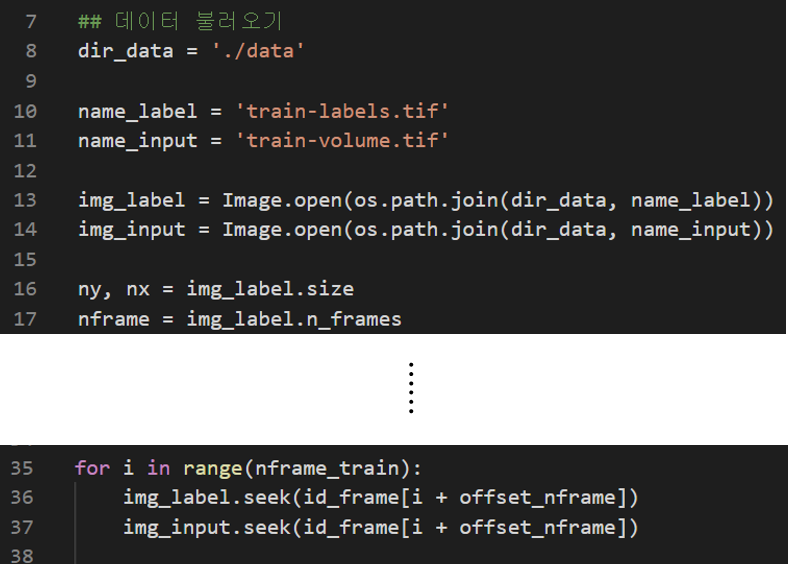
예를 들어, 아래 코드와 같이 Image.open()를 통해 Image 객체를 리턴 받은 img_input가 Image 모듈의 함수 중 하나인 seek() 을 이용할 수 있다는걸 확인 할 수 있습니다.
Image.open() 함수의 parameter 부분에 "fp" 설명을 보면 마지막 부분에 "the file object must implement "read()", "seek()", "tell()"같은 함수를 사용해야 실제로 이미지 데이터를 load할 수 있다고 합니다. (이 부분은 뒤에서 "file.seek" 함수 를 설명할 때 더 자세히 하도록 하겠습니다)
2-2. Image.seek()
앞서 실제 이미지 데이터를 load 하는 함수에는 세 가지가 있다고 언급했습니다.
read()
seek()
tell()
보통은 read() 함수를 많이 사용하지만 가끔씩 이미지들이 frame 단위로 묶여있는 경우 seek() 함수를 이용해 이미지를 읽어들입니다.
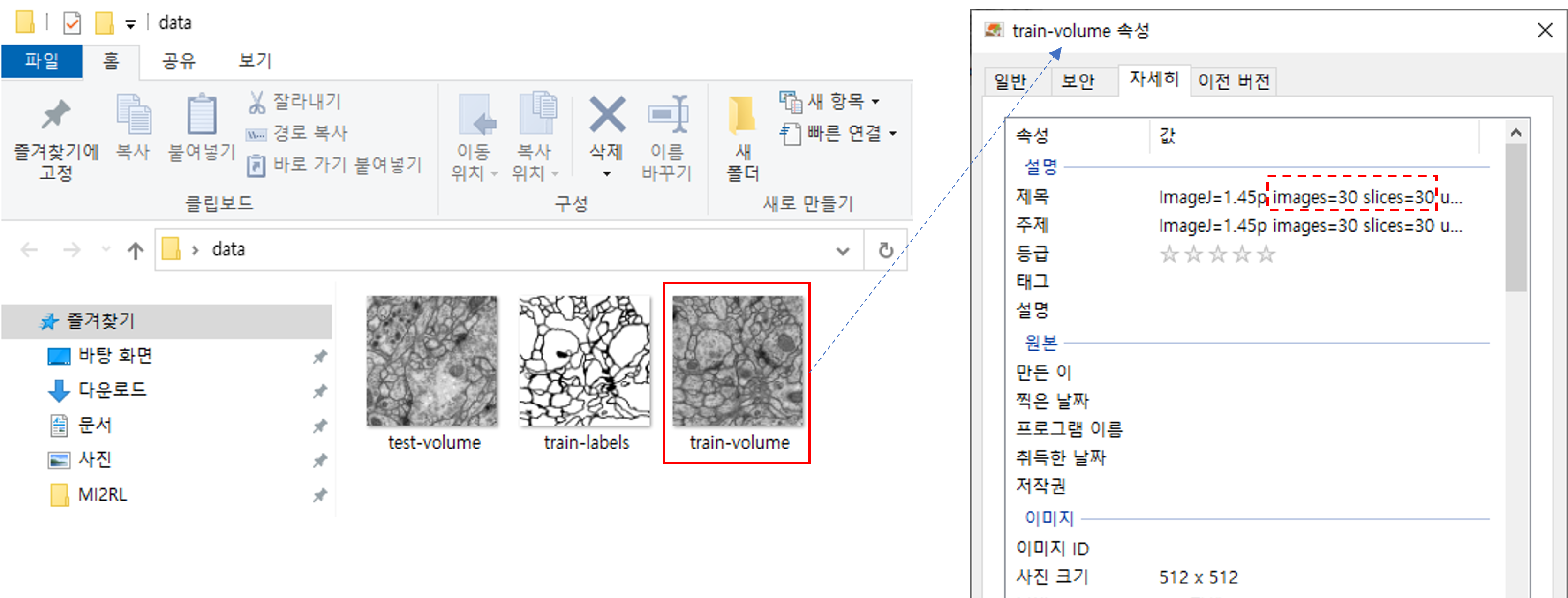
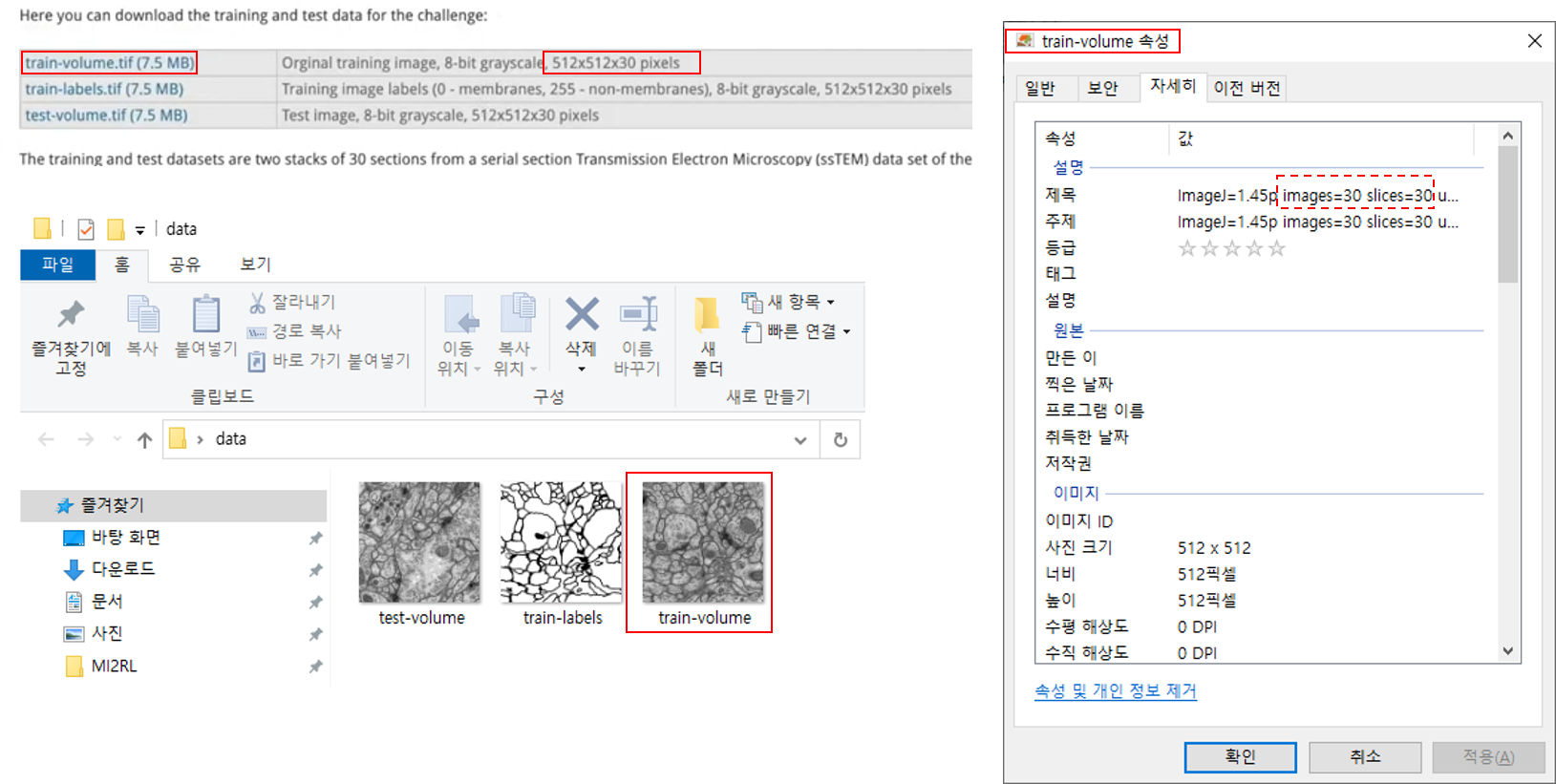
예를 들어, 아래 train-labels 이미지 정보를 보면 512×512×30 형태로 제공된 것을 볼 수 있습니다.
512×512×30에서 30이 의미하는 바는 특정 이미지 frame을 의미합니다. 예를 들어, (512, 512, 1) 값들은 첫 번째 이미지frame을 뜻하고, (512, 512, 2) 값들은 두 번 째 이미지 frame을 뜻합니다.
그래서 위와 같은 이미지 형태를 읽어들일 때는 frame 단위로 이미지를 읽어야 하는 경우가 있습니다.이러한 경우는 seek 이라는 함수를 이용합니다.
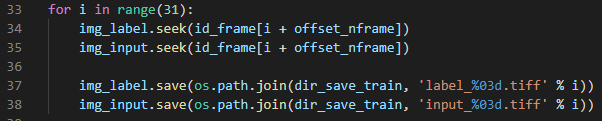
for문과 seek() 함수를 통해 frame 별 이미지들을 하나씩 따로 불러올 수 있습니다.
이렇게 불러온 binary mode 이미지를 0~255 값으로, 즉 사람이 읽을 수 있는 값으로 변형 시키려면 numpy 패키지에서 제공해주는 함수를 이용하면 됩니다. 아래 코드에서는 numpy.asarray() 함수를 이용했네요.
굳이 위와 같이 numpy로 변경 시켜줄 필요 없이, tiff 이미지만 저장시키고 싶은 경우는 아래와 같이 코드를 작성해주면 됩니다.
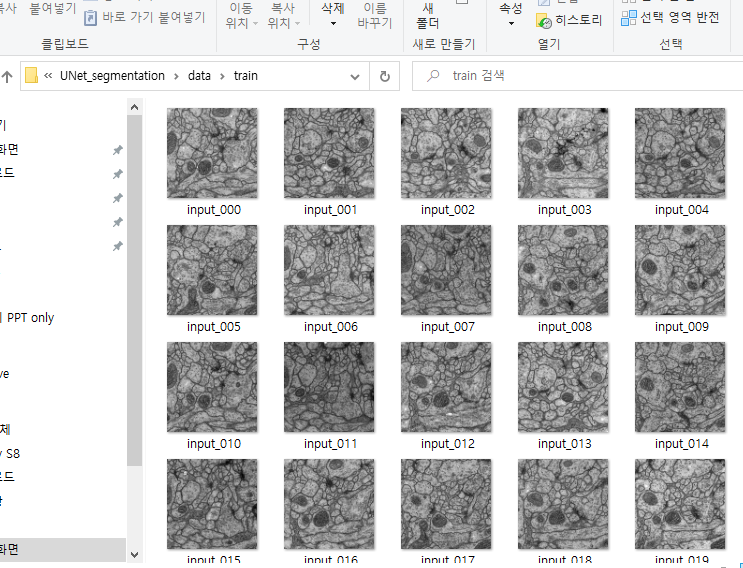
그럼 아래와 같이 이미지가 frame 별로 따로 'tiff' 형식으로 저장되는걸 확인하실 수 있습니다.
지금까지 Image 모듈에 대한 설명과 기본적인 함수인 Image.open(), Image.seek() 에 대해서 알아보았습니다.
PIL는 Python Imaging Libarary의 약자로, 파이썬으로 이미지를 다룰 때 유용한 기능들을 제공하는 라이브러리 였습니다.
"PIL is the Python Imaging Library by Fredrik Lundh and Contributors."
파이썬에서 setuptools이란 python 라이브러리 를 확장 및 배포하는데 사용되는 extension libarary인데, 이러한 setuptools을 이용하여 프로젝트 빌드, 배포를 쉽게 관리할 수 있게 도와줍니다. 하지만, PIL는 "not setuptools compatible" 하다고 알려져 있었기 때문에 이를 개선하고자 PIL를 fork하여 Pillow라는 프로젝트를 실행하게 됩니다. (파이썬에 이미지를 다루는 또 다른 패키지로는 openCV가 있습니다)
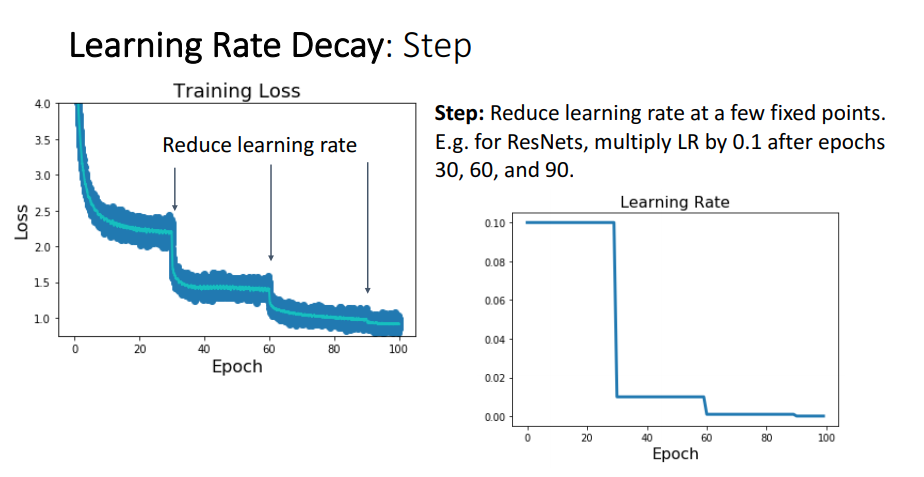
초기에는 layer 값들이 굉장히 불안정하기 때문에 너무 큰 learning rate을 적용하면 loss값이 지나치게 커질 수 있습니다. 그래서 초기의 unstable 상태를 고려해 초기 특정 epoch 까지는 learning rate을 천천히 증가시켜주는 방식이 warm_up 방식입니다.
Warm_up을 통해 특정 epoch 까지 learning rate을 증가시키면, 특정 epoch 이후에는 기존 learning rate policy를 적용시켜주어야 합니다.
아래 그림을 보면 초기 5 epoch 까지는 learning rate을 점진적으로 증가시키고, 5 epoch 이후에는 step policy 또는 cosine annealing policy 확인할 수 있습니다.
그림14
Warm_up policy는 pytorch에서 기본 learning rate policy로 제공해주고 있지 않기 때문에 따로 warm_up laerning rate policy 패키지를 설치해야합니다.
3-1) Warm_up policy with step learning rate policy
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 3 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=3, gamma=0.1)
exp_lr_scheduler = GradualWarmupScheduler(optimizer_ft, multiplier=1, total_epoch=5, after_scheduler=exp_lr_scheduler)
그림15
3-2) Warm_up policy with cosine annealing learning rate policy
3-2-1) warm_up consine annealing learning rate과 관련된 사이트 검색
from cosine_annealing_warmup import CosineAnnealingWarmupRestarts
criterion = nn.CrossEntropyLoss()
optimizer_ft = optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=1e-5) # lr is min lr
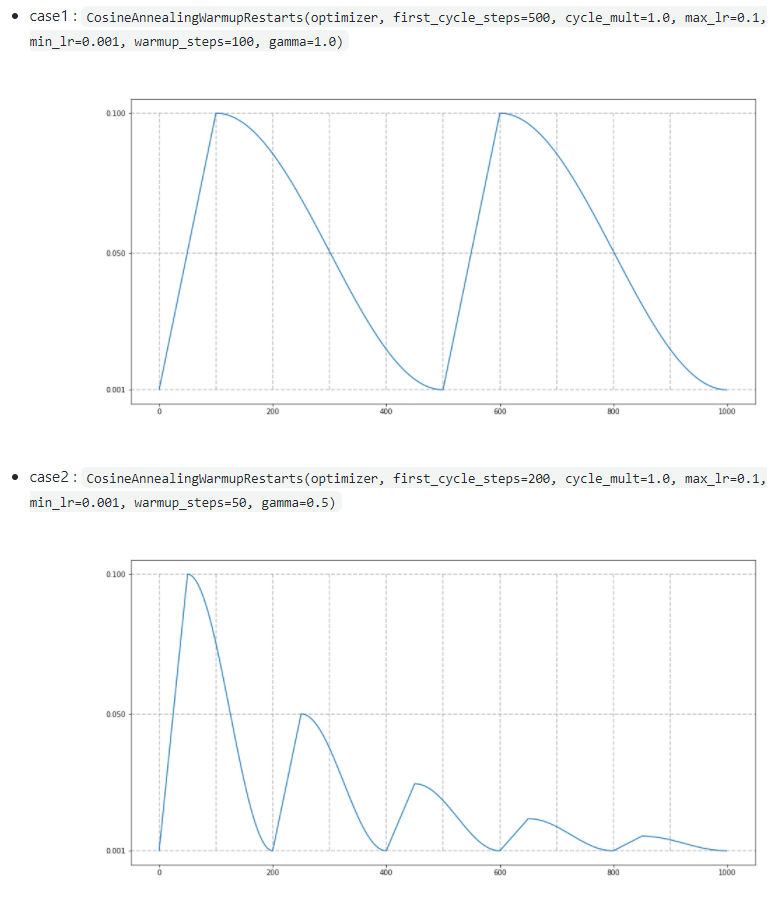
scheduler = CosineAnnealingWarmupRestarts(optimizer, first_cycle_steps=200, cycle_mult=1.0, max_lr=0.1, min_lr=0.001, warmup_steps=50, gamma=1.0)
그림16
Cosine annealing with warm_up 과 관련된 hyper parameter들은 아래 그림을 보면 이해하시기 편하실 겁니다. (참고로 gamma부분은 다음 cycle에서 max_lr을 어느 정도 줄여줄지를 결정해주는 hyper parameter 입니다)
그림17
Warm_up을 적용시킬 때 batch size에 따라 initial learning rate(=마지막 warm up 단계에서의 learning rate)를 어떻게 설정해 줄 지 결정해 주기도 합니다. 이 부분은 아래 글에서 learning rate warmup 부분을 참고해주시면 될 것 같습니다.
# Data augmentation and normalization for training
# Just normalization for validation
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = 'data/hymenoptera_data'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
추가적으로 batch 단위로 augmentation이 적용된 이미지 데이터들을 아래 함수로 확인해볼 수 있었습니다.
def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# Get a batch of training data
inputs, classes = next(iter(dataloaders['train']))
# Make a grid from batch
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])
model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
# Here the size of each output sample is set to 2.
# Alternatively, it can be generalized to nn.Linear(num_ftrs, len(class_names)).
model_ft.fc = nn.Linear(num_ftrs, 2)
model_ft = model_ft.to(device)
4-5. Loss function, Optimizer, Learning rate policy (← 현재 글)
이번 글에서는 딥러닝 모델이 학습할 방향성에 대해서 정리했고, 관련 코드는 아래와 같습니다.
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
5. 코드 정리
지금까지 배운 내용을 코드로 정리하면 아래와 같습니다.
# License: BSD
# Author: Sasank Chilamkurthy
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
from warmup_scheduler import GradualWarmupScheduler
plt.ion() # interactive mode
# Data augmentation and normalization for training
# Just normalization for validation
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = 'data/hymenoptera_data'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# Get a batch of training data
inputs, classes = next(iter(dataloaders['train']))
# Make a grid from batch
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])
model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
# Here the size of each output sample is set to 2.
# Alternatively, it can be generalized to nn.Linear(num_ftrs, len(class_names)).
model_ft.fc = nn.Linear(num_ftrs, 2)
model_ft = model_ft.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 3 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=3, gamma=0.1)
exp_lr_scheduler = GradualWarmupScheduler(optimizer_ft, multiplier=1, total_epoch=5, after_scheduler=exp_lr_scheduler)
6. 다음 글에서 배울 내용
지금까지 딥러닝 학습을 위한 모든 준비를 끝냈습니다.
그렇다면 딥러닝이 실제로 어떤 단계(code)를 통해 학습하는지 알아봐야겠죠?
이 부분에 대한 내용은 train_model이라는 함수를 통해 실행이 되는데 이 부분은 다음 글에서 살펴보도록 하겠습니다.
이번 글에서는 transfer learning을 pytorch로 적용하는 방법에 대해서 알아보도록 하겠습니다.
CNN 모델을 training하는 방식에는 2가지가 있습니다.
Scratch training (learning)
자신의 데이터 셋을 기반으로 CNN 모델을 구현하여 학습시키는 방법
Scratch training을 하려는 경우에는 지난 글("3.CNN 구현")에서 설명한 방식대로 CNN 모델을 구현하고 자신의 데이터셋을 학습시키면 됩니다.
Transfer learning (← 이번 글에서 설명)
ImageNet과 같은 데이터셋으로 학습시킨 CNN 모델을 pre-train 모델이라고 합니다.
Transfer learning은 이러한 pre-train 모델을 이용합니다.
Pre-trained 모델은 FC layer의 마지막 뉴런 수(=ImageNet 클래스 개수)가 1000 입니다. 그래서, 나의 task가 3개의 class를 분류해야하는 것이라면 FC layer의 마지막 뉴런 수가 3개인 FC layer로 교체해줘야 합니다. (← 자세한 설명은 뒤에서)
그림1. 이미지 출처: https://www.pyimagesearch.com/2019/06/03/fine-tuning-with-keras-and-deep-learning/
그럼 지금부터 transfer learning 적용을 위한 아래 코드들을 하나씩 설명해보도록 하겠습니다.
그림2
1. Pre-trained model 다운받기
from torchvision import models
그림3
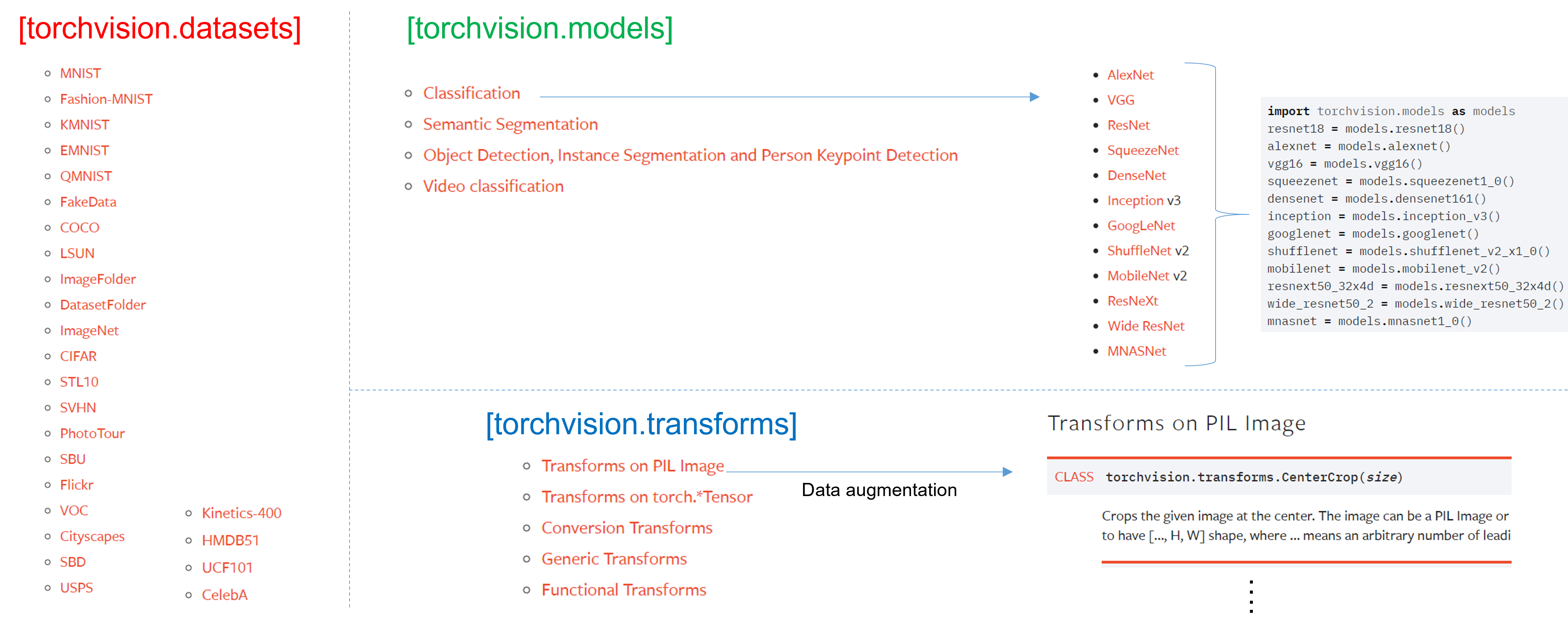
앞선 글("1.Data Load(Feat. CUDA)")에서 torchvision이 크게 3가지 기능을 제공한다고 언급했고, 이 중 2가지인 transforms와 datasets에 대해서 설명드린바 있습니다.
그림4
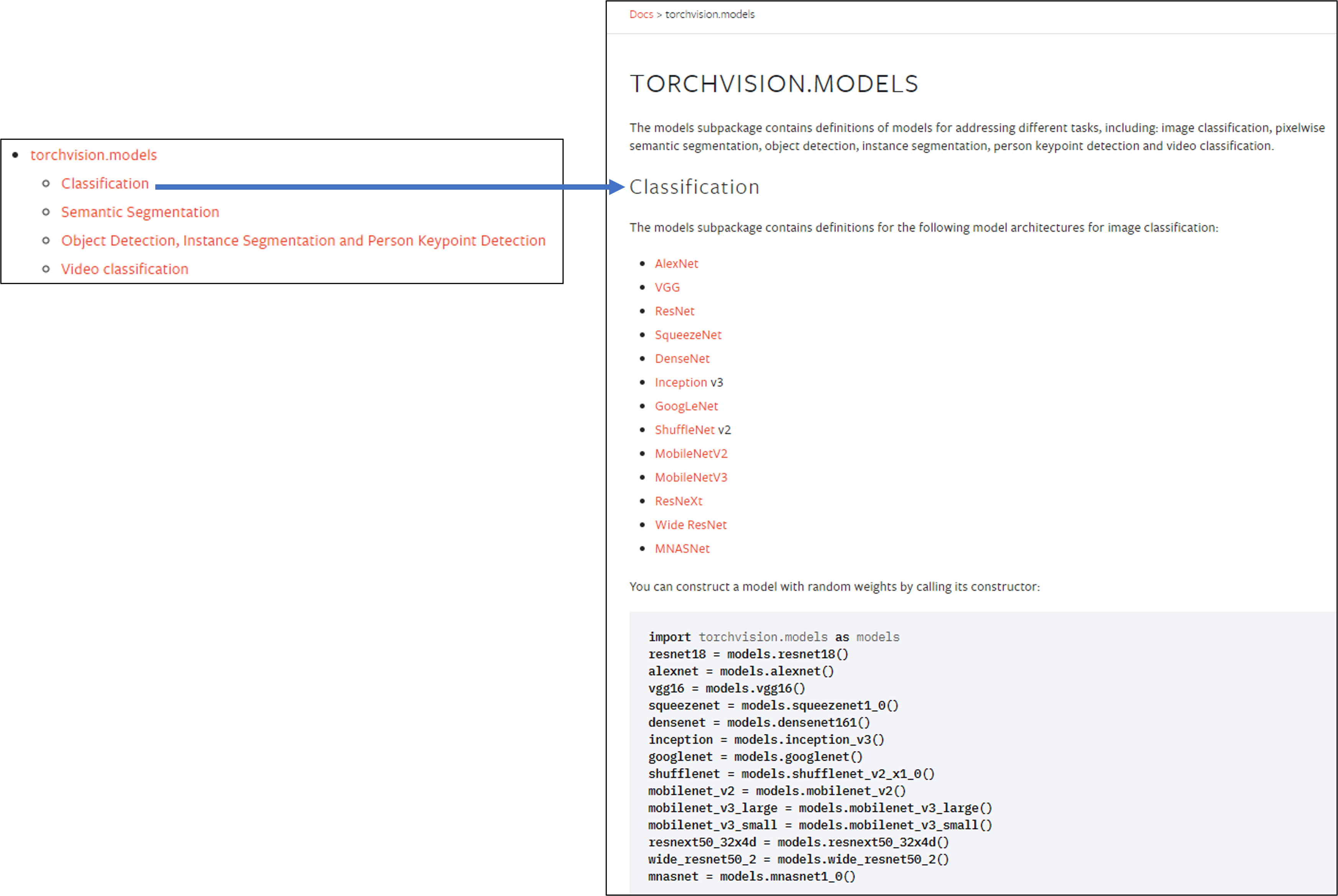
이번 글에서는 torchvision의 또 다른 기능인 models에 대해 설명드리도록 하겠습니다.
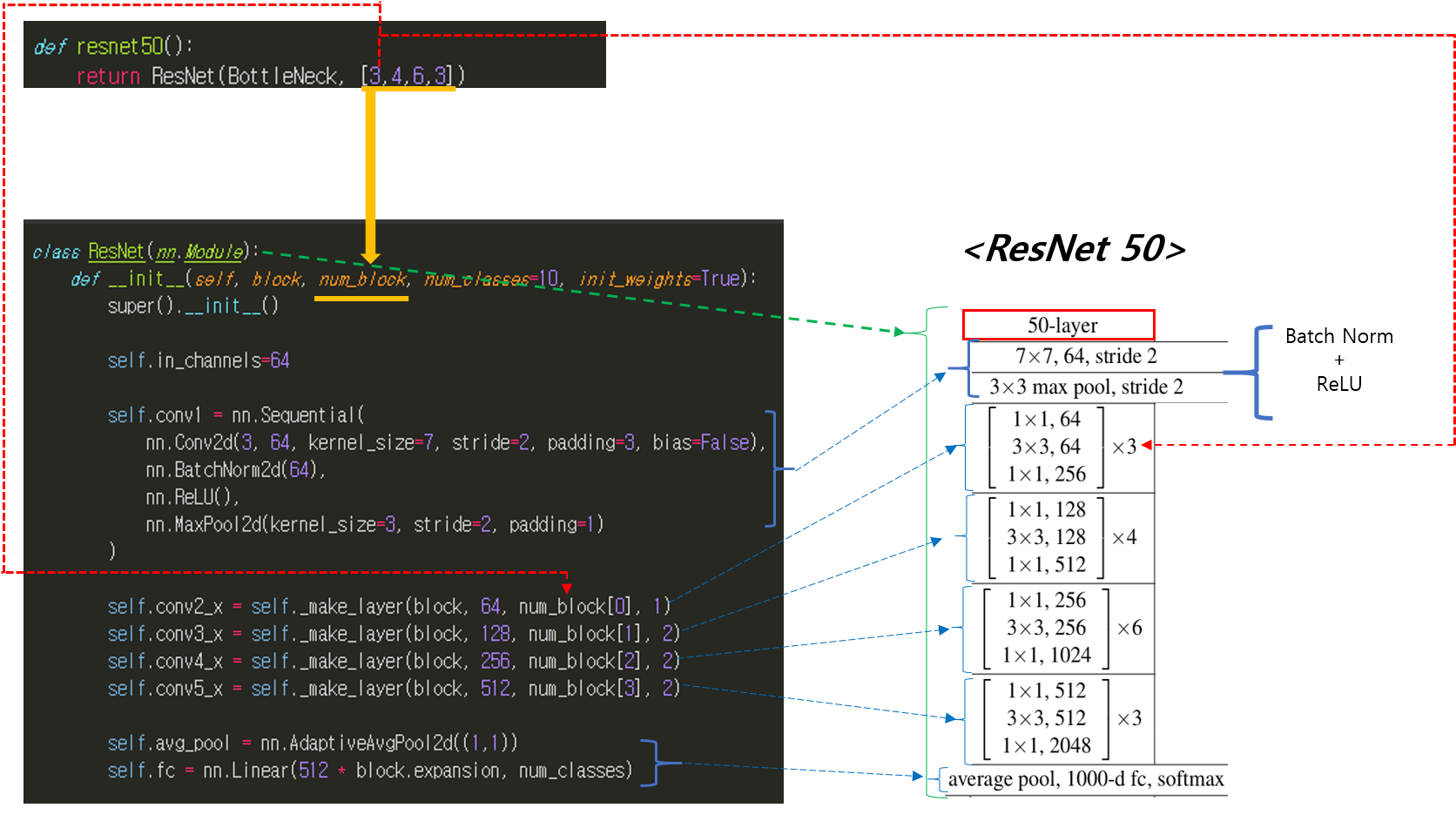
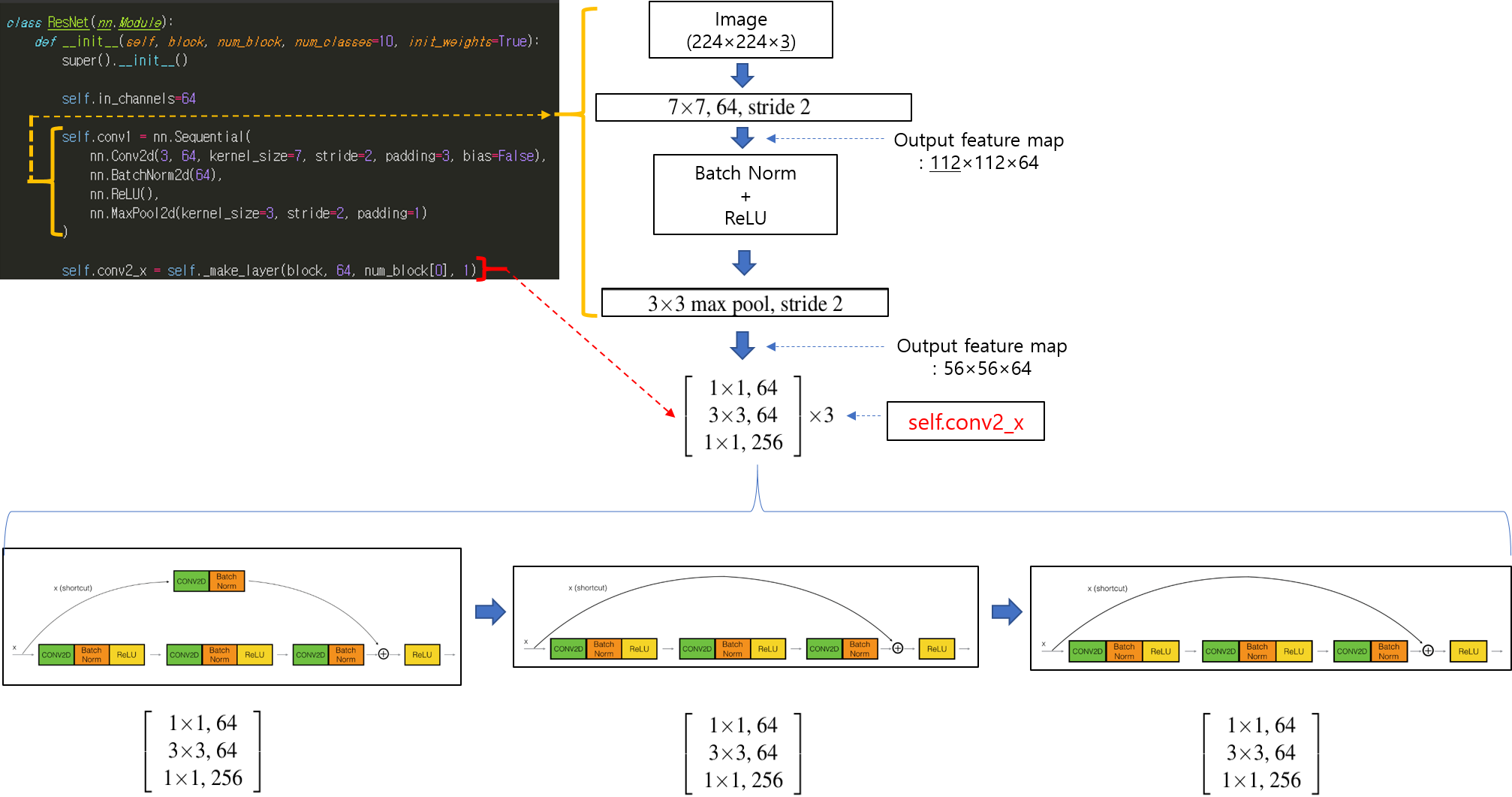
torchvision.models 패키지는 다양한 이미지 task 분야 (ex: classification, dobject detection, segmentation, etc)의 pre-trained 모델을 제공해주고 있습니다.
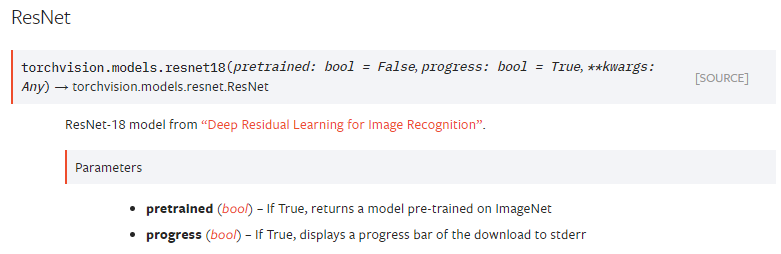
아래 parameters를 보면 알 수 있듯이 pre-trained model은 ImageNet을 기반으로 하고 있는걸 확인할 수 있습니다. 만약 "pretrained=False"로 설정하면 resnet18 모델만 사용할 수 있게 됩니다 (=Conv filter가 학습이 되지 않은 초기화 상태)
그림6
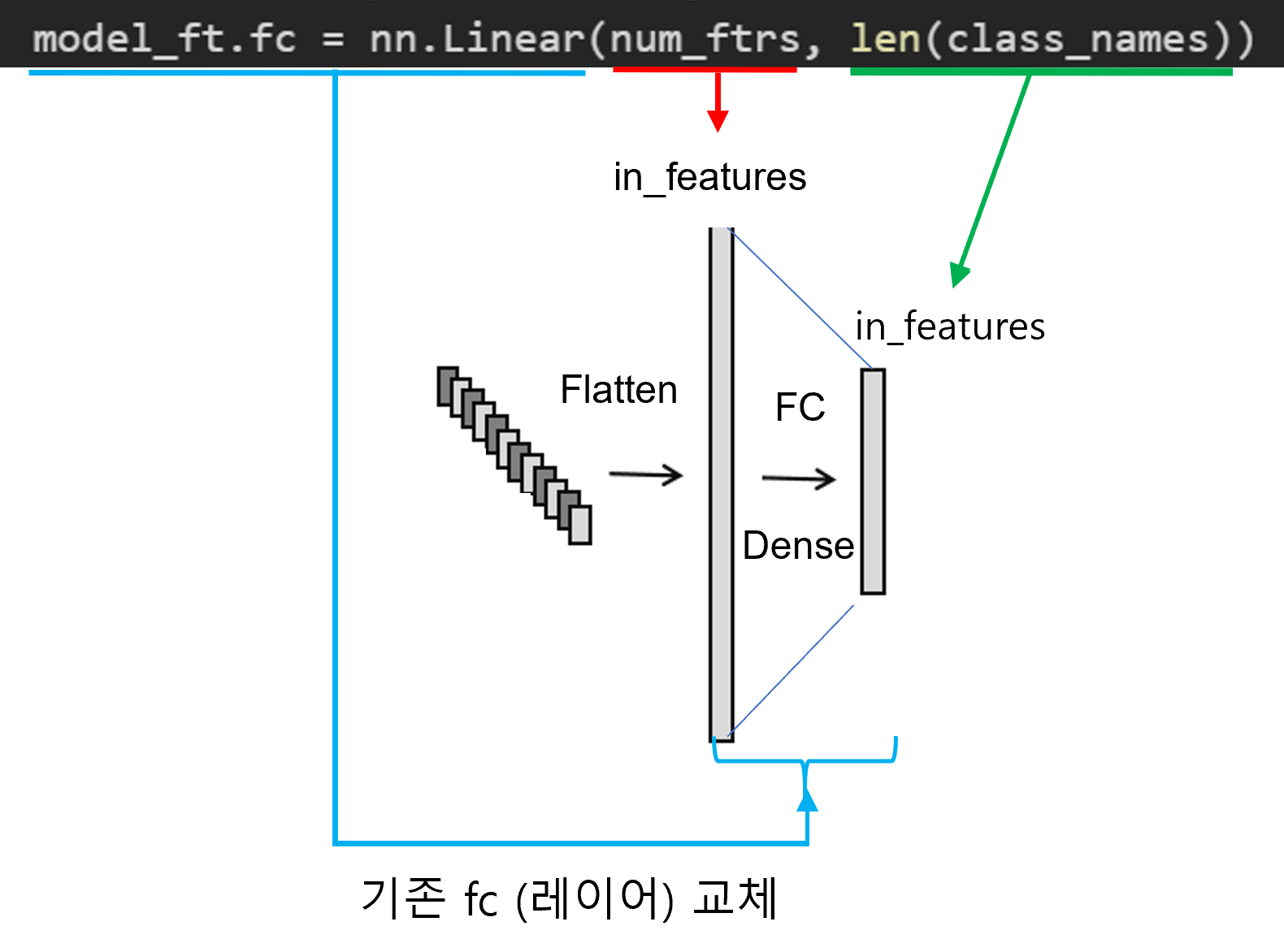
2. FC layer 수정해주기
앞서 Pre-trained model을 다운 받았으니 내가 사용할 task에 맞게 FC layer를 변경해주어야 합니다.
"1.Data Load (Feat.CUDA)" 글에서 class_names는 폴더에 있는 클래스 명들을 담고 있다고 했습니다. 만약 분류해야할 클래스가 5개이면 해당 폴더도 5가지로 구성되어 있으니, len(class_name)을 적용하면 5라는 값이 출력 될 것입니다.
그림8
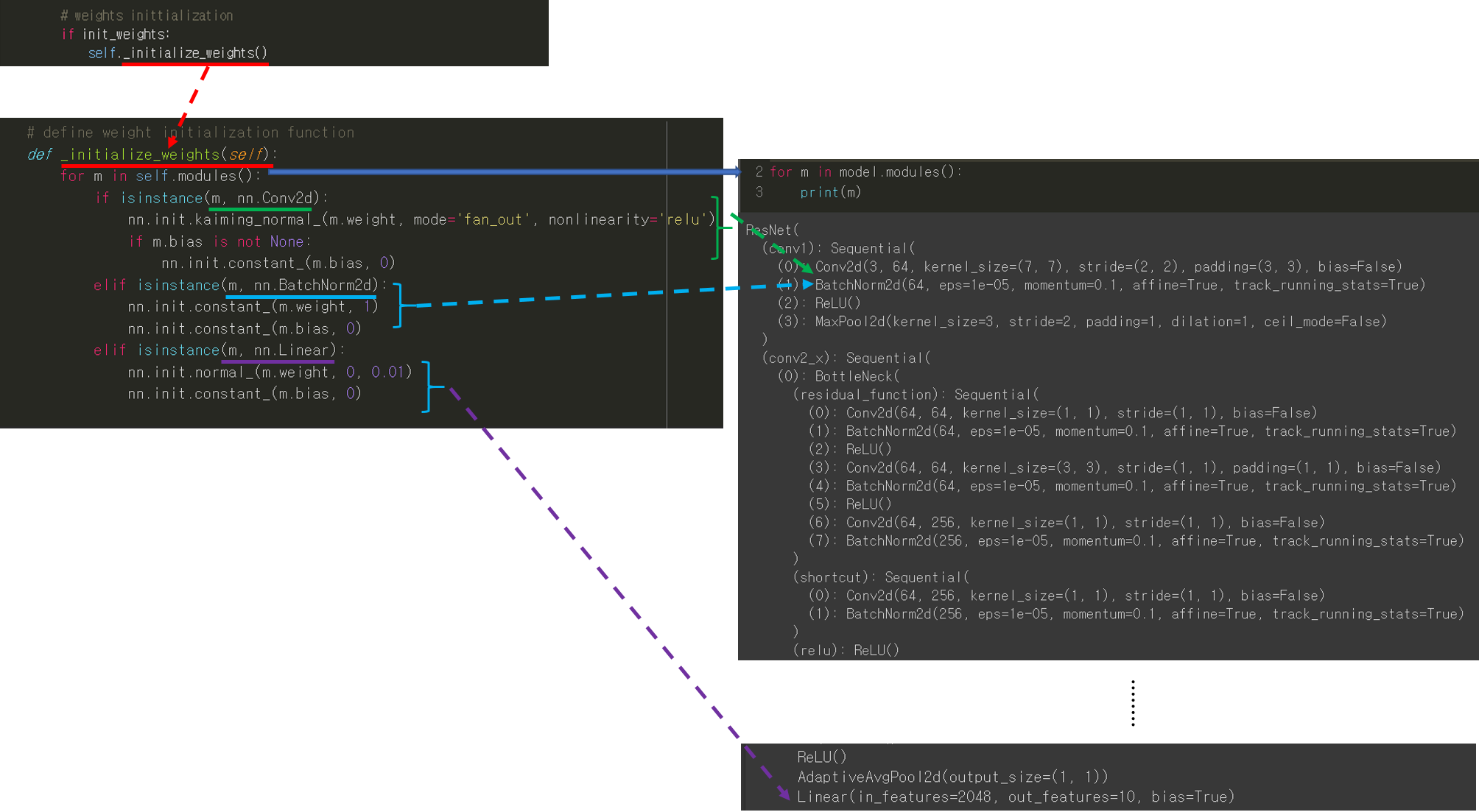
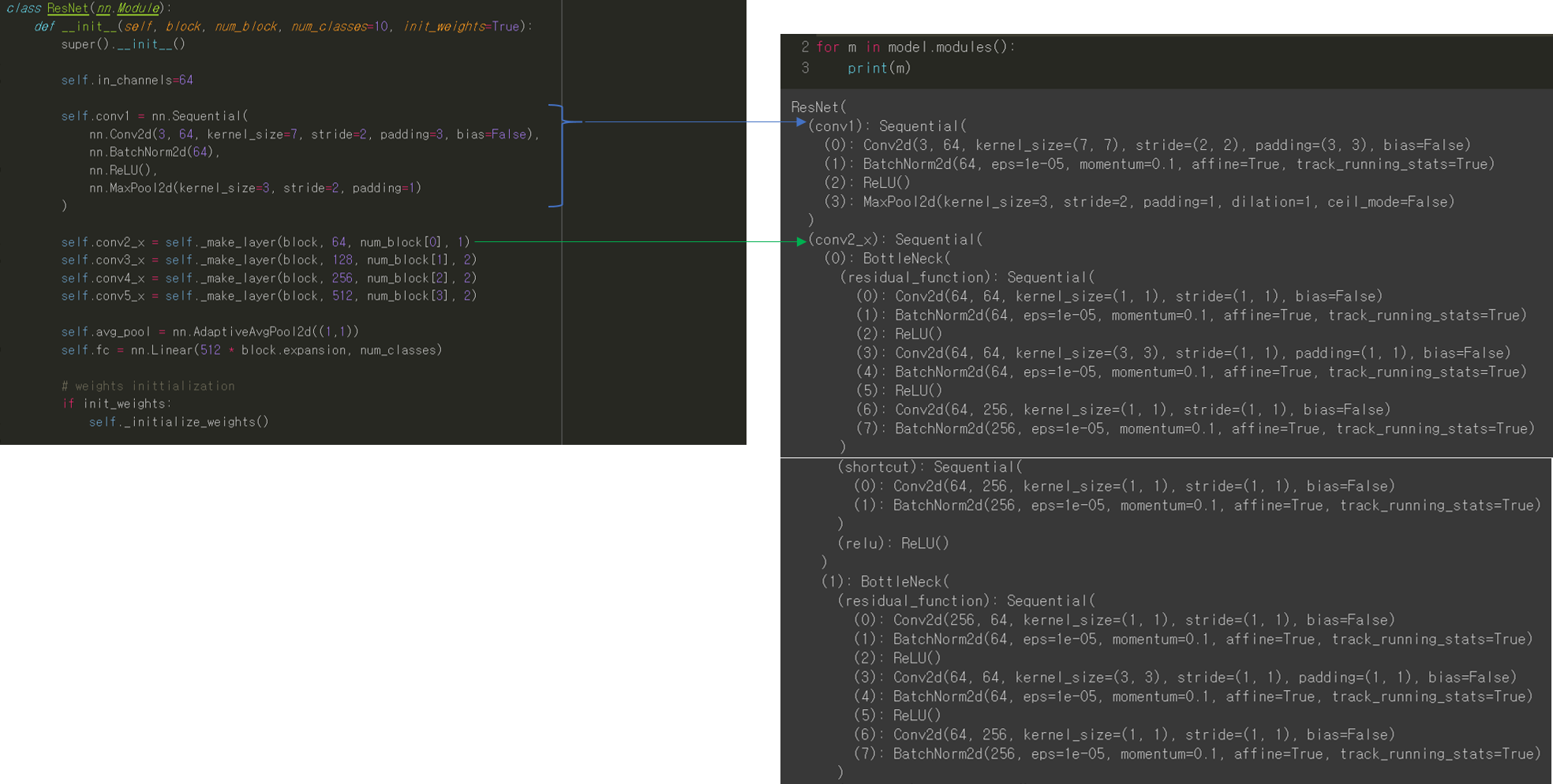
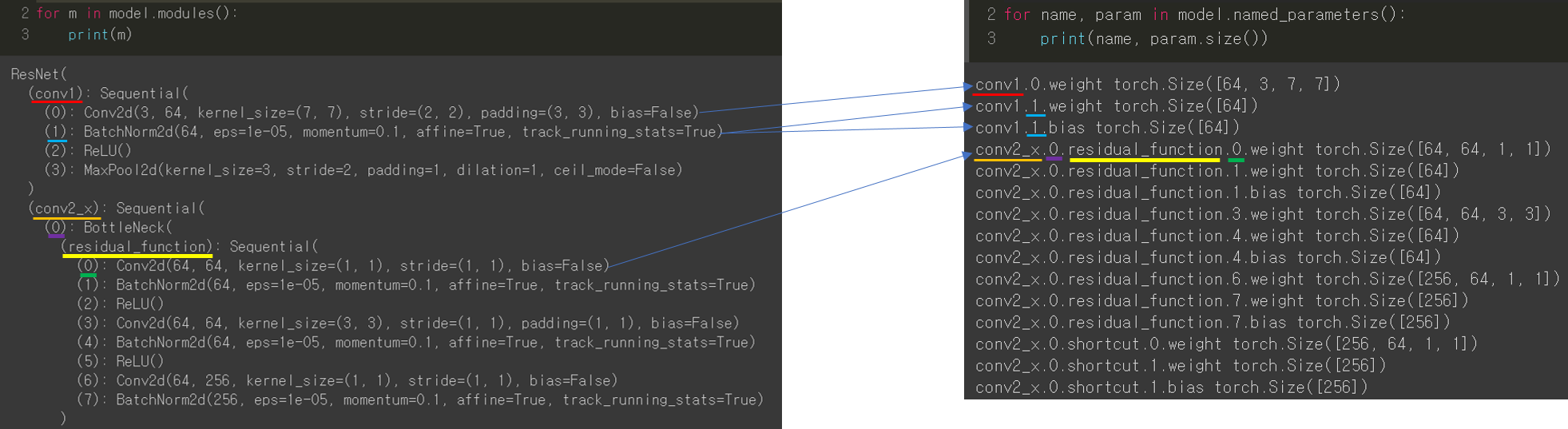
3. Fine-tuning 정도 정해주기 (Feat. freezing)
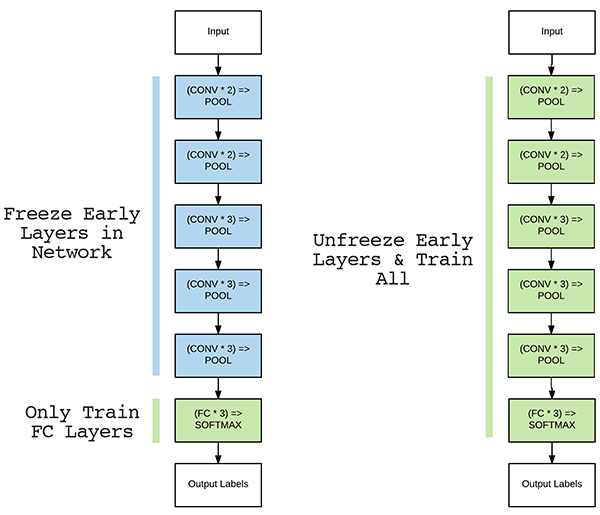
Transfer learning을 적용할 때 상황에 따라 어느 layer까지 학습 가능하게 할지 고려해주어야 합니다.
그림1. 이미지 출처: https://www.pyimagesearch.com/2019/06/03/fine-tuning-with-keras-and-deep-learning/
Freezing 정도를 pytorch에서는 어떻게 설정해주는지 글로 쓰려고 했는데, 따로 정리한 PPT에 설명이 잘되어 있어서 아래 PPT 자료로 설명을 대체하겠습니다. (파일 용량이 10MB 이상 업로드가 안돼서 디자인도 바꾸고 중간중간 슬라이드 부분도 제거해버렸네요 ㅜㅜ)
또한 특정 layer의 conv filter 또는 batch normalization의 beta, gamma 값을 초기화(initialization) 해주어야 할 때도 있습니다. 이러한 경우 어떻게 초기화 시키면 되는지 또한 PPT 자료로 정리해놨으니 참고해주시면 감사하겠습니다 (파일 용량이 10MB 이상 업로드가 안돼서 디자인도 바꾸고 중간중간 슬라이드 부분도 제거해버렸네요 ㅜㅜ)
학습하기 위해 모델 구축을 마무리 했습니다. 그럼 실제 학습을 위해 이제부터 딥러닝 model을 GPU에 올려놓도록 하겠습니다.
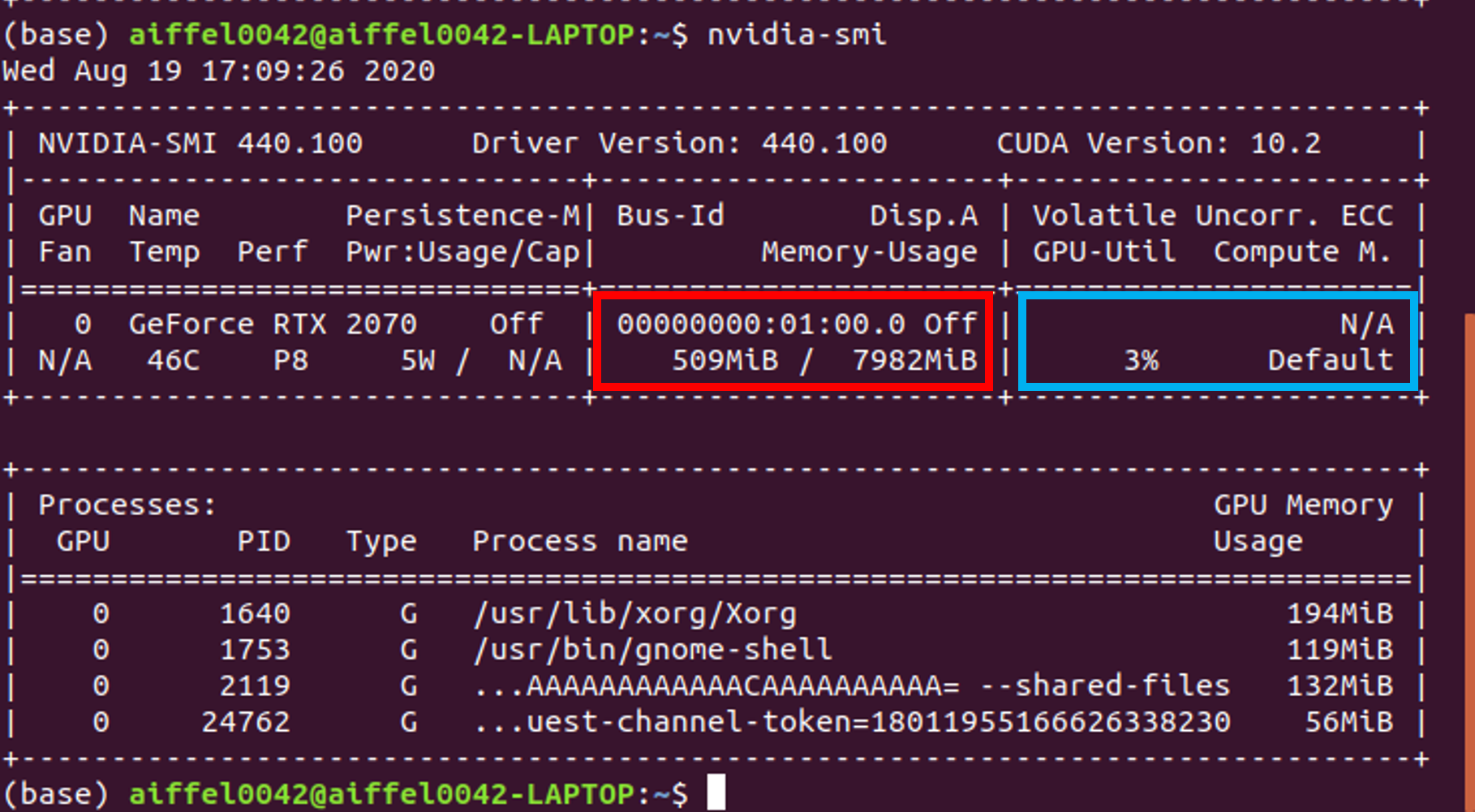
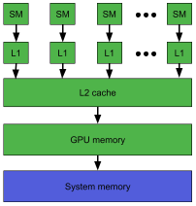
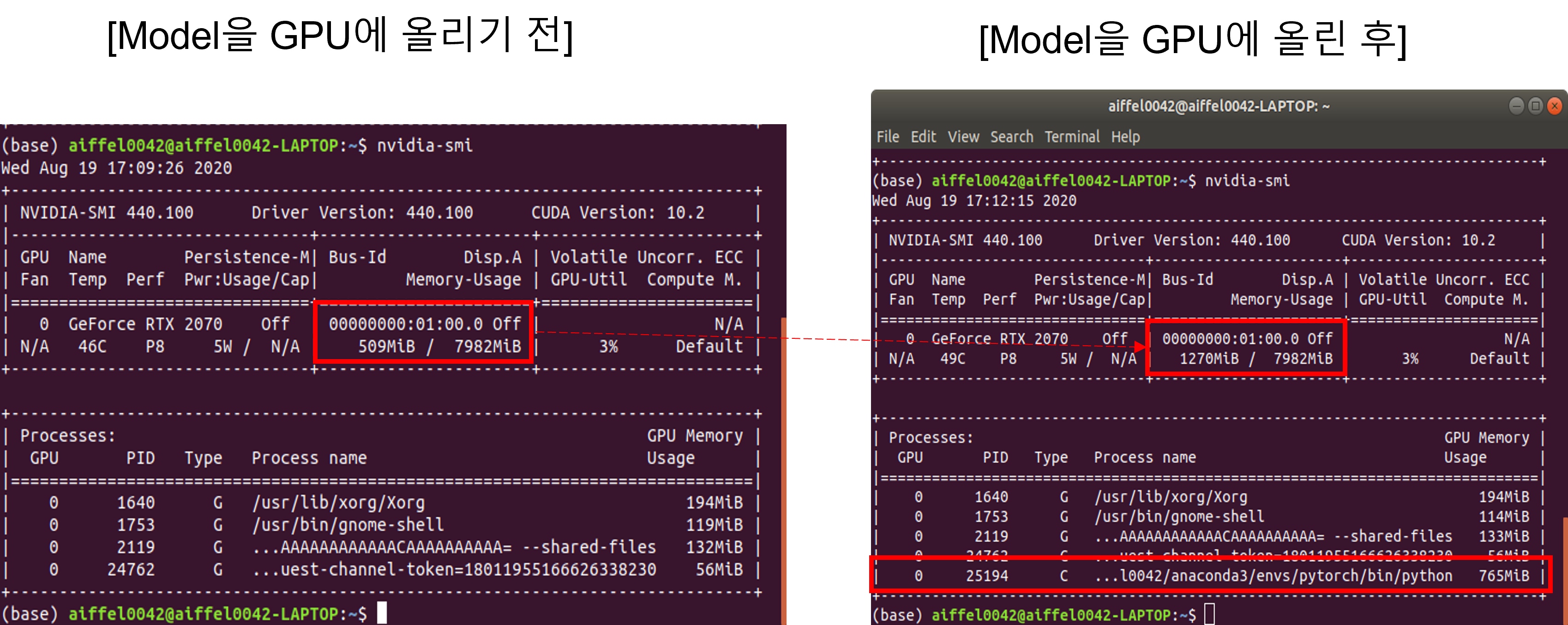
아직model을 GPU에 올리기 전상태이기 때문에,nvidia-smi를통해GPU메모리를 확인하면 대략500MiB의 메모리가 다른OS관련process를 잡고 있는걸 볼 수 있습니다. (GPU-Util (=GPU 이용율) 부분도 3%이므로 GPU가 거의 쉬고 있다고 보시면 됩니다)
그림9
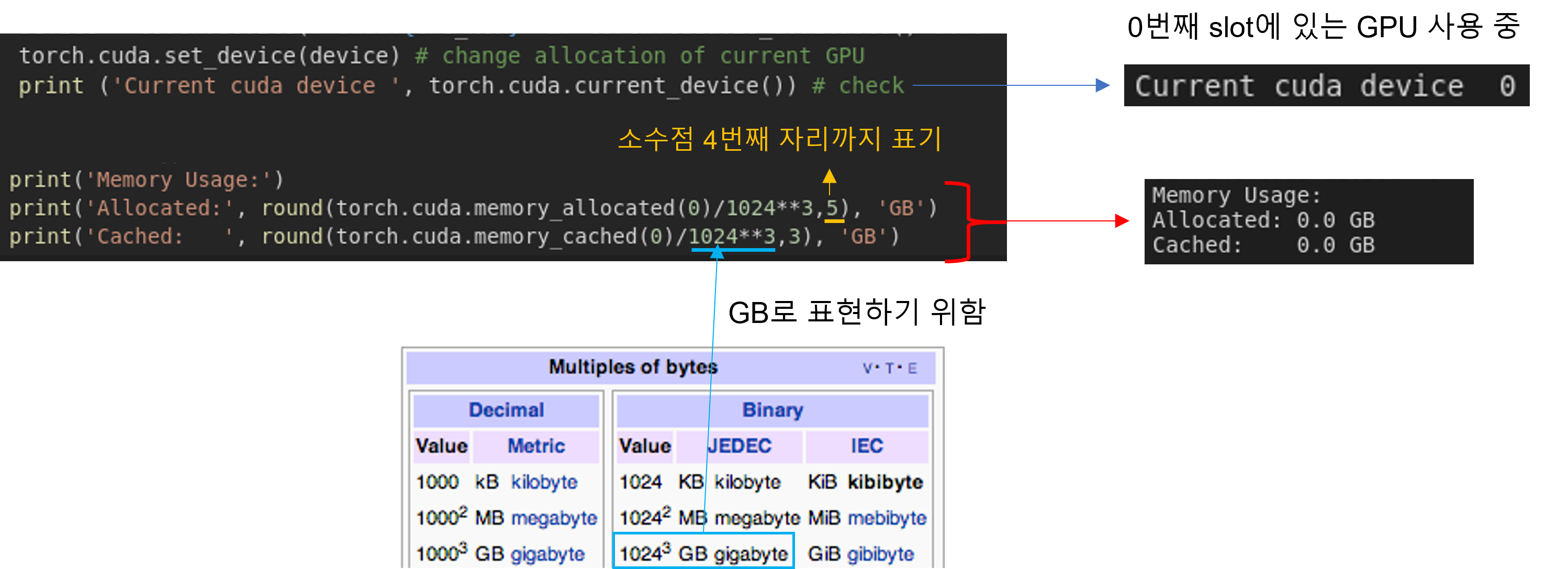
아래와 같이 코드를 수행해도 GPU 상의 메모리를 확인할 수 있는데, 아래 코드를 이용하면 아무런 메모리도 올라가 있지 않다는걸 확인할 수 있습니다. torch 관련한 코드로 GPU 메모리를 확인하면 torch 코드로 GPU 상에 데이터를 업로드 하지 않은 이상 GPU 메모리 용량이 0으로 표현되는듯 합니다.
그림10. 이미지 출처: https://velog.io/@victor/1kb-1024-bytes-1000-bytes-%EB%AD%90%EA%B0%80-%EB%A7%9E%EC%9D%84%EA%B9%8C-mojurs3pb2
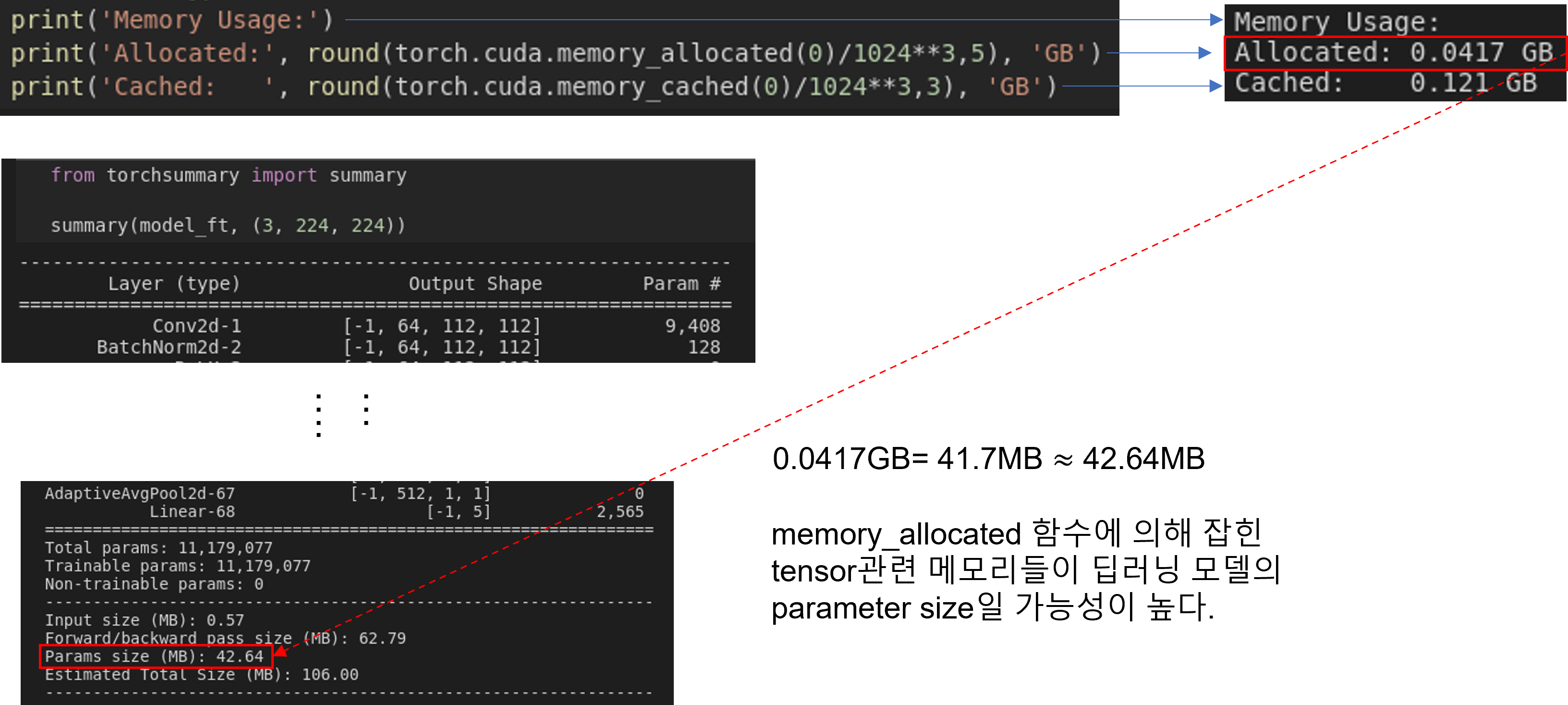
이번엔 아래 코드를 수행하여 딥러닝 모델을 GPU에 업로드 하고, GPU 메모리를 확인해 보도록 하겠습니다.
그림11
model.to(device): When loading a model on a GPU that was trained and saved on GPU, simply convert the initialized model to aCUDA optimized modelusing model.to(torch.device('cuda')).
그림12
torch.cuda.memory_allocated 설명
You can use memory_allocated() and max_memory_allocated() to monitor memory occupied bytensors, andusememory_reserved() andmax_memory_reserved() to monitor the total amount of memory managed by the caching allocator.
torch.cuda.memory_cached 설명
PyTorchuses a caching memory allocator to speed up memory allocations.
This allows fast memory deallocation without device synchronizations.
그림13
However, the unused memory managed by the allocator will still show as if used in nvidia-smi.
The nvidia-smi number includes space the allocated by the CUDA driver when it loadsPyTorch.
This can be quite large becausePyTorchincludes many CUDA kernels. On a P100, I’ve seen an overhead of ~487 MB.
This memory isn’t reported by thetorch.cuda.xxx_memoryfunctions because it’s not allocated by the program and there isn’t a good way to measure it outside of looking atnvidia-smi.
Our tensor is too small. The caching allocator allocates memory with a minimum size and a block size so it may allocate a bit more memory than the number of elements in your tensors.
Things likecudactx,cudarngstate,cudnnctx,cufftplans, and othergpumemory your other libraries may use are not counted in the torch.cuda.* stats.
그림14
지금까지 배운 내용(1.Data load(Feat. CUDA), 2.Data Preprocessing(Feat. Augmentation))을 코드로 요약 하면 아래와 같습니다.
# License: BSD
# Author: Sasank Chilamkurthy
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
plt.ion() # interactive mode
# Data augmentation and normalization for training
# Just normalization for validation
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = 'data/hymenoptera_data'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# Get a batch of training data
inputs, classes = next(iter(dataloaders['train']))
# Make a grid from batch
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])
model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
# Here the size of each output sample is set to 2.
# Alternatively, it can be generalized to nn.Linear(num_ftrs, len(class_names)).
model_ft.fc = nn.Linear(num_ftrs, 2)
model_ft = model_ft.to(device)
다음 글에서는 딥러닝 모델이 학습할 방향성을 결정해주는 loss function, optimizer, learning rate schedule 에 대해서 알아보도록 하겠습니다.
(↓↓↓ 다음 글에서 배울 코드내용↓↓↓)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)